

В этой подборке, переводом которой мы решили поделиться к старту курса о машинном и глубоком обучении, по мнению автора, каждая библиотека заслуживает отдельной статьи. Всё начинается с самого начала: предлагается библиотека, которая сокращает шаблонный код импортирования; заканчивается статья пакетом удобной визуализации данных для исследовательского анализа. Автор также касается работы с картами Google, ускорения и упрощения работы с моделями ML и библиотеки, которая может повысить качество вашего проекта в области обработки естественного языка. Посвящённый подборке блокнот Jupyter вы найдёте в конце.
PyForest
Когда вы начинаете писать код для проекта, каков ваш первый шаг? Наверное, вы импортируете нужные библиотеки. Проблема в том, что заранее неизвестно, сколько библиотек нужно импортировать, пока они вам не понадобятся, то есть пока вы не получите ошибку.
Вот почему PyForest — это одна из самых удобных библиотек, которые я знаю. С её помощью в ваш блокнот Jupyter можно импортировать более 40 популярнейших библиотек (Pandas, Matplotlib, Seaborn, Tensorflow, Sklearn, NLTK, XGBoost, Plotly, Keras, Numpy и другие) при помощи всего одной строки кода.
Выполните pip install pyforest. Для импорта библиотек в ваш блокнот введите команду from pyforest import *, и можно начинать. Чтобы узнать, какие библиотеки импортированы, выполните lazy_imports().

При этом с библиотеками удобно работать. Технически они импортируются только тогда, когда вы упоминаете их в коде. Если библиотека не упоминается, она не импортируется.
Emot
Эта библиотека может повысить качество вашего проекта по обработке естественного языка. Она преобразует эмотиконы в их описание. Представьте, например, что кто-то оставил в Твиттере сообщение “I ️️[здесь в оригинале эмодзи "красное сердце", новый редактор Хабра вырезает его] Python”. Человек не написал слово “люблю”, вместо него вставив эмодзи. Если твит задействован в проекте, придётся удалить эмодзи, а значит, потерять часть информации.
Вот здесь и пригодится пакет emot, преобразующий эмодзи в слова. Для тех, кто не совсем понял, о чём речь, эмотиконы — это способ выражения через символы. Например, :) означает улыбку, а :( выражает грусть. Как же работать с библиотекой?
Чтобы установить Emot, выполните команду pip install emot, а затем командой import emot импортируйте её в свой блокнот. Нужно решить, с чем вы хотите работать, то есть с эмотиконами или с эмодзи. В случае эмодзи код будет таким: emot.emoji(your_text). Посмотрим на emot в деле.
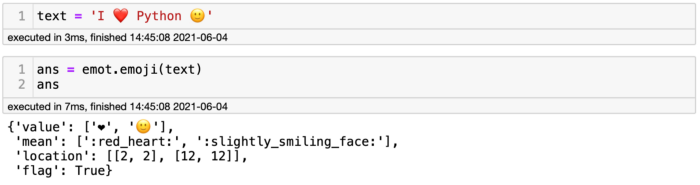
Выше видно предложение I ️ ️️[эмодзи "красное сердце"] Python, обёрнутое в метод Emot, чтобы разобраться со значениями. Код выводит словарь со значением, описанием и расположением символов. Как всегда, из словаря можно получить слайс и сосредоточиться на необходимой информации, например, если я напишу ans['mean'], вернётся только описание эмодзи.

Geemap
Говоря коротко, с её помощью можно интерактивно отображать данные Google Earth Engine. Наверное, вы знакомы с Google Earth Engine и всей его мощью, так почему не задействовать его в вашем проекте? За следующие несколько недель я хочу создать проект, раскрывающий всю функциональность пакета geemap, а ниже расскажу, как можно начать с ним работать.
Установите geemap командой pip install geemap из терминала, затем импортируйте в блокнот командой import geemap. Для демонстрации я создам интерактивную карту на основе folium:
import geemap.eefolium as geemap
Map = geemap.Map(center=[40,-100], zoom=4)
Map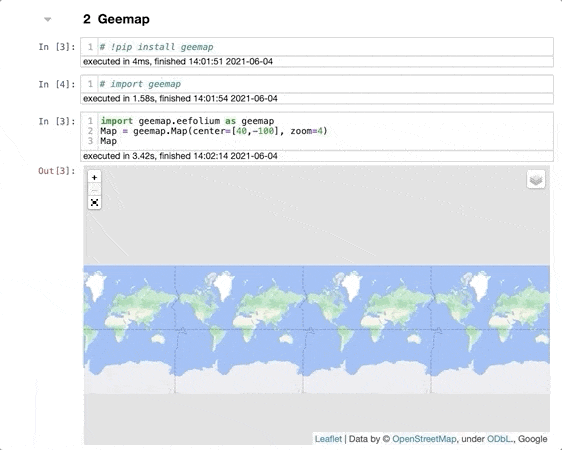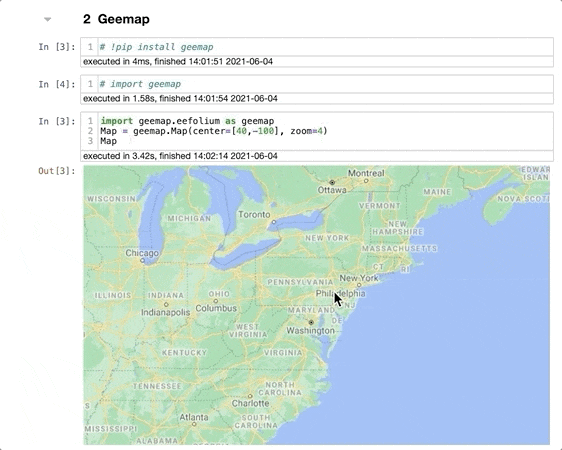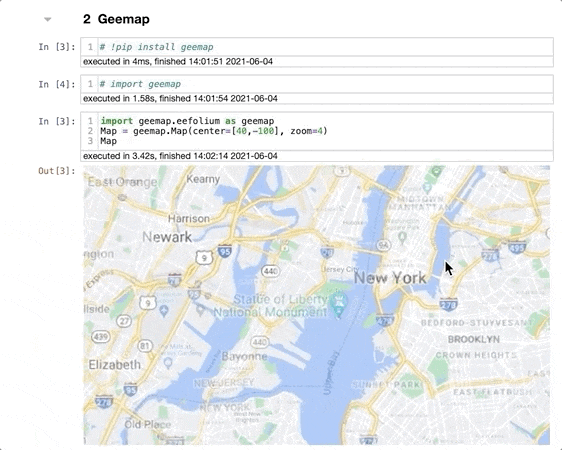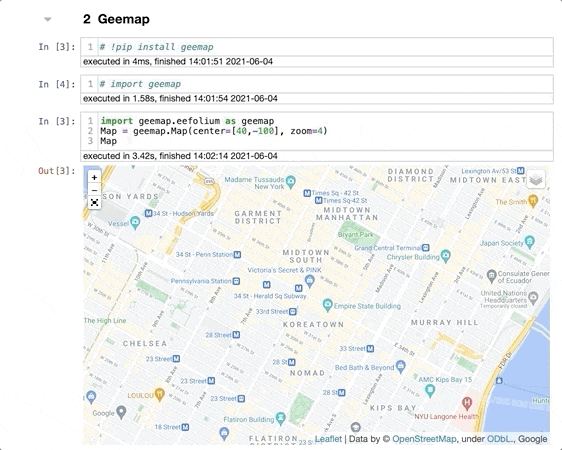
Как я уже сказал, я не изучил эту библиотеку настолько, насколько она того заслуживает. Но у неё есть исчерпывающий Readme о том, как она работает и что можно делать с её помощью.
Dabl
Позвольте мне рассказать об основах. Dabl создан, чтобы упростить работу с моделями ML для новичков. Чтобы установить её, выполните pip install dabl, импортируйте пакет командой import dabl — и можно начинать. Выполните также строчку dabl.clean(data), чтобы получить информацию о признаках, например о том, есть ли какие-то бесполезные признаки. Она также показывает непрерывные, категориальные признаки и признаки с высокой кардинальностью.
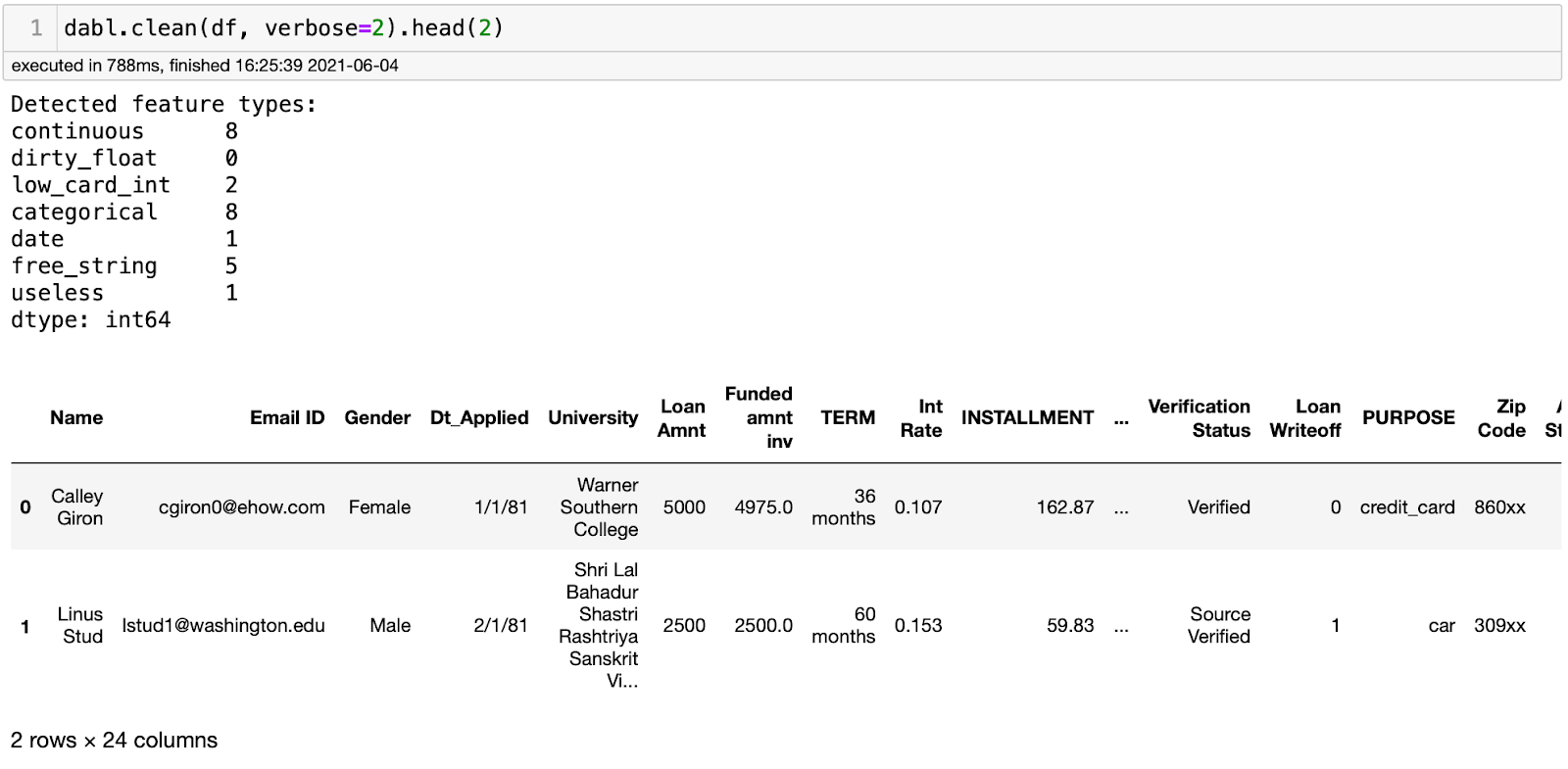
Чтобы визуализировать конкретный признак, можно выполнить dabl.plot(data).

Наконец, одной строчкой кода вы можете создать несколько моделей вот так: dabl.AnyClassifier, или так: dabl.Simplefier(), как это делается в scikit-learn. Но на этом шаге придётся предпринять некоторые обычные шаги, такие как создание тренировочного и тестового набора данных, вызов, обучение модели и вывод её прогноза.
# Setting X and y variables
X, y = load_digits(return_X_y=True)
# Splitting the dataset into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=1)
# Calling the model
sc = dabl.SimpleClassifier().fit(X_train, y_train)
# Evaluating accuracy score
print(“Accuracy score”, sc.score(X_test, y_test))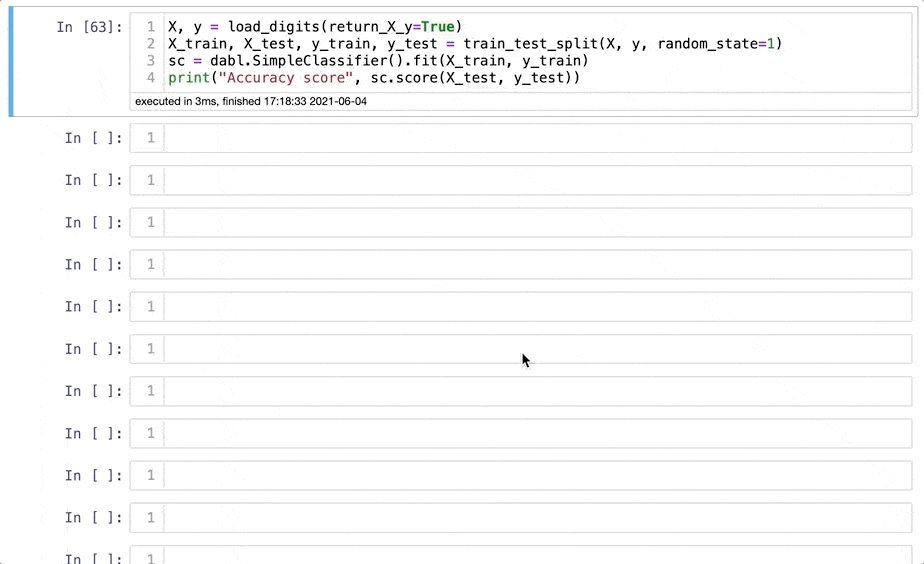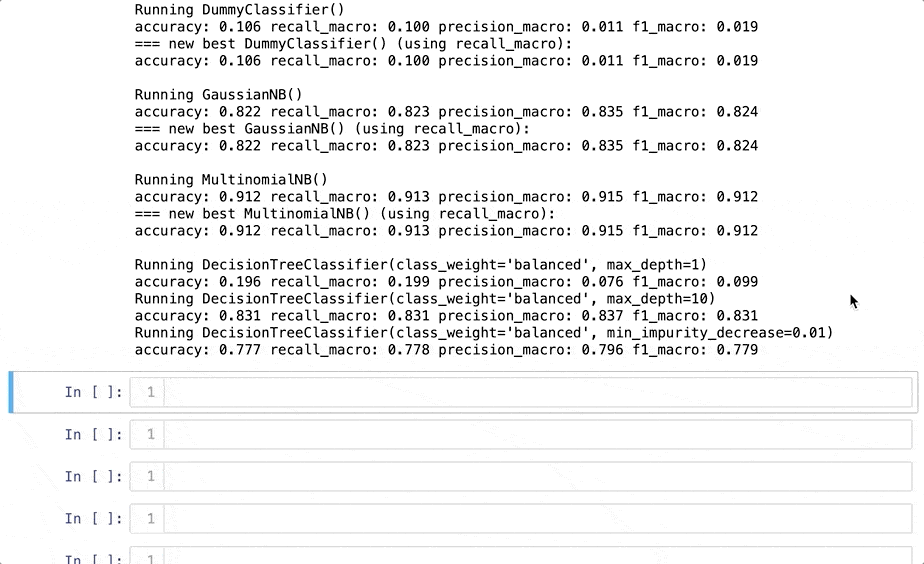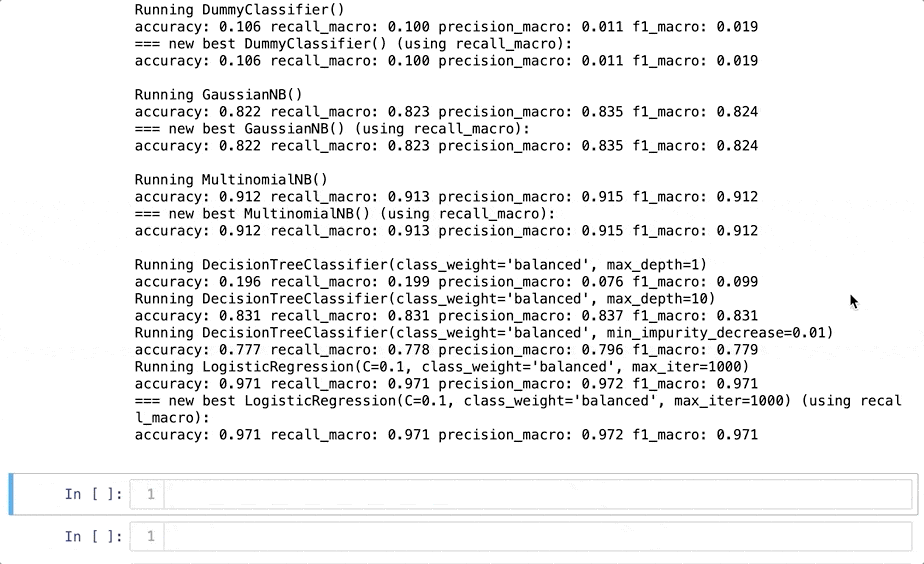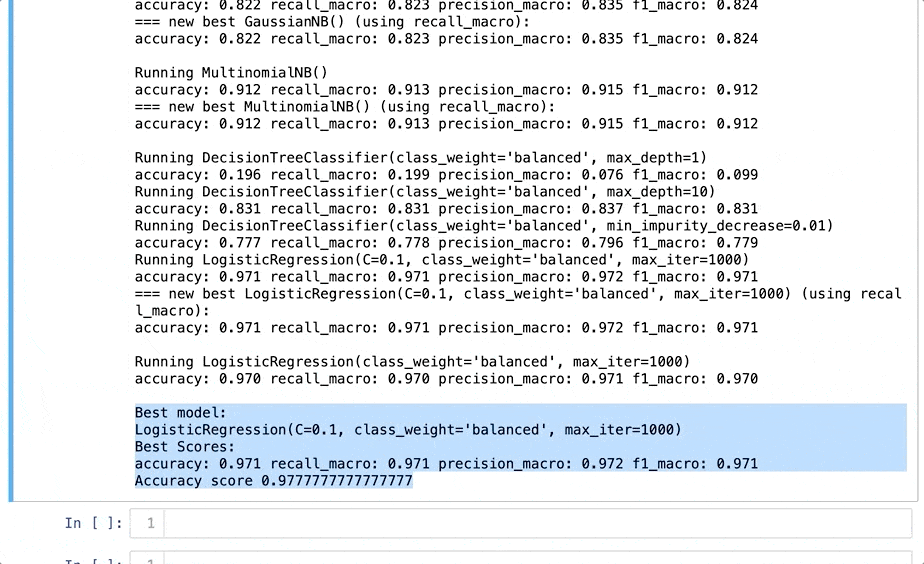
Как видите, Dabl итеративно проходит через множество моделей, включая Dummy Classifier (фиктивный классификатор), GaussianNB (гауссовский наивный Байес), деревья решений различной глубины и логистическую регрессию. В конце библиотека показывает лучшую модель. Все модели отрабатывают примерно за 10 секунд. Круто, правда? Я решил протестировать последнюю модель при помощи scikit-learn, чтобы больше доверять результату:

Я получил точность 0,968 с обычным подходом к прогнозированию и 0,971 — с помощью Dabl. Для меня это достаточно близко! Обратите внимание, что я не импортировал модель логистической регрессии из scikit-learn, поскольку это уже сделано через PyForest. Должен признаться, что предпочитаю LazyPredict, но Dabl стоит попробовать.
SweetViz
Это low-code библиотека, которая генерирует прекрасные визуализации, чтобы вывести ваш исследовательский анализ данных на новый уровень при помощи всего двух строк кода. Вывод библиотеки — интерактивный файл HTML. Давайте посмотрим на неё в общем и целом. Установить её можно так: pip install sweetviz, а импортировать в блокнот — строкой import sweetviz as sv. И вот пример кода:
my_report = sv.analyze(dataframe)
my_report.show_html()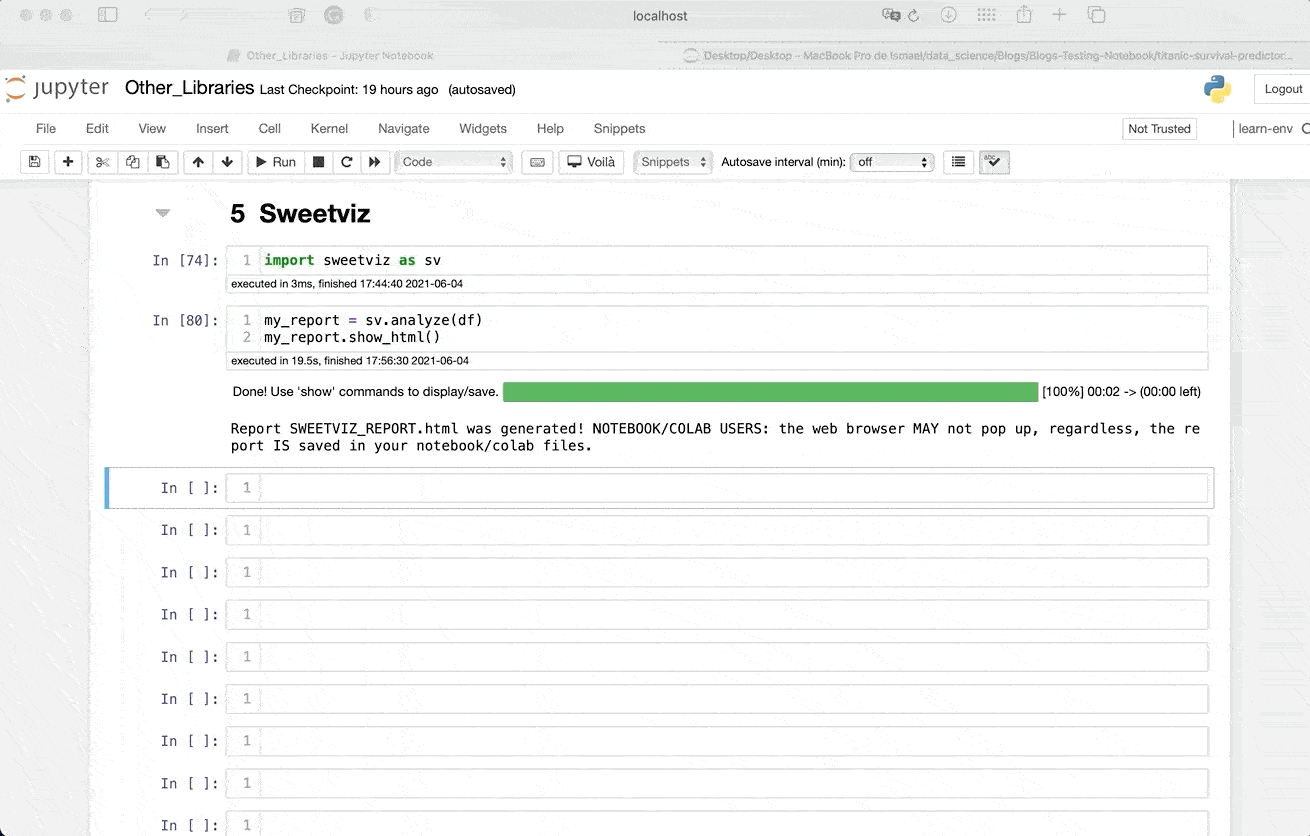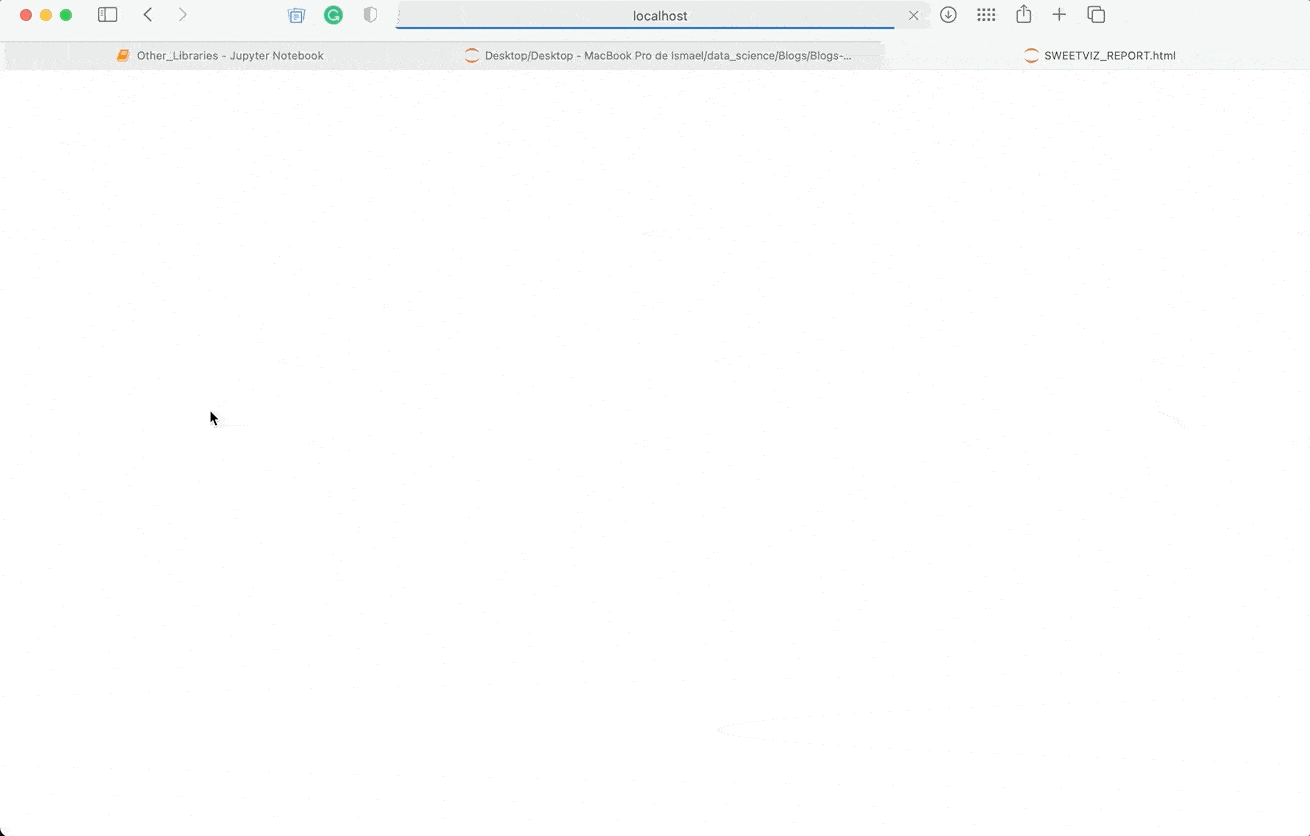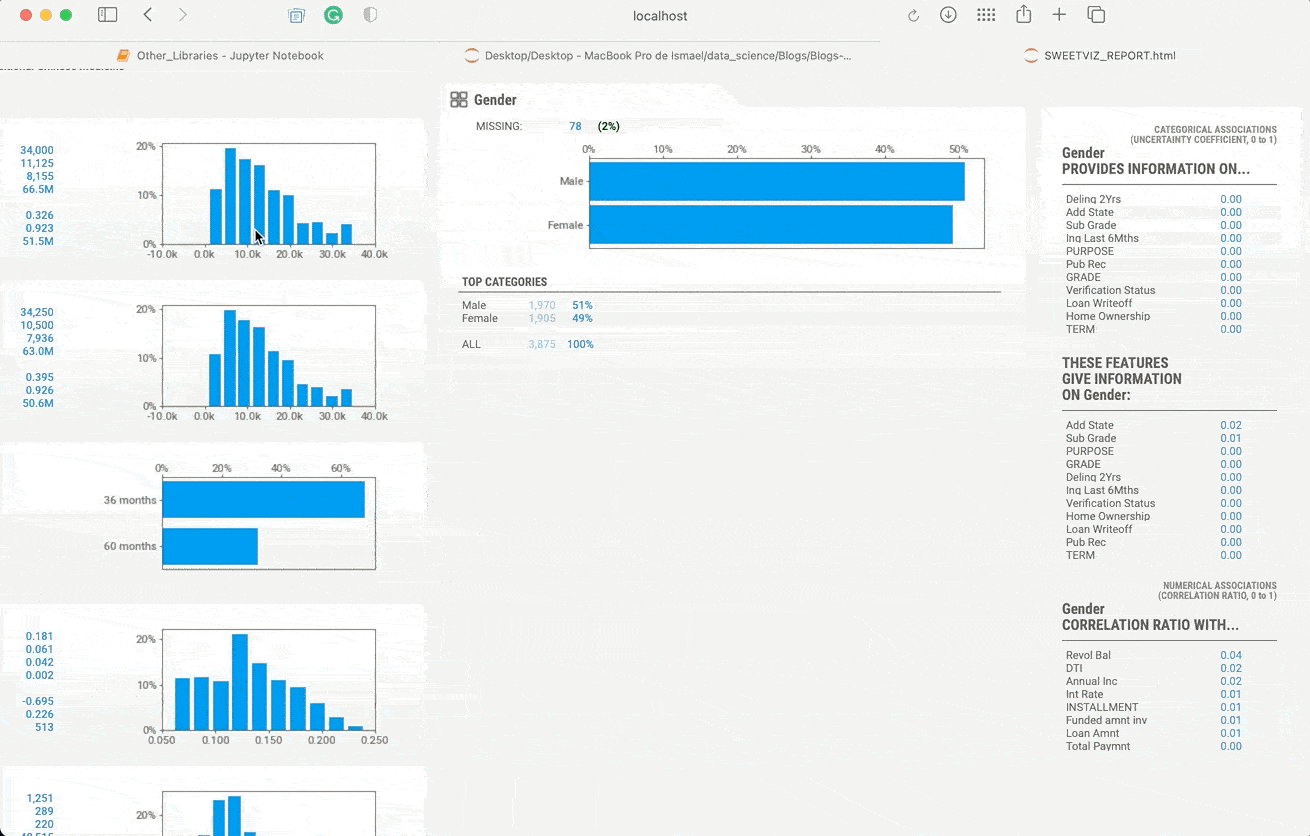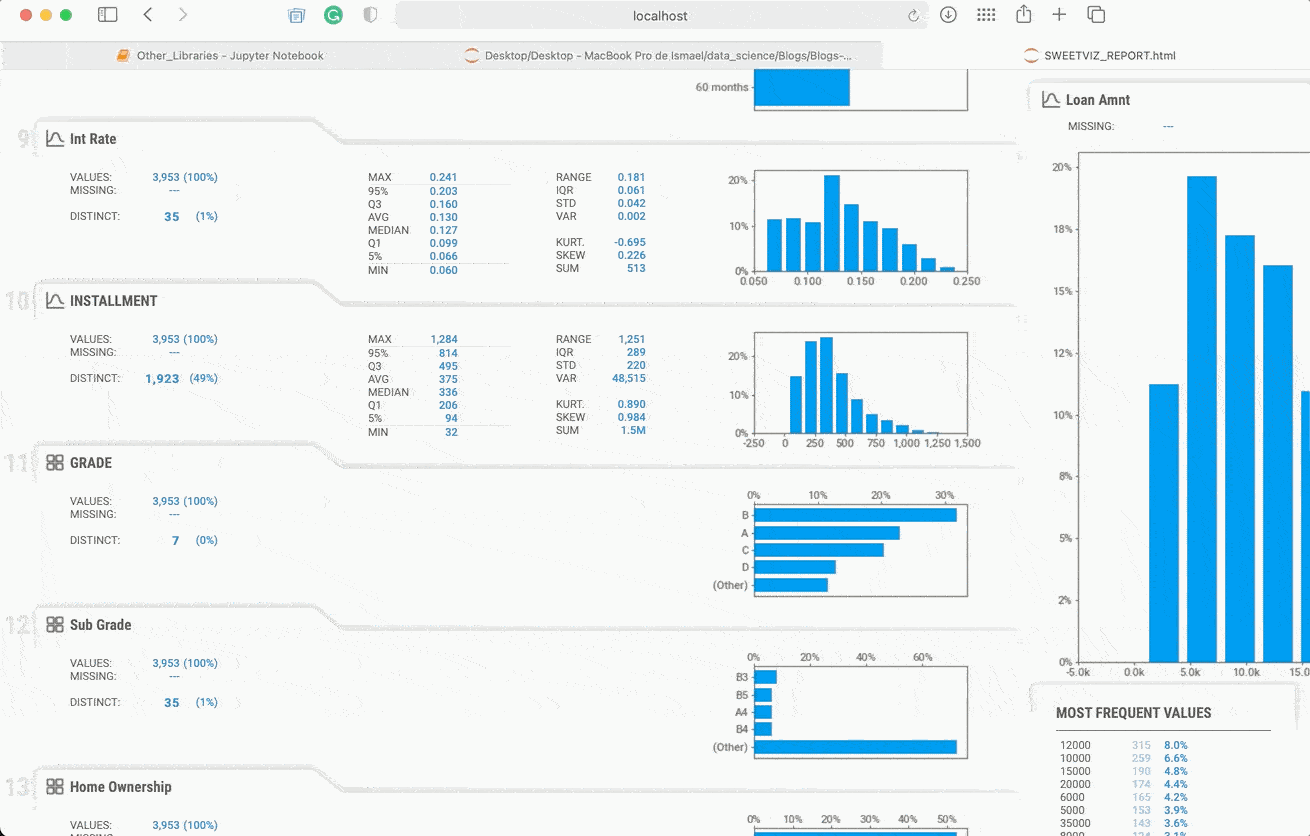
Вы видите это? Библиотека создаёт HTML-файл с исследовательским анализом данных на весь набор данных и разбивает его таким образом, что каждый признак вы можете проанализировать отдельно. Возможно также получить численные или категориальные ассоциации с другими признаками; малые, большие и часто встречающиеся значения. Также визуализация изменяется в зависимости от типа данных. При помощи SweetViz можно сделать так много, что я даже напишу о ней отдельный пост, а пока настоятельно рекомендую попробовать её.

Заключение
Все эти библиотеки заслуживают отдельной статьи и того, чтобы вы узнали о них, потому что они превращают сложные задачи в прямолинейно простые. Работая с этими библиотеками, вы сохраняете драгоценное время для действительно важных задач. Я рекомендую попробовать их, а также исследовать не упомянутую здесь функциональность. На Github вы найдёте блокнот Jupyter, который я написал, чтобы посмотреть на эти библиотеки в деле.
Этот материал не только даёт представление о полезных пакетах экосистемы Python, но и напоминает о широте и разнообразии проектов, в которых можно работать на этом языке. Python предельно лаконичен, он позволяет экономить время и в процессе написания кода, выражать идеи максимально быстро и эффективно, то есть беречь силы, чтобы придумывать новые подходы и решения задач, в том числе в области искусственного интеллекта, получить широкое и глубокое представление о котором вы можете на нашем курсе "Machine Learning и Deep Learning".

Узнайте, как прокачаться и в других специальностях или освоить их с нуля:
Профессия Data Scientist
Профессия Data Analyst
Курс по Data Engineering
Другие профессии и курсы
ПРОФЕССИИ
Профессия Fullstack-разработчик на Python
Профессия Java-разработчик
Профессия QA-инженер на JAVA
Профессия Frontend-разработчик
Профессия Этичный хакер
Профессия C++ разработчик
Профессия Разработчик игр на Unity
Профессия Веб-разработчик
Профессия iOS-разработчик с нуля
Профессия Android-разработчик с нуля
КУРСЫ
Курс по Machine Learning
Курс "Machine Learning и Deep Learning"
Курс "Математика для Data Science"
Курс "Математика и Machine Learning для Data Science"
Курс "Python для веб-разработки"
Курс "Алгоритмы и структуры данных"
Курс по аналитике данных
Курс по DevOps


