
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
В компании Klarna прилагают большие усилия к тому, чтобы помочь разработчикам в создании высококачественных и безопасных сервисов. Один из инструментов, который предназначен для разработчиков, представляет собой платформу для выполнения A/B-тестов. Важнейшим компонентом этой системы является множество процессов, которые, для каждого поступающего запроса, принимают решение о том, к какой разновидности тестов (A или B) направить запрос. Это, в свою очередь, определяет то, каким цветом вывести кнопку, какой макет показать пользователю, или даже то, какой пакет сторонней разработки использовать. Эти решения оказывают непосредственное воздействие на впечатления пользователей.

В Klarna используют платформу Node.js. Статья, перевод которой мы публикуем сегодня, посвящена тем урокам, которые специалистам компании удалось извлечь из опыта оптимизации производительности своего сервиса.
Производительность каждого процесса играет огромную роль, так как эти процессы используются синхронно в важнейших путях принятия решения экосистемы Klarna. Обычное требование к производительности подобных задач заключается в том, что для 99.9% запросов решение должно быть принято с задержкой, время которой выражается одной цифрой. Для того чтобы быть уверенными в том, что система не отклоняется от этих требований, в компании разработали конвейер для нагрузочного тестирования сервиса.
Хотя мы практически не видели проблем с производительностью в течение двух лет, которые платформа используется в продакшне, тесты недвусмысленно указывали на наличие некоторых неприятностей. В течение нескольких минут проведения теста, на умеренном стабильном уровне поступления запросов, длительность обработки запроса резко увеличивалась с нормальных значений до нескольких секунд.

Сведения о времени, необходимом на обработку запроса. Выявлена какая-то проблема
Мы решили, хотя подобное ещё не происходило в продакшне, что это — лишь вопрос времени. Если реальная нагрузка достигнет определённого уровня, мы можем столкнуться с чем-то подобным. Поэтому было решено, что этот вопрос стоит исследовать.
Ещё одна вещь, на которую стоит обратить внимание, заключается в том, что проблемы нашей системы появляются через 2-3 минуты работы под нагрузкой. В первое время мы запускали тест всего на 2 минуты. А проблему удалось увидеть только тогда, когда время выполнения теста было увеличено до 10 минут.
Обычно мы мониторим сервисы, используя следующие метрики: количество входящих запросов в секунду, длительность обработки входящих запросов, уровень ошибок. Это даёт нам довольно хорошие индикаторы состояния системы, указывая на то, имеются ли в ней какие-либо проблемы.
Но эти метрики не дают ценных сведений во время неправильной работы сервиса. Когда что-то идёт не так, нужно знать о том, где находится узкое место системы. Для таких случаев нужно мониторить ресурсы, используемые средой выполнения Node.js. Очевидно то, что в состав показателей, состояние которых отслеживается в проблемных ситуациях, входит использование процессора и памяти. Но иногда скорость работы системы зависит далеко не от них. В нашем случае, например, уровень использования процессора был невысоким. То же самое можно было сказать и об уровне потребления памяти.
Ещё один ресурс, от которого зависит производительность Node.js-проектов, это — цикл событий. Так же как нам важно знать о том, какой объём памяти используется процессом, нам нужно знать и о том, как много «задач» требуется обработать циклу событий. Цикл событий Node.js реализован в C++-библиотеке libuv (вот хорошее видео об этом). «Задачи» («task») называются здесь «активными запросами» («Active Request»). Ещё одна важная метрика — это количество «активных дескрипторов» («Active Handle»), которые представлены открытыми дескрипторами файлов или сокетами, используемыми процессами Node.js. Полный список видов дескрипторов можно посмотреть в документации к libuv. В результате, если тест использует 30 соединений, то вполне можно ожидать того, что в системе будет 30 активных дескрипторов. Показатель, характеризующий число активных запросов, указывает на число операций, ожидающих своей очереди для конкретного дескриптора. Что это за операции? Например — операции чтения/записи. Полный их список можно найти здесь.
Проанализировав метрики сервиса, мы поняли, что тут что-то не так. В то время как количество активных дескрипторов было таким, какого мы ожидали (в данном тесте — около 30), количество активных запросов было непропорционально велико — несколько десятков тысяч.

Активные дескрипторы и активные запросы
Мы, правда, ещё не знали о том, запросы каких типов были в очереди. После того, как мы разделили активные запросы по типам, ситуация немного прояснилась. А именно, весьма заметными оказались запросы
Почему система генерирует так много запросов на разрешение DNS-имён? Оказалось, что используемый нами клиент StatsD пытался разрешить имя хоста для каждого исходящего сообщения. Тут надо отметить, что этот клиент предлагает возможность кэширования результатов DNS-запросов, но здесь не учитывается TTL соответствующих DNS-записей. Результаты кэшируются на неопределённый период времени. В результате если запись обновляется после того, как клиент уже разрешил соответствующее имя, он об этом никогда не узнает. Так как балансировщик нагрузки StatsD может быть повторно развёрнут с другим IP-адресом, и мы не можем принудительно перезапустить сервис для того, чтобы обновить DNS-кэш, этот подход, при котором используется кэширование на неограниченное время, нам не подходил.
Решение, к которому мы пришли, заключалось в использовании внешнего по отношению к клиенту средства для кэширования DNS-запросов. Это несложно сделать, выполнив «обезьяний патч» модуля DNS. Результат теперь выглядел гораздо лучше, чем раньше.
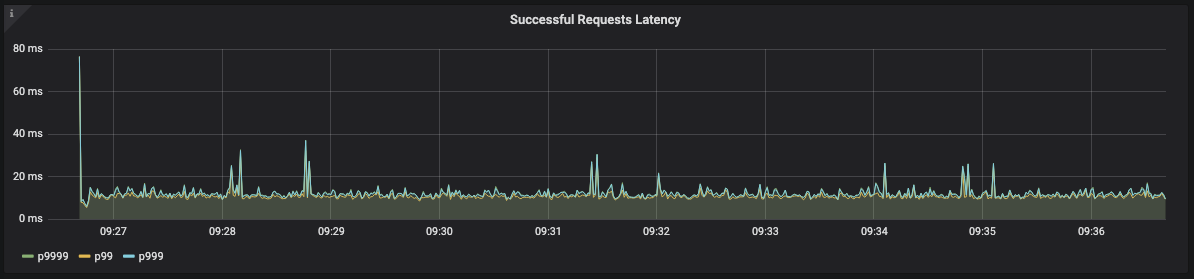
Сведения о времени, необходимом на обработку запроса. Результат использования внешнего DNS-кэша
После решения вышеописанной проблемы мы включили некоторые возможности сервиса, отключённые ранее, и снова его протестировали. В частности, мы включили код, который отправляет сообщение в тему Kafka для каждого входящего запроса. Тест, в очередной раз, выявил значительные пики в результатах измерений времени ответа (речь идёт о секундах), наблюдаемые на больших временных отрезках.

Сведения о времени, необходимом на обработку запроса. Тест выявил резкий рост времени, необходимого на формирование ответов
Эти результаты указывают на очевидную проблему именно в той функции, которую мы включили перед тестированием. В частности, мы столкнулись с тем, что отправка сообщений в Kafka требует слишком много времени.
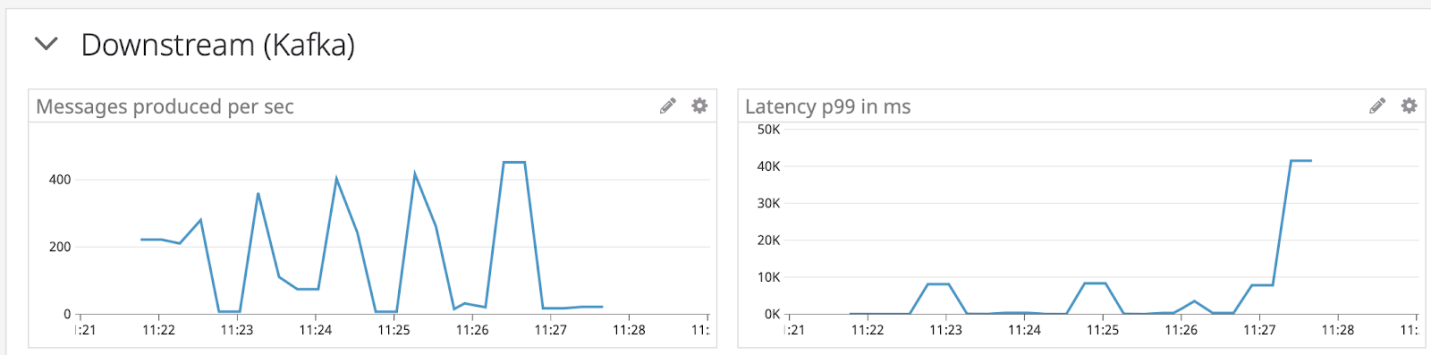
Сведения о времени, необходимом на формирование сообщений для Kafka
Мы решили воспользоваться здесь простейшим улучшением — поставить исходящие сообщения в очередь, находящуюся в памяти, и ежесекундно передавать эти сообщения в пакетном режиме. Запустив тест снова, мы обнаружили явные улучшения во времени, необходимом сервису на формирование ответа.

Сведения о времени, необходимом на обработку запроса. Улучшения после организации пакетной обработки сообщений
Вышеописанная работа по оптимизации производительности сервиса была бы невозможна без механизма запуска тестов, позволяющего получать воспроизводимые и единообразные результаты. Первая версия нашей системы тестирования не давала единообразных результатов, поэтому положиться на неё в деле принятия важных решений мы не могли. Вложив силы в создание надёжной системы тестирования, мы смогли испытывать проект в разных режимах, экспериментировать с исправлениями. Новая система тестирования, по большей части, давала нам уверенность в том, что получаемые результаты испытаний — это что-то реальное, а не некие цифры, неизвестно откуда взявшиеся.
Скажем пару слов о конкретных инструментах, использованных для организации тестирования.
Нагрузка генерировалась внутренним инструментом, упрощающим запуск Locust в распределённом режиме. В целом, всё сводилось к выполнению единственной команды, после чего осуществлялся запуск генераторов нагрузки, производилась передача им скрипта теста и выполнялся сбор результатов, визуализируемых средствами панели управления Grafana. Соответствующие результаты представлены в материале на графиках с тёмным фоном. Это — то, как система выглядит в тесте с точки зрения клиента.
Тестируемый сервис выдаёт сведения об измерениях в Datalog. Эти сведения представлены здесь графиками со светлым фоном.
Уважаемые читатели! Какие системы тестирования Node.js-сервисов вы используете?

В Klarna используют платформу Node.js. Статья, перевод которой мы публикуем сегодня, посвящена тем урокам, которые специалистам компании удалось извлечь из опыта оптимизации производительности своего сервиса.
Урок №1: тестирование производительности может дать уверенность в том, что скорость работы системы не деградирует с каждым релизом
Производительность каждого процесса играет огромную роль, так как эти процессы используются синхронно в важнейших путях принятия решения экосистемы Klarna. Обычное требование к производительности подобных задач заключается в том, что для 99.9% запросов решение должно быть принято с задержкой, время которой выражается одной цифрой. Для того чтобы быть уверенными в том, что система не отклоняется от этих требований, в компании разработали конвейер для нагрузочного тестирования сервиса.
Урок №2: самостоятельно «накручивая» нагрузку можно выявлять проблемы ещё до того, как они достигнут продакшна
Хотя мы практически не видели проблем с производительностью в течение двух лет, которые платформа используется в продакшне, тесты недвусмысленно указывали на наличие некоторых неприятностей. В течение нескольких минут проведения теста, на умеренном стабильном уровне поступления запросов, длительность обработки запроса резко увеличивалась с нормальных значений до нескольких секунд.
Сведения о времени, необходимом на обработку запроса. Выявлена какая-то проблема
Мы решили, хотя подобное ещё не происходило в продакшне, что это — лишь вопрос времени. Если реальная нагрузка достигнет определённого уровня, мы можем столкнуться с чем-то подобным. Поэтому было решено, что этот вопрос стоит исследовать.
Урок №3: длительное нагрузочное тестирование способно выявлять самые разные проблемы. Если всё выглядит хорошо — попробуйте увеличить длительность теста
Ещё одна вещь, на которую стоит обратить внимание, заключается в том, что проблемы нашей системы появляются через 2-3 минуты работы под нагрузкой. В первое время мы запускали тест всего на 2 минуты. А проблему удалось увидеть только тогда, когда время выполнения теста было увеличено до 10 минут.
Урок №4: не забывайте учитывать время, необходимое на DNS-разрешение имён, рассматривая исходящие запросы. Не игнорируйте время жизни записей кэша — это способно серьёзно нарушить работу приложения
Обычно мы мониторим сервисы, используя следующие метрики: количество входящих запросов в секунду, длительность обработки входящих запросов, уровень ошибок. Это даёт нам довольно хорошие индикаторы состояния системы, указывая на то, имеются ли в ней какие-либо проблемы.
Но эти метрики не дают ценных сведений во время неправильной работы сервиса. Когда что-то идёт не так, нужно знать о том, где находится узкое место системы. Для таких случаев нужно мониторить ресурсы, используемые средой выполнения Node.js. Очевидно то, что в состав показателей, состояние которых отслеживается в проблемных ситуациях, входит использование процессора и памяти. Но иногда скорость работы системы зависит далеко не от них. В нашем случае, например, уровень использования процессора был невысоким. То же самое можно было сказать и об уровне потребления памяти.
Ещё один ресурс, от которого зависит производительность Node.js-проектов, это — цикл событий. Так же как нам важно знать о том, какой объём памяти используется процессом, нам нужно знать и о том, как много «задач» требуется обработать циклу событий. Цикл событий Node.js реализован в C++-библиотеке libuv (вот хорошее видео об этом). «Задачи» («task») называются здесь «активными запросами» («Active Request»). Ещё одна важная метрика — это количество «активных дескрипторов» («Active Handle»), которые представлены открытыми дескрипторами файлов или сокетами, используемыми процессами Node.js. Полный список видов дескрипторов можно посмотреть в документации к libuv. В результате, если тест использует 30 соединений, то вполне можно ожидать того, что в системе будет 30 активных дескрипторов. Показатель, характеризующий число активных запросов, указывает на число операций, ожидающих своей очереди для конкретного дескриптора. Что это за операции? Например — операции чтения/записи. Полный их список можно найти здесь.
Проанализировав метрики сервиса, мы поняли, что тут что-то не так. В то время как количество активных дескрипторов было таким, какого мы ожидали (в данном тесте — около 30), количество активных запросов было непропорционально велико — несколько десятков тысяч.
Активные дескрипторы и активные запросы
Мы, правда, ещё не знали о том, запросы каких типов были в очереди. После того, как мы разделили активные запросы по типам, ситуация немного прояснилась. А именно, весьма заметными оказались запросы
UV_GETADDRINFO. Они генерируются тогда, когда Node.js пытается разрешить DNS-имя.Почему система генерирует так много запросов на разрешение DNS-имён? Оказалось, что используемый нами клиент StatsD пытался разрешить имя хоста для каждого исходящего сообщения. Тут надо отметить, что этот клиент предлагает возможность кэширования результатов DNS-запросов, но здесь не учитывается TTL соответствующих DNS-записей. Результаты кэшируются на неопределённый период времени. В результате если запись обновляется после того, как клиент уже разрешил соответствующее имя, он об этом никогда не узнает. Так как балансировщик нагрузки StatsD может быть повторно развёрнут с другим IP-адресом, и мы не можем принудительно перезапустить сервис для того, чтобы обновить DNS-кэш, этот подход, при котором используется кэширование на неограниченное время, нам не подходил.
Решение, к которому мы пришли, заключалось в использовании внешнего по отношению к клиенту средства для кэширования DNS-запросов. Это несложно сделать, выполнив «обезьяний патч» модуля DNS. Результат теперь выглядел гораздо лучше, чем раньше.
Сведения о времени, необходимом на обработку запроса. Результат использования внешнего DNS-кэша
Урок №5: выполняйте операции ввода/вывода в пакетном режиме. Подобные операции, даже асинхронные, являются серьёзными потребителями ресурсов
После решения вышеописанной проблемы мы включили некоторые возможности сервиса, отключённые ранее, и снова его протестировали. В частности, мы включили код, который отправляет сообщение в тему Kafka для каждого входящего запроса. Тест, в очередной раз, выявил значительные пики в результатах измерений времени ответа (речь идёт о секундах), наблюдаемые на больших временных отрезках.
Сведения о времени, необходимом на обработку запроса. Тест выявил резкий рост времени, необходимого на формирование ответов
Эти результаты указывают на очевидную проблему именно в той функции, которую мы включили перед тестированием. В частности, мы столкнулись с тем, что отправка сообщений в Kafka требует слишком много времени.
Сведения о времени, необходимом на формирование сообщений для Kafka
Мы решили воспользоваться здесь простейшим улучшением — поставить исходящие сообщения в очередь, находящуюся в памяти, и ежесекундно передавать эти сообщения в пакетном режиме. Запустив тест снова, мы обнаружили явные улучшения во времени, необходимом сервису на формирование ответа.
Сведения о времени, необходимом на обработку запроса. Улучшения после организации пакетной обработки сообщений
Урок №6: прежде чем пытаться внести в систему какие-либо улучшения, подготовьте тесты, результатам которых можно доверять
Вышеописанная работа по оптимизации производительности сервиса была бы невозможна без механизма запуска тестов, позволяющего получать воспроизводимые и единообразные результаты. Первая версия нашей системы тестирования не давала единообразных результатов, поэтому положиться на неё в деле принятия важных решений мы не могли. Вложив силы в создание надёжной системы тестирования, мы смогли испытывать проект в разных режимах, экспериментировать с исправлениями. Новая система тестирования, по большей части, давала нам уверенность в том, что получаемые результаты испытаний — это что-то реальное, а не некие цифры, неизвестно откуда взявшиеся.
Скажем пару слов о конкретных инструментах, использованных для организации тестирования.
Нагрузка генерировалась внутренним инструментом, упрощающим запуск Locust в распределённом режиме. В целом, всё сводилось к выполнению единственной команды, после чего осуществлялся запуск генераторов нагрузки, производилась передача им скрипта теста и выполнялся сбор результатов, визуализируемых средствами панели управления Grafana. Соответствующие результаты представлены в материале на графиках с тёмным фоном. Это — то, как система выглядит в тесте с точки зрения клиента.
Тестируемый сервис выдаёт сведения об измерениях в Datalog. Эти сведения представлены здесь графиками со светлым фоном.
Уважаемые читатели! Какие системы тестирования Node.js-сервисов вы используете?


 приложений")