Что такое Big O нотация?
Обозначение Big O нотация (или просто Big O) — это способ оценки относительной производительности структуры данных или алгоритма, обычно по двум осям: времени и пространству.
Доминирующие операции
Способ, которым мы определяем Big O алгоритмов, заключается в том, чтобы посмотреть на худшую производительность в его доминирующих операциях.
Постоянное время - O(1)
func constantTime(_ n: Int) -> Int {
let result = n * n
return result
}Алгоритмы, без цикла(например: for-in) или алгоритмы которые Ёъпросто возвращают результат какого-то простого вычисления, имеют «постоянное время» или «O(1)». Это означает, что эти операции очень быстрые.
Линейное время - O(n)
func linearTime(_ A: [Int]) -> Int {
for i in 0..<A.count {
if A[i] == 0 {
return 0
}
}
return 1
}Как только производительность алгоритма становится зависимой от размера передаваемых входных данных, мы больше не можем говорить, что он имеет «постоянное время». Если время, необходимое для обработки, представляет собой прямую линию, мы называем это «линейным временем». Это означает, что время, которое требуется, прямо пропорционально размеру ввода.
Несмотря на то, что цикл может вернуться немедленно, если первое значение массива равно нулю, при оценке Big O мы всегда ищем производительность в худшем случае. Это все еще O(n) даже с лучшим случаем O(1).
Логарифмическое время - O(log n)
func logarithmicTime(_ N: Int) -> Int {
var n = N
var result = 0
while n > 1 {
n /= 2
result += 1
}
return result
}Такие алгоритмы, как Двоичные Деревья Поиска (Бинарные Деревья Поиска), очень быстры, потому что они половинят свои результаты каждый раз, когда ищут результат. Это деление пополам является логарифмическим, которое мы обозначаем как "O(log n)".
Квадратичное время - O(n^2)
func quadratic(_ n: Int) -> Int {
var result = 0
for i in 0..<n {
for j in i..<n {
result += 1
print("\(i) \(j)")
}
}
return result
}Когда вы встраиваете один цикл for-in в другой, вы получаете квадратичный эффект, применяемый к вашему алгоритму, который может сильно замедлить работу. Это нормально для получения правильного ответа, просто они не самые производительные.
График, представленный ниже поможет лучше разобраться в производительности алгоритмов
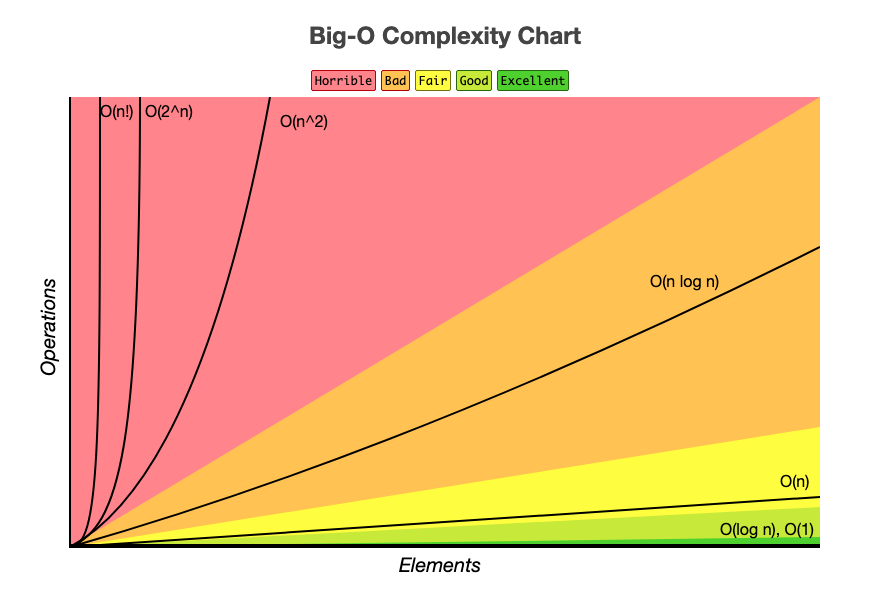
Алгоритмы, попадающие в нижний правый угол (O(1), O(logn)) считаются очень хорошими. Линейное время O(n) неплохо. Но все, что выше этого, не считается очень производительным(быстрым), например, O(n^2).
Затраты памяти
До сих пор все, что мы рассматривали, имело отношение ко времени. И когда мы говорим о Big O, мы обычно имеем в виду временную сложность. Но есть и другая сторона медали - память. Мы оцениваем затраты памяти также так же, как и время, в том смысле, что при оценке затрат памяти алгоритма мы смотрим, сколько объявлено переменных и их относительная стоимость. Простые объявления переменных — O(1). В то время как массивы и другие структуры данных относительного размера или O(n).
Меняем память на время
Одно из самых больших улучшений, которые мы можем сделать в алгоритмах, — это поменять память на время. Возьмем, к примеру, типичный вопрос на собеседовании:
Имея два массива, создайте функцию, которая позволит пользователю узнать, содержат ли эти два массива какие-либо общие элементы.
Грубым способом ответить на этот вопрос было бы перебрать каждый элемент в обоих массивах, пока не будет найдено совпадение. Очень эффективно с точки зрения памяти. Медленно с точки зрения времени O(n^2).
// Простое(грубое) решение O(n^2)
func commonItemsBrute(_ A: [Int], _ B: [Int]) -> Bool {
for i in 0..<A.count {
for j in 0..<B.count {
if A[i] == B[j] {
return true
}
}
}
return false
}
//проверка
commonItemsBrute([1, 2, 3], [4, 5, 6])
commonItemsBrute([1, 2, 3], [3, 5, 6])
С другой стороны, если пожертвовать памятью, мы могли бы улучшить время, если бы создали хэш-карту одного массива, а затем использовали ее для быстрого поиска ответа в другом.
// Конвертируем в хэш и поищем по индексу
func commonItemsHash(_ A: [Int], _ B: [Int]) -> Bool {
// Используем цикл но уже не вложенный в другой цикл,
//как было ранее - O(2n) vs O(n^2)
var hashA = [Int: Bool]()
for a in A { // O(n)
hashA[a] = true
}
//Теперь посмотрим в хэше, есть ли там элементы B.
for b in B {
if hashA[b] == true {
return true
}
}
return false
}
commonItemsHash([1, 2, 3], [4, 5, 6])
commonItemsHash([1, 2, 3], [3, 5, 6])Вот пример такого обмена памяти на время. Первый вариант не требовал дополнительного места, но с точки зрения времени это было очень медленно. Заняв немного памяти (дополнительная хэш-карта), мы выиграли много времени и в результате получили гораздо более быстрый алгоритм (O(n)).




