
Это третья и заключительная часть руководства по антипаттернам деплоя в Kubernetes. Советуем также ознакомиться с первой и второй частями статьи.
Список антипаттернов, которые мы рассмотрим:
Использование образов с тегом latest
Сохранение конфигурации внутри образов
Использование приложением компонентов Kubernetes без необходимости
Использование для деплоя приложений инструментов для развёртывания инфраструктуры
Изменение конфигурации вручную
Использование кubectl в качестве инструмента отладки
Непонимание сетевых концепций Kubernetes
Использование неизменяемых тестовых окружений вместо динамических сред
Смешивание кластеров Production и Non-Production
Развёртывание приложений без ограничения ресурсов
Неправильное использование Health Probes
Вы не используете Helm
Вы не собираете метрики приложений, позволяющие оценить их работу
Отсутствие единого подхода к хранению конфиденциальных данных
Попытка перенести все ваши приложения в Kubernetes.
11. Неправильное использование Health Probes
В прошлом антипаттерне мы рассказали о необходимости ограничивать ресурсы (limits), доступные приложениям, которые вы переносите в Kubernetes. Также следует настраивать проверки работоспособности (health probes).
По умолчанию приложения, развёрнутые в Kubernetes, не имеют health probes. По аналогии с лимитами вы должны рассматривать проверки работоспособности как неотъемлемую часть конфигурации ваших приложения в Kubernetes. Это означает, что все ваши приложения должны иметь лимиты и проверки работоспособности при развертывании в любом кластере Kubernetes.
Проверки работоспособности определяют, когда ваше приложение готово принимать трафик. Как разработчик, вы должны понимать, как работают health probes в Kubernetes (особенно, на что влияют тайм-ауты для каждой из них).
Типы проверок работоспособности:
Startup probe => Проверяет начальную загрузку вашего приложения. Запускается только один раз.
Readiness probe => Проверяет, способно ли ваше приложение принимать подключения. Работает постоянно. Если проверка вернёт ошибку, Kubernetes не будет больше направлять трафик в pod c этим приложением (и попробует выполнить повторную проверку позже).
Liveness probe => Проверяет работоспособность вашего приложения. Работает постоянно. Если проверка вернёт ошибку, Kubernetes перезапустит контейнер с приложением.
Стоит потратить время, чтобы разобраться, как работает каждый тип проверок доступности.
Несколько распространённых ошибок при использовании health probes:
Не учитывается состояние внешних сервисов в readiness probe (например, баз данных)
Используются одинаковые проверки для readiness и liveness probes
Не учитываете, что приложение запускается в контейнере, а не в виртуальной машине
Не используются средства проверки доступности вашего programming framework (если они есть)
Создание слишком сложных проверок работоспособности с неверными интервалами срабатывания (это может привести к отказу в обслуживании других приложений внутри кластера)
Проверки работоспособности приводят к каскадным сбоям при проверке внешних служб
Появление каскадных сбоев — очень распространенная проблема, которая разрушительна даже для виртуальных машин и балансировщиков нагрузки (т.е. не является специфической для Kubernetes)

Предположим, что у вас есть 3 службы, которые используют службу Auth в качестве зависимости. В идеале liveness probe для каждой службы должна проверять, может ли сама служба отвечать на запросы. Однако, если вы настроите liveness probe для проверки зависимостей, может произойти следующий сценарий:
Изначально все 4 сервиса работают корректно (включая Auth)
Служба аутентификации начинает работать некорректно
Все 3 сервиса определяют, что в работе службы аутентификации возникли проблемы
Несмотря на то, что все 3 сервиса работают корректно, результат проверки работоспособности зависит от состояния сервиса Auth
Kubernetes запускает liveness probe и решает, что все 4 сервиса не работают, и перезапускает их все (хотя на самом деле только у одного из них возникла проблема)
12. Вы не используете Helm
Сейчас для Kubernetes есть только один менеджер пакетов — Helm. Вы можете рассматривать Helm как аналог утилит apt / rpm для ваших кластеров Kubernetes.
К сожалению, люди часто неправильно понимают возможности Helm и выбирают «альтернативу». Helm — это менеджер пакетов, который также включает возможности создания шаблонов. Но это не решение для создания шаблонов, и сравнение его с одним из специализированных приложений не совсем верно.
Все решения для шаблонизации имеют одну и ту же проблему. Они могут творить чудеса при развертывании приложений, но после деплоя у вас остаётся только набор манифестов. При этом концепция «приложения» теряется, и ее можно воссоздать, только имея под рукой исходные манифесты.
Helm, с другой стороны, знает обо всем приложении и хранит информацию о нём в кластере. Helm отслеживает ресурсы приложения ПОСЛЕ развертывания. Разница может показаться небольшой, но эти различия очень важны.
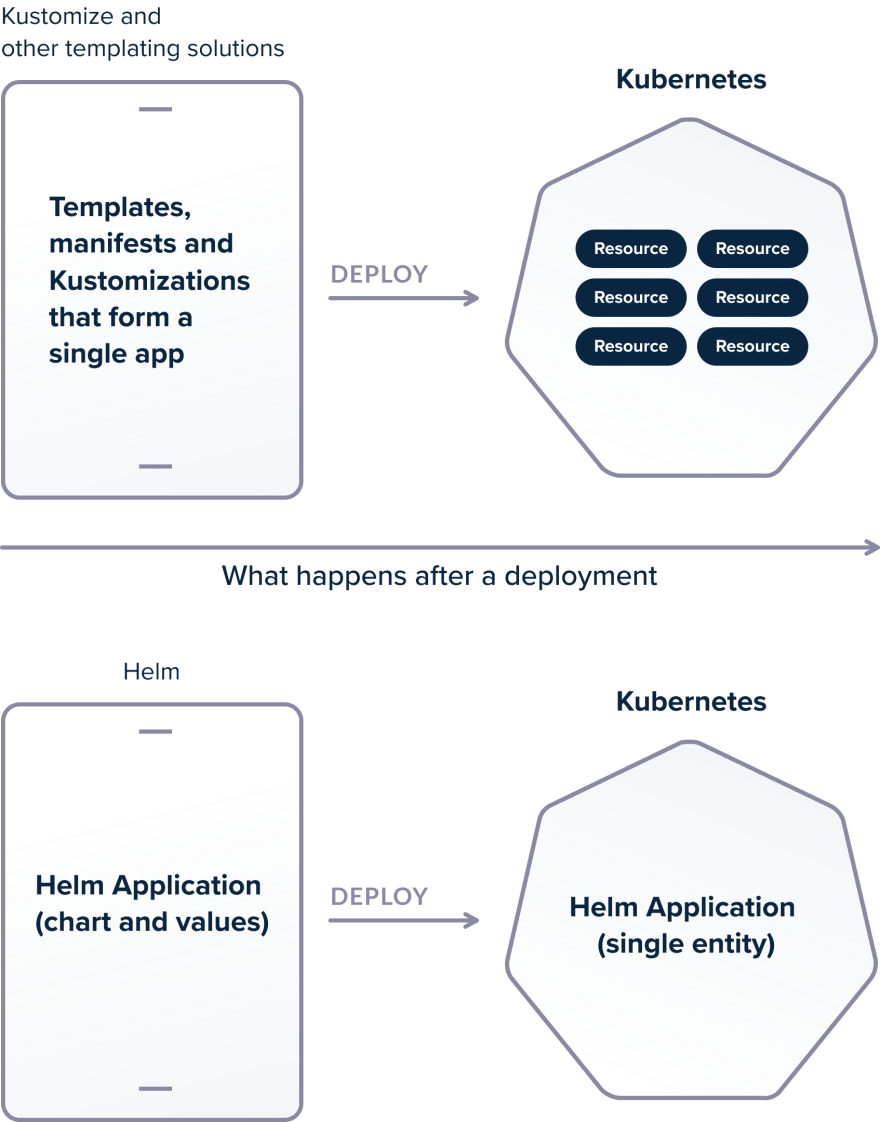
Допустим, вы получаете доступ к kubectl в кластере с 4 приложениями (каждое из которых состоит из нескольких объектов) в одном пространстве имен. Ваша задача — удалить одно из этих приложений.
Если вы использовали утилиту для создания шаблонов (например, Kustomize), вы не сможете легко понять структуру приложения, глядя на существующие ресурсы. Если у вас нет исходных шаблонов, вам потребуется вручную проверить все объекты с помощью kubectl и выполнить корреляцию между компонентами приложения.
Helm отслеживает приложение внутри кластера. Достаточно выполнить команды:
helm ls(чтобы посмотреть список приложений в пространстве имен)helm uninstall my-release(удалить приложение)
Это удобно! Вам не нужны ни исходные шаблоны, ни доступ к системе CI.
Сравнение Helm с Kustomize / k8compt / kdeploy и другими инструментами для создания шаблонов несправедливо по отношению к Helm, поскольку Helm — это гораздо больше, чем просто решение для создания шаблонов.
Одной из отличных функций Helm является возможность отката к предыдущей версии приложения. Вас будят в 3 часа ночи, и вы хотите выполнить максимально быстрый откат в кластере Kubernetes, с которым вы раньше не работали. У вас просто нет времени на поиск предыдущих версий шаблонов в Git.
Решить эту задачу с Helm очень просто:
helm ls(вывести список релизов)helm history my-release(отобразить историю версий)helm rollback my-release my-previous-version(откат к предыдущей версии)
И все это прямо из кластера, потому что Helm знает, что такое приложение в отличие от приложений для шаблонизации, которые останавливают свою работу после завершения развертывания.
Другое заблуждение состоит в том, что пакеты Helm нужно хранить в Git-репозитории. Это не так, чарты Helm должны управляться с помощью репозиториев Helm. Но вы также можете хранить копию ваших чартов в Git. Главное, чтобы установка Helm-чарта в кластере происходило из репозитория Helm, а не Git.
Также стоит отметить, что, начиная с Helm 3, больше нет серверного компонента (печально известного Tiller), поэтому, если раньше вы сталкивались с проблемами безопасности, вам нужно по-новому взглянуть на Helm без Tiller.
13. Вы не собираете метрики приложений, позволяющие оценить их работу
В предыдущих антипаттернах мы несколько раз упоминали метрики. Под метриками мы на самом деле подразумеваем:
логирование — для изучения событий и деталей запросов (обычно после инцидента),
трассировка — чтобы отследить маршрут каждого запроса (обычно после инцидента),
метрики — для обнаружения инцидента (желательно проактивно).
Метрики в Kubernetes намного важнее, чем для традиционных виртуальных машинах из-за распределенного характера всех сервисов в кластере (микросервисы). Приложения Kubernetes эфемерны (в отличие от виртуальных машин количество экземпляров приложения в Kubernetes может меняться, отдельные реплики могут пересоздаваться), и вам необходимо контролировать каждое из этих приложений.
Какое решение вы выберете для сбора метрик, не так важно, если оно предоставляет достаточно информации:
своевременное получение важной информации вместо использования kubectl (см. антипаттерн 6),
понимание того, как трафик входит в ваш кластер и каково текущее узкое место (см. антипаттерн 7),
проверка / актуализация ограничений ресурсов приложений (см. антипаттерн 10).
Однако наиболее важная задача — это понять, успешно ли выполнено развертывание. Тот факт, что контейнер запущен, не означает, что ваше приложение находится в рабочем состоянии и может принимать запросы (антипаттерн 11).
В идеале метрики не должны быть чем-то, на что вы смотрите время от времени. Метрики должны быть неотъемлемой частью вашего процесса развертывания. Некоторые организации придерживаются рабочего процесса, при котором показатели проверяются вручную после развертывания, но этот процесс неоптимален. Метрики должны обрабатываться автоматически:

Развёртывание приложения
Проверка метрик (и сравнение с целевым состоянием)
Деплой либо помечается как завершенный, либо выполняется откат. Обратите внимание, что эти действия не выполняются вручную.
Выбор правильных метрик для контроля развёртывания — непростая задача. Однако вы будете знать конечную цель и скоро поймёте, насколько важны метрики для деплоя в Kubernetes.
14. Отсутствие единого подхода к хранению конфиденциальных данных
Во втором антипаттерне мы объяснили, почему запекание конфигурации в контейнерах — плохая практика. Это еще более актуально для секретов. Если вы используете специализированный сервис для изменения конфигурации, имеет смысл использовать тот же (или аналогичный) сервис для обработки секретов.
Существует несколько подходов к обработке секретов: начиная с хранения в git (в зашифрованном виде) и до внедрения специализированного решения такого, как хранилище Hashicorp Vault.
Некоторые распространенные ошибки:
использование нескольких способов обработки секретов,
смешивание runtime secrets и build secrets,
использование сложных механизмов внедрения секретов, делающих локальную разработку и тестирование трудными или даже невозможными
Здесь важно выбрать стратегию и придерживаться ее. Все команды должны использовать один и тот же метод обработки секретов. Все секреты из всех сред следует хранить одинаково. Это упрощает отслеживание секретов (зная, когда и где был использован секрет).
Вы также должны передавать каждому приложению только те секреты, которые ему действительно нужны.
Runtime secrets — это секреты, которые нужны приложению ПОСЛЕ развертывания. Примерами могут служить пароли базы данных, сертификаты SSL и закрытые ключи.
Build secrets — это секреты, которые применяются ДО / ВО ВРЕМЯ развёртывания. Примером могут быть учетные данные для вашего репозитория артефактов (например, Artifactory или Nexus) или для хранения файлов в корзине S3. Эти секреты не нужны в производственной среде и никогда не должны отправляться в кластер Kubernetes. Каждое развернутое приложение должно получать только те секреты, которые ему необходимы (и это верно даже для непроизводственных кластеров).
Как мы также упоминали в антипаттерне 3, управление секретами должно осуществляться гибко, чтобы упростить тестирование и локальное развертывание вашего приложения. Это означает, что приложение не должно заботиться об источнике секретов и должно сосредоточиться только на их использовании.

Например, несмотря на то, что Hashicorp Vault имеет гибкий API для получения секретов и токенов, ваше приложение Kubernetes НЕ должно использовать этот API напрямую для получения необходимой информации. Если вы сделаете это, то тестирование приложения локально превратится в кошмар, поскольку разработчику потребуется локально настроить экземпляр хранилища или имитировать ответы хранилища только для запуска приложения.
15. Попытка перенести все ваши приложения в Kubernetes
Как и все предшествующие технологии, Kubernetes — это всего лишь инструмент, который решает определенный набор проблем. Если эти проблемы для вас актуальны, вы обнаружите, что внедрение Kubernetes значительно упрощает ваш рабочий процесс и предоставляет вам решение кластеризации, которое отлично спроектировано и поддерживается.
Однако важно понимать преимущества и недостатки внедрения Kubernetes. По крайней мере, сначала гораздо проще использовать Kubernetes для запуска сервисов без сохранения состояния (stateless services), которые будут использовать эластичность и масштабируемость кластера.
Хотя технически Kubernetes поддерживает сервисы с сохранением состояния (stateless services), в самом начале миграции лучше всего запускать такие сервисы вне кластера. Это нормально, если вы храните базы данных, решения для кеширования, репозитории артефактов и Docker образов вне кластера (либо на виртуальных машинах, либо в облачных сервисах).
Не останавливайтесь!
Kubernetes — это комплексное решение, требующее особого подхода (сети, хранилище, деплой и т. д.). Процесс деплоя в кластере Kubernetes может значительно отличаться от деплоя на виртуальных машинах.
Вместо того, чтобы пытаться использовать существующие механизмы деплоя, вам следует потратить некоторое время на изучение особенностей деплоя приложений в Kubernetes и не попасть в ловушки, которые мы разобрали в этом руководстве.
Удачных релизов!
")

