
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
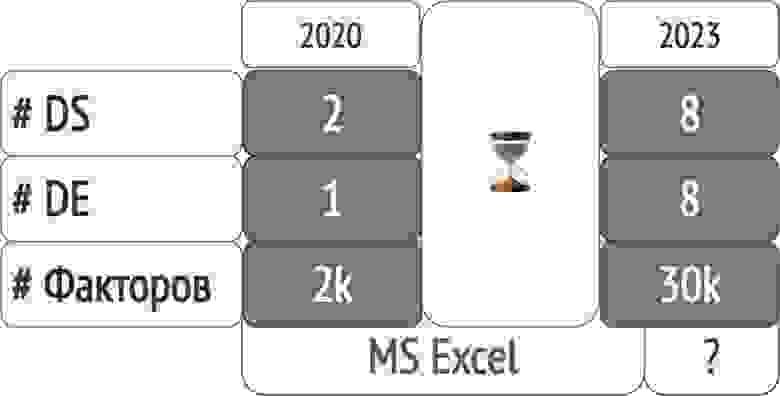
Всем привет! На связи Иван Кондраков и Константин Грушин. В банке «Открытие» мы с командой занимаемся разработкой и развитием пула моделей для принятия решений о выдаче кредитных продуктов и банковских гарантий для малого и среднего бизнеса. Еще в 2020 году у нас было всего два дата‑сайентиста, один дата‑инженер, несколько моделей и факторы в объеме до двух тысяч штук. С каждым годом количество задач и обученных моделей росло. А вместе с ними росло и количество гипотез, которые нам хотелось проверять при построении моделей. А исходя из специфики области (ограничения на интерпретируемость моделей, используемые алгоритмы, подходы), немалая доля гипотез выражалась именно в работе с факторами, на которых обучаются наши модели. К тому же сложно переоценить важность данной работы, поскольку от того, насколько выверены факторы, напрямую зависит качество моделей. Проблема в рассчитанном факторе, будь то ошибка в логике расчета или утечка информации о целевой переменной (т. н. target leakage), приводит к невалидности полученных результатов. Хорошо, когда такие ошибки выявляются до начала разработки модели, а не в процессе ее промышленной эксплуатации.
И вот на дворе 2023 год, у нас уже восемь дата‑сайентистов, команда дата‑инженеров, больше чем несколько моделей и около 30 тысяч факторов, список которых до сих пор поддерживается вручную в Excel‑файлах.
Проблематика
Для чего нам нужны такие файлы, почему без них нельзя и в чем проблема продолжать делать это руками в Excel?
По сути, это справочник, с помощью которого можно найти соответствие между именем поля в таблице с рассчитанными факторами для разработки модели и следующей информацией:
Описанием фактора;
Логикой расчета фактора;
Ожидаемой зависимостью от уровня дефолта (т. н. бизнес‑логика);
Источником;
Типом данных;
Областью допустимых значений.
Нужен он нам для фиксации рассматриваемых моделью факторов и их согласования с заказчиком моделей. Проще говоря, для того, чтобы бизнес‑подразделения банка могли ориентироваться в том, какие характеристики потенциальных пользователей продукта мы планируем рассматривать для их будущей оценки при решении поставленной задачи. А также для того, чтобы на основе того же файла формировать требования дата‑инженерам для расчета таких характеристик. Для нас, дата‑сайентистов, он тоже крайне полезен. Например, мы с легкостью можем понять, что же означает загадочное DYN_CNT_TRANS_EXP_LINKEDEXL_3M_3M при анализе данных и в последующих этапах жизненного цикла модели. Именно поэтому без такого файла жить нам стало бы в разы сложнее.
Поддерживать такие файлы с каждым добавленным фактором становится все сложнее.
Мы выделяем три основные проблемы, с которыми столкнулись в текущем подходе:
Невыносимое версионирование, а точнее его отсутствие. Так, добавление новых факторов требует предельной концентрации, понимания перечня уже имеющихся характеристик, заполнения множества полей. Случайное удаление фактора из перечня может привести к его безвозвратной потере. А изменение в логике расчета или описании сложно контролировать. Мы произвели изменения, отметили это изменение каким‑либо образом в Excel, но когда оно было сделано, кем, почему, а также что именно поменялось, часто остается неизвестным.
Множество дублей по сути, но не по срезам затрудняет поддержку. Множество агрегатов, которые мы считаем для моделей, конечно, не так уж велико. Но то, по какому множеству срезов рассчитан фактор, определяет все — в работе мы стараемся учесть самые разные потенциально важные срезы. Такие срезы важны для модели, но их комбинации приводят к быстрому разрастанию справочника (и, как следствие, к невозможности быстрого нахождения нужных факторов и вытекающим из этого сложностям). Хотя эти срезы и дублируют сутевую составляющую фактора, к чему часто приковано внимание при работе со справочником. Или частично дублируют (например, если это два похожих фактора, состоящих из тех же срезов за исключением только одного).
Низкое качество документирования. Логика расчета факторов при том же описании может быть интерпретирована по‑разному, когда она определена недостаточно явно. Таких случаев у нас было довольно много. Так, например, «максимальное количество заключенных контрактов за 12 месяцев» каждый разработчик может посчитать по‑разному. В одной модели это количество контрактов не может быть равно нулю. И если контрактов не было найдено, то это null, в другой модели количество контрактов считается за 12×30 дней без учета дня ретро‑даты, а в третьей — с ее учетом. Так, оперативное дообучение, обновление модели при ее деградации становится сложным, как и формирование требования на реализацию расчета факторов для применения модели.
И усугубляет все эти проблемы множество существующих.xlsx файлов‑справочников с пересекающимися между собой факторами с разным описанием, форматом и т. д.
Поэтому нам очень хотелось иметь один файл‑справочник, который включает все наработки в едином, унифицированном формате с детализацией логики расчета. Справочник, который можно шарить между коллегами дата‑сайентистами и моделями, иметь возможность версионировать изменения и, как следствие, беспрепятственно добавлять и проверять новые гипотезы для повышения качества наших моделей.
Наш подход
А сейчас самое время написать нам в комментарии «Статья начинается с такого‑то абзаца»…))
Основная идея — написать условный парсер языка, который бы отражал факторы компактно, а функционал под его капотом мог бы избавить пользователя от ручного труда при формировании такого справочника. Собственно, эту идею мы и принялись реализовывать.
Так, для каждого источника данных каждый из команды делал свой подход к снаряду и делился с командой своим видением реализации такого решения.
Благодаря этому в процессе разработки мы собрали лучшие практики каждого, а затем внедряли их у себя по мере написания кода. Более того, в целях повышения качества документирования и учета всех прошлых наработок пришлось просмотреть и структурировать все накопленные ранее материалы, в том числе, в виде тех самых Excel‑файлов. Только так получилось гарантировать полноту покрытия разрабатываемого решения и фикс ошибок, с которыми пришлось столкнуться ранее при расчете факторов.
Все наши решения объединяет то, что на входе они получают от юзера в кратком формате информацию о желаемом признаке (или группе признаков), а точнее о сущностях, агрегатах и срезах, по которым компонуется ожидаемая бизнес‑логика, рэнж, на котором этот фактор определен, тип данных, правила его расчета в формате псевдокода или ином виде описания алгоритма, его кодировку для хранилища данных, отдельное описание для бизнес‑подразделений и коллег. А на выходе выдают python‑инстанс длинного списка факторов, который имеет свое небольшое API для дальнейшей работы с ним. Например, мы уже сейчас можем выгрузить полученный справочник в Excel‑файл или в базу, а в будущем сможем удобно фильтровать факторы, после чего отправить запрос на расчет определенных факторов в Feature Store.

Значимым образом в этом алгоритме выделяется группа факторов, рассчитываемая на основе простых сущностей по формулам. Например, показатели финансовой отчетности, которые в основной своей массе базируются на применении простейших операций над элементами отчетности (например, в виде строк бухгалтерского баланса) и отражают финансовое положение текущих или потенциальных клиентов. Для данной группы пользовательский опыт осложнен необходимостью знать, что из себя представляют строки форм отчетности, а также базовыми знаниями финансового анализа для генерации адекватных признаков. Но сама реализация упрощена тем, что отсутствуют сложные правила агрегации и фильтрации над сущностями.
Сам по себе конфигуратор или язык, которым мы пользуемся для описания базовых сущностей, а затем генерации — несложный. Это обычный python‑скрипт с несколькими классами внутри и зашитой в них логикой для компоновки разной мета‑информации о факторе. В упрощенном виде он выглядит следующим образом:
class Application:
"""Container of main entities and aggreagtes for Application"""
CNT = Field(name="количество", better_worse=True, *args)
SUM = Field(...)
...
# 2 фактора - "Кол-во заявок за всю историю" и "Кол-во заявок за 24 мес"
features_block_1 = Application.CNT(["APPS"], ["LIFETIME", "24M"])
# 4 фактора - "Кол-во заявок с суммой больше чем максимальная сумма LIFETIME и 24 месяца"
features_block_2 = Application.CNT(["APPS"], ["LIFETIME", "24M"]).filter(
"gt", Application.SUM(["APPS"], ["MAX"], ["LIFETIME", "24M"])
)
# 1 фактор - "Комбинация двух факторов из разных источников"
features_block_3 = Application.SUM(["CONTR"]).combination(
ContractHistory.AVGSUM(["CONTR"], ["BEN"], ["24M"], ["44FZ"], grouped="by_month")
) Так, например, при генерации логики расчета фактора, который является комбинацией над ранее сгенерированными факторами (feature_block_3), мы будем учитывать, в том числе, зависимость целевой переменной от значений факторов. С учетом того, что в промышленной среде для принятия кредитного риска используются преимущественно линейные алгоритмы, позволяющие интерпретировать результат работы модели, мы стараемся сохранить линейную зависимость факторов от целевой переменной. В сохранении линейности нам помогают знания о том, каким типом представлены исходные сущности и как они зависят от целевой переменной. Логика компоненты, отвечающей за формирование бизнес‑логики и операции для комбинации двух факторов типа float, int, представлена на рисунке.

Продолжая разговор о примере в feature_block_3, следует отметить, что по итогу работы скрипта мы получим сгенерированную мета‑информацию только об одном факторе. Но это лишь пример, в реальном мире список вырастает до 25–30 факторов при увеличении количества срезов в качестве параметров при генерации. Именно это помогает нам экономить время, например, при оценке наличия тех или иных факторов в длинном списке: мы смотрим на сутевую составляющую фактора и срезы в одном месте, не дублируя информацию, размазывая ее по строкам excel‑файла. По итогу обработки feature_block_3 получаем следующую информацию о сгенерированном факторе:

Напомню, что это комбинация уже двух рассчитанных ранее факторов, поэтому логику каждого из них мы дополнительно не расписываем в поле «Логика расчета». То есть ссылаемся на уже рассчитанные ранее факторы.
Когда мы вспоминаем, что такую информацию раньше генерировали вручную и затем поддерживали для 25–30 факторов с небольшими отличиями в тех же срезах или фильтрах для каждой нашей связки факторов, которых насчитываются сотни только для комбинаций предрассчитанных факторов, то понимаем, что не зря проделали работу по автоматизации этой рутины.
Какой профит мы извлекаем из этого решения:
Автоматически строим адекватные мета‑данные для факторов. Такие, как: описания, логика и др.;
Все это храним в одном месте, единообразно генерируем, документируем и получаем возможность версионировать с помощью git;
Поддержка, поиск, чтение имеющихся факторов становится легче за счет емкого описания правил их генерации.
Помимо извлеченного профита из данного подхода, в будущем, при реализации Feature Store, мы можем пользоваться этой наработкой для передачи данных в metastore, расчета определенного пула факторов с указанием версии после фильтрации. Использовать эту информации в дальнейшем при моделировании. Использовать как часть пайплайна CI/CD и при обновлении факторов тригерить какие‑то действия в Feature Store, например, подготовку факторов для определенного часто используемого датасета.
Примерно так мы бы работали с полученным решением в связке с Feature Store:


Или так при работе дата-сайентиста над моделью и желании выяснить информацию об используемом факторе:

Что в итоге
Мы реализовали удобный, понятный конфигуратор справочника факторов с возможностью его генерации на лету, с полноценной логикой внутри для возможности автоматической генерации понятной и однозначно интерпретируемой мета‑информации о наших факторах.
Да, здесь нет сумасшедшего кодинга или модных библиотек. Цель данной статьи в том, чтобы поделиться с вами, дорогой читатель, идеей, концепцией того решения, которое мы нашли и реализовали при попытке сэкономить время, деньги и нервы в работе с формализацией, а также улучшением справочника факторов для наших моделей.
И, как всегда, есть что улучшить. Пока в дальнейшие планы входит дополнить поддержку специфичных агрегатов, операций над ними, протестировать решение в «боевых» условиях, улучшить генерацию описания факторов, унифицировать формат конфигуратора для работы с различными источниками данных и упростить их подключение, а затем интегрировать это в будущий Feature Store.



