Сегодня специалисты по анализу корпоративных данных стремятся максимально эффективно использовать свои платформы. Хранилище данных играет одну из самых важных ролей, это основа для всех вычислительных механизмов и приложений. Еще один тренд - переход к горизонтально масштабируемой модели хранения, которая позволяет получить хранилища данных высокой плотности, обладающие также высокой надежностью, масштабируемостью и производительностью. Компании Cloudera и Cisco протестировали, насколько это реально, используя узлы хранения с высокой плотностью.
Cloudera в партнерстве с Cisco помогла создать Cisco Validated design (CVD) для Apache Ozone. Валидированная архитектура CVD построена с использованием Cloudera Data Platform (CDP) Private Cloud Base 7.1.5 на стоечном сервере Cisco UCS S3260 M5 с Apache Ozone в качестве распределенной файловой системы для CDP.

КОНФИГУРАЦИЯ APACHE OZONE ВЫСОКОЙ ПЛОТНОСТИ
Apache Ozone - одно из основных нововведений, представленных в CDP, которое поддерживает архитектуру хранения следующего поколения для больших данных, где блоки данных организованы в контейнеры хранения для большего масштаба и для обработки небольших объектов. Это стало серьезным архитектурным усовершенствованием методов управления данными Apache Ozone в большом масштабе в озере данных.
Apache Ozone сочетает в себе лучшее из HDFS и Object Store:
· Преодоление ограничений HDFS.
Может поддерживать миллиарды файлов (протестировано до 10 миллиардов файлов) в отличие от HDFS, которая достигает пороговых значений масштабируемости при 400 миллионов файлов.
Может в настоящее время поддерживать 400 ТБ на узел, а в будущем - 1 ПБ, в отличие от HDFS, которая поддерживает только до 100 ТБ на узел.
Поддерживает диски емкостью 16 ТБ, в отличие от HDFS с дисками до 8 ТБ.

· Преодоление ограничений Object Store.
Apache Ozone, в отличие от других объектных хранилищ, может поддерживать большие файлы с линейной производительностью. Как и HDFS, Apache Ozone разбивает файлы на более мелкие фрагменты (другие хранилища объектов не могут этого сделать и не работают с линейной производительностью с большими файлами, поскольку в большинстве из них большие файлы обслуживаются через один узел, что снижает быстродействие). В Apache Ozone эти более мелкие фрагменты считываются со всех узлов, обеспечивая линейную производительность. При этом размер файла не создает каких-либо проблем с производительностью. Тем самым решаются проблемы работы с большими файлами, которые часто возникают в объектных хранилищах. Экзабайтный масштаб.

Разделение плоскости управления и плоскости данных, что обеспечивает высокую производительность. Поддерживает очень быстрое чтение из нескольких реплик.

Данные из HDFS можно легко перенести в Apache Ozone с помощью знакомых инструментов, таких как distcp. Apache Ozone обрабатывает файлы как большого, так и малого размера.
Ozone имеет простую в использовании консоль мониторинга и управления.

Собирает и объединяет метаданные из компонентов и представляет состояние кластера.
Метаданные в кластере не пересекаются по компонентам
Ни один компонент не может вычислить общее состояние кластера.
Как пользователю/инженеру службы поддержки Ozone, мне может потребоваться:
Просмотреть детали томов / корзин / ключей / контейнеров / конвейеров / узлов данных.
Для данного файла выяснить, частью каких узлов / конвейеров он является.
Понять, хорошо ли распределены данные между узлами Datanodes и дисками Datanode.
Узнать о наличии пропущенных файловых блоков (или недостаточно реплицируемых).
Поддерживает дезагрегацию уровней вычисления и хранения данных.

Методология тестирования
ГЕНЕРАЦИЯ ДАННЫХ В БОЛЬШОМ МАСШТАБЕ
Для создания фейковых данных для Ozone был написан инструмент генератора данных. Он работает, записывая записи синтетической файловой системы непосредственно в Ozone OM, SCM и DataNode RocksDB, а затем записывает файлы фейковых блоков данных в DataNodes. Это значительно быстрее, чем запись реальных данных с помощью приложения или другого клиента. Запуская этот инструмент параллельно на всех узлах хранения в кластере, мы можем заполнить все узлы данными по 400 ТБ в кластере менее чем за день.
С помощью этого инструмента мы смогли генерировать большие объемы данных и сертифицировать Ozone на оборудовании хранения данных высокой плотности. Мы внесли в продукт несколько усовершенствований, чтобы улучшить масштабирование и повысить производительность в соответствии с большой плотностью на каждом узле.
СТАНДАРТНЫЕ ЭТАЛОННЫЕ ТЕСТЫ
На этой тестовой установке мы проверили производительность Impala TPC-DS. Используемые шаблоны запросов и образцы запросов соответствуют стандартам, установленным спецификацией эталонного тестирования TPC-DS, и включают только незначительные модификации запросов (MQM), как указано в разделе 4.2.3 спецификации. Все эти скрипты можно найти по адресу impala-tpcds-kit. Во время выполнения теста было включено локальное кэширование Impala. Результаты тестирования показывают, что производительность 70% запросов совпала или улучшилась по сравнению с теми же запросами, выполняемыми с HDFS в качестве файловой системы.
ОБРАБОТКА ОТКАЗОВ
Потеря одного или нескольких узлов с высокой плотностью вызывает значительный трафик повторной репликации. Для обеспечения высокой надежности и доступности данных важно, чтобы файловая система быстро восстанавливалась после сбоев оборудования. Для эффективного восстановления после потери плотных узлов Ozone включает оптимизацию, в том числе использование функции multi-RAFT Apache Ozone. Это делается, чтобы улучшить распределение данных и избежать остановки репликации при меньшем количестве узлов.
Мы опубликуем результаты тестов производительности в отдельной статье.
Cisco Data Intelligence Platform
Платформа Cisco Data Intelligence Platform (CDIP) - это архитектура частного облака, рассчитанная на будущие возможности гибридной облачной архитектуры озера данных следующего поколения. Она объединяет большие данные, искусственный интеллект / вычислительную ферму и уровни хранения для совместной работ - как единое целое. Также для решения ИТ-проблем в современном центре обработки данных она предусматривает возможность независимого масштабирования. Эту архитектуру отличает:
Чрезвычайно быстрый сбор и инженерия данных в озере данных.
Ферма вычислений ИИ, позволяющая различным типам платформ ИИ и типам процессоров (CPU, GPU, FPGA) работать с этими данными для дальнейшей аналитики.
Уровень хранения, поддерживающий объем данных до эксабайтного масштаба в системе с высокой плотностью хранения и более низкой стоимостью в долларах за ТБ, что обеспечивает лучшую совокупную стоимость владения.
Простое масштабирование до тысяч узлов с помощью единой панели управления с использованием инфраструктуры Cisco, ориентированной на приложения (Cisco Application Centric Infrastructure, ACI).
Эта архитектура знаменует начало конвергенции трех крупнейших инициатив с открытым исходным кодом: Hadoop, Kubernetes и AI/ML. Ее основу составляют впечатляющий программный фреймворк и технологии на базе Cloudera Data Platform Private Cloud Base и Cloudera Data Platform Private Cloud для работы с большими данными.
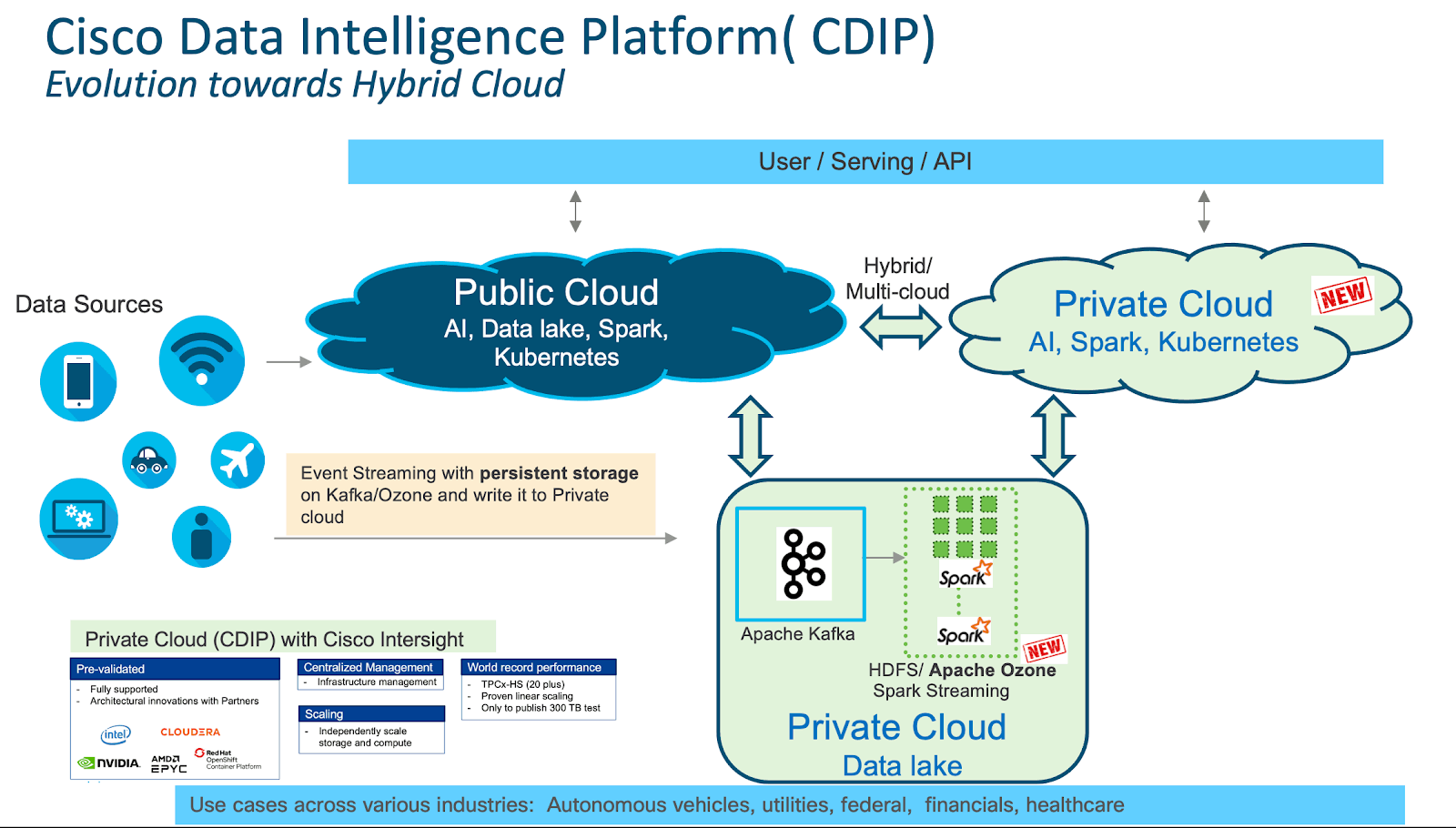
Сценарии использования в разных отраслях.
Стоечные серверы Cisco UCS C240 M5 предоставляют локальное хранилище высокой плотности, оптимизированное по стоимости, с гибкой инфраструктурой для хранения объектов, Hadoop и решений для аналитики больших данных.
CVD предлагает клиентам возможность дальнейшей консолидации их озера данных с увеличенным объемом хранилища на каждый узел данных. Apache Ozone обеспечивает следующие преимущества и экономию средств за счет консолидации систем хранения:
Более низкая стоимость инфраструктуры.
Снижение стоимости лицензирования и поддержки программного обеспечения.
Меньшая занимаемая площадь.
Новые дополнительные сценарии использования с поддержкой HDFS и S3 и миллиарды объектов, поддерживающих как большие, так и маленькие файлы.

CDIP с Cloudera Data Platform Private Cloud Experiences позволяет заказчикам независимо масштабировать хранилище и вычислительные ресурсы, сохраняя при этом локальность данных, аналогичную HDFS предыдущего поколения. Он предлагает архитектуру эксабайтного масштаба с низкой совокупной стоимостью владения (TCO) и перспективную архитектуру с использованием технологий последнего поколения, предоставляемых Cloudera.



