С развитием информационных технологий у их пользователей все сильнее и сильнее появляется желание автоматизации рутинных операций, в том числе и автоматической генерации кода. Где это уже возможно?
Я расскажу об автоматической генерации ETL-кода, которая реализована в Сбере на примере одной из использующихся платформ. Поток трансформаций данных в нашем решении называется графом. Этот граф является ориентированным ациклическим графом (DAG, directed acyclic graph). Автоматическую генерацию графов оказалось возможно реализовать благодаря наличию специального инструмента spec-to-graph, который как раз для этого и предназначен. Он позволяет формировать трансформации графа согласно написанному коду, служащему шаблоном. В этом шаблоне указывается, какие трансформации с какими параметрами следует использовать и в каком порядке нужно их соединить. Мы используем подход по генерации графов из базовых субграфов (стандартизированных маленьких графов). Т.е. мы разбиваем ETL-процесс на элементарные операции, каждую из которых реализует некоторый базовый субграф. А из субграфов формируется итоговый граф, осуществляющий загрузку данных. Данные мы грузим из Hive в Hive, дополнительно используя промежуточные индексные структуры в HBase.
Приведу примеры автогенерации кода в различных средах:
В ряде СУБД есть динамический SQL, который может применяться, например, для
Генерации кода по проверке критериев системы контроля качества данных по метаданным
Генерации кода однообразных ETL-процедур
В PowerCenter код преобразований (mappings, workflows) легко преобразовывается в относительно легко читаемый формат XML. Существует промышленный код по генерации XML, представляющих собой экспорт workflows для дальнейшего их импорта в репозиторий, например,
Программа на Python, генерирующая XML для PowerCenter по набору различных шаблонов для разных типов загрузок
В используемом в Сбере пайплайне по загрузке данных имеется специальный продукт spec-to-graph для генерации графов, примером использования которого может служить
Генерация графа из базовых субграфов, реализующих элементарные операции SMTL по загрузке витрин в облако данных для различных дата-продуктов
Начну рассказ о цепочке автогенерации в Сбере, которая генерирует ETL-трансформации. Описание дано на примере одного из вариантов “приземления”. Этот механизм можно тиражировать на различные другие ETL-платформы и фреймворки обработки данных.
Первым делом, аналитик разрабатывает код на языке SMTL по загрузке данных из источников в приёмники. Внутренний сберовский язык SMTL отличается от SQL большей гибкостью. Например, в нём есть возможность указать несколько приёмников с общим мэппингом, указать тип собираемой историчности по таблицам источника, не расписывая подробно долгий код на SQL. SMTL – это декларативный язык, в котором аналитик сообщает, как надо соединить таблицы и извлечь данные для нужных бизнес-сущностей.
Вот пример кода на SMTL, который описывает, как загружать данные по одному из дата-продуктов:
abs("p_tcp", productVersion("1.0.0")).select();
schema("/database/p_tcp/tcpf").select();
table("account", historyNone())
.column("id", pk(), linkTo(table("account_balance_history")
.column("account_id"),ONE_TO_MANY))
.column("account_type_id", linkTo(table("account_type")
.column("id"),MANY_TO_ONE))
.column("contract_id", linkTo(table("contract")
.column("id"),ONE_TO_ONE));
table("account_balance_history")
.column("id", pk());
table("account_type")
.column("id", pk());
table("contract")
.column("id", pk());
target("acct","", rows(table("account")))
.alias("account_type", from("[account_type_id]")
.jump(table("account_type"), historyNone(), once()))
.alias("contract", from("[contract_id]")
.jump(table("contract"), historyNone()))
.alias("account_balance_history_bal", from("[id]")
.jump(table("account_balance_history"),
historyPeriod("account_id", "oper_date", "")))
//.alias("account_balance_history_turn", from("[id]")
.jump(table("account_balance_history"), historyDense("account_id", "oper_date")))
.mapping("open_dt", get("[open_date]"))
.mapping("close_dt", get("[close_date]"))
.mapping("num", get("[account_number]"))
.mapping("@crncy", get("[currency_id]"))
.mapping("name", get("[account_type.name]"))
.mapping("cnsld_flag", get(" case when
[account_type.sign] = 'consolidation' then true else false end"))
//.mapping("dbt_trnovr_amt", currency("act"),
get("[account_balance_history_turn.turn_debit]"))
//.mapping("cred_trnovr_amt", currency("act"),
get("[account_balance_history_turn.turn_credit]"))
.mapping("eod_acct_amt", currency("act"),
get("[account_balance_history_bal.balance_to_end_oper_date]"))
//.mapping("sod_acct_amt", currency("act"), get("case when [account_type.kind] = 'P'
then -1*(coalesce([account_balance_history_bal.balance_to_end_oper_date],0)+
coalesce([account_balance_history_turn.turn_debit],0)-
coalesce([account_balance_history_turn.turn_credit],0)) "
//+" when [account_type.kind] = 'A' then
coalesce([account_balance_history_bal.balance_to_end_oper_date],0)+
coalesce([account_balance_history_turn.turn_credit],0)-
coalesce([account_balance_history_turn.turn_debit],0) end"))
.mapping("@subj", interpreter("'ndl_p_ucprb'"),
get("[contract.client_id]"));
//________________________CRNCY________________________
table("currency", historyNone())
.column("id", pk());
target("crncy","", rows(table("currency"))) //, where("[currency.iso] <> 0")))
.mapping("iso_code", get("[iso]"))
.mapping("name", get("[name]"));
//________________________DIV________________________
target("div", "", rows(table("contract")
, historyNone("tb_number"), choose(MAX, "[id]")
, staticWhere ("[tb_number] is not null")))
.mapping("code", get("[tb_number]"))
.mapping("@div_type",get("'REG_BANK'"));
Код на SMTL – это подобие поступившего от аналитика технического задания на выгрузку витрин данных. Для каждого дата-продукта мы составляем свой код загрузки на SMTL, в котором загружается сразу несколько целевых таблиц. В отличие от SQL мы можем, например, указать, что вычисленный определённым образом атрибут следует поместить сразу в несколько приёмников. Также, в SMTL не надо думать об историчности таблиц: как выстраивать бизнес-историю по нескольким источникам – это забота того, кто пишет приземление SMTL на различные платформы, а не аналитика данных. Уже в приземлении определяется, нужно ли делать полную выгрузку данных или собирать порции изменившихся данных с источников и вести по ним историю изменения атрибутов во времени.
Имеется также GUI, позволяющий формировать код на SMTL с помощью веб-интерфейса:

Забегая вперёд, скажу, что благодаря дизайну возможно написать приземление кода SMTL на самые различные платформы и часть таких приземлений разработана.
Итак, требуется сделать из кода на SMTL граф, который будет загружать данные. Для этого мы применяем подход по генерации графа из базовых субграфов. Поток по трансформации данных разбивается на элементарные операции. Каждой элементарной операции соответствует субграф, реализующий её. Каждый субграф имеет свои параметры, с помощью которых задаётся его режим работы. Примерами таких параметров могут служить:
· режим загрузки (полная/инкрементальная)
· название таблицы Hive или индексной структуры HBase, из которой читаются данные
· условие, по которому отфильтровываются данные
· тип историчности
· конструкция для вычислимого поля, которое добавляется в трансформации
· условие агрегации или дедупликации данных (например, взятие самого последнего состояния исторической сущности на заданную дату)
· ключи, по которым происходит соединение (join) или объединение (union) входящих потоков данных
Приведу наши элементарные операции с кратким описанием, что они делают.
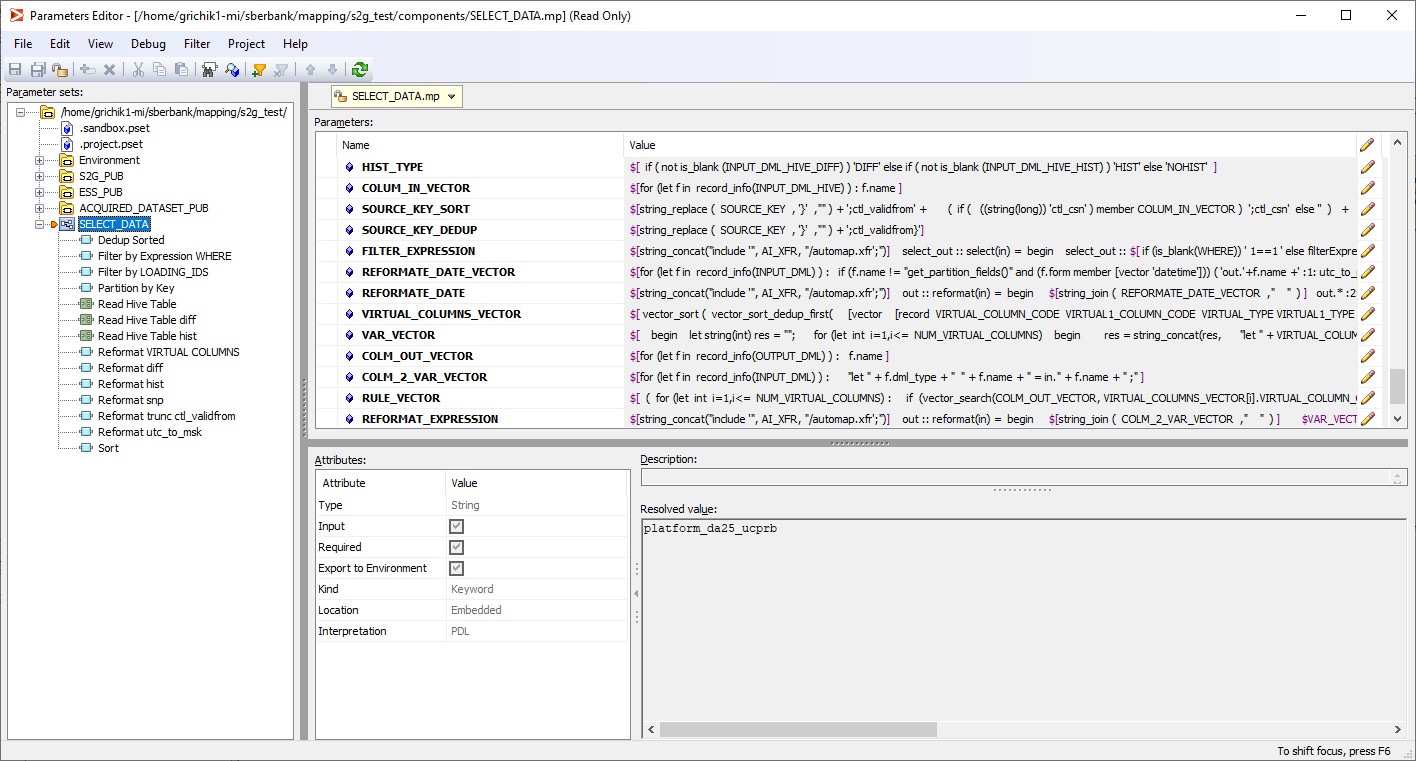
SELECT_DATA – это операция по чтению данных из источника на Hive. В зависимости от режима работы, заданного параметрами, читаются данные из таблицы среза актуального состояния данных, либо из таблиц с дельтой (порцией изменившихся данных). Далее в соответствии с параметрами в потоке данных производится приведение времени Hive к нужному часовому поясу и дедупликация данных. Затем рассчитываются вычислимые поля, применяются фильтры по отсечению данных. Так выглядит реализация этой элементарной операции в виде субграфа:

А так формируется ETL-код этой и других операций согласно входным параметрам. Разработчик пишет код этих трансформаций на языке PDL, который используется нами при генерации ETL-трансформаций. Код PDL-конструкций получается динамический, зависящий от входных параметров.
SELECT_FILTER – это простая операция, которая фильтрует входящий поток данных согласно заданному в параметрах условию. Условие фильтрации задаётся на SQL (диалекте Hive), субграф его парсит и преобразовывает к конструкции на PDL.

SELECT_SET – это операция, которая делает несколько вещей: в инкрементальном режиме особым образом обрабатывает записи, помеченные флагом на удаление; в зависимости от типа историчности выстраивает историю из интервалов постоянства атрибутов; отсекает историю, пришедшую раньше даты отсечки; заполняет дыры в истории пустыми значениями, делая историю непрерывной; дедуплицирует данные по заданным критериям, например, среди нескольких адресов клиента берёт самый последний по дате. В зависимости от входных параметров субграфа может быть задействовано различное количество таких дедупликаторов с разными правилами работы.

SELECT_KEYS – это операция, которая напоминает SQL-оператор UNION, объединяя данные из входящих потоков одинаковой структуры и убирая дубликаты. На картинке мы видим 10 входных портов, но часть из них может быть отключена. При этом происходит объединение такого количества потоков, которое необходимо. Количество активных входов задаётся параметром:

UPDATE_INDEX – это операция, которая сохраняет данные в виде индексированной структуры. Есть две опции – сохранение во внутреннем формате используемой платформы (ICFF), либо сохранение данных в виде таблицы на HBase. Как известно, в Hive нет индексов, однако в состав Hadoop входит и база данных “ключ-значение” HBase. Допустим, мы хотим записать какую-то таблицу, по которой нужен индексный поиск, в HBase. Тогда поля, входящие в индекс, мы должны привести к байтовому формату и склеить в поле key. А поля, по которым не нужен индекс, записываем в поля value. HBase умеет искать данные по ключу как в режиме точного совпадения ключа, так и в режиме диапазонного сканирования. Таким образом, у нас есть возможность записать и затем прочитать индексным сканированием данные в двух режимах. Первый режим – это, когда записали в ключ, например, поле client_id, а затем читаем данные из индекса по такому же ключу client_id. Второй режим – когда записали в ключ таблицы HBase составное значение, склеенное из байтов client_id и account_id, а затем с помощью диапазонного сканирования ищем данные по частичному ключу client_id, подставив на место байтов account_id значения от x00 x00 … x00 до xFF xFF … xFF. Реализация операции UPDATE_INDEX в виде субграфа выглядит так (на самом деле этот субграф состоит из других субграфов, внутренности которых не буду детально расписывать и показывать):

SELECT_INDEX – это операция, парная к UPDATE_INDEX. SELECT_INDEX читает данные из индексной структуры по ключу. По аналогии с UPDATE_INDEX есть два режима чтения: читаются либо данные во внутреннем формате (ICFF), либо из таблицы HBase по ключу. Таким образом, SELECT_INDEX реализует то, что в некоторых ETL-средствах называется Lookup.

UPDATE_DATA – это операция, которая осуществляет соединение (join) входящих потоков данных согласно заданным параметрам. Количество активных входных потоков задаётся параметрами. Кроме того, эта операция наделена некоторым преобразовательным функционалом, например, могут быть добавлены вычислимые поля. В некоторых режимах историчности выполняются особые обработчики записей, помеченных флагом к удалению. Результатом работы этого субграфа является формирование в HDFS файлов с порциями рассчитанных данных. В зависимости от режима работы записывается либо полный срез рассчитанных данных, либо дельта (порция изменившихся данных), которую отдельный процесс (loader) загрузит в целевые структуры облака данных.

ITERATE_START – это операция, которая нужна, чтобы управлять топологией итогового графа. Сама по себе она ничего не делает, но задаёт начало некоторой группы других субграфов:

ITERATE_END – это ещё одна операция, которая нужна, чтобы управлять топологией итогового графа. Является конечной точкой группы входящих потоков, которые завершаются этим субграфом:

Теперь расскажу о том, как собирается итоговый граф из этих базовых субграфов. Имеется фреймворк, написанный на Java, который разбирает входной SMTL и выделяет, какие базовые субграфы требуется использовать. У каждого базового субграфа имеется свой шаблон в формате mustache, который нужно заполнить конкретными значениями параметров из фреймворка. Фреймворк генерирует код, который показывает, какие базовые субграфы с какими параметрами в каком порядке нужно соединить, чтобы получился итоговый граф. Этот код генерируется на PDL и считывается модулем spec-to-graph, который специально создан для генерации графов из исходных трансформаций. В общем случае spec-to-graph может использовать какие угодно трансформации, но мы в качестве “строительного материала” используем только базовые субграфы. Фрагмент кода, который читает spec-to-graph, показан ниже. (Приведен код в нотации PDL, возможны и другие “приземления”. Важен сам подход, а не конкретная реализация “движка”, приведённая в этом посте.) Здесь показано, что надо добавить в итоговый граф субграф UPDATE_INDEX_002 и поместить его выполняться вслед за предшествующим субграфом SELECT_DATA_003. Такими фрагментами мы постепенно наполняем структуру tempEntityInfos, из которой получается целевой граф. Пополняем мы её данными о субграфах:
// UPDATE_INDEX_002
tempEntityInfos = vector_append(tempEntityInfos,
[record
entityProperties [record entity_name "UPDATE_INDEX_002"]
entityJoins [vector [record joined_entity_name "SELECT_DATA_003" is_driver "1"]]
entitySubgraph [vector [record
name "UPDATE_INDEX_002" + "_1"
subgraph_name "subgraphUpdateIndex_" + "UPDATE_INDEX_002"]]
entitySubgraphs [vector [record
subgraph_name "subgraphUpdateIndex_" + "UPDATE_INDEX_002"
subgraph_mp "$AI_COMPONENTS/UPDATE_INDEX.mp"
outputPorts [vector [record
name "namedOut"
port_name "out"
port_dml "record string(\"\") no_fields_used_by_this_output = NULL; end"]]
inputPorts [vector [record
name "namedIn"
port_name "in"
port_dml read_file("${AI_DML}/" + "usl.ndl_p_tcp_gl_SELECT_DATA_003" +
"_output_INITIALIZE.dml")]]
parameters [vector
[record
parameter_name "DATA_PRODUCT"
parameter_value "ndl_p_tcp_gl"
interpolation "pdl"],
[record parameter_name "SCHEMA_CODE"
parameter_value "internal_{{env}}tcp_{{instance}}_tcpf"
interpolation "pdl"],
[record parameter_name "TABLE_CODE"
parameter_value "account_type"
interpolation "pdl"],
[record parameter_name "ROW_KEYS"
parameter_value "{ id }"
interpolation "pdl"],
[record parameter_name "ROW_KEYS_LENGTHS"
parameter_value "{ 18 }"
interpolation "pdl"],
[record parameter_name "INDEX_TYPE"
parameter_value "CARGO"
interpolation "pdl"],
[record parameter_name "INPUT_DML"
parameter_value read_file("${AI_DML}/" +
"usl.ndl_p_tcp_gl_SELECT_DATA_003" +
"_output_INITIALIZE.dml")
interpolation "pdl"]
]]]]);
tempEntityInfos = vector_append(tempEntityInfos,
[record entityProperties [record entity_name "UPDATE_INDEX_002_Lookup_File"
entity_type 'top'
entity_dml "record string(\"\") no_fields_used_by_this_output = NULL; end"
entity_url "${AI_SERIAL}/" + "UPDATE_INDEX_002_Lookup_File" + ".txt"]
entityJoins [vector [record joined_entity_name "UPDATE_INDEX_002" is_driver "1"]]]);
В результате работы фреймворка из входного кода на SMTL получается граф по загрузке дата-продукта, который загружает сразу несколько целевых таблиц из различных таблиц-источников:

Так мы осуществили преобразование кода из текстового формата к визуальному формату из ETL-трансформаций, который при должной сноровке хорошо читаем и понятен. Разработать подобный код вручную, ничего нигде не напутав, очень трудоёмко и сложно.
Скажу ещё пару слов о том, как разрабатываются и дорабатываются базовые субграфы. Мы используем test driven development. Для каждой элементарной операции аналитик пишет набор тест-кейсов из входных данных и эталонных целевых данных, которые должны получиться в результате работы этой элементарной операции. Разработчик запускает скрипт по массовой проверке этих тест-кейсов и проверяет, соответствуют ли результаты работы субграфа эталонным ожиданиям. А если они не соответствуют, то на выходе формируются файлы с разницей между реальным и ожидаемым результатами. Эти файлы можно проанализировать, произвести отладку и скорректировать субграфы так, чтобы они проходили все тест-кейсы. Сверку результатов с эталонами делаем в той же среде, что и генерацию графов:

Также у нас есть некоторые результаты по успешному приземлению кода SMTL на другие платформы: на SQL (диалекта Hive) и на Spark. Приземление на Spark реализовано в режиме интерпретатора. Т.е. код SMTL читается, составляется DAG и поэтапно выполняется в Spark контексте. Делается это без генерации и компиляции Spark-приложения (например, *.jar).
Автор: Михаил Гричик, эксперт профессионального сообщества Сбербанка SberProfi DWH/BigData.
Профессиональное сообщество SberProfi DWH/BigData отвечает за развитие компетенций в таких направлениях, как экосистема Hadoop, Teradata, Oracle DB, GreenPlum, а также BI инструментах Qlik, SAP BO, Tableau и др.



