
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Всем привет! Меня зовут Игорь, я работаю системным архитектором в CSI. Хочу поделиться историей появления в нашем стеке технологий надежного и универсального брокера сообщений. Расскажу, как и для чего мы его используем, поделюсь полезными нюансами и примером с сетью Fix Price. Статей про Apache Kafka уже более, чем достаточно, но наш кейс немного отличается от стандартного использования. Надеюсь, опыт пригодится кому-то ещё.
Немного о нас
Мы создаём софт для автоматизации торговли крупных и не очень сетей магазинов (продукты, спортивные товары, одежда и т.п.). Несмотря на то, что у нас уже запущена целая экосистема узкоспециализированных программных продуктов, всё начиналось с монолита. Он до сих пор установлен на тысячах серверов наших клиентов — и почти весь софт распространяется on-premise. Такая модель доставляет массу сложностей: поддержка разных операционных систем, выпуск дистрибутивов, доставка обновлений, обеспечение обратной совместимости, интеграция с ИС клиента, обеспечение потребления небольших ресурсов у небольших клиентов и одновременное поддержание необходимой производительности в крупных сетях.
Учитывая более сотни тысяч инсталляций наших касс и серверов магазинов, которые обеспечивают непрерывный товарно-денежный обмен, цена ошибок в софте слишком высока. Нет возможности срочно выкатить/откатить фикс, в отличие от SAAS, PAAS-решений. Есть только возможность выпустить патч, доставить его до клиента и применить на всех узлах сети. Бэклоги команд разработки всегда расписаны минимум на полгода вперед, но нам удаётся решать все эти сложности.
Конечно, не без проблем. Когда в ежемесячных релизах появляются десятки новых фич, неминуемо выскакивают ошибки разной степени критичности – и не всегда их удается обнаружить до выпуска релиза. Для решения этих проблем у нас есть разные программные средства, процессы, регламенты, команды внедрения, линии поддержки. Между тем, количество ритейлеров, использующих наши продукты, ежегодно растет. Надеюсь, мне удалось подчеркнуть особенности и сложности создания и распространения ПО именно в ритейле.

Основные потоки данных
Перед тем, как рассказать, зачем у нас появилась Kafka, расскажу, какие потоки данных существуют в нашем основном продукте, как они реализованы, какие разновидности серверной топологии в торговых сетях.
Далее речь пойдет про тот самый монолит – фронт-офисную систему Set Retail 10. Продукт, без преувеличения, имеет огромное количество функционала, а в каждой торговой сети интегрирован с другими ИС.
Основной процесс интеграции с ERP-системой клиента упрощенно выглядит так:
импорт, обработка и сохранение в БД данных товарного справочника из ERP-системы клиента (название товара, его штрихкоды, цены, принадлежность к группам, категориям, множество свойств, различные ограничения продажи),
асинхронная доставка информации о товарах, ценах до касс,
на кассах осуществляется торговля, формируются и сохраняются в локальную БД документы – чеки и другие типы кассовых документов,
касса асинхронно отправляет эти документы на сервер,
сервер сохраняет чеки в свою БД, выполняет валидацию,
далее сервер отправляет документы в ERP и другие информационные системы клиента.
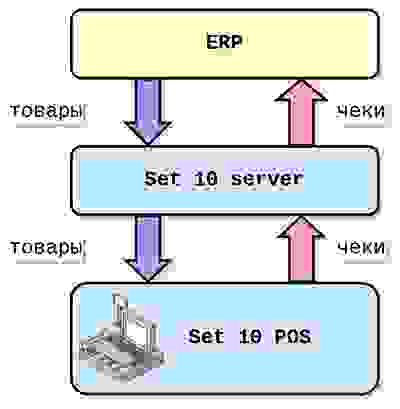
Таким образом, касса не требует наличия сервера магазина онлайн, чтобы продавать товары. Вся необходимая информация содержится в её локальной БД, это, кстати, PostgreSQL.
Отправка товаров на кассы реализована так:
сервер после обработки сериализует данные пачками по 100 шт., сохраняет файлы в папки, который сервер Nginx раздаёт, как статику (размеры файла в среднем 100 - 500 КБайт);
в качестве очередей выступают таблицы БД;
касса периодически вызывает метод сервера и получает упорядоченный список файлов для обработки;
касса по HTTP скачивает файл, десериализует, сохраняет в БД, подтверждает обработку файла вызовом метода на сервере, сервер удаляет запись из таблицы.

Обратный поток данных реализован аналогично:
касса сериализует документ и отправляет файл по HTTP в Nginx, регистрирует имя файла в очереди сервера вызовом метода;
на сервере работает процесс обработки очереди: десериализация полученных файлов, сохранение в БД, удаление файлов.
Изначально Set Retail 10 проектировалась и предназначалась как сервер для одного магазина (супермаркета или гипермаркета), однако с появлением нетипичных для нее задач трансформировалась в центральный сервер для сети магазинов с возможностью централизованной конфигурации и управления. Стала доступна работа и в сетях, где в магазинах нет своего сервера, т.е. один монолит обменивается информацией со всеми кассами.
Все магазины делятся на два типа: с серверами и без
Магазины с выделенными серверами
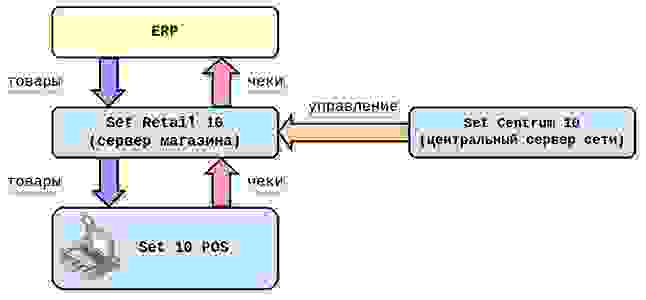
Это типичные гипермаркеты, супермаркеты с множеством касс. В такой конфигурации обмен касс выполняется с сервером магазина, а он, в свою очередь, способен обмениваться с ERP-системами клиента. Таким образом, нагрузка по обмену и обработке информации распределена между всеми серверами магазинов. Отсутствует «бутылочное горлышко» в виде зависимости от центрального сервера — он используется только для управления. Но это требует финансовых затрат на инфраструктуру и её содержание.

Магазины без выделенных серверов
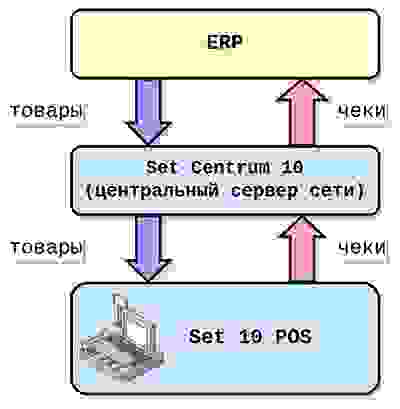
Обычно имеют 2-3 кассы. Это формат ювелирных, спортивных и небольших продуктовых магазинов. До того момента, как у нас появился клиент Fix Price, наш сервер работал в таких сетях только с сотнями касс.

10 000 касс и один сервер
В один прекрасный день появился проект по смене фронт-офисной системы в сети Fix Price. На тот момент в сети было уже более 6000 касс и планировалось расширение до 10000.
Мы тогда уже проводили нагрузочное тестирование сервера и знали, что при количестве касс более 2000 сервер переставал справляться с нагрузкой. Виной всему — реализация обмена данными с кассами. Кассы каждую минуту опрашивают сервер на предмет наличия данных, в несколько потоков, по разным типам данных, что приводит к выполнению множества SELECT и DELETE при подтверждении. Кроме постоянной нагрузки на слой работы с БД, постоянной занятости пула коннектов, есть еще такая проблема, как снижение эффективности индексов таблиц-очередей, известная, как «распухание» индексов.
Из всего этого можно было сделать только один вывод: задачу обмена сообщениями необходимо вынести из монолита, т.е. нам срочно нужен был брокер обмена асинхронными сообщениями.

К выбору брокера были составлены требования:
гарантии доставки at-least-once, exactly-once в зависимости от типа данных;
обеспечение очередности при доставке сообщений как одному получателю, так и всем (здесь имеется в виду, что через один канал может быть отправлено сообщение для всех касс, для касс конкретного магазина, для конкретной кассы);
размер одного сообщения может достигать нескольких мегабайт;
персистентность отправляемых данных, настройка времени хранения недоставленных сообщений;
обеспечивать работу более 10К клиентов с несколькими очередями сообщений (отправка и получение данных);
иметь возможность горизонтального масштабирования, обеспечение отказоустойчивости;
иметь возможность мониторинга доставки сообщений до каждого клиента;
известность (распространенность), наличие подробной документации, готовый клиент для Java;
лицензия Open Source.
Забавно, но когда всё уже было в продакшен, добавилось еще одно требование, об этом чуть позже :)
Итак, после небольшого research, выбор сузился до двух решений: RabbitMQ и Apache Kafka.
Два совершенно разных продукта: push vs poll, богатые возможности vs простота, Erlang vs Java+Scala.
Не буду тут расписывать плюсы, минусы и различия между брокерами, но однозначный выбор нами был сделан в пользу Apache Kafka. В компании уже был небольшой опыт использования его в других продуктах.
Фильтрация доставки сообщений

Apache Kafka реализует единственный паттерн обмена сообщениями publish-subscribe. Producer публикует сообщения в топик, consumer подписывается на топик, выполняет poll и получает сообщения. Причем Consumer не имеет возможности какой-либо фильтрации получаемых сообщений на стороне брокера, т.е. при подписке на топик он будет получать абсолютно все сообщения.
С доставкой документов от касс до сервера всё просто – кассы отправляют в топик, сервер подписан на топик. Надо было только проверить, как брокер «переживет» 10000 отправителей в один топик. А вот с выборочной доставкой сообщений до касс не всё так просто. Есть сообщения для всех касс сети, есть сообщения для касс одного магазина и даже для конкретной кассы, и необходимо соблюдать очередность FIFO для этих сообщений.
Варианты создать по топику или партиции на получателя были отброшены как иррациональные. Можно было бы использовать топики только для отправки сообщений, в которых указывать некий URI на внешний ресурс, например, хранилище S3. Но при on-premise распространении это добавит сложности в развертывании, конфигурировании, мониторинге и освоении «подводных камней» еще одного компонента. Не хотелось также сильно изменять код сервера и кассы в части сериализации и объема передаваемых данных — хотелось добавить лишь ветвление при непосредственно отправке и получении. У каких-то клиентов будет использоваться брокер, но у кого-то останется всё как прежде, on-prem ведь ;).
Изучив возможности API Apache Kafka, мы выбрали такой способ фильтрации сообщений:
два топика: один с payload, другой с event;
producer публикует сообщение в топик с payload и получает метаданные (RecordMetadata): в какую партицию и с каким смещением было сохранено сообщение;
затем producer публикует короткие сообщения в топик с event: кому предназначается сообщение (всем, кассам одного магазина или конкретной кассе) и метаданные о местонахождении payload в топике;
получатель создаёт два consumer: первый всегда подписан на топик с event, если полученное сообщение адресовано ему, то второй consumer выполняет assign на конкретную партицию, seek на конкретное смещение и выполняет poll для чтения сообщения с payload.
Чтобы второй consumer получал только одно сообщение, необходимо, как минимум, задать значение параметра max.poll.records = 1. Также ему нет необходимости выполнять commit.
После того, как работающий прототип доказал право на жизнь, это было реализовано в продукте.

Тестирование и внедрение
Следующим шагом было обязательное нагрузочное тестирование, чтобы убедиться в достижении ожидаемых бизнес-показателей:
скорость доставки всего товарного справочника (20 тысяч товаров, 100 млн цен) до всех касс сети — менее 8 часов;
скорость сохранения чеков на сервере — не менее 100 чеков в секунду (при размере БД в 200 млн чеков)
Также фиксировались предполагаемые проблемные места производительности сервера в части обработки данных, потребление ресурсов брокером Apache Kafka и другие важные нам показатели. Нагрузку от касс, приближенную к реальности, создавали многопоточные эмуляторы, которые получали товары и отправляли чеки. Эмулятор — это по сути простое Spring Boot приложение, которое выполняет периодические RPC вызовы к методам сервера по тому же API, что и касса, с такой же интенсивностью, имеет диапазон номеров магазинов и касс и пул потоков. Понадобилось целых 25 хостов для эмуляции 10 тысяч касс. Под брокеры Apache Kafka были выделены сервера с 8-ядерными CPU Xeon и 16GB RAM.
Результаты нагрузочного тестирования показали, что брокер отлично справляется с такой нагрузкой. Потребление CPU не превышало 30%. Нагрузку на диск мы и не ожидали, исходя из предварительных расчетов, т.к. касса не может отправлять сериализованный в 10-20 КБайт чек чаще, чем раз в минуту, а отправка товаров и цен требует предварительной обработки сервером. Запас оперативной памяти также был более, чем достаточным. Оставшаяся память выделяется ОС для файлового кеша, что только положительно сказывается на производительности чтения данных брокером.
К тому моменту, как решение было реализовано и протестировано в продукте, миграция фронт-офисной системы у клиента уже шла полным ходом. Ежедневно десятки касс меняли свой софт. Монолит пока справлялся с нагрузкой. Мы, конечно, предусмотрели переключение на использование Apache Kafka в рантайм центральным «рубильником». Установили и настроили брокер, создали топики. В час Х поменяли одну настройку, она разлетелась по всем кассам и данные пошли в топики. Этот этап прошёл у нас гладко, без происшествий, что не могло не радовать. Но нас поджидал сюрприз )
Экономия трафика

Не прошло и двух недель, как от клиента поступила жалоба. У них выросли затраты на каналы связи. Оказалось, что при аналитике проекта не была учтена важная деталь. Около 10% магазинов находятся в глубинке, куда еще не добрались витые пары и оптоволокно цивилизации. Связь с магазинами осуществляется по воздуху, при помощи модемов мобильной связи. Трафик ограничен в тарифе на каждый месяц. На весь магазин, в котором обычно 2-3 кассы, ограничение составляет от 6 до 10 ГБ на месяц. Если вычесть трафик на другие нужды и разделить на количество касс, то придётся срочно как-то вписываться в 50 МБайт/день на кассу.
Сниффер на нашем тестовом стенде подтверждал, что трафика тратится на порядок больше. Проблема была не с доставкой большого количества чеков, а с доставкой товаров. Точнее, даже при отсутствии сообщений для конкретных касс магазинов, ими тратилось много трафика. В ход пошло тщательное изучение массы настроек Apache Kafka, мозговой штурм и успокоительное для наших менеджеров :)
Решение этого, не учтенного на старте, требования было комплексным:
long polling,
партицирование топика с event-ами,
подписка каждой кассы только на одну партицию,
настройки consumer, producer.
Подробнее по каждому пункту.
Long polling. Kafka Consumer должен периодически выполнять poll, указывая время ожидания ответа в аргументе (KafkaConsumer.poll(Duration timeout)). Это время ожидания мы увеличили до 5 минут. Если за время ожидания у брокера появляются сообщения — то ответ клиенту поступает сразу.
Количество партиций у топика с уведомлениями мы увеличили до 100. Номер партиции при отправке вычисляется на основе номера магазина получателя (shopNumber % partitionsCount). Если это широковещательное сообщение, то оно отправляется в каждую партицию.
Kafka Consumer на кассе вместо подписки на все партиции топика (subscribe(Collection<String> topics)) теперь подписывается только на одну, вычисляя ее на основе номера магазина (assign(Collection<TopicPartition> partitions)).
Нам необходимо было получать ровно одно payload сообщение, но снифер показывал, что от брокера считывалось больше байт, чем размер этого сообщения. Всё потому, что алгоритм Kafka создан для обеспечения максимальной пропускной способности. Даже если указать в конфиге KafkaConsumer max.poll.records=1, данных может быть считано больше, т.к. предполагается дальнейшее последовательное чтение. Помогла настройка fetch.max.bytes=1. В документации (org.apache.kafka.clients.consumer.ConsumerConfig #MAX_PARTITION_FETCH_BYTES_DOC) сказано, что если размер сообщения больше этой настройки, то одно сообщение всё равно будет доставлено.
Мы также включили сжатие отправляемых сообщений в конфиге продюсера compression.type=gzip. Поскольку payload сообщение в нашем случае — не одна сериализованная сущность, а список до 100 штук — это также дало положительный эффект.
Замеры трафика по результатам всех этих доработок показали, что на «холостой» трафик, т.е. при отсутствии полезных данных касса тратит теперь лишь около 36 МБайт в месяц. Цель достигнута.
Set ESB

Появление Apache Kafka позволило нам не только решить задачу обмена данными в больших сетях, но и разгрузить монолитный сервер от интеграционных задач. Для экспорта данных микросервисы могут теперь подписываться на топики, выполнять преобразование и экспортировать данные во внешние системы.
Название Set ESB в семействе продуктов Set возникло само собой. Это и шина обмена, и интеграция. Да, это не полноценное, мощное и гибкое ESB-решение со своим UI и прочими штуками, что представляется обычно при упоминании этой аббревиатуры. Для нас это — скорее, подход к решению задач и дополнительный компонент именно к нашим продуктам. Для интеграции с ИС клиента у нас создаются микросервисы с использованием Apache Camel, как это завещают Enterprise Integration Patterns.
У наших клиентов может быть установлен разный набор наших продуктов, и обмен между ними осуществляется через общий кластер Apache Kafka. Решение уже внедрено во многих сетях магазинов. Кстати, в Fix Price уже более 12 тысяч касс, и сеть продолжает успешно расширяться.
Кроме доставки сообщений, мы получили возможность строить разные агрегаты в realtime, благодаря фреймворку Kafka Streams. Compacted топики используются как небольшие key-value хранилища в интеграции, не требуя установки отдельных СУБД.
Заканчивая, хочу сказать, что выбор брокера был абсолютно правильным. Продукт постоянно развивается. Zookeeper, например, уже стал необязательным спутником брокера. Кластер из Apache Kafka легко устанавливается и масштабируется, имеет очень подробную документацию и готовые библиотеки для множества языков. Созданный для других задач, благодаря своей гибкости, продуманной архитектуре и хорошему community, он является универсальным средством обмена. Он помог и продолжает помогать нам решать множество нестандартных задач.


