
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Артефакты, которые отличают подделку от реальных данных, могут находиться в спектральной или временной областях. Их надежное обнаружение обычно зависит от ансамбля сложных систем, где каждая подсистема настроена на определенные артефакты. Мы стремимся разработать единую, эффективную систему, которая может обнаруживать широкий спектр различных атак с использованием спуфинга без использования групп баллов. Мы предлагаем новый слой внимания с гетерогенным наложением графа, который моделирует артефакты, охватывающие разнородные временные и спектральные области с гетерогенным механизмом внимания и узлом стека. С новой операцией максимального графа, которая включает конкурентный механизм и расширенную схему считывания, наш подход, названный AASIST, превосходит текущее состояние дел в данной области примерно на 20%. Даже облегченный вариант, AASIST-L, всего с 85 тыс. параметров, превосходит все конкурирующие системы.
Введение
Недавние исследования показывают, что различительная информация (т. е. артефакты спуфинга) могут находиться как в спектральной, так и во временной областях [5–9]. Артефакты, как правило, зависят от характера атаки и конкретного используемого алгоритма. Поэтому адаптивные механизмы, которые обладают способностью концентрироваться на области, в которой находятся артефакты, имеют решающее значение для надежного обнаружения. В наших недавних работах [10,11] мы предложили сквозные системы, использующие кодировщик, подобный RawNet2 [12, 13], и сети внимания на графах GAT [14]. Мы моделировали как спектральную, так и временную информацию одновременно с используя два параллельных графа, а затем применили поэлементное умножение двух графов. Несмотря на то, что в [11] мы достигли высочайшего уровня производительности, мы считаем, что еще есть возможности для дальнейшего улучшения, поскольку два графа неоднородны, их интеграция с использованием техники, учитывающей неоднородность, была бы полезной.
Мы предлагаем четыре расширения для нашей предыдущей работы, RawGATST [11], где первые три составляют предложенную модель с именем AASIST, а последнее создает уменьшенную версию AASIST. Во-первых, мы предлагаем расширенный вариант слоя внимания графа, называемый «слоем внимания гетерогенного наложения графа» (“heterogeneous stacking graph attention layer” HS-GAL). Он облегчает одновременное моделирование разнородных (спектральных и временных) представлений графа. HS-GAL включает модифицированный механизм внимания, учитывающий неоднородность и дополнительные стековые узлы, каждый из которых основан на [15] и [16] соответственно. HS-GAL может напрямую моделировать два произвольных графа, где два графа могут иметь разное количество узлов и разные размерности. Во-вторых, мы предлагаем механизм, называемый «максимальная операция графа» (“max graph operation” MGO), который имитирует карту максимальных характеристик [17]. MGO включает две ветви, каждая из которых включает два HS-GAL и уровни объединения графов, за которыми следует поэлементная операция максимума. Основная цель здесь - дать возможность разным ветвям изучать разные группы артефактов. Элементы, содержащие артефакты, не подавляются MGO. В-третьих, мы представляем новую схему считывания, которая использует узел стека. Наконец, учитывая применение решений для защиты от спуфинга в существующих системах голосовой проверки [18, 19] и связанные с этим требования к практичным, легким моделям, мы также предлагаем облегченный вариант AASIST, который включает только 85K параметров.
Подбор элементов
В этом разделе мы суммируем компоненты, которые являются общими для RawGAT-ST [11] и новых моделей AASIST. Мы описываем:
I) кодировщик на основе RawNet2, используемый для извлечения высокоуровневых карт характеристик из необработанных входных сигналов;
II) модуль графа, который включает слои внимания и объединения графов. Эти два компонента соответствуют «кодировщику» и «модулю графа» на Рисунке 1 соответственно.

рис.1 Общая структура предлагаемого AASIST. Идентично [11]: кодировщик извлекает карты признаков F, затем следуют два граф модуля, каждый из которых моделирует спектральную и временную области. Предложено: использовать операцию максимального графа адаприованную для двух ветвей, которые моделируют неоднородные графы параллельно, за которыми следует поэлементный максимум. Каждая ветвь включает два предложенных слоя HS-GAL и два слоя объединения графа (graph pooling layer). )На схеме опущены слой graph pooling и один слой HS-GAL.) Наконец максимумы и средние узлов объединяются в узловом стеке, за которым следует выходной слой.
2.1. Кодировщик на основе RawNet2
Все большее число исследователей применяют модели, которые работают непосредственно с исходными сигналами. В работе, описанной в этой статье, используется вариант модели RawNet2, представленный в [12] для задачи проверки говорящего и впоследствии примененный для защиты от спуфинга [11, 13]. Он извлекает высокоуровневые представления  непосредственно из необработанного входного сигнала, где С, S и T - количество каналов, спектральные (частотные) элементы и длина временной последовательности соответственно.
непосредственно из необработанного входного сигнала, где С, S и T - количество каналов, спектральные (частотные) элементы и длина временной последовательности соответственно.
В отличие от исходной модели RawNet2, мы интерпретируем выходные данные слоя синк-свертки (sinc-convolution layer) как двумерное изображение с одним каналом (аналогично спектрограмме), а не одномерную последовательность с несколькими фильтрами, рассматривая выходные данные каждого фильтра как спектральные полосы. Серия из шести остаточных блоков (residual block) с предварительной активацией [20] используется для извлечения высокоуровневого представления. Каждый остаточный блок включает в себя слой batch normalization[21], слой Conv2D, активацию SeLU [22] и слой Max Pooling. Дополнительную информацию можно найти в [11].
2.2. Графовый модуль
Графовая сеть внимания (GAT). Недавние достижения в графовых нейронных сетях привели к прорыву в производительности в ряде задач [10, 14, 23], где граф определяется набором узлов и набором ребер, соединяющих разные пары узлов. Используя многомерный вектор в качестве узла, графовые нейронные сети можно использовать для моделирования неевклидова многообразия данных между различными узлами. В частности, мы показали, что сеть графового внимания [14] может применяться как для проверки говорящего [23], так и для обнаружения спуфинга [10, 11]. Слой графового внимания, используемый в нашей работе, представляет собой вариант оригинальной архитектуры [14]. В нашей работе графы полностью связаны в том смысле, что между каждой парой узлов есть ребра. Это связано с тем, что релевантность каждой пары узлов для поставленной задачи не может быть предопределена заранее. Вместо этого механизм самоконтроля на уровне внимания графа выводит весовые коэффициенты внимания на основе данных, назначенные каждому ребру, чтобы отразить релевантность каждой пары узлов. Перед получением весов внимания используется поэлементное умножение, чтобы сделать ребра симметричными. За дальнейшими подробностями читатель может обратиться к [11] (раздел 3).
Объединение графов (graph pooling). Различные слои объединения графов были предложены для эффективного масштабирования графа [24, 25]. Это имеет целью уменьшить сложность и улучшить различение. Мы применяем простой слой объединения графов к выходным данным каждого слоя внимания графа. За исключением исключения нормализации вектора проекции, наша реализация идентична реализации в [25].
Пусть  — выходной граф слоя внимания графа, где N — количество узлов, а D — размерность каждого узла. Обратите внимание, что порядок узлов не имеет значения; отношения между ними определяются с помощью весов внимания, назначенных каждому ребру. Веса внимания получаются через
— выходной граф слоя внимания графа, где N — количество узлов, а D — размерность каждого узла. Обратите внимание, что порядок узлов не имеет значения; отношения между ними определяются с помощью весов внимания, назначенных каждому ребру. Веса внимания получаются через  , где · (точка) – скалярное произведение, а
, где · (точка) – скалярное произведение, а  представляет собой вектор проекции, который возвращает скалярный весовой коэффициент внимания для каждого узла. После умножения сигмовидной нелинейности на соответствующие
представляет собой вектор проекции, который возвращает скалярный весовой коэффициент внимания для каждого узла. После умножения сигмовидной нелинейности на соответствующие  узлов узлы со значениями
узлов узлы со значениями  сохраняются, а остальные отбрасываются.
сохраняются, а остальные отбрасываются.
3. AASIST
AASIST строится на основе нашей предыдущей работы, RawGAT-ST, в которой два разнородных графа, один спектральный, а другой временной, объединяются на уровне модели. Однако вместо использования тривиальных поэлементных операций и полносвязных слоев новая работа основана на более элегантном подходе, использующем предложенный HS-GAL. Кроме того, AASIST включает предлагаемые методы MGO и технику считывания (readout).
Для удобства приведем здесь еще раз рисунок 1.
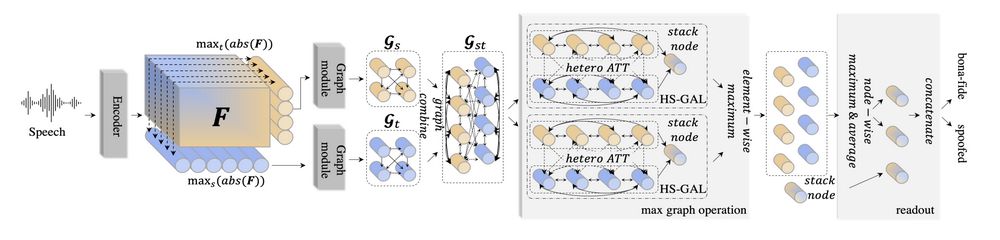
На рис. 1 показана общая структура AASIST, включая предлагаемые HS-GAL, MGO и методы считывания. Высокоуровневое представление F извлекается путем подачи необработанных сигналов в энкодер на основе RawNet2 (раздел 2.1). Два графовых модуля сначала моделируют спектральную и временную области параллельно, получая  (раздел 2.2). Результаты объединяются в
(раздел 2.2). Результаты объединяются в  (раздел 3.1) и обрабатываются с помощью MGO (раздел 3.3), который включает четыре слоя HS-GAL (раздел 3.2) и четыре graph pooling слоя. Затем выполняются операции считывания (readout), за которыми следует выходной слой с двумя узлами.
(раздел 3.1) и обрабатываются с помощью MGO (раздел 3.3), который включает четыре слоя HS-GAL (раздел 3.2) и четыре graph pooling слоя. Затем выполняются операции считывания (readout), за которыми следует выходной слой с двумя узлами.
3.1. Комбинация графов
Сначала мы составим гетерогенный граф, используя два разных графа, каждый из которых моделирует спектральную и временную области ( на рисунке 1). Пусть
на рисунке 1). Пусть  и
и спектральный и временной граф соответственно, каждый из готорых получен в соответствии с:
спектральный и временной граф соответственно, каждый из готорых получен в соответствии с:

где модуль графа относится к комбинации уровней внимания графа и слоев объединения графов, и где  представляет собой карту характеристик выхода энкодера. Затем мы формулируем комбинированный граф
представляет собой карту характеристик выхода энкодера. Затем мы формулируем комбинированный граф  , который имеет
, который имеет  узлов, добавляя ребра между каждым узлом в
узлов, добавляя ребра между каждым узлом в  и каждым узлом в
и каждым узлом в  и наоборот (пунктирные стрелки под
и наоборот (пунктирные стрелки под  ). Новые ребра в комбинированном графе
). Новые ребра в комбинированном графе  позволяют получить веса внимания между парами разнородных узлов, каждый из которых охватывает временную и спектральную области. Несмотря на комбинацию,
позволяют получить веса внимания между парами разнородных узлов, каждый из которых охватывает временную и спектральную области. Несмотря на комбинацию,  остается неоднородным графом в том смысле, что узлы в каждом из составляющих графов лежат в разных скрытых пространствах;
остается неоднородным графом в том смысле, что узлы в каждом из составляющих графов лежат в разных скрытых пространствах;  и
и  обычно отличаются от
обычно отличаются от  и
и  .
.
3.2. HS-GAL
Новый вклад основан на слое неоднородного стека (heterogeneous stacking graph
attention layer - HS-GAL — пунктирная рамка на рис. 1). Он состоит из двух компонентов, а именно неоднородного внимания и узлов мультипликации (стека). Наш подход к неоднородному вниманию вдохновлен подходом к моделированию неоднородных данных, описанным в [15]. Входные данные для HS-GAL сначала проецируются в другое скрытое пространство, чтобы дать каждому из двух графов с размерностями узлов  и
и  общую размерность
общую размерность  . Для этой цели используются два полносвязных слоя, каждый из которых проецирует один из составляющих его подграфов на размерность
. Для этой цели используются два полносвязных слоя, каждый из которых проецирует один из составляющих его подграфов на размерность  .
.
Неоднородное внимание. В то время как однородные графы используют один вектор проекций для получения весов внимания, мы используем три разных вектора проекций для вычисления весов внимания для гетерогенного (неоднородного) графа. Они проиллюстрированы внутри  на Рисунке 1 и используются для определения весовых коэффициентов внимания для ребер, соединяющих:
на Рисунке 1 и используются для определения весовых коэффициентов внимания для ребер, соединяющих:
(I) узлы в  с узлами в
с узлами в  (ребра между оранжевыми узлами);
(ребра между оранжевыми узлами);
(II) узлы в  c
c  и
и  c
c  (пунктирные ребра);
(пунктирные ребра);
(III)  c
c (ребра между синими узлами).
(ребра между синими узлами).
Вектор проекции в случае (II) выше применяется к ребрам в обоих направлениях; слой графа внимание (graph attention layer) применяет поэлементное умножение между двумя узлами, делая веса внимания симметричными, а не конкатенируя два узла, как в [14].
Объединение узлов (stack node). Мы также вводим новый, дополнительный узел, называемый "стековым" узлом (или объединяющим узлом). Роль объединяющего узла заключается в накоплении разнородной информации, а именно информации или взаимосвязи между спектральной и временной областями. Объединяющий узел подключен к полному набору узлов (исходящих из  и
и  ). Использование однонаправленных ребер от всех других узлов к объединяющему узлу помогает сохранить информацию как в
). Использование однонаправленных ребер от всех других узлов к объединяющему узлу помогает сохранить информацию как в  , так и в
, так и в  . Он не передает информацию другим узлам. Кроме того, при последовательном использовании более чем одного слоя HS-GAL объединяющий узел предыдущего слоя может быть передан следующему слою. Поведение объединяющего узела аналогично поведению маркеров классификации [16], за исключением того, что соединения с другими узлами являются однонаправленными.
. Он не передает информацию другим узлам. Кроме того, при последовательном использовании более чем одного слоя HS-GAL объединяющий узел предыдущего слоя может быть передан следующему слою. Поведение объединяющего узела аналогично поведению маркеров классификации [16], за исключением того, что соединения с другими узлами являются однонаправленными.
3.3. Операция Max graph и считывание (readout)
Новая «max graph operation» (MGO), выделенная большим серым прямоугольником на рисунке 1, вдохновлена рядом работ в литературе по борьбе со спуфингом, в которых показаны преимущества поэлементных максимальных операций [11, 26]. MGO стремится подражать процедуре обнаружения различных артефактов, вызванных параллельным спуфингом и их комбинированием. Он использует две параллельные ветви, где поэлементный максимум применяется к выходам двух ветвей. В частности, каждая ветвь последовательно включает два слоя HS-GAL, где после каждого слоя HS-GAL применяется graph pooling слой (слой объединения графа). Таким образом, MGO содержит в общей сложности четыре слоя HS-GAL и четыре graph pooling слоя. Два слоя HS-GAL в каждой ветви совместно используют объединяющий узел (stack node), путем передачи объединенного узла от предыдущего слоя HS-GAL следующему. Поэлементный максимум также применяется к объединяющим узлам двух ветвей.
Модифицированная схема считывания (readout) показана в крайнем правом сером прямоугольнике на рисунке 1. Сначала мы применяем поузловую максимизацию и усреднение. Затем формируется последний скрытый слой посредствам конкатенации двух узлов, полученных с использованием усреднения и максимизации вдоль объединенного узла.
3.4. Облегченный вариант ASSIST
Дополнительно мы исследуем облегченный вариант, а именно AASIST-L. Оставив архитектуру идентичной, мы настроим количество параметров, чтобы составить модель с 85K параметрами, используя алгоритм обучения на основе популяции (см. Популяционное обучение нейронных сетей [27]). Это приводит к модели размером 332 КБ, после чего такие методы, как обучение с половинной точностью, уменьшают размер вдвое. С помощью экспериментов мы демонстрируем, что AASIST-L по-прежнему превосходит все модели, кроме AASIST, показанной в таблице 1.

4. Эксперименты и результат
4.1. Набор данных и метрики
Все эксперименты проводились с использованием набора данных логического доступа (LA) ASVspoof 2019 [3, 39]. Он состоит из трех подмножеств: обучение, разработка и оценка. Наборы для обучения и разработки содержат атаки, созданные на основе шести алгоритмов спуфинговых атак (A01-A06), тогда как набор для оценки содержит атаки, созданные на основе тринадцати алгоритмов (A7-A19). Для получения полной информации читатели могут обратиться к [39].
Мы используем две метрики: функцию минимальной оценки обнаружения тандема по умолчанию (min t-DCF) [18] и коэффициент равной ошибки (EER). Mint-DCF показывает влияние спуфинга и системы обнаружения спуфинга на производительность системы автоматической проверки говорящего, тогда как EER отражает чисто автономную производительность обнаружения спуфинга. Wang et al. [33] показали, что производительность систем обнаружения спуфинга может значительно различаться в зависимости от случайных начальных значений. Мы наблюдали то же явление; при обучении с различными случайными начальными значениями было обнаружено, что EER базовой системы RawGAT-ST [11] варьируется от 1,19% до 2,06%. Таким образом, результаты несколько отличаются от тех, о которых сообщалось в [11]. Все результаты, представленные в этой статье, являются средними результатами в дополнение к лучшему результату из трех прогонов с разными случайными начальными значениями.
4.2. Детали реализации
AASIST был реализован с использованием PyTorch, набора инструментов для глубокого обучения на Python. На вход кодировщика, на основе RawNet2, подаются необработанные семплы размером 64600 выборок, частотой 16Khz (≈ 4 секунды). Первый слой кодировщика, sinc-convolution [40], имеет 70 фильтров. Кодер на основе RawNet2 состоит из шести остаточных блоков (residual block). Первые два имеют 32 фильтра, а остальные четыре имеют 64 фильтра. Первые два слоя внимания имеют 64 фильтра. Слои graph pooling удаляют 50 % и 30 % спектральных и временных узлов соответственно. Все последующие слои внимания имеют 32 фильтра и сопровождаются слоем graph pooling, что еще больше уменьшает количество узлов на 50%. Мы использовали оптимизатор Адама [41] со скоростью обучения 10-4 и косинусным снижением скорости обучения. Система AASIST-L была настроена с помощью генетического алгоритма в течение 7 поколений и с 30 экспериментами для каждого поколения [27].
4.3. Результаты

Таблица2. Разбивка EER (%) показатели всех 13 атак, которые существуют в оценочном наборе ASVspoof 2019 LA, объединенном минимальном t-DCF (P1) и объединенном EER (%, P2). Сравниваются RawGAT-ST [11] (базовый уровень, современное состояние) и предложенный AASIST. Мы воспроизвели RawGAT-ST, используя три разных случайных начальных числа, где оценки лучшего начального числа показывают аналогичные показатели по сравнению с исходной бумагой (в таблице 1). Все заявленные характеристики являются средними с использованием трех повторных экспериментов с разными случайными начальными значениями, в которых значения в скобках представляют собой показатели наилучшего начального числа. Лучшие показатели для каждого столбца выделена жирным шрифтом.
В таблице 2 описаны EER для каждой отдельной атаки, объединенного минимального t-DCF и объединенного EER. Для объединенных показателей мы также сообщаем о лучших показателях в скобках. В ней показано сравнение производительности предложенной модели AASIST и современной базовой модели RawGAT-ST [11]. ASSIST работает так же или лучше, чем базовый уровень для 9 из 13 условий. Для оставшихся 4 условий, при которых базовый уровень работает лучше, различия незначительны. В условиях, когда AASIST работает лучше, улучшения могут быть существенными. Например для условия A15, где AASIST превосходит базовый уровень более чем на 35% относительно (1,03% против 0,65%). Объединенные результаты min t-DCF и EER показаны в двух крайних правых столбцах таблицы 2. AASIST превосходит базовый уровень RawGAT-ST с точки зрения как объединенной минимальной t-DCF, так и объединенной EER. Для AASIST минимальное значение t-DCF снижается более чем на 20% относительного значения (0,0443 против 0,0347). С наиболее удачной начальной инициализацией AASIST демонстрирует EER 0,83 % и минимальное значение t-DCF 0,0275, что выше, чем у любой из описанных одиночных систем в литературе.
Сравнение с современными системами. В таблице 1 представлено сравнение предложенной модели AASIST с показателями ряда недавно предложенных конкурирующих систем [9–11, 28–38] для того же набора данных ASVspoof 2019 LA. Набор систем охватывает широкий спектр различных интерфейсных представлений и типовых архитектур. Пять из шести лучших систем работают с необработанными входными сигналами, а три лучшие системы основаны на сетях c графом внимания (GAT). Предлагаемая система AASIST является самой эффективной из всех.
AASIST-L: облегченный вариант. В таблице 1 также показано сравнение по сложности меньшей модели AASIST-L и других моделей, для которых количество параметров находятся в открытом доступе. Используя всего 85 тысяч параметров, AASIST-L значительно проще, чем все другие системы. Минимальные t-DCF и EER, достигнутые моделью AASIST-L, лучше, чем у всех других систем, за исключением полной модели AASIST. При соответствующей модификации с использованием таких методов, как вывод с половинной точностью и сокращение параметров, мы считаем, что он будет достаточно мал, чтобы его можно было использовать во встроенных системах.
Вклад. В таблице 3 показаны результаты экспериментов по вкладу, в которых один из компонентов модели AASIST был удален. Результаты показывают, что все три метода полезны; без какой-либо из них результаты хуже, чем у полной модели AASIST. Применение неоднородного внимания оказало наибольшее влияние с точки зрения показателей. MGO, аналогичная концепция с максимальной картой признаков [17] также была эффективной, демонстрируя последовательное влияние максимальной операции (MGO) на обнаружение спуфинга.
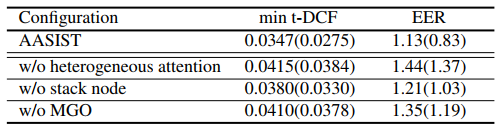
Таблица3. Эксперименты по вкладу призваны продемонстрировать эффективность каждого отдельного метода моделирования двух разнородных графов (спектрального и временного). Производительность указана как «средняя (лучшая)» после трех повторных экспериментов.
5. Заключение
Мы предлагаем AASIST, новую сквозную систему обнаружения спуфинга, основанную на графовых нейронных сетях (GNN). Новый вклад состоит из трех частей:
(I) Слой гетерогенного стека графа внимания (HS-GAL), используемый для моделирования спектральных и временных подграфов, состоит из гетерогенного механизма внимания и объединяющего узла для накопления разнородной информации;
(II) операция максимального графа (MGO), которая включает конкурентный выбор артефактов;
(III) модифицированная схема считывания (readout).
AASIST улучшает производительность современного базового уровня более чем на 20% относительно минимального t-DCF. Даже облегченная версия AASIST-L с параметрами 85K превосходит все конкурирующие систем
От переводчика: прошу присылать комментарии, уточнения и пр. буду рад обсуждению и уточнениям.
6. Использованная литератураы.
[1] Z. Wu, T. Kinnunen, N. Evans et al., “Asvspoof 2015: the first
automatic speaker verification spoofing and countermeasures
challenge,” in Proc. Interspeech, 2015.
[2] T. Kinnunen, M. Sahidullah, H. Delgado et al., “The asvspoof
2017 challenge: Assessing the limits of replay spoofing attack
detection,” in Proc. Interspeech, 2017.
[3] M. Todisco, X. Wang, V. Vestman et al., “Asvspoof 2019: Future horizons in spoofed and fake audio detection,” in Proc.
Interspeech, 2019.
[4] J. Yamagishi, X. Wang, M. Todisco et al., “Asvspoof 2021: accelerating progress in spoofed and deepfake speech detection,”
arXiv 2109.00537, 2021.
[5] J. Yang, R. K. Das and H. Li, “Significance of subband features for synthetic speech detection,” IEEE Transactions on
Information Forensics and Security, vol. 15, 2019.
[6] K. Sriskandaraja, V. Sethu, P. N. Le and E. Ambikairajah,
“Investigation of sub-band discriminative information between
spoofed and genuine speech.,” in Proc. Interspeech, 2016.
[7] J. Jung, H. Shim, H. Heo and H. Yu, “Replay attack detection
with complementary high-resolution information using end-toend dnn for the asvspoof 2019 challenge,” in Proc. Interspeech,
2019.
[8] H. Tak, J. Patino, A. Nautsch et al., “An explainability study
of the constant Q cepstral coefficient spoofing countermeasure
for automatic speaker verification,” in Proc. Odyssey, 2020.
[9] H. Tak, J. Patino, A. Nautsch et al., “Spoofing Attack Detection
using the Non-linear Fusion of Sub-band Classifiers,” in Proc.
Interspeech, 2020.
[10] H. Tak, J. Jung, J. Patino et al., “Graph attention networks for
anti-spoofing,” in Proc. Interspeech, 2021.
[11] H. Tak, J. Jung, J. Patino et al., “End-to-end spectro-temporal
graph attention networks for speaker verification anti-spoofing
and speech deepfake detection,” in Proc. ASVspoof workshop,
2021.
[12] J. Jung, S. Kim, H. Shim et al., “Improved RawNet with Feature Map Scaling for Text-Independent Speaker Verification
Using Raw Waveforms,” in Proc. Interspeech, 2020.
[13] H. Tak, J. Patino, M. Todisco et al., “End-to-end anti-spoofing
with rawnet2,” in Proc. ICASSP, 2021.
[14] P. Velickovi ˇ c, G. Cucurull, A. Casanova et al., “Graph attention ´
networks,” in Proc. ICLR, 2018.
[15] X. Wang, H. Ji, C. Shi et al., “Heterogeneous graph attention
network,” in The World Wide Web Conference, 2019.
[16] J. D. M.-W. C. Kenton and L. K. Toutanova, “Bert: Pretraining of deep bidirectional transformers for language understanding,” in Proc. NAACL-HLT, 2019.
[17] X. Wu, R. He, Z. Sun and T. Tan, “A light cnn for deep face
representation with noisy labels,” IEEE Transactions on Information Forensics and Security, vol. 13, no. 11, 2018.
[18] T. Kinnunen, K. A. Lee, H. Delgado et al., “t-dcf: a detection cost function for the tandem assessment of spoofing
countermeasures and automatic speaker verification,” in Proc.
Odyssey, 2018.
[19] H. Shim, J. Jung, J. Kim and H. Yu, “Integrated replay
spoofing-aware text-independent speaker verification,” Applied Sciences, vol. 10, no. 18, 2020.
[20] K. He, X. Zhang, S. Ren and J. Sun, “Identity mappings in
deep residual networks,” in Proc. ECCV, 2016.
[21] S. Ioffe and C. Szegedy, “Batch normalization: Accelerating
deep network training by reducing internal covariate shift,” in
Proc. ICML, 2015.
[22] G. Klambauer, T. Unterthiner, A. Mayr and S. Hochreiter,
“Self-normalizing neural networks,” in Proc NeuralIPS, 2017.
[23] J. Jung, H. Heo, H. Yu and J. S. Chung, “Graph attention networks for speaker verification,” in Proc. ICASSP, 2021.
[24] J. Lee, I. Lee and J. Kang, “Self-attention graph pooling,” in
Proc. ICML, 2019.
[25] H. Gao and S. Ji, “Graph u-nets,” in Proc. ICLM, 2019.
[26] G. Lavrentyeva, S. Novoselov, E. Malykh et al., “Audio replay attack detection with deep learning frameworks,” in Proc.
Interspeech, 2017.
[27] M. Jaderberg, V. Dalibard, S. Osindero et al., “Population
based training of neural networks,” arXiv 1711.09846, 2017.
[28] Y. Zhang, W. Wang and P. Zhang, “The effect of silence
and dual-band fusion in anti-spoofing system,” in Proc. Interspeech, 2021.
[29] G. Hua, A. Beng jin teoh and H. Zhang, “Towards end-to-end
synthetic speech detection,” IEEE Signal Processing Letters,
2021.
[30] W. Ge, J. Patino, M. Todisco and N. Evans, “Raw differentiable architecture search for speech deepfake and spoofing detection,” in Proc. ASVspoof workshop, 2021.
[31] X. Li, X. Wu, H. Lu et al., “Channel-wise gated res2net: Towards robust detection of synthetic speech attacks,” in Proc.
Interspeech, 2021.
[32] T. Chen, A. Kumar, P. Nagarsheth et al., “Generalization of
audio deepfake detection,” in Proc. Odyssey, 2020.
[33] X. Wang and J. Yamagishi, “A Comparative Study on Recent
Neural Spoofing Countermeasures for Synthetic Speech Detection,” in Proc. Interspeech, 2021.
[34] A. Luo, E. Li, Y. Liu et al., “A capsule network based approach
for detection of audio spoofing attacks,” in Proc.ICASSP, 2021.
[35] Y. Zhang, F. Jiang and Z. Duan, “One-class learning towards
synthetic voice spoofing detection,” IEEE Signal Processing
Letters, vol. 28, 2021.
[36] X. Li, N. Li, C. Weng et al., “Replay and synthetic speech
detection with res2net architecture,” in Proc. ICASSP, 2021.
[37] X. Ma, T. Liang, S. Zhang et al., “Improved lightcnn with
attention modules for asv spoofing detection,” in Proc. IEEE
ICME, 2021.
[38] W. Ge, M. Panariello, J. Patino et al., “Partially-Connected
Differentiable Architecture Search for Deepfake and Spoofing
Detection,” in Proc. Interspeech, 2021.
[39] X. Wang, J. Yamagishi, M. Todisco et al., “Asvspoof 2019: A
large-scale public database of synthesized, converted and replayed speech,” Computer Speech & Language, vol. 64, 2020.
[40] M. Ravanelli and Y. Bengio, “Speaker recognition from raw
waveform with sincnet,” in Proc. IEEE SLT, 2018.
[41] D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” in Proc. ICLR, 2015.



