
Прим. перев.: Тот восторг, что испытали наши тимлиды, увидев в блоге IBM Cloud этот материал — своеобразное «расширение» легендарного Twelve-Factor App, — говорит сам за себя. Поднятые автором вопросы не просто на слуху, а по-настоящему жизненны, т.е. актуальны в повседневной жизни. Их понимание полезно не только для DevOps-инженеров, но и разработчиков, создающих современные приложения, запускаемые в Kubernetes.
Известная методология «12 factor application» представляет собой свод четко определенных правил для разработки микросервисов. Они широко используются для запуска, масштабирования и деплоя приложений. В облачной платформе IBM Cloud Private мы следуем тем же 12 принципам при разработке контейнеризированных приложений. В статье «Kubernetes & 12-factor apps» обсуждается специфика применения этих 12 факторов (они поддерживаются моделью оркестровки контейнеров Kubernetes).
Размышляя о принципах разработки контейнеризированных микросервисов, работающих под контролем Kubernetes, мы пришли к следующему выводу: вышеуказанные 12 факторов совершенно справедливы, однако для организации production-среды крайне важны и другие, а в частности:
- наблюдаемость (observable);
- прогнозируемость (schedulable);
- обновляемость (upgradable);
- минимальные привилегии (least privilege);
- контролируемость (auditable);
- защищенность (securable);
- измеримость (measurable).
Давайте остановимся на этих принципах и попробуем оценить их значение. Чтобы сохранить единообразие, добавим их к уже имеющимся — соответственно, начнем с XIII…
Принцип XIII: Наблюдаемость
Приложения должны предоставлять сведения о своем текущем состоянии и показателях.
Распределенными системами бывает сложно управлять, поскольку в приложение объединяется множество микросервисов. По сути, различные шестеренки должны двигаться согласованно, чтобы механизм (приложение) работал. Если в одном из микросервисов происходит сбой, система должна автоматически обнаруживать его и исправлять. Kubernetes предоставляет отличные механизмы спасения, такие как тесты на readiness (готовность) и liveliness (живучесть).
С их помощью Kubernetes убеждается, что приложение готово принимать трафик. Если readiness завершается с ошибкой, Kubernetes прекращает направлять трафик в pod до тех пор, пока очередной тест не покажет готовность pod'а.
Предположим, что у нас имеется приложение, состоящее из 3 микросервисов: frontend, бизнес-логика и базы данных. Чтобы приложение смогло работать, перед принятием трафика frontend должен убедиться, что бизнес-логика и базы данных готовы. Сделать это можно с помощью теста readiness — он позволяет убедиться в работоспособности всех зависимостей.
На анимации показано, что запросы в pod не посылаются, пока тест readiness не покажет его готовность:

Тест на готовность в действии: Kubernetes использует readiness probe для проверки готовности pod'ов принимать трафик
Существует три типа тестов: с помощью HTTP, TCP-запросов и команд. Можно контролировать конфигурацию тестов, например, указывать частоту запусков, пороги успеха/неудачи и как долго ждать ответа. В случае liveness-тестов необходимо задать один очень важный параметр —
initialDelaySeconds. Убедитесь, что тест начинается только после того, как приложение уже готово. Если этот параметр задать неправильно, приложение будет постоянно перезапускаться. Вот как это может быть реализовано:livenessProbe:
# an http probe
httpGet:
path: /readiness
port: 8080
initialDelaySeconds: 20
periodSeconds: 5С помощью liveliness-тестов Kubernetes проверяет, работает ли ваше приложение. Если приложение функционирует в штатном режиме, то Kubernetes ничего не предпринимает. Если оно «умерло», Kubernetes удаляет pod и запускает новый взамен. Это соответствует потребности микросервисов в stateless и их утилизируемости (фактор IX, Disposability). Анимация ниже иллюстрирует ситуацию, когда Kubernetes перезапускает pod после провала теста на liveliness:

Liveliness-тест в действии: с его помощью Kubernetes проверяет, «живы» ли pod'ы
Огромное преимущество этих тестов в том, что приложения можно разворачивать в любом порядке, не беспокоясь о зависимостях.
Однако мы обнаружили, что этих тестов недостаточно для production-среды. Обычно у приложений имеются собственные метрики, которые необходимо отслеживать, например, число транзакций в секунду. Клиенты задают пороговые значения для них и настраивают уведомления. IBM Cloud Private заполняет этот пробел с помощью отлично защищенного стека для мониторинга, состоящего из Prometheus и Grafana с системой контроля доступа на основе ролей. Дополнительную информацию можно получить в разделе IBM Cloud Private cluster monitoring.
Prometheus собирает данные о целях с endpoint'а метрик. Ваше приложение должно задать endpoint метрик, используя следующую аннотацию:
prometheus.io/scrape: 'true'После этого Prometheus автоматически обнаруживает endpoint и собирает метрики из нее (как показано на следующей анимации):

Сбор пользовательских метрик
Прим. перев.: Более корректно было бы направить стрелки в обратную сторону, поскольку Prometheus сам ходит и опрашивает endpoint'ы, а Grafana сама забирает данные из Prometheus, но в смысле общей иллюстрации это не так критично.
Принцип XIV: Прогнозируемость
Приложения должны обеспечивать прогнозируемость ресурсных требований.
Представьте, что руководство выбрало вашу команду для экспериментирования с проектом на Kubernetes. Вы напряженно трудились над созданием соответствующей среды. В итоге получилось приложение, демонстрирующее образцовые время отклика и производительность. Потом к работе присоединилась другая команда. Она создала свое приложение и запустила его в той же среде. После старта второго приложения производительность первого внезапно снизилась. В данном случае причину такого поведения следует искать в вычислительных ресурсах (CPU и памяти), доступных для ваших контейнеров. Высока вероятность их дефицита. Возникает вопрос: как гарантировать выделение вычислительных ресурсов, необходимых приложению?
У Kubernetes есть отличная опция, позволяющая задавать ресурсные минимумы и устанавливать ограничения для контейнеров. Минимумы гарантируются. Если контейнеру требуется некий ресурс, Kubernetes запускает его только на узле, который может этот ресурс предоставить. С другой стороны, верхний предел гарантирует, что аппетит контейнера никогда не превысит определенного значения.

Минимумы и ограничения для контейнеров
Следующий фрагмент YAML-кода показывает настройку вычислительных ресурсов:
resources:
requests:
memory: "64Mi"
cpu: "150m"
limits:
memory: "64Mi"
cpu: "200m"Прим. перев.: Подробнее о предоставлении ресурсов в Kubernetes, requests и limits можно узнать из нашего недавнего доклада и его обзора «Автомасштабирование и управление ресурсами в Kubernetes», а также смотрите документацию K8s.
Еще одна интересная возможность для администраторов в production-среде — это установка квот для namespace'ов. Если квота установлена, Kubernetes не будет создавать контейнеры, для которых не определены request/limits в данном namespace'е. Пример задания квот для namespace'ов можно увидеть на рисунке ниже:

Квоты для namespace'ов
Принцип XV. Обновляемость
Приложения должны обновлять форматы данных с предыдущих поколений.
Часто возникает необходимость пропатчить работающее production-приложение, чтобы устранить уязвимость или расширить функциональные возможности. При этом важно, чтобы обновление происходило без перерывов в работе. Kubernetes предоставляет механизм выката (rolling updates), позволяющий обновить приложение без простоя. С помощью этого механизма можно обновлять по pod'у за раз, не останавливая весь сервис. Вот схематическое изображение этого процесса (на нем приложение обновляется до второй версии):

Пример соответствующего YAML-описания:
minReadySeconds: 5
strategy:
# укажите, какую стратегию для обновления хотите
type: RollingUpdate
rollingUpdate:
maxSurge: 1
maxUnavailable: 1Обратите внимание на параметры
maxUnavailable и maxSurge:-
maxUnavailable— необязательный параметр, устанавливающий максимальное количество pod'ов, которые могут быть недоступны во время процесса обновления. Хотя он опционален, установить конкретное значение все же стоит, чтобы гарантировать доступность сервиса; -
maxSurge— другой необязательный, но критически важный параметр. Он устанавливает максимальное число pod'ов, которое может быть создано сверх их желаемого количества.
Принцип XVI: Минимум привилегий
Контейнеры должны работать с минимумом привилегий.
Прозвучит пессимистично, но о каждом разрешении в контейнере вы должны думать как о потенциальной уязвимости (см. иллюстрацию). Например, если контейнер работает под root'ом, то любой человек с доступом к нему может внедрить туда вредоносный процесс. Kubernetes предоставляет политику Pod Security Policy (PSP), позволяющую ограничить доступ к файловой системе, порту хоста, Linux capabilities и многому другому. IBM Cloud Private предлагает готовый набор PSP, который привязывается к контейнерам при их provisioning’е в namespace. Дополнительные сведения доступны на странице Using namespaces with Pod Security Policies.
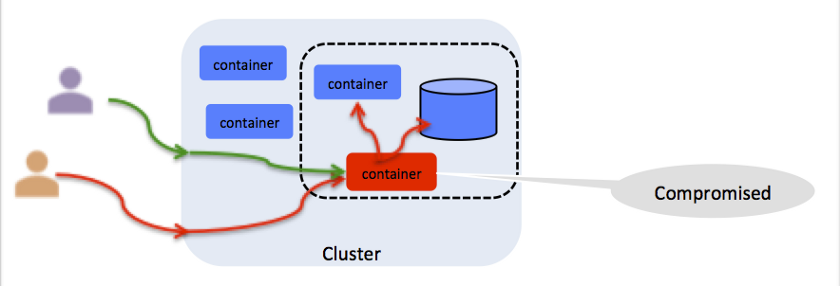
Всякое разрешение — это потенциальный вектор атаки
Принцип XVII: Контролируемость
Необходимо знать, кто, что, где и когда для всех критически важных операций.
Контролируемость критически важна для любых действий с кластером Kubernetes или приложением. Например, если приложение обрабатывает операции с кредитными картами, необходимо подключить аудит, чтобы иметь в распоряжении контрольный след каждой транзакции. IBM Cloud Private использует отраслевой стандарт Cloud Auditing Data Federation (CADF), инвариантный к конкретным облачным реализациям. Дополнительная информация доступна в разделе Audit logging in IBM Cloud Private.
CADF-событие содержит следующие данные:
-
initiator_id— ID пользователя, выполнившего операцию; -
target_uri— целевой URI CADF (например: data/security/project); -
action— выполняемое действие, обычноoperation: resource_type.
Принцип XVIII: Защищенность (идентификация, сеть, область применения, сертификаты)
Необходимо защищать приложение и ресурсы от посторонних.
Этот пункт заслуживает отдельной статьи. Достаточно сказать, что production-приложениям необходима сквозная защита. IBM Cloud Private применяет следующие меры для обеспечения безопасности production-сред:
- аутентификация: подтверждение личности;
- авторизация: проверка доступа аутентифицированных пользователей;
- управление сертификатами: работа с цифровыми сертификатами, включая создание, хранение и продление;
- защита данных: обеспечение безопасности передаваемых и хранимых данных;
- сетевая безопасность и изоляция: предотвращение доступа к сети неавторизованных пользователей и процессов;
- советник по уязвимостям: выявление уязвимостей в образах;
- советник по мутациям: выявление мутаций в контейнерах.
Подробности можно узнать из руководства по безопасности IBM Cloud Private.
Особого внимания заслуживает менеджер сертификатов. Этот сервис в IBM Cloud Private основан на открытом проекте Jetstack. Менеджер сертификатов позволяет выпускать и управлять сертификатами для сервисов, работающих в IBM Cloud Private. Он поддерживает как публичные, так и самозаверенные сертификаты, полностью интегрируется с kubectl и контролем доступа на основе ролей.
Принцип XIX: Измеримость
Использование приложения должно быть измеримым для целей квотирования и расчетов между подразделениями.
В конечном итоге компаниям приходится оплачивать IT-издержки (см. рис. ниже). Вычислительные ресурсы, выделенные для запуска контейнеров, должны быть измеримыми, а организации, использующие кластер, должны быть подотчетными. Убедитесь, что следуете принципу XIV — Прогнозируемости. IBM Cloud Private предлагает службу учета, которая собирает данные о вычислительных ресурсах для каждого контейнера и объединяет их на уровне namespace для дальнейших расчетов (в рамках showback'ов или chargeback'ов).
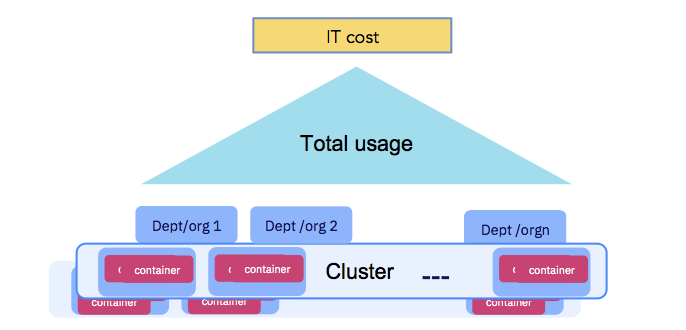
Использование приложения должно быть измеримым
Заключение
Надеюсь, тема, поднятая в этой статье, вам понравилась, и вы отметили факторы, которые уже используете, и задумались о тех, которые пока остаются в стороне.
Для дополнительной информации рекомендую ознакомиться с записью нашего выступления на KubeCon 2019 в Шанхае. В нем я и Michael Elder обсуждаем 12+7 принципов для оркестровки контейнеров на основе Kubernetes.
P.S. от переводчика
Читайте также в нашем блоге:
- «Микросервисы: размер имеет значение, даже если у вас Kubernetes»;
- «7 лучших практик по эксплуатации контейнеров по версии Google»;
- «Мониторинг и Kubernetes (обзор и видео доклада)»;
- «Смерть микросервисного безумия в 2018 году».



