
С течением жизни приложения в его БД накапливается все больше данных. Десктопное оно, SaaS или даже мобильное - неважно, в современном мире почти каждый что-то хранит "у себя".
Если это какая-то локальная утилита - не страшно, само ее существование у пользователя достаточно ограничено. Но если это что-то вроде нашего СБИС, который накапливает и помогает анализировать операции за все время существования бизнеса, то, по мере его роста, не только операций становится больше, но и понимания, какие именно сводные отчеты помогают в оперативном управлении.
Вот про то, как сделать такие отчеты быстрыми, какие бывают способы их реализации и встречаются "грабли" на этом пути, сегодня и поговорим.
Динамический подсчет
Самая простая реализация - просто берем и считаем count(*)/sum/min/max/... прямо по исходному набору данных. Чувствует себя достаточно неплохо, если количество агрегируемых записей не превышает нескольких сотен и будет эффективен за счет малой вычислительной нагрузки и нахождения в кэше всего, что хочется считать.

Несколько одновременных агрегатов
Первая оптимизация, которая может помочь в ускорении такого запроса - это вычисление сразу нескольких агрегатов за единственный проход данных.
Подробно об этой методике рассказано в статье "SQL HowTo: 1000 и один способ агрегации".

EXPLAIN-оценка count(*)
Этот способ актуален для "длинных" отчетов, в которых очень хочется отобразить "пейджинг" - и обязательно с общим счетчиком "записей всего". И это - классический антипаттерн, поскольку из-за использования MVCC, PostgreSQL вынужден все равно вычитывать и считать отдельно все эти записи, а это медленно.
К счастью, для любителей странного есть "хак" для вероятностной оценки count() на основе вывода EXPLAIN.
Триггер-аккумулятор
Следующий вариант уже требует изменений в структуре БД - заводим отдельную от исходных данных таблицу, в которой будут жить агрегаты, а на таблицу(ы) с "первичкой" вешаем триггер.
В самом простом виде это может выглядеть примерно так:
-- таблица значений
CREATE TABLE tbl(
id
integer
);
-- таблица счетчиков
CREATE TABLE agg(
id
integer
PRIMARY KEY
, qty
integer
);
-- триггер актуализации счетчика
CREATE OR REPLACE FUNCTION agg() RETURNS trigger AS $$
BEGIN
UPDATE agg SET qty = qty + 1 WHERE id = NEW.id;
RETURN NEW;
END;
$$ LANGUAGE plpgsql;
CREATE TRIGGER agg AFTER INSERT ON tbl
FOR EACH ROW
EXECUTE PROCEDURE agg();Теперь нам достаточно прочитать всего лишь одну запись из таблицы агрегатов, чтобы получить значение нужного счетчика.
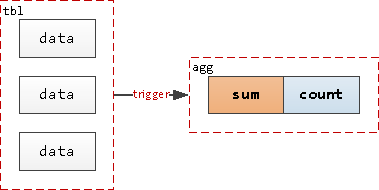
Таблица агрегатов vs MVCC
Но состояние такой записи достаточно часто меняется, поэтому из-за MVCC в этой таблице начинает постепенно накапливаться "мусор" (dead tuples), который уже ни один запрос как бы не может увидеть, но движок PostgreSQL все равно вынужден их фильтровать. Это может вызывать существенную деградацию производительности и неконтролируемый рост объема таблицы.
Подробнее про влияние MVCC на скорость работы UPDATE можно прочитать в статье "PostgreSQL Antipatterns: обновляем большую таблицу под нагрузкой".
Чтобы такой мусор вычищался, а место переиспользовалось, в PostgreSQL существует процесс autovacuum'а. Но иногда скорость изменений данных превышает дефолтные настройки, тогда стоит базе "помочь":
ALTER TABLE agg SET (
autovacuum_vacuum_threshold = 100 -- запускать при изменении хотя бы 100 записей
, autovacuum_vacuum_scale_factor = 0.01 -- запускать при изменении хотя бы 1% записей
);Эта настройка задает условия, при которых процесс очистки вообще возьмется за нашу таблицу. А с какой частотой он будет это делать, определяет параметр autovacuum_naptime, с помощью которого мы уменьшим интервал между сканированиями:
ALTER SYSTEM SET autovacuum_naptime = '1min'; -- запускать процесс проверки ежеминутноБудьте осторожны! В базах с большим количеством таблиц/секций, сама инициализация процесса autovacuum/autoanalyze и определение таблиц для обработки могут потреблять достаточно существенные ресурсы.
Дробление агрегатов
А что если изменения будут идти очень-очень часто и в несколько потоков? Такой триггер из-за блокировок при обновлении единственной "целевой" записи превратит нашу работу в "однопоточную":
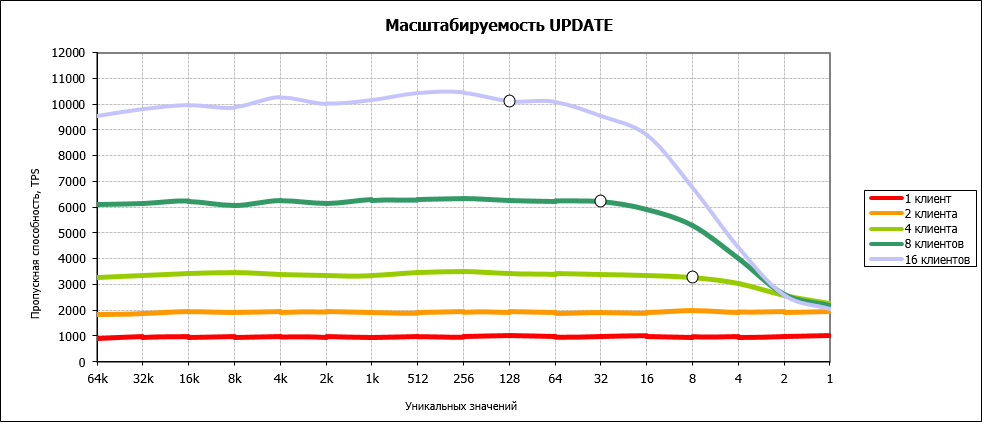
Достаточно очевидное решение - если упираемся в одну запись, давайте сделаем их несколько, а при выводе будем суммировать - все равно их будет существенно меньше, чем исходных данных.
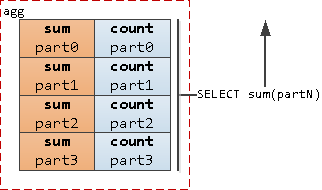
Таким образом, наши шансы наткнуться на блокировку снижаются кратно, пропорционально количеству "долек".
Таблица изменений + worker
Но и такой вариант неидеален - "раздробленные" агрегаты не дают возможность "быстро и дешево", за единственный Index Scan, получить "рейтинговые" отчеты вроде тех, которые описаны в статье "SQL HowTo: рейтинг-за-интервал".
Поэтому давайте оставим все-таки единственную запись агрегата, а все "свежее" будем писать в таблицу изменений, и периодически (по событию или таймеру) будем "набегать" на эту таблицу, массово обрабатывать и удалять все изменения, и накатывать изменения на агрегаты.
Прелесть метода - в "однопоточности". То есть агрегат обновляется только одним этим нашим процессом, и блокировкам взяться неоткуда - достаточно обеспечить единственность активного worker'а. Этого легко добиться с помощью pg_try_advisory_lock.
С различными способами использования рекомендательных блокировок можно познакомиться в статье "Фантастические advisory locks, и где они обитают".
В качестве таблицы изменений, впрочем, может выступать и сама таблица исходных данных - лишь бы был способ (индекс/признак) быстро вычленить все необработанные записи.
При всех недостатках (+2 таблицы и реализация "вне БД"), метод позволяет в любой момент актуальные значения получить из БД - то есть транзакционная целостность при нас.

Примерно так у нас в СБИС живет счетчик остатков складской карточки, расчет себестоимости и сводные сальдо и обороты.
В этом случае обрабатывающий запрос может выглядеть как-то так:
WITH del AS (
DELETE FROM
diff
RETURNING * -- возвращаем в CTE все удаляемое
)
INSERT INTO
agg
SELECT -- агрегируем данные по ID счетчика
id
, sum(qty)
, count(*)
FROM
del
GROUP BY
1
ON CONFLICT(id) -- вставляем с обновлением при конфликте
DO UPDATE SET
(sum, count) = (agg.sum + EXCLUDED.sum, agg.count + EXCLUDED.count);При этом еще необработанные записи между итерациями worker'а доступны в diff-таблице, откуда мы их можем (если хотим, конечно) прочитать и добавить к сохраненному значению агрегата.
Фактически, мы получили длинную таблицу-очередь, что чревато проблемами из-за MVCC - значит, стоит брать ее обслуживание в свои руки и применять методики, описанные в "DBA: когда пасует VACUUM — чистим таблицу вручную".
Агрегация где-то рядом
Но считать (да и хранить) агрегаты внутри PostgreSQL - может не всегда оказаться эффективно. Поэтому, если требования проекта позволяют, можно посмотреть на альтернативные варианты.
Временная агрегация в памяти процесса
Если ваш процесс относится к долгоживущим, то нет необходимости сбрасывать в БД прямо уж каждое изменение, если вы готовы насколько-то отойти от полной непротиворечивости данных агрегата в каждый момент времени. Тогда можно вести счетчики в памяти процесса, а в БД отправлять по таймеру.
Так работает в "Тензоре" коллектор нашей системы мониторинга PostgreSQL.
Поток изменений в событиях очереди
Микс из предыдущих двух вариантов. При изменении данных вы кидаете сообщение в очередь NOTIFY/PgQ/RabbitMQ/Kafka/..., а на принимающей стороне worker получает эти события "пачками", и пушит в БД.
В базе, но не в PostgreSQL
PostgreSQL "честно" соблюдает ACID. Но ведь есть множество других БД, в которых с этим делом существенно проще: Redis, Tarantool, ClickHouse, ... - выбирайте под свои задачи.
Примерно так у нас живет история загрузки (Redis) и статистика работы облака (ClickHouse).
Применяете другие техники работы с агрегатами? Расскажите в комментариях!



