
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Языков в мире программирования масса, но корону по праву носит Python. Многие полюбили его за гибкость, лаконичность, бесчисленное количество модулей и поддержку сообщества. Именно этот язык стал основой для самых популярных мировых площадок: YouTube, Instagram, Uber и многих других. Однако, некоторые программисты считают Python языком с ограниченными возможностями и уверены, что он «задохнется» под тяжелой архитектурой highload системы.
Я, технический директор компании STM Labs, Андрей Комягин, за несколько минут смогу переубедить всех скептиков и доказать обратное.

Недавно в мире IT случилось важное событие — институт IEEE опубликовал список самых востребованных языков программирования. Корону победителя с гордостью примерил Python. Это вполне закономерный результат, поскольку Python — бесплатный язык программирования с открытым исходным кодом и удобными структурами данных. Он запускается на любых ОС и поддерживает множество сервисов, сред разработки и фреймворков. К тому же, он подходит для новичков, и его просто выучить.

Если и этого мало, то давайте не будем забывать, что именно Python стал основой для создания веб-сервисов и мобильных приложений, без которых мы не смогли бы делать ряд важных вещей ежедневно. Например, не смогли бы смотреть ролики на YouTube или следить за жизнью знаменитостей в Instagram, заказывать такси в Uber и юзать такие площадки, как Quora, Pinterest, Blender, Inkscape и Autodesk. Все они написаны на Python и, пожалуй, уже даже этот факт возводит его в «лик святых» языков программирования.
По этим и многим другим причинам мы привыкли, что в области машинного обучения (ML) и больших данных (Big Data) Python – это уже стандарт де-факто. Но, как только мы начинаем говорить о highload системах, тут же «всплывает» устоявшийся стереотип о том, что высоконагруженные системы надо делать на чем-то быстром. Чаще всего в таких случаях я слышу фразу: «Лучше взять сишечку! (семейство языков программирования С/C++) или, на худой конец, Java или C#». И когда я привожу в пример YouTube и говорю, что мы успешно делаем highload системы на Python, некоторые мои собеседники морщатся от удивления…
Давайте вместе ломать стереотип: на конкретном примере я расскажу, как правильно использовать Python в режиме Fast and Furious и построить на нем крутую архитектуру highload системы!
В качестве задачи рассмотрим систему обработки событий или процессинга документов. Архитектура у них плюс-минус одинаковая и имеет следующий pipeline (ETL):
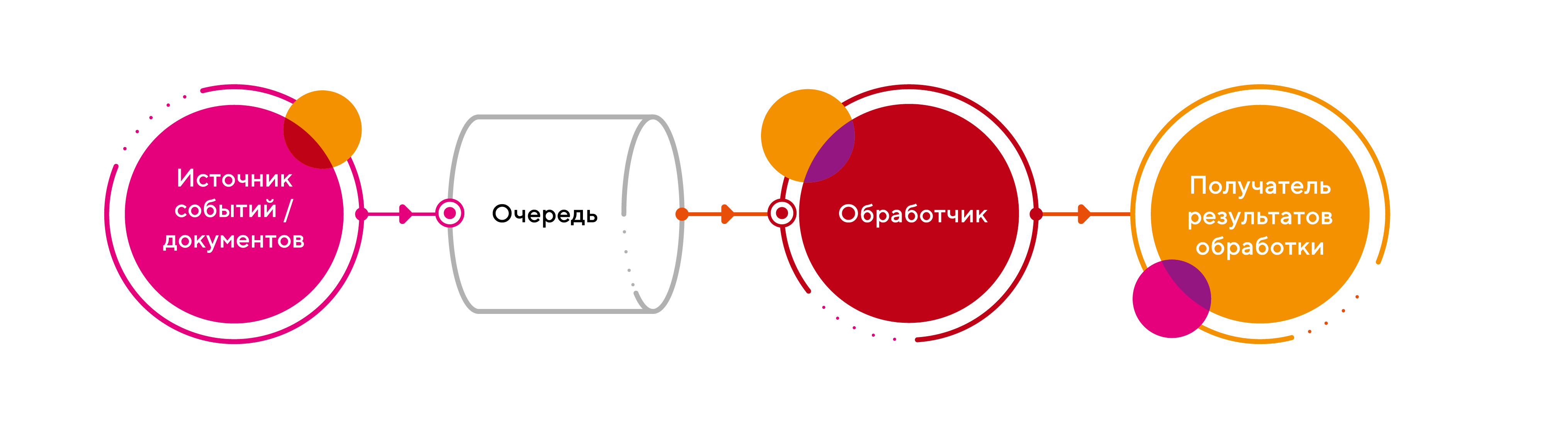
Для начала, решим задачу в лоб:
1. В качестве брокера возьмем Kafka;
2. В обработчике реализуем линейный процессинг сообщений из очереди на базе класса Kafka Consumer из библиотеки Kafka-Python;
3. Результат обработки запишем в СУБД MongoDb.
Имеем следующую схему:
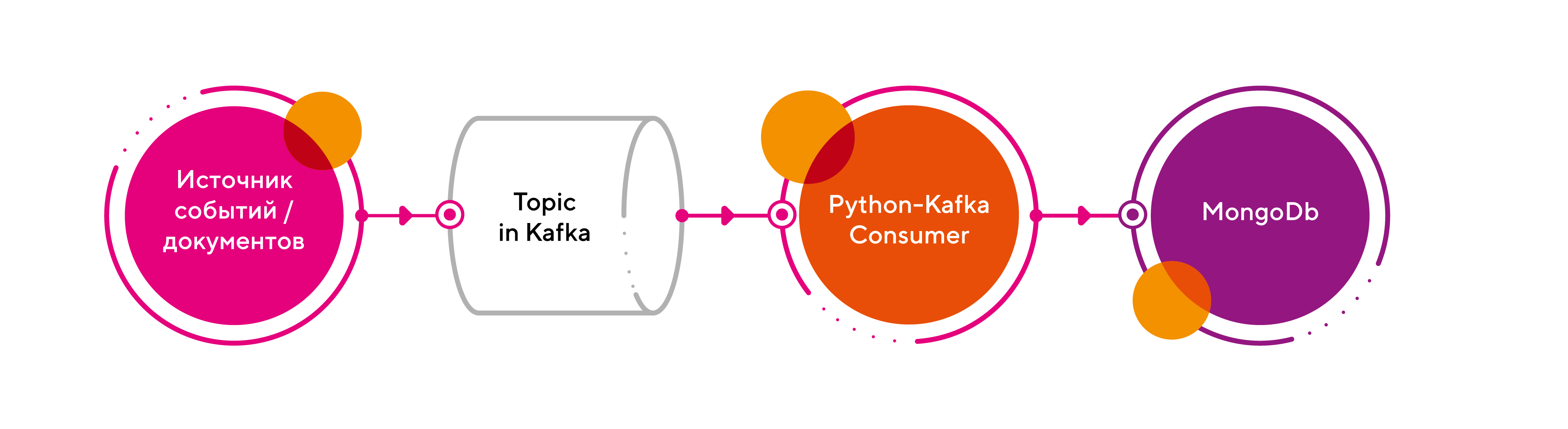
Приведу небольшой code snippet, как это реализовать:
Работает, но процессинг очереди идет слишком медленно! Пессимисты уже кричат: «Все пропало! Что же нам теперь делать?». Мое решение простое и лаконичное – использовать процессный пул для параллельной обработки.

Чтобы понять, как это реализовать, приведу еще один короткий пример без лишних деталей. Задача – погрузить всю нашу логику обработки в пул воркеров, чтобы сделать процессинг параллельным, и вот как это выглядит:
Давайте разберемся, как работает и что делает данный код:
Готово, все летает! «А можно еще быстрее?» — спросите вы. Ответ однозначный – легко! Давайте воспользуемся штатными возможностями партиционирования топиков в Kafka.
Напомню, разбивка топика по разделам (партициям) – это основной механизм параллелизма в Apache Kafka, который позволяет линейно масштабировать нагрузку на консьюмеров. Ключевыми моментами этой концепции являются следующие:
Итак, добавим партиций (3 шт) для нашего топика raw_events и на каждую партицию поставим отдельный экземпляр консьюмера (тоже 3 шт). Поскольку количество партиций можно динамически увеличивать, то имеем бесконечный горизонт масштабирования! Что может быть прекраснее?
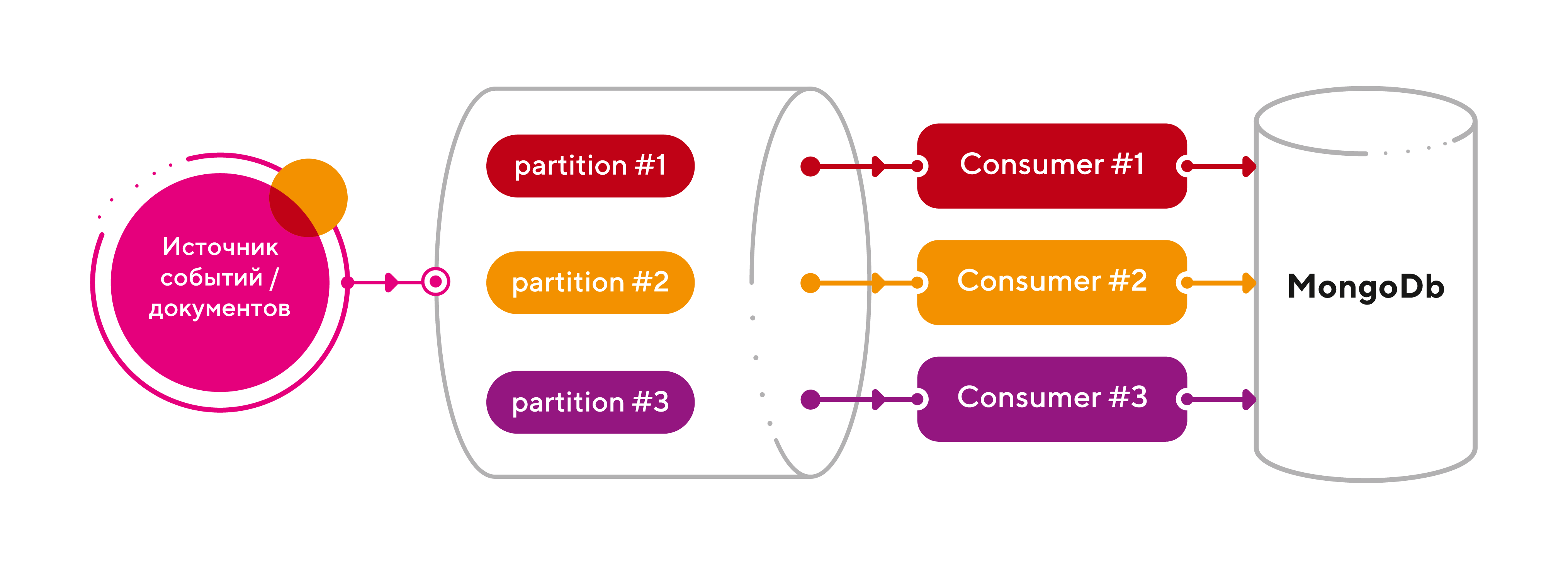
Подведем итоги: мы получили отличную архитектуру для highload системы, затратив на это 5 минут времени. При этом, нам не пришлось менять любимый язык программирования, а значит, жертвовать гибкостью и скоростью разработки.
Я, технический директор компании STM Labs, Андрей Комягин, за несколько минут смогу переубедить всех скептиков и доказать обратное.
Недавно в мире IT случилось важное событие — институт IEEE опубликовал список самых востребованных языков программирования. Корону победителя с гордостью примерил Python. Это вполне закономерный результат, поскольку Python — бесплатный язык программирования с открытым исходным кодом и удобными структурами данных. Он запускается на любых ОС и поддерживает множество сервисов, сред разработки и фреймворков. К тому же, он подходит для новичков, и его просто выучить.
Если и этого мало, то давайте не будем забывать, что именно Python стал основой для создания веб-сервисов и мобильных приложений, без которых мы не смогли бы делать ряд важных вещей ежедневно. Например, не смогли бы смотреть ролики на YouTube или следить за жизнью знаменитостей в Instagram, заказывать такси в Uber и юзать такие площадки, как Quora, Pinterest, Blender, Inkscape и Autodesk. Все они написаны на Python и, пожалуй, уже даже этот факт возводит его в «лик святых» языков программирования.
По этим и многим другим причинам мы привыкли, что в области машинного обучения (ML) и больших данных (Big Data) Python – это уже стандарт де-факто. Но, как только мы начинаем говорить о highload системах, тут же «всплывает» устоявшийся стереотип о том, что высоконагруженные системы надо делать на чем-то быстром. Чаще всего в таких случаях я слышу фразу: «Лучше взять сишечку! (семейство языков программирования С/C++) или, на худой конец, Java или C#». И когда я привожу в пример YouTube и говорю, что мы успешно делаем highload системы на Python, некоторые мои собеседники морщатся от удивления…
Давайте вместе ломать стереотип: на конкретном примере я расскажу, как правильно использовать Python в режиме Fast and Furious и построить на нем крутую архитектуру highload системы!
Python vs пессимисты
В качестве задачи рассмотрим систему обработки событий или процессинга документов. Архитектура у них плюс-минус одинаковая и имеет следующий pipeline (ETL):
Для начала, решим задачу в лоб:
1. В качестве брокера возьмем Kafka;
2. В обработчике реализуем линейный процессинг сообщений из очереди на базе класса Kafka Consumer из библиотеки Kafka-Python;
3. Результат обработки запишем в СУБД MongoDb.
Имеем следующую схему:
Приведу небольшой code snippet, как это реализовать:
from kafka import KafkaConsumer
from pymongo import MongoClient
from json import loads
# создаем консьюмера
consumer = KafkaConsumer(
"raw_events",
bootstrap_servers=["localhost:9092"],
auto_offset_reset="earliest",
enable_auto_commit=True,
group_id="my-group",
value_deserializer=lambda x: loads(x.decode("utf-8")),
)
# открываем соединение к MongoDb
# получаем доступ к нашей коллекции событий – processed_events
client = MongoClient("localhost:27017")
collection = client.processed_events
# читаем из топика и пишем в базу
for message in consumer:
doc = message.value
collection.insert_one(doc)
Работает, но процессинг очереди идет слишком медленно! Пессимисты уже кричат: «Все пропало! Что же нам теперь делать?». Мое решение простое и лаконичное – использовать процессный пул для параллельной обработки.
Чтобы понять, как это реализовать, приведу еще один короткий пример без лишних деталей. Задача – погрузить всю нашу логику обработки в пул воркеров, чтобы сделать процессинг параллельным, и вот как это выглядит:
from multiprocessing import Pool
def processing_func(msg):
# пишем тут в БД
store_data(msg)
# создаем пул воркеров из 16 процессов (лучше число ядер CPU х 2)
pool = Pool(16)
for message in consumer:
pool.apply_async(processing_func, (message,))
Давайте разберемся, как работает и что делает данный код:
- Создает пул из 16 процессов
- Читает очередь, но весь процессинг самих сообщений отдается воркерам из пула с помощью метода самого пула — apply_async
- Метод apply_async принимает на вход функцию, которая, собственно, и делает весь процессинг. В нашем случае — пишет данные в БД.
Готово, все летает! «А можно еще быстрее?» — спросите вы. Ответ однозначный – легко! Давайте воспользуемся штатными возможностями партиционирования топиков в Kafka.
Напомню, разбивка топика по разделам (партициям) – это основной механизм параллелизма в Apache Kafka, который позволяет линейно масштабировать нагрузку на консьюмеров. Ключевыми моментами этой концепции являются следующие:
- каждый топик может иметь 1 или больше разделов, распараллеленных на разные узлы кластера (брокеры), чтобы сразу несколько консьюмеров могли считывать данные из одного топика одновременно;
- если число консьюмеров меньше числа разделов, то один консьюмер получает сообщения из нескольких разделов;
- если консьюмеров больше, чем разделов, то некоторые консьюмеры не получат никаких сообщений и будут простаивать;
- для повышения надежности и доступности данных в кластере Kafka, разделы могут иметь копии (реплики), число которых задается коэффициентом репликации (replication factor). Он показывает, на сколько брокеров-последователей (follower) будут скопированы данные с ведущего-лидера (leader);
- число разделов и коэффициент репликации можно настроить для всего кластера или для каждого топика отдельно.
Итак, добавим партиций (3 шт) для нашего топика raw_events и на каждую партицию поставим отдельный экземпляр консьюмера (тоже 3 шт). Поскольку количество партиций можно динамически увеличивать, то имеем бесконечный горизонт масштабирования! Что может быть прекраснее?
Подведем итоги: мы получили отличную архитектуру для highload системы, затратив на это 5 минут времени. При этом, нам не пришлось менять любимый язык программирования, а значит, жертвовать гибкостью и скоростью разработки.


")