
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!

Недавно мы публиковали статью про производительность Vault с разными бэкендами, а сегодня расскажем, как делать бэкапы — и снова на разных бэкендах: Consul, GCS (Google Cloud Storage), PostgreSQL и Raft.
Как известно, HashiCorp предоставляет нативный метод бэкапа только для одного бэкенда — Integrated Storage (Raft Cluster), представленного как GA в апреле прошлого года. В нем можно снять снапшот всего одним curl’ом и не беспокоиться о каких-либо нюансах. (Подробности смотрите в tutorial и документации по API.)
В остальных же случаях придется выкручиваться самим, придумывая, как правильно реализовывать бэкап. Очевидно, что во время резервного копирования Vault часть данных может меняться, из-за чего мы рискуем получить некорректные данные. Поэтому важно искать пути для консистентного бэкапа.
1. Consul
В Consul существует встроенный механизм для создания и восстановления снапшотов. Он поддерживает point-in-time backup, поэтому за консистентность данных можно не переживать. Однако есть существенный недостаток: на время снапшота происходит блокировка, из-за чего могут возникнуть проблемы с операциями на запись.
Для создания такого снимка необходимо:
1. Подключиться к инстансу с Consul и выполнить команду:
# consul snapshot save backup.snap
Saved and verified snapshot to index 199605
#2. Забрать файл backup.snap (заархивировать и перенести в место для хранения бэкапов).
Для восстановления будет схожий алгоритм действий с выполнением другой команды на сервере с Consul:
# consul snapshot restore backup.snapВ HA Vault-кластере активный узел будет являться лидером во время экспорта данных или моментального снимка. После восстановления данных Vault в Consul необходимо вручную снять эту блокировку, чтобы кластер Vault мог выбрать нового лидера.
Выполните команду после восстановления данных для снятия блокировки:
# consul kv delete vault/core/lockРабота со снапшотами обычно происходит быстро (см. примеры в конце статьи) и обычно не вызывает трудностей.
2. Google Cloud Storage
С GCS всё оказалось сложнее: подходящих вариантов для создания снапшотов/бэкапов бакета найти не удалось. Предусмотрена поддержка версионирования, но с ним восстановить сразу весь бакет на определенный момент времени нельзя — можно только по одному файлу. В теории это решается скриптом для взаимодействия со всеми файлами, но если учесть размер Vault’а и количества файлов в нем, скорее всего такой скрипт будет работать слишком долго. Если мы хотим получить консистентные данные, то снятия дампа придется на время останавливать Vault.
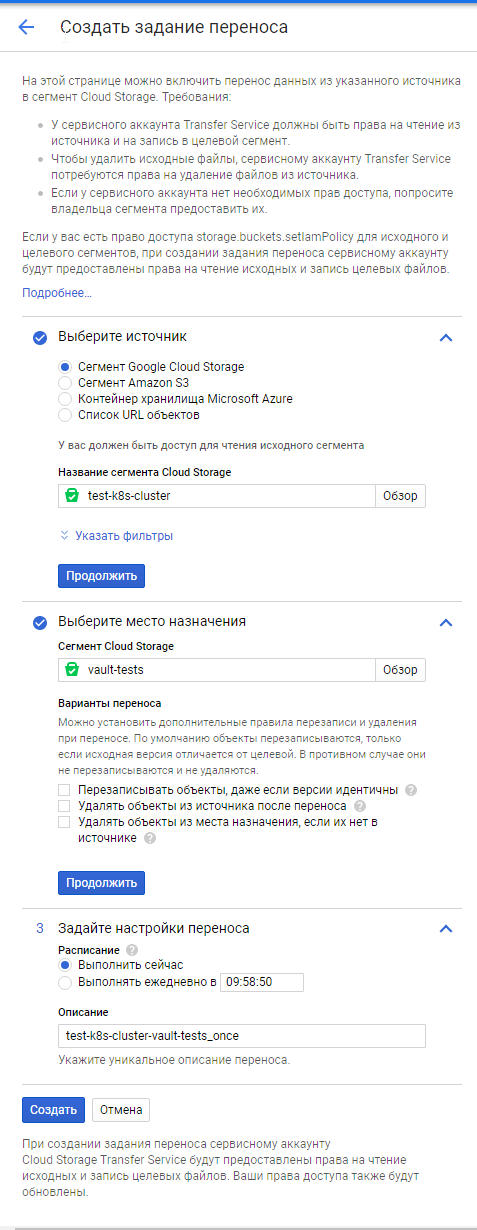
А для копирования данных в GCS предусмотрен удобный способ — Data Transfer. С его помощью можно создать полную копию бакета, а дальше уже работать с ним по своему усмотрению.
Последовательность действий:
Выключаем Vault.
Заходим в Data Transfer (https://console.cloud.google.com/transfer/cloud).
Выбираем исходный бакет, вводим название бакета, куда переносить данные, и выбираем разовую операцию. Здесь возможно установить и операцию по расписанию, но она не учитывает специфики Vault (тот факт, что сервис необходимо остановить Vault на время её выполнения), поэтому оставляем разовый запуск.
После успешного копирования запускаем Vault.
С созданным бакетом можно работать: например, скачать его содержимое при помощи
gsutil, заархивировать все данные и отправить на долгосрочное хранение.
В зависимости от количества ключей продолжительность бэкапа может сильно изменяться: от нескольких минут и практически до бесконечности. Ниже будет приведена таблица с примерными значениями.
Скриншоты страницы при создании трансфера и после завершения:

3. PostgreSQL
Базу в PostgreSQL достаточно забэкапить любыми доступными для этой СУБД способами — не сомневаюсь, что они хорошо известны инженерам, уже работающим с PgSQL. Инструкции по выполнению операций для настройки бэкапов и восстановления данных на нужный момент времени (PITR, Point-in-Time Recovery) описаны в официальной документации проекта. Также хорошую инструкцию можно найти в этой статье от Percona.
Не останавливаясь на технических деталях по этим операциям (они уже раскрыты в многочисленных статьях), отмечу, что у PostgreSQL получился заметно более быстрый бэкап, чем у вариантов выше. Для простоты действий, мы замеряли бэкап и восстановление обычными pg_dump и pg_restore (да, это упрощенное измерение, однако использование схемы с PITR не повлияет значительно на скорость).
4. Integrated Storage (Raft)
Однако обзор не был бы полным без самого удобного и простого на сегодняшний день бэкенда — Raft. Благодаря тому, что Raft полностью дублирует все данные на каждый из узлов, выполнять снапшот можно на любом сервере, где запущен Vault. А сами действия для этого предельно просты.
Для создания снимка необходимо:
. Зайти на сервер/pod, где запущен Vault, и выполнить команду:
# vault operator raft snapshot save backup.snapshotЗабрать файл
backup.snapshot(заархивировать и перенести в место для хранения бэкапов).
Для восстановления команду на сервере с Vault надо заменить на:
# vault operator raft snapshot restore backup.snapshotКак работать с Raft и со снапшотами, хорошо описано в официальной документации.
Простой бенчмарк
Не претендуя на полноценное исследование о производительности, сделаем простой замер скорости создания бэкапов и восстановления из них для всех упомянутых бэкендов для Vault.
Загрузка данных в Vault
Перед началом тестирования загрузим данные в Vault. Мы для этого использовали официальный репозиторий от HashiCorp: в нем есть скрипты для вставки ключей в Vault.
Протестируем на двух коллекциях: 100 тысяч и 1 млн ключей. Команды для первого теста:
export VAULT_ADDR=https://vault.service:8200
export VAULT_TOKEN=YOUR_ROOT_TOKEN
vault secrets enable -path secret -version 1 kv
nohup wrk -t1 -c16 -d50m -H "X-Vault-Token: $VAULT_TOKEN" -s write-random-secrets.lua $VAULT_ADDR -- 100000Эту операцию проделаем для всех инсталляций Vault, а затем повторим её для другого количества ключей.
Результаты
После загрузки данных мы сделали бэкап для всех 4 бэкендов. Бэкап для каждого hosted-бэкенда снимался на однотипной машине (4 CPU, 8 GB RAM).
Результаты сравнения по бэкапу и восстановлению:
100k backup | 100k restore | 1kk backup | 1kk restore | |
Consul | 3.31s | 2.50s | 36.02s | 27.58s |
PosgreSQL | 0.739s | 1.820s | 4.911s | 24.837s |
GCS* | 1h | 1h24m | 12h | 16h |
Raft | 1.96s | 0.36s | 22.66s | 4.94s |
* Восстановление бэкапа в GCS может происходить в нескольких вариантах:
Мы просто переключаем Vault на бэкапный бакет. В таком случае достаточно перезапустить Vault с новым конфигом и все сразу же заработает.
Загрузить файлы бэкапа в бакет через утилиту
gsutilи уже после этого переключать. Результаты для такого варианта будут зависеть от количества файлов и их размера — в таблице приведен результат именно для такого варианта.
NB. В этом мини-тестировании сравниваются решения разного рода: single-экземпляр PostgreSQL против кластеров Consul и Raft против сетевого распределённого хранилища (GCS). Это может показаться не совсем корректным, потому что у таких бэкендов и разные возможности/свойства (отказоустойчивость и т.п.). Однако данное сравнение приведено исключительно как примерный ориентир — для того, чтобы дать понимание порядковой разницы в производительности. Ведь это зачастую является одним из факторов при выборе того или иного способа.
Выводы
PostgreSQL занимает уверенное первое место по скорости создания бэкапа. Raft не так сильно отстает от лидера на небольшом объеме секретов, но разница заметно возрастает при увеличении количества данных. Однако в то же время Raft явно лидирует в скорости восстановления.
Если сравнивать удобство, то Raft и Consul — максимально простые: для выполнения бэкапа и восстановления достаточно выполнить буквально одну команду. GCS же предоставляет встроенный функционал в UI для копирования бакетов: на мой вкус, это немного сложнее, однако для других пользователей может быть плюсом, что все действия выполняются мышкой в браузере. Но в GCS есть существенная проблема с отсутствием гарантий по времени создания снапшотов: одинаковый набор данных может бэкапиться как за 1 час, так и за 3-4 часа.
Помимо производительности и удобства есть и другой критерий — надежность. Вывод, казалось бы, довольно банален: чем менее надежен бэкенд, тем легче его бэкапить. Хотя Vault сам по себе позиционируется как приложение категории cloud native, его бэкап полностью зависит от выбранного бэкенда, и во многих случаях мы получим простой, что недопустимо для такого важного сервиса:
В Consul можно ожидать проблем с чтением и записью при бэкапе/восстановлении данных.
А у PostgreSQL — при восстановлении.
У GCS — проблема другого характера: нет гарантий на скорость копирования.
Получается, что все эти решения имеют серьёзные недостатки, которые могут быть недопустимы в production. Понимая это, в HashiCorp и создали своё оптимальное решение — Integrated Storage (Raft). В нём получается делать бэкапы полностью беспростойно и при этом быстро.
В итоге: если вам важна максимальная скорость для снятия и восстановления бэкапов, то подойдут PostgreSQL и Raft. В первом случае, однако, надо повозиться с удобством: чтобы все правильно настроить и автоматизировать, придется потратить время (и иметь экспертизу). Наш текущий выбор пал на Integrated Storage (Raft) как самый простой в использовании и надежный бэкенд.
P.S.
Читайте также в нашем блоге:
«Сравниваем производительность HashiCorp Vault с разными бэкендами»;
«Как мы Elasticsearch в порядок приводили: разделение данных, очистка, бэкапы».



