
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Для программистов настали тяжёлые времена. Хотя Утечка Памяти была уничтожена valgrind-ом, оставшиеся силы UB преследовали программистов по всей галактике.
Избегая встречи с грозными знаковыми переполнениями, группа борцов за свободу, ведомая Кириллом Бриллиантовым, Глебом Соловьевым и Денисом Лочмелисом, обустроила новый секретный репозиторий.
Тёмная владычица UB неинициализированная переменная, одержимая желанием сломать все программы галактики, разослала тысячи раздражающих ошибок в самые далекие уголки космоса…
Мы — трое студентов бакалавриата «Прикладная математика и информатика» в Питерской Вышке. В качестве учебного проекта во втором полугодии мы решили написать UB-tester — анализатор кода на С++.

Реальная история: контест идет, времени остается мало, кодить задачки надо быстро. Именно в тот момент, когда разум участника охвачен быстрыми алгоритмами и тикающими секундами, С++ начинает выходить из-под контроля. В итоге программист старательно и очень долго ищет ошибку в реализации алгоритма, в неразобранном крайнем случае,в себе. Но пропускает случайно набранный неправильный индекс при обращении к массиву, неожиданное переполнение при арифметических операциях или заезженную неинициализированную переменную: ошибку или опечатку непосредственно в коде.
С такой ситуацией каждый из нас сталкивался лично. Поэтому в качестве проекта по С++ мы решили создать инструмент, с помощью которого будет удобно находить такие ошибки.
Нам предстояло выбрать основной метод обнаружения ошибок. Источником вдохновения послужил достопочтенный С-шный макрос — assert. Если программист регулярно проверяет инварианты с помощью assert-а, то поиск ошибки при отладке становится намного более локализованной и простой задачей. Но вряд ли кто-то в здравом уме использовал бы такую проверку постоянно, обращаясь к массиву или складывая два int-а. Мы решили создать инструмент, который будет анализировать пользовательский код, а затем заменять ошибкоопасные места на написанные нами обертки, в случае чего выбрасывающие пользователю подробный лог ошибки. К примеру:

Пример: программа, складывающая два числа типа int, может вызывать UB при переполнении знакового числа, а ее обработанная версия — нет.
Безусловно, производить такие замены в исходном коде пользователя далеко не вежливо, поэтому результатом работы нашей программы является новая версия оригинального кода со вставленными обертками.
Такой подход к обнаружению ошибок оказался удачным или, по крайней мере, интересным. Пользователь получил возможность автоматически тестировать свою программу на предмет простых UB — без лишних усилий и затрат времени.
Финальной версии не было суждено стать новым valgrind-ом, а функционалу — покорить сердца миллионов, но процесс разработки оказался весьма захватывающим. Про это мы и расскажем далее.
Первым шагом работы ub-tester является нахождение всех ошибкоопасных мест в программе. Парсить код на C++ вручную и с нуля — путь в могилу (или по крайней мере в отдельный проект), поэтому нам предстояло подобрать инструменты для решения этой задачи. Пожалуй, самым известным и наиболее практичным инструментом по разбору исходного кода на плюсах является clang, поэтому мы выбрали его в качестве основы для нашего проекта. Сlang — большая библиотека, поэтому остановимся только на важных для понимания статьи понятиях.
Сперва стоит сказать об AST (Abstract Syntax Tree). Это структура данных — дерево (как можно было догадаться из названия), внутренние вершины которого соответствуют операторам языка, а листья — операндам. Вот пример AST для простой программы.
Исходный код:
AST:

Описанная абстракция и используется в clang-е для представления исходного кода. Такой структуры данных достаточно для обнаружения ошибкоопасных мест. К примеру, чтобы найти в программе теоретически возможные index out of bounds, нужно изучить все вершины AST, соответствующие операторам обращения к массиву по индексу.
Теперь дело остается за малым: получить доступ к AST. В clang-е существует несколько механизмов для решения этой задачи. Мы пользовались Visitor-ами.
В clang-е реализован базовый класс RecursiveASTVisitor, осуществляющий дфсный обход AST. Каждый Visitor должен от него наследоваться, чтобы уметь путешествовать по дереву. Далее, чтобы выполнять специфичные для определенных вершин операции, класс-наследник должен иметь набор методов вида Visit***, где *** — название узла AST. Оказываясь в вершине дерева, Visitor вызывает соответствующий ее названию метод Visit***, затем рекурсивно спускается в ее детей. Таким образом, чтобы создать своего Visitor-а, достаточно реализовать методы обработки конкретных вершин.
Вот пример небольшого класса, который посещает все бинарные операторы и выводит на экран их местоположения в коде.
Теперь можно со спокойной душой переходить к следующему пункту: к замене участков исходного кода.
Сразу скажем, что, вероятно, мы избрали далеко не лучшее решение этой задачи. Мы разработали класс CodeInjector, который
Другое решение — использовать уже готовый инструмент для рефакторинга кода (класс Rewriter) внутри clang-а. Почему же мы от него отказались? Проблема в том, что иногда нужно изменять один и тот же участок кода несколько раз: на одну и ту же позицию в коде может прийтись сразу несколько ошибкоопасных мест, что потребует нескольких замен.
Простой пример. Есть такое выражение:
Пусть мы сначала захотим поменять сложение на ASSERT_SUM, получим следующее:
Кроме того, мы хотим проверить, что не произойдет выход за границы массива. Снова обратимся к этому же участку кода:
Наши Visitor-ы работают в полном неведении друг о друге, поэтому организовывать им сложную коммуникацию, чтобы они могли совершать замены, как-то договариваясь, категорически неудобно. Поскольку некоторые замены можно производить только последовательно и с постоянно разрастающимися операндами, то встроенный инструмент clang-а не сможет помочь — он не поддерживает такой функционал.
Мы заметили, что схемы замен состоят из чередования кусков, которые мы оставляем, и кусков, которые мы заменяем. Проиллюстрируем на примере: выражение: arr[1+2]. В нем есть два ошибкоопасных места: обращение к массиву и операция сложения. Должны произойти следующие замены:
Далее мы, внутри команды, договорились об интерфейсе для взаимодейстия с CodeInjector-ом, основанном на этой идее.
Все готово! Можно приступать к самому интересному — работе с конкретными видами UB.
Наша программа ориентирована на поиск и выявление UB, а также операций в коде, результат которых может быть не совсем очевидным для пользователя. К таким относятся, например, неявные преобразования во время вычисления арифметических выражений.
Основные ошибки, выявляемые нашей программой:
Подробно про некоторые аспекты функционала мы расскажем далее.
Известнейшие представители UB арифметике — целочисленные переполнения в самых разных операциях. Есть и более изощренные UB, которыми могут похвастаться, например, остаток от деления и особенно битовые сдвиги. Кроме того, часто можно встретить составные операторы присваивания (+= и другие) и операторы инкремента/декремента. Во время их использования происходит целая цепочка неявных преобразований типов, которая и может повлечь крайне неожиданный и нежеланный результат. Да и неявные касты сами по себе могут служить большой бедой.
Так или иначе, общее правило для всех UB в арифметике — их сложно найти, легко проглядеть (никаких segfault-ов!) и невозможно простить.
Важно: впредь и далее речь пойдет про стандарт С++17, на который и ориентирован ub-tester. Он также поддерживает C++20, но из-за того, что в нем исчезли некоторые виды UB в арифметике (а новых не добавилось), про него говорить не так интересно.
Мы много работали с целочисленными вычислениями, дробные пока остались в стороне. В первую очередь, из-за их отличия в представлении в железе, соответственно, и в методах обработки ошибок. Насколько мы знаем, самым удачным вариантом борьбы с UB в арифметике с плавающей точкой является проверка специальных флагов с помощью fenv.h, но дальше первого знакомства мы не зашли. В любом случае, и целочисленного случая хватило, чтобы один из членов нашей команды вполне увлекательновычислился провел половину учебного года. Перейдем к сути.
Основным этапом являлось создание самой обертки. Весь ее интерфейс — это макросы, которые разворачиваются в вызовы шаблонных функций или методов шаблонного класса. Такая функция или метод проверяет, корректно ли будет произведено вычисление, и в случае отсутствия проблем совершает его, возвращая ожидаемый результат. Самый простой пример — проверка оператора сложения.
В случае работы с префиксными операторами и операторами составного присваивания функции же возвращают нужное значение по ссылке в соответствии с документацией. В итоге, обертки над арифметическими операторами являются эквивалентами своих оригиналов с точностью не только до результата, но и до категории значения.
Как видно на примере оператора сложения, проверки по сути своей являются просто последовательностью условий, методично повторяющих формулировки документации языка. Во время ее изучения встретились и более интересные случаи UB.
Также было необходимо реализовать проверку целочисленного приведения типов для вообще осмысленности всей арифметики — неявные конвертации могут тайком пробраться к вам в вычисления и без лишнего шума изменить результат. К проверке. Обнаружение самих неявных преобразований оставили на AST, оно прекрасно их все отображает. Что фактически хотелось: научиться проверять, представимо ли число в новом типе, к которому происходит конвертация. Конечно, достаточно просто сравнить число с его новыми границами. Но в каком типе производить это сравнение, чтобы все операнды принимали свои фактические значения? Потребовалось разобраться со знаковостью типов согласно документации, затем просто выбрать более широкий. Проверка приведения типов особенно мощно выстрелит далее.
Самыми интересными в работе оказались операторы составного присваивания и инкремента/декремента — за счет неявной цепочки особенно неявных преобразований. Простой пример.
Вы с другом пошли в лес и решили прибавить к чару единицу… Красиво прибавить, то есть ++c. Будет ли вас ожидать в следующем примере UB?
И тут понеслось. Во-первых, безобидный префиксный инкремент решил вычисляться наподобие своему старшему собрату, то есть как составное присваивание c += 1. Для этого он привел c и 1 к общему типу, в данном случае к int-у. Затем честно посчитал сумму. И перед записью результата обратно в c, не забыл вызвать неявное преобразование к char-у. Уф.
И UB не случилось. Действительно, само сложение произошло в большом типе int, где число 128 законно существует. Но при этом результат все равно получился с изюминкой, благодаря неявному приведению результата к char-у. Более того, такое приведение чисто теоретически могло закончится не -128, а чем-то особенным в зависимости от компилятора — документация это допускает, ведь тип знаковый.
В итоге, из леса получилось выбраться живыми и вам, и другу, причем с большой вероятностью даже с ожидаемым результатом. Но путь оказался весьма неожиданным и интересным.
В случае с операторами составного присваивания AST не жалеет информации, поэтому проследить цепочку преобразований типов несложно. Далее несложно и проверить корректность вычисления в одном типе, затем неявное приведение к исходному (обе такие проверки уже есть в арсенале). Однако по поводу инкремента/декремента AST отказалось сотрудничать, скрыв всю кухню преобразований. Решением было внимательно прочитать документацию С++, а затем начать цепочку приведений с std::common_type от типа аргумента и int-a (типа единицы). Искушенный clang-ом читатель может поймать нас за руку, заметив, что именно по поводу таинственных ++ и — AST, вообще говоря, знает, возможно переполнение или нет.
Небольшой паноптикум арифметики закончился, дальше новые угрозы.
Каждому, кто знаком с C++, известно (но зачастую это анти-интуитивно для новичков, пришедших из других языков): если объявить переменную базового типа, но не проинициализировать её никаким значением, а потом в неё посмотреть — возникает UB. В то же время, такой синтаксис бывает удобен и иногда даже необходим, к примеру, для использования `cin` или `scanf`, поэтому мы решили побороться с этим типом ошибок.
Самое простое и бесполезное решение: просто добавить всем таким объявлениям переменных значение по умолчанию, но во-первых, так пользователю не станет проще найти ошибку, а во-вторых, в коде появляются “магические числа”, что считается плохой практикой. Другого тривиального решения C++ не предлагает, и потому в итоге мы остановились на следующем: мы заменим типы переменных на обертку, поддерживающую информацию о том, была внутренняя переменная проинициализирована или нет. Базовое описание такого класса выглядит примерно вот так:
А затем возникают вопросы. Как мы понимаем, когда происходит именно чтение значения переменной, а когда она просто упоминается каким-либо другим образом? Суть в том, что согласно стандарту, UB возникает именно в момент lvalue to rvalue cast, а его Clang AST выделяет в отдельную вершину `ImplicitCastExpr` нужного типа. Хорошо, тогда более сложный вопрос: пусть есть `scanf`, читающий несколько переменных, но пользователь дал некорректный ввод — и прочиталась только одна переменная. Тогда как понять, что происходит внутри наших оберток?
После некоторых размышлений волевым усилием отвечаем: никак. Если нет доступа к исходному коду функции, которая принимает переменную по ссылке или указателю, и при этом на момент вызова этой функции переменная не была проинициализирована, мы можем только сказать пользователю: “Эй, у тебя тут потенциально опасная ситуация, но мы за это не отвечаем”, а затем про эту переменную забыть.
Чтобы понять, доступны ли нам исходники этой функции, мы заранее пройдемся по AST всех переданных файлов и поищем в них определения вызываемых функций. Если исходники есть — они будут обработаны нашим анализатором, поэтому такой функции можно смело передавать обертку целиком и, таким образом, сохранить необходимую информацию.

Пример: обработанная версия программы, читающая IP-адрес по шаблону при помощи scanf, не может обнаружить UB, возникающее при выводе результата на экран
Перейдем к тому, как мы использовали AST. По вершинам `VarDecl` мы находим объявления переменных и заменяем их на конструкторы оберток, по операторам присваивания — находим собственно присваивания, которые и являются инициализациями. Интереснее с доступом к значению: информацию о переменной содержат вершины `DeclRefExpr`, но мы-то ищем `ImplicitCastExpr`, находящийся выше в дереве. При этом принципиально важно обработать случаи доступа по значению (с кастом) и по ссылке (без него) по-разному. На помощь приходит технология Parent-ов, позволяющая подниматься по дереву независимо от обхода Visitor-ов. (Передаю привет неполной документации ParentMapContext, из-за которой пришлось долго гулять по исходникам clang-а). Увы, это палка о двух концах — из-за потенциального обхода целого дерева асимптотика нашего анализатора возрастает до квадратной, и время работы самого анализатора ухудшается значительно. А что же делать, если обращение к переменной по ссылке? Возможно, эта ссылка куда-то передается, возможно, сохраняется в новую переменную… И что делать с полями классов? А вложенных классов?
Пример: страшный сон исследователей неинициализированных переменных и его AST
Не будем утомлять читателя миллионом вопросов, которые мы сами себе задавали и вынуждены были искать ответы. Скажем только, что ключевой сложностью оказалось отсутствие какого бы то ни было источника информации, в котором были бы собраны все пререквизиты и ценные мысли, объясняющие, каким вообще образом стоит реализовывать данную идею. Как следствие, пришлось наступать на все старательно разложенные языком C++ и clang-ом грабли, и по мере осмысления всё большего количества тонкостей и деталей задачи, глобальное представление об этой части проекта сильно видоизменялось и обрастало подробностями и замысловатостями. На продумывание и размышления ушло много больше времени, чем на саму реализацию.
Полномасштабное тестирование мы, к сожалению, не успели провести. Тем не менее, мы проверяли, как наша программа работает, на 1) отдельных изощренных ситуациях, 2) примерах простеньких программ на C++ из интернета, 3) своих решениях контестов и домашек. Вот пример преобразования, получающегося в результате работы нашего анализатора:
Пример до:
Пример после:
Видно, что код достаточно сильно раздувается в объеме. Впрочем, мы считаем, что сохранить читабельность на каком-то уровне нам удалось, а главное, ошибки действительно находятся!

Пример: вот так работает код, приведенный выше, на входных данных 5 и 15
Ради интереса мы также проверили, насколько медленнее работают более-менее реальные программы после обработки нашим анализатором. В качестве примера мы взяли собственную реализацию алгоритма Флойда. Результаты оказались неутешительными:

В заключение скажем: перед нами не стояло цели создать готовый продукт — нам было важно столкнуться с LLVM, clang и С++ и разбиться насмерть. Возможно, результат вышел не самым практичным, но чтение документаций и стандарта оказалось занимательным и особенно полезным времяпрепровождением. Будьте осторожны при использовании С++ и да хранит вас Бьёрн Страуструп.
Ссылка на гитхаб
Избегая встречи с грозными знаковыми переполнениями, группа борцов за свободу, ведомая Кириллом Бриллиантовым, Глебом Соловьевым и Денисом Лочмелисом, обустроила новый секретный репозиторий.
Тёмная владычица UB неинициализированная переменная, одержимая желанием сломать все программы галактики, разослала тысячи раздражающих ошибок в самые далекие уголки космоса…
Мы — трое студентов бакалавриата «Прикладная математика и информатика» в Питерской Вышке. В качестве учебного проекта во втором полугодии мы решили написать UB-tester — анализатор кода на С++.
Вступление
Реальная история: контест идет, времени остается мало, кодить задачки надо быстро. Именно в тот момент, когда разум участника охвачен быстрыми алгоритмами и тикающими секундами, С++ начинает выходить из-под контроля. В итоге программист старательно и очень долго ищет ошибку в реализации алгоритма, в неразобранном крайнем случае,
С такой ситуацией каждый из нас сталкивался лично. Поэтому в качестве проекта по С++ мы решили создать инструмент, с помощью которого будет удобно находить такие ошибки.
Небольшое введение в контекст
Анализаторы кода делятся на две группы: статические и динамические. Статические анализируют код без реального выполнения программы. Динамические, напротив, пытаются извлечь информацию во время ее исполнения. Самые известные примеры — статический clang static analyzer с большим функционалом, его платный аналог PVS studio, а также динамические valgrind и sanitizer.
Нам предстояло выбрать основной метод обнаружения ошибок. Источником вдохновения послужил достопочтенный С-шный макрос — assert. Если программист регулярно проверяет инварианты с помощью assert-а, то поиск ошибки при отладке становится намного более локализованной и простой задачей. Но вряд ли кто-то в здравом уме использовал бы такую проверку постоянно, обращаясь к массиву или складывая два int-а. Мы решили создать инструмент, который будет анализировать пользовательский код, а затем заменять ошибкоопасные места на написанные нами обертки, в случае чего выбрасывающие пользователю подробный лог ошибки. К примеру:
Пример: программа, складывающая два числа типа int, может вызывать UB при переполнении знакового числа, а ее обработанная версия — нет.
Безусловно, производить такие замены в исходном коде пользователя далеко не вежливо, поэтому результатом работы нашей программы является новая версия оригинального кода со вставленными обертками.
Такой подход к обнаружению ошибок оказался удачным или, по крайней мере, интересным. Пользователь получил возможность автоматически тестировать свою программу на предмет простых UB — без лишних усилий и затрат времени.
Финальной версии не было суждено стать новым valgrind-ом, а функционалу — покорить сердца миллионов, но процесс разработки оказался весьма захватывающим. Про это мы и расскажем далее.
Сlang и AST
Первым шагом работы ub-tester является нахождение всех ошибкоопасных мест в программе. Парсить код на C++ вручную и с нуля — путь в могилу (или по крайней мере в отдельный проект), поэтому нам предстояло подобрать инструменты для решения этой задачи. Пожалуй, самым известным и наиболее практичным инструментом по разбору исходного кода на плюсах является clang, поэтому мы выбрали его в качестве основы для нашего проекта. Сlang — большая библиотека, поэтому остановимся только на важных для понимания статьи понятиях.
Сперва стоит сказать об AST (Abstract Syntax Tree). Это структура данных — дерево (как можно было догадаться из названия), внутренние вершины которого соответствуют операторам языка, а листья — операндам. Вот пример AST для простой программы.
Исходный код:
if (a > b) {
print(a);
} else {
print(b);
}
AST:
Описанная абстракция и используется в clang-е для представления исходного кода. Такой структуры данных достаточно для обнаружения ошибкоопасных мест. К примеру, чтобы найти в программе теоретически возможные index out of bounds, нужно изучить все вершины AST, соответствующие операторам обращения к массиву по индексу.
Теперь дело остается за малым: получить доступ к AST. В clang-е существует несколько механизмов для решения этой задачи. Мы пользовались Visitor-ами.
В clang-е реализован базовый класс RecursiveASTVisitor, осуществляющий дфсный обход AST. Каждый Visitor должен от него наследоваться, чтобы уметь путешествовать по дереву. Далее, чтобы выполнять специфичные для определенных вершин операции, класс-наследник должен иметь набор методов вида Visit***, где *** — название узла AST. Оказываясь в вершине дерева, Visitor вызывает соответствующий ее названию метод Visit***, затем рекурсивно спускается в ее детей. Таким образом, чтобы создать своего Visitor-а, достаточно реализовать методы обработки конкретных вершин.
Вот пример небольшого класса, который посещает все бинарные операторы и выводит на экран их местоположения в коде.
class FindBinaryOperatorVisitor : public clang::RecursiveASTVisitor<FindBinaryOperatorVisitor> {
public:
bool VisitBinaryOperator(clang::BinaryOperator* BinOp) {
std::cout << BinOp->getBeginLoc() << ‘\n’;
return true;
}
};
Теперь можно со спокойной душой переходить к следующему пункту: к замене участков исходного кода.
CodeInjector
Сразу скажем, что, вероятно, мы избрали далеко не лучшее решение этой задачи. Мы разработали класс CodeInjector, который
- лениво применяет предоставленные ему замены исходного кода: сохраняет все пришедшие ему запросы, а затем разом их выполняет в конце обработки файла;
- никак не связан с clang-ом: сам открывает файл на чтение, сам ищет нужные строки и так далее.
Другое решение — использовать уже готовый инструмент для рефакторинга кода (класс Rewriter) внутри clang-а. Почему же мы от него отказались? Проблема в том, что иногда нужно изменять один и тот же участок кода несколько раз: на одну и ту же позицию в коде может прийтись сразу несколько ошибкоопасных мест, что потребует нескольких замен.
Простой пример. Есть такое выражение:
arr[1] + arr[2];Пусть мы сначала захотим поменять сложение на ASSERT_SUM, получим следующее:
ASSERT_SUM(arr[1], arr[2]);Кроме того, мы хотим проверить, что не произойдет выход за границы массива. Снова обратимся к этому же участку кода:
ASSERT_SUM(ASSERT_IOB(arr, 1), ASSERT_IOB(arr, 2));Наши Visitor-ы работают в полном неведении друг о друге, поэтому организовывать им сложную коммуникацию, чтобы они могли совершать замены, как-то договариваясь, категорически неудобно. Поскольку некоторые замены можно производить только последовательно и с постоянно разрастающимися операндами, то встроенный инструмент clang-а не сможет помочь — он не поддерживает такой функционал.
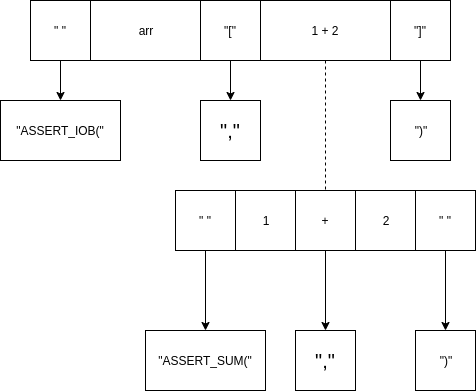
Мы заметили, что схемы замен состоят из чередования кусков, которые мы оставляем, и кусков, которые мы заменяем. Проиллюстрируем на примере: выражение: arr[1+2]. В нем есть два ошибкоопасных места: обращение к массиву и операция сложения. Должны произойти следующие замены:
- arr[1+2] заменяется на ASSERT_IOB(arr, 1 + 2)
- ASSERT_IOB(arr, 1 + 2) заменяется на ASSERT_IOB(arr, ASSERT_SUM(1, 2))
arr[1 + 2] ~~~~~> ASSERT_IOB(arr, 1 + 2) ~~~~~~> ASSERT_IOB(arr, ASSERT_SUM(1, 2)
Далее мы, внутри команды, договорились об интерфейсе для взаимодейстия с CodeInjector-ом, основанном на этой идее.
Все готово! Можно приступать к самому интересному — работе с конкретными видами UB.
Функционал
Наша программа ориентирована на поиск и выявление UB, а также операций в коде, результат которых может быть не совсем очевидным для пользователя. К таким относятся, например, неявные преобразования во время вычисления арифметических выражений.
Основные ошибки, выявляемые нашей программой:
- выход за границы С-шного массива;
- UB в целочисленной арифметике;
- обращение к неинициализированной переменной.
Подробно про некоторые аспекты функционала мы расскажем далее.
Целочисленная арифметика
Известнейшие представители UB арифметике — целочисленные переполнения в самых разных операциях. Есть и более изощренные UB, которыми могут похвастаться, например, остаток от деления и особенно битовые сдвиги. Кроме того, часто можно встретить составные операторы присваивания (+= и другие) и операторы инкремента/декремента. Во время их использования происходит целая цепочка неявных преобразований типов, которая и может повлечь крайне неожиданный и нежеланный результат. Да и неявные касты сами по себе могут служить большой бедой.
Так или иначе, общее правило для всех UB в арифметике — их сложно найти, легко проглядеть (никаких segfault-ов!) и невозможно простить.
Важно: впредь и далее речь пойдет про стандарт С++17, на который и ориентирован ub-tester. Он также поддерживает C++20, но из-за того, что в нем исчезли некоторые виды UB в арифметике (а новых не добавилось), про него говорить не так интересно.
int a = INT_MIN, b = -1, z = 0;
int test1 = a + b; // overflow
int test2 = a * b; // overflow
int test3 = a << 5; // lhs is negative => UB
int test5 = 5 % z; // % by 0 => UB
int test6 = --a; // overflow
Мы много работали с целочисленными вычислениями, дробные пока остались в стороне. В первую очередь, из-за их отличия в представлении в железе, соответственно, и в методах обработки ошибок. Насколько мы знаем, самым удачным вариантом борьбы с UB в арифметике с плавающей точкой является проверка специальных флагов с помощью fenv.h, но дальше первого знакомства мы не зашли. В любом случае, и целочисленного случая хватило, чтобы один из членов нашей команды вполне увлекательно
Основным этапом являлось создание самой обертки. Весь ее интерфейс — это макросы, которые разворачиваются в вызовы шаблонных функций или методов шаблонного класса. Такая функция или метод проверяет, корректно ли будет произведено вычисление, и в случае отсутствия проблем совершает его, возвращая ожидаемый результат. Самый простой пример — проверка оператора сложения.
template <typename T>
ArithmCheckRes checkSum(T Lhs, T Rhs) {
FLT_POINT_NOT_SUPPORTED(T);
if (Rhs > 0 && Lhs > std::numeric_limits<T>::max() - Rhs)
return ArithmCheckRes::OVERFLOW_MAX;
if (Rhs < 0 && Lhs < std::numeric_limits<T>::lowest() - Rhs)
return ArithmCheckRes::OVERFLOW_MIN;
return ArithmCheckRes::SAFE_OPERATION;
}
В случае работы с префиксными операторами и операторами составного присваивания функции же возвращают нужное значение по ссылке в соответствии с документацией. В итоге, обертки над арифметическими операторами являются эквивалентами своих оригиналов с точностью не только до результата, но и до категории значения.
Как видно на примере оператора сложения, проверки по сути своей являются просто последовательностью условий, методично повторяющих формулировки документации языка. Во время ее изучения встретились и более интересные случаи UB.
Например
Например, неопределенное поведение во время взятия остатка INT_MIN % (-1), вызванное тем, что результат не помещается в int. Если же вы, как и я, всегда немного осторожничали с битовыми сдвигами — то не зря. Битовый сдвиг влево может похвастаться рекордом по количеству различных UB, которые может вызывать. К примеру, сдвиг на отрицательное число бит это неопределенное поведение. Сдвиг на большее число бит, чем есть в типе — тоже. А если попробовать битово сдвинуть влево отрицательное число, то до C++20, безусловно, снова UB. Но если вам повезло, и ваше число в знаковом типе неотрицательно, то корректность результата будет зависеть от возможности представить его в беззнаковой версии, что тоже можно не удержать в голове. В общем, хоть эти правила и понятные, но, в случае неаккуратного с ними обращения, последствия могут оказаться весьма плачевными.
int a = INT_MIN, b = -1;
int test = a % b; // -INT_MIN > INT_MAX => UB
int test1 = a << 5; // lhs is negative => UB
int test2 = 5 << b; // rhs is negative => UB
int32_t c = 1, d = 33;
int32_t test3 = c << d; // rhs is >= size of c in bits => UB
int test4 = 2e9 << c; // test = -294967296, not UB
int test5 = 2e9 << (c + 1); // (2e9 << 2) > UINT_MAX => UB
Также было необходимо реализовать проверку целочисленного приведения типов для вообще осмысленности всей арифметики — неявные конвертации могут тайком пробраться к вам в вычисления и без лишнего шума изменить результат. К проверке. Обнаружение самих неявных преобразований оставили на AST, оно прекрасно их все отображает. Что фактически хотелось: научиться проверять, представимо ли число в новом типе, к которому происходит конвертация. Конечно, достаточно просто сравнить число с его новыми границами. Но в каком типе производить это сравнение, чтобы все операнды принимали свои фактические значения? Потребовалось разобраться со знаковостью типов согласно документации, затем просто выбрать более широкий. Проверка приведения типов особенно мощно выстрелит далее.
Самыми интересными в работе оказались операторы составного присваивания и инкремента/декремента — за счет неявной цепочки особенно неявных преобразований. Простой пример.
Вы с другом пошли в лес и решили прибавить к чару единицу… Красиво прибавить, то есть ++c. Будет ли вас ожидать в следующем примере UB?
char c = 127;
++c;
И тут понеслось. Во-первых, безобидный префиксный инкремент решил вычисляться наподобие своему старшему собрату, то есть как составное присваивание c += 1. Для этого он привел c и 1 к общему типу, в данном случае к int-у. Затем честно посчитал сумму. И перед записью результата обратно в c, не забыл вызвать неявное преобразование к char-у. Уф.
И UB не случилось. Действительно, само сложение произошло в большом типе int, где число 128 законно существует. Но при этом результат все равно получился с изюминкой, благодаря неявному приведению результата к char-у. Более того, такое приведение чисто теоретически могло закончится не -128, а чем-то особенным в зависимости от компилятора — документация это допускает, ведь тип знаковый.
В итоге, из леса получилось выбраться живыми и вам, и другу, причем с большой вероятностью даже с ожидаемым результатом. Но путь оказался весьма неожиданным и интересным.
В случае с операторами составного присваивания AST не жалеет информации, поэтому проследить цепочку преобразований типов несложно. Далее несложно и проверить корректность вычисления в одном типе, затем неявное приведение к исходному (обе такие проверки уже есть в арсенале). Однако по поводу инкремента/декремента AST отказалось сотрудничать, скрыв всю кухню преобразований. Решением было внимательно прочитать документацию С++, а затем начать цепочку приведений с std::common_type от типа аргумента и int-a (типа единицы). Искушенный clang-ом читатель может поймать нас за руку, заметив, что именно по поводу таинственных ++ и — AST, вообще говоря, знает, возможно переполнение или нет.
Однако мы здесь собрались не просто так

Читатель ловит нас за руку, в то время как AST делает нашу работу
Вопреки названию нашего проекта, ub-tester находит не только UB. Мотивацией арифметических проверок были не только ошибки, влекущие за собой обессмысливание всей программы, но и неприметные на первый взгляд источники неожиданных результатов (при этом корректных с точки зрения С++). Поэтому информации о возможности/невозможности UB в операторах инкремента/декремента мало, проверка должна уметь детектировать еще и сужающее неявное преобразование и уметь рассказывать про это пользователю. По этой причине в случае ++ и — пришлось дополнительно поработать, чтобы добиться желаемого функционала.

Вывод ub-tester-а на примере с char c = 127; ++c;
Читатель ловит нас за руку, в то время как AST делает нашу работу
Вопреки названию нашего проекта, ub-tester находит не только UB. Мотивацией арифметических проверок были не только ошибки, влекущие за собой обессмысливание всей программы, но и неприметные на первый взгляд источники неожиданных результатов (при этом корректных с точки зрения С++). Поэтому информации о возможности/невозможности UB в операторах инкремента/декремента мало, проверка должна уметь детектировать еще и сужающее неявное преобразование и уметь рассказывать про это пользователю. По этой причине в случае ++ и — пришлось дополнительно поработать, чтобы добиться желаемого функционала.
Вывод ub-tester-а на примере с char c = 127; ++c;
Неинициализированные переменные
Каждому, кто знаком с C++, известно (но зачастую это анти-интуитивно для новичков, пришедших из других языков): если объявить переменную базового типа, но не проинициализировать её никаким значением, а потом в неё посмотреть — возникает UB. В то же время, такой синтаксис бывает удобен и иногда даже необходим, к примеру, для использования `cin` или `scanf`, поэтому мы решили побороться с этим типом ошибок.
Самое простое и бесполезное решение: просто добавить всем таким объявлениям переменных значение по умолчанию, но во-первых, так пользователю не станет проще найти ошибку, а во-вторых, в коде появляются “магические числа”, что считается плохой практикой. Другого тривиального решения C++ не предлагает, и потому в итоге мы остановились на следующем: мы заменим типы переменных на обертку, поддерживающую информацию о том, была внутренняя переменная проинициализирована или нет. Базовое описание такого класса выглядит примерно вот так:
template <typename T>
class UBSafeType final {
public:
UBSafeType() : Value_{}, IsInit_{false} {}
UBSafeType(T t) : Value_{t}, IsInit_{true} {}
T assertGetValue_() const;
T& assertGetRef();
T& setValue_(T Val);
private:
T Value_;
bool IsInit_;
};
А затем возникают вопросы. Как мы понимаем, когда происходит именно чтение значения переменной, а когда она просто упоминается каким-либо другим образом? Суть в том, что согласно стандарту, UB возникает именно в момент lvalue to rvalue cast, а его Clang AST выделяет в отдельную вершину `ImplicitCastExpr` нужного типа. Хорошо, тогда более сложный вопрос: пусть есть `scanf`, читающий несколько переменных, но пользователь дал некорректный ввод — и прочиталась только одна переменная. Тогда как понять, что происходит внутри наших оберток?
После некоторых размышлений волевым усилием отвечаем: никак. Если нет доступа к исходному коду функции, которая принимает переменную по ссылке или указателю, и при этом на момент вызова этой функции переменная не была проинициализирована, мы можем только сказать пользователю: “Эй, у тебя тут потенциально опасная ситуация, но мы за это не отвечаем”, а затем про эту переменную забыть.
Чтобы понять, доступны ли нам исходники этой функции, мы заранее пройдемся по AST всех переданных файлов и поищем в них определения вызываемых функций. Если исходники есть — они будут обработаны нашим анализатором, поэтому такой функции можно смело передавать обертку целиком и, таким образом, сохранить необходимую информацию.
Пример: обработанная версия программы, читающая IP-адрес по шаблону при помощи scanf, не может обнаружить UB, возникающее при выводе результата на экран
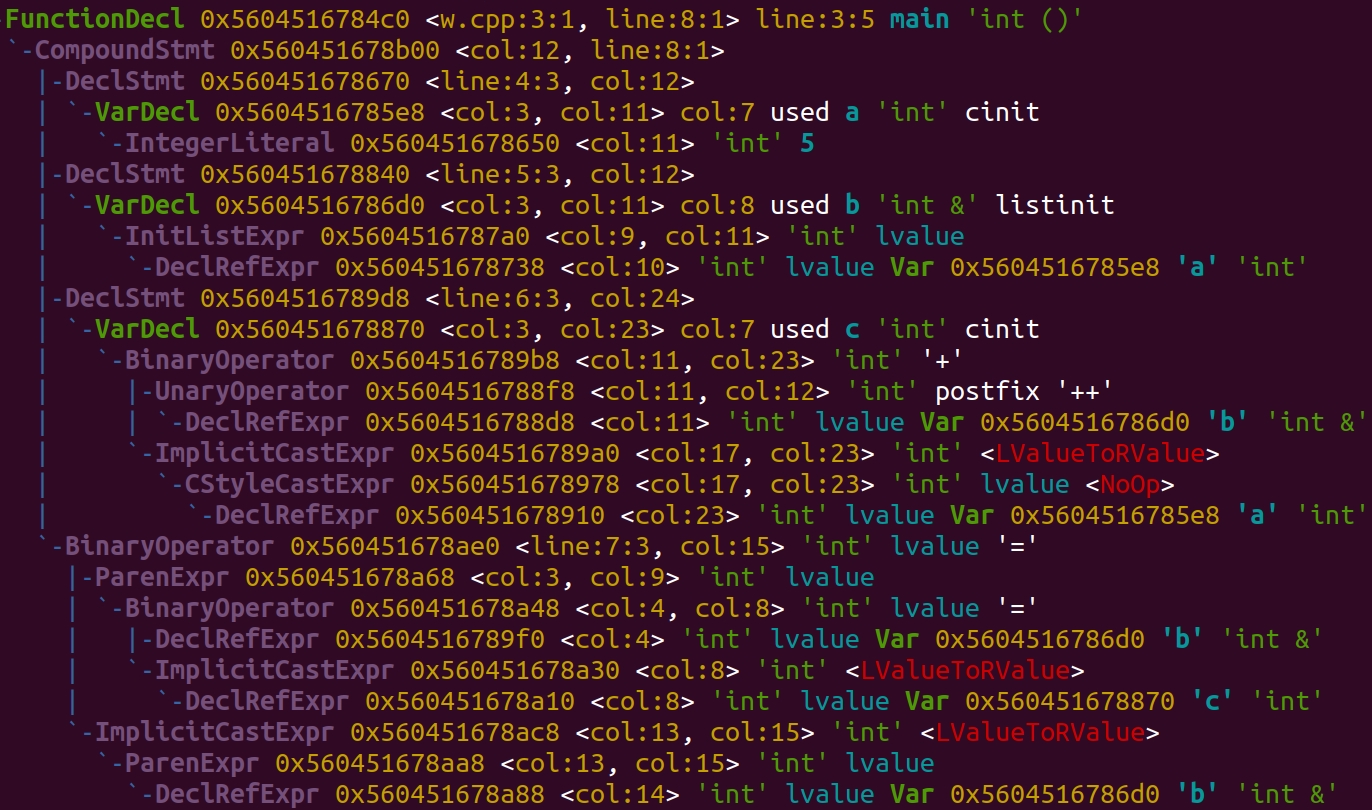
Перейдем к тому, как мы использовали AST. По вершинам `VarDecl` мы находим объявления переменных и заменяем их на конструкторы оберток, по операторам присваивания — находим собственно присваивания, которые и являются инициализациями. Интереснее с доступом к значению: информацию о переменной содержат вершины `DeclRefExpr`, но мы-то ищем `ImplicitCastExpr`, находящийся выше в дереве. При этом принципиально важно обработать случаи доступа по значению (с кастом) и по ссылке (без него) по-разному. На помощь приходит технология Parent-ов, позволяющая подниматься по дереву независимо от обхода Visitor-ов. (Передаю привет неполной документации ParentMapContext, из-за которой пришлось долго гулять по исходникам clang-а). Увы, это палка о двух концах — из-за потенциального обхода целого дерева асимптотика нашего анализатора возрастает до квадратной, и время работы самого анализатора ухудшается значительно. А что же делать, если обращение к переменной по ссылке? Возможно, эта ссылка куда-то передается, возможно, сохраняется в новую переменную… И что делать с полями классов? А вложенных классов?
int main() {
int a = 5;
int& b{a};
int c = b++ + (int&)a;
(b = c) = (b);
}
Пример: страшный сон исследователей неинициализированных переменных и его AST
Не будем утомлять читателя миллионом вопросов, которые мы сами себе задавали и вынуждены были искать ответы. Скажем только, что ключевой сложностью оказалось отсутствие какого бы то ни было источника информации, в котором были бы собраны все пререквизиты и ценные мысли, объясняющие, каким вообще образом стоит реализовывать данную идею. Как следствие, пришлось наступать на все старательно разложенные языком C++ и clang-ом грабли, и по мере осмысления всё большего количества тонкостей и деталей задачи, глобальное представление об этой части проекта сильно видоизменялось и обрастало подробностями и замысловатостями. На продумывание и размышления ушло много больше времени, чем на саму реализацию.
Результаты
Полномасштабное тестирование мы, к сожалению, не успели провести. Тем не менее, мы проверяли, как наша программа работает, на 1) отдельных изощренных ситуациях, 2) примерах простеньких программ на C++ из интернета, 3) своих решениях контестов и домашек. Вот пример преобразования, получающегося в результате работы нашего анализатора:
Пример до:
#include "../../include/UBTester.h"
#include <iostream>
int main() {
int a, b;
std::cin >> a;
char c = 89;
c = 2 * c; // unsafe conversion
int arr[10];
arr[a] = a; // possible index out of bounds
a = b; // uninit variable
}
Пример после:
#include "../../include/UBTester.h"
#include <iostream>
int main() {
UBSafeType<int> a, b;
std::cin >> ASSERT_GET_REF_IGNORE(a);
UBSafeType<char> c(IMPLICIT_CAST(89, int, char));
ASSERT_SET_VALUE(c, IMPLICIT_CAST(ASSERT_BINOP(Mul, 2, IMPLICIT_CAST(c, char, int), int, int), int, char)); // unsafe conversion
UBSafeCArray<int, 10> arr(ASSERT_INVALID_SIZE(std::vector<int>({10})));
ASSERT_IOB(arr, ASSERT_GET_VALUE(a)) = ASSERT_GET_VALUE(a); // possible index out of bounds
ASSERT_SET_VALUE(a, ASSERT_GET_VALUE(b)); // uninit variable
}
Видно, что код достаточно сильно раздувается в объеме. Впрочем, мы считаем, что сохранить читабельность на каком-то уровне нам удалось, а главное, ошибки действительно находятся!
Пример: вот так работает код, приведенный выше, на входных данных 5 и 15
Ради интереса мы также проверили, насколько медленнее работают более-менее реальные программы после обработки нашим анализатором. В качестве примера мы взяли собственную реализацию алгоритма Флойда. Результаты оказались неутешительными:
В заключение скажем: перед нами не стояло цели создать готовый продукт — нам было важно столкнуться с LLVM, clang и С++ и разбиться насмерть. Возможно, результат вышел не самым практичным, но чтение документаций и стандарта оказалось занимательным и особенно полезным времяпрепровождением. Будьте осторожны при использовании С++ и да хранит вас Бьёрн Страуструп.
Ссылка на гитхаб




