Привет, я работаю продуктовым аналитиком и мои задачи, в большей степени, связаны с анализом пользовательского поведения в продукте.
Пожалуй, чаще всего, мне приходится работать с разного рода исследованиями. В отдельную категорию можно выделить исследования интерфейсных решений, отдельных фичей или механик продукта. Это могут быть как новые релизы, так и старые фичи, до которых у команды раньше не дотягивались руки. Основной вопрос в таких задачах звучит примерно так: "Нравится ли юзерам вот эта штука, которую мы добавили, приносит ли она нам деньги?"
Чем больше подобных задач я переделывал, тем яснее вырисовывались общие паттерны такого анализа. В итоге у меня сформировался небольшой “фреймворк”, который помогает наметить план детального исследования и не сложно адаптируется под разные продукты с разной спецификой.
Тут я расскажу о нём в общих чертах.
А зачем вообще разбирать прилку на фичи, не проще рассматривать её целиком? Продукт (в частности сайт или приложение) по сути — это совокупность механик и отдельных фичей, а управление макро-показателями всего продукта можно осуществлять через управление микро-показателями отдельных его составляющих. Улучшение каждой отдельной части плавно улучшает всю систему.
Суть этого подхода в поиске универсальной для продукта системы метрик, которые мы используем для поверхностной оценки элемента — от заметности в интерфейсе, до экономического импакта. Каждая метрика должна описывать какой-то результат взаимодействия юзера с фичей, а при соотношении наших ожиданий на релизе и результатов расчётов, мы получаем сигналы к тому или иному дальнейшему действию.
Базовые метрики
Постепенно я пришёл к использованию 5 таких метрик (лёгкий кастом на основе общепринятых), которые дают верхнеуровневое понимание эффективности фичи или механики:
Adoption Rate (или Visible Rate) — метрика, которая отвечает за “заметность” фичи в интерфейсе. Её можно рассчитать как отношение количества юзеров, хоть как-то взаимодействующих с исследуемым объектом за день к общему количеству активных юзеров:

Значение метрики ниже заложенного ожидания, может указывать на 2 потенциальные проблемы:
Точка касания с фичей слишком спрятана от пользователя. Возможно, кнопка запуска сценария фичи не заметна или находится глубоко в иерархии приложения. А может она встроена в баннер, который гасится “баннерной слепотой”;
Точка касания заметна, но у неё плохой CTA. Юзеры могут видеть кнопку, но она не вызывает достаточного интереса чтобы на неё нажать.
Engagement Rate — эта метрика отвечает за выполнения ключевой задачи фичи или механики. У каждой фичи есть своя микро-цель, достигая которой, юзер приближается к решению своей основной задачи. Например цель поисковой строки — выдать результат по запросу, а в идеале результат, устраивающий пользователя. В контексте поиска, оценкой успешности может быть переход по какому-то объекту из поисковой выдачи, а критерием неуспешности — повторный поиск.
Посчитать её можно как отношение количества юзеров, совершивших целевое действие фичи за день к количеству юзеров, воспользовавшихся фичей за день:

Для каких-то фичей, ER может показывать понимание пользователем A-ha момента фичи, т.е. смысл метрики может меняться, в зависимости от дизайна фичи.
Низкий ER может сигнализировать:
О сложности фичи, не понятно что тут делать и зачем это нужно;
О несоответствии ожиданиям пользователя — название кнопки, по которой он перешёл, он трактовал для себя как что-то другое и ожидал увидеть иной сценарий фичи;
Stickiness (Feature retention) — метрика, показывающая “залипательность” фичи в повседневном юзер-флоу. Отлично подходит, например, для описания параллельных механик продукта, на сколько они нравятся пользователям.
По смыслу это похоже на классический Retention, но считать лучше по сессионным дням. Т.е. если у юзера за месяц было 10 дней активности, из которых в 7 днях он возвращался к фиче, то показатель будет равен 70%:

Низкий Stickiness обычно говорит о том, что фича юзеру не зашла, если, конечно, её дизайн не подразумевает низкой оценки. Например, когда это какое-то разовое событие.
Conversion Rate — оценка доли cконвертировавшихся юзеров фичи в общем объёме юзеров фичи. Прямой логикой конверсия не ложится на большинство фичей, оценить влияние, например, новой системы промокодов, можно, а вот использование тёмной темы уже вряд ли. Поэтому здесь стоит быть аккуратными и при трактовании значений всегда держите в голове смысл фичи.
Рассчитывать метрику можно как отношение количества сконвертировавшихся юзеров, которые пользовались фичей за день к количеству юзеров фичи в этот день:

Низкое значение этой метрики может говорить о том, что фича находится в далёкой связи с бизнес-целями приложения, а вот плохо это или нормально зависит уже от дизайна фичи.
Monetization Impact — эта метрика оценивает как фича влияет на доходы от приложения, включая прямое влияние (например, покупки внутри приложения, связанные с фичей) и косвенное (например, улучшение удержания, что ведет к увеличению LTV пользователя).
Оценивается через доход, полученный от сессионных дней, в которых была использована фича, в сравнении с общим доходом:

Низкое значение может говорить, например, о слабой популярности фичи среди платящей аудитории.
Что с этим всем теперь делать?
Все эти метрики в совокупности показывают “характер” фичи, т.е. условно про что она в большей степени — про деньги, даёт буст возвращаемости или мотивирует к конверсии и т.д.
Удобнее всего работать с этим через график Spider/Radar. Помещаем на оси наши метрики, и запускаем в паутину какой-то набор фичей. Получаем что-то типа такого:
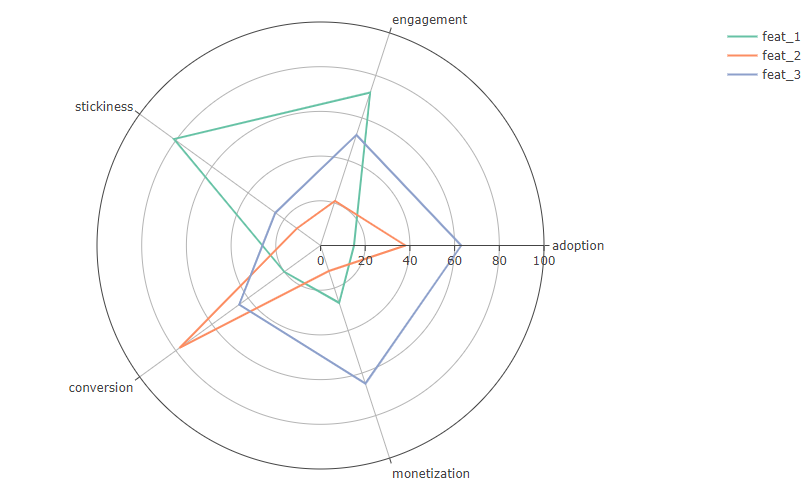
Если засунуть на график все основные механики, можно увидеть сильные и слабые стороны продукта, в такой сегментации по его составляющиим.
Обзорно глянув на график, уже можно наметить план детального исследования фичей. Например, что можно понять из этого графика на примере feat_1 (зелёной линии)?
Высокий уровень engagement, т.е. фича простая в понимании и её цель достигается с высокой вероятностью. В совокупности с высоким значением stickiness, можно заключить, что те юзеры, которые фичей воспользовались и достигли её микро-цели, скорее всего, интегрируют её в свой повседневный флоу работы с приложением. Т.е. вопрос “зашла ли фича аудитории” можно смело закрывать;
Низкий показатели метрики monetization при высоком stickiness это не очень хорошо, т.к. показывает, что юзеры, которые используют фичу далеко не всегда являются платящими и дают слабый вклад в общий доход. Но тут же мы видим низкий adoption, который немного выправляет эту гипотезу — зная, что фича аудитории в целом зашла, мы можем заключить, что ей просто пользуется небольшая доля аудитории, от этого тоже может быть низкий вклад в доход;
Низкий показатель конверсии говорит о характере фичи, она классная и всем нравится, но совершенно не мотивирует юзеров к конверсии. Если дизайн позволяет, можно попробовать как-то поработать с этим;
Но главная проблема тут может скрываться как раз в adoption. Если фича не заточена на узкий сегмент аудитории, то, возможно, есть проблемы в расположении точки входа в сценарий.
В целом фича удобная и понятная, переделывать её механику глобально не нужно. Но её сложно найти. Повысив этот показатель, мы можем привлечь сюда больше платящих, увеличив итоговую долю её дохода. А зная, что она “залипательная”, мы косвенно можем увеличить классический Retention платящих юзеров. Кроме того, можно подумать как увеличить конверсию, чтобы также повлиять на доход.
Дальше накидываем гипотез и отправляемся тестировать.
Для себя я пилил такую системку на R в Shiny, поэтому когда в работе мне прилетает новый релиз, я просто добавляю название фичи в скрипт и она добавляется к общему списку. Удобно :) Скрипт скидывать не буду, уж очень специфичен для нашего продукта. Но как-нибудь обязательно сделаю более универсальный для гитхаба. Следите за обновлениями в тг, как говорится.
Мне рассказывали, что похожую систему раньше (а может и сейчас) использовали в некоторых продуктах Яндекса, там в итоге ещё все метрики приводили к общей взвешенной оценке и выстраивали рейтинг по этому скору. Фичи в начале списка идут в развитие и расширение в первом потоке, а фичи в конце попадают под вопрос удаления из продукта.
Конечно, именно эта система не ложится идеально на все типы продуктов, но это просто пример инструмента, который может помочь вам в быстром обзорном анализе, чтобы сразу наметить векторы детального изучения.
Про продуктовую аналитику в целом я больше пишу в тг, присоединяйтесь, если интересно:
")
")


покрытия кода по результатам динамического анализа")