
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!

Перед вами обновлённая коллекция вредных советов для C++ программистов, которая превратилась в целую электронную книгу. Всего их 60, и каждый сопровождается пояснением, почему на самом деле ему не стоит следовать. Всё будет одновременно и в шутку, и серьёзно. Как бы глупо ни смотрелся вредный совет, он не выдуман, а подсмотрен в реальном мире программирования.
Я буду публиковать советы по 5 штук, чтобы не утомить вас, так как мини-книга содержит много интересных отсылок на другие статьи, видео и т. д. Однако, если вам не терпится, здесь вы можете сразу перейти к её полному варианту: "60 антипаттернов для С++ программиста". В любом случае желаю приятного чтения.
Вредный совет N21. Профессионалы не ошибаются
Никогда не тестируйте. И не пишите тестов. Ваш код идеален, что там тестировать! Ведь не зря вы настоящие C++ программисты.
Думаю, читателю понятна ирония, и никто всерьёз не задаётся вопросом, почему этот совет вреден. Но тут есть интересный момент. Соглашаясь с тем, что программисты допускают ошибки, вы, скорее всего, думаете, что это относится к вам в меньшей степени. Ведь вы эксперт, и в среднем лучше других понимаете, как надо программировать и тестировать.

Мы все подвержены когнитивному искажению "иллюзорного превосходства". Причём, по моему жизненному опыту, программисты подвержены ему в большей степени :). Интересная статья на эту тему: Программисты "выше среднего".
Вредный совет N22. Анализаторы нужны только студентам
И статические анализаторы не используйте. Это инструменты для студентов и неудачников.
Как раз наоборот. В первую очередь статические анализаторы используют профессиональные программисты с целью повысить качество своих программных проектов. Они ценят статический анализ за то, что он позволяет найти ошибки и уязвимости нулевого дня на ранних этапах. Ведь чем раньше дефект в коде обнаружен, тем дешевле его устранение.
Что интересно, у студента есть шанс написать качественную программу в рамках курсового проекта. И он вполне может обойтись без статического анализа. А вот написать без ошибок проект уровня игрового движка невозможно. Дело в том, что с ростом кодовой базы растёт плотность ошибок. И для поддержания высокого качества кода приходится затрачивать большие усилия и использовать различные методологии, в том числе и инструменты анализа кода.
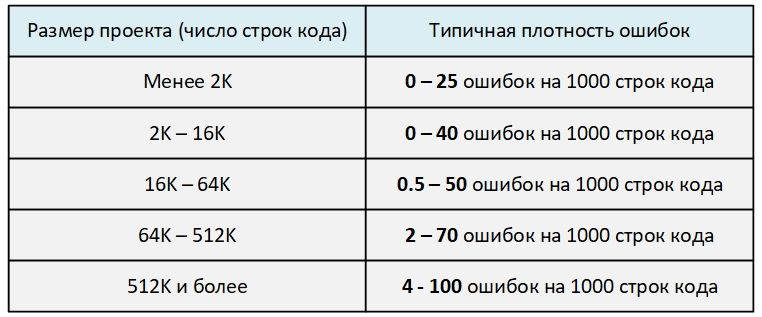
Давайте разберём, что значит рост плотности ошибок. Чем больше размер кодовой базы, тем легче допустить ошибку. Количество ошибок растёт с ростом размера проекта не линейно, а экспоненциально.
Человеку уже невозможно удержать в голове весь проект. Каждый программист работает только с частью проекта и кодовой базы. В результате программист не может предвидеть абсолютно все последствия, которые могут возникнуть в процессе изменения им какого-то кода. По-простому: в одном месте что-то изменили, в другом месте что-то сломалось.
Да и в целом, чем сложнее становится система, тем легче допустить ошибку. Это подтверждается числами. Взгляните на таблицу, взятую мной из книги Стивена Макконнелла "Совершенный код".
Статический анализ кода – хороший помощник программистов и менеджеров, заботящихся о качестве проекта и скорости его разработки. Регулярное использование инструментов анализа снижает плотность ошибок, а это в целом положительно сказывается на продуктивности работы. Вот что пишет Дэвид Андерсон в книге "Канбан. Альтернативный путь в Agile":
Кейперс Джонс сообщает, что в 2000 году во время пузыря доткомов он оценивал качество программ для североамериканских команд, и оно колебалось от шести ошибок на одну функциональную точку до менее чем трех ошибок на 100 функциональных точек — 200 к одному. Серединой будет примерно одна ошибка на 0,6-1,0 функциональной точки. Таким образом, для команд вполне типично тратить более 90 % своих усилий на устранение ошибок. Есть и прямое тому свидетельство: в конце 2007 года Аарон Сандерс, один из первых последователей Канбана, написал на листе рассылки Kanbandev, что команда, с которой он работал, тратила 90% доступной производительности на исправление ошибок.
Стремление к изначально высокому качеству окажет серьёзное влияние на производительность и пропускную способность команд, имеющих большую долю ошибок. Можно ожидать увеличения пропускной способности в два-четыре раза. Если команда изначально отстающая, то концентрация на качестве позволяет увеличить этот показатель вдесятеро.
Используйте статические анализаторы кода, такие как PVS-Studio, и ваша команда будет больше заниматься интересным полезным программированием, а не искать, из-за какой опечатки что не работает.
Написанное выше вовсе не означает, что студентам нет смысла использовать статические анализаторы кода. Во-первых, статический анализатор, указывая на ошибки и некачественный код, помогает быстрее осваивать тонкости языка программирования. Во-вторых, умение работать с анализаторами кода пригодится в будущем при работе с большими проектами. Наша команда понимает это и предоставляет для студентов бесплатные лицензии PVS-Studio.
Дополнительные ссылки:
- Статья о статическом анализе кода для менеджеров, которую не стоит читать программистам.
- Развитие инструментария С++ программистов: статические анализаторы кода.
- Ощущения, которые подтвердились числами.
- Как внедрить статический анализатор кода в legacy проект и не демотивировать команду.
Вредный совет N23. "Херакс, херакс и в продакшен" ©
Всегда и везде выкатывайте любые изменения сразу на продакшен. Тестовые сервера – лишняя трата денег.
Это универсальный вредный совет, который применим к разработке на любом языке программирования.
Не знаю, что тут написать умного и полезного. Вред такого подхода очевиден. Что, впрочем, не мешает некоторым следовать этому принципу :)
Думаю, здесь уместна какая-то интересная поучительная история. Но у меня её нет. Возможно, кто-то из читателей расскажет что-то на эту тему. И тогда я вставлю это сюда :).
Вредный совет N24. Прося помощь на форуме, делай так, чтобы из тебя вытягивали информацию. Так всем будет интереснее.
Все только и мечтают тебе помочь. Поэтому стоит спросить на Stack Overflow/Reddit "почему мой код не работают?" и все готовы преодолеть любые препятствия, чтобы ответить.
Этот вредный совет предназначается тем, кто пришёл за помощью на сайт Stack Overflow, Reddit или ещё какой-то форум. Сообщество достаточно лояльно относится к помощи новичкам, но иногда создаётся впечатление, что задающие вопрос делают всё возможное, чтобы его проигнорировали. Рассмотрим подобный вопрос, который я видел на Reddit.
Тема: Кто-то сможет мне объяснить, почему у меня возникает segmentation fault?
Тело вопроса: Ссылка на документ, лежащий в облачном хранилище OneDrive.
Это хороший пример, как не надо задавать вопросы.
Выбран крайне неудобный способ для выкладывания кода. Вместо того, чтобы прочитать необходимый код сразу в теле вопроса, нужно переходить по ссылке. Сайт OneDrive потребовал, чтобы я залогинился, но я поленился это делать. Не настолько мне было интересно, что там за код. По отсутствию ответов на вопрос, лень было не только мне. Более того, многие вообще там не зарегистрированы.
Не понятно даже, о каком языке программирования идёт речь. Стоит ли идти смотреть код, если может оказаться, что ты с ним не работаешь...
Вопрос задан неконкретно. Я так и не узнал, что там за код был, но подозреваю, что его могло быть недостаточно, чтобы дать ответ. Никакой дополнительной информации вопрос не содержит. Не надо так делать.
Попробую сформулировать как следует писать вопрос, чтобы вам помогли.
Основной принцип. Пусть тем, кого вы просите дать ответ, будет удобно!
Вопрос должен быть самодостаточным. Он должен содержать всю необходимую информацию, чтобы не требовалось задавать уточняющие вопросы. Часто спрашивающие попадают в ментальную ошибку, считая, что и так всем всё будет понятно. Помните, люди, которые вам помогают, не знают, что делают ваши функции и классы. Поэтому не ленитесь описать все функции/классы, которые относятся к делу. Я имею в виду, показать, как они устроены и/или описать их словами.
В идеале, следует предоставить минимальный фрагмент кода, на котором воспроизводится проблема. Да, не всегда это получается, но крайне полезно по трём причинам:
- Пока вы будете составлять минимальный пример для воспроизведения, высока вероятность, что вы сами поймёте, в чём состоит ошибка.
- С воспроизводимой ошибкой легко и приятно работать. Скорее всего, вы получите нужную вам помощь от сообщества.
- Оформив воспроизводимый пример, вы можете попробовать обнаружить в нём ошибку, воспользовавшись другим компилятором или статическим анализатором кода. Для этого удобно использовать сайт Compiler Explorer. Там можно скомпилировать ваш код разными C++ компиляторами с разными ключами. Возможно, один из компиляторов выдаст полезное предупреждение. Или это сделает анализатор кода.
Дополнительные ссылки:
- Чему я научился за 10 лет на Stack Overflow.
- How do I ask a good question?
- Тем, кто учится программировать и решил написать вопрос на Stack Overflow: "Почему код не работает?"
Вредный совет N25. Ромбовидное наследование
Язык C++ разрешает выполнять виртуальное наследование и реализовывать с его помощью ромбовидное наследование. Так почему бы не воспользоваться такой прикольной штукой!
Использовать можно. Только надо знать про некоторые тонкости, и сейчас мы их рассмотрим.
Об инициализации виртуальных базовых классов
В начале поговорим, как размещаются в памяти классы, если нет виртуального наследования. Рассмотрим код:
class Base { ... };
class X : public Base { ... };
class Y : public Base { ... };
class XY : public X, public Y { ... };Здесь всё просто. Члены невиртуального базового класса Base размещаются как простые данные-члены производного класса. В результате внутри объекта XY мы имеем два независимых подобъекта Base. Схематически это можно изобразить так:
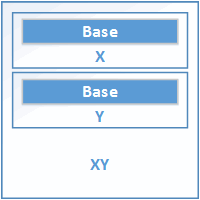
Рисунок 25.1. Невиртуальное множественное наследование.
Объект виртуального базового класса входит в объект производного класса только один раз. Это ещё называется ромбовидным наследованием:
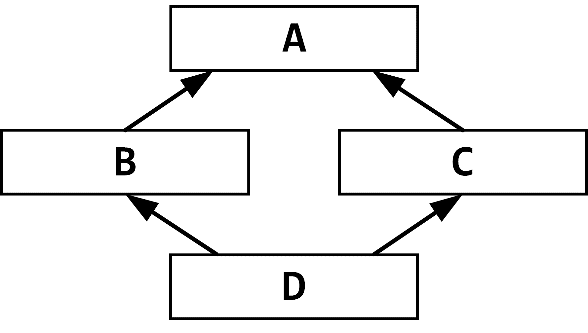
Рисунок 25.2. Ромбовидное наследование.
Устройство объекта XY для приведённого ниже кода с ромбовидным наследование отображено на рисунке 25.3.
class Base { ... };
class X : public virtual Base { ... };
class Y : public virtual Base { ... };
class XY : public X, public Y { ... };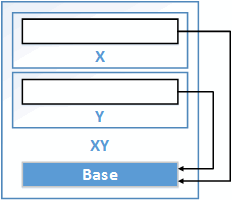
Рисунок 25.3. Виртуальное множественное наследование.
Память для разделяемого подобъекта Base, скорее всего, будет выделена в конце объекта XY. Как именно будет устроен класс, зависит от компилятора. Например, в классах X и Y могут храниться указатели на общий объект Base. Но, как я понимаю, такой метод вышел из обихода. Чаще ссылка на разделяемый подобъект реализуется в виде смещения или информации, которая хранится в таблице виртуальных функций.
Только "самый производный" класс XY точно знает, где должна находиться память для подобъекта виртуального базового класса Base. Поэтому инициализировать все подобъекты виртуальных базовых классов поручается самому производному классу.
Конструкторы XY инициализируют подобъект Base и указатели на этот объект в X и Y. Затем инициализируются остальные члены классов X, Y, XY.
После того как подобъект Base инициализируется в конструкторе XY, он не будет ещё раз инициализироваться конструктором X или Y. Как это будет сделано, зависит от компилятора. Например, компилятор может передавать специальный дополнительный аргумент в конструкторы X и Y, который будет указывать не инициализировать класс Base.
А теперь самое интересное, приводящее ко многим непониманиям и ошибкам. Рассмотрим вот такие конструкторы:
X::X(int A) : Base(A) {}
Y::Y(int A) : Base(A) {}
XY::XY() : X(3), Y(6) {}Какое число примет конструктор базового класса в качестве аргумента? Число 3 или 6? Ни одно из них.
Конструктор XY инициализирует виртуальный подобъект Base, но делает это неявно. Вызывается конструктор Base по умолчанию.
Когда конструктор XY вызывает конструктор X или Y, он не инициализирует Base заново. Поэтому явного обращения к Base с каким-то аргументом не происходит.
На этом приключения с виртуальными базовыми классами не заканчиваются. Помимо конструкторов существуют операторы присваивания. Если я не ошибаюсь, стандарт говорит, что генерируемый компилятором оператор присваивания может многократно выполнять присваивание подобъекту виртуального базового класса. А может только один раз. Так что неизвестно, сколько раз будет происходить копирование объекта Base.
Если вы реализуете свой оператор присваивания, то вы должны самостоятельно позаботься об однократном копировании объекта Base. Рассмотрим неправильный код:
XY &XY::operator =(const XY &src)
{
if (this != &src)
{
X::operator =(*this);
Y::operator =(*this);
....
}
return *this;
}Это код приведёт к двойному копированию объекта Base. Чтобы этого избежать, в классах X и Y необходимо реализовать функции, которые не будут копировать члены класса Base. Содержимое класса Base копируется однократно здесь же. Исправленный код:
XY &XY::operator =(const XY &src)
{
if (this != &src)
{
Base::operator =(*this);
X::PartialAssign(*this);
Y::PartialAssign(*this);
....
}
return *this;
}Такой код будет работать, но всё это некрасиво и запутанно. Поэтому и говорят, что лучше избегать множественного виртуального наследования.
Виртуальные базовые классы и приведение типов
Из-за особенностей размещения виртуальных базовых классов в памяти нельзя выполнить вот такие приведения типов:
Base *b = Get();
XY *q = static_cast<XY *>(b); // Ошибка компиляции
XY *w = (XY *)(b); // Ошибка компиляцииОднако настойчивый программист может всё-таки привести тип, воспользовавшись оператором 'reinterpret_cast':
XY *e = reinterpret_cast<XY *>(b);Однако скорее всего это даст непригодный для использования результат. Адрес начала объекта Base будет интерпретирован как начало объекта XY. А это совсем не то, что надо. Смотрите поясняющий рисунок 25.4.
Единственный способ выполнить приведение типа — воспользоваться оператором dynamic_cast. Однако код, где регулярно используется dynamic_cast, плохо пахнет.
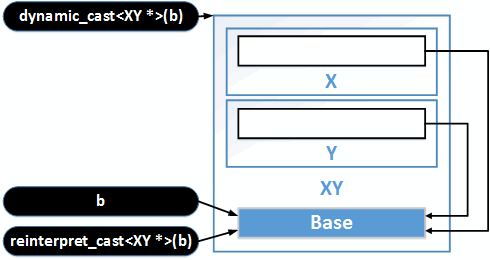
Рисунок 25.4. Приведение типов.
Отказываться ли от виртуального наследования?
Я согласен с мнением многих авторов, что следует всячески избегать виртуального наследования. И от простого множественного наследования тоже лучше уходить.
Виртуальное наследование порождает проблемы при инициализации и копировании объектов. Инициализацией и копированием должен заниматься "самый производный" класс. А это значит, он должен знать интимные подробности об устройстве базовых классов. Образуется лишняя связанность между классами, которая усложняет структуру проекта и заставляет делать дополнительные правки в разных классах при рефакторинге. Всё это способствует ошибкам и усложняет понимание проекта новыми разработчиками.
Сложности приведений типов также способствуют возникновению ошибок. Отчасти проблемы решаются при использовании оператора dynamic_cast. Однако это медленный оператор. И если он начинает массово появляться в программе, то, скорее всего, это свидетельствует о плохой архитектуре проекта. Почти всегда можно реализовать структуру проекта, не прибегая к множественному наследованию. Собственно, во многих языках вообще нет таких изысков. И это не мешает реализовывать большие проекты.
Глупо настаивать отказаться от виртуального наследования. Иногда оно полезно и удобно. Однако стоит хорошо подумать, прежде чем им воспользоваться.
Польза от множественного наследования
Хорошо, критика множественного виртуального наследования и просто множественного наследования понятна. А есть ли места, где она безопасна и удобна?
Да, я могу назвать как минимум одно: подмешивание интерфейсов. Если вам не знакома эта методология, предлагаю обратиться к книге Ален И. Голуба "Верёвка достаточной длины чтобы… выстрелить себе в ногу". Легко ищется в интернете. Следует смотреть раздел 101 и далее.
В интерфейсном классе нет никаких данных. Все функции, как правило, чисто виртуальные. Конструктора в нём нет, или он ничего не делает. Это значит, что нет проблем с созданием или копированием таких классов.
Если базовый класс является интерфейсом, то присваивание — это пустая операция. Так что, даже если объект будет копироваться множество раз, это нестрашно. В скомпилированном коде программы это копирование будет просто отсутствовать.
Об этой мини-книге
Автор: Карпов Андрей Николаевич. E-Mail: karpov [@] viva64.com.
Более 15 лет занимается темой статического анализа кода и качества программного обеспечения. Автор большого количества статей, посвящённых написанию качественного кода на языке C++. С 2011 по 2021 год удостаивался награды Microsoft MVP в номинации Developer Technologies. Один из основателей проекта PVS-Studio. Долгое время являлся CTO компании и занимался разработкой С++ ядра анализатора. Основная деятельность на данный момент — управление командами, обучение сотрудников и DevRel активность.
Ссылки на полный текст:
- RU — 60 антипаттернов для С++ программиста
- EN — 60 terrible tips for a C++ developer
Подписывайтесь на ежемесячную рассылку, чтобы не пропустить другие публикации автора и его коллег.



