
С каждым днем в мире становится все больше и больше инструментов для проведения нагрузочного тестирования. Собственно, и сам интерес к этой теме начинает возрастать.
Основная задача инструмента нагрузочного тестирования — подать заданную нагрузку на систему. Но кроме этого есть еще одна, не менее важная задача — предоставить отчет о результатах подачи этой нагрузки. Иначе мы проведем тестирование, но ничего не сможем сказать о его результате и не сможем достаточно точно определить, с какого момента началась деградация системы.
В настоящий момент наиболее популярными инструментами тестирования являются Gatling, MF LoadRunner, Apache JMeter. Все они обладают возможностями как генерации готовых отчетов по проведенному тестированию, так и отдельных графиков или сырых данных, на основе которых строится уже сам отчет.

Прежде чем писать любой отчет, нужно понять, для кого мы его пишем и какую цель преследуем. Нет никакого смысла добавлять множество графиков времени отклика приложения в отчет по каждой операции, если ваша цель — определить, есть ли утечки памяти, зафиксирована ли нестабильная работа во время теста надежности, или если вам нужно сравнить два релиза между собой в рамках регрессионного тестирования. Для ответа на эти вопросы вам хватит всего пары графиков, если, конечно, вы не зафиксировали проблемы и не хотите в них разобраться. Поэтому, прежде чем создавать отчет, подумайте, а точно ли вам нужно добавить все графики в него или лишь наиболее показательные и дающие ответ на цель тестирования. Также набор графиков и их анализ для отчета зависят от выбранной модели нагрузки — закрытой или открытой, так как разные модели дадут разные фигуры на графиках.
Мы в Тинькофф активно используем инструмент Gatling, поэтому на его примере расскажем, как создать отчет вашей мечты и куда следует смотреть при его анализе. Также сразу хочу заметить, что почти все графики, описанные в статье, можно получать в режиме онлайн с помощью связки вашего инструмента с Grafana. Это наиболее удобный инструмент для создания отчетов «на лету», с помощью сконфигурированного заранее дашборда. Более того, это позволяет более быстро создать почти любой график на основе отправленных вами данных. Уже сейчас есть готовые дашборды почти для всех инструментов нагрузочного тестирования. Графики для других инструментов — MF LoadRunner и Apache JMeter — тоже будут приведены, их анализ строится по аналогии с Gatling.
Показывают количественное и процентное распределение времени отклика запросов по группам. Графики этого типа удобно использовать, чтобы дать быструю предварительную оценку результатам тестирования без более глубокого анализа остальных графиков.
Пороги для перехода из группы в группу задаются заранее на основе экспертной оценки или SLA (нефункциональных требований). Например, может быть три группы:
В Gatling вы сами можете настроить пороги для перехода из группы в группу и их количество в файле gatling.conf. Графики такого типа лучше строить на основе методики. APDEX (Application Performance Index)
Также можно добавить индикатор с количеством/процентами ошибочных запросов.
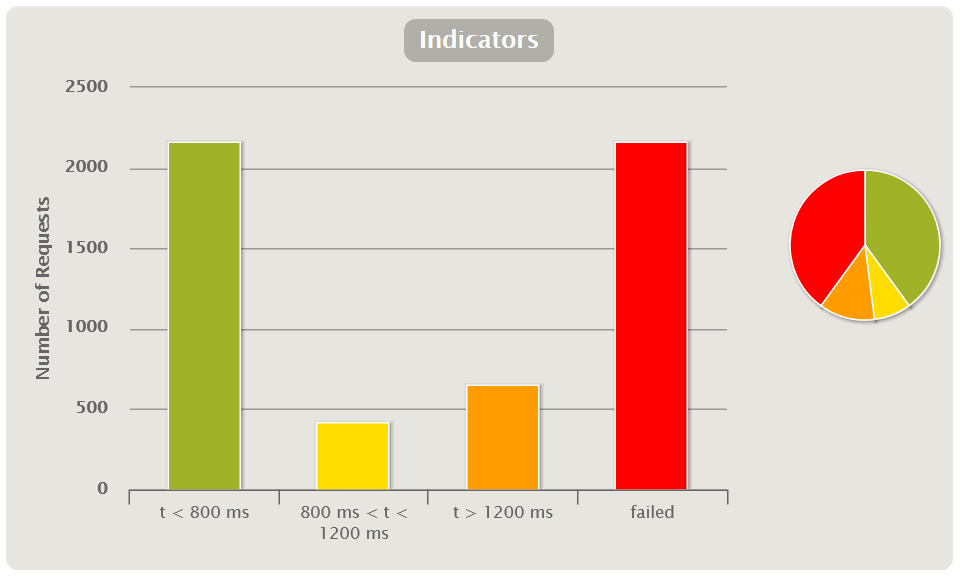
Метод APDEX позволяет использовать индикаторы в регрессионном тестировании для сравнения релизов: так сразу видно, насколько хуже или лучше стал релиз в общем. К сожалению, этого графика нет из коробки в MF LoadRunner и Apache JMeter, но его легко создать с помощью дашборда Grafana.
По умолчанию Gatling строит таблицу по перцентилям, среднему и максимальному времени отклика, а также по ошибкам. По ней отслеживается выход за пределы SLA (превышение нефункциональных требований). Обычно в SLA указывают перцентили 95, 99 и процент ошибок. Таким образом таблица позволяет получить быструю оценку результатов тестирования.
Если группировать запросы в виде транзакций, можно увидеть в таблице как оценку отдельных запросов, так и оценку всей группы и транзакции сразу.
Обычно измеряется в штуках и показывает, как пользователи заходят в приложение, тем самым иллюстрируя реальный профиль нагрузки. Стоит сразу оговориться, что для MF LoadRunner и Gatling эти графики показывают количество Virtual Users, а для Apache JMeter — количество Thread.
График используют для контроля правильности подачи нагрузки. Необходимо, чтобы ваш расчетный сценарий соответствовал тому, что вы подали на систему в реальности. Например, если вы видите на графике большие отклонения от планируемого сценария в верхнюю сторону, значит, что-то пошло не так: ошибка в расчете, запущено больше, чем нужно, копий инструмента нагрузки и так далее. Возможно, дальнейшие графики уже нет смысла анализировать, так как вы подали на 100 пользователей больше, чем планировали, а система изначально проектировалась для работы лишь 10 пользователей.
Этот график разделяется на два вида:
Вид графика также зависит от модели нагрузки:
Чаще всего измеряется в миллисекундах — показывает время ответа на запросы к приложению. Время отклика не должно превышать SLA. Этот график является основным инструментом для поиска точек деградации при проведении нагрузочного тестирования.
Если на графике видны пики, значит, в этот момент приложение не отвечало по какой-то причине — это может являться отправной точкой для дальнейших исследований. Время отклика должно быть равномерным, без пиков для всех операций на протяжении всей ступени нагрузки, а также коррелировать с увлечением нагрузки. Gatling не содержит график «чистого» (среднего, не агрегированного) времени отклика, в отличие от других инструментов.
Кроме графика времени ответа каждого запроса удобно показывать также линию с суммарным временем ответа (Total Response Time). Если наложить график подаваемой нагрузки (VU/RPS), можно отслеживать корреляцию с увеличением времени отклика от увеличения подаваемой нагрузки (VU/RPS). В Apache JMeter этот график называется Response Times vs Threads.
Далее пойдут графики, на которых может быть множество линий, каждая из которых отображает свой сценарий или запрос. Если у вас сложный тест со множеством операций и нелинейным профилем, советуем отражать в отчете лишь наиболее показательные запросы или группы запросов. Как вариант, можно отражать лишь запросы, превысившие SLA/SLO, чтобы не засорять график и отчет.
Возможна модификация, в которой применяются перцентили времени отклика и добавляется линия среднего времени отклика по всем запросам. Использование перцентилей здесь будет более правильным решением, так как среднее время отклика очень чувствительно к резким выбросам.
В тестировании производительности чаще всего используется 95 и 99 перцентиль для большей наглядности. Однако, если вы все же смотрите среднее время отклика, вам стоит учитывать при этом стандартное (среднеквадратичное) отклонение.
Также есть прекрасные графики, показывающие зависимость распределения времени от количества запросов.
Этот вид графиков чем-то напоминает индикаторы, но показывает более полную картину распределения времени, без обрезки перцентилями или другими агрегатами. С помощью графика можно более наглядно определить границы для групп индикаторов. У MF LoadRunner такого графика нет.
Из этой метрики также можно выделить дополнительный параметр Latency (миллисекунды) — время задержки (чаще всего под этим понимают Network Latency). Этот параметр показывает время между окончанием отправки запроса до получения первого ответного пакета от системы.
С помощью этого параметра можно измерять также задержки на сетевом уровне, если параметр будет расти. Желательно, чтобы он стремился к нулю. Этот и следующий тип графиков в основном используются при глубоком анализе и поиске проблем производительности. Этого графика из коробки нет в Gatling. В MF LoadRunner этот график называется Average Latency Graph в блоке Network Virtualization Graphs если у вас установленные агенты мониторинга.
Аналогично метрике выше можно выделить параметр Bandwidth (килобит в секунду) — ширину пропускания канала. Он показывает, какой максимальный объем данных может быть передан за единицу времени.
Изменяя этот параметр на инструменте нагрузки можно моделировать различные источники подключений к приложению: мобильная связь 4G или проводная сеть. В бесплатной версии Gatling этого графика нет, он есть лишь в платной версии Gatling FrontLine. Этот график из коробки есть лишь в MF LoadRunner, находится в том же блоке, что и Latency, и называется Average Bandwidth Utilization Graph.
Измеряется в штуках в секунду — показывает количество запросов, поступающее в систему за 1 секунду.
График показывает, сколько запросов может выдержать ваша система под нагрузкой, и он является также основным графиком для построения отчета. По нему также отслеживается выход за пределы SLA, так как с ростом нагрузки при прохождении точки деградации или локальных экстремумов может наблюдаться провал, а затем резкий рост. Чаще всего это связано с тем, что, когда приложение начинает деградировать, запросы тоже начинают копиться на входе в приложение (появляется очередь), затем приложение выдает им какой-то ответ или запросы падают по тайм-ауту, что вызывает резкий рост на графике — ведь получен ответ.
Измеряется в штуках в секунду и показывает количество транзакций (в рамках транзакции может быть множество запросов) за 1 секунду.
Например, транзакция «вход в личный кабинет» включает следующие запросы: открытие главной страницы, ввод логина, пароля, нажатие кнопки «отправить», переадресацию на приветственную страницу — в единицу времени. В Gatling график можно получить лишь с помощью применения Grafana, так как для групп в HTML-отчёте строятся графики лишь по времени отклика.
Обычно измеряется в rate (штук в секунду) — график показывает рост количества ошибочных запросов. Также удобно измерять значение в процентах от общего числа запросов. По этому графику отслеживается выход за пределы SLA по количеству или проценту ошибок.
Если наложить график Response Time, можно увидеть, как увеличение ошибок влияет на рост времени ответа приложения.
Gatling по умолчанию не имеет отдельного графика, отображающего лишь ошибки. В Gatling он совмещен с графиком VU и сразу показывает, как рост нагрузки сказывается на росте числа ошибок, и помогает обнаружить порог, с которого идет превышение SLA или вообще появляются ошибки. В Apache JMeter также нет отдельного графика, он совмещен с графиками количества транзакций.
Возможно также выводить на график распределения количества ошибок по кодам ответа приложения — удобно использовать для классификации ошибок.
Например, если на предыдущем графике вы получили 100%, вы начинаете анализировать, а какие именно 50x ошибки из-за того, что сервер не отвечает, или 403 из-за того, что неверный пул и пользователи не могу авторизоваться, если, например, вы используете HTTP-протокол.
Изначально в бесплатной версии Gatling этого графика нет, он есть лишь в платной версии Gatling FrontLine. Чтобы график появился в бесплатной версии, необходимо перенастроить logback.xml так, чтобы логи собирались в graylog, и уже в нем строить нужный график.
Измеряется обычно в битах в секунду. График показывает пропускную способность приложения, а именно какой объем данных был отправлен и обработан приложением в единицу времени.
Обычно его используют для глубокого анализа проблемы приложений. В Gatling этот график содержится лишь в FrontLine, в бесплатной версии его нет.
Большинство графиков можно получить, используя отчет HTML Based Gatling Reports после теста или же настроив связку мониторинга Graphite-InfluxDB-Grafana. Для отображения можно использовать готовый дашборд из библиотеки дашбордов https://grafana.com/grafana/dashboards/9935.
При анализе и составлении своих дашбордов для Gatling следует учитывать, что результаты в InfluxDB хранятся агрегированные и подходят только для предварительной оценки результатов НТ. Рекомендуется после теста повторно загрузить simulation.log в базу данных и уже по нему строить итоговый отчет и выполнять поиск проблем производительности системы.
Всё, что мы описали выше, представлено в виде маленькой таблички, суммирующей все эти знания.
Основная задача инструмента нагрузочного тестирования — подать заданную нагрузку на систему. Но кроме этого есть еще одна, не менее важная задача — предоставить отчет о результатах подачи этой нагрузки. Иначе мы проведем тестирование, но ничего не сможем сказать о его результате и не сможем достаточно точно определить, с какого момента началась деградация системы.
В настоящий момент наиболее популярными инструментами тестирования являются Gatling, MF LoadRunner, Apache JMeter. Все они обладают возможностями как генерации готовых отчетов по проведенному тестированию, так и отдельных графиков или сырых данных, на основе которых строится уже сам отчет.
Прежде чем писать любой отчет, нужно понять, для кого мы его пишем и какую цель преследуем. Нет никакого смысла добавлять множество графиков времени отклика приложения в отчет по каждой операции, если ваша цель — определить, есть ли утечки памяти, зафиксирована ли нестабильная работа во время теста надежности, или если вам нужно сравнить два релиза между собой в рамках регрессионного тестирования. Для ответа на эти вопросы вам хватит всего пары графиков, если, конечно, вы не зафиксировали проблемы и не хотите в них разобраться. Поэтому, прежде чем создавать отчет, подумайте, а точно ли вам нужно добавить все графики в него или лишь наиболее показательные и дающие ответ на цель тестирования. Также набор графиков и их анализ для отчета зависят от выбранной модели нагрузки — закрытой или открытой, так как разные модели дадут разные фигуры на графиках.
Мы в Тинькофф активно используем инструмент Gatling, поэтому на его примере расскажем, как создать отчет вашей мечты и куда следует смотреть при его анализе. Также сразу хочу заметить, что почти все графики, описанные в статье, можно получать в режиме онлайн с помощью связки вашего инструмента с Grafana. Это наиболее удобный инструмент для создания отчетов «на лету», с помощью сконфигурированного заранее дашборда. Более того, это позволяет более быстро создать почти любой график на основе отправленных вами данных. Уже сейчас есть готовые дашборды почти для всех инструментов нагрузочного тестирования. Графики для других инструментов — MF LoadRunner и Apache JMeter — тоже будут приведены, их анализ строится по аналогии с Gatling.
Основные метрики
Индикаторы
Показывают количественное и процентное распределение времени отклика запросов по группам. Графики этого типа удобно использовать, чтобы дать быструю предварительную оценку результатам тестирования без более глубокого анализа остальных графиков.
Пороги для перехода из группы в группу задаются заранее на основе экспертной оценки или SLA (нефункциональных требований). Например, может быть три группы:
- отличная — время отклика менее 50 секунд;
- средняя — более 50, но менее 100 секунд;
- ужасная — более 100 секунд.
В Gatling вы сами можете настроить пороги для перехода из группы в группу и их количество в файле gatling.conf. Графики такого типа лучше строить на основе методики. APDEX (Application Performance Index)
Также можно добавить индикатор с количеством/процентами ошибочных запросов.
Метод APDEX позволяет использовать индикаторы в регрессионном тестировании для сравнения релизов: так сразу видно, насколько хуже или лучше стал релиз в общем. К сожалению, этого графика нет из коробки в MF LoadRunner и Apache JMeter, но его легко создать с помощью дашборда Grafana.
Таблица с временем отклика
По умолчанию Gatling строит таблицу по перцентилям, среднему и максимальному времени отклика, а также по ошибкам. По ней отслеживается выход за пределы SLA (превышение нефункциональных требований). Обычно в SLA указывают перцентили 95, 99 и процент ошибок. Таким образом таблица позволяет получить быструю оценку результатов тестирования.
Если группировать запросы в виде транзакций, можно увидеть в таблице как оценку отдельных запросов, так и оценку всей группы и транзакции сразу.
| HTML Gatling Report | 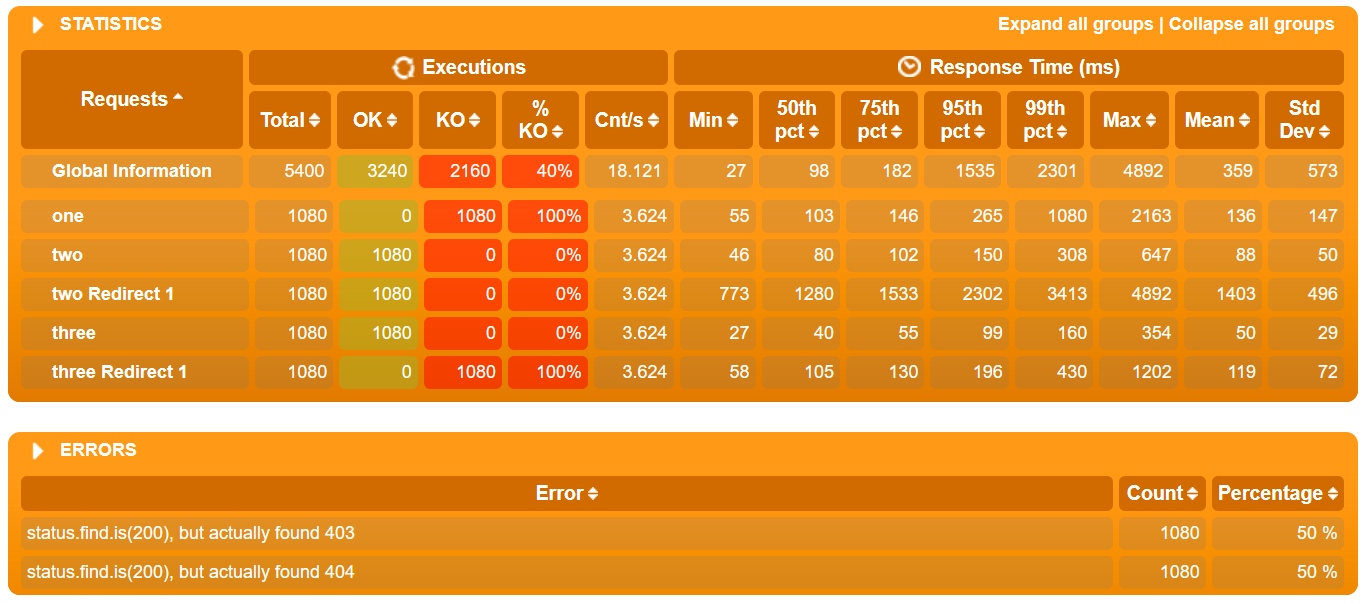 |
| MF LoadRunner также создает таблицу сам в блоке Analysis Summary Report и называется Transaction Summary | 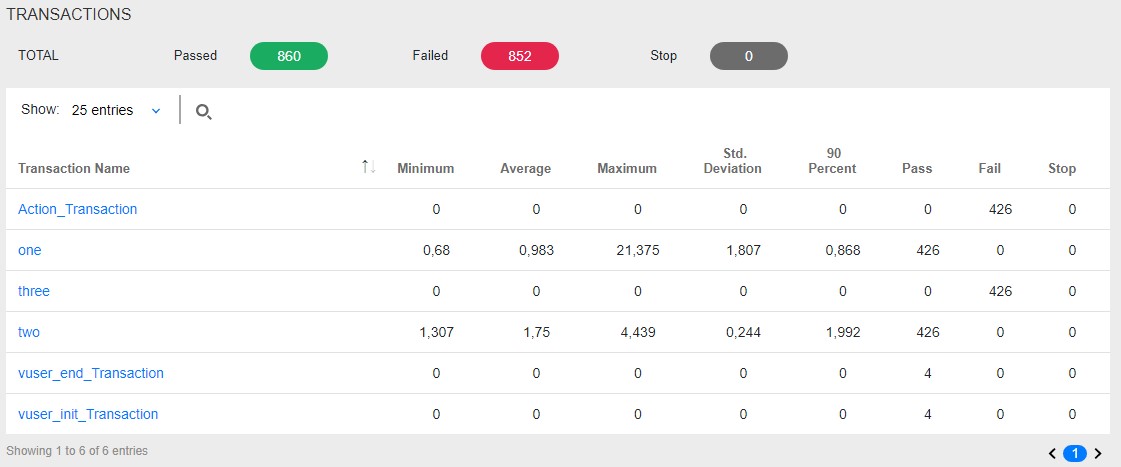 |
| В Apache JMeter эти данные можно найти в Aggregate Report | 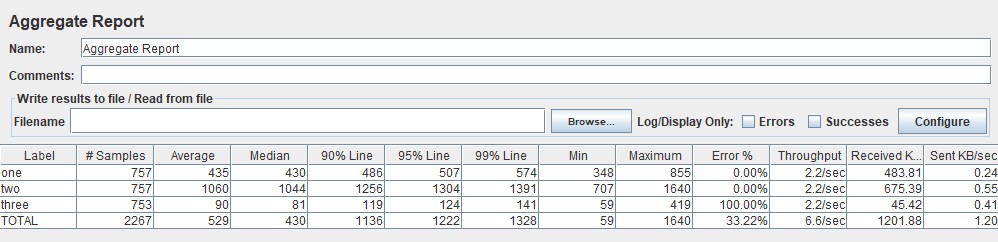 |
График Virtual Users
Обычно измеряется в штуках и показывает, как пользователи заходят в приложение, тем самым иллюстрируя реальный профиль нагрузки. Стоит сразу оговориться, что для MF LoadRunner и Gatling эти графики показывают количество Virtual Users, а для Apache JMeter — количество Thread.
График используют для контроля правильности подачи нагрузки. Необходимо, чтобы ваш расчетный сценарий соответствовал тому, что вы подали на систему в реальности. Например, если вы видите на графике большие отклонения от планируемого сценария в верхнюю сторону, значит, что-то пошло не так: ошибка в расчете, запущено больше, чем нужно, копий инструмента нагрузки и так далее. Возможно, дальнейшие графики уже нет смысла анализировать, так как вы подали на 100 пользователей больше, чем планировали, а система изначально проектировалась для работы лишь 10 пользователей.
Этот график разделяется на два вида:
- Active Users отображает, сколько потоков сейчас активно в секунду. Когда потоки стартуют и останавливаются, особенно в открытой модели нагрузки, этот показатель будет колебаться на протяжении всего теста.
- Total VUsers показывает, сколько потоков стартовали и останавливались с начала тестирования суммарно. Удобно для закрытой модели нагрузки, в которой потоки не умирают.
Вид графика также зависит от модели нагрузки:
- Закрытая модель — пользователи должны заходить в систему согласно планируемому профилю нагрузки. Если на графике видны провалы или пики, это говорит о том, что нагрузка шла не по рассчитанному или запланированному сценарию, и требует дальнейшего изучения
- Открытая модель — на графике могут быть видны пики и провалы, и это нормально для этой модели. Пик на графике должен коррелировать с увлечением времени отклика, так как в этот момент пользователи ожидают ответа от сервера и общая нагрузка на систему начинает падать. В связи с чем инструмент начинает поднимать новых виртуальных пользователей, чтобы количество запросов к системе оставалось постоянным, несмотря на долгие ответы/ошибки приложения. Для защиты от чрезмерного увеличения количества пользователей необходимо использовать функции троттлинга, принудительно задающие верхний порог — максимальное количество поднятых пользователей инструментом нагрузки.
| HTML Gatling Report | 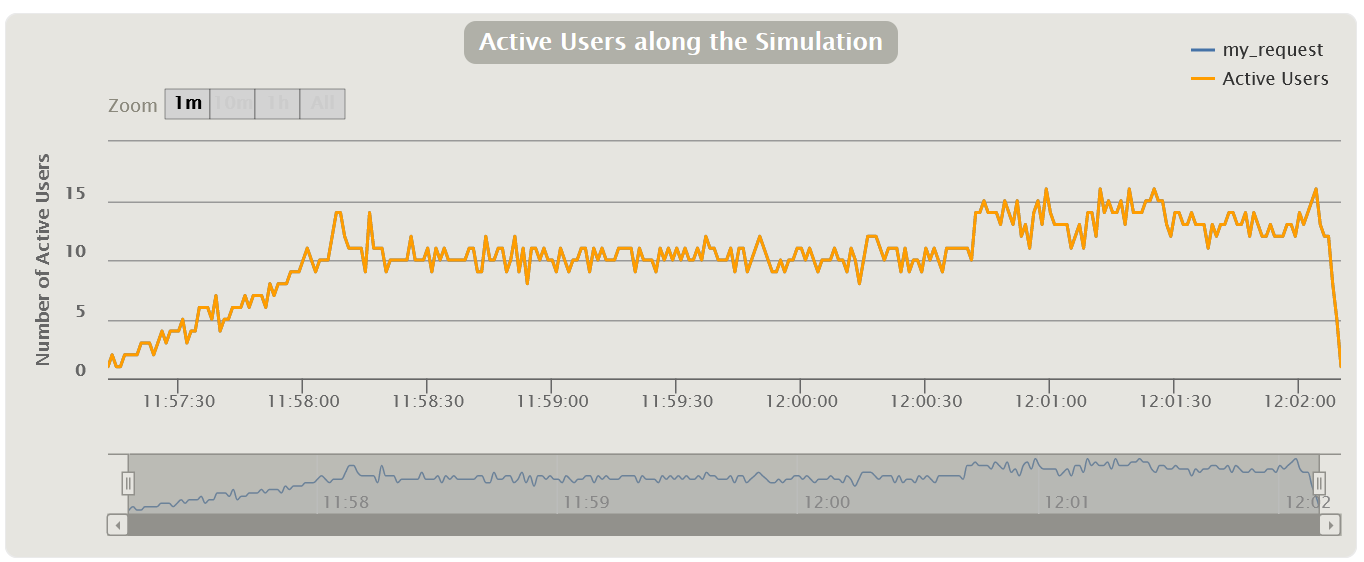 |
| В MF LoadRunner этот график называется Running Vusers |  |
| В Apache JMeter график называется Active Threads Over Time и не входит в стандартную поставку, но его можно бесплатно скачать на сайте JMeter-Plugins.org | 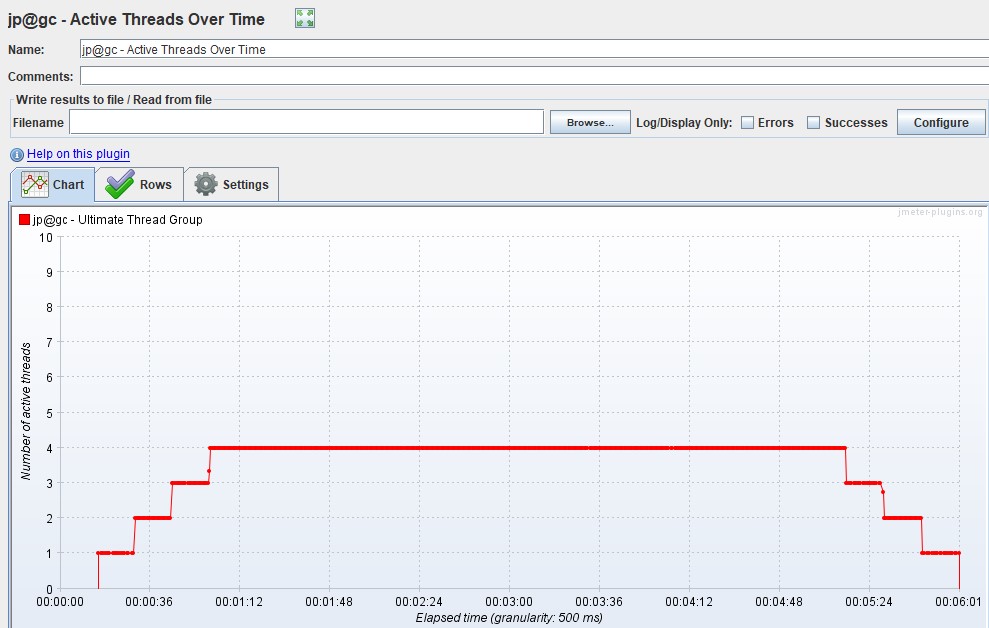 |
График Response Time
Чаще всего измеряется в миллисекундах — показывает время ответа на запросы к приложению. Время отклика не должно превышать SLA. Этот график является основным инструментом для поиска точек деградации при проведении нагрузочного тестирования.
Если на графике видны пики, значит, в этот момент приложение не отвечало по какой-то причине — это может являться отправной точкой для дальнейших исследований. Время отклика должно быть равномерным, без пиков для всех операций на протяжении всей ступени нагрузки, а также коррелировать с увлечением нагрузки. Gatling не содержит график «чистого» (среднего, не агрегированного) времени отклика, в отличие от других инструментов.
Кроме графика времени ответа каждого запроса удобно показывать также линию с суммарным временем ответа (Total Response Time). Если наложить график подаваемой нагрузки (VU/RPS), можно отслеживать корреляцию с увеличением времени отклика от увеличения подаваемой нагрузки (VU/RPS). В Apache JMeter этот график называется Response Times vs Threads.
Далее пойдут графики, на которых может быть множество линий, каждая из которых отображает свой сценарий или запрос. Если у вас сложный тест со множеством операций и нелинейным профилем, советуем отражать в отчете лишь наиболее показательные запросы или группы запросов. Как вариант, можно отражать лишь запросы, превысившие SLA/SLO, чтобы не засорять график и отчет.
| В MF LoadRunner график называется Average Transaction Response Time и показывает среднее время для транзакций | 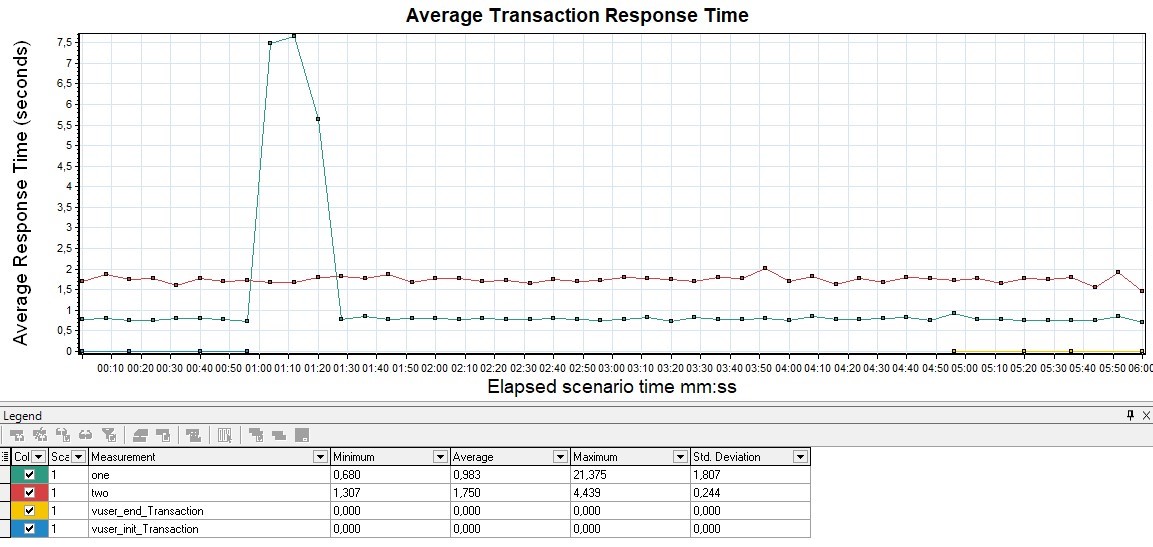 |
| Для Apache JMeter график существует в двух вариантах в расширенном пакете с сайта JMeter-Plugins.org и называется Response Times Over Time и, по умолчанию, Response Time Graph. Более наглядный и удобный, на мой взгляд, — первый вариант | 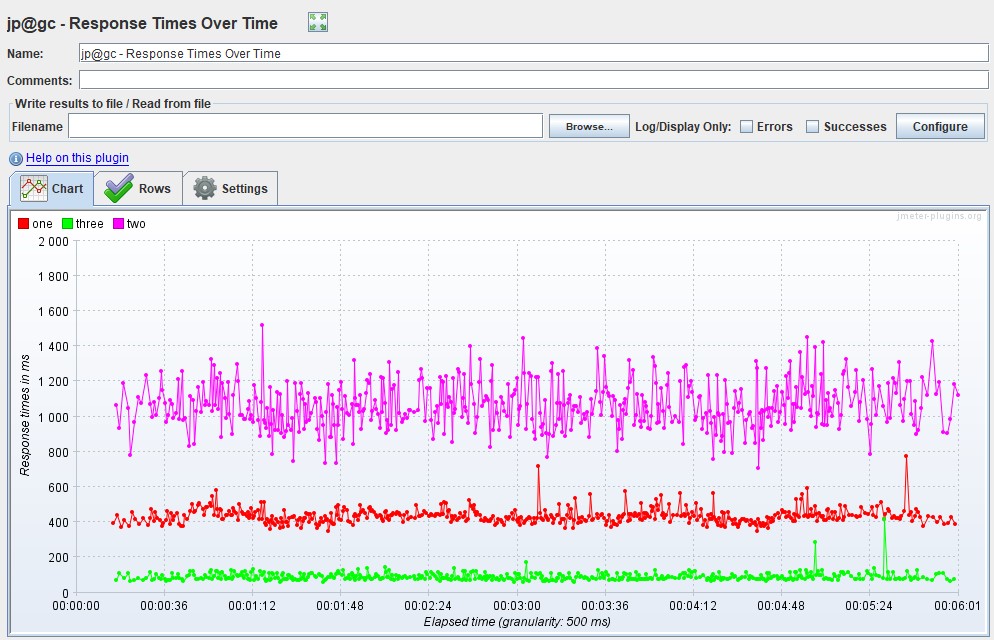 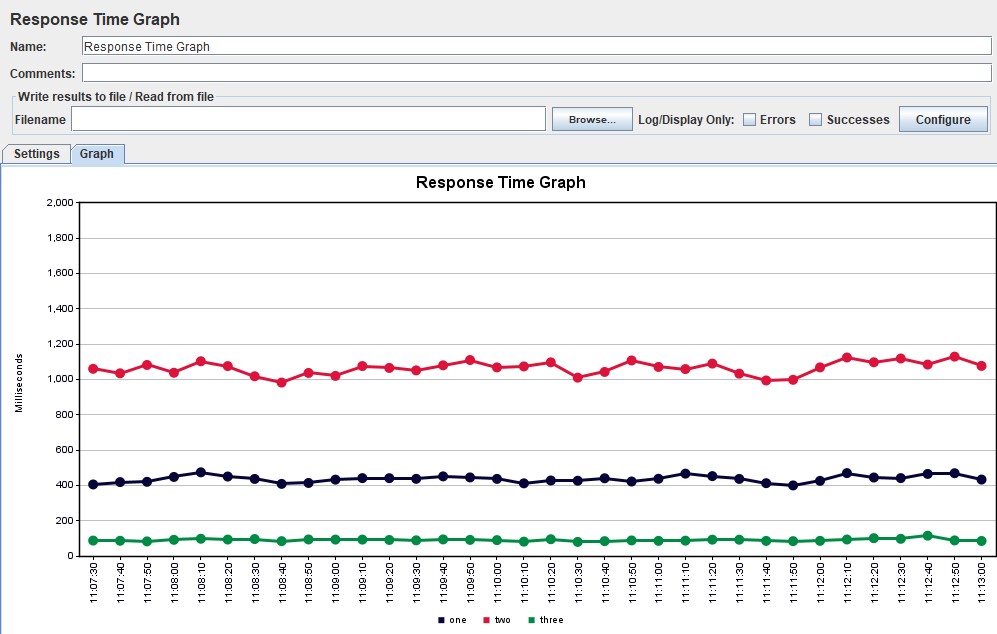 |
Вариации графика
Возможна модификация, в которой применяются перцентили времени отклика и добавляется линия среднего времени отклика по всем запросам. Использование перцентилей здесь будет более правильным решением, так как среднее время отклика очень чувствительно к резким выбросам.
В тестировании производительности чаще всего используется 95 и 99 перцентиль для большей наглядности. Однако, если вы все же смотрите среднее время отклика, вам стоит учитывать при этом стандартное (среднеквадратичное) отклонение.
| HTML Gatling Report | 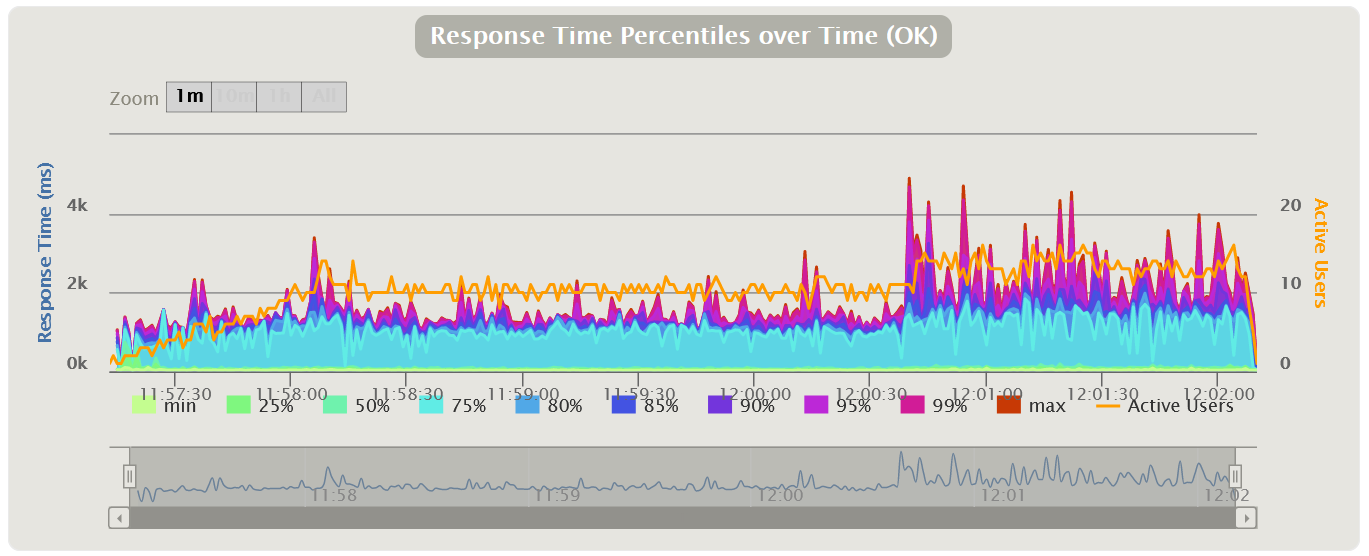 |
| Для MF LoadRunner график будет называться Transaction Response Time (Percentile) | 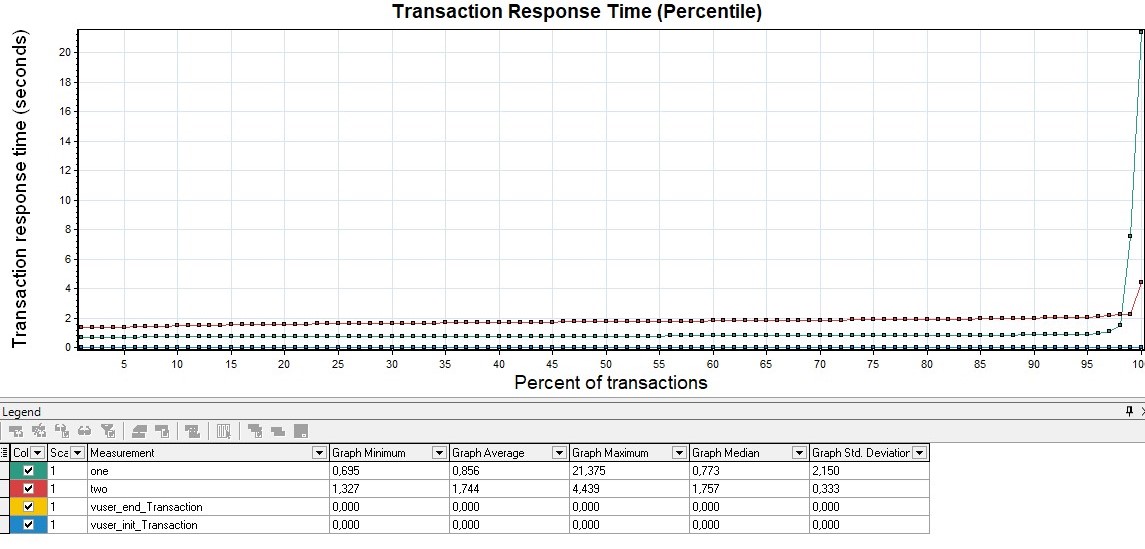 |
| Также вы можете получить и перцентили для Apache JMeter с помощью графика Response Times Percentiles из этого же расширенного набора | 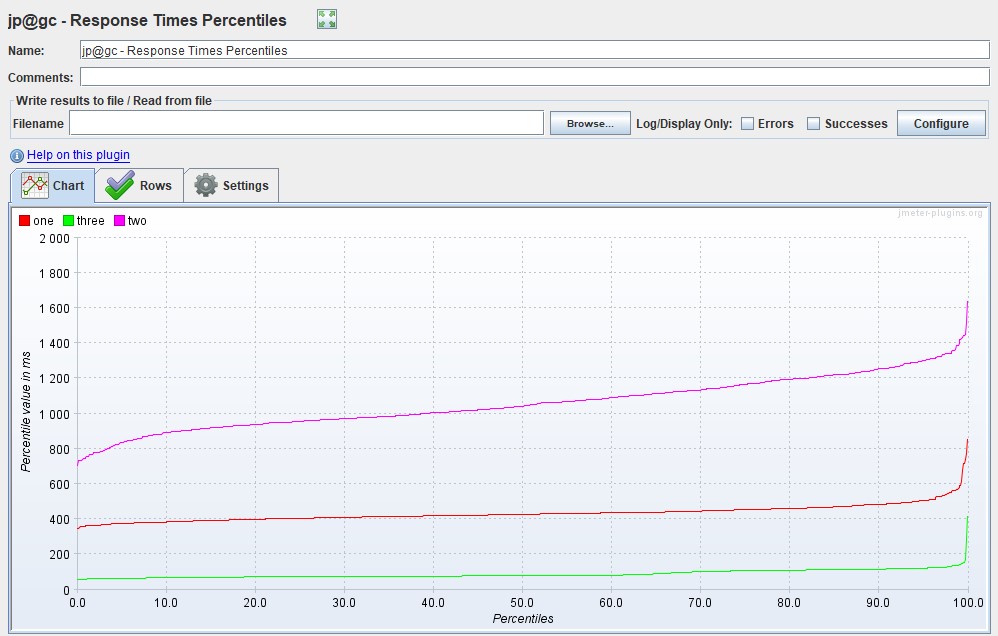 |
Распределение Response Time
Также есть прекрасные графики, показывающие зависимость распределения времени от количества запросов.
Этот вид графиков чем-то напоминает индикаторы, но показывает более полную картину распределения времени, без обрезки перцентилями или другими агрегатами. С помощью графика можно более наглядно определить границы для групп индикаторов. У MF LoadRunner такого графика нет.
| HTML Gatling Report для каждого запроса | 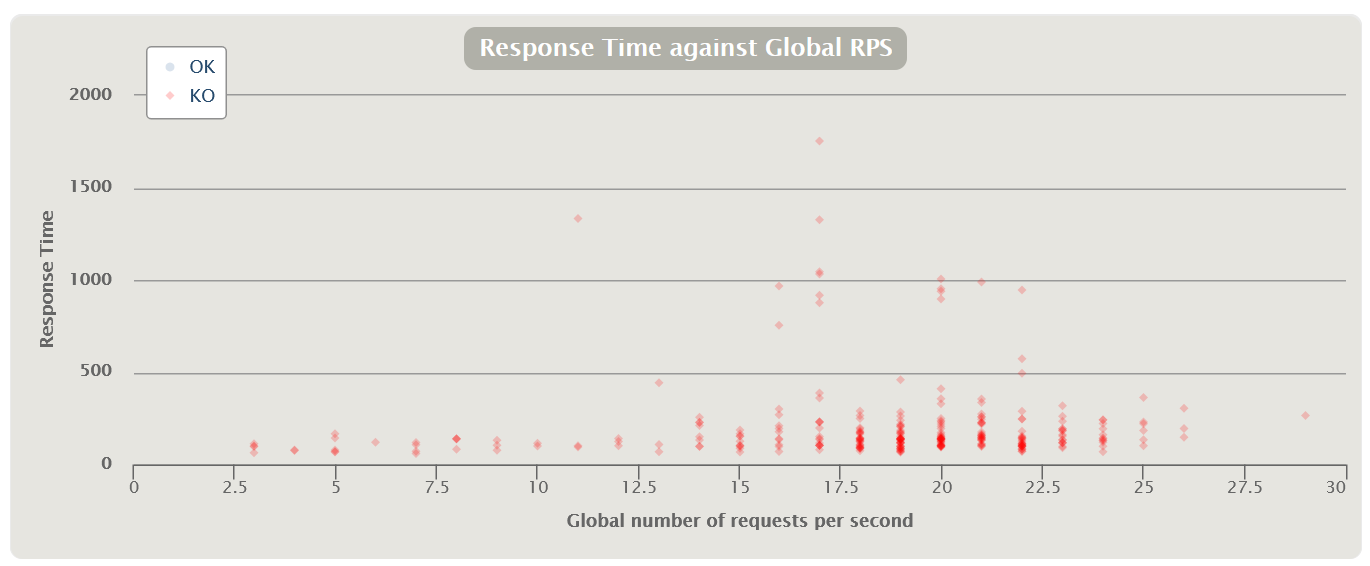 |
| Есть еще один вариант распределения времени выполнения запроса от количества запросов в разрезе успешных и ошибочных запросов для всего теста | 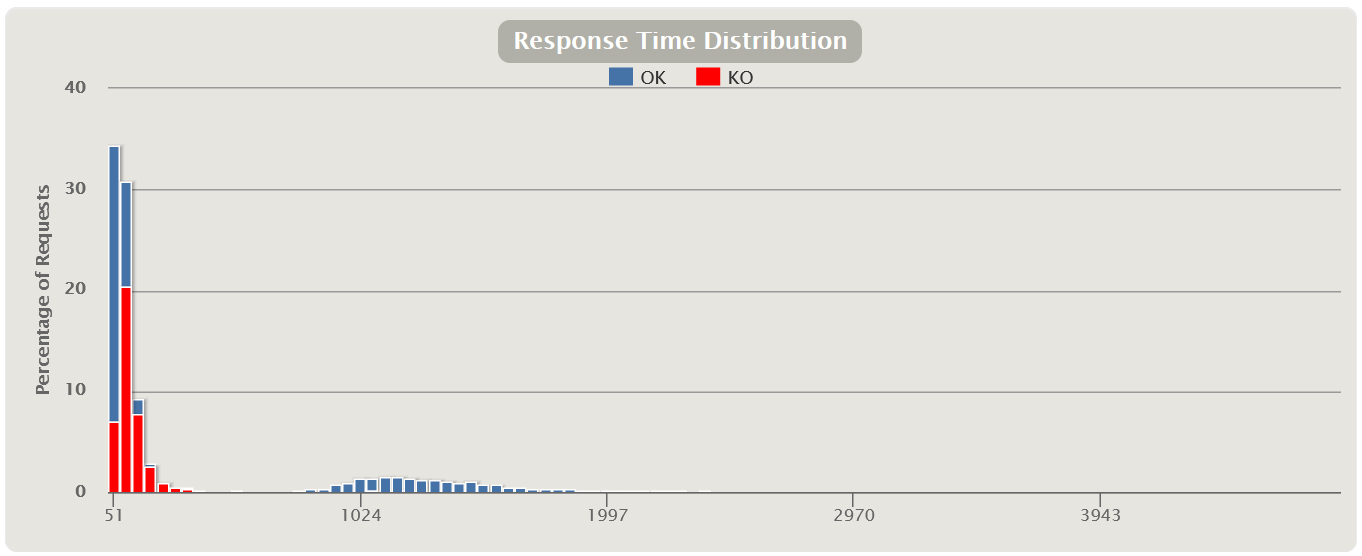 |
| Для MF LoadRunner данный график будет называться Transaction Response Time (Distribution) и показывать распределение для транзакций | 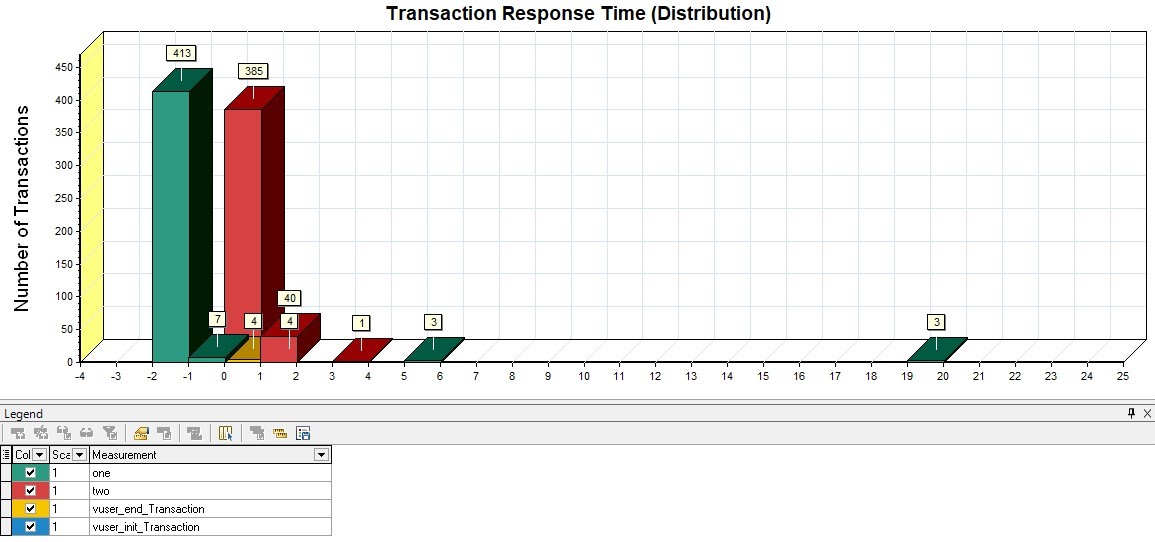 |
| В Apache JMeter тоже есть этот график в расширенном пакете и называется Response Times Distribution | 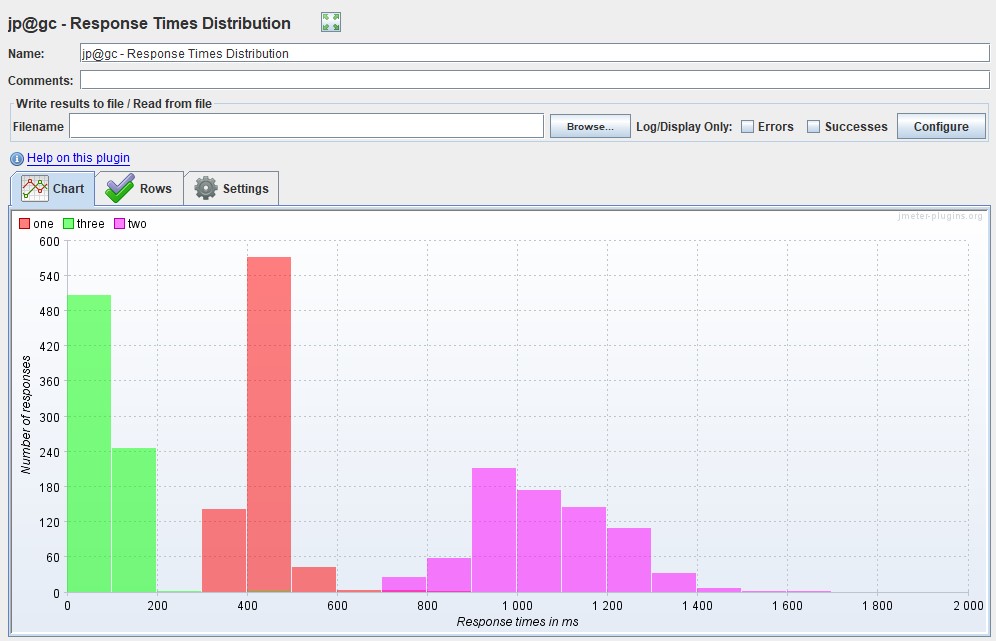 |
Latency
Из этой метрики также можно выделить дополнительный параметр Latency (миллисекунды) — время задержки (чаще всего под этим понимают Network Latency). Этот параметр показывает время между окончанием отправки запроса до получения первого ответного пакета от системы.
С помощью этого параметра можно измерять также задержки на сетевом уровне, если параметр будет расти. Желательно, чтобы он стремился к нулю. Этот и следующий тип графиков в основном используются при глубоком анализе и поиске проблем производительности. Этого графика из коробки нет в Gatling. В MF LoadRunner этот график называется Average Latency Graph в блоке Network Virtualization Graphs если у вас установленные агенты мониторинга.
| В Apache JMeter этот график присутствует лишь в расширенном наборе и называется Response Latencies Over Time |  |
Bandwidth
Аналогично метрике выше можно выделить параметр Bandwidth (килобит в секунду) — ширину пропускания канала. Он показывает, какой максимальный объем данных может быть передан за единицу времени.
Изменяя этот параметр на инструменте нагрузки можно моделировать различные источники подключений к приложению: мобильная связь 4G или проводная сеть. В бесплатной версии Gatling этого графика нет, он есть лишь в платной версии Gatling FrontLine. Этот график из коробки есть лишь в MF LoadRunner, находится в том же блоке, что и Latency, и называется Average Bandwidth Utilization Graph.
График Request Per Second
Измеряется в штуках в секунду — показывает количество запросов, поступающее в систему за 1 секунду.
График показывает, сколько запросов может выдержать ваша система под нагрузкой, и он является также основным графиком для построения отчета. По нему также отслеживается выход за пределы SLA, так как с ростом нагрузки при прохождении точки деградации или локальных экстремумов может наблюдаться провал, а затем резкий рост. Чаще всего это связано с тем, что, когда приложение начинает деградировать, запросы тоже начинают копиться на входе в приложение (появляется очередь), затем приложение выдает им какой-то ответ или запросы падают по тайм-ауту, что вызывает резкий рост на графике — ведь получен ответ.
- Если наложить график на VU, можно увидеть увлечение RPS/TPS с увлечением количества пользователей, а также уменьшение в связи с выходом пользователей или стабилизацией подаваемой нагрузки.
- Если наложить график Response Time, можно увидеть среднее время, за которое обрабатываются все транзакции или запросы на протяжении теста.
| HTML Gatling Report | 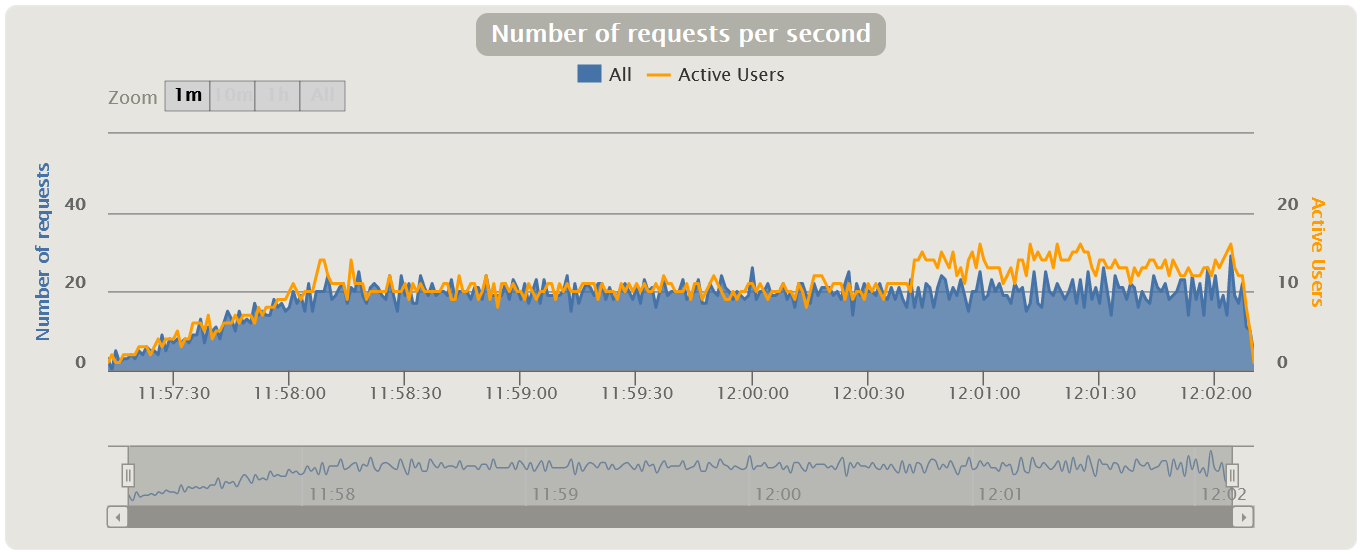 |
| В MF LoadRunner график называется Hits per Second | 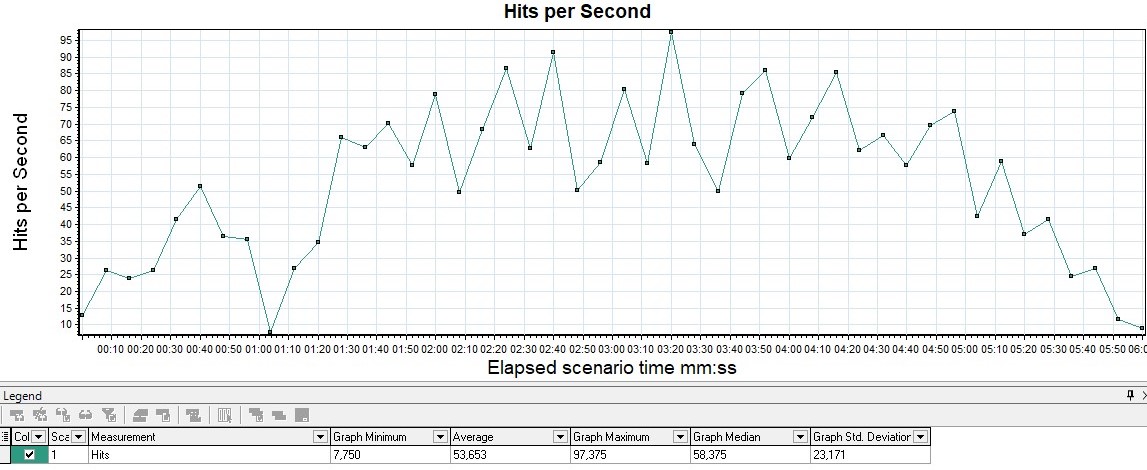 |
| Для Apache JMeter существует график Hits per Second из расширенного пакета | 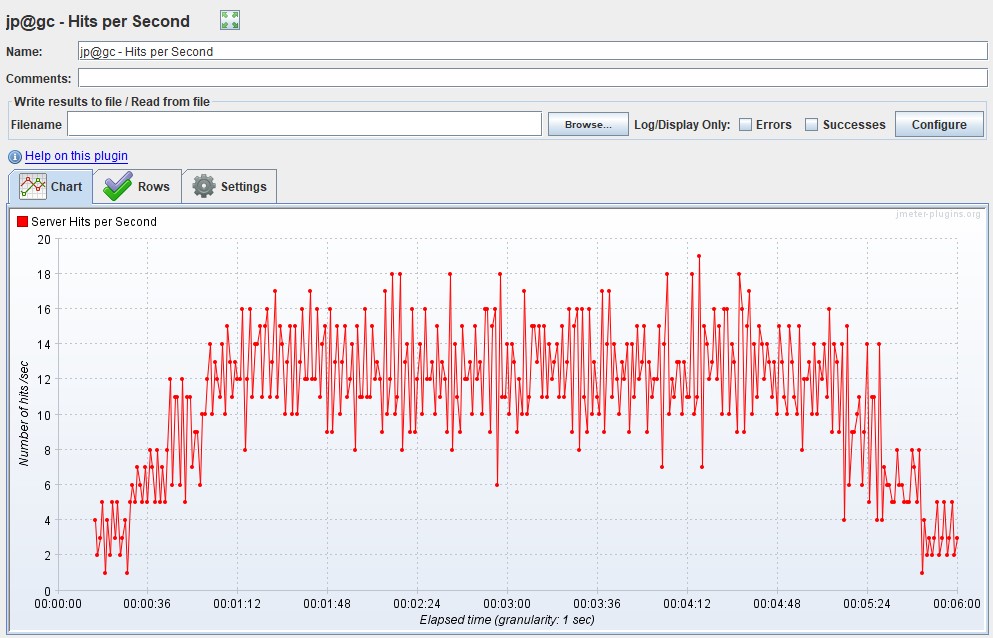 |
TPS
Измеряется в штуках в секунду и показывает количество транзакций (в рамках транзакции может быть множество запросов) за 1 секунду.
Например, транзакция «вход в личный кабинет» включает следующие запросы: открытие главной страницы, ввод логина, пароля, нажатие кнопки «отправить», переадресацию на приветственную страницу — в единицу времени. В Gatling график можно получить лишь с помощью применения Grafana, так как для групп в HTML-отчёте строятся графики лишь по времени отклика.
| MF LoadRunner — Transactions per Second | 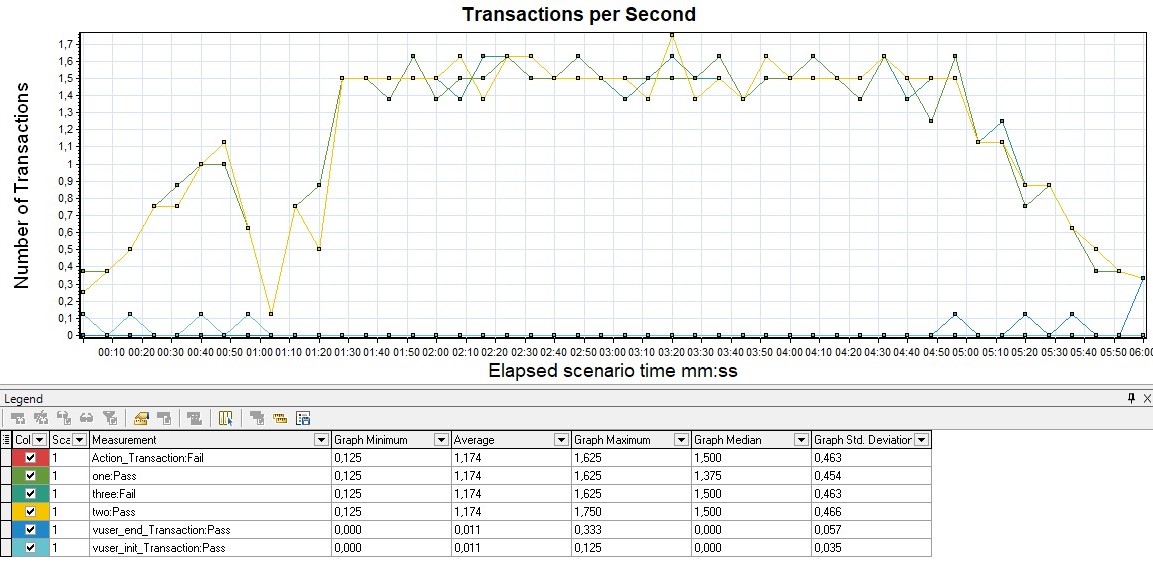 |
| Для расширенного пакета Apache JMeter — Transactions per Second | 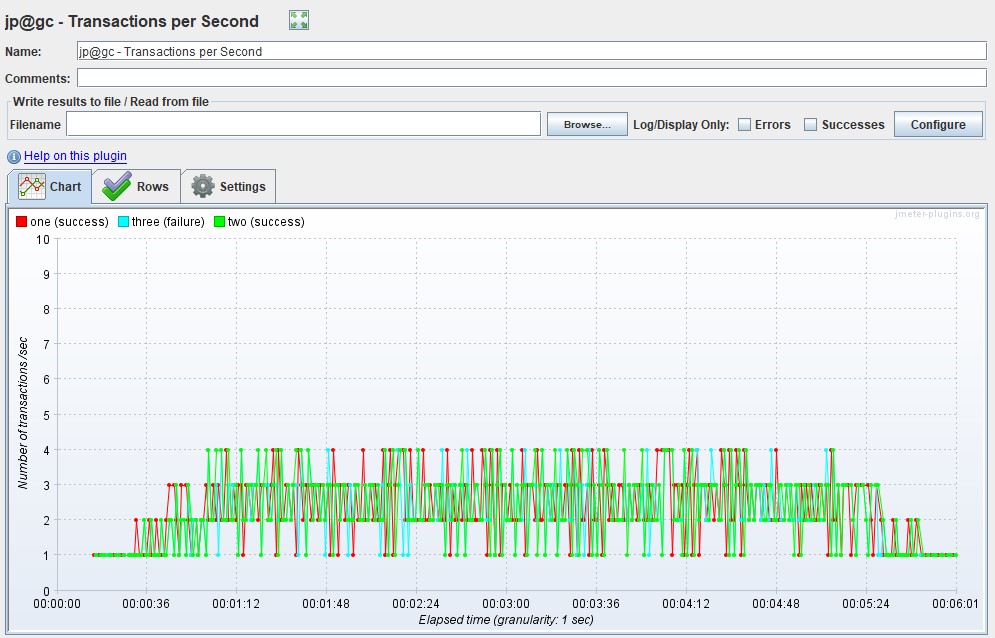 |
График Errors
Обычно измеряется в rate (штук в секунду) — график показывает рост количества ошибочных запросов. Также удобно измерять значение в процентах от общего числа запросов. По этому графику отслеживается выход за пределы SLA по количеству или проценту ошибок.
Если наложить график Response Time, можно увидеть, как увеличение ошибок влияет на рост времени ответа приложения.
Gatling по умолчанию не имеет отдельного графика, отображающего лишь ошибки. В Gatling он совмещен с графиком VU и сразу показывает, как рост нагрузки сказывается на росте числа ошибок, и помогает обнаружить порог, с которого идет превышение SLA или вообще появляются ошибки. В Apache JMeter также нет отдельного графика, он совмещен с графиками количества транзакций.
| HTML Gatling Report | 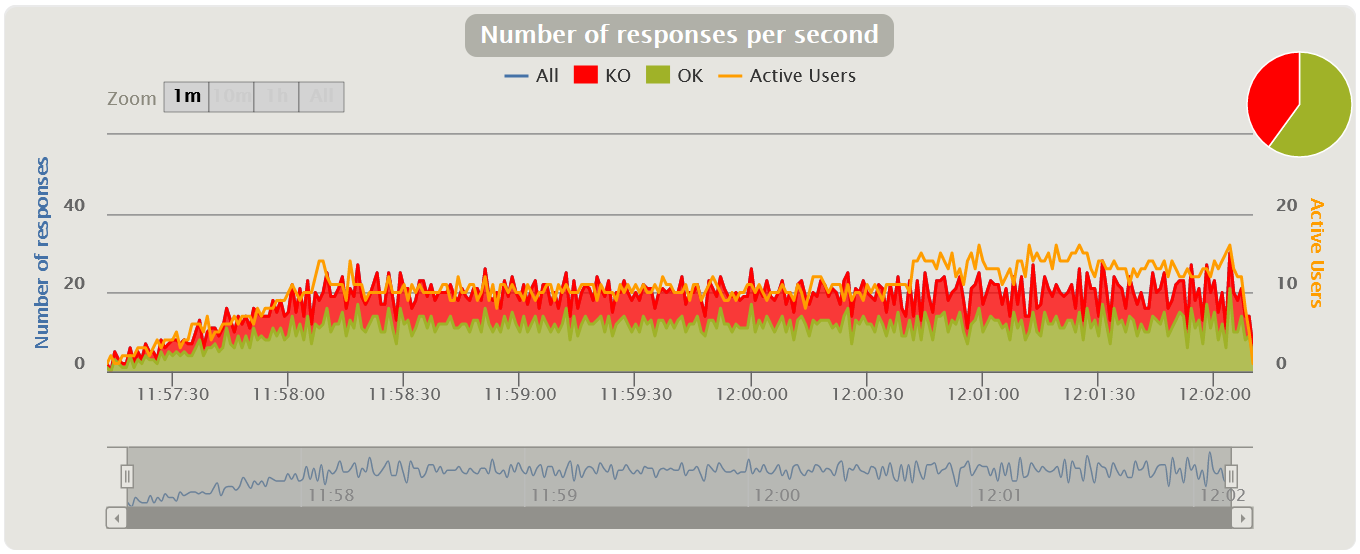 |
| В MF LoadRunner этот график называется Errors per Second | 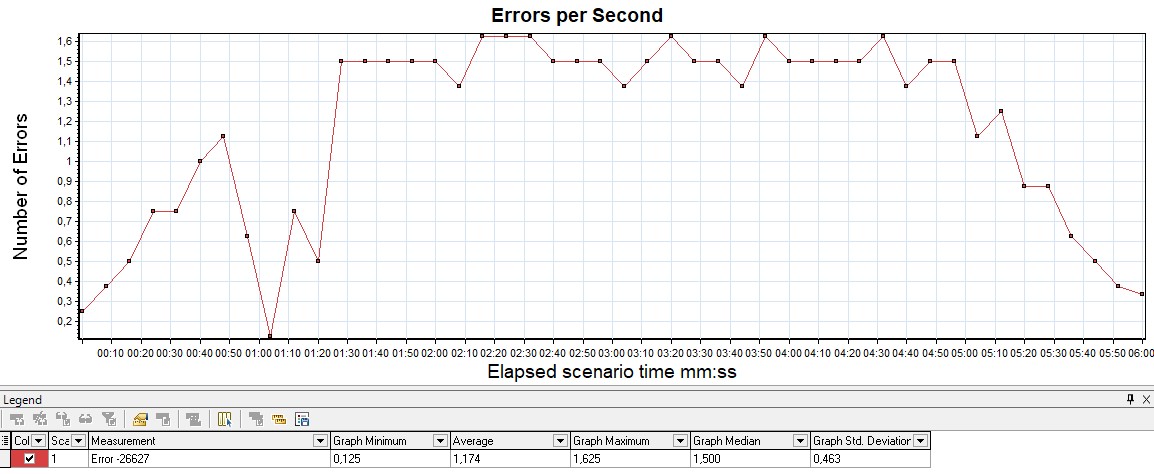 |
HTTP responses status
Возможно также выводить на график распределения количества ошибок по кодам ответа приложения — удобно использовать для классификации ошибок.
Например, если на предыдущем графике вы получили 100%, вы начинаете анализировать, а какие именно 50x ошибки из-за того, что сервер не отвечает, или 403 из-за того, что неверный пул и пользователи не могу авторизоваться, если, например, вы используете HTTP-протокол.
Изначально в бесплатной версии Gatling этого графика нет, он есть лишь в платной версии Gatling FrontLine. Чтобы график появился в бесплатной версии, необходимо перенастроить logback.xml так, чтобы логи собирались в graylog, и уже в нем строить нужный график.
| В MF LoadRunner этот график называется HTTP Responses per Second | 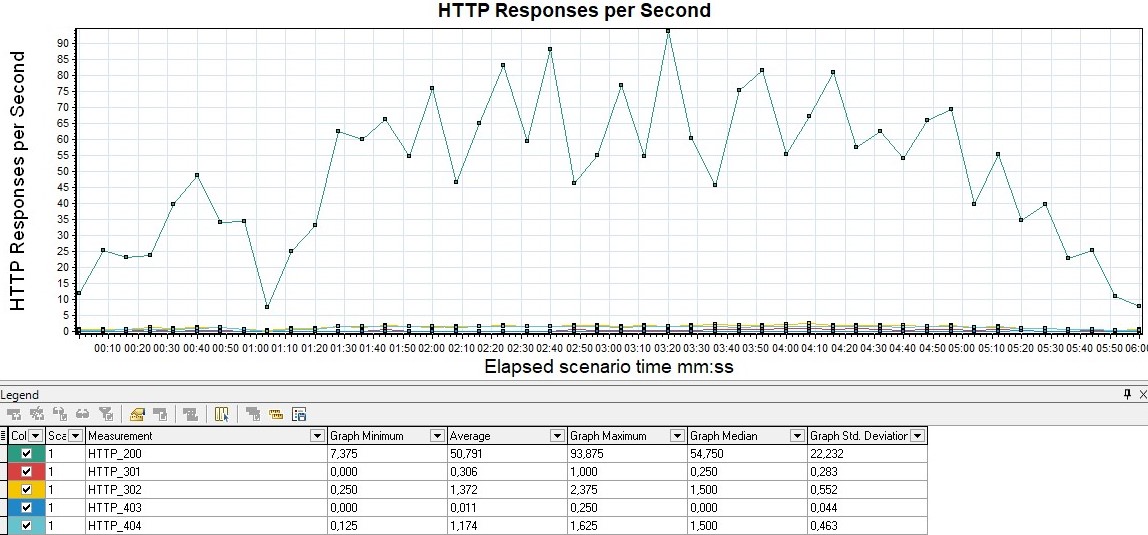 |
| В Apache JMeter этот график называется Response Codes per Second из расширенного пакета | 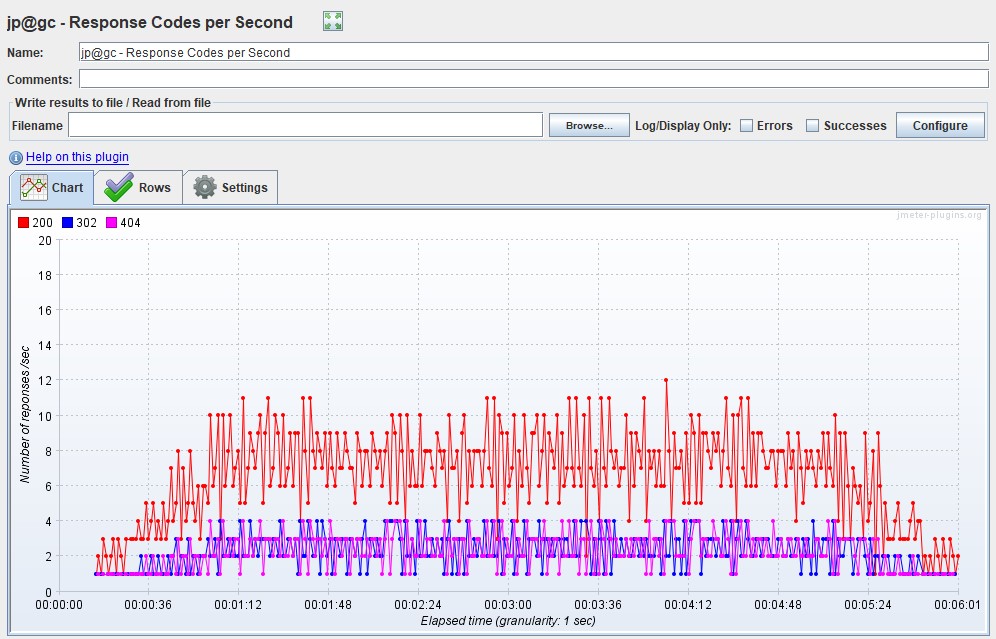 |
График Throughput
Измеряется обычно в битах в секунду. График показывает пропускную способность приложения, а именно какой объем данных был отправлен и обработан приложением в единицу времени.
Обычно его используют для глубокого анализа проблемы приложений. В Gatling этот график содержится лишь в FrontLine, в бесплатной версии его нет.
| Этот график есть из коробки в MF LoadRunner, он называется Throughput | 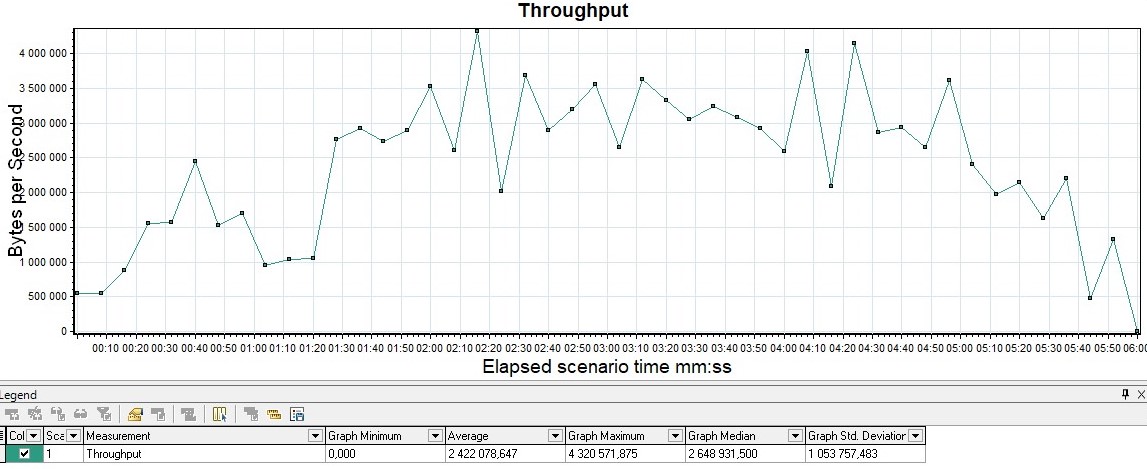 |
| В Apache JMeter график называется Bytes Throughput Over Time из расширенного пакета | 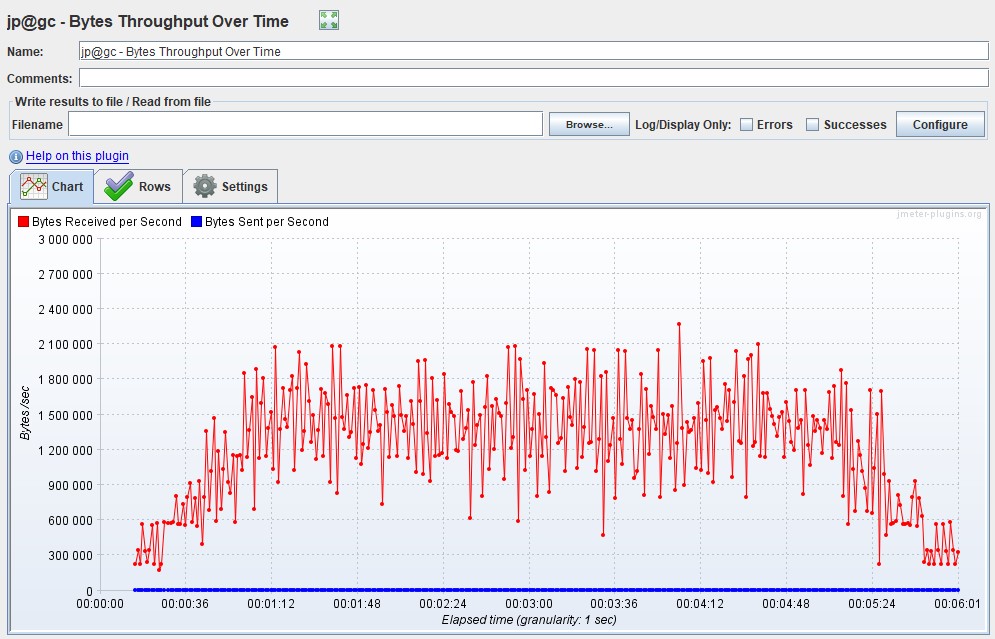 |
Возможные модификации
- Если наложить график Response Time, можно увидеть, что рост времени ответа часто связан с увеличением числа отправленных данных (Throughput). Если на графике замечен рост Response Time, а Throughput при этом остается прежним, это указывает на проблемы с сетью или с приложением: где-то начинает копиться очередь запросов.
- Если наложить график Bandwidth, то при совпадении объема данных на двух графиках будет видно, что ограничивающим фактором является пропускная способность сети.
- Если наложить график VU, то они должны полностью коррелировать, без резких скачков и провалов, так как рост нагрузки должен приводить к планомерному росту объема данных. Расхождения или резкие выбросы являются поводами для дальнейшего изучения.
Получение графиков
Большинство графиков можно получить, используя отчет HTML Based Gatling Reports после теста или же настроив связку мониторинга Graphite-InfluxDB-Grafana. Для отображения можно использовать готовый дашборд из библиотеки дашбордов https://grafana.com/grafana/dashboards/9935.
При анализе и составлении своих дашбордов для Gatling следует учитывать, что результаты в InfluxDB хранятся агрегированные и подходят только для предварительной оценки результатов НТ. Рекомендуется после теста повторно загрузить simulation.log в базу данных и уже по нему строить итоговый отчет и выполнять поиск проблем производительности системы.
Матричное описание метрик
Всё, что мы описали выше, представлено в виде маленькой таблички, суммирующей все эти знания.
| Тип | VU | Response Time | Requests | Errors | Throughput |
|---|---|---|---|---|---|
| VU | Позволяет сравнить планируемую нагрузку с реальной | Показывает, как увеличение пользователей сказывается на росте времени отклика при закрытой модели | Можно увидеть увеличение RPS/TPS/HITS с увеличением количества пользователей, а также уменьшение в связи с выходом пользователей или стабилизацией подаваемой нагрузки | Показывает, при каком числе VU происходит рост ошибок. Не всегда показателен, так как в открытой модели сложно коррелировать графики | Метрики должны полностью коррелировать, так как рост пользователей приводит к росту объема данных, отправляемых ими. Расхождения или резкие выбросы являются поводами для дальнейшего изучения |
| Response Time | Показывает, как быстро сервер отвечает на наши запросы. Основная метрика | Показывает среднее время, за которое обрабатываются все транзакции или запросы на всем протяжении теста | Можно увидеть, как увеличение ошибок влияет на рост времени ответа приложения | Рост времени ответа часто связан с увеличением количества отправленных данных (Throughput). Если на графике замечен рост Response Time, а Throughput при этом остается прежним, это указывает на проблемы с сетью или с приложением: где-то начинает копиться очередь запросов | |
| Requests | Показывает, сколько запросов выдерживает система в секунду, минуту и т. д. | Позволяет найти значение интенсивности, после которой появляются ошибки. Удобно для определения SLA | Позволяет контролировать рост объема данных и количества запросов. Эти метрики должны коррелировать. Появление проблем может свидетельствовать, что мы отправляем неверные запросы | ||
| Errors | Позволяет оценить рост числа ошибок и тип ошибок, которые проявляются под нагрузкой | Можно найти объем данных, при котором приложение начинает генерировать ошибки | |||
| Throughput | Показывает, какой объем данных приложение может прокачать через себя за заданный промежуток времени |




