

Один из ключевых моментов в обеспечении высокой доступности — быстрая реакция на сбой. Хотя нередко можно встретить ручное управление базами данных и систему мониторинга, которая следит за их состоянием и отправляет предупреждения дежурному персоналу. А это означает, что кому-то, возможно, придется проснуться среди ночи, добраться до компьютера, войти в систему и посмотреть логи — то есть до начала восстановления может пройти довольно много времени. В идеале весь этот процесс должен быть автоматизирован.
В этой статье мы рассмотрим, как развернуть полностью автоматизированную систему, которая детектируют отказ первичной базы данных, и инициирует failover, изменяя роль (promote) вторичной базы данных. Для реализации автоматического failover базы данных Moodle PostgreSQL мы будем использовать ClusterControl.
Преимущество автоматического failover
Уменьшается время на восстановление базы данных
Увеличивается время uptime
Уменьшается зависимость от DBA или администраторов, настраивающих высокую доступность баз данных
Архитектура

На текущий момент у нас есть один первичный сервер Postgres и два вторичных — все за балансировщиком нагрузки HAProxy, который отправляет трафик Moodle на первичный узел PostgreSQL. Для настройки автоматического failover в ClusterControl есть важные параметры восстановления кластера (cluster recovery) и узла (node auto recovery).

На какой сервер переключаться
В ClusterControl есть белый и черный списки серверов, с помощью которых вы можете настраивать участие в failover.
В конфигурации cmon это две переменные:
replication_failover_whitelist— список IP-адресов или имен вторичных серверов, которые должны использоваться в качестве потенциальных кандидатов на роль первичного сервера. Если эта переменная установлена, то будут рассматриваться только эти хосты.replication_failover_blacklist— список хостов, которые никогда не будут рассматриваться в качестве кандидата на роль первичного сервера. Вы можете использовать этот список для указания вторичных серверов, которые используются для резервного копирования или аналитических запросов. Если аппаратная конфигурации вторичных серверов отличаются, то здесь вы можете указать более медленные сервера.
Процесс автофайловера (auto failover)
Шаг 1
Начинаем загрузку данных на первичном сервере (192.168.33.14) с помощью sysbench.
[root@centos11 sysbench]# /bin/sysbench --db-driver=pgsql --oltp-table-size=100000 --oltp-tables-count=24 --threads=2 --pgsql-host=****** --pgsql-port=6543 --pgsql-user=sbtest --pgsql-password=***** --pgsql-db=sbtest /usr/share/sysbench/tests/include/oltp_legacy/parallel_prepare.lua run
sysbench 1.0.20 (using bundled LuaJIT 2.1.0-beta2)
Running the test with following options:
Number of threads: 2
Initializing random number generator from current time
Initializing worker threads...
Threads started!
thread prepare0
Creating table 'sbtest1'...
Inserting 100000 records into 'sbtest1'
Creating secondary indexes on 'sbtest1'...
Creating table 'sbtest2'...
Шаг 2
После этого остановим первичный сервер Postgres (192.168.33.14). Так как в ClusterControl включен параметр enable_cluster_autorecovery, то на роль первичного будет выбран первый подходящий сервер.
# service postgresql-12 stopШаг 3
ClusterControl обнаружит сбой в работе первичного узла и переключит один из вторичных серверов на роль первичного. Также он изменит настройки на других вторичных серверах таким образом, чтобы они реплицировались с нового первичного сервера.

В нашем случае 192.168.33.13 становится новым первичным сервером, а вторичные сервера теперь реплицируются с него. И HAProxy направляет трафик базы данных с серверов Moodle на новый первичный сервер.

Запуск на 192.168.33.13
postgres=# select pg_is_in_recovery();
pg_is_in_recovery
-------------------
f
(1 row)Запуск на 192.168.33.15
postgres=# select pg_is_in_recovery();
pg_is_in_recovery
-------------------
t
(1 row)Текущая топология
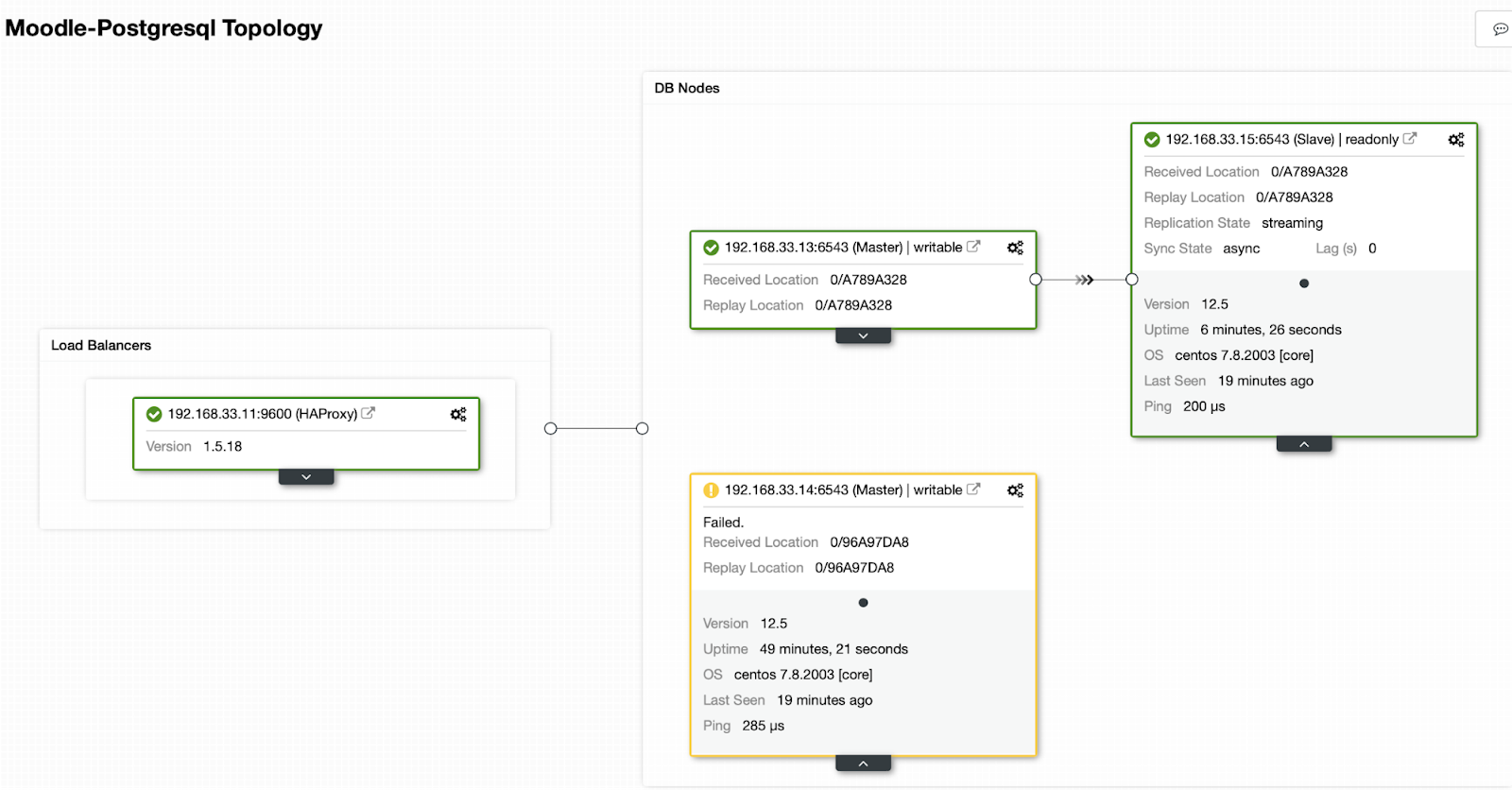
HAProxy автоматически обнаруживает недоступность узлов и перестает отправлять на него трафик. Эта проверка выполняется сценариями проверки работоспособности, которые настраиваются во время развертывания ClusterControl.
После того как ClusterControl повысит роль вторичного сервера до первичного, HAProxy помечает, что старый первичный сервер в оффлайне и переводит новый первичный узел в онлайн.
Когда старый первичный сервер снова заработает, то он не синхронизируется автоматически с новым первичным сервером. Мы должны вернуть его обратно в топологию и сделать это можно через интерфейс ClusterControl. Это позволит избежать потери или несогласованности данных, например, если нужно выяснить причину выхода из строя сервера.
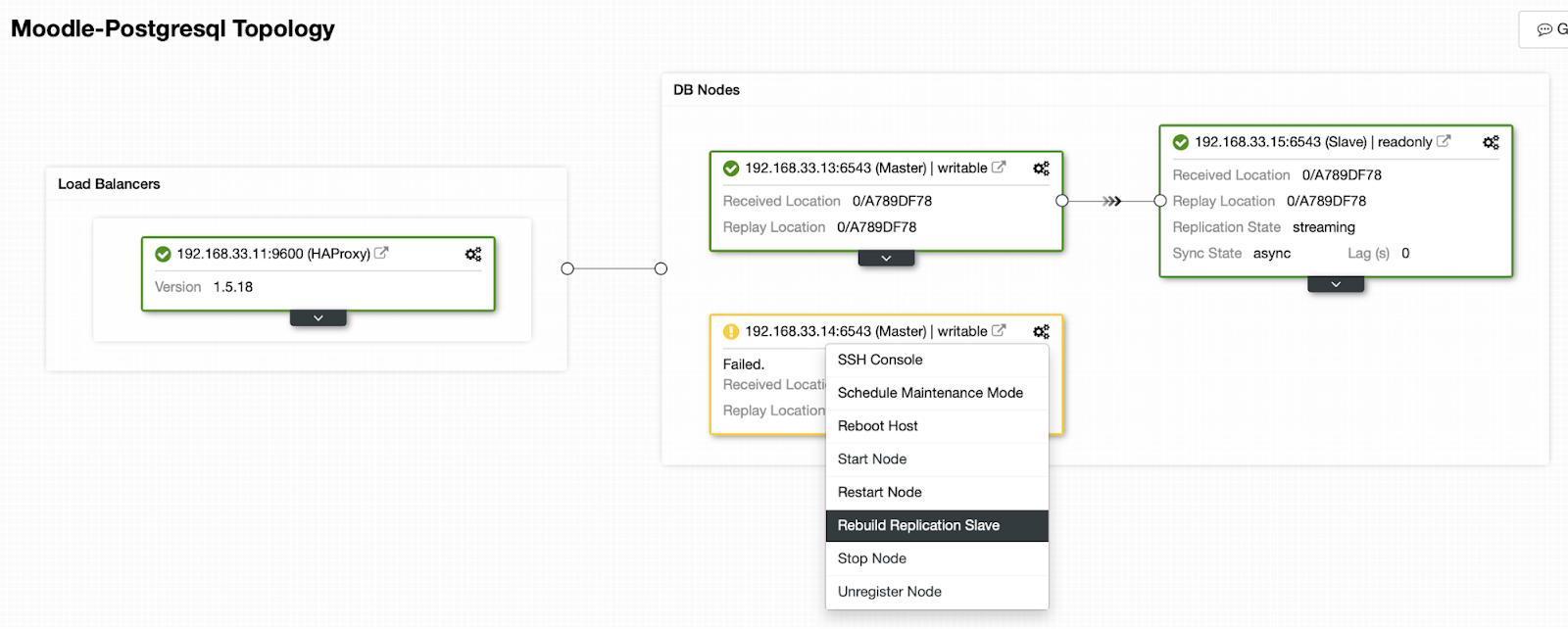
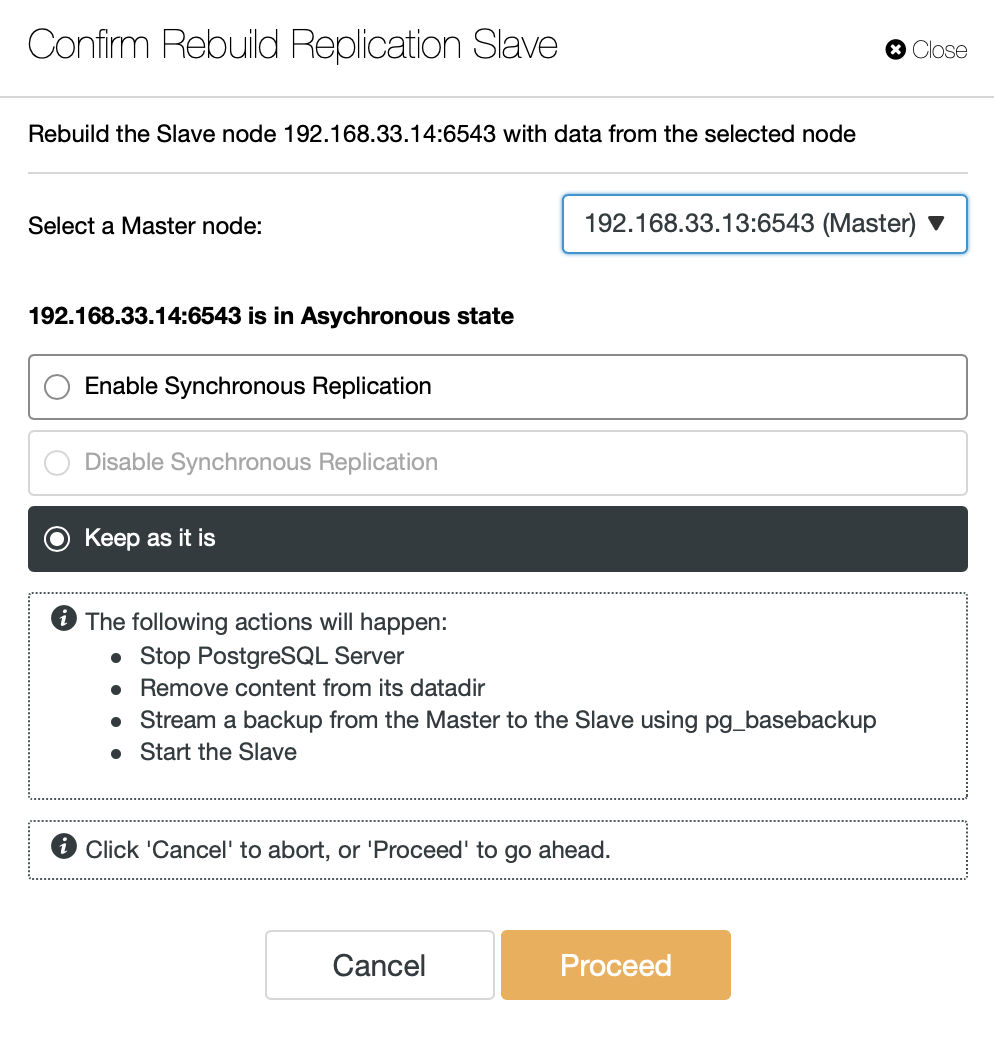
ClusterControl передаст резервную копию с нового первичного сервера и настроит репликацию.
Заключение
Автоматический failover — важная часть любой продуктивной базы Moodle. Благодаря ему можно сократить время простоя при отказе сервера, а также при выполнении задач по обслуживанию и миграции. Важно все настроить правильно, чтобы программное обеспечение автоматического failover могло принять правильные решения.
Перевод статьи подготовлен в преддверии старта курса "PostgreSQL".
Также приглашаем всех желающих на демо-урок «Проблемы миграции данных». В рамках урока:
— поговорим о видах миграции и способах их реализации;
— разберем основные проблемы, связанные с миграцией данных и пути их устранения;
— рассмотрим несколько реальных практических кейсов и порассуждаем над эффективностью их решения;
— вспомним программные средства, позволяющие автоматизировать процесс миграции данных.ЗАПИСАТЬСЯ НА ВЕБИНАР




