
Добрый день, хочу поделиться с вами своим опытом по настройке и использованию сервиса AWS EKS (Elastic Kubernetes Service) для Windows контейнеров, а точнее о невозможности его использования, и найденном баге в системном контейнере AWS, тем кому интересен этот сервис для Windows контейнеров, просьба под кат.
Знаю что windows контейнеры не популярная тема, и мало кто пользуется ими, но все же решил написать эту статью, так как на Хабре было пару статей по kubernetes и windows и такие люди все-таки есть.
Начало
Все началось с того что сервисы в нашей компании решено было мигрировать в kubernetes, это 70% windows и 30% linux. Для этого как один из возможных вариантов рассматривался облачный сервис AWS EKS. До 8 октября 2019 AWS EKS Windows был в Public Preview, я начал с него, версия kubernetes там использовалась старая 1.11, но я решил проверить его все равно и посмотреть на каком этапе данный облачный сервис, работоспособен ли вообще, как оказалось нет, там был баг с добавлением удалением подов, при этом старые переставали откликаться по внутреннему ip с той же подсети где и windows worker node.
Поэтому было принято решение отказаться от использования AWS EKS в пользу собсвтенного кластера на kubernetes на тех же EC2, только всю балансировку и HA пришлось бы описывать самому через CloudFormation.
Amazon EKS Windows Container Support now Generally Available
by Martin Beeby | on 08 OCT 2019
Не успел я дописать template в CloudFormation для собственного кластера, как увидел эту новость Amazon EKS Windows Container Support now Generally Available
Я конечно же отложил все свои наработки, и принялся изучать что они сделали для GA, и как все изменилось с Public Preview. Да AWS молодцы обновили образы для windows worker node до версии 1.14 а так же сам кластер версии 1.14 в EKS теперь с поддержкой windows nodes. Проект по Public Preview на гитхабе они прикрыли и сказали пользуйтесь теперь официальной документацией вот тут: EKS Windows Support
Интеграция кластера EKS в текущий VPC и подсети
Во всех источниках, в ссылке выше по анонсу а так же в документации, предлагалось деплоить кластер буть то через фирменную утилиту eksctl или через CloudFormation + kubectl после, только с использованием public подсетей в Амазоне, а так же с созданием отдельного VPC под новый кластер.
Такой вариант подходит не многим, во-первых отдельный VPC это дополнительные затраты на его стоимость + пиринг трафик до вашего текущего VPC. Что делать тем у кого уже есть готовая инфраструктура в AWS со своими Multiple AWS accounts,VPC,subnets,route tables,transit gateway и так далее? Конечно же не хочется все это ломать или переделывать, и надо интегрировать новый кластер EKS в текущую сетевую инфраструктуру, используя имеющийся VPC ну и для разделения максимум создать новые подсети для кластера.
В моем случае и был выбран этот путь, я использовал имеющийся VPC добавил только по 2 public подсети и по 2 private подсети для нового кластера, конечно же все правила были учтены согласно документации Create your Amazon EKS Cluster VPC.
Так же было одно условие ни каких worker node в public subnets с использованием EIP.
eksctl vs CloudFormation
Оговорюсь сразу что я пробовал оба метода деплоя кластера, в обоих случаях была картина одинаковая.
Покажу пример лишь с использованием eksctl так как код, тут короче получится. При помощи eksctl кластер деплоить в 3 шага:
1.Создаем сам кластер + Linux worker node на котором позже разместятся системные контейнеры и тот самый злополучный vpc-controller.
eksctl create cluster \
--name yyy \
--region www \
--version 1.14 \
--vpc-private-subnets=subnet-xxxxx,subnet-xxxxx \
--vpc-public-subnets=subnet-xxxxx,subnet-xxxxx \
--asg-access \
--nodegroup-name linux-workers \
--node-type t3.small \
--node-volume-size 20 \
--ssh-public-key wwwwwwww \
--nodes 1 \
--nodes-min 1 \
--nodes-max 2 \
--node-ami auto \
--node-private-networkingДля того чтобы деплоиться к существующий VPC достаточно указать id ваших подсетей, и eksctl сам определит VPC.
Чтобы ваши worker node деплоились только в private подсеть, нужно указать --node-private-networking для nodegroup.
2. Устанавливаем vpc-controller в наш кластер, который будет потом обрабатывать наши worker nodes считая кол-во свободных ip адресов, а так же кол-во ENI на инстансе, добавляя и удаляя их.
eksctl utils install-vpc-controllers --name yyy --approve3.После того как ваши системные контейнеры успешно запустились на вашей linux worker node в том числе vpc-controller, осталось только создать еще одну nodegroup с windows workers.
eksctl create nodegroup \
--region www \
--cluster yyy \
--version 1.14 \
--name windows-workers \
--node-type t3.small \
--ssh-public-key wwwwwwwwww \
--nodes 1 \
--nodes-min 1 \
--nodes-max 2 \
--node-ami-family WindowsServer2019CoreContainer \
--node-ami ami-0573336fc96252d05 \
--node-private-networkingПосле того как ваша нода успешно зацепилась к вашему кластеру и все вроде бы хорошо она в статусе Ready, но нет.
Ошибка в vpc-controller
Если попытаться запустить pods на windows worker node то мы получим ошибку:
NetworkPlugin cni failed to teardown pod "windows-server-iis-7dcfc7c79b-4z4v7_default" network: failed to parse Kubernetes args: pod does not have label vpc.amazonaws.com/PrivateIPv4Address]Если смотреть глубже то мы видим что наш инстанс в AWS выглядит вот так:

А должен быть так:

Из этого понятно что vpc-controller не отработал свою часть по какой то причине и не смог добавить новых ip-адресов на инстанс, чтобы их могли использовать pod-ы.
Лезем смотреть логи pod-а vpc-controller и вот что мы видим:
kubectl log <vpc-controller-deployment> -n kube-system
I1011 06:32:03.910140 1 watcher.go:178] Node watcher processing node ip-10-xxx.ap-xxx.compute.internal.
I1011 06:32:03.910162 1 manager.go:109] Node manager adding node ip-10-xxx.ap-xxx.compute.internal with instanceID i-088xxxxx.
I1011 06:32:03.915238 1 watcher.go:238] Node watcher processing update on node ip-10-xxx.ap-xxx.compute.internal.
E1011 06:32:08.200423 1 manager.go:126] Node manager failed to get resource vpc.amazonaws.com/CIDRBlock pool on node ip-10-xxx.ap-xxx.compute.internal: failed to find the route table for subnet subnet-0xxxx
E1011 06:32:08.201211 1 watcher.go:183] Node watcher failed to add node ip-10-xxx.ap-xxx.compute.internal: failed to find the route table for subnet subnet-0xxx
I1011 06:32:08.201229 1 watcher.go:259] Node watcher adding key ip-10-xxx.ap-xxx.compute.internal (0): failed to find the route table for subnet subnet-0xxxx
I1011 06:32:08.201302 1 manager.go:173] Node manager updating node ip-10-xxx.ap-xxx.compute.internal.
E1011 06:32:08.201313 1 watcher.go:242] Node watcher failed to update node ip-10-xxx.ap-xxx.compute.internal: node manager: failed to find node ip-10-xxx.ap-xxx.compute.internal.Поиски в гугле ни к чему не привели, так как такой баг видимо ни кто не словил еще, ну или не запостил issue по нему, пришлось думать сначала варианты самому. Первое что пришло в голову так это возможно vpc-controller не может отрезолвить ip-10-xxx.ap-xxx.compute.internal и достучаться до него и поэтому ошибки валятся.
Да, действительно у нас используются кастомные dns сервера в VPC и амазоновские мы в принципе не используем поэтому даже forwarding не был настроен на этот домен ap-xxx.compute.internal. Я проверил этот вариант, и он не принес результатов, возможно тест был не чистым, и поэтому далее при общении с техподдержкой я поддался на их идею.
Так как идей особо не было, все security group создавались самим eksctl поэтому верить в их исправность не было сомнения, таблицы маршрутов тоже были правильными, nat, dns, доступ в интернет с worker nodes тоже был.
При этом если задеплоить worker node в public подсеть без использования --node-private-networking, эта нода тут же обновлялась vpc-controller-ом и все работало как часы.
Вариантов было два:
- Забить и подождать пока кто то опишет баг этот в AWS и они его исправят и потом можно спокойно пользоваться AWS EKS Windows, ведь они только зарелизились в GA(прошло 8 дней на момент написания статьи), наверняка многие пойдут по тому же пути что и я.
- Написать в AWS Support и изложить им суть проблемы со всей пачкой логов отовсюду и доказать им что их сервис не работает при использовании своего VPC и подсетей, не зря у нас была Business поддержка, надо же ее хоть раз использовать :-)
Общение с инженерами AWS
Создав тикет, на портале, я по ошибке выбрал ответить мне через Web — email or support center, через этот вариант они могут вам ответить спустя несколько дней вообще, при том что мой тикет имел Severity — System impaired, что подразумевало ответ в течении <12 часов, а так как у Business support plan 24/7 поддержка, то я надеялся на лучшее, но получилось как всегда.
Мой тикет провалялся в Unassigned с пятницы до пн, потом я решил написать им еще раз и выбрал вариант ответа Chat. Недолго прождав ко мне назначился Harshad Madhav, и тут началось…
Мы дебажили с ним в режиме онлайн часа 3 подряд, передача логов, деплой такого же кластера в лаборатории AWS для эмуляции проблемы, пересоздание кластера с моей стороны и так далее, единственно к чему мы пришли это то что по логам было видно что не работает резол внутренних доменных имен AWS о чем я писал выше, и Harshad Madhav попросил меня создать forwarding якобы мы используем кастомный днс и это может быть проблемой.
Forwarding
ap-xxx.compute.internal -> 10.x.x.2 (VPC CIDRBlock)
amazonaws.com -> 10.x.x.2 (VPC CIDRBlock)Что и было сделано, день кончился Harshad Madhav отписался что проверь и должно работать, но нет, резолв ни чем не помог.
Далее было общение еще с 2 инженерами один просто отвалился от чата, видимо испугался сложного кейса, второй потратил мой день на опять полный цикл дебага, пересылку логов, создание кластеров с обоих сторон, в итоге он просто сказал ну у меня работает, вот я по официальной документации все делаю пошагово сделай и ты и у тебя все получится.
На что я вежливо попросил его уйти, и назначить на мой тикет другого, если ты не знаешь где искать проблему.
Финал
На третий день, ко мне назначился новый инженер Arun B., и с самого начала общения с ним было сразу понятно что это не 3 предыдущих инженера. Он прочитал всю history сразу попросил собрать логи его самописным скриптом на ps1 который лежал у него на гитхабе. Далее последовало опять все итерации создания кластеров, вывода результатов команд, собирание логов, но Arun B. двигался в правильном направлении судя по задаваемым вопросам мне.
Когда мы дошли до того чтобы включить -stderrthreshold=debug в ихнем vpc-controller, и что произошло дальше? он конечно же не работает) pod просто не запускается с такой опцией, работает только -stderrthreshold=info.
На этом мы закончили и Arun B. сказал что будет пытаться воспроизводить мои шаги чтобы получить такую же ошибку. На следующий день я получаю ответ от Arun B. он не бросил этот кейс, а взялся за review code ихнего vpc-controller и нашел таки место где оно и почему не работает:
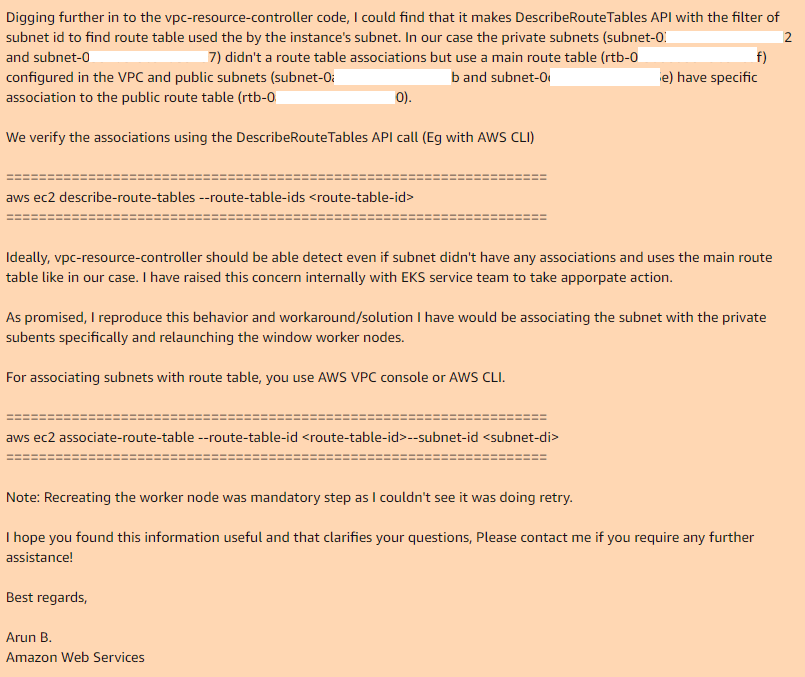
Таким образом если вы используете main route table в вашем VPC, то по дефолту у него нет ассоциаций с нужными подсетями, так необходимые vpc-controller-у, в случае с public подсетью, у нее кастомная route table которая имеет ассоциацию.
Добавив вручную ассоциации для main route table с нужными подсетями, и пересоздав nodegroup все работает идеально.
Я надеюсь что Arun B. действительно сообщит об этом баге разработчикам EKS и мы увидим новую версию vpc-controller-а где будет работать все из коробки. На данный момент последняя версия: 602401143452.dkr.ecr.ap-southeast-1.amazonaws.com/eks/vpc-resource-controller:0.2.1
имеет эту проблему.
Спасибо всем кто дочитал до конца, тестируйте все что собираетесь использовать в production, перед внедрением.

 Безопасный дайджест: новые мегаутечки и один пароль на всех")


