
Привет, я Андрей Сергеев, руководитель группы разработки IoT-решений в Mail.ru Cloud Solutions. Известно, что универсальной базы данных не существует. Особенно когда нужно построить платформу интернета вещей, способную обрабатывать миллионы событий от датчиков в секунду в режиме near real-time.
Наш продукт Mail.ru IoT Platform начинался с прототипа на базе Tarantool. Расскажу, какой путь мы прошли, с какими проблемами столкнулись и как их решали. А также покажу текущую архитектуру современной платформы индустриального интернета вещей. В статье поговорим:
- о предъявляемых нами требованиях к базе данных, универсальном решении и CAP-теореме;
- о том, является ли подход database + application server in one серебряной пулей;
- об эволюции платформы и баз данных, используемых в ней;
- о том, сколько у нас используется Tarantool’ов и как мы дошли до жизни такой.
Эта статья — по видео выступления на @Databases Meetup by Mail.ru Cloud Solutions, если не хотите читать, можно посмотреть.
Mail.ru IoT Platform в настоящее время
Наш продукт Mail.ru IoT Platform — масштабируемая и аппаратно-независимая платформа для построения решений индустриального интернета вещей. Она позволяет собирать данные одновременно с сотен тысяч устройств и обрабатывать этот поток в режиме near real-time (то есть квазиреальном времени), в том числе с помощью пользовательских правил — скриптов на языках Python или Lua.
Платформа может хранить неограниченный объем сырых данных от источников, есть набор готовых компонентов для визуализации и анализа данных, встроенные инструменты для предиктивной аналитики и создания приложений на базе платформы.

Так выглядит устройство Mail.ru IoT Platform
На данный момент платформа доступна для установки по модели on-premise на мощностях заказчика, в этом году планируется релиз платформы как сервиса в публичном облаке.
Прототип на Tarantool: с чего все начиналось
Наша платформа начиналась как пилотный проект — прототип с single instance Tarantool, основная функция которого заключалась в получении потока данных от OPC-сервера, обработке полученных событий с помощью Lua-скриптов в реальном времени, мониторинге ключевых показателей на их основе и генерации событий и алертов в вышестоящие системы.
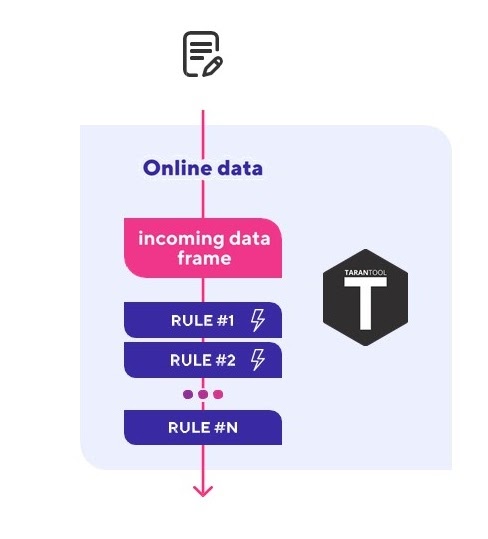
Схема прототипа на Tarantool
Этот прототип даже проработал в боевых условиях несколько месяцев на кустовой площадке, это платформа для добычи нефти в открытом море, в Ираке, в Персидском заливе. Он мониторил ключевые показатели и поставлял данные для системы визуализации и журнала событий. Пилот признали успешным, но как часто бывает с прототипами — дальше пилота дело не пошло и прототип был отложен в долгий ящик до тех пор, пока не попал к нам в руки.
Наши цели при разработке IoT-платформы
Вместе с прототипом мы получили задачу — сделать полноценную, масштабируемую и отказоустойчивую IoT-платформу, которую можно было бы в дальнейшем запустить как сервис в публичном облаке.
Нам нужно было построить платформу со следующими вводными:
- Одновременное подключение сотен тысяч устройств.
- Прием миллионов событий в секунду.
- Потоковая обработка в режиме near real-time.
- Хранение сырых данных за несколько лет.
- Инструменты как для потоковой аналитики, так и для аналитики по историческим данным.
- Поддержка развертывания в нескольких дата-центрах для обеспечения максимальной катастрофоустойчивости.
Плюсы и минусы прототипа платформы
На момент старта активной разработки прототип выглядел следующим образом:
- Tarantool, который используется как база данных + сервер приложений (Application Server);
- все данные хранятся в памяти Tarantool;
- приложение на Lua в этом же Tarantool, которое выполняет функции по приему данных, их обработке и вызову пользовательских скриптов на входящих данных.
У такого подхода к построению приложений есть свои плюсы:
- Код и данные лежат в одном месте, что позволяет оперировать данными прямо в памяти приложения и убирает накладные расходы на походы по сети, характерные для традиционных приложений.
- Tarantool использует JIT (Just in Time Compiler) для Lua, который во время выполнения компилирует Lua-код в машинный, что позволяет простым скриптам на Lua выполняться на скорости, сравнимой с кодом на C (40 000 RPS с одного ядра — и это не предел!).
- В основе Tarantool лежит кооперативная многозадачность, то есть каждый вызов хранимой процедуры запускается в своем файбере, аналоге корутины, что дает еще больший буст производительности в задачах с I/O-операциями, например походами по сети.
- Эффективное использование ресурсов — мало какой инструмент способен обслужить 40 000 запросов в секунду с одного ядра CPU.
Но есть и существенные минусы:
- Нам нужно хранить сырые данные от устройств за несколько лет, но у нас нет сотен петабайт памяти для Tarantool.
- Прямое следствие из первого плюса: весь код нашей платформы — хранимые процедуры в базе данных, значит, любое обновление кодовой базы платформы — это обновление базы данных, что очень больно.
- Динамическое масштабирование затруднено, так как производительность всей системы завязана на потребляемую этой системой память. Проще говоря, нельзя быстро и просто добавить еще один Tarantool для увеличения пропускной способности без потери 24-32 Гб памяти (Tarantool аллоцирует всю память под данные при старте) и решардинга имеющихся данных. Также при шардировании данных мы теряем наш первый плюс — данные не обязательно окажутся на том же Tarantool, что и выполняемый код.
- Деградация производительности при усложнении кода по мере развития платформы. Это происходит как из-за того, что Tarantool выполняет весь Lua в одном системном потоке, так и из-за того, что LuaJIT на сложном коде чаще переходит в медленный режим интерпретатора вместо компиляции.
Вывод: Tarantool — хороший выбор для создания MVP, но для полноценной, масштабируемой, легко поддерживаемой и отказоустойчивой IoT-платформы, способной принимать, обрабатывать и хранить данные от сотен тысяч устройств, он не подходит.
Главные боли прототипа, от которых мы хотели избавиться
Первым делом нам хотелось излечить две боли нашего прототипа:
- Уйти от концепции база данных + сервис приложения. Нам хотелось обновлять код приложения независимо от хранилища данных.
- Упростить динамическое масштабирование под нагрузкой. Хотелось получить легкое независимое горизонтальное масштабирование как можно большего числа функций.
Для решения этих проблем мы выбрали инновационный и еще мало кем опробованный подход: микросервисная архитектура и разделение сервисов на Stateless — приложения и Stateful — база данных.
Для еще большего облегчения эксплуатации и горизонтального масштабирования Stateless-сервисов мы их контейнеризировали и взяли на вооружение Kubernetes.

Со Stateless-сервисами разобрались, осталось решить, что же делать с данными.
Основные требования к базе данных для IoT-платформы
Изначально нам не хотелось городить огород и хотелось хранить все данные платформы в одном универсальной базе данных. Проанализировав поставленные цели мы пришли к следующему списку требований к универсальной базе данных:
- ACID-транзакции — клиенты будут держать в платформе реестр своих устройств, не хотелось бы случайно потерять пару устройств при модификации данных.
- Строгая консистентность — нужно получать одинаковые ответы от всех нод базы данных.
- Горизонтальное масштабирование на запись и чтение — от устройств идет большой поток данных, эти данные нужно обработать и сохранить в режиме near real-time.
- Отказоустойчивость — платформа должна уметь оперировать данными из нескольких дата-центров для обеспечения максимальной катастрофоустойчивости.
- Доступность — никто не станет использовать облачную платформу, которая будет целиком выходить из строя при отказе отдельных узлов.
- Объем хранения и хорошее сжатие — сырые данные должны храниться за период в несколько лет (это петабайты данных!), при этом нужно их сжимать.
- Производительность — быстрый доступ к сырым данным и средствам аналитики для потоковой аналитики, в том числе из пользовательских скриптов (десятки тысяч запросов на чтение в секунду!).
- SQL — хочется дать клиентам выполнять аналитические запросы на знакомом языке.
Проверка требований к базе данных по CAP-теореме
Прежде чем начать перебирать все базы данных, которые есть на рынке на предмет соответствия нашим требованиям, мы решили провалидировать наши требования на вменяемость с помощью довольно известного инструмента — CAP-теоремы.
CAP-теорема говорит, что распределенная система может иметь максимум два из трех следующих свойств:
- Consistency (согласованность данных) — во всех вычислительных узлах в один момент времени данные не противоречат друг другу.
- Availability (доступность) — любой запрос к распределенной системе завершается корректным откликом, однако без гарантии, что ответы всех узлов системы совпадают.
- Partition tolerance (устойчивость к разделению) — даже если между узлами нет связи, они продолжают работать независимо друг от друга.
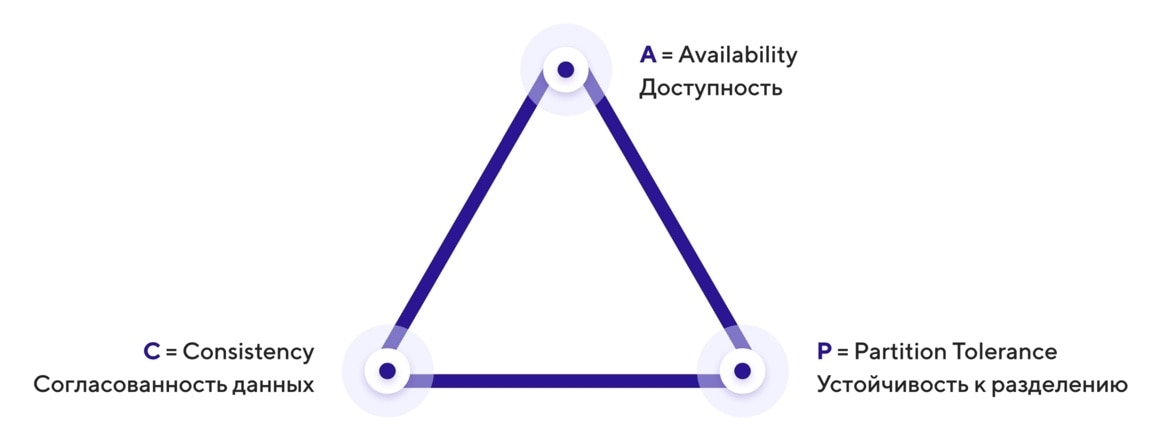
Например, классической CA-системой является кластер Master-Slave PostgreSQL с синхронной репликацией, а классической AP-системой является Cassandra.
Вернемся к нашим требованиям и классифицируем их с помощью CAP-теоремы:
- ACID-транзакции и строгая консистентность (либо хотя бы не eventual consistency) — это C.
- Горизонтальное масштабирование на запись и чтение плюс высокая доступность — это A (мульти-мастер).
- Отказоустойчивость — это P, при выпадении одного дата-центра платформа не должна умереть.

Вывод: нужная нам универсальная база данных должна обладать всеми тремя свойствами из CAP-теоремы, а значит универсальной базы данных под все наши требования не существует.
Выбор базы данных под данные, с которыми работает IoT-платформа
Если не получается выбрать универсальную базу данных, мы решили выделить типы данных, с которыми будет работать платформа, и подобрать базу данных под каждый тип.
При первом приближении мы поделили данные на два типа:
- Метаинформация — модель мира, устройства, настройки, правила, практически все данные, кроме тех, что передают конечные устройства.
- Сырые данные от устройств — показания датчиков, телеметрия и служебная информация от устройств. Фактически, это временные ряды, где каждое отдельное сообщение содержит значение и метку времени.
Выбор базы данных для метаданных
Требования к базе данных для метаданных. Метаданные по своей природе реляционны. Для них характерен небольшой объем, они редко модифицируются, но — это важные данных, их нельзя терять, поэтому важна консистентность хотя бы в рамках асинхронной репликации, а также ACID-транзакции и горизонтальное масштабирование на чтение.
Таких данных относительно немного и изменяться они будут относительно нечасто, поэтому можно пожертвовать горизонтальным масштабированием на запись, а также возможной недоступностью базы на запись в случае аварии. То есть в терминах CAP-теоремы нам нужна CA-система.
Что подходит в обычном случае. При такой постановке задачи нам вполне подошла бы любая классическая реляционная база данных с поддержкой кластеров с асинхронной репликацией вроде PostgreSQL или MySQL.
Особенности нашей платформы. Нам также была нужна поддержка деревьев с определенными требованиями. В составе прототипа была фича из систем класса БДРВ (баз данных реального времени) — моделирование мира с помощью дерева тегов. Они позволяют объединять все устройства клиента в одну древовидную структуру, что облегчает управление большим количеством устройств и их отображение.
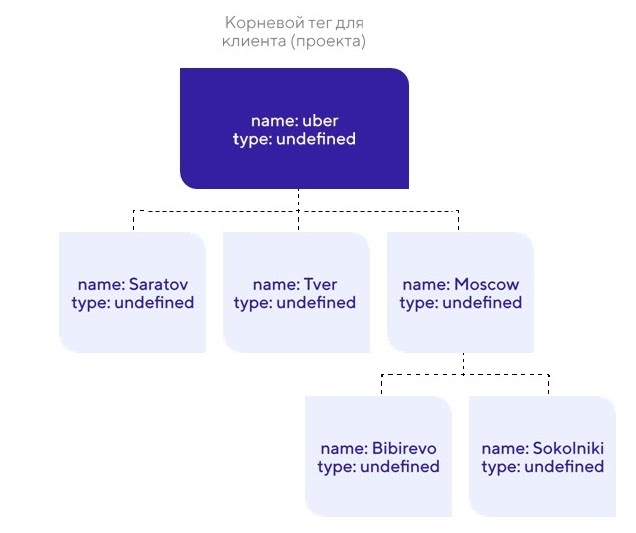
Так выглядит отображение устройств в виде древовидной структуры
Такое дерево позволяет увязать конечные устройства с окружением, например, можно поместить устройства, физически расположенные в одном помещении, в одно поддерево, что сильно облегчает работу с ними в дальнейшем. Это удобная функция, кроме того, дальше мы хотели работать в нише БДРВ, а там наличие подобной функциональности — фактически промышленный стандарт.
Для полноценной реализации деревьев тегов потенциальная база данных должна отвечать таким требованиям:
- Поддержка деревьев с произвольной шириной и глубиной.
- Модификация элементов дерева в ACID-транзакциях.
- Высокая производительность при обходе дерева.
Классические реляционные базы данных могут неплохо управляться с небольшими деревьями, но с произвольными деревьями они справляются не так хорошо.
Возможное решение. Использовать две базы данных — графовую базу данных для хранения дерева и реляционную базу данных для хранения остальной метаинформации.
У этого подхода сразу несколько больших недостатков:
- Для обеспечения консистентности между двумя БД нужно добавить внешний координатор транзакций.
- Такая конструкция сложна в поддержке и не очень надежна.
- На выходе получаем две базы данных вместо одной, при этом графовая база нужна только для поддержки ограниченной функциональности.
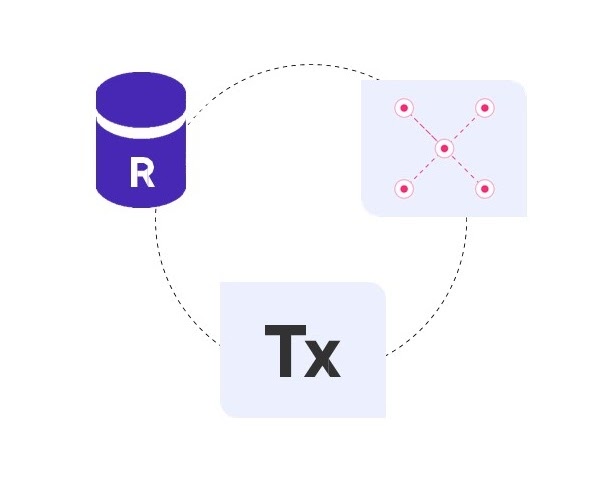
Возможное, но не очень хорошее решение с двумя базами данных
Наше решение для хранения метаданных. Мы подумали еще и вспомнили, что изначально данный функционал был реализован в прототипе на базе Tarantool и получилось очень даже неплохо.
Прежде чем продолжить, я хотел бы дать нестандартное определение Tarantool: Tarantool — это не база данных, а набор примитивов для построения базы данных под ваш конкретный кейс.
Доступные примитивы из коробки:
- Спейсы — аналог таблиц в БД для хранения данных.
- Полноценные ACID-транзакции.
- Репликация — асинхронная с помощью WAL-логов.
- Инструмент для шардирования, который поддерживает автоматический решардинг.
- Сверхбыстрый LuaJIT для хранимых процедур.
- Большая стандартная библиотека.
- Пакетный менеджер LuaRocks с еще большим количеством пакетов.
Нашим СА-решением стала реляционная + графовая база данных на базе Tarantool. Мы собрали хранилище метаинформации мечты на базе примитивов Tarantool:
- Спейсы для хранения данных.
- ACID-транзакции — были в наличии.
- Асинхронная репликация — была в наличии.
- Relations — сделали на хранимых процедурах.
- Деревья — тоже сделали на хранимых процедурах.
Кластерная инсталляция у нас классическая для подобных систем — один Master для записи и несколько Slive с асинхронной репликацией для масштабирования на чтение.
Результат: быстрый масштабируемый гибрид реляционной и графовой базы данных. Один инстанс Tarantool способен обрабатывать тысячи запросов на чтение, в том числе с активным обходом дерева.
Выбор базы данных для данных от устройств
Требования к базе данных для данных от устройств. Для этих данных характерны частая запись и большой объем данных: миллионы устройств, несколько лет хранения, петабайты информации как приходящих сообщений, так и хранимых данных. Важна их высокая доступность, так как именно показаниями датчиков в основном оперируют как пользовательские правила, так и наши внутренние сервисы.
Для базы данных важно горизонтальное масштабирование на чтение и запись, доступность и отказоустойчивость, а также наличие готовых аналитических инструментов для работы с этим массивом данных, желательно на базе SQL. При этом консистентностью и ACID-транзакциями мы можем пожертвовать.
То есть в рамках CAP-теоремы нам нужна AP-система.
Дополнительные требования. У нас было несколько дополнительных требований для решения, где будут храниться гигантские объемы данных:
- Time Series — данные от датчиков являются временными рядами, хотелось получить специализированную базу.
- Open source — плюсы открытого исходного кода не нуждаются в комментариях.
- Бесплатный кластер — распространенный бич среди новомодных баз данных.
- Хорошее сжатие — учитывая объемы данных и в целом их однородность хотелось эффективного сжатия хранимых данных.
- Успешная эксплуатация — мы хотели стартовать на базе данных, которую уже кто-то активно эксплуатирует на близких к нашим нагрузках, чтобы минимизировать риски.
Наше решение. Под наши требования подходил исключительно ClickHouse — колоночная база данных временных рядов с репликацией, мультимастером, шардированием, поддержкой SQL и бесплатным кластером. Более того, у Mail.ru есть многолетний успешный опыт в эксплуатации одного из самых больших по объему хранимых данных кластеров ClickHouse.
Но насколько бы ни был хорош ClickHouse, и с ним у нас возникли проблемы.
Проблемы с базой данных для данных устройств и их решение
Проблема с производительностью на запись. Сразу возникла проблема с производительностью записи большого потока данных. Их нужно как можно быстрее донести до аналитической базы данных, чтобы правила, которые анализируют поток событий в режиме реального времени, могли посмотреть историю конкретного устройства и решить — поднимать алерт или нет.
Решение проблемы. ClickHouse плохо переносит множественные одиночные вставки (инсерты), но хорошо работает с большими пачками (батчами) данных — легко справляется с записью батчей на миллионы строк. Мы решили буферизировать входящий поток данных, а затем вставлять эти данные батчами.
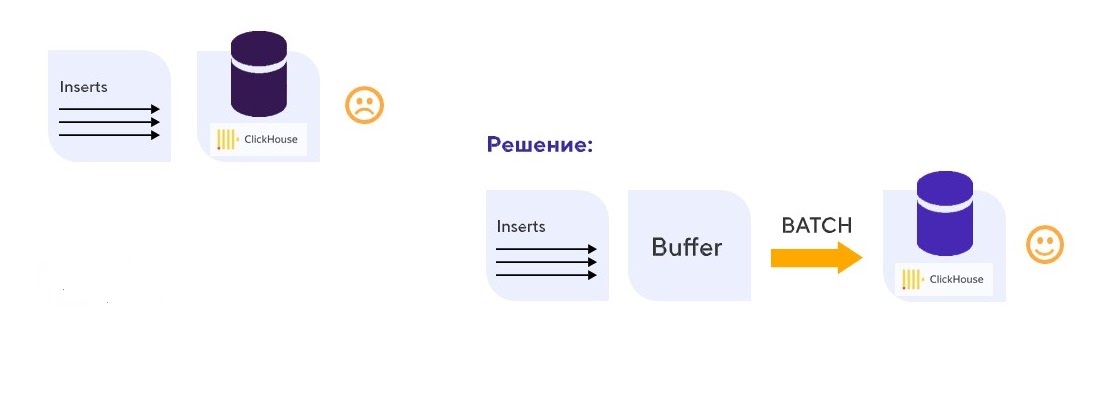
Так мы справились с низкой производительностью на запись
Проблема с записью была решена, но это стоило нам появления существенной задержки в несколько секунд между поступлением данных в систему и их появлением в нашей базе.
А это критически важно для различных алгоритмов, реагирующих на данные с датчиков в режиме реального времени.
Проблема с производительностью на чтение. Потоковой аналитике для обработки данных в режиме реального времени постоянно нужна информация из базы данных — это десятки тысяч мелких запросов. В среднем одна нода ClickHouse держит около ста аналитических запросов одновременно, она создавалась для нечастых тяжелых аналитических запросов по обработке больших объемов данных. Конечно, это не подходит для подсчета трендов на потоке данных от сотен тысяч датчиков.

С большим количеством запросов ClickHouse работает плохо
Решение проблемы. Мы решили поставить перед ClickHouse кэш, в котором будут находиться наиболее запрашиваемые в правилах горячие данные за последние 24 часа.
Данные за последние 24 часа — это не данные за год, но тоже довольно значительный объем данных, поэтому здесь также нужна AP-система с горизонтальным масштабированием на чтение и запись, но уже с упором на производительность как на запись одиночных событий, так и на множественные чтения. Также требуется высокая доступность, средства аналитики по временным рядам, персистентность и встроенный TTL.
В итоге нужен был быстрый ClickHouse, который может даже хранить все в памяти ради скорости. На рынке мы не нашли ни одного подходящего решения, поэтому решили сконструировать его на базе примитивов Tarantool:
- Персистентность — есть (WAL-логи + снапшоты).
- Производительность — есть, все данные в памяти.
- Масштабирование — есть репликация + шардирование.
- Высокая доступность — есть.
- Инструменты аналитики по временным рядам (группировка, агрегация, etc.) — сделали на хранимых процедурах.
- TTL — сделали на хранимых процедурах одним фоновым файбером (корутиной).
Получилось удобное и производительное решение — один инстанс держит 10 000 RPC на чтение, в том числе аналитические запросы до десятков тысяч запросов.
Вот такая архитектура получилась в итоге:

Итоговая архитектура: ClickHouse как аналитическая база данных и кэш Tarantool, который хранит данные за 24 часа
Новый тип данных — состояние и его хранение
Мы подобрали специализированные базы данных для всех данных, но платформа развивалась и появился новый тип данных — состояние. Состояние содержит текущее состояние устройств и датчиков, а также различные глобальные переменные для правил потоковой аналитики.
Например, в помещении есть лампочка. Она может быть как выключена, так и включена, и нужно всегда иметь доступ к ее текущему состоянию, в том числе в правилах. Другой пример — переменная в потоковых правилах, например, какой-нибудь счетчик. Характеризуется этот тип данных потребностью в частой записи и быстром доступе, но при этом сами данные занимают относительно небольшой объем.
Хранилище метаинформации плохо подходит для таких типов данных, так как состояние может меняться часто, а у нас потолок записи ограничен одним Master. Долговременное и оперативное хранилища тоже плохо подходят, так как у нас состояние последний раз менялось три года назад, а нам важно иметь быстрый доступ на чтение.
То есть для базы данных, в которой хранят состояние, важны горизонтальное масштабирование на чтение и запись, высокая доступность и отказоустойчивость, при этом консистентность нужна на уровне значений/документов. Можно пожертовать общей консистентностью и ACID-транзакциями.
Подходящим решением может быть любая Key Value или документная БД: шардированный кластер Redis, MongoDB либо снова Tarantool.
Плюсы Tarantool:
- Это самый популярный способ использования Tarantool.
- Горизонтальное масштабирование — есть асинхронная репликация + шардирование.
- Консистентность на уровне документа — есть.
В итоге сейчас у нас три Tarantool, которые мы используем для совершенно разных кейсов: хранение метаинформации, кэш для быстрого чтения данных с устройств и хранение данных состояния.
Как выбрать базу данных для IoT-платформы
- Универсальной базы данных не существует.
- Каждому типу данных — свою базу данных, наиболее подходящую ему.
- Иногда нужной вам базы данных на рынке может не быть.
- Tarantool подходит как основа для специализированной базы данных.
Этот доклад впервые прозвучал на @Databases Meetup by Mail.ru Cloud Solutions. Смотрите видео других выступлений и подписывайтесь на анонсы мероприятий в Telegram Вокруг Kubernetes в Mail.ru Group.
- Какую базу данных выбрать для проекта, чтобы не выбирать снова.
- Больше чем Ceph: блочное хранилище в облаке MCS.



