
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!

Поиск вакансий
У меня есть привычка накапливать и изучать разные данные, до которых удается дотянуться. В этот раз настала очередь перечня вакансий специалистов по качеству данных (Data Quality, DQ, КД) с hh.ru. Ссылки собирались в течение 2023 года, поэтому среди них есть как открытые, так и уже закрытые вакансии.
Вот фильтр для поиска по названию в Москве
(качество данных) OR (data quality) OR (data governance) OR (управление данными)По нему за период с марта по октябрь 2023 было найдено 471 уникальных URL. Запрос охватывает и другие вакансии, например, на позиции экспертов по управлению данными. Поэтому ориентируясь на заголовки и содержимое вакансий, я постарался очистить выборку и оставить только вакансии, напрямую относящиеся к направлению качества данных. Все, что осталось (141 ссылка), +/- укладывается в более подходящий фильтр
(качество данных) OR (data quality)Но он тоже не идеален. Вот пример не подпадающей под условие вакансии Data Governance специалиста, которую можно отнести к DQ: https://hh.ru/vacancy/83703097. Также по такому фильтру по-прежнему выводятся неподходящие вакансии: консультанты и presale с более широким функционалом, специалисты по нормативно-справочная информация</p>" data-abbr="НСИ">НСИ, а также разработчики DQ-инструментов. Сюда же попадают вакансии, в названии которых просто встречаются эти слова, например, "Аналитик данных (анализ качества логистики)". Запрос можно улучшить, если включить поиск по тексту вакансии и настроить исключения. Примеры таких запросов можно посмотреть в статье: Анализ вакансий ИТ в Москве: системное администрирование, 2023г
В итоге получаем список вакансий, который включает в себя аналитиков качества данных (DQA), инженеров по качеству данных (DQE), менеджеров по качеству данных (DQM), руководителей направления, тимлидов, экспертов и специалистов. Причины такого разнообразия должностей кроются в их обязанностях, которые разбираются ниже.
Ссылка на список вакансий
https://github.com/BogdanPetrov/dq_vacancies/blob/main/dq_vacancies.txt
Наверняка в этом списке есть что-то лишнее и чего-то не хватает. На общую картину эти недочеты никак не повлияли.
Сбор датасета
Со списком ссылок далеко не уедешь, поэтому дальше пришлось задуматься, как составить набор данных, чтобы с ним было удобно работать и получить нужные результаты.
Конечный вид представлялся примерно таким:
[
{
'title': "Аналитик качества данных",
'company': "Крупный банк",
'description': "Ищем коллегу, который поможет навести порядок и прозрачность в данных и будет связующим звеном между дата-аналитиками, дата-инженерами и разработкой.",
'responsibilities': [
"Организация и выполнение работ по качеству данных",
"Разработка стандартов и процедур контроля качества данных",
"Поддержка и развитие проверок качества данных",
"Ежедневный контроль качества данных в хранилищах"
],
'requirements': [
"Критическое мышление",
"Стрессоустойчивость",
"Усидчивость",
"Гибкость мышления",
"Продвинутые навыки решения проблем",
"Склонность к анализу"
]
}
]
Превратив список ссылок в набор html-файлов, я начал думать, как извлечь из них обязанности и требования. Уверен, что если бы я тратил свое время не на подобные занятия, а на изучение методов машинного обучения, то смог бы сделать это в 10 строчек кода. Но копипастить со 141 страницы — тоже не вариант. Пришлось половину работы автоматизировать, а другую половину доделать вручную.

Вся вакансия разбивается на блоки. Границы блоков определяются таким образом, чтобы последним элементом блока был список. Блок может не содержать списка только в двух случаях: если это последний блок вакансии либо если в вакансии нет ни одного списка. Дополнительно в блоке могут присутствовать еще два элемента: предваряющий текст (синий блок на картинке) и строка перед списком (заголовок списка, красный блок).
Разбивка на блоки была выполнена нехитрым скриптом. А вот классификация каждого блока — уже вручную. Это было несложно, так как заголовки списков говорят сами за себя.

Всего получилось 4 вида блоков: обязанности, требования, условия и остальное (например, какая-то информация о самой компании или проекте).
Типичные заголовки блоков
Обязанности: вам предстоит / вы будете / задачи / обязанности / чем необходимо заниматься
Требования: для нас важно / ждем от вас / мы ожидаем / наши пожелания / необходимые навыки / требования / будет плюсом / будет преимуществом
Условия: мы предлагаем / условия
Таким образом, для каждой вакансии удалось получить и требования и обязанности.
Компании
С собранным датасетом дело пошло веселее. Прежде чем переходить к самой сути, обязательно нужно взглянуть на работодателей, чье виденье специальности будет отображено в результатах.
Всего получилось 48 компаний (экосистему Сбера посчитал за одну, извините), ниже мое очень условное деление на категории:
16 банков и страховых компаний (63 вакансии)
9 IT-компаний (13 вакансий)
7 ритейл (24 вакансии)
6 IT-подразделений не IT-компаний, в том числе добывающих (20 вакансий)
3 телекома (5 вакансий)
3 государственных конторы (8 вакансий)
2 интегратора (5 вакансий)
2 HR-агентства (3 вакансии)
По количеству вакансий наиболее выделяются Самолет, X5, ВТБ, Сбер, МТС Банк.
При беглом взгляде с этой статистикой можно не согласиться, так как представлено слишком мало компаний. Я попробовал посмотреть, почему так получается. Часть компаний, которые раньше нанимали DQ-специалистов, теперь выставляют другие вакансии: либо более специализированные, либо более широкого профиля по управлению данными. У некоторых компаний при развитой программе руководства данными кажется, что нет отдельных позиций аналитиков по качеству данных. Это в том числе намекает на то, что не стоит концентрироваться исключительно на одном сегменте DMBOK</p>" data-image="https://habrastorage.org/getpro/habr/upload_files/283/539/845/28353984569bfc8b5a03692d73f4e240.PNG" data-abbr="круга DAMA" data-image-width="317" data-image-height="325">круга DAMA, описание которого в книге занимает 60 страниц. Нужно либо усиливать свою позицию техническими компетенциями, либо охватывать соседние сектора (управление метаданными, дата-каталог, мастер данные и НСИ и т.д.).
Требования
На входе получилось 480 уникальных формулировок, но многие дублируют друг друга по смыслу. Не стал детально рассматривать требования к образованию и опыту работы. Понятно, что приветствуются опыт работы по специальности и высшее образование. В некоторых требованиях не отражена специфика DQ:
Примеры универсальных требований
Аналитический склад ума
Английский
Гибкость мышления
Желание развиваться
Критическое мышление
Усидчивость
Опыт работы в команде
Продвинутые навыки решения проблем
Знание лучших практик анализа данных
Навыки работы с Jira и Confluence
Системное мышление
Склонность к анализу
Способность понятно излагать мысли
Совсем нерелевантных требований я не обнаружил, так как предварительно просеивал вакансии.
Резюмируя, получаем:
SQL, Python, Git
Опыт работы с СУБД: Oracle, MS SQL, PostgreSQL, ...
Понимание принципов и знание методологий DWH, DG (DAMA), ETL, DataOps
Опыт анализа и обработки данных, знание матстатистики: поиск аномалий, профилирование, EDA (разведочный анализ данных)
Развитые коммуникативные навыки
Навыки работы с BI-инструментами
Опыт работы с большими данными: Hive, Spark, Greenplum, Teradata, ...
Опыт работы с коробочными решениями: IBM, SAS, Informatica, Ataccama, ...
релевантный опыт работы и соответствующие навыки (см следующий пункт про обязанности)
понимание предметной области
дополнительный бэкграунд с уклоном в руководство данными (DG), аналитику данных (DA), системную аналитику (SA), бизнес-аналитику (BA), дата-инженерию (DE), тестирование (QA) или эксплуатацию
Думаю, что в дополнительных комментариях эти требования не нуждаются. Отдельно я бы отметил две формулировки, которые как-то выделяются на фоне остальных и близки лично мне:
Наличие софт-скиллов для достижения договоренностей с поставщиками данных
Понимание ценности качественных данных для бизнеса
Обязанности
Всего на входе получилось 458 сформулированных обязанностей и задач. Примерно четверть из них слишком размыты или не имеют отношения к качеству данных. Они были исключены. Оставшиеся я разделил на категории, которые затем изобразил на двух диаграммах.
Примеры исключенных из рассмотрения обязанностей
Участвовать в проектировании архитектуры решений, генерировать идеи
участие в разработке корпоративной архитектуры данных
создание витрин данных
Соблюдать лучшие практики анализа и сбора данных
Проверка методологии на работоспособность
Проведение системного и бизнес анализа
Дорабатывать, рефакторить и поддерживать текущий код
Автоматизировать процессы по работе с данными
На первой диаграмме отображены обязанности, связанные с внедрением, развитием и поддержкой практики DQ в целом. Они включают в себя:
разработку стратегии, стандартов, политик, регламентов, методологий, чек-листов, а также определение SLA
выбор и развитие DQ-инструмента
подготовку отчетов и презентаций по качеству данных
консультирование, обучение, развитие культуры работы с данными

На второй диаграмме отображены виды операционных задач по управлению качеством данных, которые в свою очередь делятся на меры по обеспечению текущего уровня качества данных и меры по повышению уровня качества данных до целевого значения.

И конечно, все эти активности дополняются и связаны между собой коммуникациями со всевозможными заинтересованными и ответственными лицами, среди которых: представители бизнес-подразделений, потребители данных, аналитики, разработчики, архитекторы, команды эксплуатации.
Для сравнения, вот как выглядит контекстная диаграмма в DAMA DMBOK 2

Заключение
Целью данной работы был не процесс, а результат, которым я был рад поделиться. Мне было интересно сформировать и посмотреть на усредненные (а точнее, просуммированные и почищенные) требования и схему обязанностей, в которые хорошо укладываются изученные мной вакансии на позицию DQ-специалиста.
Приложения и бонусы
О попытках применить методы NLP
После того, как все обязанности сложились в единую картинку, я подумал, что теперь можно попробовать с помощью методов NLP присвоить каждой формулировке вектор и отобразить это при помощи чего-то наподобие t-SNE. Вообще говоря, я ожидал, что как в лучших гайдах интернета, мои вектора красиво разложатся на несколько изолированных групп, каждая из которых будет соответствовать элементам диаграммы. Это бы подтвердило, что классификация проведена корректно.
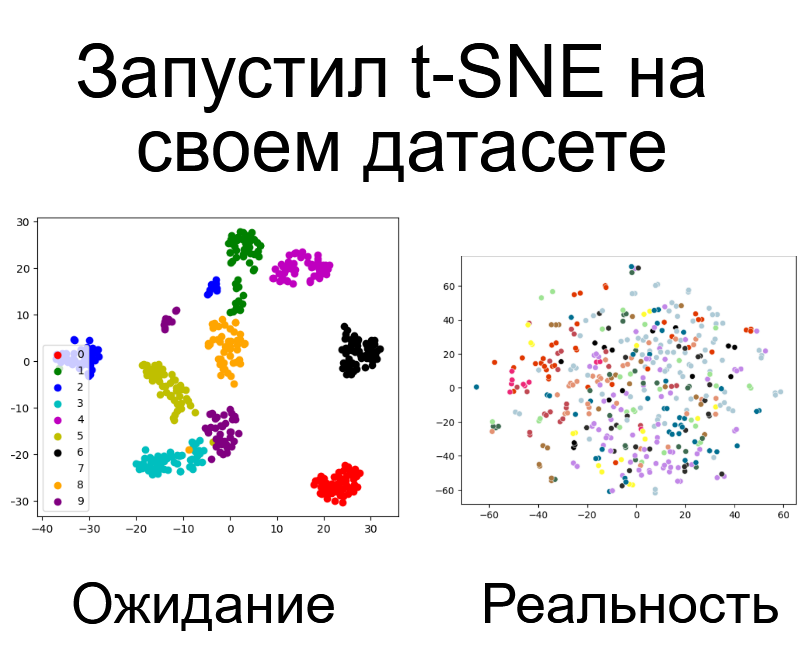
Как видно, получилось не особо. Скорее всего это связано с тем, что во-первых, повторяющимися словами выражаются разные по своей сути работы, а во-вторых, одинаковые задачи формулируются совершенно разными словами. Возможно, что уловить эти тонкости может модель типа GPT-4, но проверять это я не планирую.
В блокноте есть пример обработки текста и визуализации полученных векторов в TensorBoard: https://github.com/BogdanPetrov/dq_vacancies/blob/main/06_embeddings.ipynb

С облаком слов получилось лучше, но для этого текст пришлось также немного обработать: https://github.com/BogdanPetrov/dq_vacancies/blob/main/03_wordcloud.ipynb

Советы по обработке и очистке данных по вакансиям
Нечеткий поиск работает по-умолчанию
У hh.ru есть функция отправки новых вакансий по фильтру в Telegram
Вакансии могут быть на английском языке: https://hh.ru/vacancy/76706470
Вакансии могут дублироваться, то есть по разным ссылкам будут одинаковые тексты, см пример: https://hh.ru/vacancy/80903353 и https://hh.ru/vacancy/86454274
Текст вакансии может быть отредактирован, именно поэтому в моей датасет просочились вакансии, которые раньше относились к DQ, а потом превратились, например, в Python-разработчика: https://hh.ru/vacancy/86548460
Вакансия может быть недоступна: https://hh.ru/vacancy/81190478
Списки могут задаваться не только разметкой, но и просто символами или цифрами: https://hh.ru/vacancy/76765451
Дополнительные требования могут идти отдельным блоком (плюсом будет, преимуществом будет): https://hh.ru/vacancy/80903353
В большинстве вакансий первый блок — это обязанности, а второй и иногда третий — требования. Однако бывает по всякому и закладываться не это не стоит. Также могут получиться вакансии, в которых по какой-то причине не оказалось блоков с требованиями или обязанностями (сложности парсинга или классификации).
Извлечение требований и обязанностей можно автоматизировать
Из вакансий можно вытащить больше информации, чем я использовал для этой статьи (длительность размещения вакансии, оклад, условия работы, уровень позиции и т.д.)
Пункты пользовательского соглашения hh.ru, на которые следует обратить внимание
https://hh.ru/account/agreement
5.1 Используя Сайт, Соискатель обязуется не нарушать или пытаться нарушать информационную безопасность Сайта, что включает в себя:
5.1.6. использование или попытки использования любого программного обеспечения, или процедуры для навигации или поиску на Сайте, кроме встроенной в Сайт поисковой машины и традиционных и общедоступных браузеров (Microsoft Explorer, Mozilla Firefox и других подобных).
5.1.7. использование программных средств, имитирующих работу Соискателя на Сайте, в т.ч. в приложении Исполнителя.
9.4. При перепечатке и ином использовании материалов Сайта, не являющихся Резюме Соискателей, описаниями компаний или вакансий, а также логотипом, элементами дизайна, внешнего вида и структуры Сайта, ссылка на Сайт обязательна.
9.5. Использование Резюме/Видеорезюме Соискателей, описаний компаний и вакансий недопустимо ни с какими целями, кроме соответствующих тематике Сайта (поиск работы и иных видов занятости, сотрудников, получение информации о рынке труда). Запрещается использование на Сайте плагинов, осуществляющих парсинг/копирование, а также любое копирование информации, не связанное с процессом поиска работы и подбора персонала.
9.7. Не допускается использование программных средств (скриптов, роботов) для считывания или сбора информации (данных) с Сайта.
Подборка хабрастатей по качеству данных и смежным темам
Философия SLA: что такое эскалация и зачем она нужна
Как следить за тысячей метрик и не сойти с ума. Без программирования (почти)
Контроль качества данных и точка. Как мы строили модуль DQM с нуля
Промышленный мониторинг качества данных в Feature Store. Предпосылки и реализация
Как не перестать быть data driven из-за data driften, или Пару слов о дрейфе данных
Чтобы не терять деньги: оповещения о падениях продуктовых метрик
Страдающее ML: как мы автоматизировали проверку данных, чтобы не было мучительно больно
Как быстрее узнать, что сервису плохо, или Realtime-детекция разладок с помощью CatBoost


. Кэширование — нужно или нет?")

