
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Всем привет, меня зовут Артем Жаринов, я специалист по анализу данных и машинному обучению команды RnD в Lamoda.
Блуждая по нашему сайту вы, возможно, заметили такие полки рекомендаций «С этим товаром покупают» или «Популярные товары». Для персонализированного ранжирования товаров в этих полках мы используем модель из фреймворка Vowpal Wabbit, написанного на языке C. Другой алгоритм отбирает определенный набор товаров, который может показываться на этой полке, а задача Vowpal Wabbit – предсказать вероятность того, что пользователь кликнет на какой-либо товар.
В этой статье расскажу, как мы:

Vowpal Wabbit – это целый фреймворк разнообразных моделей с различными режимами работы. Для нашей задачи мы используем самый простой линейный алгоритм логистической регрессии. Модель делает предсказание вероятности принадлежности к какому-либо классу (в нашем случае – вероятность клика). У неё есть несколько особенностей работы:
Собственно, возникает вопрос: если кролик такой хитрый и сложный, почему мы взяли именно его, а не использовали какие-нибудь стандартные ML-библиотеки в Python, которые хорошо и удобно переносятся в продакшн. На это есть три причины:
Я упомянул лишь критичные и наиболее специфичные свойства vowpal-wabbit для наших задач. Про другие преимущества и функционал можно прочесть на официальном вики проекта.
Выше я описал сложности и особенности работы с Vowpal Wabbit, чтобы показать, как непросто автоматизировать этот процесс. В какой-то момент мы решили формализовать весь пайплайн. Нас не устраивало следующее:
Репозитории и процессы
Весь пайплайн обучения модели существовал лишь в личных папках, в черновиках в Jupyter-ноутбуках.
Документация
Вся передача знаний о фреймворке и данных происходила лично из рук в руки, от сотрудника к сотруднику, bus factor был близок к единице.
Постоянный контроль качества
Метрика качества модели, конечно же, рассчитывалась, но разные версии моделей не сравнивались между собой, что не позволяло наглядно видеть эволюцию модели.
Сначала мы хотели автоматизировать только сбор данных для обучения моделей, но потом пошли дальше и задумались, как автоматизировать все до конца.
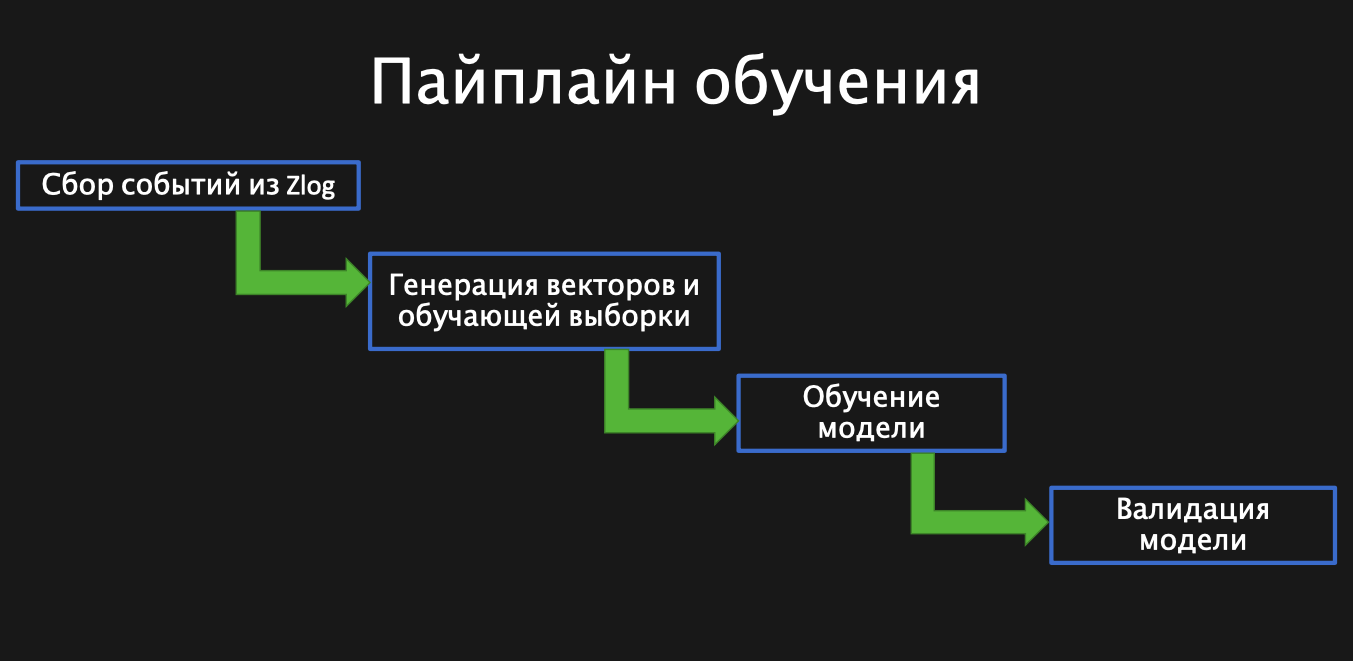
Так схематично выглядит пайплайн обучения модели. Сначала мы собираем необходимые нам события из Zlog – таблицы со всеми логами Lamoda. Это самый простой шаг автоматизации. Далее нам нужно сгенерировать векторы и выборку для обучения, затем обучить модельку, и реализовать валидацию, то есть посмотреть, как в итоге отработала автоматическая модель.
Какие данные нам нужны
Направить модель на повышение конкретной метрики, связанной с прибыльностью и полезной для компании – задача, которую сложно формулировать и поставить перед моделью. Поэтому целью vowpal-wabbit было повысить только параметр CTR (click-through-rate). Эта метрика считается как доля случаев, когда пользователь кликнул на полку товаров, из всех случаев, когда он эту полку увидел. Получается, нам бы хотелось знать, какие товары пользователь видел – такие события мы называем показы (или импрешны), а также на какие товары он кликнул (клики).
Мало просто собрать в кучу эти события. Нам важно знать, какой клик был совершен для какого показа, иными словами – сгруппировать эти события в небольшие цепочки. Для этого используем атрибуцию – это многофункциональный инструмент нашей собственной разработки, основанный на Zlog.
Атрибуцированные данные – это события, собранные из логов в цепочки. С помощью атрибуции мы можем отследить путь пользователя на сайте – что он увидел на баннере, куда кликнул, какие товары добавил в корзину или “Избранное”, как сделал заказ и так далее. Этот инструмент также хорошо обрабатывает сложные сценарии: пользователь кликнул на полку, ушел, вернулся и кликнул на другой товар, потом вернулся обратно на поисковую выдачу и пошел искать что-то другое, потом резко ушел в “Корзину”. Разумеется, определенная часть событий все равно теряется, но это погрешность, с которой мы готовы смириться.
Итак, нас интересовали два события: клики и связанные с ними показы. Получается, что клик по товару мы считаем хорошим примером (объектом класса 1), когда пользователь дал положительный фидбек, а проигнорированные товары – это отрицательные примеры (объекты класса -1).
Собираем вектор
У нас есть события и клики пользователя, из которых будем собирать вектор для обучения. На вход в Vowpal Wabbit подается уникальный формат – это разреженная вертикальными черточками строка, может быть json:

В начале указывается Label – это класс, к которому принадлежит вектор. В данном случае у нас задача бинарной классификации, то есть модель должна определить, будет ли клик или нет. Значит, есть два класса – один и минус один.
И дальше через вертикальные черточки мы указываем сами признаки для модели. Название признака в векторе состоит из названия нэймспейса (пространство, в котором находится признак), а затем в той же строке название признака (например, brand, color), далее через пробел — значение этого признака.

Это пример вектора, который подается на вход. В нём очень много строк и букв, но его структуру достаточно легко прояснить. Вектор полностью описывает ситуацию, когда пользователь видит товар из полки рекомендаций, и состоит из 4 основных частей:
Здесь я выделил пространство G наших признаков – это “прошлое”. В этих нескольких строчках — весь портрет пользователя, то есть все его предыдущие сессии. Здесь можно увидеть несколько интерпретируемых признаков типа бренда, гендера, цвета. Например, на этом векторе в 20% случаев этот человек кликал на Adidas, в 40% случаев на Puma, в 65% случаев его интересовал мужской пол, а в 25% случаев он искал серый цвет.

Дальше мы смотрим на U-часть вектора, которая отвечает за “настоящее”, за текущую сессию пользователя. Она также имеет большое значение для нас. Если пользователь большую часть времени искал спорттовары для жены, а теперь захотел прикупить себе носочки, было бы большой ошибкой показать ему белые платья! Благодаря этому namespace мы можем синхронизировать текущую цель пользователя с его предыдущим поведением на сайте.

И дальше “будущее” для пользователя – S&P часть. P-часть – это якорный товар, то есть тот, с которого пользователь перешел на рекомендацию. Например, сперва он открыл страницу определенных кроссовок, а под ними была полка с рекомендациями. Кроссовки в данном случае – якорный товар, а S-часть – это конкретный товар на полке рекомендаций.
S&P-часть я вульгарно назвал “будущим”, потому что по сути пользователь еще не видел этого товара и не провзаимодействовал с ним. P-часть – это предметы, которые пользователь только что увидел. Но если в этой части вектора нет значений, это не подразумевает, что товар не учитывается. Его характеристики входят в текущую сессию (U-часть). Мы еще раз прописываем P-часть, если хотим показать модели: в S-части нужно видеть характеристики, отличные от P-части (или наоборот, схожие с P-частью).
Поэтому признаки в S-части не имеют значений. По умолчанию, если такое происходит, то vowpal-wabbit выставляет такому признаку значение 1, то есть считает, что пользователь кликнул на него. Получается, что vowpal-wabbit предсказывает “возможность” ситуации, описываемой вектором.
На скрине можно увидеть, что S-часть на самом деле не S, а много пространств А, В, С, D и так далее. Ранее это все было действительно S-частью, но недавно мы раздробили их на отдельные пространства, чтобы при обучении моделей закрывать ей глаза на некоторые характеристики. Например, чтобы она сделала предсказание, зная только бренд показываемого товара или только его категорию.

Дальше мы указываем (L-часть) – это “паспортные данные” пользователя, его платформа и страна (desktop, RU).
Таким образом, мы видим, что вектор полностью описывают ситуацию, в которой может оказаться пользователь.
Сборка векторов была неплохо подготовлена для автоматизации. Для сборки датасета нужно было лишь пощелкать некоторые ячейки с кодом – и выборка готова. Для обучения мы брали период данных за неделю, что давало нам примерно 60 миллионов векторов.
В нашем датасете на 1 клик приходится примерно 10 показов, то есть на 10 негативных примеров приходился 1 позитивный – получался довольно несбалансированный датасет. Для некоторых пользователей нам даже приходилось вручную урезать количество негативных примеров, чтобы их не было слишком много.
Также мы делили выборку по пользователям на обучение и тест, чтобы один и тот же человек не попадал и в обучающую, и в тестовую выборку. Это дает гарантию, что модель не сможет переобучиться на конкретном человеке.
Так мы собирали векторы, затем записывали их все в текстовые файлы построчно и сохраняли локально в хранилище.
Этот этап было легко автоматизировать, а вот дальше начинается веселье – обучение модели. Дело в том, что команда для обучения Vowpal Wabbit пишется через специальную bash-команду. Вот один из подобных скриптов, который мы используем:
Как видно, режим обучения, конфигурация модели и другие особенности задаются через специальные флажки. Самые важные из них:
-d — путь к датасету для обучения,
-f — путь к итоговому файлу модели,
-b — параметр для хэш-функции
Полное описание всех флажков можно почитать вот тут, но в целом они довольно неплохо говорят сами за себя. Например, loss_function задает тип функции потерь, а interactions указывает, каким пространствам признаков нужно взаимодействовать (знак двоеточия в g:u означает “все остальные пространства”). ignore перечисляет пространства, которые модель не будет учитывать в качестве признаков, а l1, l2 – параметры регуляризации, и так далее. Это основные параметры, которые мы используем при обучении Vowpal Wabbit.
Валидация модели
Мы обучили модель на какой-то выборке, и протестировать ее тоже легко на соответствующей выборке.
Здесь флаг -t означает “не обучайся, работай в тестовом режиме”. Модель, путь к которой задается через флажок -i, закрывает глаза на истинные лейблы векторов, находящихся в выборке по адресу -d, и начинает их предсказывать. Все предсказанные вероятности сохраняются в отдельный файлик predictions.txt, путь к которому указан в параметре -p.
Мы получили предсказания и хотим понять, насколько они хороши. Для этого решили использовать метрику AUC ROC, поскольку она хорошо интерпретируется и позволяет адекватно провести валидацию с несбалансированным датасетом. Написали функцию, которая считает эту метрику, рисуем ROC-кривую, перебираем GridSearch разные комбинации параметров модели – типичный дата саенс. Всё это было реализовано в Jupyter-ноутбуке в виде самописных питоновских функций и процессов.

Сборка датасета теперь еженедельно производится в табличку в нашем хранилище данных Hive. Каждому вектору проставляется дата расчета, платформа, страна, тег (это метка “train”/”test” – выборка, к которой относится вектор). В поле params указываются разные другие параметры для вектора. Например, некоторые модельки у нас обучались только по первому клику в сессии, поэтому на скрине можно увидеть параметр first_click: true либо false. С этой частью особых проблем не было.
Автоматизируем обучение модели
Погоняв много комбинаций параметров через GridSearch, мы поняли, что оптимальная конфигурация для каждой модели каждый раз остается практически неизменной. Поэтому мы решили упростить себе жизнь и для начала автоматизировать процесс обучения с фиксированными параметрами.
Стоявшая перед нами проблема заключалась в том, что Vowpal Wabbit не был установлен на кластере, где происходят вычисления и все скрипты запускаются по определенному расписанию. К тому же, нам хотелось запускать обучение этих моделей отдельно от всех остальных регулярных скриптов. Мы опасались, что кролик будет требовать много памяти, которой мы не можем ему выделить на общем кластере, или же, что хуже, он начнет теснить все остальные процессы. Мы рассматривали много самых разных вариантов, но решение было ближе, чем нам казалось.
Тут стоит сказать огромное спасибо нашим девопсам и дата-инженерам. После длительных переговоров и соглашений они предоставили отдельный воркер специально для задач машинного обучения, на котором установлен и настроен Vowpal Wabbit. Там мы можем разгуляться и экспериментировать над нашими модельками вдоль и поперек.
Далее все стало намного понятнее. Мы запускаем баш-команду и обучаем модельку. Приписываем в название дату обучения и кладем её в хранилище Artifactory, откуда позже API будет тянуть последнюю версию модели. Все параметры обучения и конфигурацию модели записываем в виде json-строки в отдельную табличку в PostgreSQL.
Автоматизация валидации
 Дальше пошла самая необычная часть. Основная проблема с валидацией была в том, что все наши скрипты, которые считали метрики и качество модельки, были написаны на Python. Нам бы очень не хотелось переносить питоновское окружение на новый кластер, если есть возможность использовать bash.
Дальше пошла самая необычная часть. Основная проблема с валидацией была в том, что все наши скрипты, которые считали метрики и качество модельки, были написаны на Python. Нам бы очень не хотелось переносить питоновское окружение на новый кластер, если есть возможность использовать bash.
Мы уже хотели написать свою функцию на баше для подсчета ROC-AUC, но неожиданно нашли самописную библиотечку perf – это внешний инструмент для подсчета различных метрик для анализа данных, созданная в 2004 году на KDD Cup. Библиотека написана на С и работает с большим количеством самых разнообразных метрик. Она принимает на вход два файла: один с предсказаниями, другой с истинными лейблами, затем считает метрики, которые указываются флажками в баш-команде. На скрине я указал ее типичный выход.
Когда мы нашли эту библиотеку, автоматизация валидации тоже стала простым процессом. Мы так же, как и при обучении, запускаем баш-команду, тестируем модель и получаем файл с предиктами. Затем собираем истинные лейблы в отдельный файлик и кидаем получившиеся файлы в perf. Он считает метрику, а результат мы аккуратно складываем в json. Итог валидации вместе с датой тоже записывается в таблицу в PostgreSQL.
Вся валидация занимает примерно 1.5 часа, потому что соотношение этих обучений и тестовой выборки у нас приблизительно 4 к 1. Опять же, все происходит на отдельном воркере, и мы совершенно не затрагиваем другие регулярные скрипты.

Контроль качества модели
Итак, мы обучили модельку и получили какое-то качество ее работы. Ручная работа на этом не заканчивается: необходимо сравнить качество текущей модели с предыдущей. Ведь если мы получим снижение качества, и пустим такое в продакшн, всем будет очень плохо.
Нам нужно понять, необходимо ли обновлять модель, которая сейчас работает на сайте. Для этого реализовали контроль качества моделей.
Сейчас мы реализовали контроль качества на двух моделях – сегодняшней и предыдущей (с прошлой недели). Обе тестируются на одной и той же тестовой выборке. Таким образом, для старой модели мы получаем обновленную метрику. Если видим, что новая моделька справилась так себе, а старая не изменилась или даже улучшилась – оставляем ее в проде. Или, например, старая стала лучше, но новая работает даже еще лучше – в таком случае даем дорогу новой модели. Все обновленные метрики складываем в PostgreSQL. Это позволяет API на сайте брать именно ту модель, которая показала самое лучшее качество из последних двух.

Контроль качества прост в реализации и дает целую массу приятных бонусов:
Всё начиналось с простого стремления перестать каждый раз прощелкивать ячейки с кодом в Jupyter-ноутбуках, а переросло в целый мощный пайплайн с большим набором инструментов, ресурсов и возможностей. Конечно, это в том числе и фундамент для многих будущих моделей и проектов, которые можно сделать на этой автоматизации.
Блуждая по нашему сайту вы, возможно, заметили такие полки рекомендаций «С этим товаром покупают» или «Популярные товары». Для персонализированного ранжирования товаров в этих полках мы используем модель из фреймворка Vowpal Wabbit, написанного на языке C. Другой алгоритм отбирает определенный набор товаров, который может показываться на этой полке, а задача Vowpal Wabbit – предсказать вероятность того, что пользователь кликнет на какой-либо товар.
В этой статье расскажу, как мы:
- составляем рекомендации, которые отображаются на сайте;
- обучаем модели, которые эти рекомендации делают;
- и почему мы пришли к тому, что необходимо автоматизировать весь процесс обучения моделей.
Свойства фреймворка Vowpal Wabbit
Vowpal Wabbit – это целый фреймворк разнообразных моделей с различными режимами работы. Для нашей задачи мы используем самый простой линейный алгоритм логистической регрессии. Модель делает предсказание вероятности принадлежности к какому-либо классу (в нашем случае – вероятность клика). У неё есть несколько особенностей работы:
- Это скорее особенность не vowpal-wabbit, а режима работы: он использует значения признаков для предсказания.
weight_1*feature_1 + weight_2*feature_2 + … = predict - Названия признаков хэшируются и хранятся в файле модели в зашифрованном виде. Этот прием называется hashing trick. Он позволяет сопоставить каждому весу зашифрованное название признака, которому он соответствует, а также хранить эту информацию в файле небольшого размера.
- Признаки можно делить на пространства (namespace). Это может быть обусловлено желанием разграничить их логически: например, в одном пространстве находятся признаки, описывающие только товар, в другом – пользователя, в третьем – особенности сессии, сезонности и т.д. Также это позволяет задавать взаимодействия между пространствами.
Собственно, возникает вопрос: если кролик такой хитрый и сложный, почему мы взяли именно его, а не использовали какие-нибудь стандартные ML-библиотеки в Python, которые хорошо и удобно переносятся в продакшн. На это есть три причины:
- Высокая скорость — самое важное для нас качество Vowpal Wabbit. Он быстро обучается, к тому же он позволяет запускать мультипоточное обучение благодаря реализации парсинга входных данных и обновления весов на раздельных потоках. По умолчанию модель оптимизируется при помощи SGD (Stochastic Gradient Descent) — довольно быстрого метода оптимизации весов.
Скорость отдачи предсказаний также невероятно высокая. Например, рекомендации на сайте прогружаются за примерно 10-20 миллисекунд, из них около 100 микросекунд занимает предсказание Vowpal Wabbit (1% от времени прогрузки рекомендаций). Остальная часть времени – прогрузка картинок товаров, подтягивание их из базы. - Масштабируемость: Vowpal Wabbit сразу же выделяет память, которая ему потребуется для обучения и этот объем не меняется в процессе. Модели не важен размер выборки – будь то сто строчек, миллион или сто миллионов. Обучение происходит в режиме онлайн: кролик берет порцию данных, обучается на ней и идет дальше. Таким образом, фреймворк сразу сообщает, какое количество ресурсов потратит, и не обвалится посреди обучения с недостатком памяти.
- Гибкость входных данных – непосредственно перед обучением мы сразу задаем Vowpal Wabbit связи между признаками, которые нам интересны. Например, у нас есть три пространства признаков, которые мы назвали A, B и C. По умолчанию, кролик использует их все по отдельности, но если прописать --interactions AC, то каждый признак из A перемножится с каждым признаком из C и образует новый признак. А в некоторых случаях можем параметром --ignore B сказать модели не использовать никакие признаки из пространства B. Все это настраивается пользователем вручную перед началом обучения и легко воспринимается моделью.
Я упомянул лишь критичные и наиболее специфичные свойства vowpal-wabbit для наших задач. Про другие преимущества и функционал можно прочесть на официальном вики проекта.
Почему же мы решили автоматизировать весь пайплайн?
Выше я описал сложности и особенности работы с Vowpal Wabbit, чтобы показать, как непросто автоматизировать этот процесс. В какой-то момент мы решили формализовать весь пайплайн. Нас не устраивало следующее:
Репозитории и процессы
Весь пайплайн обучения модели существовал лишь в личных папках, в черновиках в Jupyter-ноутбуках.
Документация
Вся передача знаний о фреймворке и данных происходила лично из рук в руки, от сотрудника к сотруднику, bus factor был близок к единице.
Постоянный контроль качества
Метрика качества модели, конечно же, рассчитывалась, но разные версии моделей не сравнивались между собой, что не позволяло наглядно видеть эволюцию модели.
Сначала мы хотели автоматизировать только сбор данных для обучения моделей, но потом пошли дальше и задумались, как автоматизировать все до конца.
Так схематично выглядит пайплайн обучения модели. Сначала мы собираем необходимые нам события из Zlog – таблицы со всеми логами Lamoda. Это самый простой шаг автоматизации. Далее нам нужно сгенерировать векторы и выборку для обучения, затем обучить модельку, и реализовать валидацию, то есть посмотреть, как в итоге отработала автоматическая модель.
Какие данные нам нужны
Направить модель на повышение конкретной метрики, связанной с прибыльностью и полезной для компании – задача, которую сложно формулировать и поставить перед моделью. Поэтому целью vowpal-wabbit было повысить только параметр CTR (click-through-rate). Эта метрика считается как доля случаев, когда пользователь кликнул на полку товаров, из всех случаев, когда он эту полку увидел. Получается, нам бы хотелось знать, какие товары пользователь видел – такие события мы называем показы (или импрешны), а также на какие товары он кликнул (клики).
Мало просто собрать в кучу эти события. Нам важно знать, какой клик был совершен для какого показа, иными словами – сгруппировать эти события в небольшие цепочки. Для этого используем атрибуцию – это многофункциональный инструмент нашей собственной разработки, основанный на Zlog.
Атрибуцированные данные – это события, собранные из логов в цепочки. С помощью атрибуции мы можем отследить путь пользователя на сайте – что он увидел на баннере, куда кликнул, какие товары добавил в корзину или “Избранное”, как сделал заказ и так далее. Этот инструмент также хорошо обрабатывает сложные сценарии: пользователь кликнул на полку, ушел, вернулся и кликнул на другой товар, потом вернулся обратно на поисковую выдачу и пошел искать что-то другое, потом резко ушел в “Корзину”. Разумеется, определенная часть событий все равно теряется, но это погрешность, с которой мы готовы смириться.
Итак, нас интересовали два события: клики и связанные с ними показы. Получается, что клик по товару мы считаем хорошим примером (объектом класса 1), когда пользователь дал положительный фидбек, а проигнорированные товары – это отрицательные примеры (объекты класса -1).
Собираем вектор
У нас есть события и клики пользователя, из которых будем собирать вектор для обучения. На вход в Vowpal Wabbit подается уникальный формат – это разреженная вертикальными черточками строка, может быть json:
В начале указывается Label – это класс, к которому принадлежит вектор. В данном случае у нас задача бинарной классификации, то есть модель должна определить, будет ли клик или нет. Значит, есть два класса – один и минус один.
И дальше через вертикальные черточки мы указываем сами признаки для модели. Название признака в векторе состоит из названия нэймспейса (пространство, в котором находится признак), а затем в той же строке название признака (например, brand, color), далее через пробел — значение этого признака.
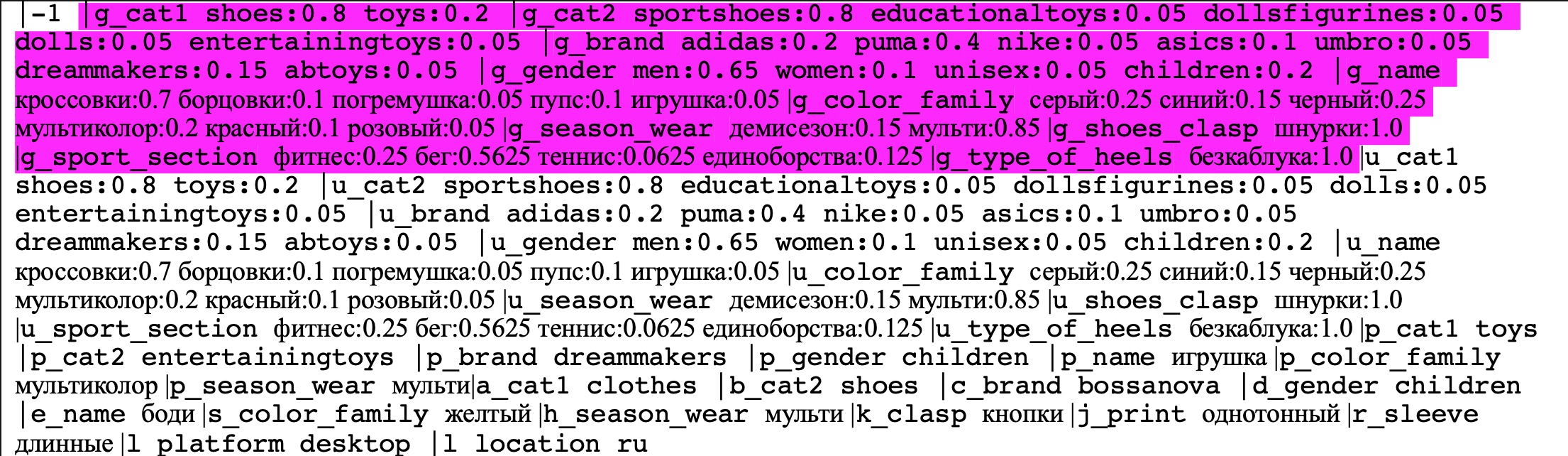
Это пример вектора, который подается на вход. В нём очень много строк и букв, но его структуру достаточно легко прояснить. Вектор полностью описывает ситуацию, когда пользователь видит товар из полки рекомендаций, и состоит из 4 основных частей:
Здесь я выделил пространство G наших признаков – это “прошлое”. В этих нескольких строчках — весь портрет пользователя, то есть все его предыдущие сессии. Здесь можно увидеть несколько интерпретируемых признаков типа бренда, гендера, цвета. Например, на этом векторе в 20% случаев этот человек кликал на Adidas, в 40% случаев на Puma, в 65% случаев его интересовал мужской пол, а в 25% случаев он искал серый цвет.
Дальше мы смотрим на U-часть вектора, которая отвечает за “настоящее”, за текущую сессию пользователя. Она также имеет большое значение для нас. Если пользователь большую часть времени искал спорттовары для жены, а теперь захотел прикупить себе носочки, было бы большой ошибкой показать ему белые платья! Благодаря этому namespace мы можем синхронизировать текущую цель пользователя с его предыдущим поведением на сайте.
И дальше “будущее” для пользователя – S&P часть. P-часть – это якорный товар, то есть тот, с которого пользователь перешел на рекомендацию. Например, сперва он открыл страницу определенных кроссовок, а под ними была полка с рекомендациями. Кроссовки в данном случае – якорный товар, а S-часть – это конкретный товар на полке рекомендаций.
S&P-часть я вульгарно назвал “будущим”, потому что по сути пользователь еще не видел этого товара и не провзаимодействовал с ним. P-часть – это предметы, которые пользователь только что увидел. Но если в этой части вектора нет значений, это не подразумевает, что товар не учитывается. Его характеристики входят в текущую сессию (U-часть). Мы еще раз прописываем P-часть, если хотим показать модели: в S-части нужно видеть характеристики, отличные от P-части (или наоборот, схожие с P-частью).
Поэтому признаки в S-части не имеют значений. По умолчанию, если такое происходит, то vowpal-wabbit выставляет такому признаку значение 1, то есть считает, что пользователь кликнул на него. Получается, что vowpal-wabbit предсказывает “возможность” ситуации, описываемой вектором.
На скрине можно увидеть, что S-часть на самом деле не S, а много пространств А, В, С, D и так далее. Ранее это все было действительно S-частью, но недавно мы раздробили их на отдельные пространства, чтобы при обучении моделей закрывать ей глаза на некоторые характеристики. Например, чтобы она сделала предсказание, зная только бренд показываемого товара или только его категорию.
Дальше мы указываем (L-часть) – это “паспортные данные” пользователя, его платформа и страна (desktop, RU).
Таким образом, мы видим, что вектор полностью описывают ситуацию, в которой может оказаться пользователь.
Реализация год назад
Сборка векторов была неплохо подготовлена для автоматизации. Для сборки датасета нужно было лишь пощелкать некоторые ячейки с кодом – и выборка готова. Для обучения мы брали период данных за неделю, что давало нам примерно 60 миллионов векторов.
В нашем датасете на 1 клик приходится примерно 10 показов, то есть на 10 негативных примеров приходился 1 позитивный – получался довольно несбалансированный датасет. Для некоторых пользователей нам даже приходилось вручную урезать количество негативных примеров, чтобы их не было слишком много.
Также мы делили выборку по пользователям на обучение и тест, чтобы один и тот же человек не попадал и в обучающую, и в тестовую выборку. Это дает гарантию, что модель не сможет переобучиться на конкретном человеке.
Так мы собирали векторы, затем записывали их все в текстовые файлы построчно и сохраняли локально в хранилище.
Этот этап было легко автоматизировать, а вот дальше начинается веселье – обучение модели. Дело в том, что команда для обучения Vowpal Wabbit пишется через специальную bash-команду. Вот один из подобных скриптов, который мы используем:
vw
-d “train_dataset.txt”
--loss_function "logistic"
--link "logistic"
-b "28"
--interactions "g:l u:l"
--ignore p
--holdout_off
--l1 "1e-08"
--l2 "1e-10"
--initial_t "0.01"
-f “model.vw"
Как видно, режим обучения, конфигурация модели и другие особенности задаются через специальные флажки. Самые важные из них:
-d — путь к датасету для обучения,
-f — путь к итоговому файлу модели,
-b — параметр для хэш-функции
Полное описание всех флажков можно почитать вот тут, но в целом они довольно неплохо говорят сами за себя. Например, loss_function задает тип функции потерь, а interactions указывает, каким пространствам признаков нужно взаимодействовать (знак двоеточия в g:u означает “все остальные пространства”). ignore перечисляет пространства, которые модель не будет учитывать в качестве признаков, а l1, l2 – параметры регуляризации, и так далее. Это основные параметры, которые мы используем при обучении Vowpal Wabbit.
Валидация модели
Мы обучили модель на какой-то выборке, и протестировать ее тоже легко на соответствующей выборке.
vw
-d “test_dataset.txt”
-t
-i “model.vw”
-p “predictions.txt"
Здесь флаг -t означает “не обучайся, работай в тестовом режиме”. Модель, путь к которой задается через флажок -i, закрывает глаза на истинные лейблы векторов, находящихся в выборке по адресу -d, и начинает их предсказывать. Все предсказанные вероятности сохраняются в отдельный файлик predictions.txt, путь к которому указан в параметре -p.
Мы получили предсказания и хотим понять, насколько они хороши. Для этого решили использовать метрику AUC ROC, поскольку она хорошо интерпретируется и позволяет адекватно провести валидацию с несбалансированным датасетом. Написали функцию, которая считает эту метрику, рисуем ROC-кривую, перебираем GridSearch разные комбинации параметров модели – типичный дата саенс. Всё это было реализовано в Jupyter-ноутбуке в виде самописных питоновских функций и процессов.
Год спустя: как всё работает сейчас
Сборка датасета теперь еженедельно производится в табличку в нашем хранилище данных Hive. Каждому вектору проставляется дата расчета, платформа, страна, тег (это метка “train”/”test” – выборка, к которой относится вектор). В поле params указываются разные другие параметры для вектора. Например, некоторые модельки у нас обучались только по первому клику в сессии, поэтому на скрине можно увидеть параметр first_click: true либо false. С этой частью особых проблем не было.
Автоматизируем обучение модели
Погоняв много комбинаций параметров через GridSearch, мы поняли, что оптимальная конфигурация для каждой модели каждый раз остается практически неизменной. Поэтому мы решили упростить себе жизнь и для начала автоматизировать процесс обучения с фиксированными параметрами.
Стоявшая перед нами проблема заключалась в том, что Vowpal Wabbit не был установлен на кластере, где происходят вычисления и все скрипты запускаются по определенному расписанию. К тому же, нам хотелось запускать обучение этих моделей отдельно от всех остальных регулярных скриптов. Мы опасались, что кролик будет требовать много памяти, которой мы не можем ему выделить на общем кластере, или же, что хуже, он начнет теснить все остальные процессы. Мы рассматривали много самых разных вариантов, но решение было ближе, чем нам казалось.
Тут стоит сказать огромное спасибо нашим девопсам и дата-инженерам. После длительных переговоров и соглашений они предоставили отдельный воркер специально для задач машинного обучения, на котором установлен и настроен Vowpal Wabbit. Там мы можем разгуляться и экспериментировать над нашими модельками вдоль и поперек.
Далее все стало намного понятнее. Мы запускаем баш-команду и обучаем модельку. Приписываем в название дату обучения и кладем её в хранилище Artifactory, откуда позже API будет тянуть последнюю версию модели. Все параметры обучения и конфигурацию модели записываем в виде json-строки в отдельную табличку в PostgreSQL.
Раньше мы обучали все модели лишь на недельных данных, а теперь решили разгуляться, раз у нас есть целый воркер. Для обучения теперь берем данные за 2-3 последних месяца. Размер выборки исчисляется сотнями миллионов векторов. Обучение модели занимает примерно 5-6 часов и проводится раз в неделю. Все метрики, связанные с обучающей выборкой и нагруженностью кластера, выводятся на дашборды в grafana. Так что все отслеживается, и если что-то упадет, мы это сразу увидим.
Автоматизация валидации
Дальше пошла самая необычная часть. Основная проблема с валидацией была в том, что все наши скрипты, которые считали метрики и качество модельки, были написаны на Python. Нам бы очень не хотелось переносить питоновское окружение на новый кластер, если есть возможность использовать bash.Мы уже хотели написать свою функцию на баше для подсчета ROC-AUC, но неожиданно нашли самописную библиотечку perf – это внешний инструмент для подсчета различных метрик для анализа данных, созданная в 2004 году на KDD Cup. Библиотека написана на С и работает с большим количеством самых разнообразных метрик. Она принимает на вход два файла: один с предсказаниями, другой с истинными лейблами, затем считает метрики, которые указываются флажками в баш-команде. На скрине я указал ее типичный выход.
Когда мы нашли эту библиотеку, автоматизация валидации тоже стала простым процессом. Мы так же, как и при обучении, запускаем баш-команду, тестируем модель и получаем файл с предиктами. Затем собираем истинные лейблы в отдельный файлик и кидаем получившиеся файлы в perf. Он считает метрику, а результат мы аккуратно складываем в json. Итог валидации вместе с датой тоже записывается в таблицу в PostgreSQL.
Вся валидация занимает примерно 1.5 часа, потому что соотношение этих обучений и тестовой выборки у нас приблизительно 4 к 1. Опять же, все происходит на отдельном воркере, и мы совершенно не затрагиваем другие регулярные скрипты.
Контроль качества модели
Итак, мы обучили модельку и получили какое-то качество ее работы. Ручная работа на этом не заканчивается: необходимо сравнить качество текущей модели с предыдущей. Ведь если мы получим снижение качества, и пустим такое в продакшн, всем будет очень плохо.
Нам нужно понять, необходимо ли обновлять модель, которая сейчас работает на сайте. Для этого реализовали контроль качества моделей.
Сейчас мы реализовали контроль качества на двух моделях – сегодняшней и предыдущей (с прошлой недели). Обе тестируются на одной и той же тестовой выборке. Таким образом, для старой модели мы получаем обновленную метрику. Если видим, что новая моделька справилась так себе, а старая не изменилась или даже улучшилась – оставляем ее в проде. Или, например, старая стала лучше, но новая работает даже еще лучше – в таком случае даем дорогу новой модели. Все обновленные метрики складываем в PostgreSQL. Это позволяет API на сайте брать именно ту модель, которая показала самое лучшее качество из последних двух.
Контроль качества прост в реализации и дает целую массу приятных бонусов:
- Контроль аномалий данных – если вдруг что-то случилось с данными, и метрика внезапно упала или обнулилась, мы это увидим и начнем разбираться.
- Контроль ошибок при обучении – если ухудшилось качество, тоже обязательно вылезет флажок, и мы это проверим.
- И самое главное – это позволяет модели в продакшене постоянно развиваться или, по крайней мере, не деградировать.
К чему мы пришли в итоге
- Удобный собранный пайплайн, где все задокументировано и подробно расписано: где в какой табличке что лежит, в каком репозитории хранится код.
- Обучение, валидация и сбор датасета происходит каждую неделю, все полностью автоматизировано.
- Есть контроль качества. Мы не пускаем плохие модельки в продакшн.
Всё начиналось с простого стремления перестать каждый раз прощелкивать ячейки с кодом в Jupyter-ноутбуках, а переросло в целый мощный пайплайн с большим набором инструментов, ресурсов и возможностей. Конечно, это в том числе и фундамент для многих будущих моделей и проектов, которые можно сделать на этой автоматизации.
Планы на будущее и мечты
- Vowpal Wabbit – это многофункциональный фреймворк, который может работать не только в линейном режиме, но и во многих других: факторизация матриц, LDA, мультиклассовая классификация one-against-all и даже режим однослойной нейронной сети. Любые из этих функционалов можно также легко подключить к работе на новом кластере на проложенных рельсах.
- Можно подключить vowpal-wabbit для ранжирования рекомендаций в других полках Lamoda, например, сделать полку похожих товаров.
- Также можно добавлять в пайплайн другие фреймворки помимо Vowpal Wabbit: различные XGBoost, RandomForest, нейронные сети.


