
Введение
Несколько лет назад, мы решили, что настало время поддержать SIMD код в .NET. Мы представили пространство имен System.Numerics с типами Vector2, Vector3,Vector4 и Vector<T>. Эти типы представляют API общего назначения для создания, доступа и оперирования векторными инструкциями, когда это возможно. Они, так же, обеспечивают программную совместимость для тех случаев, где аппаратное обеспечение не поддерживает подходящих инструкций. Это позволило, с минимальным рефакторингом, векторизовать ряд алгоритмов. Как бы там ни было, общность такого подхода делает его сложным в применении с целью получения полного преимущество от всех доступных, на современном аппаратном обеспечении, векторных инструкций. В дополнении, современное аппаратное обеспечение предоставляет ряд специализированных, не векторных, инструкций, которые могут значительно улучшать производительность. В этой статье я расскажу, как мы обошли эти ограничения в .NET Core 3.0.

Примечание: пока ещё нет устоявшегося термина для перевода Intrisics. В конце статьи есть голосовалка за вариант перевода. Если выберем хороший вариант, статью изменим
Что такое аппаратные характеристики
В .NET Core 3.0 мы добавили новую функциональность под названием аппаратные характеристики (Термин 'характеристики' был выбран в качестве перевода слова 'intrinsics' по причине того, что он наиболее точно передает смысл: 'Характеристика' — краткое, но верное описание главных отличительных признаков, свойств чего-либо. Т.к. набор аппаратно-зависимых функции отличает одну платформу от другой, то, мне кажется, логично использовать данный термин при описании наборов функций, посредством которых код получает доступ к инструкциям аппаратного обеспечения.). Эти характеристики обеспечивают доступ ко многим специфичным инструкциям аппаратного обеспечения, которые не могут быть просто представлены механизмами более общего назначения. Они отличаются от существующих SIMD-инструкций тем, что они не имеют общего назначения (новые характеристики не являются кросс-платформенными и их архитектура не обеспечивает программной совместимости). Вместо этого, они напрямую обеспечивают платформенно и аппаратно-зависимую функциональность для разработчиков .NET. Существующие SIMD-функции, к примеру, кросс-платформенные, обеспечивают программную совместимости, и они слегка абстрагированы от лежащего под ними аппаратного обеспечения. Эта абстракция может дорого стоить, к тому же, она может препятствовать раскрытию некоторой функциональности (когда, например, функциональность не существует, или сложно эмулируема на всех целевых платформах).
Новые характеристики, и поддерживаемые типы, расположены под пространством имен System.Runtime.Intrinsics. Для .NET Core 3.0, в настоящий момент, существует одно пространство имен System.Runtime.Intrinsics.X86. Мы работаем над поддержкой характеристик для других платформ, таких как System.Runtime.Intrinsics.Arm.
Под платформо-специфичными пространствами имён характеристики группируются в классы, которые представляют группы логически объединённых инструкций аппаратного обеспечения (часто называемые архитектурой набора команд (ISA)). Каждый класс предоставляет свойство IsSupported указывающее поддерживает ли аппаратное обеспечение, на котором выполняется код, этот набор инструкций. Далее, каждый такой класс содержит набор методов сопоставляемых с соответствующим набором инструкций. Иногда существует дополнительный подкласс, который соответствует части того же набора команд, которая может ограничиваться (поддерживаться) специфичным аппаратным обеспечением. Например, класс Lzcnt обеспечивает доступ к инструкциям подсчёта ведущих нулей. У него существует подкласс, именуемый X64, который содержит форму этих инструкций используемых только на машинах с 64-битной архитектурой.
Некоторые из этих классов имеют естественную иерархическую природу. Например, если Lzcnt.X64.IsSupported возвращает true, тогда Lzcnt.IsSupported также должны вернуть true, так как это явный подкласс. Или, например, если Sse2.IsSupported возвращает true, то и Sse.IsSupported должен вернуть true, потому что Sse2 явным образом наследуется от Sse. Однако, стоит отметить, что схожесть имён классов не является показателем принадлежности их к одной иерархии наследования. Например, Bmi2 не наследуются от Bmi1, поэтому значения возвращаемые IsSupported для этих двух наборов инструкций будут отличаться. Основополагающим принципом при разработке этих классов было явное представление ISA-спецификаций. SSE2 требует поддержки SSE1, поэтому классы, представляющие их, связаны наследованием. В тоже время, BMI2 не требует поддержки BMI1, поэтому мы не использовали наследования. Далее представлен пример описанного выше API.
namespace System.Runtime.Intrinsics.X86
{
public abstract class Sse
{
public static bool IsSupported { get; }
public static Vector128<float> Add(Vector128<float> left, Vector128<float> right);
// Additional APIs
public abstract class X64
{
public static bool IsSupported { get; }
public static long ConvertToInt64(Vector128<float> value);
// Additional APIs
}
}
public abstract class Sse2 : Sse
{
public static new bool IsSupported { get; }
public static Vector128<byte> Add(Vector128<byte> left, Vector128<byte> right);
// Additional APIs
public new abstract class X64 : Sse.X64
{
public static bool IsSupported { get; }
public static long ConvertToInt64(Vector128<double> value);
// Additional APIs
}
}
}Вы можете увидеть больше в исходном коде по следующим ссылкам source.dot.net or dotnet/coreclr on GitHub
Проверки IsSupported обрабатываются JIT-компилятором как константы времени выполнения (когда включена оптимизация), поэтому вам не нужна кросс-компиляция для поддержки нескольких ISA, платформ или архитектур. Вместо этого вам достаточно написать код используя if-выражения, в результате чего неиспользуемые ветки кода (т.е. те ветки, которые не достижимы, вследствие значения переменной в условном операторе) будут отброшены при генерации нативного кода.
Важно чтобы проверка соответствующего IsSupported предшествовала использованию встроенных команд аппаратного обеспечения. Если такой проверки нет, то код, использующий платформенно-зависимые команды, запущенный на платформах/архитектурах где эти команды не поддерживаются, сгенерирует исключение времени выполнения PlatformNotSupportedException.
Какие преимущества они дают?
Конечно аппаратные характеристики не для всех, но они могут быть использованы для повышения производительности в нагруженных вычислениями операциях. Фреймворки CoreFX и ML.NET используют эти методы для ускорения таких операций как копирование в памяти, поиск индекса элемента в массиве или строке, изменение размера изображения, или работа с векторами/матрицами/тензорами. Ручная векторизация некоторого кода, который оказался "бутылочным горлышком", также может быть проще чем кажется. Векторизация кода, в действительности, это выполнения нескольких операций за раз, в общем случае, используя SIMD-инструкции (один поток команд, множественный поток данных).
Перед тем как вы решите проводить векторизацию некоторого кода, необходимо провести профилирование чтобы убедиться, что этот код действительно является частью "горячей точки" (и, поэтому, ваша оптимизация даст существенный прирост производительности). Также важно проводить профилирование на каждом этапе векторизации, так как векторизация не всякого кода приводит к повышению производительности.
Векторизация простого алгоритма
Для иллюстрации использования характеристик возьмём алгоритм суммирования всех элементов массива или диапазона. Такого рода код — это идеальный кандидат на векторизацию, т.к. на каждой итерации выполняется одна и таже тривиальная операция.
Пример реализации такого алгоритма может выглядеть следующим образом:
public int Sum(ReadOnlySpan<int> source)
{
int result = 0;
for (int i = 0; i < source.Length; i++)
{
result += source[i];
}
return result;
}Этот код достаточно прост и понятен, но, в тоже время, достаточно медленный для входных данных большого размера, т.к. делает только одну тривиальную операцию за итерацию.
BenchmarkDotNet=v0.11.5, OS=Windows 10.0.18362
AMD Ryzen 7 1800X, 1 CPU, 16 logical and 8 physical cores
.NET Core SDK=3.0.100-preview9-013775
[Host] : .NET Core 3.0.0-preview9-19410-10 (CoreCLR 4.700.19.40902, CoreFX 4.700.19.40917), 64bit RyuJIT [AttachedDebugger]
DefaultJob : .NET Core 3.0.0-preview9-19410-10 (CoreCLR 4.700.19.40902, CoreFX 4.700.19.40917), 64bit RyuJIT| Method | Count | Mean | Error | StdDev |
|---|---|---|---|---|
| Sum | 1 | 2.477 ns | 0.0192 ns | 0.0179 ns |
| Sum | 2 | 2.164 ns | 0.0265 ns | 0.0235 ns |
| Sum | 4 | 3.224 ns | 0.0302 ns | 0.0267 ns |
| Sum | 8 | 4.347 ns | 0.0665 ns | 0.0622 ns |
| Sum | 16 | 8.444 ns | 0.2042 ns | 0.3734 ns |
| Sum | 32 | 13.963 ns | 0.2182 ns | 0.2041 ns |
| Sum | 64 | 50.374 ns | 0.2955 ns | 0.2620 ns |
| Sum | 128 | 60.139 ns | 0.3890 ns | 0.3639 ns |
| Sum | 256 | 106.416 ns | 0.6404 ns | 0.5990 ns |
| Sum | 512 | 291.450 ns | 3.5148 ns | 3.2878 ns |
| Sum | 1024 | 574.243 ns | 9.5851 ns | 8.4970 ns |
| Sum | 2048 | 1 137.819 ns | 5.9363 ns | 5.5529 ns |
| Sum | 4096 | 2 228.341 ns | 22.8882 ns | 21.4097 ns |
| Sum | 8192 | 2 973.040 ns | 14.2863 ns | 12.6644 ns |
| Sum | 16384 | 5 883.504 ns | 15.9619 ns | 14.9308 ns |
| Sum | 32768 | 11 699.237 ns | 104.0970 ns | 97.3724 ns |
Повышение производительности за счет развертывания циклов
Современные процессоры имеют различные варианты повышения производительности кода. Для однопоточных приложений, одним из таких вариантов выполнение нескольких примитивных операций за один такт процессора.
Большинство современных процессоров могут выполнять четыре операции сложения за один такт (при оптимальных условиях), в следствии чего, при правильной "раскладке" кода, вы можете, иногда, улучшить производительность, даже в однопоточной реализации.
Хотя JIT может выполнить развертку циклов самостоятельно, JIT консервативен при принятии такого рода решения, из-за размеров генерируемого кода. Поэтому, может быть выгодно развернуть цикл, в коде, вручную.
Вы можете развернуть цикл в показанном выше коде следующим образом:
public unsafe int SumUnrolled(ReadOnlySpan<int> source)
{
int result = 0;
int i = 0;
int lastBlockIndex = source.Length - (source.Length % 4);
// Pin source so we can elide the bounds checks
fixed (int* pSource = source)
{
while (i < lastBlockIndex)
{
result += pSource[i + 0];
result += pSource[i + 1];
result += pSource[i + 2];
result += pSource[i + 3];
i += 4;
}
while (i < source.Length)
{
result += pSource[i];
i += 1;
}
}
return result;
}Этот код несколько сложнее, но он лучше использует возможности аппаратного обеспечения.
Для действительно маленьких циклов, этот код выполняется немного медленнее. Но эта тенденция меняется уже для входных данных из восьми элементов, после чего скорость выполнения начинает расти (время выполнения оптимизированного кода, для 32 тыс. элементов, на 26% меньше чем время исходного варианта). Стоит отметить, что такая оптимизация не всегда повышает производительность. К примеру, при работе с коллекциями с элементами типа float "развернутая" версия алгоритма имеет практически ту же скорость, что и исходная. Поэтому очень важно проводить профилирование.
| Method | Count | Mean | Error | StdDev |
|---|---|---|---|---|
| SumUnrolled | 1 | 2.922 ns | 0.0651 ns | 0.0609 ns |
| SumUnrolled | 2 | 3.576 ns | 0.0116 ns | 0.0109 ns |
| SumUnrolled | 4 | 3.708 ns | 0.0157 ns | 0.0139 ns |
| SumUnrolled | 8 | 4.832 ns | 0.0486 ns | 0.0454 ns |
| SumUnrolled | 16 | 7.490 ns | 0.1131 ns | 0.1058 ns |
| SumUnrolled | 32 | 11.277 ns | 0.0910 ns | 0.0851 ns |
| SumUnrolled | 64 | 19.761 ns | 0.2016 ns | 0.1885 ns |
| SumUnrolled | 128 | 36.639 ns | 0.3043 ns | 0.2847 ns |
| SumUnrolled | 256 | 77.969 ns | 0.8409 ns | 0.7866 ns |
| SumUnrolled | 512 | 146.357 ns | 1.3209 ns | 1.2356 ns |
| SumUnrolled | 1024 | 287.354 ns | 0.9223 ns | 0.8627 ns |
| SumUnrolled | 2048 | 566.405 ns | 4.0155 ns | 3.5596 ns |
| SumUnrolled | 4096 | 1 131.016 ns | 7.3601 ns | 6.5246 ns |
| SumUnrolled | 8192 | 2 259.836 ns | 8.6539 ns | 8.0949 ns |
| SumUnrolled | 16384 | 4 501.295 ns | 6.4186 ns | 6.0040 ns |
| SumUnrolled | 32768 | 8 979.690 ns | 19.5265 ns | 18.2651 ns |

Повышение производительности за счет векторизации циклов
Как бы то ни было, но мы можем еще чуть-чуть оптимизировать этот код. SIMD-инструкции -это еще одни вариант, который предоставляется со стороны современных процессоров для повышения производительности. Используя одну инструкцию, они позволяют вам выполнить несколько операций за один такт. Это может быть лучше прямого разворачивания циклов, потому что, по сути, делается тоже самое, но с меньшим объемом генерируемого кода.
Уточним, каждая операция сложения, в развернутом цикле, занимает 4 байта. Таким образом нам требуется 16 байт для 4-х операций сложения в развернутой форме. В то же время, SIMD-инструкция для сложения так же выполняет 4 операции сложения, но занимает лишь 4 байта. Это значит, что мы имеем меньшее количество инструкций для ЦП. В дополнении к этому, в случае SIMD-инструкции, ЦП может сделать предположения и выполнить оптимизацию, но это выходит за рамки данной статьи. Что еще лучше, так это то, что современные процессоры могут выполнить за раз более чем одну SIMD-инструкцию, т.е., в некоторых случаях, вы можете применить смешенную стратегию, одновременно выполнить частичную развертку цикла и векторизацию.
В общем случае, стартовать надо с рассмотрения класса общего назначения Vector<T> под ваши задачи. Он, как и новые аппаратные характеристики, будет встраивать SIMD-инструкции, но при этом, учитывая универсальность этого класса, он позволяет сократить количество "ручного" кодирования.
Код может выглядеть так:
public int SumVectorT(ReadOnlySpan<int> source)
{
int result = 0;
Vector<int> vresult = Vector<int>.Zero;
int i = 0;
int lastBlockIndex = source.Length - (source.Length % Vector<int>.Count);
while (i < lastBlockIndex)
{
vresult += new Vector<int>(source.Slice(i));
i += Vector<int>.Count;
}
for (int n = 0; n < Vector<int>.Count; n++)
{
result += vresult[n];
}
while (i < source.Length)
{
result += source[i];
i += 1;
}
return result;
}Этот код работает быстрее, но мы вынуждены обращаться к каждому элементу отдельно при расчете конечной суммы. Так же Vector<T> не имеет точно определенного размера, и может варьироваться, в зависимости от оборудования, на котором выполняется код. Аппаратные характеристики предоставляют дополнительную функциональность, которая может слегка улучшить этот код и сделать немного быстрее (ценой будут дополнительная сложность кода и требования к обслуживанию).
| Method | Count | Mean | Error | StdDev |
|---|---|---|---|---|
| SumVectorT | 1 | 4.517 ns | 0.0752 ns | 0.0703 ns |
| SumVectorT | 2 | 4.853 ns | 0.0609 ns | 0.0570 ns |
| SumVectorT | 4 | 5.047 ns | 0.0909 ns | 0.0850 ns |
| SumVectorT | 8 | 5.671 ns | 0.0251 ns | 0.0223 ns |
| SumVectorT | 16 | 6.579 ns | 0.0330 ns | 0.0276 ns |
| SumVectorT | 32 | 10.460 ns | 0.0241 ns | 0.0226 ns |
| SumVectorT | 64 | 17.148 ns | 0.0407 ns | 0.0381 ns |
| SumVectorT | 128 | 23.239 ns | 0.0853 ns | 0.0756 ns |
| SumVectorT | 256 | 62.146 ns | 0.8319 ns | 0.7782 ns |
| SumVectorT | 512 | 114.863 ns | 0.4175 ns | 0.3906 ns |
| SumVectorT | 1024 | 172.129 ns | 1.8673 ns | 1.7467 ns |
| SumVectorT | 2048 | 429.722 ns | 1.0461 ns | 0.9786 ns |
| SumVectorT | 4096 | 654.209 ns | 3.6215 ns | 3.0241 ns |
| SumVectorT | 8192 | 1 675.046 ns | 14.5231 ns | 13.5849 ns |
| SumVectorT | 16384 | 2 514.778 ns | 5.3369 ns | 4.9921 ns |
| SumVectorT | 32768 | 6 689.829 ns | 13.9947 ns | 13.0906 ns |

ЗАМЕЧАНИЕ Для этой стати я принудительно сделал размер Vector<T> равным 16 байтам, используя параметр внутренней конфигурации (COMPlus_SIMD16ByteOnly=1). Эта подстройка нормализовала результаты при сравнении SumVectorT с SumVectorizedSse, и позволила сохранить простоту кода последнего. В частности, позволило избежать написания условного перехода if (Avx2.IsSupported) { }. Этот код, почти идентичен коду для Sse2, но имеет дело с Vector256<T> (32-байтным) и обрабатывает еще больше элементов за одну итерацию цикла.
Таким образом, воспользовавшись новыми аппаратными характеристиками код можно переписать следующим образом:
public int SumVectorized(ReadOnlySpan<int> source)
{
if (Sse2.IsSupported)
{
return SumVectorizedSse2(source);
}
else
{
return SumVectorT(source);
}
}
public unsafe int SumVectorizedSse2(ReadOnlySpan<int> source)
{
int result;
fixed (int* pSource = source)
{
Vector128<int> vresult = Vector128<int>.Zero;
int i = 0;
int lastBlockIndex = source.Length - (source.Length % 4);
while (i < lastBlockIndex)
{
vresult = Sse2.Add(vresult, Sse2.LoadVector128(pSource + i));
i += 4;
}
if (Ssse3.IsSupported)
{
vresult = Ssse3.HorizontalAdd(vresult, vresult);
vresult = Ssse3.HorizontalAdd(vresult, vresult);
}
else
{
vresult = Sse2.Add(vresult, Sse2.Shuffle(vresult, 0x4E));
vresult = Sse2.Add(vresult, Sse2.Shuffle(vresult, 0xB1));
}
result = vresult.ToScalar();
while (i < source.Length)
{
result += pSource[i];
i += 1;
}
}
return result;
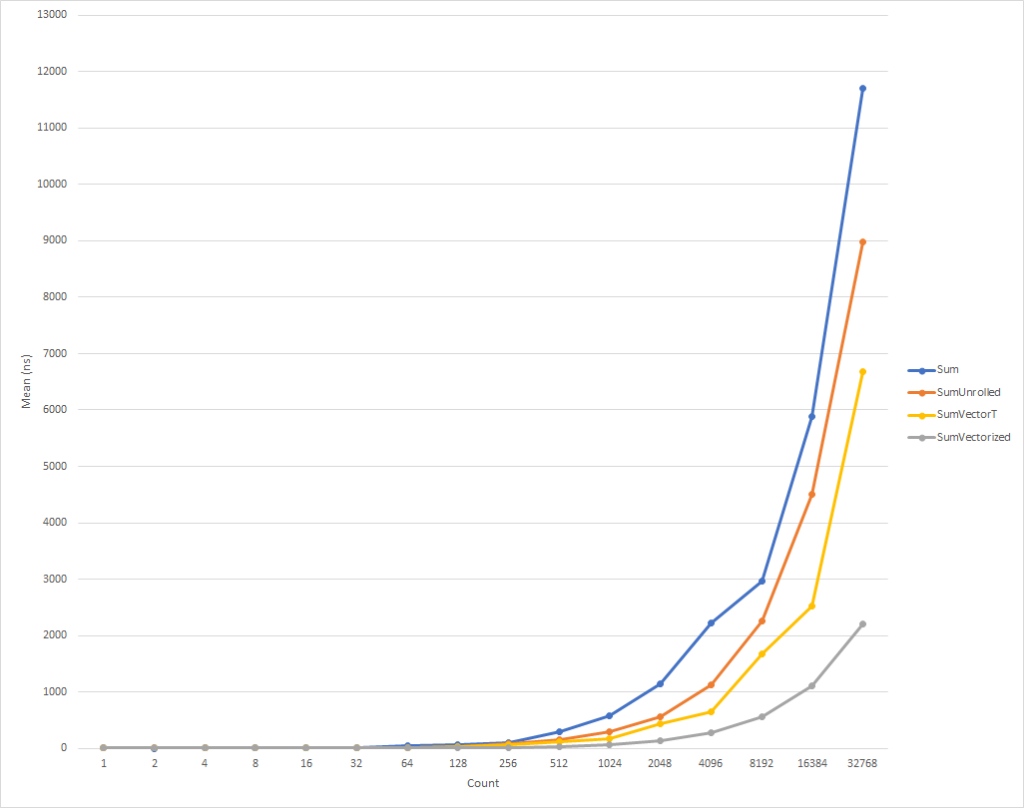
}Этот код, опять таки, немного сложнее, но он значительно быстрее для все, кроме самых маленьких, входных наборов. Для 32 тыс. элементов, этот код выполняется на 75% быстрее чем развернутый цикл, и на 81% быстрее чем исходный код примера.
Вы заметили, что мы написали несколько проверок IsSupported. Первая проверяет, поддерживает ли текущее аппаратное обеспечение требуемый набор характеристик, если нет, то выполняется оптимизация через комбинацию развертки и Vector<T>. Последний вариант будет выбран для таких платформ как ARM/ARM64, которые не поддерживают требуемого набора инструкций, или же если для платформы этот набор был отключен. Вторая проверка IsSupported, в методе SumVectorizedSse2, используется для дополнительной оптимизации, если аппаратное обеспечение поддерживает и набор инструкций Ssse3.
В остальном, большая часть логики, по сути, такая же как и для развернутого цикла. Vector128<T> — это 128-битный тип, содержащий Vector128<T>.Count элементов. В данном случае, uint, который сам 32-битный, может иметь 4 (128 / 32) элемента, именно так мы развернули цикл.
| Method | Count | Mean | Error | StdDev |
|---|---|---|---|---|
| SumVectorized | 1 | 4.555 ns | 0.0192 ns | 0.0179 ns |
| SumVectorized | 2 | 4.848 ns | 0.0147 ns | 0.0137 ns |
| SumVectorized | 4 | 5.381 ns | 0.0210 ns | 0.0186 ns |
| SumVectorized | 8 | 4.838 ns | 0.0209 ns | 0.0186 ns |
| SumVectorized | 16 | 5.107 ns | 0.0175 ns | 0.0146 ns |
| SumVectorized | 32 | 5.646 ns | 0.0230 ns | 0.0204 ns |
| SumVectorized | 64 | 6.763 ns | 0.0338 ns | 0.0316 ns |
| SumVectorized | 128 | 9.308 ns | 0.1041 ns | 0.0870 ns |
| SumVectorized | 256 | 15.634 ns | 0.0927 ns | 0.0821 ns |
| SumVectorized | 512 | 34.706 ns | 0.2851 ns | 0.2381 ns |
| SumVectorized | 1024 | 68.110 ns | 0.4016 ns | 0.3756 ns |
| SumVectorized | 2048 | 136.533 ns | 1.3104 ns | 1.2257 ns |
| SumVectorized | 4096 | 277.930 ns | 0.5913 ns | 0.5531 ns |
| SumVectorized | 8192 | 554.720 ns | 3.5133 ns | 3.2864 ns |
| SumVectorized | 16384 | 1 110.730 ns | 3.3043 ns | 3.0909 ns |
| SumVectorized | 32768 | 2 200.996 ns | 21.0538 ns | 19.6938 ns |
Заключение
Новые аппаратные характеристики дают вам возможность воспользоваться платформенно-специфичной функциональностью машины на который вы запускаете код. Существует примерно 1500 API для X86 и X64 распределенных по 15 наборам, их слишком много для того чтобы описать в одной статье. Профилируя код для определения узким мест вы можете определить ту часть кода, которая выиграет от векторизации и наблюдайте за довольно неплохим приростом производительности. Существует множество сценариев где векторизация может быть применена и развертка циклов это лишь начало.
Все кто хочет увидеть больше примеров может поискать использования характеристик в фреймворке (смотрите dotnet и aspnet), или в других статьях сообщества. И хотя существующие в настоящее время характеристики обширны, все еще есть много функционала, который должен быть представлен. Если у вас есть функциональность, которую вы хотите представить, не стесняйтесь зарегистрировать запрос на API через dotnet/corefx on GitHub. Процес рассмотрения API описан тут и есть хороший пример шаблона запроса на API указанного в шаге 1.
Особые благодарности
Хочу выразить особую благодарность членам нашего сообщества Fei Peng (@fiigii) и Jacek Blaszczynski (@4creators) за помощь в реализации аппаратных характеристик, а так же всем членам сообщества за ценную обратную связь в отношении разработки, реализации и удобства использования этой функциональности.
Послесловие к переводу
*Мне нравится наблюдать за развитием платформы .NET, и, в частности, языка C#. Придя из мира C++, и имея небольшой опыт разработки на Delphi и Java, мне было очень комфортно начать писать программы на C#. В 2006 году этот язык программирования (именно язык) мне показался более лаконичным и практичным, чем Java, в мире управляемой сборки мусора и кросплатформенности. Поэтому мой выбор пал на С#, и я не пожалел. Первый этап эволюции языка было просто его появление. К 2006 году С# впитал в себя все лучшее, что было на тот момент в лучших языках и платформах: C++/Java/Delphi. В 2010-м, в широкий доступ вышел F#. Он был экспериментальной площадкой для изучения функциональной парадигмы с целью внедрения ее в мир .NET. Результатом экспериментов стал следующий этап в эволюции C# — расширение его возможностей в сторону ФП, за счет введения анонимных функции, лямбда выражений, и, в конечном итоге, LINQ. Такое расширение языка сделало C# самым продвинутым, с моей точки зрения, языком общего назначения. Следующий шаг эволюции был связан с поддержкой параллелизма и асинхронности. Task/Task<T>, вся концепция TPL, развитие LINQ — PLINQ, и, в конце концов, async/await. И вот, в последние два-три года, мы наблюдаем новый этап эволюции платформы .NET и языка C# — движение в сторону обеспечения высокопроизводительных вычислений. Сюда относится введение Span<T> и Memory<T>, ValueTask/ValueTask<T>, IAsyncDispose, ref readonly struct и квалификатор in, асинхронынй foreach, IO.Streams. Все эти нововведения направлены на снижение нагрузки на GC и повышения производительности кода. В этой статье, представлен следующий шаг в этом направлении — предоставления разработчику доступа к функциям аппаратного обеспечения. Я рад, что в разработке платформы .NET и языка C#, в частности, участвую инженеры с такими широкими и разносторонними взглядами и интересами. Надеюсь увидеть (а может даже приложить свою руку к этому) еще много интересных поворотов в развитии платформы и языка.*




