
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Доброго времени суток!
Представляю вашему вниманию чек-лист из 100 вопросов по Data Science. Вопросы покрывают 5 областей: SQL, Python, Machine Learning, статистику и собственно саму DS.
Кому это вообще может быть полезно:
желающему получить оффер в сфере DS
тому, кто уже давно дата-сайнтист, но хочется освежить какие-то алгоритмы/темы
кто хочет поменять стек на что-то в области анализа и присматривается к DS
Собрал здесь самые частые вопросы с собесов на позицию джуна Data Science, получился так сказать 95% доверительный интервал всех возможных вопросов. Так что если разобраться в этих вопросах, с большой вероятностью Авито, Тинькофф и что у нас там ещё делает DS примет вас к себе на борт.
А если с синдромом самозванца проблем нет, то смело пробивайтесь в FAANG* (*MAANG), успехов)
Ну и в качестве интерлюдии, гениальная схема о том, как изучать DS. Нет, ну правда же)
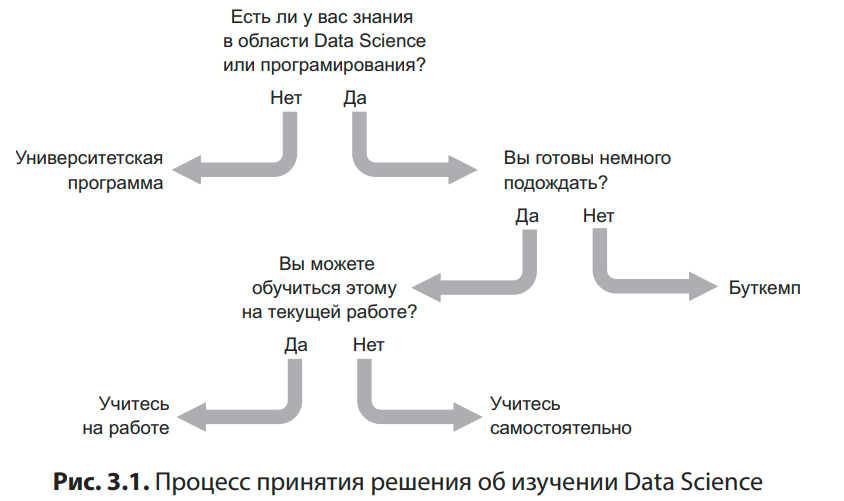
Кстати, если вам реально хочется изучать Data Science, массу годного контента вы найдёте в моём тг канале — это разборы заданий с собесов и масса полезных инструментов. А вот телеграм канал для тех, кто хочет изучить машинное обучение — нейронные сети, машинное обучение, Python. Вот ещё папка с годными ресурсами по Python — поможет в подготовке к собесу.
Параллельно к этой статье я запилил ролик с разбором части этих вопросов (в основном по Python), прошу — https://youtu.be/6Pk4OgdNxXQ

Ок, переходим к вопросам. Поехали!
Содержание
Секция "Статистика"
Что такое нормальное распределение?
Средняя проектная оценка в группе из 10 учеников получилась 7, а медиана 8. Как так получилось? Чему больше доверять?
Какова вероятность заражения пациента, если его тест позитивен, а вероятность заболевания в его стране составляет 0.1%?
Что такое центральная предельная теорема? В чем заключается ее практический смысл?
Какие примеры набора данных с негауссовым распределением вы можете привести?
Что такое метод максимизации подобия?
Вы баллотируетесь на пост, в выборке из 100 избирателей 60 будут голосовать за вас. Можете ли вы быть уверены в победе?
Как оценить статистическую значимость анализа?
Сколько всего путей, по которым мышь может добраться до сыра, перемещаясь только по линиям клетки?
В чем разница между линейной и логистической регрессией?
Приведите три примера распределений с длинным хвостом. Почему они важны в задачах классификации и регрессии?
Суть закона больших чисел
Что показывает p-значение (значимая вероятность)
Что такое биномиальная формула вероятности?
Счетчик Гейгера записывает 100 радиоактивных распадов за 5 минут. Найдите приблизительный 95% интервал для количества распадов в час.
Как рассчитать необходимый размер выборки?
В каких случаях вы бы использовали MSE и MAE?
Когда медиана лучше описывает данные, чем среднее арифметическое?
В чём разница между модой, медианой и матожиданием
Секция "SQL"
В чем заключается разница между MySQL и SQL Server?
Что делает UNION? В чем заключается разница между UNION и UNION ALL?
Как оптимизировать SQL-запросы?
Выведите список сотрудников с зарплатой выше, чем у руководителя
Какие оконные функции существуют?
Найдите список ID отделов с максимальной суммарной зарплатой сотрудников
В чём разница между CHAR и VARCHAR?
Выберите самую высокую зарплату, не равную максимальной зарплате из таблицы
Чем отличаются SQL и NoSQL?
В чём разница между DELETE и TRUNCATE?
Пронумеруйте строки в таблице employee
Пронумеруйте строки в таблице в разрезе отдела по зарплате
Какие есть уровни изоляции транзакций?
Секция "Python"
Какие отличия есть у Series и DataFrame в Pandas?
Напишите функцию, которая определяет количество шагов для преобразования одного слова в другое
В чём преимущества массивов NumPy по сравнению с (вложенными) списками python?
В чём отличие между map, apply и applymap в Pandas?
Самый простой способ реализовать скользящее среднее с помощью NumPy
Поддерживает ли Python регулярные выражения?
Продолжи: "try, except, ..."
Как построить простую модель логистической регрессии на Python?
Как выбрать строки из DataFrame на основе значений столбцов?
Как узнать тип данных элементов из массива NumPy?
В чём отличие loc от iloc в Pandas?
Напишите код, который строит все N-граммы на основе предложения
Каковы возможные способы загрузки массива из текстового файла данных в Python?
Чем отличаются многопоточное и многопроцессорное приложение?
Как можно использовать groupby + transform?
Напишите финальные значения A0, ..., A7
Чем отличаются mean() и average() в NumPy?
Приведите пример использования filter и reduce над итерируемым объектом
Как объединить два массива NumPy?
Напишите однострочник, который будет подсчитывать количество заглавных букв в файле
Как бы вы очистили датасет с помощью Pandas?
array и ndarray — в чём отличия?
Вычислите минимальный элемент в каждой строке 2D массива
Как проверить, является ли набор данных или временной ряд случайным?
В чём разница между pivot и pivot_table?
Реализуйте метод k-средних с помощью SciPy
Какие есть варианты итерирования по строкам объекта DataFrame?
Что такое декоратор? Как написать собственный?
Секция "Data Science"
Что такое сэмплирование? Сколько методов выборки вы знаете?
Чем корреляция отличается от ковариации?
Что такое кросс-валидация? Какие проблемы она призвана решить?
Что такое матрица ошибок? Для чего она нужна?
Как преобразование Бокса-Кокса улучшает качество модели?
Какие методы можно использовать для заполнения пропущенных данных, и каковы последствия невнимательного заполнения данных?
Что такое ROC-кривая? Что такое AUC?
Что такое полнота (recall) и точность (precision)?
Как бы вы справились с разными формами сезонности при моделировании временных рядов?
Какие ошибки вы можете внести, когда делаете выборку?
Что такое RCA (root cause analysis)? Как отличить причину от корреляции?
Что такое выброс и внутренняя ошибка? Объясните, как их обнаружить, и что бы вы делали, если нашли их в наборе данных?
Что такое A/B-тестирование?
В каких ситуациях общая линейная модель неудачна?
Является ли подстановка средних значений вместо пропусков допустимым? Почему?
Есть данные о длительности звонков. Разработайте план анализа этих данных. Как может выглядеть распределение этих данных? Как бы вы могли проверить, подтверждаются ли ваши ожидания?
Секция "Machine Learning"
Что такое векторизация TF/IDF?
Что такое переобучение и как его можно избежать?
Вам дали набор данных твитов, задача – предсказать их тональность (положительная или отрицательная). Как бы вы проводили предобработку?
Расскажите про SVM
В каких случаях вы бы предпочли использовать SVM, а не Случайный лес (и наоборот)?
Каковы последствия установки неправильной скорости обучения?
Объясните разницу между эпохой, пакетом (batch) и итерацией.
Почему нелинейная функция Softmax часто бывает последней операцией в сложной нейронной сети?
Объясните и дайте примеры коллаборативной фильтрации, фильтрации контента и гибридной фильтрации
В чем разница между bagging и boosting для ансамблей?
Как выбрать число k для алгоритма кластеризации «метод k-средних» (k-Means Clustering), не смотря на кластеры?
Как бы вы могли наиболее эффективно представить данные с пятью измерениями?
Что такое ансамбли, и чем они полезны?
В вашем компьютере 5Гб ОЗУ, а вам нужно обучить модель на 10-гигабайтовом наборе данных. Как вы это сделаете?
Всегда ли методы градиентного спуска сходятся в одной и той же точке?
Что такое рекомендательные системы?
Объясните дилемму смещения-дисперсии (bias-variance tradeoff) и приведите примеры алгоритмов с высоким и низким смещением.
Что такое PCA, и чем он может помочь?
Объясните разницу между методами регуляризации L1 и L2.
Секция "Статистика"
Вообще, если вы думаете, что матаном, производными и вычислением градиента мучают только свежеиспечённых выпускников-стажёров, то это не совсем так.
Вот, гляньте на задания с собеседования в ВТБ (спасибо Вадим) на позицию Data Science.

В целом, задания простые, но из-за отсутствия практики с ними могут быть проблемки. Так что на всякий случай перед собеседованием вспомните подобные базовые штуки из анализа, линейки, теорвера и прочих.
Да и вообще, учите матан — не зря же Миша Ломоносов говорил, что это ум в порядок приводит)
Перед тем, как перейти к разным вопросам по статистике и т.д. можно пройти вот такой замечательный тест, насколько в голове ещё сохранились основы (тест позаимствован из статьи)


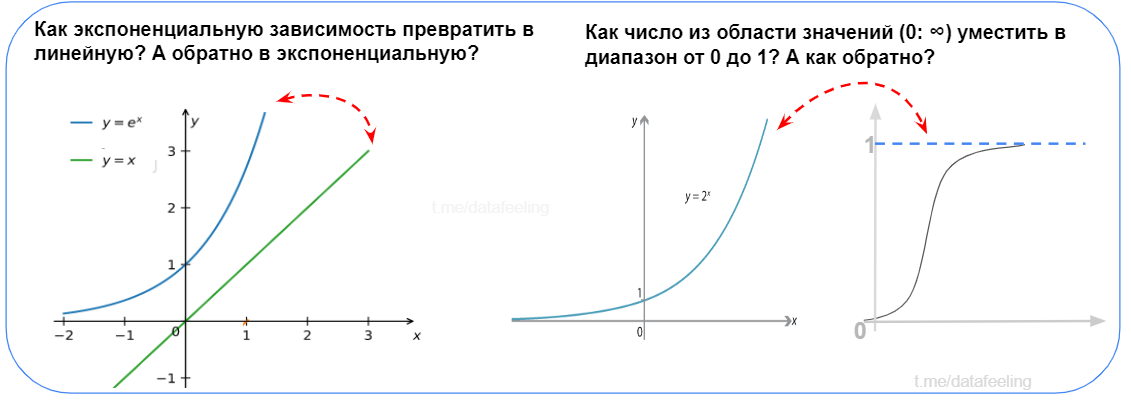

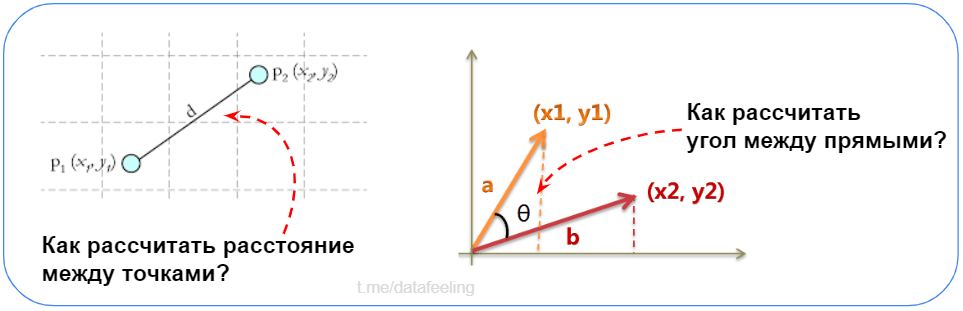

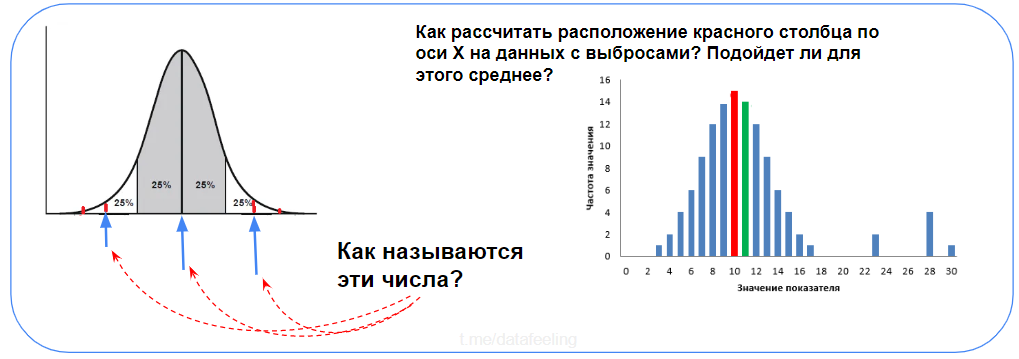
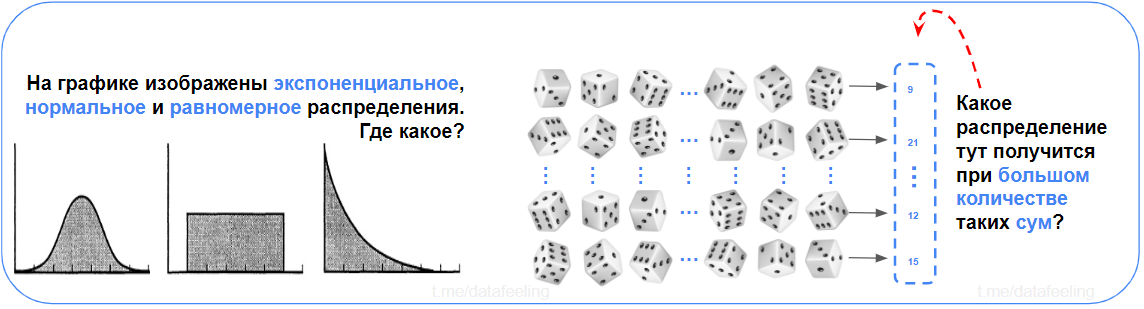
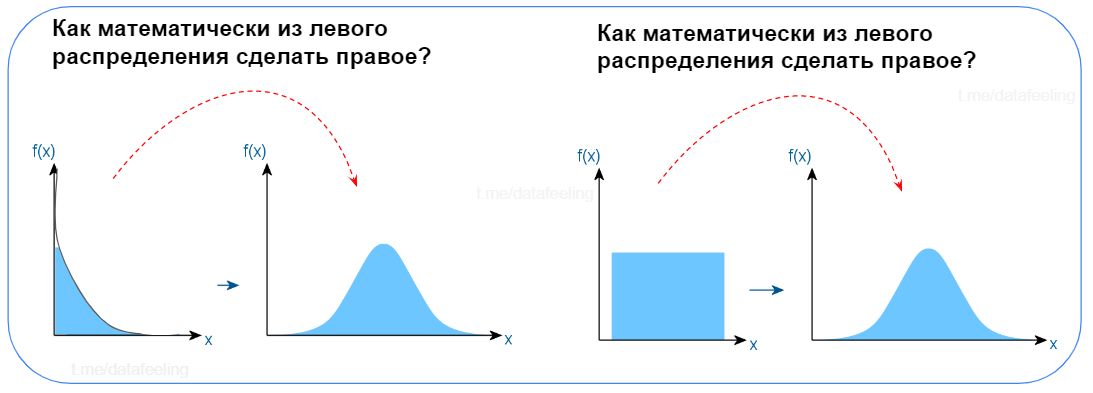


Что такое нормальное распределение?
А что, вдруг кандидат не знает ¯\_(ツ)_/¯
Нормальное распределение (Гаусса) задаётся такой функцией плотности вероятности:
тут параметр  — математическое ожидание (среднее значение), медиана и мода распределения, а параметр
— математическое ожидание (среднее значение), медиана и мода распределения, а параметр  — среднеквадратическое отклонение,
— среднеквадратическое отклонение,  — дисперсия распределения.
— дисперсия распределения.
А это график нормального распределения и процент попадания случайной величины на отрезки, равные среднеквадратическому отклонению.
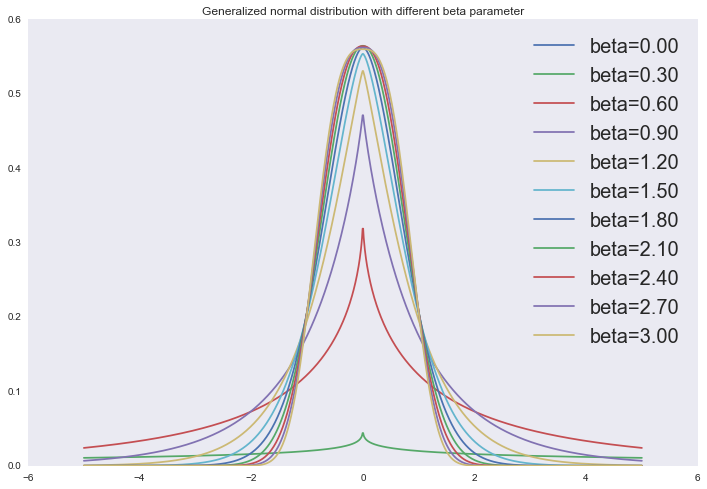
Кстати, если хочется блеснуть на собесе, можно упомянуть обобщённую формулу нормального распределения:

Отрисовать это можно так:
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import gennorm
x = np.linspace(-5, 5, 1000)
for beta in np.linspace(0, 3, 11):
plt.plot(x, gennorm.pdf(x, beta=beta), label='beta=%0.2f' % beta)
plt.legend(loc='upper right', prop={'size': 10})
plt.title('Generalized normal distribution with different beta parameter')
plt.show()
Средняя проектная оценка в группе из 10 учеников получилась 7, а медиана 8. Как так получилось? Чему больше доверять?
Это простой вопрос.
Если средняя оценка в группе – 7, а медиана – 8, это может означать, что в группе есть несколько учеников, которые получили довольно низкие оценки, что снизило среднюю оценку, но при этом большинство учеников получили более высокие оценки, что повысило медиану.
Доверять в данном случае можно обоим показателям, но важно учитывать их интерпретацию. Средняя оценка подвержена влиянию крайних значений, так что если в группе есть несколько учеников с низкими оценками, это существенно снизит среднюю оценку. Медиана же отражает значение, которое разделяет выборку на две равные части, и не подвержена такому влиянию крайних значений.
Чему больше доверять - зависит от цели анализа данных. Если интересует общая картина и средний уровень успеваемости группы, то лучше использовать среднюю оценку. Если же интересует типичный уровень успеваемости учеников, то лучше использовать медиану.
Какова вероятность заражения пациента, если его тест позитивен, а вероятность заболевания в его стране составляет 0.1%?
Для решения этой задачи нам нужно знать чувствительность и специфичность теста. Чувствительность теста - это вероятность того, что тест даст положительный результат у зараженного пациента. Специфичность теста - это вероятность того, что тест даст отрицательный результат у незараженного пациента.
Допустим, что у нашего теста чувствительность 95% и специфичность 99%. Это означает, что из 100 зараженных пациентов тест правильно определит 95, а из 100 незараженных пациентов тест правильно определит 99.
Теперь мы можем использовать формулу Байеса для вычисления вероятности заражения при положительном тесте:

где  - вероятность получить положительный тест при наличии заражения,
- вероятность получить положительный тест при наличии заражения,  - вероятность заражения в популяции,
- вероятность заражения в популяции,  - общая вероятность получить положительный тест.
- общая вероятность получить положительный тест.
Подставляя значения, получаем:

Таким образом, вероятность заражения пациента при положительном тесте составляет около 8.7%.
Что такое центральная предельная теорема? В чем заключается ее практический смысл?
Пока не далеко ушли от нормального распределения, обсудим центральную предельную теорему (ЦПТ).

Интересные статьи
Интересные статьи


