
В статье будет рассмотрено решение задачи анализа открытых метеорологических данных сервиса meteo.ru Федеральной службы по гидрометеорологии и мониторингу окружающей среды. Анализ будет произведен в Jupyter Notebook при помощи Python библиотеки Pandas, а также будут сделаны выводы относительно того какие изменения произошли в климате за последние 50 лет в нашей стране. Вы узнаете еще одну страшную правду о глобальном потеплении…
Примечание
Для того чтобы на практике повторить все нижеуказанные действия и действительно убедиться в справедливости сделанных в статье выводов вам потребуется знание математической статистики, а также элементарное умение установки и использования Python, Jupyter Notebook. Все остальное будет показано и рассказано в данной статье.
Введение
Мы начнем с того, что в нашей стране есть замечательная Федеральная служба по гидрометеорологии и мониторингу окружающей среды (Гидрометцентр), которая собирает и анализирует данные, а также формирует прогнозы погоды и состояния климата на территории всей нашей страны. Подробнее об этой службе вы можете узнать на официальном сайте: https://meteoinfo.ru/about.
В рамках нашей задачи нас интересует возможность использования данных, которые эта служба предоставляет в открытый доступ. А именно информация по всем метеорологическим станциям нашей страны, на которых производятся постоянные измерения параметров атмосферы, в первую очередь такие важные климатические параметры как давление, атмосферные осадки и температура атмосферы.
Эти данные мы можем получить с сайта Всероссийского научно-исследовательского института гидрометеорологической информации, входящего в состав Гидрометцентра по данной ссылке: http://meteo.ru/data/162-temperature-precipitation.
Процесс получения данных
Для получения данных необходимо пройти стандартные процедуры регистрации, которые я предлагаю вам выполнить самостоятельно. Нужно выбрать именно пункт «Получить данные через новый сайт по технологии Web Аисори-М (режим опытной эксплуатации)»: http://aisori-m.meteo.ru/waisori/index.xhtml
Как только вы прошли регистрацию, вы можете зайти на сайт, чтобы получить данные.

После успешного ввода ваших пользовательских данных, вы увидите список текущих обновлений данных в системе Web Аисори-М:

Затем нужно выполнить «Переход к выбору данных», после чего перед вами появится панель управления выборкой данных.

Здесь вы можете выбрать любые интересующие вас данные из списка

Мы выбираем температуру и осадки (TTTR), так как нам интересно узнать изменения именно в этих параметрах, так как они отражают локальные изменения в климате на территории нашей страны. По этим данным мы также сможем оценить насколько локальные изменения в климате связаны с тенденцией глобального потепления климата в атмосфере Земли, которые произошли за последние 60 лет, начиная примерно с 1960-го года (так как данные по всем станциям доступны начиная примерно с этого времени).
Дальше нам нужно заполнить Список выбранных станций. Мы выбираем все станции, поэтому достаточно просто кликнуть на кнопку «Все».

Все станции будут добавлены после этого в список автоматически.
После этого вы сможете перейти к следующему пункту, нажав на кнопку «Дальше».

Здесь для удобства представления мы указываем в пункте «Задайте разделитель» опцию «Точка с запятой».

Итак, нам нужно также заполнить временные параметры, как показано на скриншоте:

Если вас интересуют другие диапазоны времени, то вы также можете указать другие параметры. Информация по некоторым станциям может быть предоставлена ранее 1950-года, так что если вас интересуют конкретная местность и расположенные на ней метеостанции, вы можете попробовать получить данные за более длительный срок времени.
В параметры запроса нам нужно добавить метеорологические параметры температуры воздуха (минимальной, максимальной и средней за сутки) и количество осадков. Общий признак качества температур мы можем не учитывать, так как правило данные по температурам собраны корректно, но для простоты мы просто кликаем на кнопку «Все» и добавляем все параметры в список.

Теперь все готово, чтобы получить данные. Нажимаем на кнопку «Получить результат». После нажатия на кнопку «Получить результат», будет показано сообщение:

Ожидаем немного времени (как правило не более 5 минут), после чего становится доступной кнопка «Получить результат» во всплывающем сообщении:

Жмем на нее, видим перед собой страницу с описанием данных:

Мы видим, что данные записаны в столбцы и по номеру столбца мы можем получить конкретные значения температур и осадков в зависимости от времени и места, которые определяются первыми четырьмя столбцами. Здесь в первом столбце «Индекс ВМО» указан уникальный индекс метеостанции, который позже мы свяжем с географическими координатами станции.
Остался последний шаг, чтобы получить данные — нажать на кнопку «Загрузить»

После загрузки мы получаем файл с данными по 600 метеостанциям нашей страны, официально предоставленные нашей гидрометеорологической службой! Спасибо людям, работающим на метеостанциях и в росгидромете за эту возможность исследовать климат нашей родной страны!
Описание файла с данными
Файл с данными представляет собой простой ZIP-архив

В нем содержатся 3 файла, первый из которых по списку это файл с данными.

Второй файл с префиксом statlist это список данных метеостанций, связывающие индекс метеостанции с ее географическим расположением (название города, села, страны).

Третий файл содержит описание названий столбцов файла с данными:

Мы его уже с вами видели. Собственно данные представляют простую таблицу, в соответствии с вышеобозначенным описанием:

Теперь можно приступить к их обработке!
Обработка данных: Подготовка компьютера
Для обработки данных нам понадобиться несколько библиотек Python, которые вы можете установить вручную используя команду pip install <имя пакета>, либо используя дистрибутив Anaconda (вы можете скачать его с официального сайта https://www.anaconda.com/download), в который по умолчанию входит пакет Jupyter Notebook, а также библиотеки Pandas, SciPy, NumPy и Pla, которые понадобятся нам для решения нашей задачи.
Если вы обнаружите вдруг, что какой-либо пакет не входит в текущую версию Anaconda, вы можете использовать команду conda install <имя пакета>, аналогично команде pip install.
Все дальнейшие действия предполагают, что вы уже настроили свой jupyter notebook и установили все необходимые для обработки данных пакеты.
Да и еще один момент, нам нужно создать рабочую директорию в которую мы распакуем полученные нами данные, в моем случае получиться следующая файловая иерархия:
/home/egor/Work/Habr/Roshydromet
└── data
├── wr201126
│ ├── fld201126a0.txt
│ ├── statlist201126.txt
│ └── wr201126.txt
└── wr201126.zipОбработка данных: Работа в Jupyter Notebook
Запускаем Jupyter Notebook
Видим перед собой отображение нашего домашнего каталога
Теперь нам нужно перейти к рабочему каталогу, который мы создали ранее (в предыдущем пункте)

Здесь нам нужно создать файл блокнота Jupyter. Выбираем опцию Python 3 из выпадающего меню пункта New для создания нового блокнота:

После добавления файла и открытия новой вкладки браузера, файл можно будет переименовать используя пункт меню Flie > Rename...

Теперь наша файловая иерархия изменилась в ней появился новый файл

Итак, Jupyter приглашает нас заняться программированием, так что начнем!

Обработка данных: Предобработка
Мы сразу подключим все нужные нам библиотеки.
import pandas as pd
import numpy as np
import scipy as sp
import scipy.stats as st
import plotly.offline as py
import plotly.graph_objs as go
import os
import rePandas позволит нам загружать и использовать большие таблицы данных, удобную индексацию и встроенные функции по статистической обработке. В нашем случае размер файла данных составляет около 600 МБ, что не очень много по сравнению к примеру файлам моделей нейросетей или датасетам для обучения нейросетевых алгоритмов.
Тем не менее удобно обращаться с такими данными используя уже готовые решения, которые не требуют изобретения велосипеда заново. К тому же эти данные бесценны, так как связанны непосредственно с нашей жизнью и нашим будущим.
Библиотеки SciPy и NumPy мы будем использовать для аппроксимации, которая необходима для построения линии тренда и прогноза будущего климата нашей страны и возможно некоторых отдельных регионов.
Нам также понадобиться настройка, чтобы можно было использовать интерактивные графики pyplot внутри Jupyter Notebook
py.init_notebook_mode(connected=True)Далее мы пропишем пути к файлам данных
DATA_PATH = os.path.join('data','wr201126')
DATA_MAIN_PATH = os.path.join(DATA_PATH, 'wr201126.txt')
DATA_METEOSTATIONS_PATH = os.path.join(DATA_PATH, 'statlist201126.txt')
DATA_FIELDS_PATH = os.path.join(DATA_PATH, 'fld201126a0.txt')Теперь мы можем загрузить данные в датафреймы, которыми оперирует Pandas
meteostations = []
with open(DATA_METEOSTATIONS_PATH, encoding="WINDOWS-1251") as f:
for line in f.readlines():
m_data = re.split("\s+", line)[:-1]
if len(m_data) > 3:
m_name = " ".join(m_data[1:-2]).strip()
meteostations.append([m_data[0], m_name, m_data[-1]])
else:
meteostations.append(m_data)
for m_data in meteostations:
assert len(m_data) == 3
df_meteostations = pd.DataFrame(meteostations, columns=["Индекс ВМО", "Название станции", "Страна"])Здесь мы просто добавляем таблицу данных по всем метеостанциям в структуру df_meteostations, включая их идентификатор (Индекс ВМО), название и страну расположения (некоторые станции могут находиться в других странах СНГ).
К сожалению нам приходится здесь вручную считывать данные в массив, так как нам нужен сложный разделитель, включающий запятые. Вообще-то Pandas поддерживает регекспы для разделения строк на элементы данных, но в нашем случае проще будет обойтись прямым считыванием данных из файла.
Также нам потребуются заголовки к колонкам таблицы с данными, которые записаны в отдельный файл
header = []
with open(DATA_FIELDS_PATH, encoding="WINDOWS-1251") as f:
header = [ " ".join(re.split("\s+", s)[4:]).strip() for s in f.readlines() ]
assert len(header) == 9Теперь мы можем считать данные по температуре и осадкам
df = pd.read_csv(DATA_MAIN_PATH, sep=";", header=None, names=header)При формировании файла на сайте Web Аисори-М мы специально указали, чтобы разделитель был точкой с запятой, так что мы легко можем считать данные, указав его в параметр sep. Мы указываем параметр header=None, чтобы Pandas понял, что в данных нет заголовка. А названия колонок он будет брать из параметра names, который мы указываем равным header — списку, считанному ранее из файла с заголовком таблицы данных.
Теперь можно посмотреть что у нас получилось
df
Итак, мы видим, что у нас в файле данных присутствуют пропуски. На это также указывает параметр качества температур, но иногда в данных могут быть ошибки, так что этот параметр не может полностью рассказать нам о том, где есть еще пропуски в данных, тем более что он учитывает только параметр температуры.
Здесь Индекс ВМО однозначно определяет метеорологическую станцию, на которой были произведены измерения
df_meteostations
Итак, данные считаны, теперь нам нужно привести их в более удобное представление.
Первое что нам нужно сделать это преобразовать колонки Год, Месяц, День к формату Даты, чтобы можно было удобно ориентироваться и использовать встроенные функции усреднения по времени
date_column = pd.DataFrame(pd.to_datetime(df.Год10000+df.Месяц100+df.День,format='%Y%m%d'))
df.insert(1,"Дата",date_column)
df = df.set_index("Дата")
df = df.drop(["Год","Месяц", "День"], axis=1)Мы также можем профильтровать данные по параметру качества температуры
df = df[df["Общий признак качества температур"] != 9]Но это будет ошибкой, потому как данные по осадкам в этом случае будут утеряны, поэтому мы просто убираем эту колонку из таблицы
df = df.drop(["Общий признак качества температур"], axis=1)После этого у нас в таблице данные становятся упорядоченными по Дате

Так же нам потребуется более удобный способ раздельного обращения к данным по температуре и осадкам
_tp_cols = header[5:9]
_t_cols = _tp_cols[0:3]
_p_col = _tp_cols[3]Мы просто записываем названия колонок в отдельные массивы и переменную, чтобы можно было выделить данные по конкретному параметру из датафрейма, получается следующее
_tp_cols = ['Минимальная температура воздуха', 'Средняя температура воздуха', 'Максимальная температура воздуха', 'Количество осадков']
_t_cols = ['Минимальная температура воздуха', 'Средняя температура воздуха', 'Максимальная температура воздуха']
_p_col = 'Количество осадков'Теперь мы можем подсчитать количество пропусков в данных. Это не обязательный шаг, но он позволит нам увидеть насколько хорошо собраны данные и какое количество данных отсутствует в наборе за весь период наблюдений. А я напомню, что весь период наблюдений, который мы выбрали при формировании файла данных составляет 72 полных года, начиная с января 1950 года и заканчивая январем 2023 года.
print("Количество пропусков в данных")
print("-----------------------------")
for _col in _tp_cols:
n_voids = 0
for value in df[_col].tolist():
if re.match("^\s+$", value):
n_voids += 1
print("{}: {} из {} ({:.2}%)".format(_col, n_voids, df.shape[0], n_voids * 100.0 / float(df.shape[0])))
Таким образом мы видим, что количество пропусков в данных составляет не более 1%, что говорит о том, насколько хорошо постарались для нас сотрудники метеорологических станций, почет им и уважение!
Хорошо, теперь нам нужно убрать из данных пропуски
v = " "
dft = df[(df[_t_cols[0]] != v) & (df[_t_cols[1]] != v) & (df[_t_cols[2]] != v)]
dft = dft.drop([_p_col], axis=1)
dfp = df[ df[_p_col] != v ]
dfp = dfp.drop(_t_cols, axis=1)
dftp = df[(df[_t_cols[0]] != v) & (df[_t_cols[1]] != v) & (df[_t_cols[2]] != v) & (df[_p_col] != v) ]Здесь переменная v приравнена строке из пробелов длинной равной стандартному размеру поля данных, а в выходных структурах мы формируем наборы данных, которые не содержат пропусков
dft — данные без пропусков только по температуре

dfp — данные без пропусков только по осадкам

dftp — данные без пропусков и по температуре, и по осадкам

Здесь мы используем сложные фильтры для сравнения значения столбца на равенство строке из пробелов, а так же простой фильтр, который я показал ранее для отсеивания данных по параметру качества температуры.
Все предельно просто
В pd.Dataframe есть встроенная функция info, которая показывает общую информацию о данных
df.info()
<class 'pandas.core.frame.DataFrame'>
DatetimeIndex: 14554115 entries, 1958-01-01 to 1998-12-31
Data columns (total 5 columns):
Индекс ВМО int64
Минимальная температура воздуха object
Средняя температура воздуха object
Максимальная температура воздуха object
Количество осадков object
dtypes: int64(1), object(4)
memory usage: 666.2+ MBЗдесь нам интересно то, что климатические параметры хранятся у нас как строки (тип object), когда нас интересует представление float, чтобы мы могли работать с данными как с числами. Нам придется конвертировать полученные нами данные в представление чисел с плавающей точкой
for _column in _t_cols:
dft[_column] = dft[_column].astype(float)
dfp[_p_col] = dfp[_p_col].astype(float)
for _column in _tp_cols:
dftp[_column] = dftp[_column].astype(float)
dftp[_p_col] = dftp[_p_col].astype(float)Таким образом мы получили структуры
dft.info()
<class 'pandas.core.frame.DataFrame'>
DatetimeIndex: 14461038 entries, 1958-01-01 to 1998-12-31
Data columns (total 4 columns):
Индекс ВМО int64
Минимальная температура воздуха float64
Средняя температура воздуха float64
Максимальная температура воздуха float64
dtypes: float64(3), int64(1)
memory usage: 551.6 MB
dfp.info()
<class 'pandas.core.frame.DataFrame'>
DatetimeIndex: 14541315 entries, 1958-01-01 to 1998-12-31
Data columns (total 2 columns):
Индекс ВМО int64
Количество осадков float64
dtypes: float64(1), int64(1)
memory usage: 332.8 MB
dftp.info()
<class 'pandas.core.frame.DataFrame'>
DatetimeIndex: 14449103 entries, 1958-01-01 to 1998-12-31
Data columns (total 5 columns):
Индекс ВМО int64
Минимальная температура воздуха float64
Средняя температура воздуха float64
Максимальная температура воздуха float64
Количество осадков float64
dtypes: float64(4), int64(1)
memory usage: 661.4 MBМы могли бы сделать это на исходном датафрейме df с целью экономии ресурса памяти, но тогда нам пришлось бы несколько иначе подходить к загрузке данных и предусмотреть загрузку не числовых значений NaN вместо строки с пробелами, а также мириться с тем, что наша таблица может содержать пропуски.
А на этом предобработка данных завершена и теперь мы можем приступить к их анализу.
Обработка данных: Анализ данных
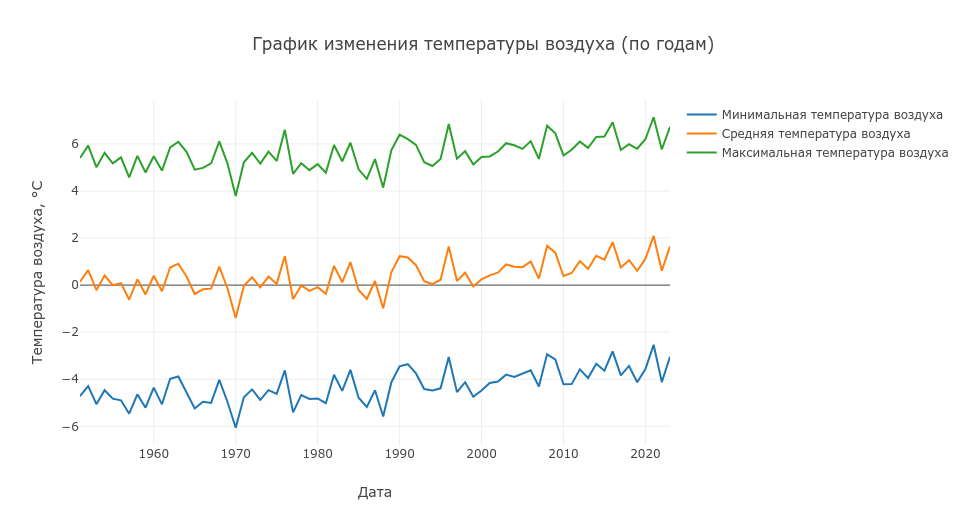
Первое, что мы сделаем — построим график изменения температуры воздуха по годам
data = dft[_t_cols].resample("Y").mean()
layout = go.Layout(
title="График изменения температуры воздуха (по годам)",
xaxis=dict(title = "Дата", type='date'),
yaxis=dict(title = "Температура воздуха, °C"),
)
temperature_traces = []
for _t_col in _t_cols:
temperature_traces.append(go.Scatter(x = data.index, y = data[_t_col], name = _t_col))
py.iplot(go.Figure(data=temperature_traces, layout=layout))
Здесь я должен пояснить что делает первая строка
data = dft[_t_cols].resample("Y").mean()По сути она берет параметры температуры (минимальной, средней и максимальной), группирует их по годам и высчитывает среднее значение температуры по каждому году — таким образом мы получаем таблицу среднегодовых значений температуры, которые мы затем просто добавляем на график.
По этим данным еще трудно понять, а есть ли какое-то существенные изменения в средней температуре во времени, но если мы выделим основной параметр средней температуры и сгладим наши данные с помощью скользящего среднего за период декады (10 лет), то возможно нам удастся лучше разглядеть их наличие…
data = dft[[_t_cols[1]]].resample("Y").mean().rolling(10, min_periods=10).mean().dropna()
layout = go.Layout(
title="График изменения среднегодовой температуры воздуха усредненной за период декады (10 лет)",
xaxis=dict(title = "Время, год", type='date'),
yaxis=dict(title = "Температура воздуха, °C"),
)
trace1 = go.Scatter(x = data.index, y=data[_t_cols[1]], name=_t_cols[1])
py.iplot(go.Figure(data=[trace1], layout=layout))
Итак, мы действительно видим, что средняя температура воздуха действительно возрастает и это происходит, начиная примерно с 1990-го года. Повышение средней температуры воздуха относительного его среднего значения в прошлом составляет 1.2°C. Это поразительно!
Колебания параметров температуры на величину в 1°C характерны для периодов в тысячи и десятки тысяч лет, но ни как для периодов декады. Естественные причины изменения температурного параметра связаны с вполне определенными циклами планетарного и космического масштаба (о которых можно почитать здесь и здесь), и в их текущую фазу являются фактором понижающим температуру, а не повышающим ее.
Это означает, что действительно настоящее время происходят существенные изменения в климате связанные с именно с деятельностью человека, развитием человеческой цивилизации и ее возросшим влиянием на нашу планету.
Мы можем оценить примерную скорость прироста температуры по тренду, который можно построить на основе интерполяции данных линейной функцией
data = dft[dft.index > "1988-01-01"][[_t_cols[1]]].resample("Y").mean().rolling(10, min_periods=10).mean().dropna()
temperature = data[_t_cols[1]].tolist()
idx = np.arange(0,len(temperature))
slope, intercept, r_value, p_value, std_err = st.linregress(idx,temperature)
line = slope * idx + intercept
layout = go.Layout(
title="График изменения среднегодовой температуры воздуха усредненной за период декады (10 лет)",
xaxis=dict(title = "Время, год", type='date'),
yaxis=dict(title = "Температура воздуха, °C"),
)
trace1 = go.Scatter(x = data.index, y=data[_t_cols[1]], name=_t_cols[1])
trace2 = go.Scatter(x = data.index, y=line, name='Линия тренда')
py.iplot(go.Figure(data=[trace1, trace2], layout=layout))
Параметр slope позволяет оценить скорость, с которой возрастает температура атмосферы за год:
print("Температура воздуха возрастает в среднем на {}°C за год".format(round(slope,2)))
Температура воздуха возрастает в среднем на 0.03°C за годНа основе данного параметра можно сделать эвристический прогноз, касающийся климата будущего. Нужно учесть правда, что наш эвристический прогноз не может показать нам далекое будущее и горизонт такого прогноза ограничен не более чем несколькими десятилетиями, так как исходные данные которыми мы располагаем ограничены по времени.
Для построения прогноза на 10 лет нужно иметь данные «с запасом» примерно за 50 — 100 лет, чтобы исключить высокочастотные составляющие колебаний, которые могут быть помехой в оценке реального тренда.
Но если мы допустим, что тенденция сохраниться, тогда уже через 10 лет мы получим прирост температуры на 0.3 °C, при этом средняя температура атмосферы Земли достигнет критического значения 1.5 °C. Значение в 1.5 °C связывают с глобальной системной перестройкой атмосферных и климатических процессов на всей планете, которые могут быть катастрофическими для некоторых регионов нашей планеты!
Согласно первому с 2013 года отчету Межправительственной группы экспертов, при всех сценариях выбросов (даже при самом большом их уменьшении) к 2040 году температура повысится на 1.5 градуса, а арктический лед полностью растает по крайней мере один раз до 2050 года, что приведет к существенному повышению уровня океанов и морей.
Повышение уровня океанов и морей может привести к затоплению прибрежных и островных территорий, к большим экономическим потерям, миграции людей (подробнее об этом можно прочитать здесь).
Но что еще более интересно, локальные изменения в климате конкретных регионов могут существенно различаться по темпам прироста температуры в разы!
То есть в некоторых регионах средняя температура воздуха может расти быстрее, чем 1 °C за 33 года. Вы можете проверить это, к примеру, использовав фильтр данных по индексу ближайшей к вам метеостанции (Индекс ВМО), получить который вы можете из таблицы df_meteostations
df_meteostations[df_meteostations["Название станции"].str.contains("Москва")]Я живу в Барнауле, и у нас здесь средняя температура повысилась за последние десятилетия в среднем на 4 °C! По ощущениям скажу, что у нас стали гораздо более теплыми зимы и лето стало еще жарче! И это очень приятно!
А еще у нас на месяц раньше наступает весна, в связи с тем, что время устойчивого перехода температуры через 0 °C сдвинулось на 1 месяц назад по сравнению с 1950-м годом.
При этом у нас стало гораздо меньше кровососущих насекомых, так как в условиях недостатка влаги и повышенной температуры они быстро погибают и не успевают размножиться.
Но, в то же время, фактор повышения средней температуры в нашем регионе начинает неблагоприятно влиять работу аграрной отрасли...
Дело в том, что повышение средней температуры может привести к засухе. Вдали от морей и больших озер, при континентальном климате, колебания значений температур между зимой и летом, как правило, больше, чем рядом с ними, поэтому жаркое лето становится опасным — может произойти гибель посевных культур из-за потери растениями влаги.
Поэтому аграриям нужно найти приемлемое решение для выращивания растений в экстремальных условиях. К примеру это может быть организованная система орошения как в странах с пустынным климатом или большее количество поливальных машин…
Для кого интересно узнать реальную ситуацию засухи повторяющейся уже 2-й год в Алтайском крае (начиная с 2020 года) можете прочитать эти статьи:
Почти на всей территории Алтая ввели режим ЧС из-за засухи
Удар по сельскому хозяйству нанесла аномальная жара на Алтае
А еще, если вы помните, в Сибири в 2019-м году прошел крупный пожар, горела тайга, причем по масштабам это было рекордное событие, так как площадь возгорания превысила средние показатели в 1.5 раза (сгорело более 5 млн. га).
А до того, в 2018-м году горела Калифорния. Конечно по площади пожары в Сибири оказались гораздо крупнее, тем не менее, все это следствия глобального потепления.
А еще, если кто помнит, в 2019 — 2020 годах бушевали ужасные пожары в Австралии, уничтожившие 12 млн. га леса и около 3 млрд. животных.
При этом также, если посмотреть так же на другие погодные явления, которые случались за этот период (ураганы, смерчи, землетрясения, наводнения и тд.), то можно увидеть прямую зависимость между повышением температуры атмосферы Земли и активизацией экстремальных погодных явлений.
Чтобы легче было это понять, можно представить кастрюлю, в которой мы нагреваем воду — чем выше температура, тем сильнее в ней будет идти испарение, а также перемешивание слоев воды из-за конвекции, а еще повышение давления пара и возникновение турбулентных потоков под крышной — просто энергия заставляет частицы воды и воздуха быстрее двигаться. На Земле происходит что-то подобное, но в других масштабах.
Что интересно в 2021 году Международной группой экспертов по изменению климата (организация под эгидой ООН, куда входят авторитетные ученные-климатологи планеты) было доказано, что глобальное потепление является прямым следствием возросшего влияния человеческой цивилизации на экосистемы планеты.
Мы можем проделать подобный анализ и для параметра осадков. Только здесь нас интересует сумма осадков за год, а не среднее годовое значение (как было с температурой). При этом мы так же учитываем, что нам нужно нормировать это число на количество станций.
Давайте попробуем увидеть сразу более точную картину, убрав высокочастотные составляющие с помощью скользящего среднего с периодом усреднения 10 лет.
data = dfp[[_p_col]].resample("Y").sum().rolling(10, min_periods=10).mean().dropna() / 600
precipitation = data[_p_col].tolist()
idx = np.arange(0,len(precipitation))
slope, intercept, r_value, p_value, std_err = st.linregress(idx,precipitation)
line = slope * idx + intercept
layout = go.Layout(
title="График изменения годовой суммы атмосферных осадков усредненной за период декады (10 лет)",
xaxis=dict(title = "Время, год", type='date'),
yaxis=dict(title = "Атмосферные осадки, мм"),
)
trace1 = go.Scatter(x = data.index, y=data[_p_col], name=_p_col)
py.iplot(go.Figure(data=[trace1,trace2], layout=layout))
Итак, мы видим похожую картину, правда резкое изменение в осадках произошло гораздо раньше, чем это произошло с температурой. Мы видим, что основные изменения в осадках произошли в период 30 лет с 1960 по 1975-й годы — произошло быстрое увеличение уровня осадков примерно на 36% по сравнению с началом периода. При этом скорость роста уровня осадков составила в среднем 8.65 мм в год.

Так как мы уже знаем о том, что деятельность человека является причиной глобального потепления, мы можем смело предположить, что повышение осадков в этот период может быть связано с завершением процесса индустриализации, наращиванием энергетических мощностей страны, и развитием промышленности, связанными с повышенным выбросом аэрозольных частиц в воздух.
Повышение уровня аэрозольных частиц в атмосфере может служить фактором повышающим вероятность выпадения осадков. Это связано с тем, что аэрозольные частицы представляют собой центры конденсации, притягивающие частицы воды и способствующие формированию дождевых облаков, являющихся одной из основных причин атмосферных осадков.
Подобное справедливо также и для формирования снежных облаков, так как центрами кристаллизации снежинок являются так же аэрозольные частицы. Таким образом повышенный уровень аэрозольных частиц в воздухе, особенно над городами, где сконцентрирована вся промышленность, является причиной выпадения большего количества осадков.
Конечно повышение уровня осадков это позитивный фактор, который способствует развитию сельского хозяйства, особенно в засушливых регионах. Но в то же время мы видим, что на текущий момент рост уровня осадков остановился. Точнее, как мы можем увидеть на нашем графике, роста осадков не происходит и колебания уровня осадков медленно идут на спад со скоростью в среднем 0.74 мм за год

Так что в прогнозе с учетом повышения уровня средней температуры атмосферы, и медленного понижения уровня атмосферных осадков, картина будущего изменения климата не особенно радует.
То есть если сохраниться тенденция на повышение температуры, а по некоторым прогнозам средняя температура по всей планете до 2100 года возрастет на 3 — 5°C, что полностью совпадает с нашими рассчетами, так как при линейном росте средней температуры атмосферы к концу века на территории России она составит 3.5°C, причем локально изменения могут составить еще большие значения, тогда в тех регионах, которые уже сейчас испытывают проблемы с экстремальными значениями температур — станут еще менее благоприятными для ведения сельскохозяйственной деятельности, и это с учетом того, что уровень осадков будет медленно убывать, и к концу века может составить 418 мм.
Это означает, что нам придется изменить характер сельскохозяйственной и других видов деятельности, приспособиться к экстремальным климатическим условиям и лучше уже сейчас начать думать над этим, потому как эти изменения могут потребовать значительное время.
Заключение
В статье мы рассмотрели процесс получения и анализа климатических данных Гидрометцентра, на основе популярных библиотек Python: Pandas, SciPy, NumPy и Plotly. Это позволило нам понять какие изменения будут происходить в климате нашей страны и планеты в ближайшие десятилетия.
В следующей статье я расскажу о том, как мы можем визуализировать эти данные, привязав их географическим координатам на карте, чтобы проанализировать, где будут наилучшие условия для жизни на территории нашей страны с учетом меняющегося климата.
P.S.
Данная статья написана под впечатлением от курса "Анализ временных рядов" Елены Владимировны Понькиной, преподавателя кафедры кибернетики Алтайского государственного университета. Я выражаю ей свою искреннюю благодарность.
Я также выражаю благодарность всем моим преподавателям и учителям. Спасибо вам за ваш не легкий, но светлый труд!
P.P.S.
Я создал репозиторий на git и залил туда Jupyter Notebook со всем кодом для всех, кто желает сразу получить результат.
Не забудьте распаковать архив с данными после загрузки, если воспользуетесь репозиторием!
Спасибо за внимание!




