Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Дисклеймер номер один: 18+. В этой статье присутствует ненормативная лексика, так как некоторые гости Юрия, не стесняются в выражениях. Мы не хотим никого задеть или оскорбить чьи-то чувства, присутствие мата объясняется лишь объектом нашего исследования.
Выход практически каждого ролика на канале «вДудь» считается событием, а некоторые из этих релизов даже сопровождаются скандалами из-за неосторожных высказываний его гостей.
Сегодня при помощи статистических подходов и алгоритмов ML мы будем анализировать прямую речь. В качестве данных используем интервью, которые журналист Юрий Дудь (признан иностранным агентом на территории РФ) берет для своего YouTube-канала. Посмотрим с помощью Python, о чем таком интересном говорили в интервью на канале «вДудь».
Сбор данных
Дисклеймер номер два (если вы не обратили внимание на первый): осторожно, в статье присутствует мат!
C помощью YouTube API мы получили список всех видео с канала Юрия Дудя, а также их метаинформацию. О том, как это сделать, вы можете узнать, например, из статьи нашего блога.
Если вы уже слышали знаменитое “Юрий будет дуть, дуть будет Юрий”, то наверняка знаете, что на этом канале есть документальные фильмы, а также интервью, в которых участвуют сразу несколько гостей. Нас заинтересовали только те выпуски, в которых преимущественно говорит только один гость. Поэтому нам пришлось провести фильтрацию всех видео вручную.
Для дальнейшего анализа нам необходимо было получить длительности роликов. Это мы сделали с помощью GET-запросов к YouTube API. Результаты приходили в специфическом формате (для примера: “PT1H49M35S”), поэтому их нам пришлось распарсить и перевести в секунды.
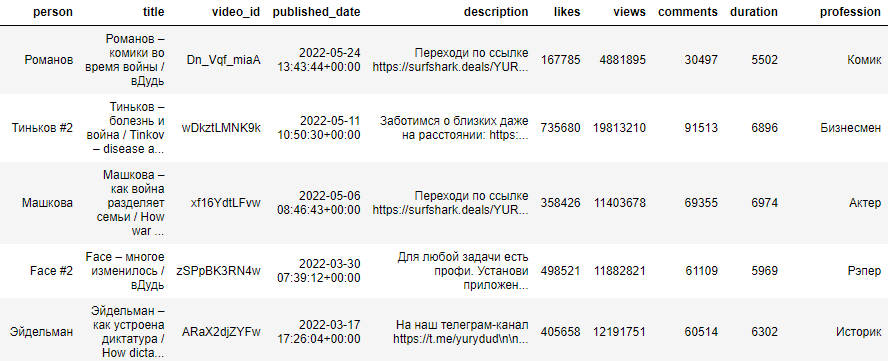
Итак, мы получили датафрейм, состоящий из 122 записей:
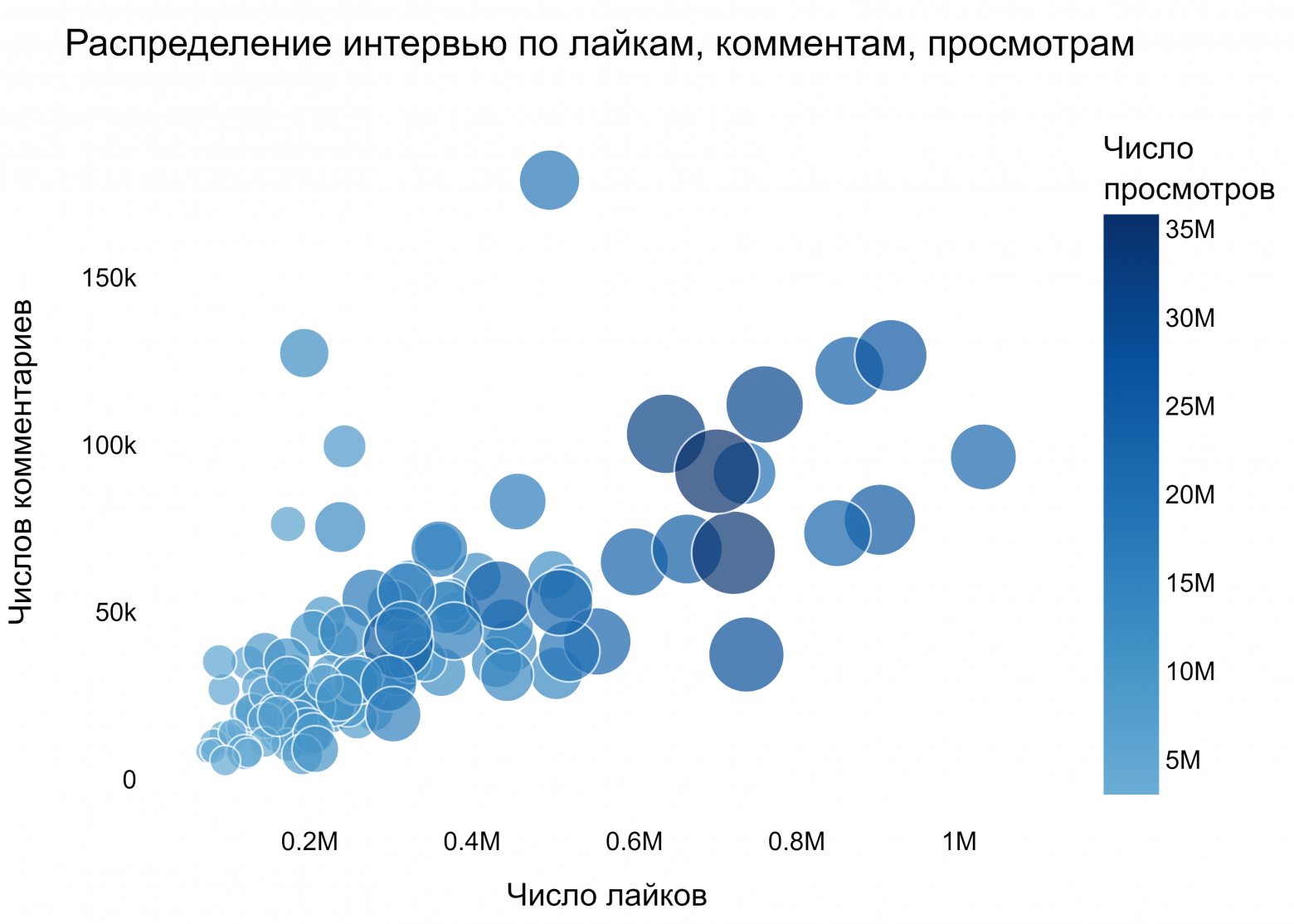
На основе метаинформации по лайкам, комментариям и просмотрам мы построили следующий Bubble Chart:
Так как наша цель – проанализировать речь в интервью, нам необходимо было получить текстовые составляющие роликов. В этом нам помог API-интерфейс youtube_transcript_api, который скачивает субтитры из видео на YouTube. Для каких-то роликов субтитры были прописаны вручную, но для большинства они были сгенерированы автоматически. К сожалению, для 10 видео субтитров не оказалось: беседы с L'one, Шнуром, Ресторатором, Амираном, Ильичом, Ильей Найшуллером, Соболевым, Иваном Дорном, Навальным, Noize MC. Причину их отсутствия мы, к сожалению, понять не смогли.
А гости кто?
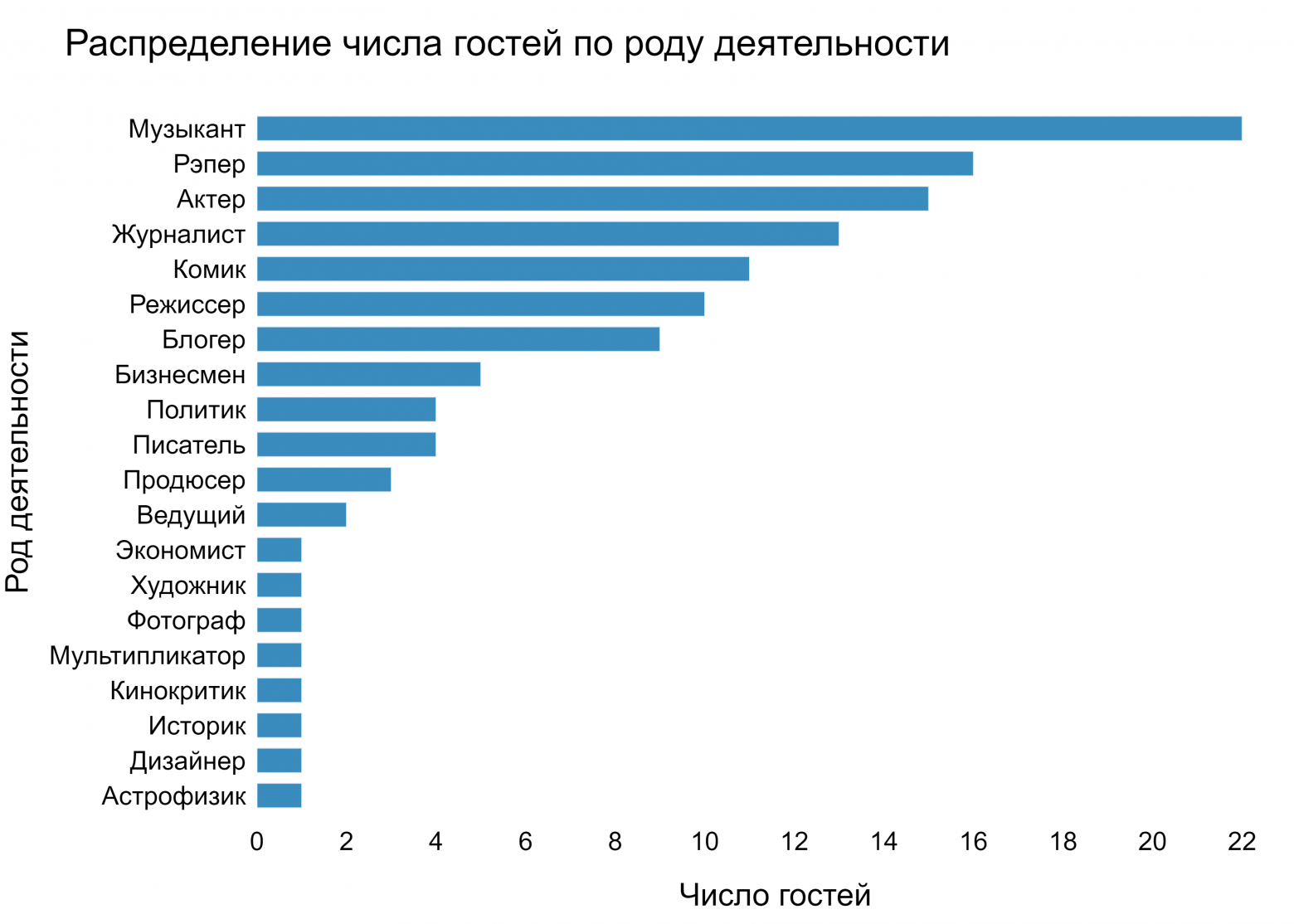
Спектр рода деятельности гостей канала «вДудь» достаточно обширен, поэтому было решено пополнить исходные данные информацией о том, чем же в основном занимается приглашенный участник каждого интервью. К сожалению, ролики не сопровождаются четкими метками профессиональной принадлежности гостя, поэтому мы прописали эту информацию сами. На момент выгрузки данных последним видео на канале был разговор с комиком Дмитрием Романовым.
Если с идентификацией профессии каждого гостя мы не ошиблись, то вот такое распределение в итоге получается:
Обработка текста
Анализ текстовой информации сложен в той степени, в какой сложен язык, на котором написан текст. Подробно о подготовке текста к анализу мы рассказывали в материале «Python и тексты нового альбома Земфиры». Тут была проведена идентичная работа.
Как и раньше, для решения аналитической задачи мы решили использовать такой подход как лемматизация, т.е. приведение слова к его словарной форме. Проведя лемматизацию текстовых данных по правилам русского языка, мы получим существительные в именительном падеже единственного числа (кошками - кошка), прилагательные в именительном падеже мужского рода (пушистая - пушистый), а глаголы в инфинитиве (бежит - бежать). В этом проекте мы опять воспользовались библиотекой Pymorphy, представляющую собой морфологический анализатор.
Помимо приведения к словарной форме нам потребовалось убрать из текстов часто встречающиеся слова, которые не несут ценности для анализа. Это было необходимо, потому что так называемые стоп-слова могут повлиять на работу используемой модели машинного обучения. Список таких слов мы взяли из пакета ntlk.corpus, а после расширили его, изучив тексты интервью. Конечно, мы также убрали все знаки пунктуации.
Анализ словарного запаса
После обработки текста мы посчитали для каждого интервью количество всех слов, а также абсолютное и относительное количество уникальных слов. Конечно, полученные значения неидеальны, так как, во-первых, для большинства интервью были получены автоматически сгенерированные субтитры, которые являются неточными, а во-вторых, тексты были очищены от лишней информации.
Сперва мы решили наглядно представить основной массив лексики, которая звучит в интервью. После группировки интервью по роду деятельности гостя нам удалось это сделать и в этом нам помогла библиотека wordcloud. У нас получились такие облака слов:

Лейтмотивом всех интервью Юрия являются обсуждение России (политики, социальной жизни и других особенностей), уровня заработка гостей, а также непосредственно профессиональной деятельности гостя (это особенно заметно у представителей индустрии кинопроизводства).
Далее мы решили построить боксплот для количества слов для каждого рода деятельности (профессии, которые были представлены единственным гостем, мы не стали учитывать):
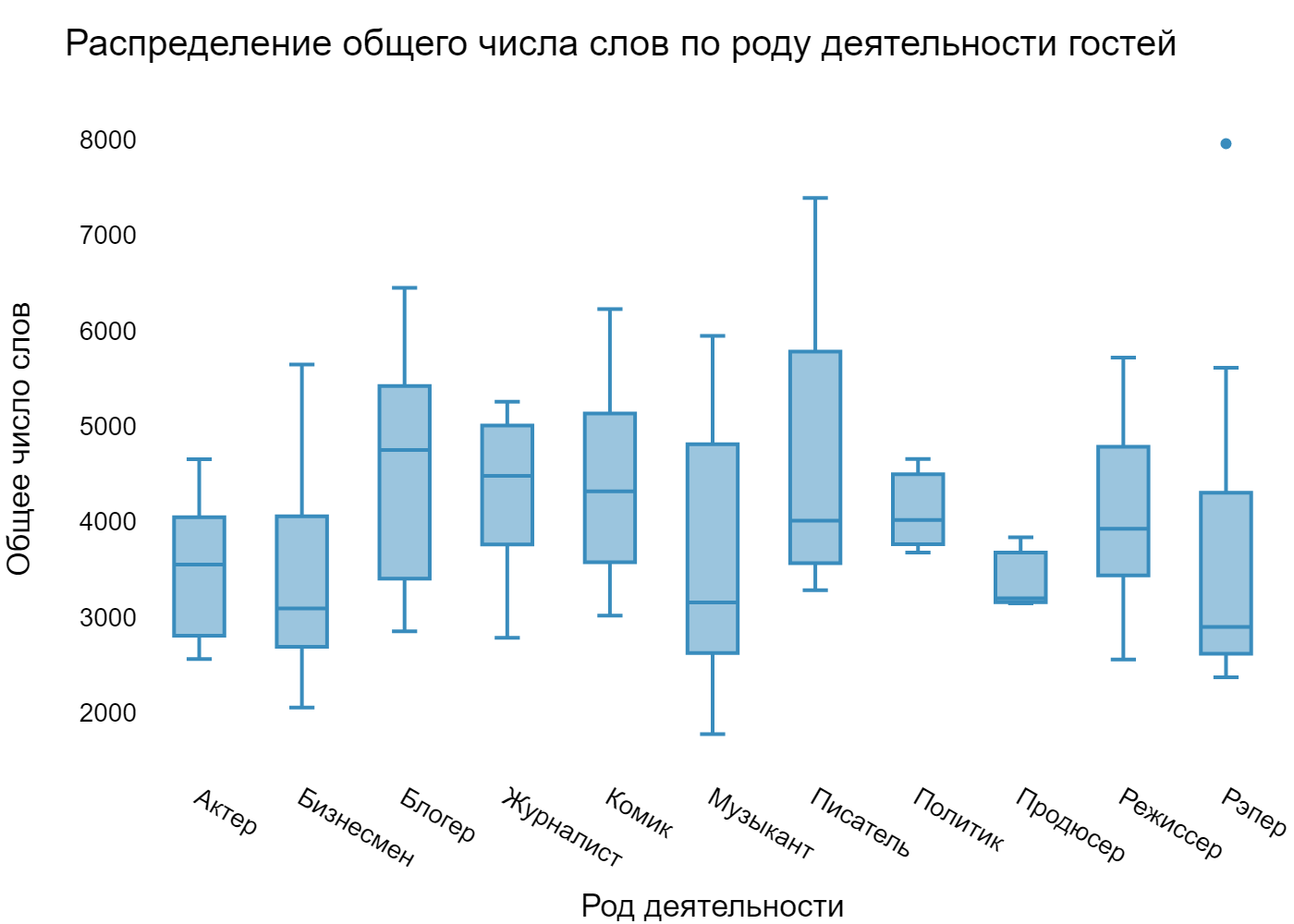
Наиболее разговорчивыми гостями оказались блогеры. По медиане, они наговорили больше всего слов. Чуть поодаль от них журналисты и комики, а вот самыми немногословными оказались рэперы.
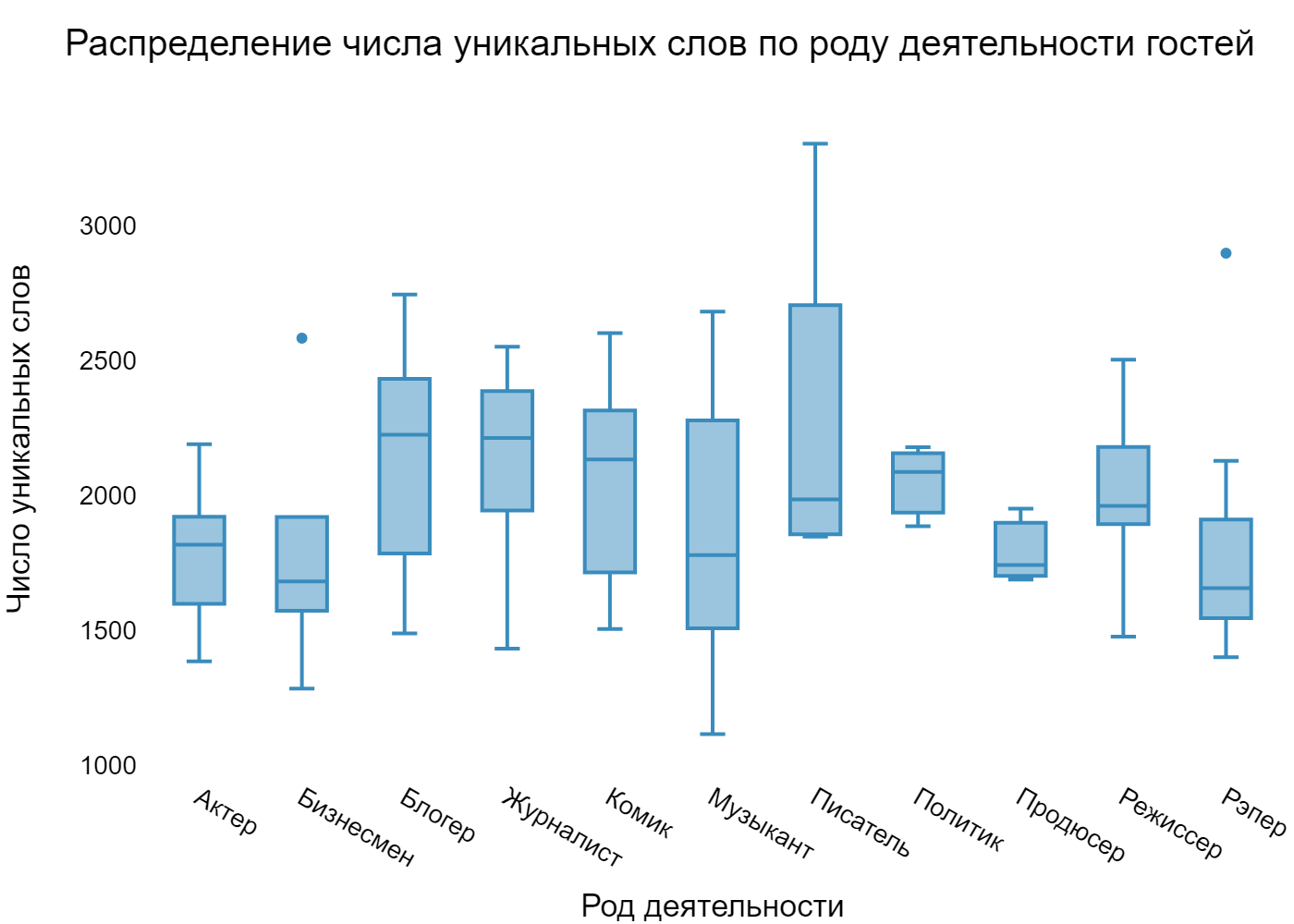
Что касается количества уникальных слов, то тут ситуация аналогичная. И рэперы опять в аутсайдерах…
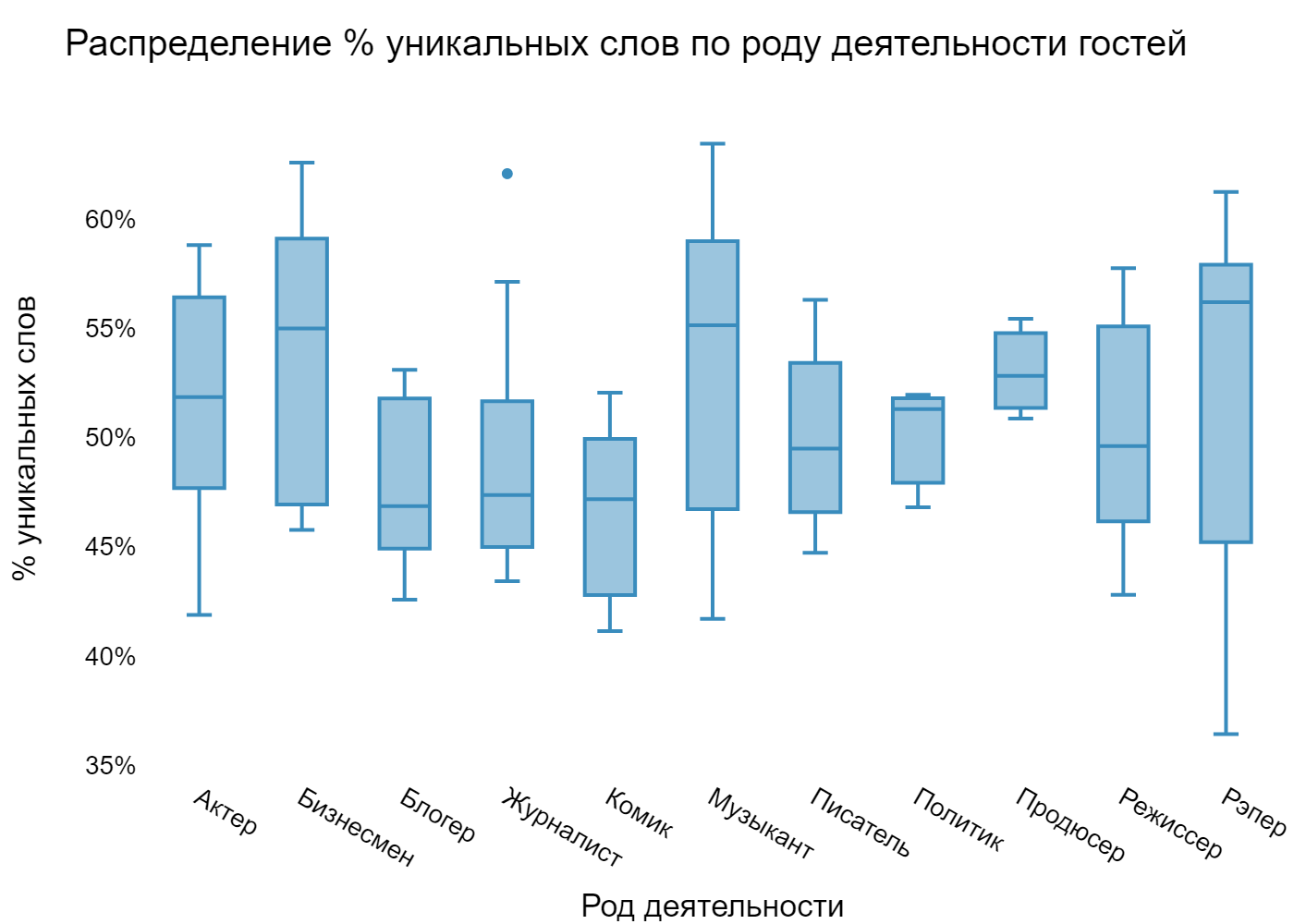
Если говорить об отношении уникальных слов к общему количеству, то тут можно увидеть совершенно иную картину. Теперь впереди оказываются, рэперы, музыканты и бизнесмены. Предыдущие же лидеры, наоборот, становятся самыми последними.
Конечно, стоит отметить, что такие сравнения могут быть несправедливыми, так как длительность интервью у каждого гостя Дудя разная, а потому кто-то просто мог успеть наговорить больше слов, чем остальные. Наглядно в этом можно убедиться, взглянув на распределение длительности интервью по роду деятельности (для построения использовался тот же пул гостей, что и для боксплотов выше):
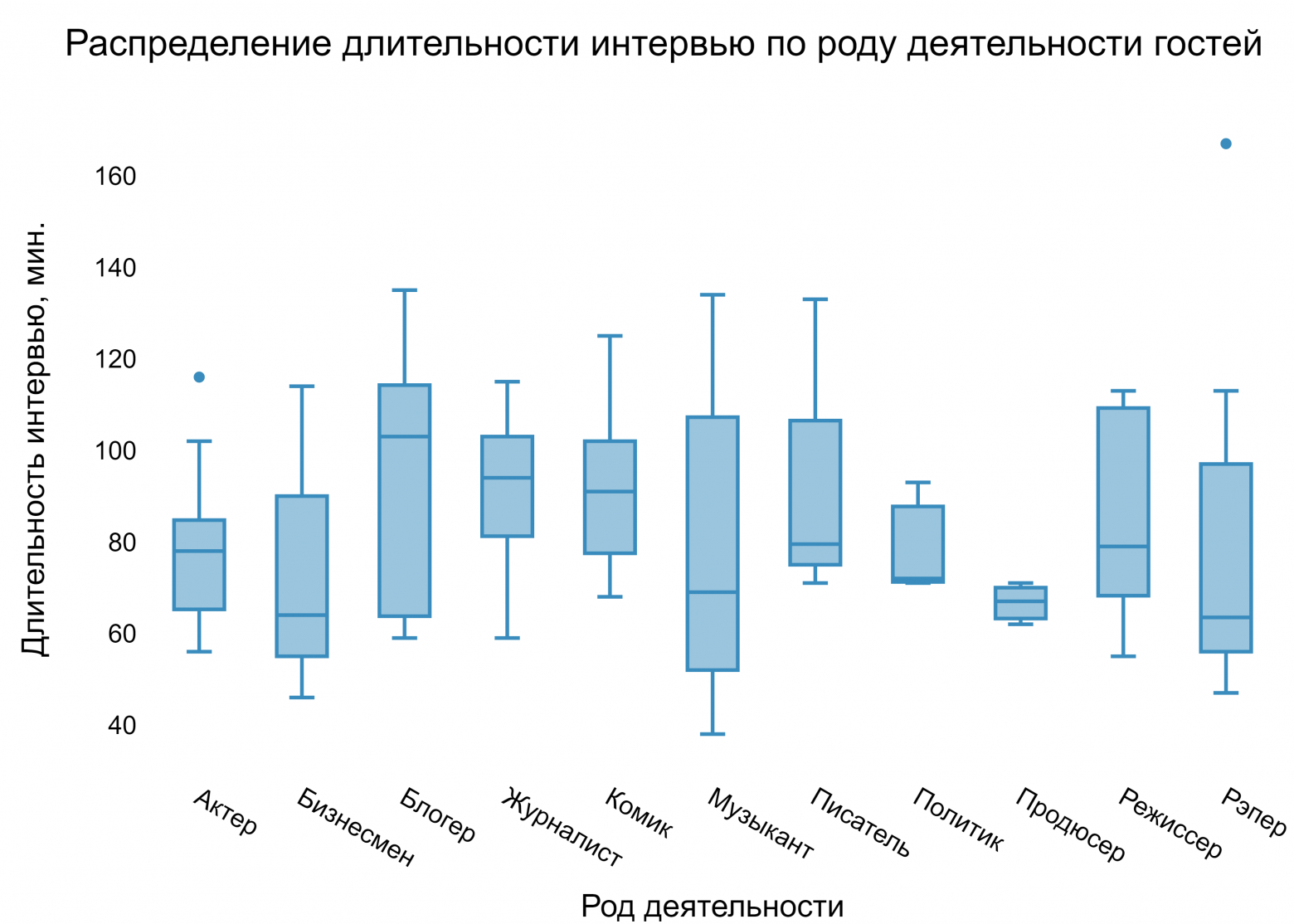
К тому же, разные роды деятельности представляет разное количество человек, это тоже могло сказаться на результатах.
Далее мы составили список слов, появление которых в интервью было бы интересно отследить, и посмотрели как часто они упоминаются для каждого рода деятельности. Также мы решили учесть дисбаланс среди представителей разных профессиональных категорий и разделили полученные частоты на соответствующее количество гостей. Получилось следующее:
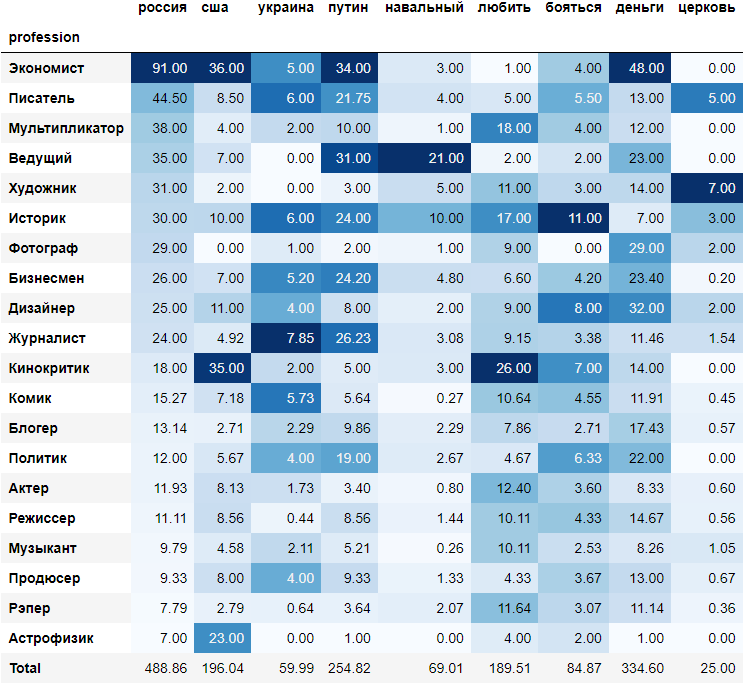
Первое место по упоминаниям очевидно занимает Россия. Что касается Запада, то про США гости говорили в 2,5 раза меньше. Что касается лидера РФ, то про него речь заходила достаточно часто. Его оппонент, Алексей Навальный, в этой словесной “баталии” потерпел поражение. Интересно, что политики далеко не в топе по упоминаниям Путина. Впереди оказался экономист Сергей Гуриев, после него ведущий Александр Гордон, а тройку замкнули журналисты.
Глагол “любить” чаще использовали люди, имеющие отношение к искусству, творчеству и гуманитарным наукам – кинокритик Антон Долин, мультипликатор Олег Куваев, историк Тамара Эйдельман, актеры, рэперы, художник Федор Павлов-Андреевич, комики, музыканты, режиссеры. Про страхи (если судить по глаголу “бояться”) гости говорили реже, чем о любви. В топ вошли историк Эйдельман, дизайнер Артемий Лебедев, кинокритик Долин и политики. Может быть в этом кроется ответ на вопрос, почему же политики не так охотно произносили имя президента России.
Что касается денег, то о них говорили все. Ну, за исключением человека науки, астрофизика Константина Батыгина. С церковью же имеем совершенно обратную ситуацию. О ней по большей части говорили только писатели и художник Павлов-Андреевич.
Анализ мата
Далее мы решили проанализировать то, как часто гости Юрия Дудя ругались матом. С помощью регулярных выражений мы составили словарь матерных слов со всех интервью. После этого, для каждого ролика было подсчитано суммарное количество вхождений элементов составленного словаря.
Мы построили диаграммы, отражающие топ-10 любителей нецензурно выражаться по количеству “запрещенных” слов в минуту.
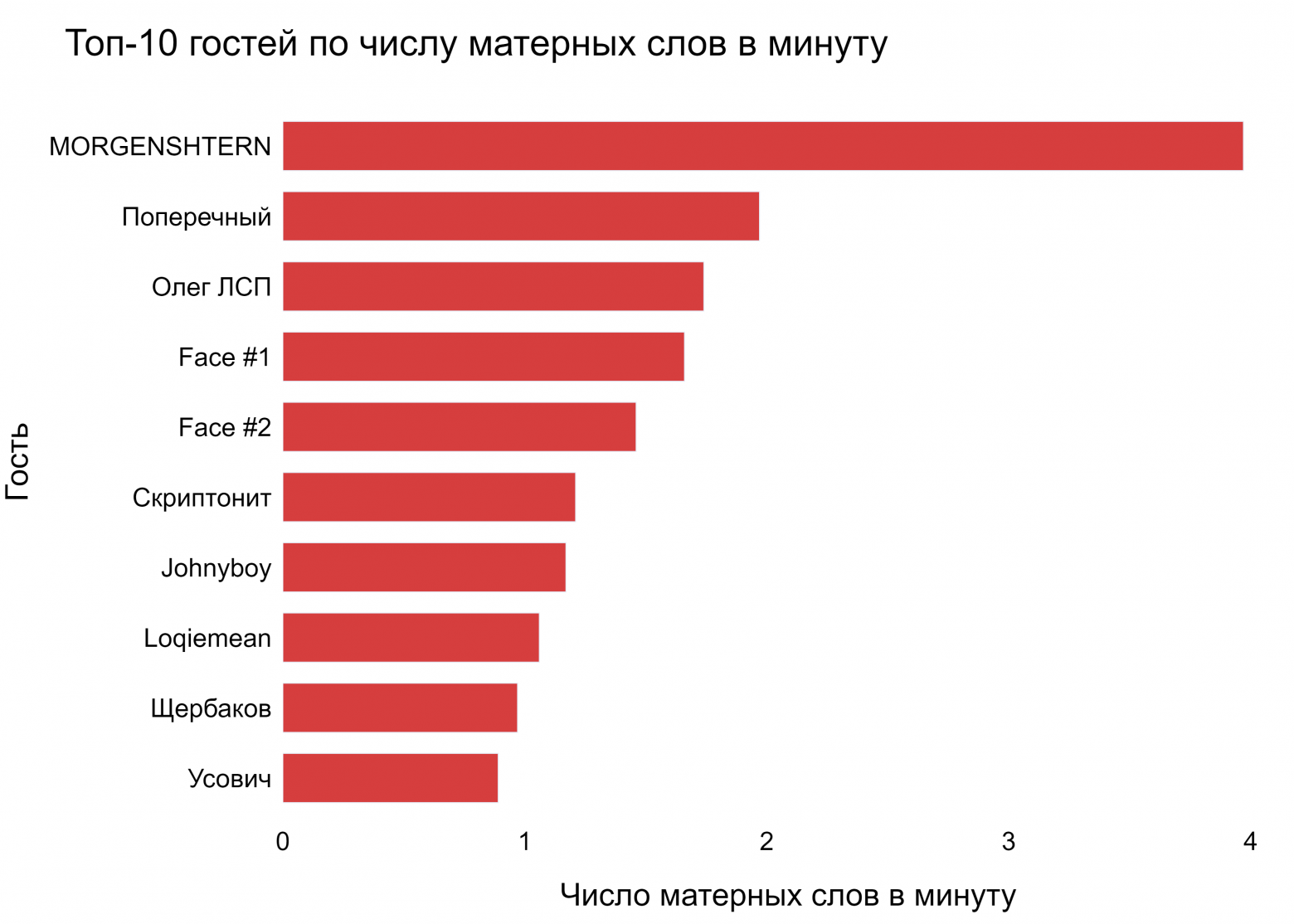
Как видим, рэперы и музыканты почти полностью захватили топ. Помимо них очень часто ругались такие гости как блогер Данила Поперечный и комики Иван Усович и Алексей Щербаков. Первое место в рейтинге с большим отрывом от остальных держит Morgenstern (признан иностранным агентом на территории РФ), а вот Олег Тиньков в своем последнем интервью матерился не так много, чтобы попасть в Топ-10.
Зато, как искрометно!

После персонального анализа мы решили узнать, насколько насыщена нецензурными словами речь представителей разных профессиональных групп. Нулевые показатели при этом были опущены.
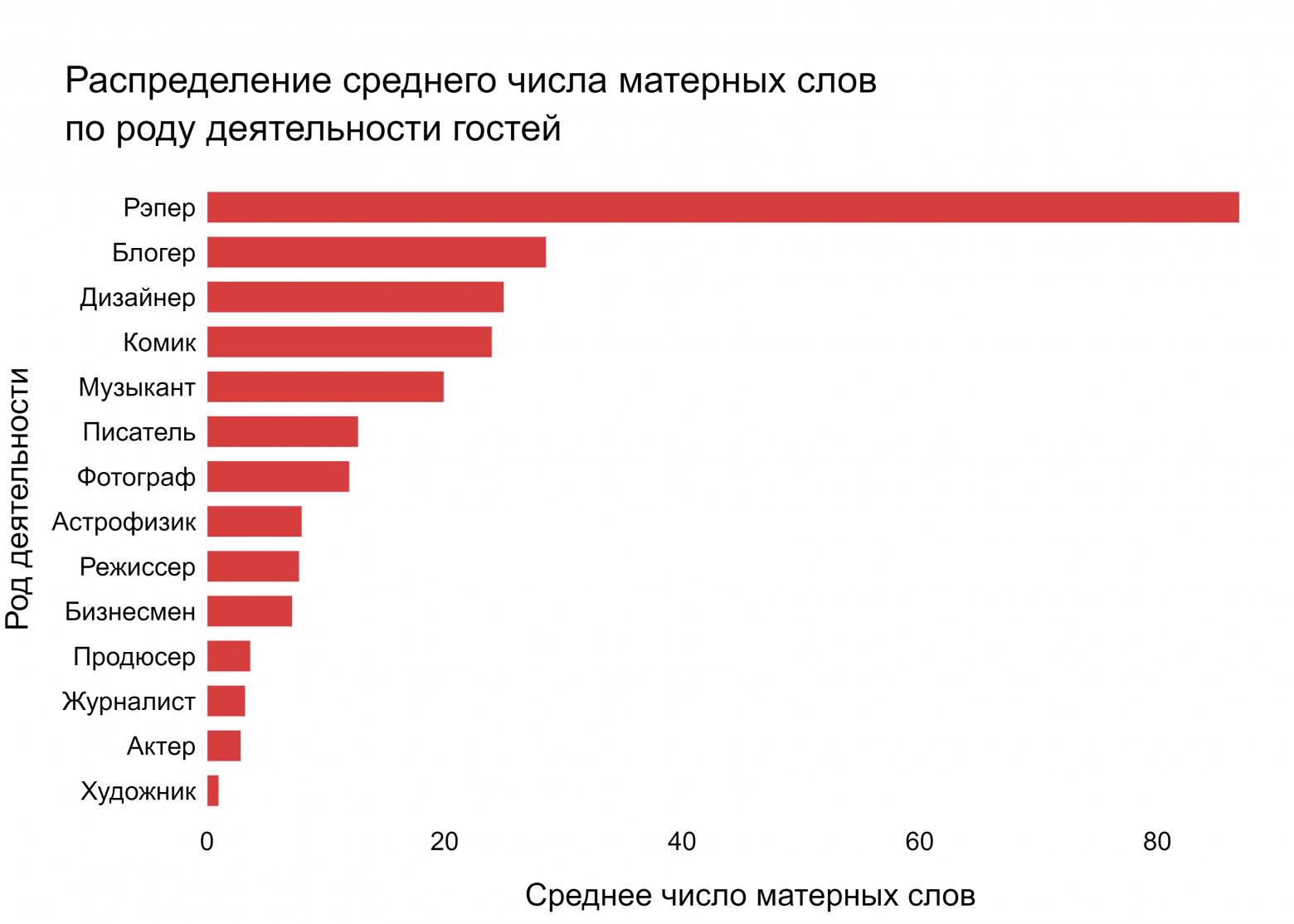
Ожидаемо, что больше всех матерились рэперы. На втором месте оказались блогеры (по большей части за счет Поперечного). За ними следует Артемий Лебедев, единственный дизайнер в нашей выборке, благодаря разнообразия речи которого, представители этой профессии и попали в топ-3 этого распределения. Кстати, если вы еще не знакомы с нашим анализом телеграм-канала Лебедева, то мы не понимаем, чего же вы ждете!
Ограничения анализа
Стоит отметить, что в нашем небольшом исследовании есть два недостатка:
Как уже говорилось ранее, мы не смогли отделить слова гостей Дудя от речи Юрия, который и сам зачастую не брезгует использовать нецензурные выражения. Однако, задача интервьюера – подстроиться под стиль речи гостя, поэтому, скорее всего, результаты бы не сильно изменились.
В автосгенерированных субтитрах нам встретилось некое подобие цензуры - некоторые слова были заменены на ‘[ __ ]’. Тут можно выделить несколько интересных моментов:
действительно некоторые матерные слова были зацензурены (по большей части слово “б***ь”);
остальные матерные слова остались нетронутыми;
под чистку попали некоторые другие грубые слова, при этом не являющиеся матерными (“мудак”, “гавно”).
Продемонстрируем наглядно на примере следующего диалога:
Дудь: Почему твои треки такое гавно?
Гнойный: Мои треки ох**тельные, Юра, просто ты любишь гавно.

Такие замены встречались в субтитрах роликов с людьми, которые не употребляли нецензурные выражения в своей речи (по крайней мере на протяжении интервью). Однозначное решение, что же делать с ‘[ __ ]’, мы не смогли принять, поэтому для некоторых гостей какая-то часть матерных слов была, увы, не подсчитана.
Работа с Word2vec
После статистического анализа интервью мы перешли к определению их контекста. Для этого мы, как и раньше, воспользовались моделью Word2vec. Она основана на нейронной сети и позволяет представлять слова в виде векторов с учетом семантической составляющей. Косинусная мера семантически схожих слов будет стремиться к 1, а у двух слов, не имеющих ничего общего по смыслу, она близка к 0. Модель можно обучать самостоятельно на подготовленном корпусе текстов, но мы решили взять готовую - от RusVectores. Для ее использования нам понадобилась библиотека gensim.
Мы рассчитали векторы-представления для каждой профессиональной группы. Наверное, можно ожидать, что режиссёры обсуждали кино и все, что с ним связано, а музыканты - музыку. Поэтому для каждого рода деятельности мы получили список слов, описывающих тематику текстов соответствующих роликов. Также мы раскрасили ячейки в зависимости от того, насколько каждое полученное слово было близко к текстам соответствующей категории гостей.
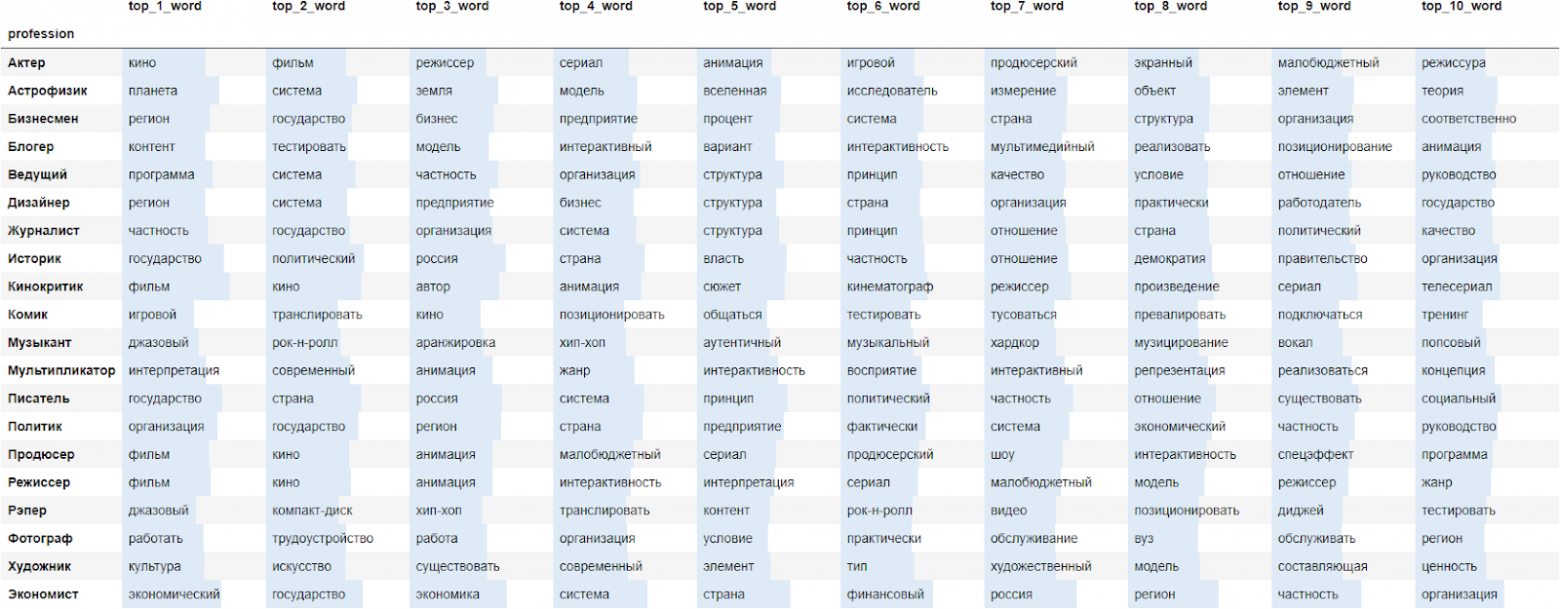
Можно сказать, что в целом каждая профессиональная категория описывается вполне соответствующими терминами. Конечно, некоторые слова могут показаться спорными. К примеру, на первом месте для рэперов стоит слово “джазовый”, хотя ни с 1 представителем хип-хоп течения речь о джазе не заходила. Тем не менее модель посчитала, что это слово достаточно близко к общему смыслу интервью людей, относящихся к этой категории (видимо, за счет непосредственного отношения рэперов к музыке).
P.S. Мистическое число 25.000000
Как мы уже говорили, среди скачанных субтитров некоторые были написаны вручную. Интересно, что все они начинаются с числа 25.000000, причем оно нигде не озвучивается.

Что же это за мистическое число? Если уйти в конспирологию, то можно вспомнить про 25-й кадр. К сожалению, нам об этом ничего неизвестно, мы просто оставим вам это как пищу для размышлений…