
Привет, Хабр! Меня зовут Василь Хамидуллин, я работаю в ЦК тестирования решений на платформе SAP в компании РСХБ-Интех. В прошлый раз я делился опытом тестирования бизнес процессов, внедряемых модулей SAP, в банке. Сегодня расскажу вам про LSMW, и как данный инструмент можно использовать для автоматизации подготовки тестовых данных.

При внедрении ERP-системы SAP одним из наиважнейших вопросов является вопрос загрузки данных исторических систем (например, тех, что функционировали на предприятии до внедрения SAP) в новую ERP. В нашем же случае одним из важнейших вопросов является создание данных, которые можно использовать для тестирования системы.
Миграция данных является неотъемлемой частью жизнедеятельности любой ИС. Объектами миграции данных являются:
все необходимые справочные данные (НСИ), имеющиеся в исторических системах;
все необходимые персональные данные, имеющиеся в исторических системах.
Миграция данных осуществляется с помощью разработанных программ или стандартными средствами. В качестве стандартного средства в системе SAP предусмотрен инструмент загрузки данных LSMW (Система Переноса данных из Исторических Систем). Это инструмент, поддерживающий передачу данных из не-SAP-систем (они называются «историческими системами» или Legacy System) в системы стандарта SAP R/3. Это может быть как разовая, так и периодическая передача.
Общая структура работы LSMW может быть наглядно представлена следующим образом. Сначала готовятся данные в не SAP системе определенным образом, затем эти данные считываются системой миграции. После этого происходит мэппинг полей в загружаемом файле с данными и в принимающей системе. Если при мэппинге полей ошибок не выявлено, начинается преобразование данных в формат, который может обработать и усвоить SAP. Последний шаг — это непосредственно импорт самих данных, подлежащих миграции.

Рассмотрим структуру работы системы миграции более подробно. LSMW поддерживает преобразование данных унаследованной системы множеством способов. Затем данные можно импортировать в систему SAP R/3 с помощью пакетного ввода, прямого ввода, BAPI или IDoc.
Кроме того, LSMW предоставляет функцию записи, которая позволяет генерировать «объект переноса данных», чтобы включить миграцию из любой требуемой транзакции.

Начало работы с LSMW и создание проекта
Чтобы начать работать с LSMW используем одноименную транзакцию и попадаем на данный экран. Раскрыв допустимые значения для поля «проект», мы увидим созданные ранее проекты. Создаем/присваиваем краткое или полное имя для проекта, подпроекта, объекта. В наименованиях используем только английские символы, в расшифровке возможен русский язык.


Становимся курсором в поле Project и жмем белый листок, создаем проект. Проектом может быть как, например, верхнеуровневый «проект» (например, с названием «PM» для работы с ним всей группы ТОРО, оно же Техническое обслуживание и ремонт оборудования), так и более локализованный. После указания названия проекта жмем зеленую галку и следом указываем название и описание подпроекта.
Подпроект — это всего лишь структуризация вашего проекта, поэтому в зависимости от принятого решения о выборе проекта соответствующим образом создаем и подпроект. Ну и объект. Тут уже детализируем, что именно мы собираемся грузить в систему/изменять с помощью LSMW.
После указания наименований всех необходимых полей нажимаем часики (выполнить).
Данные три параметра необходимы лишь для того, чтобы легче ориентироваться и искать созданные макросы и проекты. Технически названия ни на что не влияют. Не обязательно создавать каждый раз новый Проект, достаточно в уже созданном создать Подпроект или Объект.




Процесс загрузки исторических данных в SAP
Меню по загрузке данных состоит из 20 пунктов, каждый из которых необходимо выполнить. После прохождения пункта проставляется дата внесения изменений и активным становится следующий пункт. В пункте меню Edit включаем Numering On, чтобы напротив каждого шага отображался порядковый номер. Некоторые шаги заполняются автоматически, но мы зайдем в каждый, чтобы проверить, что все создалось корректно.

1. Define object attributes
Заполним первый пункт. Определяем основные параметры макроса, на основании чего и как он будет работать. На этом шаге нам необходимо указать, каким образом мы будем производить загрузку данных. Я остановлюсь на двух наиболее часто используемых методах. Для этого встаем на первый пункт списка и жмем часики.
A) Стандартный Объект (Standart Batch/Direct Input)
В LSMW предусмотрен перечень предопределенных объектов, среди которых с большой долей вероятности есть тот, который нужен вам. В нашем случае это Единица оборудования.
B) Batch Input Recording
Если вам не достаточно стандартного объекта, либо для ваших нужд стандартного объекта нет в принципе, в этом случае вам необходимо записать «макрос». То есть вы вызываете транзакцию, данные которой вам и необходимо загрузить, и записываете последовательность ваших действий, а потом на последующих шагах под стать записанному «макросу» вы создаете структуру для файла-шаблона загрузки.
Данный метод мы рассмотрим позже.
Указываем в поле объект первого пункта необходимый объект – единица оборудования. Жмем галку.

Далее в поле Method выбираем 0001 — Создание ПакВв (то есть «пакетный ввод»). Сохраняем шаг и выходим.


После сохранения и выхода из первого шага система выделяет следующий по очередности шаг и фиксирует его временные данные.

2. Define source structures
На этом шаге нам необходимо определить структуру наших загружаемых данных. В случае с Единицами Оборудования структура будет одноуровневой («плоской») без подчиненных подструктур. Последние бы пригодились нам, скажем, в случае загрузки Заказов ТОРО, когда для одного заголовка Заказа может быть N операций, к каждой из которых может быть M компонентов. А у единицы оборудования есть номер и набор данных без вложенности.
Если структура плоская, то этот шаг — формальность. Создаем структуру. Сохраняем, выходим. Для этого Переходим в режим редактирования, нажав кнопку «Изменить». Для создания новой записи нажимаем кнопку «Создать». Заполняем поля. Наименование структуры указываем без пробелов.


3. Define source fields
На шаге 3 определяем поля, которые мы планируем грузить. Позиционируем курсор на нашу основную структуру, жмем значок «белый лист» и создаем поля, которые мы собираемся прогружать для нашего объекта. Например, загрузим для ЕО следующие поля:
изготовитель производственной установки HERST C(030);
тип ЕО EQTYP C(001);
название ЕО EQKTX C(040);
группа плановиков для сервиса клиентов и ТОРО INGRP C(003);
завод, планирующий ТОРО IWERK C(004).
Поле «номер ЕО» мы грузить не может, поскольку оно создается в системе по методу счетчика. Создание полей количественно не ограничено. Можно создавать любые необходимые поля. Рекомендуется указывать наименования полей согласно их техническим наименованиям в системе для минимизации ошибок при мэппинге (на пятом шаге). Чтобы узнать, как называется то или иное поле, какого они типа и какой разрядности, становимся курсором на это поле и жмем «F1». Среди полей находим интересующее нас (в данном случае «Изготовитель» — это поле HERST), его тип (CHAR) и длину (30 символов). И, соответственно, эти данные прописываем в создаваемое на третьем шаге поле.


Указываем параметры найденных полей. Сохраняем и получаем общую структуру полей, которые будем грузить в систему.


Также указать параметры необходимых полей можно с помощью кнопки «Table Maintenance». Важно: описание поля подтягивается само, если вы назвали поле также как существующий элемент данных в системе. Описание поля в дальнейшем ни на что не влияет технически. Также важно правильно определить тип данных и его длину. С(си) это char, т.е. символьная переменная. Если вы укажете длину меньше, чем фактическое значение в загружаемом шаблоне (excel-файле или блокноте), то такое значение обрежется на стадии чтения данных из источника, как следствие в макрос попадут недостоверные данные.


4. Define structure relations
На этом шаге нам необходимо связать наши структуры со стандартными. В нашем случае с простой, плоской структурой все очень просто: позиционируем курсор на IBIP, Единица Оборудования, жмем белый листочек. Единственная наша структура, которую мы создали ранее, автоматом подвязывается к стандартной структуре ЕО. Сохраняем, выходим.

5. Define field mapping and conversion rules
На данном шаге мы определяем правила трансформации данных из структуры источника в структуру, которую будет использовать макрос. Чтобы наиболее быстро определить правила трансформации необходимо иметь названия полей структуры источника такие же, как и в структуре макроса. Иными словами, нам требуется связать созданные нами поля, предполагаемые к загрузке, с соответствующими полями ЕО, известными системе. Вот тут-то нам и пригодится то, что на шаге №3 мы называли поля также, как их знает система.

Теперь в пункте меню Extras нажимаем на Auto-Field Mapping, после чего система автоматом смэппливает поля, предварительно уточнив правила их распознавания. В этом окне можно ничего не менять, оно уже настроено так, чтобы сопоставлять данные с одинаковыми именами. Единственное, если у вас много полей, можно избежать запросов на подтверждения для каждого поля, переключив самый нижний параметр No confirmation.


Во всех далее появляющихся окошках необходимо «Принять предложение». Если у вас нет ошибок в наименовании вами созданных полей, то система автоматом все смэппит.


Для каждого поля структуры макроса присвоилось поле структуры, и мы видим также выполняемое действие. По желанию в этом меню можно настроить какие угодно правила, вплоть до собственной программы ABAP.


6. Define fixed values, translations, user-defined routines
На данном шаге мы можем управлять фиксированными значениями. В нашем примере их нет. Этот пункт может быть использован как ракурс ведения констант. Например, если вы в этом же объекте создадите еще один макрос, то для тех же переменных, которые заполнены константами, вы можете определить фиксированное значение и далее определять эту константу фиксированным значением в правилах трансформации, что сэкономит время в том случае, если вы создаете или используете много однотипных макросов. Данный пункт используется при сложных правилах загрузки с использованием фиксированных значений, преобразований, пользовательских расширений. В большинстве случаев, как и в нашем, фиксированные значения можно не использовать. Сохраняем и закрываем.

7. Specify files
На данном шаге мы определяем параметры файла источника и его путь на компьютере или внутреннем сервере. Тут два варианта:
а) Legacy Data On the PC (Frontend)
б) Legacy Data On the R/3 server (application server)
Вариант «а» — это выбор файла-шаблона, располагающего непосредственно на вашем компьютере, а «б» — на сервере SAP. Со вторым вариантом как-то не сталкивался. Все время для удобства использовал файл, находящийся непосредственно в файловой системе. Позиционируемся на Legacy Data (на красную область), жмем листочек «Создать».
На данном этапе необходимо предварительно подготовить файл шаблона. Для этого пересохраняем файл с данными либо в формате *.xls, либо в формате *.txt с разделителями табуляции, либо *.csv. Создаем шаблон в формате тхт в блокноте на жестком диске. Вспоминаем наши пять полей: Тип ЕО, Название ЕО, Вид ЕО, Изготовитель, Группа плановиков.
Можно в файле-шаблоне первой строкой через TAB указать системные названия полей для наглядности. Во второй и последующих строчках также через TAB пишем значения для загрузки. Желательно не использовать русские символы, в противном случаем сохраняем файл как текст юникод.


На появившемся экране выбираем месторасположения файла‑шаблона на диске вашего компьютера, устанавливаем радиокнопку «Tabulator» на подэкране Delimiter (разделитель), ставим галку на пункте «Field Names at Start of File» (указываем, что первая строка файла — это технические имена полей или заголовок, о чем следует сказать программе чтения). Если у вас последовательность полей в файле‑шаблоне не соответствует соответствующей последовательности шага три — Maintain source fields, то нужно снять галку с пункта «Fields Order Matches Source Structure Definition». Остальное на экране не трогаем, жмем галку, закрываем и выходим.

Проверяем указанные параметры. Сохраняем и выходим. Наименование временных файлов для импорта и конвертации создается автоматически и может быть очень длинным, что, в свою очередь, вызовет ошибку при сохранении, поэтому в этом случае необходимо будет «провалиться» в эти наименования и подкорректировать их.

8. Assign files
В данном пункте достаточно проверить, что данные файла правильно соединены с данными структуры, в которую будет происходить чтение, т.е. в структуру источник. Если у вас структур источников больше, чем одна, то в этом пункте необходимо настроить, какой файл будет читаться в какую структуру. Поскольку у нас плоская структура с одним входящим файлом-шаблоном, открываем этот пункт на редактирование, сохраняем и выходим. Единственный файл наш привязывается к единственной структуре.

9. Read data
Переходим к самому интересному — чтению и обработке. На данном шаге мы читаем данные из файла в структуру источник. Примечателен тот факт, что если вы не закроете исходный файл шаблон (excel, блокнот) то программа не сможет прочитать файл, т.к. он будет занят другим процессом. Поэтому файлы шаблоны необходимо закрыть.

Если чтение прошло успешно, вы увидите следующую информацию. Следует обратить внимание на выделенный столбец. Если у вас неправильно сформировался файл, то здесь будет указано количество строк, которые не прочитались. Если в этом столбце не ноль, то следует перепроверить файл на корректность типов данных и длину полей. Если продолжить дальше обрабатывать данные, то будут обработаны только те, которые успешно прочитались из файла.

10. Display read data
В этом разделе мы можем проверить, как легли наши данные в структуру. Фактически здесь проверяется, какие значения из файла в какие поля структуры попали, и не потерялись ли символы при чтении у полей.




11. Convert data
Трансформация данных — один из самых важных шагов создания LSMW, т.к. при обработке этого шага выполняются все изменения данных из структуры источника в структуру, с которой будет работать макрос. Иными словами, конвертируем данные во внутренний формат системы. Нажимаем часики, видим результат конвертации, выходим.


12. Display converted data
На этом шаге мы проверяем, как прошла наша трансформация. В нашем случае мы получили ожидаемый результат. Выходим.




13. Create batch input session
Непосредственно создание макроса (пакетного ввода). Путь менять нельзя. Можно поменять название макроса в соответствующем поле. Запускаем, галочки выставляем как на принтскрине и разрешаем SAP GUI создавать файл ошибок на локальном диске.


Проверяем наличие ошибок при создании пакетного ввода.
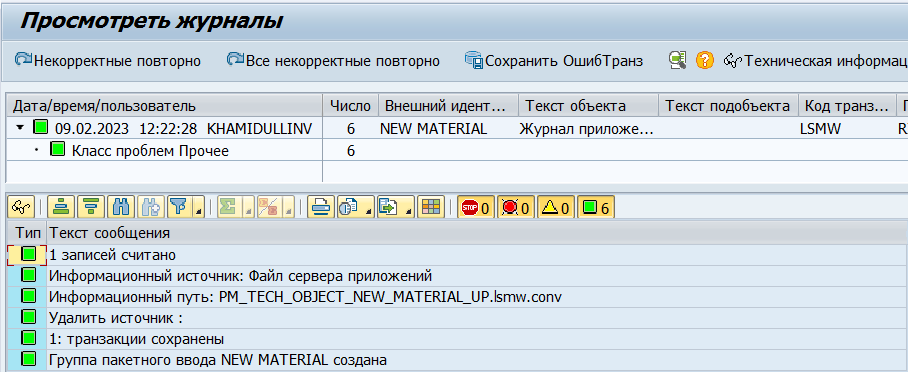
14. Run batch input session
На данном шаге мы можем запустить созданный нами макрос (пакетный ввод) и просмотреть результат его выполнения. Находим в списке заданий наше (для открытия этого списка можно использовать тр. SM35). Выделяем строку, жмем «выполнить», открывается окошко.

Программа запросит дополнительные параметры запуска. Режим выполнения влияет на то, как программа будет запущена. Если указать «выполнить видимо», то на экране вы увидите, как программа выполняет все шаги и на каждое выполняемое действие требует ввода от пользователя. Такой режим может быть полезен для отладки и только в том случае, если у вас несколько записей для обработки. Если у вас записей больше 10 штук, этот режим будет уже бесполезным.
В режиме «просмотр только ошибок» при выполнении макроса программа будет останавливаться на каждой ошибке и предупреждении. Что тоже полезно только при малом значении транзакций и записей. Если транзакций много, то лучше запускать «фоновый режим», т.к. в этом случае программа не спрашивает пользователя, а все ошибки пишет в лог. Для этого режима будет полезна галочка «расширенный журнал». Запускаем макрос.

Для проверки корректности загрузки данных в систему необходимо проверить созданные ЕО, если их немного, либо при объемной загрузке применить выборочную проверку. Проще всего найти вновь созданные ЕО в таблице EQUI по создателю, но можно использовать и комбинацию фильтров. Проект LSMW можно переносить между мандантами.





Для загрузки русских символов из шаблона в систему необходимо выполнить одну настройку:
Открываем SAP Logon, жмем ПКМ на необходимую систему и выбираем пункт «Свойства». Далее появится предупреждение, которое мы игнорируем и жмем «ОК».


В открывшемся окне выбираем вкладку «Кодовая страница», а в ней указываем кодировку «По умолчанию UTF-8 для систем уникода».

Для соответствия кодировок системы и файла-шаблона необходимо указать кодировку шаблона при сохранении «UTF-8».

После данной настройки появится возможность загружать данные из шаблона на русском языке.

Также появится возможность присваивать русские наименования проектам, подпроектам и объектам.

Для определения применимости данной технологии мы проведем анализ технологии методом SWOT-анализа. Это метод планирования, который помогает определить варианты использования технологии с учетом ее сильных и слабых сторон, а также возможностей и внешних отрицательных факторов:
S (strengths) — сильные стороны, которые отличают технологию от остальных;
W (weaknesses) — недостатки, или слабые стороны технологии;
O (opportunities) — внешние факторы и события, которые создают возможности для использования технологии;
T (threats) — внешние угрозы при использовании технологии, которые не зависят от действий того, кто ее применяет.

Учитывая все приведенные показатели, я склоняюсь к мнению, что перспектива использования данной технологии при загрузке исторических данных актуальна и по сей день.
В следующей статье я рассмотрю процесс автоматизация загрузки исторических данных в SAP с помощью SAP GUI Scripting. Также будет проведено сравнение двух этих инструментов.
Если есть вопросы/предложения, пишите в комментариях — обсудим. Спасибо за внимание!
")



