
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
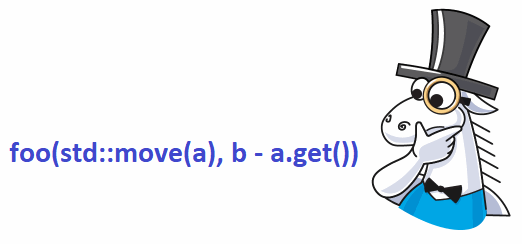
Совмещать много действий в одном выражении языка C++ плохо, так как такой код тяжело понимать, тяжело поддерживать, так в нём еще и легко допустить ошибку. Например, создать баг, совмещая различные действия при вычислении аргументов функции. Мы согласны с классической рекомендацией, что код должен быть прост и понятен. И сейчас рассмотрим интересный случай, когда формально анализатор PVS-Studio не прав, но с практической точки зрения код всё равно стоит изменить.
Порядок вычисления аргументов
То, что будет сейчас рассказано, — это продолжение старой истории о порядке вычисления аргументов, про которую мы писали в статье "Глубина кроличьей норы или собеседование по C++ в компании PVS-Studio".
Краткая суть заключается в следующем. Порядок вычисления аргументов функции — это неуточненное поведение. Стандарт не регламентирует, в каком именно порядке разработчики компиляторов обязаны произвести вычисление аргументов. Например, слева направо (Clang) или справа налево (GCC, MSVC). До стандарта C++17, когда при вычислении аргументов возникали побочные эффекты, это могло приводить к неопределённому поведению.
С появлением стандарта C++17 ситуация изменилась в лучшую сторону: теперь вычисление аргумента и его побочные эффекты начнут выполняться лишь с того момента, как будут выполнены все вычисления и побочные эффекты предыдущего аргумента. Однако, это не значит, что теперь нет места для ошибки.
Рассмотрим простую тестовую программу:
#include <cstdio>
int main()
{
int i = 1;
printf("%d, %d\n", i, i++);
return 0;
}Что распечатает этот код? Ответ, по-прежнему, зависит от компилятора, его версии и настроения. В зависимости от компилятора может быть распечатано как "1, 1", так и "2, 1". И действительно, воспользовавшись Compiler Explorer я получит следующие результаты:
- программа, скомпилированная с помощью Clang 11.0.0, выдаёт "1, 1".
- программа, скомпилированная с помощью GCC 10.2, выдаёт "2, 1".
В этой программе нет неопределённого поведения, но есть неуточнённое поведение (порядок вычисления аргументов).
Код из проекта CSV Parser
Вернёмся к фрагменту кода из проекта CSV Parser, о котором я упоминал в статье "Проверка коллекции header-only C++ библиотек (awesome-hpp)".
Мы с анализатором знаем о том, что аргументы могут вычисляться в разном порядке. Поэтому анализатор, а вслед за ним и я, посчитали этот код ошибочным:
std::unique_ptr<char[]> buffer(new char[BUFFER_UPPER_LIMIT]);
....
this->feed_state->feed_buffer.push_back(
std::make_pair<>(std::move(buffer), line_buffer - buffer.get()));Предупреждение PVS-Studio: V769 The 'buffer.get()' pointer in the 'line_buffer — buffer.get()' expression equals nullptr. The resulting value is senseless and it should not be used. csv.hpp 4957
На самом деле, мы оба неправы, и никакой ошибки нет. Про нюансы будет дальше, а пока начнём с простого.
Итак, давайте разберёмся, почему опасно писать код следующего вида:
Foo(std::move(buffer), line_buffer - buffer.get());Я думаю, вы догадываетесь про ответ. Результат зависит от последовательности вычисления аргументов. Рассмотрим это на следующем синтетическом коде:
#include <iostream>
#include <memory>
void Print(std::unique_ptr<char[]> p, ptrdiff_t diff)
{
std::cout << diff << std::endl;
}
void Print2(ptrdiff_t diff, std::unique_ptr<char[]> p)
{
std::cout << diff << std::endl;
}
int main()
{
{
std::unique_ptr<char[]> buffer(new char[100]);
char *ptr = buffer.get() + 22;
Print(std::move(buffer), ptr - buffer.get());
}
{
std::unique_ptr<char[]> buffer(new char[100]);
char *ptr = buffer.get() + 22;
Print2(ptr - buffer.get(), std::move(buffer));
}
return 0;
}Вновь воспользуемся Compiler Explorer и посмотрим результат работы этой программы, собранной разными компиляторами.
Компилятор Clang 11.0.0. Результат:
23387846
22Компилятор GCC 10.2. Результат:
22
26640070Результат ожидаем, и писать так нельзя. О чём, собственно, и предупреждает анализатор PVS-Studio.
На этом бы хотелось поставить точку, но всё немного сложнее. Дело в том, что речь идёт о передаче аргументов по значению, а при инстанцировании шаблона функции std::make_pair всё будет иначе. Продолжим погружаться в нюансы и узнаем, почему PVS-Studio в данном случае неправ.
std::make_pair
Обратимся к сайту cppreference и посмотрим, как менялся шаблон функции std::make_pair.
Until C++11:
template< class T1, class T2 >Since C++11, until C++14:
std::pair<T1,T2> make_pair( T1 t, T2 u );
template< class T1, class T2 >Since C++14:
std::pair<V1,V2> make_pair( T1&& t, T2&& u );
template< class T1, class T2 >Как видите, когда-то давным-давно std::make_pair принимал аргументы по значению. Если бы в те времена существовал std::unique_ptr, то рассмотренный выше код действительно был некорректным. Работал бы ли этот код или нет, зависело от везения. На практике, конечно, такая ситуация бы никогда не возникла, так как std::unique_ptr появился в C++11 как замена std::auto_ptr.
constexpr std::pair<V1,V2> make_pair( T1&& t, T2&& u );
Вернёмся в наше время. Начиная с версии стандарта C++11, конструктор начал использовать семантику перемещения.
Здесь есть тонкий момент в том, что std::move на самом деле ничего не перемещает, а всего-навсего производит преобразование объекта к rvalue-ссылке. Это позволит std::make_pair передать указатель новому std::unique_ptr, оставив nullptr в исходном умном указателе. Но эта передача указателя не произойдет, пока мы не попадём внутрь std::make_pair. К тому времени мы уже вычислим line_buffer — buffer.get(), и всё будет хорошо. То есть, вызов функции buffer.get() не может вернуть nullptr в момент, когда он вычисляется, вне зависимости от того, когда именно это произойдёт.
Прошу прощения за сложное описание. Суть в том, что такой код вполне корректен. И по факту статический анализатор PVS-Studio в данном случае выдал ложное срабатывание. Впрочем, наша команда не уверена, что следует спешить вносить изменения в логику работы анализатора для подобных ситуаций.
Король умер, да здравствует король!
Мы разобрались, что срабатывание, описанное в статье, оказалось ложным. Спасибо одному нашему читателю, который обратил наше внимание на особенность реализации std::make_pair.
Однако, это тот случай, когда мы не уверены, что стоит улучшать поведение анализатора. Дело в том, что этот код слишком запутанный. Согласитесь, то, что делает разобранный нами код, не заслуживает такого подробного разбирательства, потянувшего на целую статью. Если этот код требует так много внимания, то это очень плохой код.
Здесь уместно вспомнить статью "False positives are our enemies, but may still be your friends". Публикация не наша, но мы с ней согласны.
Это, пожалуй, тот самый случай. Пусть предупреждение ложное, но оно указывает на место, где лучше провести рефакторинг. Достаточно написать что-то вроде этого:
auto delta = line_buffer - buffer.get();
this->feed_state->feed_buffer.push_back(
std::make_pair(std::move(buffer), delta));А можно в данной ситуации сделать код еще лучше, воспользовавшись методом emplace_back:
auto delta = line_buffer - buffer.get();
this->feed_state->feed_buffer.emplace_back(std::move(buffer), delta);Такой код создаст итоговый объект std::pair в контейнере "по месту", минуя создание временного объекта и его перемещение в контейнер. Кстати, анализатор PVS-Studio, предлагает сделать такую замену, выдавая предупреждение V823 из набора правил по микрооптимизациям кода.
Код станет однозначно проще и понятнее любому читателю и анализатору. Нет никакого достоинства в том, чтобы запихать в одну строчку кода как можно больше действий.
Да, в данном случае повезло, и ошибки нет. Но вряд автор при написании этого кода держал в голове всё то, что мы обсудили. Скорее всего, сыграло именно везение. А другой раз может и не повезти.
Заключение
Итак, мы разобрались, что настоящей ошибки нет. Анализатор выдаёт ложное срабатывание. Возможно, мы уберём предупреждение именно для таких случаев, а возможно и нет. Мы ещё подумаем над этим. Ведь это достаточно редкий случай, а код, где аргументы вычисляются с побочными эффектами, опасен в целом, и его лучше не допускать. Стоит сделать рефакторинг хотя бы в профилактических целях.
Код вида:
Foo(std::move(buffer), line_buffer - buffer.get());легко сломать, изменяя что-то в другом месте программы. Такой код тяжело сопровождать. А ещё он неприятен тем, что может возникать ложное ощущение, что всё работает правильно. На самом же деле, это просто стечение обстоятельств, и всё может сломаться при смене компилятора или настроек оптимизации.
Пишите код проще!

Если хотите поделиться этой статьей с англоязычной аудиторией, то прошу использовать ссылку на перевод: Andrey Karpov. The Code Analyzer is wrong. Long live the Analyzer!.



