
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!

Уже третий год мы проводим форум по искусственному интеллекту RAIF (Russian Artificial Intelligence Forum), на котором спикеры из мира бизнеса и науки рассказывают о своей работе. Самыми интересными докладами мы решили поделиться. В этом посте Андрей Фильченков, руководитель лаборатории машинного обучения ИТМО, рассказывает всю правду об AutoML.
В рамках прошедшего в Сколково форума RAIF 2019, организованного «Инфосистемы Джет», я выступил с докладом, в котором рассказал об AutoML и перспективах его использования. Поскольку я ученый, мне не так уж часто приходится выступать на подобных мероприятиях: обычно я участвую в научных конференциях.
Одной из основных областей, которой мы занимаемся, является AutoML. Кроме того, я являюсь техническим директором двух небольших стартапов. Один из них – Statanly technologies – создает сервисы AutoML и занимается анализом данных. Фактически я являюсь тем человеком, который придумывает алгоритмы, внедряет их и пользуется ими. Наверное, я единственный человек, который может рассказать про AutoML со всех трех возможных позиций.
Что же такое AutoML?
В последний год это направление вызывает большой интерес, и сейчас по фокусу внимания его можно сравнить с популярным в свое время глубоким обучением. Появление автоматического машинного обучения на самом деле можно датировать 1976 годом. Существовало небольшое комьюнити по ML, и в 2017 году оно стало набирать популярность, уже через год выйдя за пределы собственно машинного обучения. Теперь о нем говорят в бизнесе, в промышленности и в разных других областях. Правда, в России, к сожалению, не все люди даже из сообщества ML представляют себе, что такое автоматическое машинное обучение. Почему же так получилось?
Ответ прост – спрос на data scientist-ов растет значительно быстрее, чем они успевают выпускаться из ВУЗов и заканчивать курсы. При этом большую часть времени (до 80%) они тратят на то, чтобы выбрать модель, настроить ее и подождать, пока все обсчитается. Все потому, что не существует идеального алгоритма – к сожалению, любой из них обладает ограниченной областью применения, и специалистам по анализу данных приходится для каждой конкретной задачи подбирать тот алгоритм, который будет оптимален, а потом еще и настраивать его. Тут уже многое зависит от квалификации аналитика: чем больше он знает в предметной области и разбирается в алгоритмах, тем более оптимальное решение может подобрать за определенное время. Здесь-то и помогает AutoML. Собственно, AutoML позволяет автоматизировать и ускорить подбор решений и задач машинного обучения.
Давайте сразу определимся: есть два связанных, но отличных друг от друга направления.
Первое: данные представлены в таблице, есть метки, и когда нам нужно их классифицировать, мы выбираем объект из большого списка и настраиваем его гипер-параметры, а заодно можем обработать данные.
Второй сценарий – более сложный. Например, изображения, последовательности и те области, где сейчас глубокое обучение является стандартом – здесь задача становится чуть интереснее, поскольку можно придумывать новые архитектуры: их не так-то просто перебрать. Так, «Поиск нейронных архитектур», занимается тем, что подбирает оптимальную сеть и настраивает гипер-параметры, которые позволяют решать ту или иную задачу. При этом AutoML не учитывает семантику данных. Есть и методы, которые позволяют «вынимать» описания данных и использовать их для прогноза, но это лишь способствует повышению универсальной применимости AutoML. Совершенно неважно, откуда пришли данные: газовик ли вы, продавец мороженого или кто-то еще – методы универсальны. При этом AutoML позволяет с одной стороны строить наиболее эффективные решения, подбирая сложные и не самые очевидные даже для специалиста по анализу данных конструкции, с другой – быстрее искать и оптимизировать такие решения. И еще одна неочевидная вещь – AutoML дает возможность ускорить написание кода. Вот, например:

Справа код написан на Keras для распознавания MNIST, а слева код для Auto-Keras в библиотеке автоматизации, написанной под Keras. Разница видна, время на написании при этом сэкономлено.
Обилие существующих решений (2019 г.)
На текущий момент существует огромное число разных библиотек и платформ для автоматического анализа данных, я привел лишь некоторые из них (на самом деле, их сильно больше).
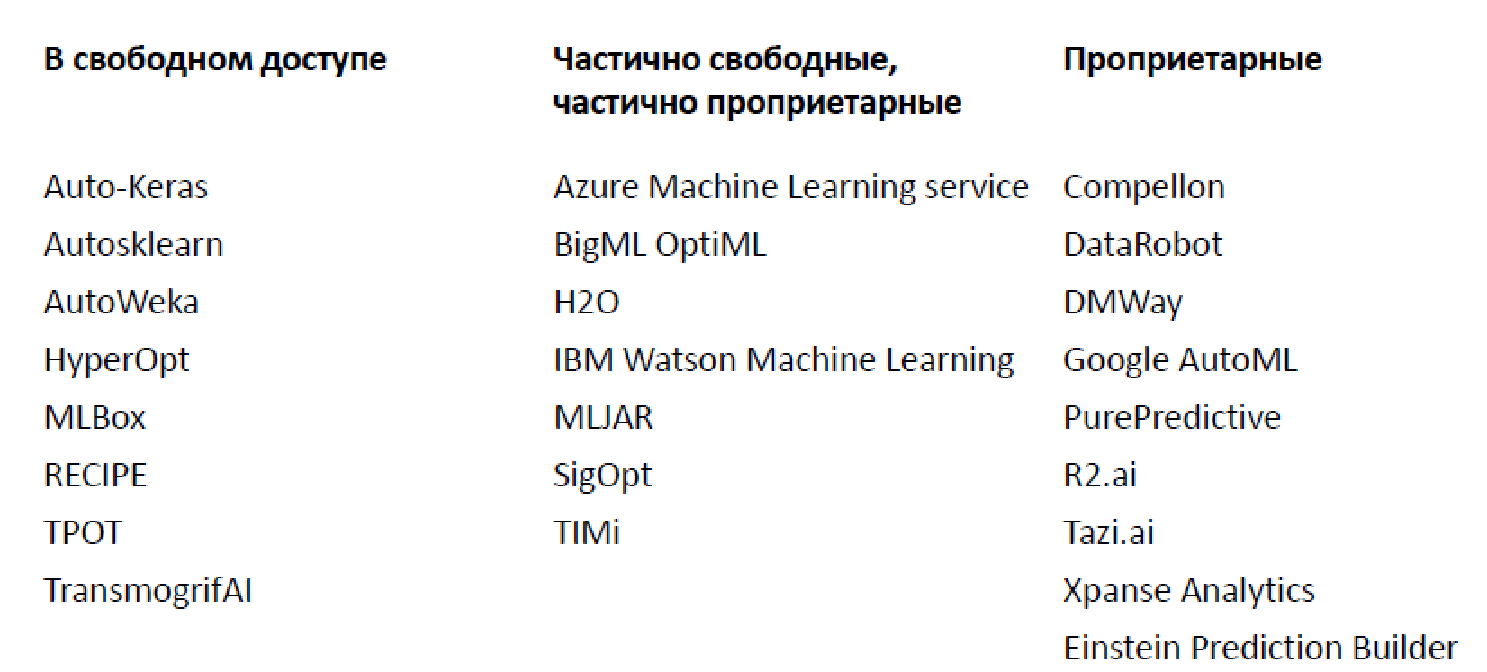
Есть как открытые, которые реализуют ограниченный функционал, так и проприетарные варианты. Наиболее известным, наверное, является Google AutoML, который не дает вам модель, а обучает ее на ваших данных, позволяя пользоваться за 20 долларов в час. Плюс есть большое количество приличных сценариев, когда базовый функционал дается бесплатно, а вот за более продвинутые компоненты приходится платить.
Светлые прогнозы
Само сообщество крайне высоко оценивает перспективы AutoML. Например, Джефф Дин (Jeff Dean) – ученый в области искусственного интеллекта и старший научный сотрудник Google – еще в марте 2018 года заявил, что существующую экспертизу в машинном обучении можно заменить, увеличив в сто раз вычислительные мощности (практически все, что делают data scientist-ы, можно будет автоматизировать). Чуть более сдержанный, но все еще пугающий прогноз от Gartner гласит, что к 2020 году 40% data scientist-ов можно будет заменить AutoML.
Немножко дегтя
Так выглядит стандартная методология CRISP DM:
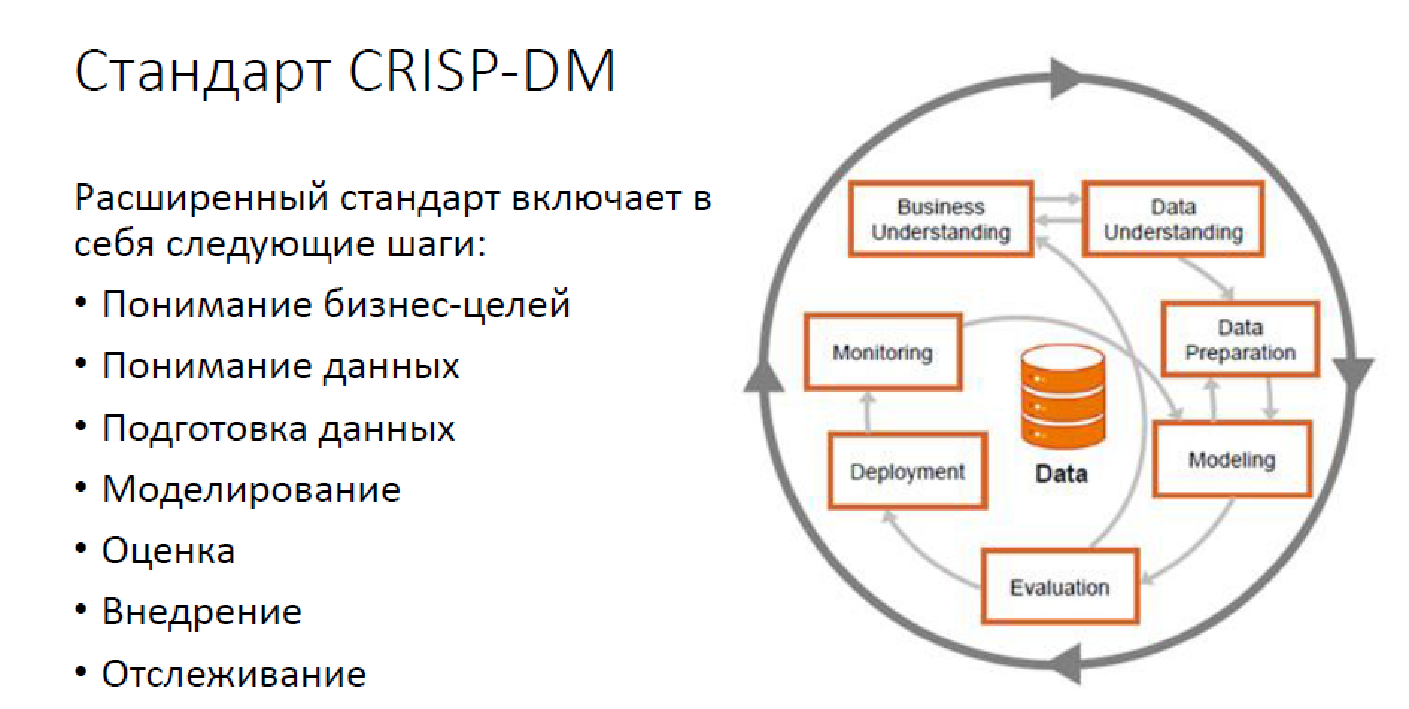
Это расширенный вариант, с мониторингом, но тем не менее. Сегодня решение задач по анализу данных не сводится только к построению моделей. У нас есть большое число задач, которые нужно решать, и нужно решать именно людьми.
На текущий момент в большинстве случаев AutoML стоит лишь на 2,5 столпах: выбор модели, ее настройка и иногда, когда получается, выбор синтез-признаков и просто данных.
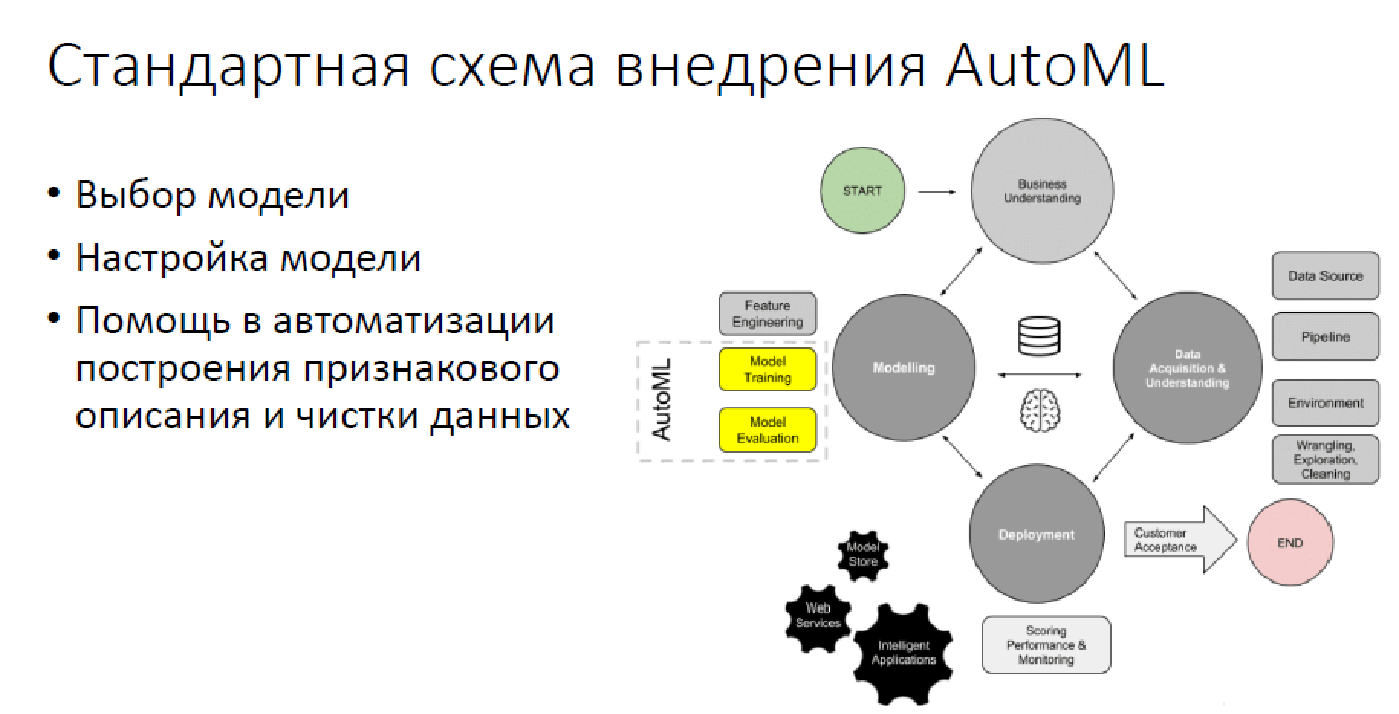
Вне возможностей AutoML
К сожалению, за бортом остается довольно большое число операций, которые AutoML не делает и в разумной перспективе делать не сможет. Естественно, это подразумевает преобразование задач из реального мира в мир анализа данных: «Как спроецировать вашу проблему, чтобы ее можно было решать средствами анализа данных?». Это всевозможные отслеживания модели, оценка качества, поиск разных неприятных моментов – все для того, чтобы решение не оказалось, например, слишком нетолерантным к кому-либо, ведь подобное уже бывало. Естественно, никакой AutoML не сможет поддерживать решения и общаться с заказчиками. Плюс об интерпретируемости на текущий момент времени речи не идет.
Таким образом, это очень удобный инструмент, но к сожалению, для нас не решающий далеко не все проблемы.

Чем мы занимаемся?
Вот как выглядит идеальная схема (такой, какой она видится мне):
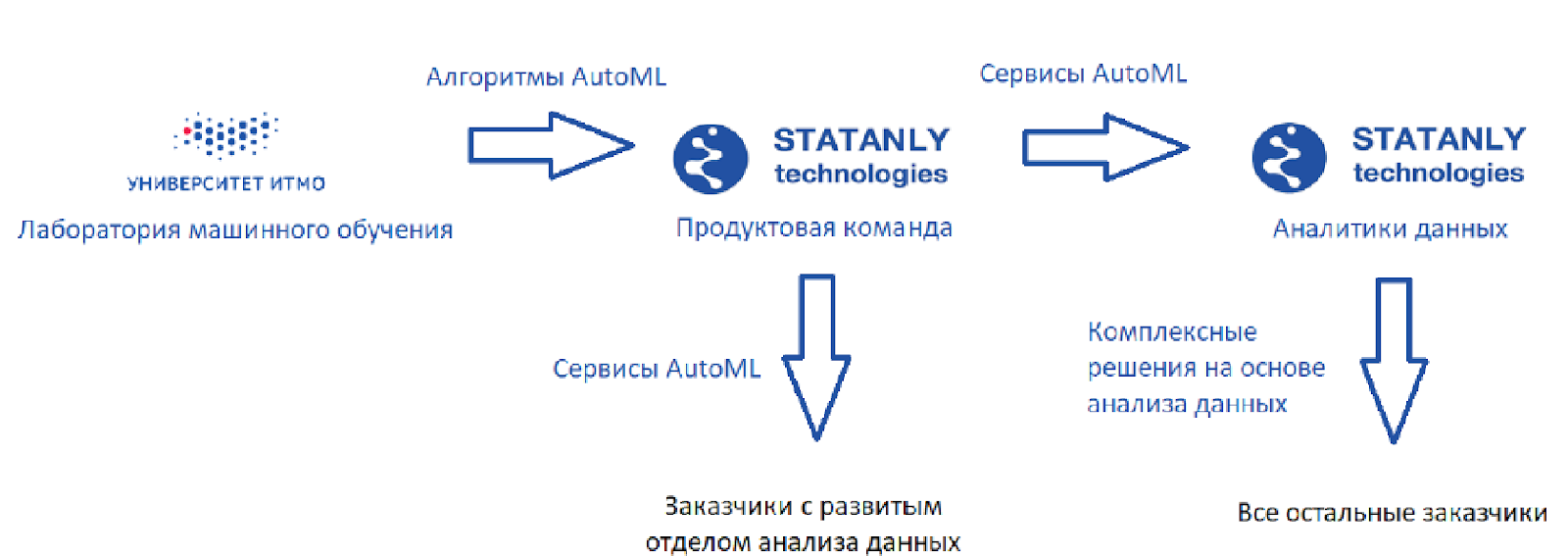
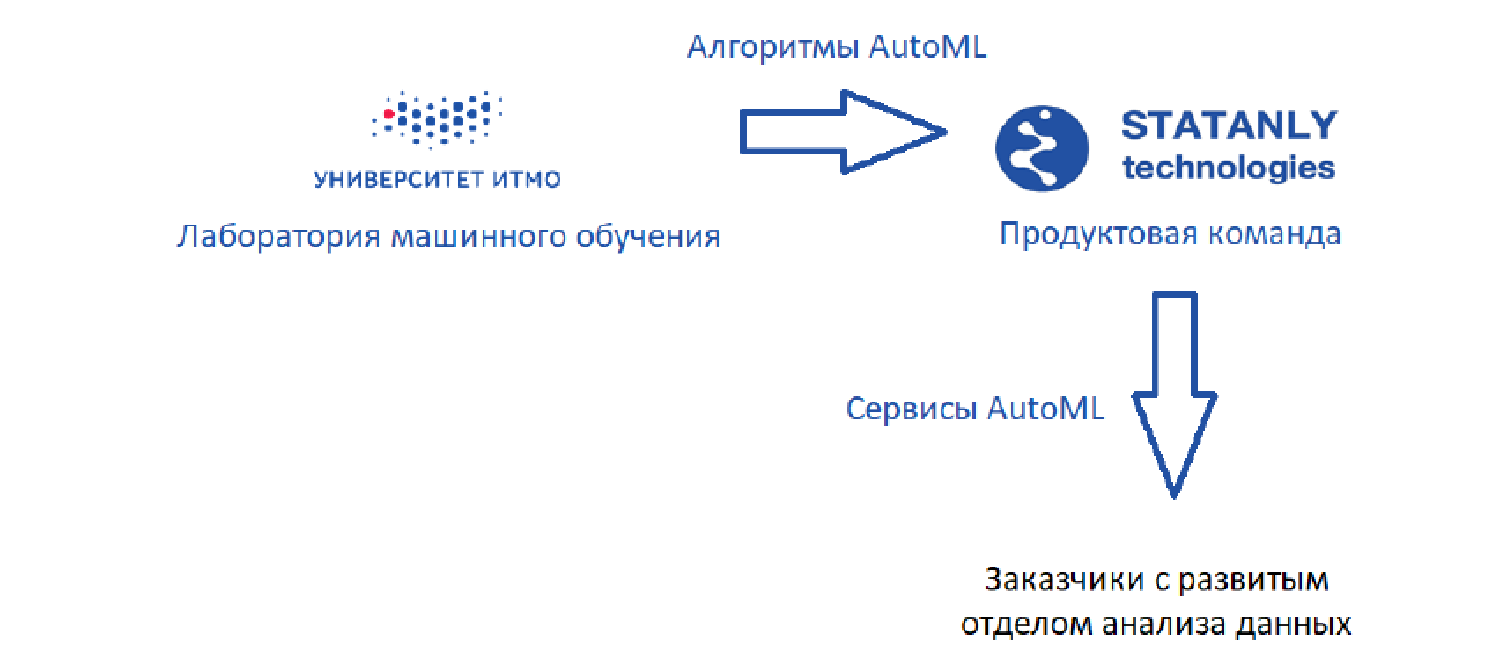
Есть лаборатория машинного обучения, которая разрабатывает алгоритмы, плюс есть Statanly Technologies – продуктовая команда, которая на основе наших алгоритмов реализует сервисы по AutoML. Они работают на компании, у которых есть большой отдел Data Science. Эти же продукты используются командой аналитиков данных в самом Statanly Technologies и решают конкретно задачи компаний, которые пока свой отдел анализа данных не расширили или даже не создали. Выглядит модель здорово, но реальность, конечно, чуть прозаичнее.
Начинали мы в 2017 году примерно с того, что никакого анализа данных здесь не было:
Мы хотели выпускать продукт, которым бы пользовались аналитики данных, но в 2017 году, к сожалению, не смогли найти контакта с инвесторами – они не понимали, что такое AutoML, зачем он нужен и кто им будет пользоваться.
На текущий момент мы ничего не продаем, как компания, которая разрабатывает AutoML-решения, мы лишь облегчаем себе жизнь, как команда, которая занимается анализом данных:

Немного о том, как мы это делаем. Естественно, мы настраиваем гипер-параметры (никакого grid-search), но кроме их настройки мы практически всегда пытаемся построить какие-то базовые решения на основе AutoML, и иногда помогаем себе в шагах по предобработке данных.
У меня есть несколько вдохновляющих и разнообразных примеров – фактически все, что мы с AutoML делали, от простого к сложному.
Простой пример – это задача в «Газпромнефти»: есть скважина, нужно предсказать потенциальное время отказа. В нашем распоряжении классические табличные данные и признаки. В итоге мы построили прогнозную модель при помощи AutoML, при этом ни один аналитик не то, что не пострадал, но даже и не участвовал в процессе. Фактически это оказалось лучшим решением:

Вторая история: Sinara Technologies. Здесь задача была чуть сложнее, потому что фактически там было ровно две колонки: время/параметр + как он изменялся. Нужно было предсказать отказ двигателя. Здесь мы использовали AutoML, чтобы немножко помочь себе с обработкой данных – построили baseline, который потом сами же и превзошли:

Третий пример: задача, которая к AutoML на первый взгляд не имеет отношения. Есть сайт телеканала ТВЦ – база статей, в которых нужно осуществлять поиск, причем поиск семантически богатый. Мы бы хотели находить не только точные выражения слов, но и подходящие по смыслу. Плюс большой перечень разных требований, которые тоже нужно учесть.
Как мы подошли к решению этого вопроса?
Решили проиндексировать все документы на основе гибких кластеров похожих слов, потому что так индексация удобнее. Более того, в базе более 100 тысяч документов, и если этого не сделать, то поиск будет бесконечно долгим. Далее мы построили векторное представление (надеюсь, все про него слышали) и кластеризацию над векторными представлениями, чтобы позволить себе индексировать.
Вторая проблема: как нам кластеризовать данные? Мы применили AutoML, чтобы выбрать меры оценки качества кластеризации, а также подобрать алгоритмы и гипер-параметры для кластеризации:

При этом чаще всего мы AutoML не применяем. Вот два очень показательных примера.
Во втором нашем стартапе «Cпецвидеоаналитика» продукт – это система распознавания признаков автомобилей для обеспечения их централизованного доступа на закрытую территорию. Здесь основная проблема – в малом числе данных. В этом случае довольно сложно настраивать параметры моделей. А еще мы сильно ограничены, потому что часто AutoML применяют бездумно и пытаются настраивать модели на тех же данных, на которых тестируют. Так делать нельзя: по классике машинного обучения нужно выделять валидационное множество: чем больше поиск, тем больше машин должно быть. Так вот, когда у нас мало данных, мы больше переживаем, чтобы эти данные найти и разметить, чем по поводу того, чтобы строить более сложную модель.
Еще один пример – наша совместная разработка с Huawei. Мы делали для них проект по распознаванию текста на изображениях. Здесь вроде бы можно применять AutoML, поскольку в наличии аж три метрики, которые можно оптимизировать: качество распознавания, время распознавания и параметр модели (поскольку все это предполагалось к внедрению в мобильные устройства). Но сейчас ни у кого нет достаточной экспертизы, чтобы оптимально реализовать все три аспекта.
В итоге не хватило вычислительных мощностей: мы были ограничены по времени и не располагали достаточным количеством серверов. Если бы мы запустили это у себя (а должны были в ВШИ), мы бы просто ничего не успели. Поскольку для обработки необходимо пять часов, здесь обошлось лишь нашими компетенциями.
Заключение
В целом, AutoML – это очень полезная вещь, но довольно узкая в применении. Естественно, он не сможет вам придумывать решения по ТЗ. На текущий момент AutoML полезен исключительно аналитикам данных. Может быть, когда-нибудь он их и заменит, но совершенно явно не в ближайшие пять лет.
Автор: Андрей Фильченков, руководитель лаборатории машинного обучения ИТМО




