
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!

Привет, Хабр!
Мы - Константин Егоров, Иван Свиридов и Николай Романенко, сотрудники Лаборатории искусственного интеллекта Сбера. В этом году наша команда участвовала в качестве экспертов и модераторов медицинской задачи соревнования AI Challenge. Церемония награждения победителей конкурса состоялась в рамках конференции AI Journey 2023.
Уже не первый год Сбер совместно с Альянсом в сфере искусственного интеллекта проводит международный конкурс для молодежи младше 18 лет, увлекающихся технологиями искусственного интеллекта. Это большой вклад в будущий кадровый потенциал и залог успешного развития всей области ИИ. Для участников это возможность оценить технические навыки в решении реальных прикладных задач, а также варианты карьерного развития.
Публикации о некоторых соревнованиях в рамках конференции «Путешествие в мире искусственного интеллекта» (AI Journey) и решениях уже выходили на Хабре, например, Digital Пётр или ЕГЭ-аттестация. Вот ещё лишь некоторые соревнования и задачи, которые предлагались участникам в прошлые годы:
FusionBrain Challenge 2.0 – соревнование по созданию единой мультизадачной мультимодальной модели (12 задач в текстовой и визуальной модальностях);
AI4Talk – соревнование по распознаванию речи на языках малых народов России;
Handwritten Text Recognition – распознавание рукописного текста на изображении;
AI4Biology – задача идентификации бактерий по результатам масс-спектрального анализа;
Code2codeTranslation – перевод с языка программирования Java на Python.
В этом году участникам также предлагалось решить задачи по различным направлениях от генерации изображений и видео до медицины и сельского хозяйства. Общий призовой фонд всех треков в рамках AI Challenge 2023 году составил 10 000 000 ₽.
Немного предыстории
Возвращаясь к конкурсу этого года. Весной 2023 организаторы AI Challenge пригласили сотрудников Лаборатории ИИ принять участие в подготовке медицинского трека. После обсуждения с коллегами мы решили предложить задачу анализа ЭКГ-сигналов на предмет выявления сердечно-сосудистых заболеваний (ССЗ). Тем более что в центре мы сами работали над проблемами в этой области, поэтому для соревнования постарались подготовить практическую задачу из списка тех, с которыми нам приходится иметь дело в своей работе.
"Когда в начале года мы получили письмо с предложением поучаствовать в организации AI Challenge 2023 в роли экспертов, то и представить не могли, что этот запрос перерастет в такой масштабный и серьезный проект!"
(с) Николай Романенко
Медицинская задача
ССЗ на сегодняшний день остаются основной причиной смертности в России, занимая долю в 44% от общей смертности по стране по данным 2022 года. Причем большинство заболевших уходят из жизни на пике своей активности – в возрасте от 25 до 64 лет, а многие из тех, кто остался жив, теряют трудоспособность. Именно поэтому диагностика и раннее выявление таких заболеваний способны кардинально сократить смертность населения и в целом повысить уровень качества жизни.
Одним из наиболее надежных способов выявления болезней сердца является подробный анализ электрокардиограмм или ЭКГ-сигналов. Однако, такая процедура является сложной задачей, требующей тщательной работы медицинских специалистов высокой квалификации. И здесь методы искусственного интеллекта способны существенно помочь врачам, избавив их от рутины и исключив человеческий фактор. Именно поэтому мы предложили участникам соревнования разработать алгоритмы автоматического анализа ЭКГ-сигналов для диагностики сердечных патологий.
ЭКГ-сигналы и искусственный интеллект
Для начала давайте немного разберёмся в методе электрокардиографии. Он заключается в представлении электрической активности сердца в виде электрокардиограммы. Первые ЭКГ-сигналы были записаны ещё в XIX веке французским физиком Габриэлем Липпманом, когда стало ясно, что сердце во время своей работы производит некоторое количество электричества. Со временем метод развивался и на данный момент является одним из ведущих способов определения сердечно-сосудистых заболеваний.
Электрокардиограмма представляет собой хронологическую последовательность разностей потенциалов между электродами, закрепленными на конечностях и груди человека. Наверное, все помнят кушетку и присоски в кабинете врача, которые надолго оставляют после себя следы. Эти разности потенциалов называются отведениями, чаще всего в диагностике используется 12 отведений – этакий золотой стандарт.
Важна также форма самой ЭКГ, которая определяется по 5 зубцам: P, Q, R, S и T. Они формируют интервалы различной формы и длины. Сигнал начинается с волны P, представляющей начало сердцебиения, за которой следует комплекс QRS, отражающий процесс удара сердца. После QRS идет волна T, символизирующая конец сердцебиения. Схематическое изображение этого процесса у отведения I нормального ЭКГ-сигнала показано ниже:
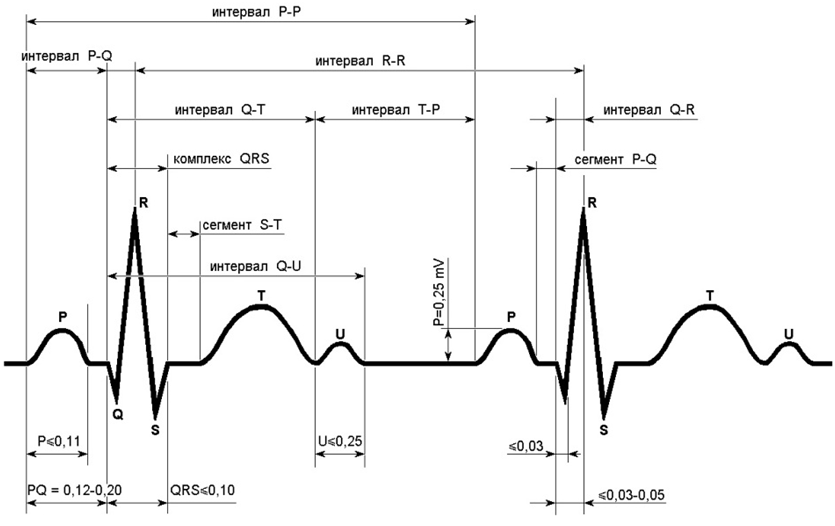
Помимо отведений, запись ЭКГ происходит с определённой частотой, которая измеряется в герцах (число измерений в секунду). В наборе данных, который мы подготовили для соревнования, частота записи равна 500 Герц (то есть, 500 измерений сигнала в секунду), по времени запись сигнала длится 10 секунд. Таким образом, каждая запись по пациенту включает 12x500x10 = 60 000 измерений.
Стоит отметить, что область анализа электрокардиограмм методами ИИ является довольно обширной и активно исследуется – на сегодняшний день опубликовано большое количество работ на тему классификации, сегментации и даже генерации ЭКГ-сигналов. Также, недавно в рамках публичного бенчмарка MedBench мы запустили задачу multi-label классификации ЭКГ-сигналов. Данные для задачи взяли из публичного датасета PTB-XL и переразметили 3 тысячи записей с помощью ведущих врачей-кардиологов (по схеме консенсуса асессоров) согласно отечественному тезаурусу сердечных патологий.
Новая разметка предполагает более качественное и полное представление о сигналах, из которых удалось выделить 73 класса, описывающих наличие возможных сердечных патологий или служебно-технических характеристик сигнала. Соревновательная задача во многом основывается на этой работе.
Итоговая постановка звучала следующим образом: построить модель определения наличия и локализации инфаркта миокарда по ЭКГ-сигналу.
Для этого из исходных 73 классов были выбраны относящиеся к целевой патологии 6 итоговых подклассов, описывающих возможную локализацию инфаркта миокарда, а именно, нижний, передне-перегородочный, перегородочный, передний, передне-боковой и боковой + класс “норма”. Итоговое распределение данных выглядело следующим образом:
Количество сигналов в обучающей выборке | Количество сигналов в открытой тестовой выборке | Количество сигналов в закрытой тестовой выборке | |
Норма | 1686 | 362 | 362 |
Нижний | 218 | 46 | 46 |
Передне-перегородочный | 119 | 22 | 27 |
Перегородочный | 58 | 13 | 8 |
Передний | 55 | 10 | 12 |
Передне-боковой | 26 | 7 | 7 |
Боковой | 2 | 3 | 2 |
Механика соревнования
Как говорили раньше, соревнование проходило в три этапа: квалификационный, командный и финальный.
На квалификационном этапе претенденты должны были решить индивидуальные задачи и получить набольшее количество баллов для прохождения в следующий. Все участники могли принять участие в буткемпах, пройти тестирование, чтобы определить наиболее подходящее направление.
Во втором, командном этапе, участники обмениваются опытом и совместно выполняют задания по использованию ИИ в одном из пяти направлений конкурса: медицине, креативных индустриях, эффективном производстве, анализе изображения и видео, сельском хозяйстве. По направлению «Медицина» участники решали задачу бинарной классификации – определение наличия на ЭКГ-сигнале пациента критического состояния. Для этого все метки, относящиеся к 6 классам с инфарктом, были использованы как положительный класс, а норму – как отрицательный. У участников был открытый лидерборд, на котором они могли оценить свои решения во время этапа и получить баллы в зависимости от позиции в нем. Итогом этапа была презентация/защита решений команд и отправка кода на проверку. Мы валидировали код решений участников на воспроизводимость результатов и запускали на закрытой тестовой части. В этом этапе участвовало 14 команд, 10 из которых были отобраны в финал.
Метрика, на основе которой решения участников сравнивались на лидербордах, была F1-мера. Она считается по формуле:

где 
Эта метрика позволяет оценить качество модели на датасетах с дисбалансом классов, сравнивая количество верно классифицированных объектов (TP или True Positives), ложноположительных (FP или False Positives) и ложноотрицательных (FN или False Negatives).
В финальном этапе команды должны были решить более сложную задачу multi-label классификации, а именно предсказать наличие или отсутствие всех 7 классов. По итогу также проверялся код, использовался закрытый тест и была защита решения. Кроме этого участникам предлагалась возможность реализовать API, демонстрирующий итоговое решение команды, например, в виде телеграм-бота или веб-сервиса. За это начислялись бонусные баллы. По итогам этапа выбиралось три команды-победителя.
В течение всего соревнования было проведено 4 раунда встреч с участниками: welcome-вебинар на старте, в котором рассказали о актуальности задачи; по ходу решения провели две полноценные консультации с командами, на которых слушали идеи ребят и давали технические оценки и советы; а также финальную защиту решений в конце соревнования.
Решения участников
Мы попросили команд-победителей, занявших первые три места, немного рассказать о своих подходах в решении задачи финального этапа.
Команда DarkLEDshipping (3 место)
, Максим Кузнецов (Москва)")
Модель
Изначально мы решили попробовать подойти к задаче тривиально: аугментировать выборку, нормализовать данные, лейблы оставить в виде one hot encoding. В качестве архитектуры взяли кастомную модель в виде объединения трансформерных и сверточных блоков, а в качестве лосса использовали бинарную кросс-энтропию. Выходы этой модели конкатенировали и подавали в полносвязный слой, который возвращал вероятность принадлежности ЭКГ-сигнала к тому или иному классу. На вход же подавали отрезки сигнала по 800 измерений с шагом 100, для каждой записи вероятность со всех отрезков ЭКГ усредняли.
Выбор методов и гиперпараметров
Мы перепробовали разные методы нормализации, learning rate schedulers, различные оптимизаторы и их гиперпараметры, а также вместо one hot encoding пробовали использовать label encoding. Также, мы попробовали использовать добавление случайного шума к модели. Изначально получили лучший результат такой модели  = 0.38, оставив one hot encoding.
= 0.38, оставив one hot encoding.
Итоговое решение
После этого мы решили немного упростить задачу для модели и разделили решение проблемы на два этапа:
1) Определение, есть ли инфаркт – бинарная классификация;
2) Классификация локализации инфаркта в зависимости от выходов первой модели.
Для моделей обоих этапов взяли предыдущую архитектуру, у бинарной модели оставили один нейрон на выходе, а у второй модели – шесть нейронов на выходе. Каждая модель обучалась отдельно друг от друга; 90% данных использовалось для обучения, остальное для валидации. Для обеих моделей мы искали лучший трешхолд перебором, основываясь на валидационной выборке и максимизации метрики  . После того, как нашли лучшее количество эпох и трешхолд, обучали обе модели уже на полном объёме данных. Для первой модели удалось получить
. После того, как нашли лучшее количество эпох и трешхолд, обучали обе модели уже на полном объёме данных. Для первой модели удалось получить  = 0.72, для второй
= 0.72, для второй  = 0.54.
= 0.54.
Так как задача сложнее, чем бинарная классификация, то для того, чтобы добиться хороших результатов, мы решили делить данные на отрезки по 700 измерений с шагом 50, таким образом, мы получили большее количество отрезков, а, значит, ещё больше данных!
Преимущества нашего подхода:
Простота архитектуры нейросети;
Очень быстрый инференс (время порядка 5 секунд на всю тестовую выборку);
Возможность предсказывать результаты для последовательностей ЭКГ любой длины;
Возможность получать как метки классов, так и вероятностные оценки;
Многозадачность.
Потенциальные улучшения:
Обучение нескольких моделей для каждой локализации внутри записи сигнала;
Использование различных отведений из ЭКГ для анализа каждой локализации;
Использование разреженной последовательности целиком, чтобы модель лучше "понимала" полную структуру записи;
Балансировка сэмплов или их дополнительная генерация;
Использование более продвинутых способов подбора трешхолда.
Ссылка на решение
Команда ALT_F4 (2 место)
, Данис Динмухаметов (Москва), Кристиан Богдан (Москва), Ян Густов (Калининград)")
Обработка данных
Датасет, который нам предоставили, содержал в себе 2101 наблюдение для 7 классов, что само по себе довольно немного, к этому прибавился ещё очень сильный дисбаланс в данных. Некоторые классы составляли менее 1% от общего числа наблюдений, а класс "норма" занимал 80% выборки!
Одна из самых основных особенностей данных ЭКГ состоит в том, что практически каждая точка данных содержит в себе информацию, и некорректная аугментация может привести к искажению данных. Нам изначально стало понятно, что датасет придется расширять, и для начала мы решили попробовать достать информацию, не изменяя наблюдения. Спустя время мы пришли к очень интересному подходу, описанному в этой статье.
Подход заключается в захвате QRS комплекса засчет выделения R-пиков. Таким образом, с каждой записи мы смогли получить в среднем по 10 примеров QRS для каждого класса. Так нам удалось повысить количество наблюдений в каждом классе минимум до 200 элементов. Затем, на основе новых данных, представлявших собой набор QRS комплексов (массивов 12 отведений на 600 точек), был применён алгоритм генерации синтетических данных SMOTE. Коротко суть этого алгоритма заключается в том, что берется случайное наблюдение одного класса и происходит поиск максимально похожего элемента к этому наблюдению, а новое наблюдение генерируется как среднее между выбранными двумя элементами. Важно понимать, что для генерации синтетических данных необходимо очистить уже имеющиеся данные от шума и так называемых "блужданий базовой линии”, для этого мы использовали медианный фильтр и фильтр Савицкого-Голея.
Архитектуры
Результатом процессинга данных стали двумерные массивы. С ними удобнее всего работать при помощи сверточных нейронных сетей (Convolutional Neural Network, CNN), применяемых для анализа изображений. Но такие данные не являются полноценными картинками, следовательно, нужно как-то модифицировать привычные CNN-архитектуры. Поэтому мы использовали блоки внимания к входным каналам (SE блоки). Этот вид сверточных блоков работает "в глубину", назначает веса именно каналам входного изображения, а в случае ЭКГ-сигналов большую роль играют именно каналы (отведения). В экспериментах мы сравнивали различные предобученные модели с блоками внимания (SENet, SEResNet и т.п.), но лучше всего себя показала архитектура ECGNet, ее и взяли за основу.
Обучение
Даже после применения методов аугментации, описанных выше, в данных сохранялся дисбаланс среди большинства классов, на нормальный класс приходилось более 18 тыс. наблюдений (QRS), тогда как на аугментированные классы количество примеров не превышало 7 тысяч, а в одном из них и вовсе было менее 1500. Обучать модель на такой несбалансированной выборке было не совсем корректно (модель хорошо запомнит доминирующий класс и везде будет видеть только его). Размножать примеры записей мелких классов тоже не стоит, поскольку можно потерять информативность и получить множество похожих элементов, но и отбрасывать некоторые примеры крупного класса не хотелось. В такой ситуации к нам на помощь пришла достаточно интересная функция ошибки: FocalLoss, которая имеет вид:

где  уверенность модели в
уверенность модели в  - м истинном классе, а
- м истинном классе, а  - гиперпараметр, отвечающий же величину штрафа модели при неуверенности в истинном классе.
- гиперпараметр, отвечающий же величину штрафа модели при неуверенности в истинном классе.
Как видно из формулы, она очень похожа на стандартную кросс-энтропию, но её "магия" заключается в новом множителе с параметром гамма, за счет него функция ориентируется на те примеры, которые модель плохо классифицирует. Иными словами, модель обращает внимание на "плохие" наблюдения и концентрируется на них. Следовательно, можно обучаться на данных, в которых есть дисбаланс, с помощью коэффициента лямбда компенсируя его и "подталкивая" модель в сторону нужных (трудных) классов.
Итоговый вариант
В результате наше решение представляло собой ансамбль из 5 легковесных архитектур, три из них ECGNet и два SEResNet. Из каждой входной записи выделялись QRS комплексы, каждый из которых классифицировался отдельно каждой из сетей, результаты усредняются. Далее формируется список предсказанных значений для QRS, а итоговое предсказание получается, как мода таких значений.
Ссылка на решение
Команда minions (1 место)
, Максим Чусовлянов (Санкт-Петербург), Валерий Токарев (Владивосток), Антон Епифанов (Владивосток)")
Мы изначально догадывались, что придется использовать стекинг, так как нужно было объединить данные об ЭКГ-сигнале и метаданные. В планах было создать нейронную сеть, которая бы классифицировала локализацию инфаркта по ЭКГ сигналу, и использовать её результат в градиентном бустинге вместе с метаданными записи.
Первая попытка – первая неудача
Сначала мы попробовали работать не с полными сигналами, а только с определенными сегментами. Сегмент ЭКГ-сигнала – один из R-R промежутков. Мы “нарезали” каждый сигнал и брали статистические функции от таких фрагментов для каждого отведения (mean, max, min, quantiles, и т.д.). По итогу получили двухмерный массив размерностью [длина одного сегмента, 12 количество признаков]. В качестве модели взяли нейронную сеть – двумерную свертку для обработки таких входных данных. Однако, результаты такого подхода были очень плохими.
количество признаков]. В качестве модели взяли нейронную сеть – двумерную свертку для обработки таких входных данных. Однако, результаты такого подхода были очень плохими.
Вторая попытка
В другом подходе мы использовали цельный ЭКГ-сигнал. Также строили сверточную нейронную сеть, но уже на цельных сигналах. Основная фишка заключалась в том, что мы делали мультилейбл-классификацию при помощи стратегии One Vs Rest, но немного оптимизированной под нашу задачу. Всего это решение включало 7 нейронных сетей: одна отличала нормальный сигнал от сигнала с какими-либо признаками инфаркта, а другие 6 отличали одну из локализаций инфаркта от других. Сетей локализации инфаркта было именно 6, а не 7, так как мы не строили классификатор на боковом инфаркте (для этого класса в обучающей выборке было всего 2 примера).
Вторая фишка заключалась в том, что разные сетки мы обучали на разных отведениях (не на всех 12, а на определенных подмножествах). Отведения выбирали исходя из того, какие из них используют врачи, для определения типов инфаркта (статья). Это позволяло нейронкам быстрее обучаться.
Тестирование ML методов и техник
1. Синтетические данные с помощью DCGAN. Мы пробовали генерировать и сегмент сигнала, и целый сигнал, все это не получилось… Считаем, что так произошло из-за нехватки данных;
2. Аугментация. Тестировали несколько различных методов аугментации и их комбинации, что-то дало прирост к метрикам, а что-то нет;
3. MixUp. Очень интересная техника, которая заключается в смешивании двух экземпляров, а также смешивании их лейблов в одинаковых пропорциях. Протестировали такой подход на сегментах и целых сигналах, но увидели две проблемы: чтобы это делать на исходном сигнале, требуется как минимум совпадение R-пиков. Если рассматривать отдельные сегменты, тоже получается не всегда хорошо. При смешивании двух сегментов с признаками инфаркта они могут “съесть” друг друга и выдать сигнал, который напоминает нормальный или сигнал с признаками другого вида инфаркта.
4. Новые признаки. С помощью библиотеки neurokit2 мы создали несколько числовых признаков на основе длины R-R интервалов сигнала. Использовали функции: ecg_rate, hrv_time, hrv_frequancy, entropy_sample.
Итоговое решение
В итоговом решении использовали нейронные сети из семейста полносвязных, сверточных и сетей со skip-connection, в частности, SeResNet. Каждый сигнал сначала предобрабатывали (обрезали по бокам, применяли медианный фильтр), прогоняли по всем сеткам и из каждой сетки брали результаты из предпоследнего линейного слоя. Затем вытаскивали числовые признаки из сигнала. Все эти данные использовали в CatBoostClassifier, также по стратегии One Vs Rest, в результате чего получали финальные предсказания.
Стоит упомянуть, что мы на каждый класс обучали несколько алгоритмов бустинга, так как в каждом из них брали разные подмножества признаков из предпоследних слоев сверточных сетей, чтобы бороться с переобучением. Например, в одном из вариантов бустинга брали лишь каждый третий признак из предпоследнего слоя нейросети. Такой способ имел неоспоримые преимущества, в итоговом лидерборде нам удалось получить лучшую метрику, так как наше решение с высокой точностью предсказывало класс бокового инфаркта.
Ссылка на решение
Подводя итоги
После защиты решений, конечный рейтинг был сформирован следующим образом:

По нашему мнению, все участники достойно выступили, показав хороший уровень владения современными методами машинного обучения для обработки и классификации сигналов. А по вышеописанным решениям можно сделать однозначный вывод о том, что победившие команды по своему уровню приближаются к уровню студентов топовых ВУЗов страны. Многие участники детально погрузились в решаемую задачу, самостоятельно проанализировали формы и вид ЭКГ-сигналов, выделили статистические и визуальные различия между классами сигналов, как это делают на практике врачи-кардиологи.
Вообще, одна из ключевых задач публичных ML соревнований – быстрая проверка широкого набора гипотез, поиск новых идей и направлений исследований. Мы рады, что так получилось и в нашем соревновании. Например, команда «pears», которая заняла 8 место в финальном этапе, использовала в своем решении оригинальный метод кодировки ЭКГ сигнала "по Успенскому", основанный на подходе описанном в монографии Успенского В.М. "Информационная функция сердца". Этот подход кажется нам крайне интересным и перспективным, вне всякого сомнения, проверим эту идею в дальнейших экспериментах.
 ;)")
В заключение хотим ещё раз поблагодарить всех участников и организаторов конкурса AI Challenge! Настолько крутое мероприятие было бы невозможно без ваших усилий и вовлечённости!А также надеемся, что в следующем году проведём ещё более амбициозное соревнование на стыке искусственного интеллекта и медицины!




