
Алгоритм нечеткого поиска TextRadar — основные подходы
В отличие от нечеткого сравнения строк, когда обе сравниваемых строки равнозначны, в задаче нечеткого поиска выделяются строка поиска и строка данных, а определить необходимо не степень похожести двух строк, а степень присутствия строки поиска в строке данных.
Постановка задачи
Даны строка данных и строка поиска как произвольные наборы символов, состоящих из слов – групп символов, разделенных пробелами.
Требуется найти в строке данных наиболее близкий к строке поиска по составу и взаимному расположения символов набор фрагментов.
Для оценки качества результата поиска вычислить коэффициент, значение которого должно лежать в диапазоне от 0 до 1, где 0 должен соответствовать полному отсутствию символов строки поиска в строке данных, а 1 – наличию строки поиска в строке данных в неискаженном виде.
Поиск должен осуществляться путем посимвольного анализа исходных строк, с учетом взаимного расположения символов и слов в строках, но без учета синтаксиса и морфологии языка.
Описание алгоритма
Поиск осуществляется в несколько этапов.
Построение матрицы совпадений
Матрица совпадений (M) представляет собой двумерную матрицу, количество столбцов которой соответствует длине строки данных, а количество строк – длине строки поиска. Элементы матрицы совпадений принимают значения 0 или 1 в зависимости от того, совпадают или нет соответствующие символы строк за исключением пробелов (разделителей слов).
Матрица совпадений для строки данных «ABCD EF» и строки поиска «ABC» имеет вид:
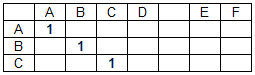
Элемент матрицы совпадений m(i, j) = 1, если d(i) = s(j), где D – массив символов строки данных, S – массив символов строки поиска, i – номер столбца матрицы совпадений M (номер символа строки данных), j – номер строки матрицы совпадений (номер символа в строке поиска). В остальных случаях m(i,j) = 0. Совпадения разделителей слов (в нашем случае это пробелы) не учитывается, то есть: m(i,j) = 0, если d(i) = s(j) = ‘ ‘.
Диагонали матрицы совпадений
Элементы матрицы совпадений M образуют диагонали. Элементы матрицы находятся на одной диагонали, если их индексы i и j одновременно различаются на +1 или на – 1.

Диагонали соответствуют положениям строки поиска в последовательности сдвигов вдоль строки данных.

Элементы одной из диагоналей и соответствующий ей сдвиг на рисунке выше выделены синим.
Идея использования последовательности сдвигов строк друг относительно друга в задаче нечеткого поиска восходит к хорошо известной методике обнаружения радиолокационных сигналов на фоне помех, которая предполагает вычисление взаимной корреляционной функции радиосигналов. Взаимнокорреляционная функция определяет степень схожести копий двух различных сигналов v(t) и u(t), сдвинутых на время τ друг относительно друга и определяется как интеграл:
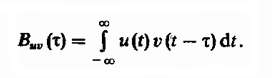
Общее количество диагоналей рассчитывается по формуле:

Длины диагоналей равны длине строки поиска.
Группы совпадений
Единицы, следующие подряд в диагоналях матрицы совпадений, образуют группы совпадений. Ниже представлены группы совпадений для строки данных «ABCD DEF JH» и строки поиска «ABC DE J» — 4 группы, находящиеся на разных диагоналях.

Матрицы проекций
Диагонали матрицы совпадений и содержащиеся в них группы совпадений отображаются на соответствующие участки строки поиска и строки данных, образуя две матрицы проекций – на строку поиска и на строку данных соответственно. Для нашего примера матрицы проекций будут выглядеть следующим образом:
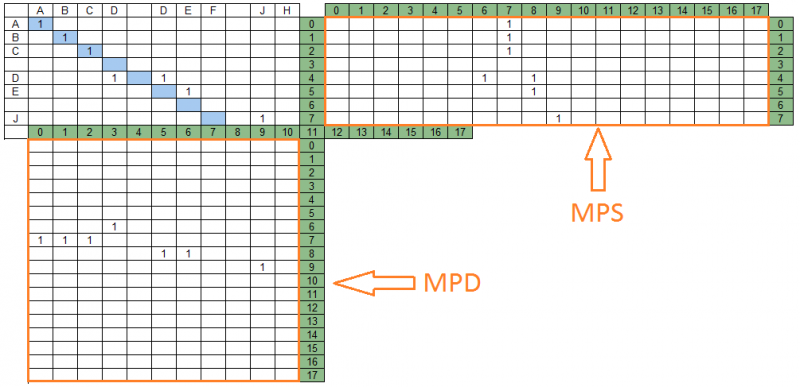
На приведенном рисунке, справа от матрицы совпадений находится матрица проекций на строку поиска — MPS, снизу – матрица проекций на строку данных MPD. Количество столбцов MPS равно количеству строк MPD и равно числу диагоналей матрицы совпадений – в нашем примере их 18.
Поиск результирующего набора групп
Для решения задачи необходимо найти такой набор групп, который наиболее полно «накроет» строку поиска, при этом наименее фрагментировано (максимально крупными частями), без взаимных пересечений в матрицах проекций и отображение которого на строку данных будет наиболее близко к «оригиналу» — строке поиска.
Пересечение групп в матрице проекций
В нашем примере есть группы, пересекающиеся в матрице MPS – на рисунке ниже они выделены красным. При этом в матрице MPD эти же группы не пересекаются, на рисунке они выделены зеленым.
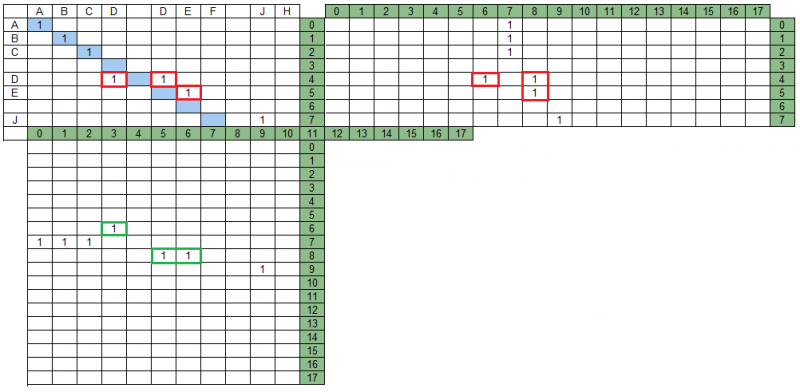
Поиск результирующего набора групп подразумевает, что в него войдут не все группы и что часть из оставшихся групп может быть модифицирована (усечена) при анализе взаимных пересечений групп в проекциях.
Поиск результирующего набора может быть осуществлен путем обхода в «бесконечном» цикле (количество итераций цикла не превысит количества групп) таблицы всех групп, в которую изначально помещаются группы матрицы совпадений, на каждой итерации которого будут осуществляться следующие действия:
- Выбор наилучшей по определенным (зависящим от контекста решаемой задачи) параметрам — в самом простом случае это может быть выбор первой попавшейся группы наибольшего размера;
- Помещение лучшей группы в таблицу групп результата и удаление ее из таблицы всех групп (обход строк которой производится);
- Удаление (или усечение) из таблицы групп пересекающихся с выбранной наилучшей группой в матрицах проекций групп.
Оптимальный набор групп для нашего примера представлен на рисунке ниже — группы набора выделены оранжевым.

Удаленная в процессе обработки пересечений (пересекающаяся в матрице MPS с наилучшей группой второй итерации) группа выделена красным.
Результат поиска в строке данных будет выглядеть так:

Вычисление коэффициента
Для количественной оценки результатов поиска сопоставляются длины найденных групп с длинами слов строки поиска (оценка состава групп), а также общая длина строки поиска с протяженностью найденных групп в строке данных. При этом предполагается, что значимость оценки состава найденных групп выше значимости оценки протяженности в строке данных, что учтено в весовых коэффициентах формулы расчета итогового коэффициента:

Где коэффициент состава групп рассчитывается как отношение суммы квадратов длин найденных групп к сумме квадратов длин слов строки поиска:

Коэффициент протяженности – как отношение длины строки поиска к общей протяженности найденных групп на строке данных. В случае, если полученное таким образом значение больше 1, берется его обратная величина:

Для нашего примера:

Оценка объема вычислений
Наиболее ресурсоемкими являются операции:
- определение матрицы совпадений M — количество элементов матрицы определяется как произведение длины строки поиска на длину строки данных: Lп * Lд;
- определение матриц проекций на строки данных и поиска — количество элементов матриц составит для MPS: (Lп + Lд – 1) * Lп, для MPD: (Lп + Lд – 1) * Lд;
- формирование таблицы всех групп — количество групп не превысит величины Lп * Lд / 2;
- поиск результирующего набора групп — количество итераций цикла не превысит исходного количества групп, то есть Lп * Lд / 2.
Таким образом, общий объем вычислений будет кратен произведению длины строки поиска на длину строки данных:

Линейность объема вычислений относительно размера исходных данных является важным аргументом в пользу практического применения алгоритма.
Нелинейность
Стоит отметить, что линейность обусловлена упрощенной процедурой поиска результирующего набора групп. В общем случае, если рассматривать все возможные варианты размещений групп на строке данных с учетом возможных вариантов обработки пересечений и осуществлять выбор наилучшего набора групп из множества возможных, а не выбор одной группы на каждой итерации цикла, то объем вычислений перестанет быть линейным по отношению к размеру исходных данных. Нелинейная зависимость объема вычислений от размера исходных данных сильно ограничивает возможности практического применения.
Находим баланс
Для обеспечения оптимального баланса между качеством поиска и потребностью в ресурсах, важно правильно выбрать методику поиска результирующего набора групп, что как правило удается сделать, используя особенности контекста решаемой задачи.
На сайте textradar.ru развернут демо-стенд, на котором можно протестировать работу алгоритма.




