

Источник изображения: Shutterstock.com/photowind
Добрый день, меня зовут Тараканов Анатолий, я senior java разработчик SberDevices. 2.5 года программирую на Java, до этого 6 лет писал на C# и 1 год на Scala. Хочу поделиться опытом создания сервиса-оркестратора Voice Processing Service. Он является точкой входа для пользователей семейства виртуальных ассистентов Салют. Через него также проходит часть трафика приложений SmartMarket, где любой разработчик может написать навык для наших виртуальных ассистентов Салют. Одним словом, на сервис приходится немалая нагрузка. Давайте посмотрим, какие проблемы при его создании возникли и как мы их решали, а также сколько времени ушло на поиск причин. И всё это в контексте реактивного фреймворка Spring WebFlux.
Немного о сервисе
Начнем с обзора архитектуры нашего сервиса-оркестратора. Он управляет процессом обработки входящего трафика от пользователей, формированием и передачей ответа. Среди смежных систем, к которым он обращается, есть такие сервисы:
- идентификации по токену, а также голосовым и видеоданным;
- насыщения запроса дополнительными данными о пользователе и истории взаимодействия;
- преобразования речевого сигнала в текстовое представление;
- обработки естественного языка;
- преобразования текста в голосовое представление;
- запуска пилотных фич;
- распознавания музыки и другие.
Как видно, смежных систем немало. API части из них доступны по REST-у – запрос-ответ, другие по Socket-у – потоковая передача данных.
Сервис хостится в нескольких ЦОДах, в том числе в SberCloud, горизонтально масштабируется в OpenShift. Для передачи, поиска и хранения логов используется ELK-стек, для трассировки –Jaeger, для сбора метрик – Prometheus, а для их отображения – Grafana.
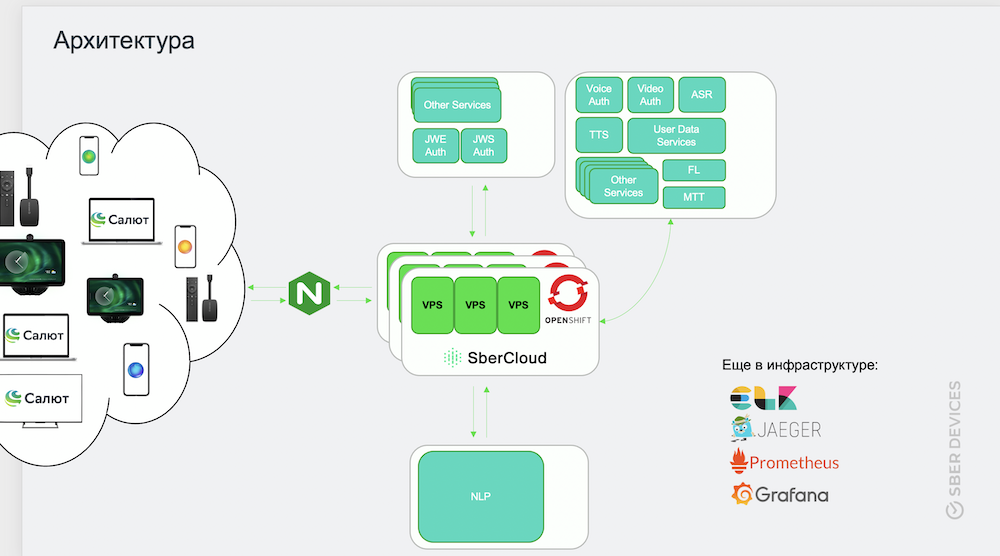
Каждый инстанс в секунду держит нагрузку примерно в 7000 пакетов (средний размер пакета 3000 байт). Это эквивалентно активности 400 пользователей, которые без перерыва обращаются к виртуальному ассистенту. С учётом взаимодействия нашего сервиса со смежными число пакетов увеличивается втрое – до 21 000.
Каждая виртуалка имеет 3 ядра и 8 Gb оперативной памяти.
Сервис создавался в реалиях стартапа, а значит неопределенности. Были такие вводные:
- поддержка TLS/mTLS;
- WebSocket с клиентом;
- текстовый, голосовой стриминг;
- отказоустойчивость 99.99;
- высокая нагрузка;
- масса смежных систем в перспективе и необходимость в гибком формате контракта.
В этих реалиях мы выбрали такие технологии:
- Java 11 с Gradle;
- JSON/Protobuf на транспортном уровне.
Оба формата позволяют легко шерить контракт между командами, программирующими на разных языках. Для обоих форматов есть решения автогенерации DTO в нотации многих языков на базе исходной структуры. Оба позволяют без боли вносить изменения в контракт.
А ещё мы использовали Junit 5 и Mokito для тестирования и несколько библиотек – Nimbus JOSE + JWT, Google Guava, Lombok, vavr.io – для удобства в виде синтаксического сахара и автогенерации кода.
Оценив требования, мы решили втащить в наш технологический стек Spring WebFlux с Reactor и Netty под капотом.
Итак, поговорим о нюансах использования этого реактивного фреймворка.
Кастомизация Netty-сервера
Сразу отмечу, что не все настройки Netty-сервера доступны через спринговые проперти или аргументы командной строки. А ещё иногда необходимо повесить логику на события самого сервера и подключения, заменить стандартный обработчик события в рамках подключения и добавить свой регистратор метрик.
Так вот, всё это можно сделать в компоненте, имплементирующем WebServerFactoryCustomizer. В его методе доступны как HttpServer, так и каждое клиентское подключение.

Пропущу этап создания сервиса и сразу перейду к его сдаче на стенд нагрузочного тестирования. В тот же день мы получили фидбэк о том, что с течением времени число незакрытых соединений растёт. Стали искать причину – анализировали tcp-дампы с помощью WireShark. Выяснилось, что клиент не присылал сигнал о закрытии соединения, а также, что в реакторе по умолчанию не инициализируются обработчики таймаутов на входящие/исходящие пакеты. Для исправления ситуации в вышеуказанный компонент был добавлен такой обработчик.
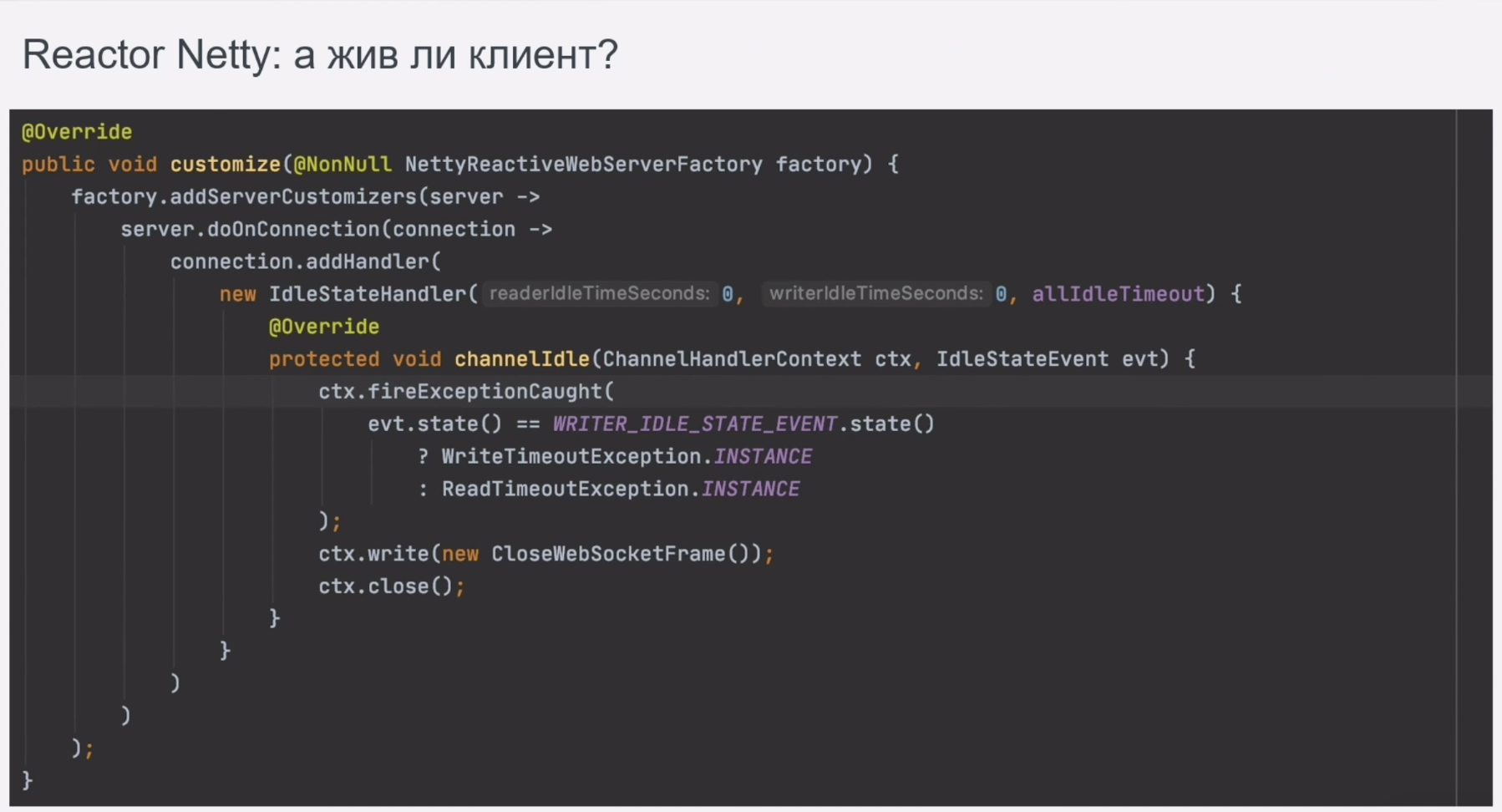
На просмотр логов, анализ ситуации со смежниками, сбор дампов и их анализ, исправление и тестирование у нас ушло 2 дня. Немало.
Следующей проявившейся под нагрузкой проблемой было то, что спустя порядка 30 минут после начала теста смежные сервисы, доступные по RESTу, стали иногда отвечать на запросы ошибкой «Сonnection reset by peer». Мы снова отправились смотреть логи, дампы. Оказалось, дело было в том, что при инициализации HttpClient-а фабричным методом .create(), размер пула соединений по умолчанию будет равен 16 или числу процессоров, умноженному на два. Со своей логикой выселения, ожидания свободного соединения и многим другим. И это всё на каждый тип протокола.

Фреймворк таким образом нам «помогает сэкономить» на хэндшейках, построении маршрута в сети, что, конечно, приятно, когда есть корреляция хотя бы по ttl между ним и настройками смежных сервисов и операционных систем в месте их хостинга.
Но всего этого не было, поэтому на время при взаимодействии с такими клиентами мы стали применять ConnectionProvider с отключенным пулом.

Поиск причины такого поведения съел 3 дня, это больно.
Мы развивали наш сервис дальше, накручивали логику, сценарии становились всё сложнее – и вот, в один прекрасный день с нагрузочного тестирования пришла печальная весть: мы перестали держать ожидаемую нагрузку. Что обычно делают в таком случае – берут в руку JFR и профилируют. Так мы и поступили. Результат не заставил себя долго ждать. Мы обнаружили, что при написании fluent-цепочек вызовов методов Flux-ов о декомпозиции логики в функциональном стиле стоит забыть.
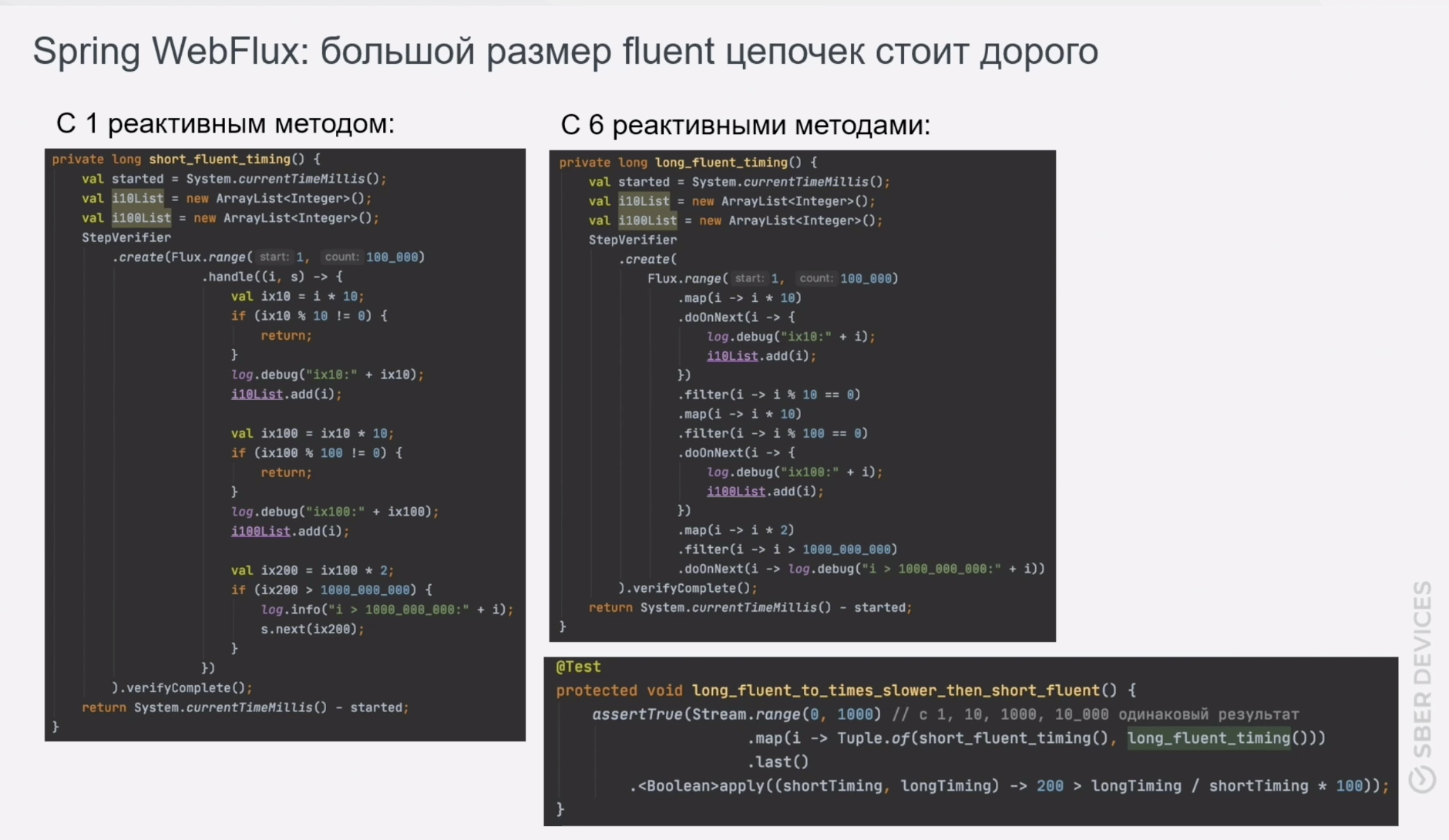
В приведенном фрагменте кода замеряется работа флакса из 100_000 элементов с 1 реактивным методом, во втором – с 6 методами. Тест проверяет, что первый метод работает вдвое быстрее второго, причем число итераций проверок не играет роли.
Почему так? Потому что на каждом этапе вызова методов .map/.filter/.flatmap/.switchOnFirst/.window и других создается Publisher, Subscriber и другие специфичные каждому из этих методов объекты. В момент подписки происходит вызов Publisher и Subscriber вверх по fluent-цепочке. Все эти накладные расходы можно наглядно увидеть в стектрейсах. Эту проблему решали 3 дня, такого рода рефакторинг – недешёвое удовольствие.
Итак, мы отрефачили код, прошли тестирование. Ещё несколько месяцев обрастали новыми смежными сервисами и сценариями потоковой обработки. Как вы думаете, какие грабли пришли в движение следующими? Те, что находятся в ядре самого WebFlux-а. В логике сервиса было с десяток мест с методами .groupBy и .flatMap. В связи с особенностями контракта и бизнес-логики они порождали множество очередей, к тому же при некоторых стечениях обстоятельств группы не финализировались. Приклад не падал, но процессинг останавливался, а перед этим происходила утечка памяти.
Кстати, на гитхабе много вопросов по этой теме. Если отвечать коротко, то стоит заглядывать вглубь каждого метода. Там может быть много интересного: от ограничений по размеру внутренней очереди, volatile чтений/записей, до порождения потенциально бесконечного числа очередей, которые сами собой не зафиналятся. Подробнее здесь: github.com/reactor/reactor-core/issues/596.
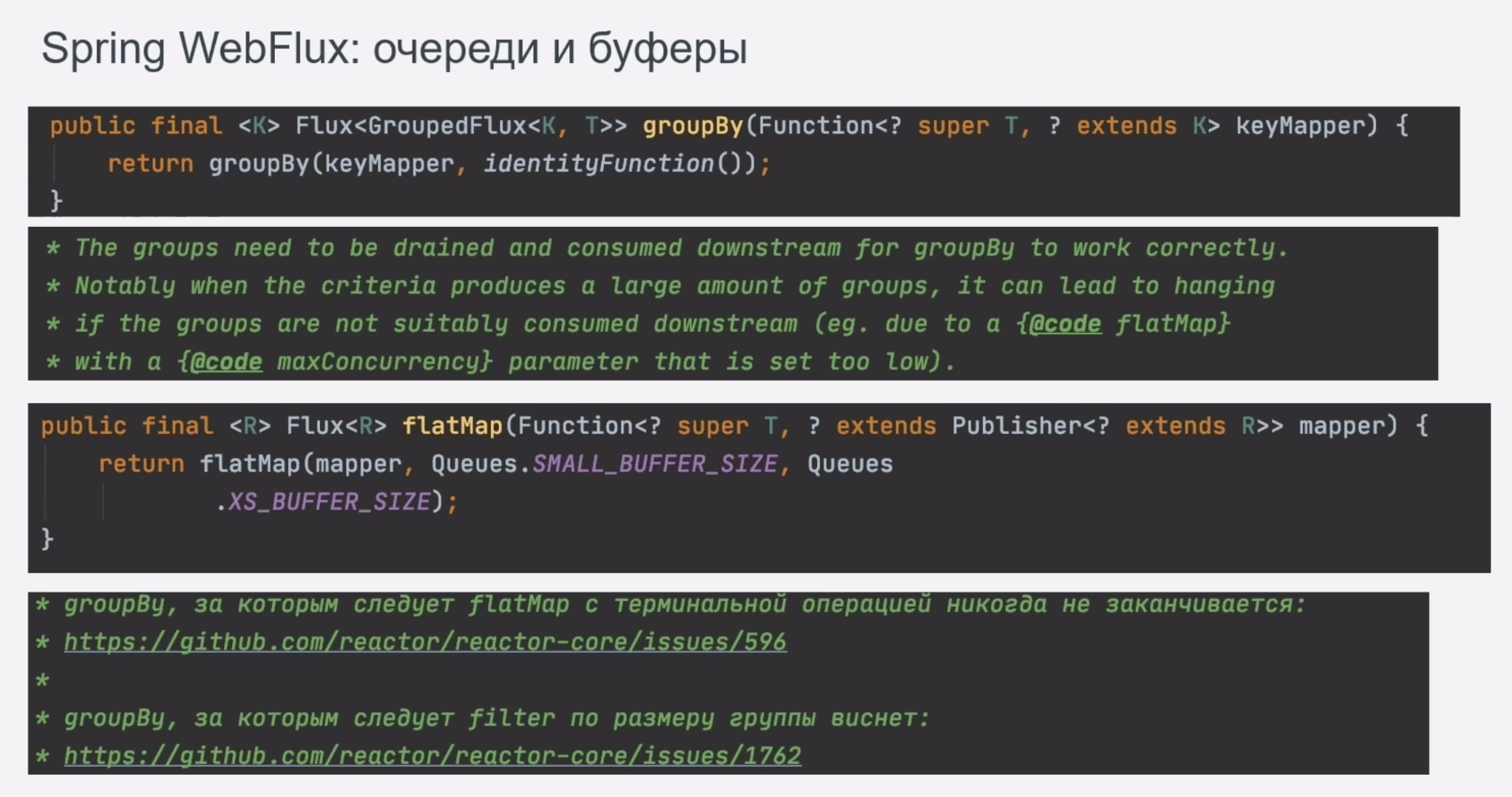
Вот, собственно, простой тест с замиранием процессинга.
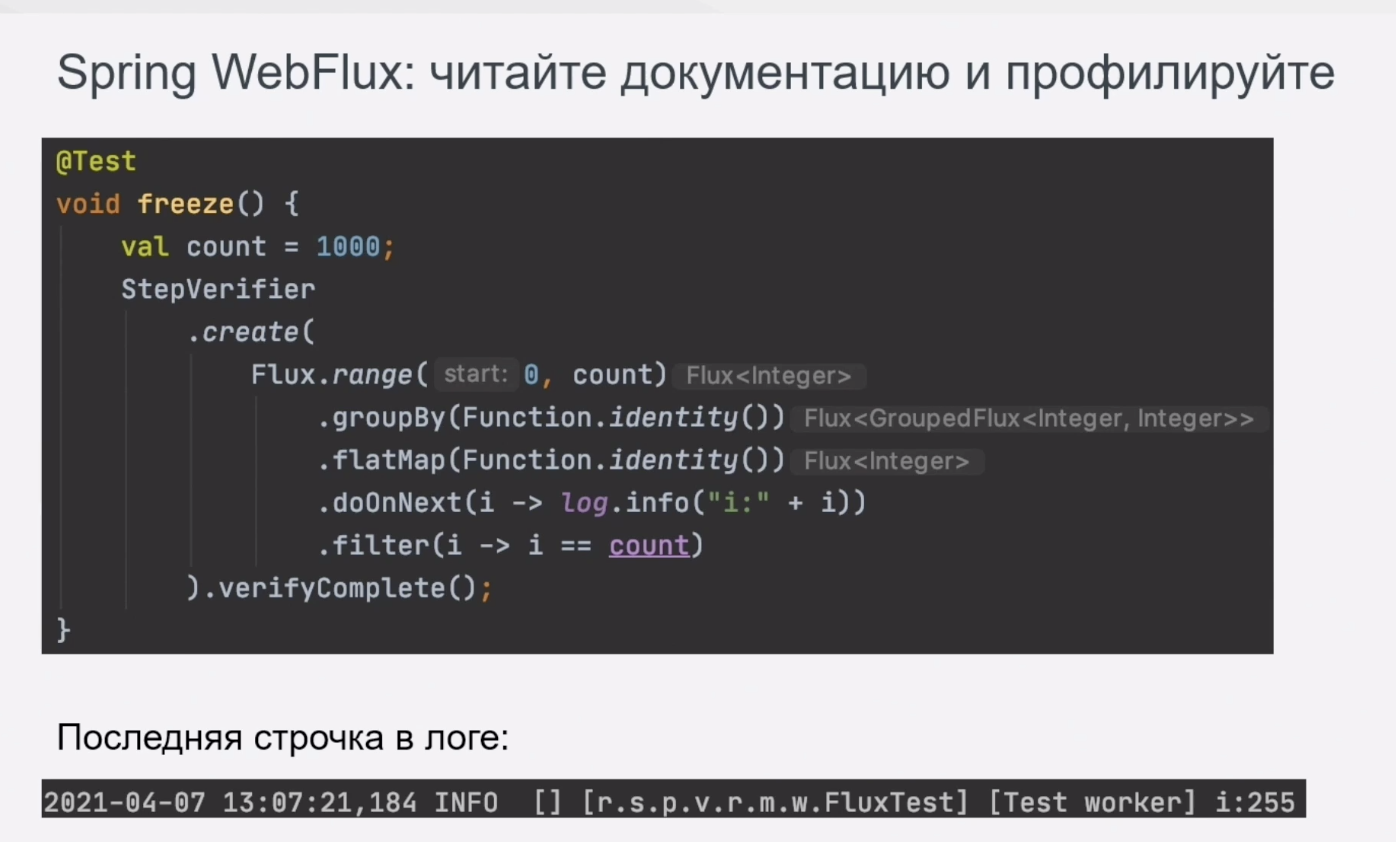
Как видно, последняя запись в логе – 255 элемент. Если заглянуть в документацию, то причина такого поведения станет очевидна, но кто её читает?) Особенно когда методы имеют такие говорящие и всем привычные названия.
Были проблемы и с методом .windowWhile. Вот ссылка на найденный нами в этом методе баг. Отмена подписки на его источник данных останавливала работу оператора.
С фреймворком Spring WebFlux нужно быть очень аккуратным. В том числе нужно следить за тем, какой паблишер возвращается методом. На какие-то можно подписываться неограниченное число раз (FluxReplay), но они имеют нюанс с размером буфера, другие возвращают один и тот же элемент каждому новому подписчику (MonoDefer).
Несколько эффективных и дешёвых оптимизаций
- Переход на Z Garbage Collector сильно улучшил производительность, а интервалы простоя приложения во время сборки мусора сократились с 200 мс до 20 мс.
- С той же версией приложения и под той же нагрузкой G1 давал пилу с большими зубьями по таймингам, Major GC вообще шёл вразнос, так как не хватало CPU на I/O-операции. В то же время ZGC / Shenandoah GC сократили пилу раз в 10.
- Если ваш сервис занимается передачей тяжеловесных данных (голоса или видео) стоит внимательно посмотреть на io.netty.buffer и пользоваться его возможностями. Профилирование показало, что его использование позволило вдвое уменьшить основную категорию мусора в памяти.
- Использование метрик Reactor Netty вместе с профилированием показали, что на криптографию уходила уйма времени, поэтому мы перешли с JDK SSL на Open SSL. Это в 2 раза ускорило приклад.
Используйте JFR + JMC, именно они подсветили все эти проблемы. Во время ревью кода можно сделать неверные выводы, бенчмарк для отдельных маленьких операций можно некорректно написать и получить непоказательные результаты, но flame graph/monitor wait/thread park/GC-разделы в JMC подсветят реальные проблемы.
В качестве итогов
Reactor Netty – удобен, гибок и быстр. Что касается текущей реализации Spring WebFlux, то она позволяет добиться высокой производительности, даже если сервис процессит большой объем событий в единицу времени в рамках каждого подключения и содержит витиеватую логику с нелинейной обработкой и ветвлениями.
Но придётся следовать трём правилам:
— размеры очередей и буферов «под капотом» требуют тонкой настройки. Также нужно помнить, что использование фреймворка на каждом шагу порождает новый источник данных, который нужно закрывать;
— следует избегать тяжеловесных .groupBy и .flatMap, лучше использовать .handle и .flatMapIterable, где возможно;

— цепочки вызовов методов фреймворка должны быть короткими, а декомпозицией логики обработки лучше заниматься в своих методах, либо использовать Operators.lift и Sinks для создания своего реактивного оператора.

И повторюсь, читайте документацию и профилируйте. Этот кактус нужно научиться готовить прежде, чем есть, иначе в ходе трапезы он станет только больше.

Источник изображения: Shutterstock.com/SEE D JAN
Отдельного рассказа заслуживают нюансы применения сборщиков мусора (GC), инструментов JFR/JMC, особенности работы с буферами и очередями в Spring WebFlux, а также тонкости настройки Netty-сервера.



