
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!

За годы эксплуатации Kubernetes в production у нас накопилось немало занимательных историй, как баги в различных системных компонентах приводили к неприятным и/или непонятным последствиям, влияющим на работу контейнеров и pod'ов. В этой статье мы сделали подборку некоторых наиболее частых или интересных из них. Даже если вам никогда не повезёт столкнуться с такими ситуациями, читать о подобных кратких детективах — тем более, «из первых рук» — всегда занятно, разве не так?..
История 1. Supercronic и зависающий Docker
На одном из кластеров мы периодически получали «зависший» Docker, что мешало нормальному функционированию кластера. При этом в логах Docker наблюдалось следующее
level=error msg="containerd: start init process" error="exit status 2: \"runtime/cgo: pthread_create failed: No space left on device
SIGABRT: abort
PC=0x7f31b811a428 m=0
goroutine 0 [idle]:
goroutine 1 [running]:
runtime.systemstack_switch() /usr/local/go/src/runtime/asm_amd64.s:252 fp=0xc420026768 sp=0xc420026760
runtime.main() /usr/local/go/src/runtime/proc.go:127 +0x6c fp=0xc4200267c0 sp=0xc420026768
runtime.goexit() /usr/local/go/src/runtime/asm_amd64.s:2086 +0x1 fp=0xc4200267c8 sp=0xc4200267c0
goroutine 17 [syscall, locked to thread]:
runtime.goexit() /usr/local/go/src/runtime/asm_amd64.s:2086 +0x1
…В этой ошибке больше всего нас интересует сообщение:
pthread_create failed: No space left on device. Беглое изучение документации пояснило, что Docker не может форкнуть процесс, из-за чего периодически и «зависал».В мониторинге происходящему соответствует такая картина:

Схожая ситуация наблюдается и на других узлах:


На этих же узлах видим:
root@kube-node-1 ~ # ps auxfww | grep curl -c
19782
root@kube-node-1 ~ # ps auxfww | grep curl | head
root 16688 0.0 0.0 0 0 ? Z Feb06 0:00 | \_ [curl] <defunct>
root 17398 0.0 0.0 0 0 ? Z Feb06 0:00 | \_ [curl] <defunct>
root 16852 0.0 0.0 0 0 ? Z Feb06 0:00 | \_ [curl] <defunct>
root 9473 0.0 0.0 0 0 ? Z Feb06 0:00 | \_ [curl] <defunct>
root 4664 0.0 0.0 0 0 ? Z Feb06 0:00 | \_ [curl] <defunct>
root 30571 0.0 0.0 0 0 ? Z Feb06 0:00 | \_ [curl] <defunct>
root 24113 0.0 0.0 0 0 ? Z Feb06 0:00 | \_ [curl] <defunct>
root 16475 0.0 0.0 0 0 ? Z Feb06 0:00 | \_ [curl] <defunct>
root 7176 0.0 0.0 0 0 ? Z Feb06 0:00 | \_ [curl] <defunct>
root 1090 0.0 0.0 0 0 ? Z Feb06 0:00 | \_ [curl] <defunct>Оказалось, такое поведение — следствие работы pod’а с supercronic (утилита на Go, которую мы используем для запуска cron-задач в pod’ах):
\_ docker-containerd-shim 833b60bb9ff4c669bb413b898a5fd142a57a21695e5dc42684235df907825567 /var/run/docker/libcontainerd/833b60bb9ff4c669bb413b898a5fd142a57a21695e5dc42684235df907825567 docker-runc
| \_ /usr/local/bin/supercronic -json /crontabs/cron
| \_ /usr/bin/newrelic-daemon --agent --pidfile /var/run/newrelic-daemon.pid --logfile /dev/stderr --port /run/newrelic.sock --tls --define utilization.detect_aws=true --define utilization.detect_azure=true --define utilization.detect_gcp=true --define utilization.detect_pcf=true --define utilization.detect_docker=true
| | \_ /usr/bin/newrelic-daemon --agent --pidfile /var/run/newrelic-daemon.pid --logfile /dev/stderr --port /run/newrelic.sock --tls --define utilization.detect_aws=true --define utilization.detect_azure=true --define utilization.detect_gcp=true --define utilization.detect_pcf=true --define utilization.detect_docker=true -no-pidfile
| \_ [newrelic-daemon] <defunct>
| \_ [curl] <defunct>
| \_ [curl] <defunct>
| \_ [curl] <defunct>
…Проблема в следующем: когда задача запускается в supercronic, процесс, порожденный им, не может корректно завершиться, превращаясь в зомби.
Примечание: Если говорить точнее, то процессы порождаются cron-задачами, однако supercronic не является init-системой и не может «удочерить» процессы, которые породили его дети. При возникновении сигналов SIGHUP или SIGTERM они не передаются порождённым процессам, в результате чего дочерние процессы не завершаются, оставаясь в статусе зомби. Подробнее обо всём этом можно прочитать, например, в такой статье.
Есть пара способов решения проблем:
- Как временный workaround — увеличить количество PID’ов в системе в единый момент времени:
/proc/sys/kernel/pid_max (since Linux 2.5.34) This file specifies the value at which PIDs wrap around (i.e., the value in this file is one greater than the maximum PID). PIDs greater than this value are not allo‐ cated; thus, the value in this file also acts as a system-wide limit on the total number of processes and threads. The default value for this file, 32768, results in the same range of PIDs as on earlier kernels - Или же сделать запуск задач в supercronic не напрямую, а с помощью того же tini, который способен корректно завершать процессы и не порождать zombie.
История 2. «Зомби» при удалении cgroup
Kubelet начал потреблять большое количество CPU:
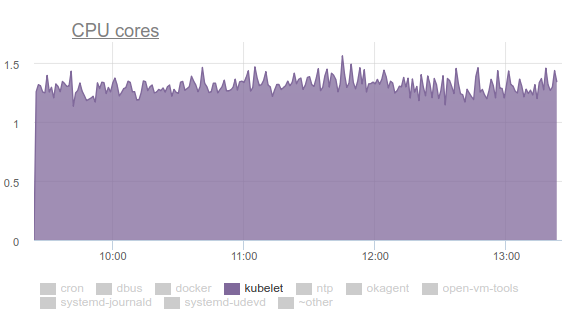
Такое никому не понравится, поэтому мы вооружились perf и стали разбираться с проблемой. Итоги расследования оказались следующими:
- Kubelet тратит больше трети процессорного времени на вытаскивание данных о памяти из всех cgroup:

- В рассылке разработчиков ядра можно найти обсуждение проблемы. Если вкратце, то суть сводится к тому, что разные tmpfs-файлы и другие похожие вещи не полностью удаляются из системы при удалении cgroup — остаются так называемые memcg zombie. Рано или поздно они всё же удалятся из page cache, однако памяти на сервере много и смысла тратить время на их удаление ядро не видит. Поэтому они продолжают копиться. Почему это вообще происходит? Это сервер с cron-заданиями, который постоянно создаёт новые job’ы, а с ними — новые pod’ы. Таким образом, для контейнеров в них создаются новые cgroup, которые вскоре удаляются.
- Почему cAdvisor в kubelet тратит столько времени? Это легко увидеть простейшим выполнением
time cat /sys/fs/cgroup/memory/memory.stat. Если на здоровой машине операция занимает 0,01 секунды, то на проблемной cron02 — 1,2 секунды. Всё дело в том, что cAdvisor, очень медленно читающий данные из sysfs, пытается учесть использованную память и в zombie cgroups. - Чтобы насильно удалить зомби, мы попробовали зачистить кэши, как рекомендовали в LKML:
sync; echo 3 > /proc/sys/vm/drop_caches, — но ядро оказалось сложнее и повесило машину.
Что же делать? Проблема исправляется (коммит, а описание см. в сообщении о релизе) обновлением ядра Linux до версии 4.16.
История 3. Systemd и его mount
Снова kubelet потребляет слишком много ресурсов на некоторых узлах, но на сей раз — уже памяти:

Оказалось, что есть проблема в systemd, используемом в Ubuntu 16.04, и возникает она при управлении mount’ами, которые создаются для подключения
subPath из ConfigMap’ов или secret’ов. После завершения работы pod’а сервис systemd и его служебный mount остаются в системе. Со временем их накапливается огромное количество. На эту тему даже есть issues:- kops #5916;
- kubernetes #57345.
… в последнем из которых ссылаются на PR в systemd: #7811 (issue в systemd — #7798).
Проблемы уже нет в Ubuntu 18.04, но если вы хотите и дальше использовать Ubuntu 16.04, вам может пригодиться наш workaround на эту тему.
Итак, мы сделали следующий DaemonSet:
---
apiVersion: extensions/v1beta1
kind: DaemonSet
metadata:
labels:
app: systemd-slices-cleaner
name: systemd-slices-cleaner
namespace: kube-system
spec:
updateStrategy:
type: RollingUpdate
selector:
matchLabels:
app: systemd-slices-cleaner
template:
metadata:
labels:
app: systemd-slices-cleaner
spec:
containers:
- command:
- /usr/local/bin/supercronic
- -json
- /app/crontab
Image: private-registry.org/systemd-slices-cleaner/systemd-slices-cleaner:v0.1.0
imagePullPolicy: Always
name: systemd-slices-cleaner
resources: {}
securityContext:
privileged: true
volumeMounts:
- name: systemd
mountPath: /run/systemd/private
- name: docker
mountPath: /run/docker.sock
- name: systemd-etc
mountPath: /etc/systemd
- name: systemd-run
mountPath: /run/systemd/system/
- name: lsb-release
mountPath: /etc/lsb-release-host
imagePullSecrets:
- name: antiopa-registry
priorityClassName: cluster-low
tolerations:
- operator: Exists
volumes:
- name: systemd
hostPath:
path: /run/systemd/private
- name: docker
hostPath:
path: /run/docker.sock
- name: systemd-etc
hostPath:
path: /etc/systemd
- name: systemd-run
hostPath:
path: /run/systemd/system/
- name: lsb-release
hostPath:
path: /etc/lsb-release… а в нём используется такой скрипт:
#!/bin/bash
# we will work only on xenial
hostrelease="/etc/lsb-release-host"
test -f ${hostrelease} && grep xenial ${hostrelease} > /dev/null || exit 0
# sleeping max 30 minutes to dispense load on kube-nodes
sleep $((RANDOM % 1800))
stoppedCount=0
# counting actual subpath units in systemd
countBefore=$(systemctl list-units | grep subpath | grep "run-" | wc -l)
# let's go check each unit
for unit in $(systemctl list-units | grep subpath | grep "run-" | awk '{print $1}'); do
# finding description file for unit (to find out docker container, who born this unit)
DropFile=$(systemctl status ${unit} | grep Drop | awk -F': ' '{print $2}')
# reading uuid for docker container from description file
DockerContainerId=$(cat ${DropFile}/50-Description.conf | awk '{print $5}' | cut -d/ -f6)
# checking container status (running or not)
checkFlag=$(docker ps | grep -c ${DockerContainerId})
# if container not running, we will stop unit
if [[ ${checkFlag} -eq 0 ]]; then
echo "Stopping unit ${unit}"
# stoping unit in action
systemctl stop $unit
# just counter for logs
((stoppedCount++))
# logging current progress
echo "Stopped ${stoppedCount} systemd units out of ${countBefore}"
fi
done… и он запускается каждые 5 минут с помощью уже упомянутого раньше supercronic. Его Dockerfile выглядит так:
FROM ubuntu:16.04
COPY rootfs /
WORKDIR /app
RUN apt-get update && \
apt-get upgrade -y && \
apt-get install -y gnupg curl apt-transport-https software-properties-common wget
RUN add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu xenial stable" && \
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | apt-key add - && \
apt-get update && \
apt-get install -y docker-ce=17.03.0*
RUN wget https://github.com/aptible/supercronic/releases/download/v0.1.6/supercronic-linux-amd64 -O \
/usr/local/bin/supercronic && chmod +x /usr/local/bin/supercronic
ENTRYPOINT ["/bin/bash", "-c", "/usr/local/bin/supercronic -json /app/crontab"]История 4. Конкурентность при планировании pod’ов
Было замечено, что: если у нас на узел размещается pod и его образ выкачивается очень долго, то другой pod, который «попал» на этот же узел, просто не начинает pull’ить образ нового pod'а. Вместо этого он ждет, пока с’pull’ится образ предыдущего pod’а. В результате, pod, который уже был запланирован и образ которого мог бы скачаться всего за минуту, окажется на продолжительное время в статусе
containerCreating.В event’ах будет примерно следующее:
Normal Pulling 8m kubelet, ip-10-241-44-128.ap-northeast-1.compute.internal pulling image "registry.example.com/infra/openvpn/openvpn:master"Получается, что один-единственный образ из медленного реестра может заблокировать деплой на узел.
К сожалению, выходов из ситуации не так много:
- Старайтесь использовать свой Docker Registry прямо в кластере или непосредственно с кластером (к примеру, GitLab Registry, Nexus и т.п.);
- Воспользуйтесь такими утилитами, как kraken.
История 5. Зависание узлов при нехватке памяти
За время эксплуатации различных приложений мы также получали ситуацию, когда узел полностью перестает быть доступен: не отвечает SSH, все демоны мониторинга отваливаются, а в логах потом ничего (или почти ничего) аномального нет.
Расскажу в картинках на примере одного узла, где функционировала MongoDB.
Вот так atop выглядит до аварии:

А вот так — после аварии:

В мониторинге тоже наблюдается резкий скачок, при котором узел перестает быть доступен:
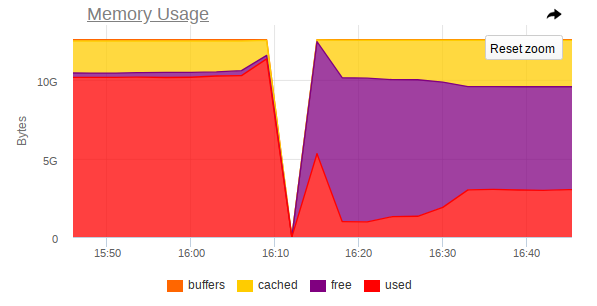
Таким образом, из скриншотов видно, что:
- Оперативная память на машине близка к концу;
- Наблюдается резкий скачок потребления оперативной памяти, после чего резко отключается доступ ко всей машине;
- На Mongo прилетает большая задача, которая заставляет процесс СУБД использовать больше памяти и активно читать с диска.
Оказывается, если в Linux заканчивается свободная память (наступает memory pressure) и swap’а нет, то до прихода OOM killer’а может наступить эквилибриум между закидыванием страниц в page cache и writeback’ом их обратно на диск. Занимается этим kswapd, который отважно освобождает как можно больше страниц памяти для последующего распределения.
К сожалению, при большой нагрузке на ввод/вывод вкупе с малым количеством свободной памяти, kswapd становится бутылочным горлышком всей системы, потому что на него завязываются все выделения (page faults) страниц памяти в системе. Это может продолжаться очень долго, если процессы не захотят больше использовать память, а зафиксируются на самом краю OOM-killer-бездны.
Закономерен вопрос: а почему OOM killer приходит так поздно? В текущей своей итерации OOM killer крайне глуп: он прибьёт процесс только тогда, когда провалится попытка выделить страницу памяти, т.е. если page fault пройдёт с ошибкой. Этого достаточно долго не происходит, потому что kswapd отважно освобождает страницы памяти, сбрасывая page cache (весь дисковый I/O в системе, по сути) обратно на диск. Более подробно, с описанием шагов, необходимых для устранения подобных проблем в ядре, можно почитать здесь.
Данное поведение должно улучшиться с ядром Linux 4.6+.
История 6. Pod’ы зависают в состоянии Pending
В некоторых кластерах, в которых функционирует по-настоящему много pod’ов, мы начали замечать, что большая их часть очень долго «висит» в состоянии
Pending, хотя при этом сами Docker-контейнеры уже запущены на узлах и с ними можно вручную работать.При этом в
describe ничего нет плохого: Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 1m default-scheduler Successfully assigned sphinx-0 to ss-dev-kub07
Normal SuccessfulAttachVolume 1m attachdetach-controller AttachVolume.Attach succeeded for volume "pvc-6aaad34f-ad10-11e8-a44c-52540035a73b"
Normal SuccessfulMountVolume 1m kubelet, ss-dev-kub07 MountVolume.SetUp succeeded for volume "sphinx-config"
Normal SuccessfulMountVolume 1m kubelet, ss-dev-kub07 MountVolume.SetUp succeeded for volume "default-token-fzcsf"
Normal SuccessfulMountVolume 49s (x2 over 51s) kubelet, ss-dev-kub07 MountVolume.SetUp succeeded for volume "pvc-6aaad34f-ad10-11e8-a44c-52540035a73b"
Normal Pulled 43s kubelet, ss-dev-kub07 Container image "registry.example.com/infra/sphinx-exporter/sphinx-indexer:v1" already present on machine
Normal Created 43s kubelet, ss-dev-kub07 Created container
Normal Started 43s kubelet, ss-dev-kub07 Started container
Normal Pulled 43s kubelet, ss-dev-kub07 Container image "registry.example.com/infra/sphinx/sphinx:v1" already present on machine
Normal Created 42s kubelet, ss-dev-kub07 Created container
Normal Started 42s kubelet, ss-dev-kub07 Started containerПокопавшись, мы сделали предположение, что kubelet просто не успевает отправить API-серверу всю информацию о состоянии pod’ов, liveness/readiness-пробах.
А изучив help, нашли следующие параметры:
--kube-api-qps - QPS to use while talking with kubernetes apiserver (default 5)
--kube-api-burst - Burst to use while talking with kubernetes apiserver (default 10)
--event-qps - If > 0, limit event creations per second to this value. If 0, unlimited. (default 5)
--event-burst - Maximum size of a bursty event records, temporarily allows event records to burst to this number, while still not exceeding event-qps. Only used if --event-qps > 0 (default 10)
--registry-qps - If > 0, limit registry pull QPS to this value.
--registry-burst - Maximum size of bursty pulls, temporarily allows pulls to burst to this number, while still not exceeding registry-qps. Only used if --registry-qps > 0 (default 10)Как видно, значения по умолчанию — довольно маленькие, и в 90 % они покрывают все потребности… Однако в нашем случае этого оказалось недостаточно. Поэтому мы выставили такие значения:
--event-qps=30 --event-burst=40 --kube-api-burst=40 --kube-api-qps=30 --registry-qps=30 --registry-burst=40… и перезапустили kubelet’ы, после чего на графиках обращения к API-серверу увидели следующую картину:

… и да, всё начало летать!
P.S.
За помощь в сборе багов и подготовке статьи выражаю большую благодарность многочисленным инженерам нашей компании, а в особенности — коллеге из нашей R&D-команды Андрею Климентьеву (zuzzas).
P.P.S.
Читайте также в нашем блоге:
- «Плагин kubectl-debug для отладки в pod'ах Kubernetes»;
- «Мониторинг и Kubernetes (обзор и видео доклада)»;
- Цикл Kubernetes tips & tricks:
- «Перевод работающих в кластере ресурсов под управление Helm 2»;
- «О выделении узлов и о нагрузках на веб-приложение»;
- «Доступ к dev-площадкам»;
- «Ускоряем bootstrap больших баз данных».



