
Продолжаем публиковать блог нашего друга Алеса Носека. В первой части мы поговорили про CI/CD-конвейеры с охватом нескольких кластеров OpenShift. А сегодня расскажем об архитектуре системы Apache Airflow на платформе OpenShift, рассмотрим функции ее ключевых компонентов и способы их развертывания применительно к Apache Airflow версии 1.10.12. Напоминаем, что Вы можете задать любой вопрос после прочтения Алесу в комментариях. За самый оригинальный вопрос – набор туриста с картой маршрутов от Red Hat – в подарок. И шляпу!
Архитектура Airflow
Apache Airflow имеет три основных компонента: Webserver, Scheduler и Worker-ы. Webserver отвечает за веб-интерфейс, который является основным инструментом работы с Airflow и позволяет пользователю визуализировать свои DAG-и (Directed Acyclic Graph) и контролировать их выполнение. Кроме того, Webserver предоставляет экспериментальный REST API, которые позволяют управлять Airflow не через веб-интерфейс, а программно. Второй компонент, Airflow Scheduler, оркестрирует выполнение DAG-ов, обеспечивая их запуск в нужное время и в нужном порядке. И Webserver, и Scheduler – это долгоживущие сервисы, а вот третий компонент Airflow, так называемые Worker-ы, представляют собой эфемерные pod-ы. Их создает Kubernetes Executor, и они служат только для выполнения одной-единственной DAG-задачи. После того, как задача выполнена, ее Worker-pod уничтожается. Архитектура Aiflow на платформе OpenShift представлена на рисунке ниже:
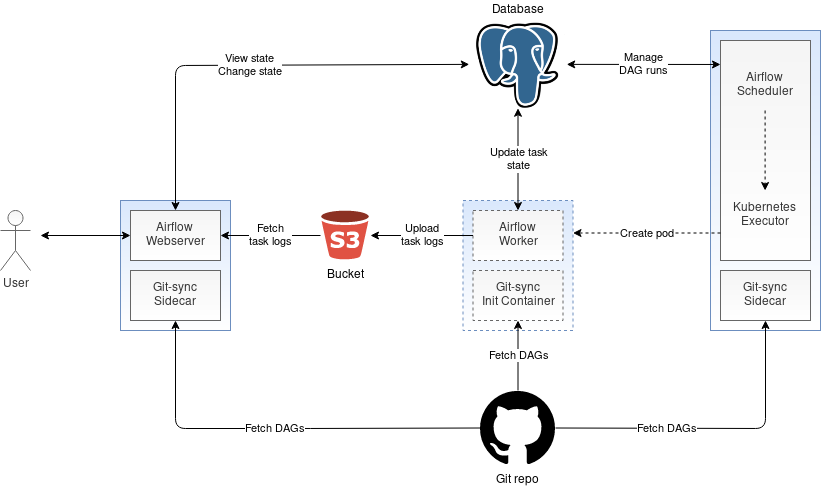
Общая база данных
Как видно из схемы, компоненты Airflow взаимодействует друг с другом не напрямую, а путем чтения и изменения состояний в общей базе данных. Например, Webserver берет из этой БД текущее состояние выполнения DAG и отображает его в веб-интерфейсе. Когда вы запускаете DAG в веб интерфейсе, Webserver обновляет состояние DAG-ов в базе данных. Scheduler периодически проверяет эти состояния и обнаружив запуск и проверив, что время для этого подходящее, диспетчеризует новые задачи на выполнение. После того, как задача выполнена, Worker проставляет для нее соответствующий статус в базе данных, а веб-интерфейс считывает этот статус и показывает пользователю, что задача выполнена.
Архитектура с общей базой данных обеспечивает полностью согласованное представление состояния системы для всех компонентов Airflow. Однако с ростом числа выполняемых задач база данных становится узким местом в производительности, поскольку к ней подключается все больше и больше Worker-ов. Чтобы снизить нагрузку на базу данных, подключения к ней можно пустить через пул соединений, вроде PgBouncer, который будет поддерживать относительно небольшое количество подключений к БД и повторно использовать их для обслуживания запросов от разных Worker-ов.
Что касается выбора СУБД, то в продакшне, как правило, применяют PostgreSQL или MySQL. База данных может выполняться непосредственно на платформе OpenShift, и в этом случае она должна располагаться на постоянном томе RWO (ReadWriteOnce), который организован, к примеру, средствами OpenShift Container Storage. Либо можно задействовать внешнюю БД, например, если ваш OpenShift хостится в облаке AWS, можно воспользоваться управляемым СУБД-сервисом Amazon RDS.
Как предоставить компонентам Airflow доступ к DAG-ам
Все три основных компонента Airflow – Webserver, Scheduler и Worker-ы – построены в расчете на то, что определения DAG-ов можно считать из локальной файловой системы. Но как обеспечить доступ к DAG-ам, когда локальная файловая система находится в контейнере? Тут есть два способа. Первый состоит в том, чтобы создать общий том для хранения всех DAG-ов и подключить его к pod-ам Airflow. Второй подход предполагает, что DAG-и размещаются в репозитории git, а рядом с Airflow Server и Scheduler развертываются sidecar-контейнеры, периодически синхронизирующие репозиторий с локальной файловой системой. Что касается pod-ов Worker, то там DAG-и извлекаются из репозитория только один раз, и это делает init container перед запуском Worker-а.
Обратите внимание, что начиная с Airflow версии 1.10.10, можно использовать функцию DAG Serialization. В этом случае Scheduler считывает DAG-и из локальной файловой системы и сохраняет их в БД. А Webserver затем считывает эти DAG-и из БД, а не из локальной файловой системы. То есть, можно обойтись без подключения общего тома к контейнеру Webserver и без настройки git-sync.
Для синхронизации DAG-ов с локальной файловой системой мы предпочитаем использовать git-sync, а не общие тома. Во-первых, DAG-и всяко лучше держать в системе управления версиями, а во-вторых, git-sync, на наш взгляд, гораздо проще с точки зрения устранения неполадок и восстановления при сбоях.
Мониторинг Airflow
Как известно, без мониторинга продакшн – это не продакшн. Как же мониторить Apache Airflow, работающий на OpenShift? Мы советуем использовать для этого Prometheus – систему мониторинга рабочих нагрузок Kubernetes. Airflow генерирует метрики по протоколу statsd, поэтому потребуется развернуть statsd_exporter в качестве прокладки между Airflow и Prometheus, которая будет агрегировать метрики statsd, конвертировать их в формат Prometheus и затем предоставлять серверу Prometheus.
Сбор логов Airflow
По умолчанию Apache Airflow пишет логи на локальную файловую систему. Если у вас есть постоянный том RWX (ReadWriteMany), то можно подключить его к Webserver-у, Scheduler-у и Worker-ам и писать логи туда. Поскольку логи Worker пишутся на общий том, они тут же доступны Webserver-у, что позволяет просматривать их в веб-интерфейсе в реальном времени.
Либо можно использовать альтернативный подход – удаленное логирование Airflow. В этом случае логи Worker отправляются в какое-то другое место, например, в S3, откуда их потом берет Webserver и отображает в веб-интерфейсе. Обратите внимание, что когда таким удаленным местом служит объектное хранилище, то логи Worker загружаются туда только после того, как задача будет выполнена. А до этого их не получится увидеть в веб-интерфейсе, то есть пропадет контроль в реальном времени.
Удаленное логирование Airflow занимается логами Worker, а что делать с логами Webserver-а и Scheduler-а, если у нас нет постоянного тома? Тогда Airflow можно настроить таким образом, чтобы он сбрасывал логи в stdout, а OpenShift уже будет собирать их и отправлять их в какое-то центральное хранилище.
Заключение
Итак, мы рассмотрели архитектуру Apache Airflow на платформе OpenShift, роли ее отдельных компонентов и то, как они взаимодействуют друг с другом, а также общую базу данных Airflow. Кроме того, мы показали, как сделать DAG-и доступными для компонентов Airflow и рассказали о мониторинге и логах Ariflow.



