

Вступительное слово
Я выступил с этим докладом на английском языке на конференции GopherCon Russia 2019 в Москве и на русском — на митапе в Нижнем Новгороде. Речь в нём идёт о bitmap-индексе — менее распространённом, чем B-tree, но не менее интересном. Делюсь записью выступления на конференции на английском и текстовой расшифровкой на русском.
Мы рассмотрим, как устроен bitmap-индекс, когда он лучше, когда — хуже других индексов и в каких случаях он значительно быстрее них; увидим, в каких популярных СУБД уже есть bitmap-индексы; попробуем написать свой на Go. А «на десерт» мы воспользуемся готовыми библиотеками, чтобы создать свою супербыструю специализированную базу данных.
Очень надеюсь, что мои труды окажутся для вас полезными и интересными. Поехали!
Введение
http://bit.ly/bitmapindexes
https://github.com/mkevac/gopherconrussia2019
Привет всем! Сейчас шесть вечера, мы все суперуставшие. Замечательное время, чтобы поговорить о скучной теории индексов баз данных, да? Не волнуйтесь, у меня будет пара строчек исходного кода тут и там. :-)
Если без шуток, то доклад переполнен информацией, а у нас не так много времени. Поэтому давайте начинать.

Сегодня я буду говорить о следующем:
- что такое индексы;
- что такое bitmap-индекс;
- где он используется и где он НЕ используется и почему;
- простая имплементация на Go и немного борьбы с компилятором;
- чуть менее простая, но гораздо более производительная имплементацию на Go-ассемблере;
- «проблемы» bitmap-индексов;
- существующие реализации.
Так что такое индексы?
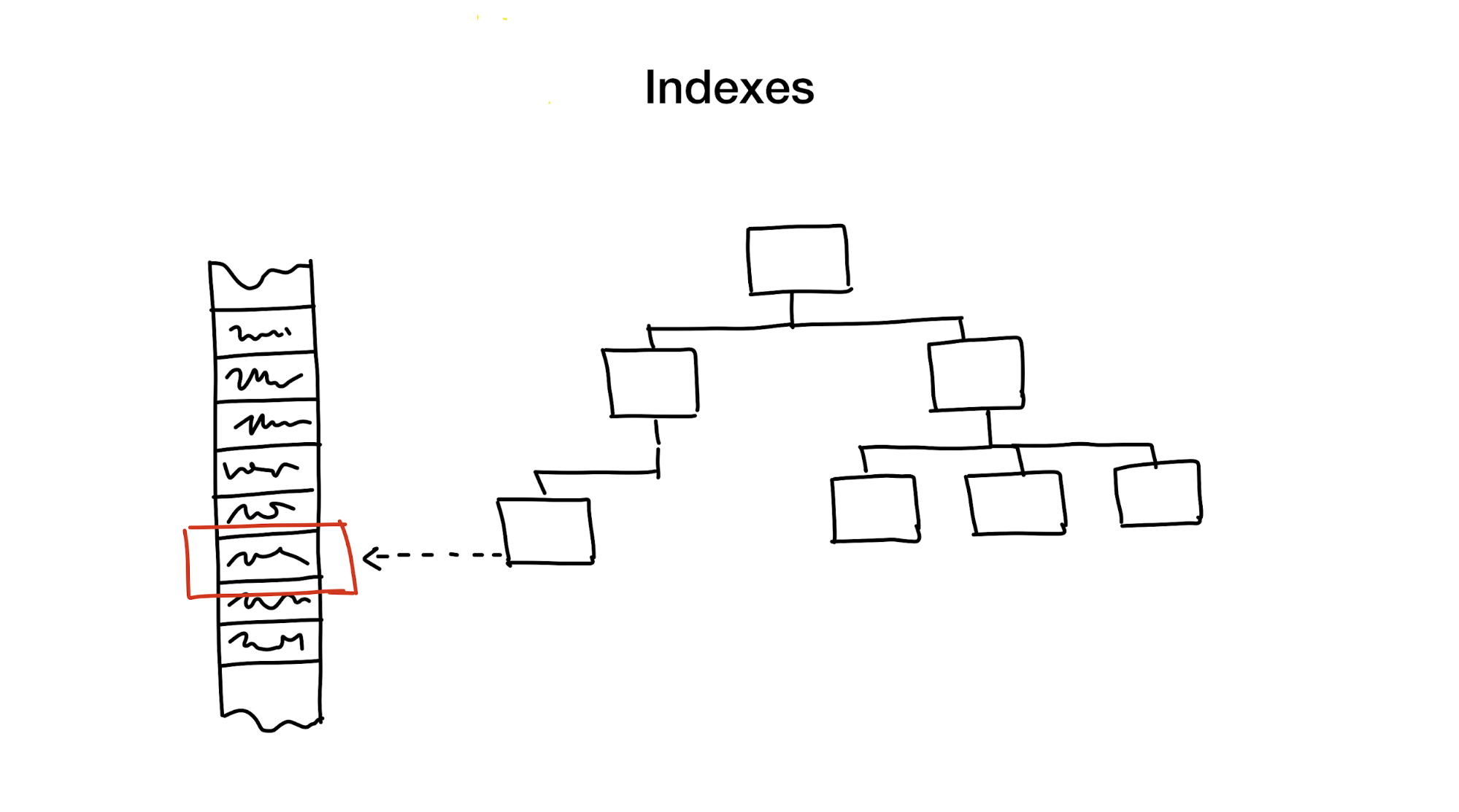
Индекс — это отдельная структура данных, которую мы держим и обновляем в дополнение к основным данным. Она используется для ускорения поиска. Без индексов поиск требовал бы полного прохода по данным (процесс, называемый full scan), и этот процесс имеет линейную алгоритмическую сложность. Но базы данных обычно содержат огромное количество данных и линейная сложность — это слишком медленно. В идеале нам бы получить логарифмическую или константную.
Это огромная сложная тема, переполненная тонкостями и компромиссами, но, посмотрев на десятки лет разработки и исследования различных баз данных, я готов утверждать, что существует всего несколько широко используемых подходов к созданию индексов БД.

Первый подход заключается в иерархичном уменьшении области поиска, разделении области поиска на более мелкие части.
Обычно мы делаем это, используя разного рода деревья. Примером может служить большая коробка с материалами в вашем шкафу, в которой находятся более мелкие коробки с материалами, разделёнными по различным тематикам. Если вам нужны материалы, то вы наверняка будете искать их в коробке с надписью «Материалы», а не в той, на которой написано «Печеньки», так ведь?
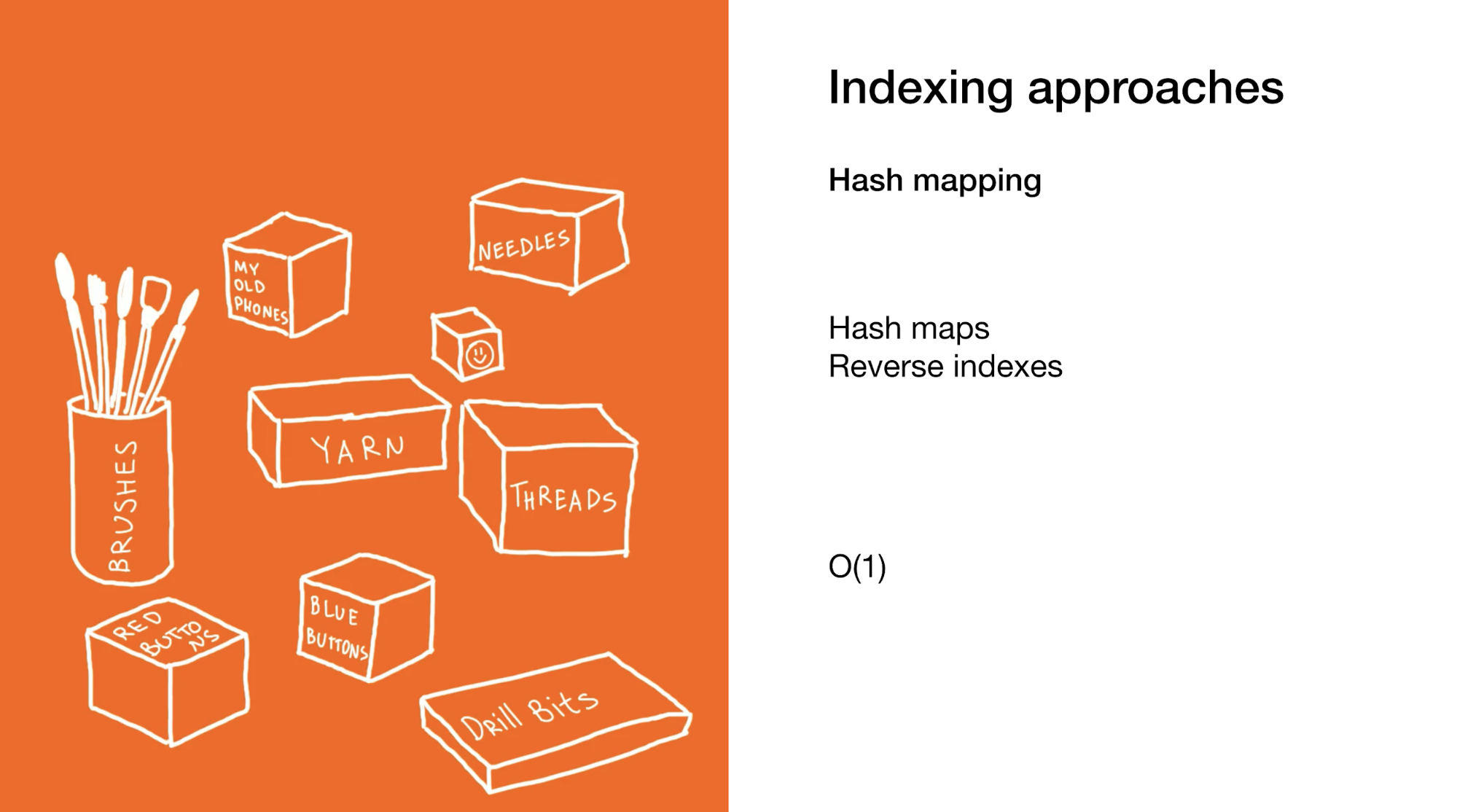
Второй подход заключается в том, чтобы сразу выделить нужный элемент или группу элементов. Мы делаем это в hash maps или в обратных индексах. Использование hash maps очень похоже на предыдущий пример, только вместо коробки с коробками у вас в шкафу куча маленьких коробок с финальными предметами.

Третий подход — избавиться от необходимости поиска. Это мы делаем с помощью Bloom-фильтров или cuckoo-фильтров. Первые дают ответ мгновенно, избавляя вас от необходимости осуществлять поиск.
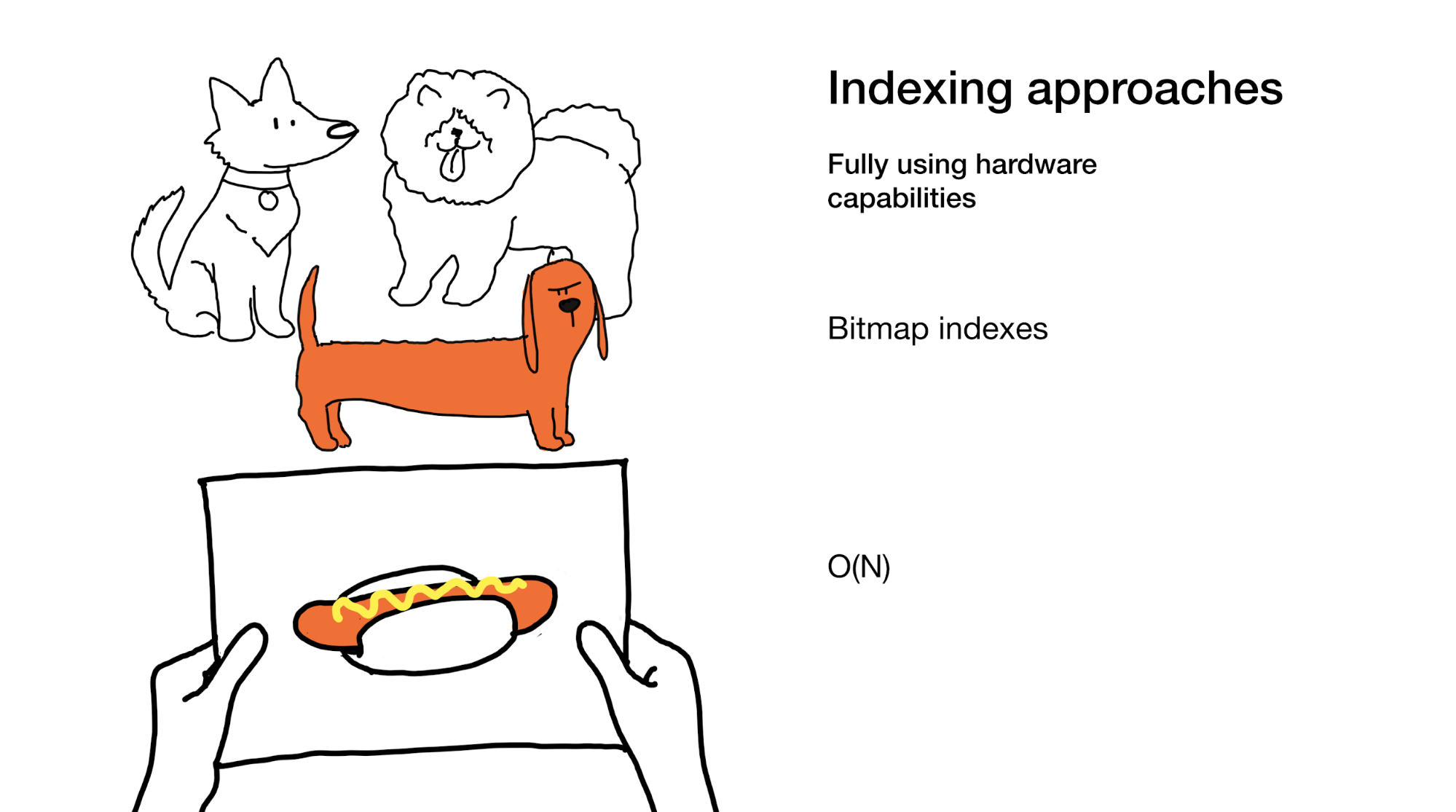
Последний подход заключается в полноценном использовании всех мощностей, которые даёт нам современное железо. Именно это мы делаем в bitmap-индексах. Да, при их использовании нам иногда требуется пройти по всему индексу, но делаем мы это суперэффективно.
Как я уже сказал, тема индексов БД обширна и переполнена компромиссами. Это значит, что иногда мы можем использовать несколько подходов одновременно: если нам нужно ещё сильнее ускорить поиск или если необходимо покрыть все возможные типы поиска.
Сегодня я расскажу о наименее известном подходе из названных — о bitmap-индексах.
Кто я такой, чтобы говорить на эту тему?
Я работаю тимлидом в Badoo (возможно, вы лучше знаете другой наш продукт — Bumble). У нас уже более 400 млн пользователей по всему миру и много фич, которые занимаются тем, что подбирают для них лучшую пару. Делаем мы это с помощью кастомных сервисов, использующих в том числе и bitmap-индексы.
Так что же такое bitmap-индекс?
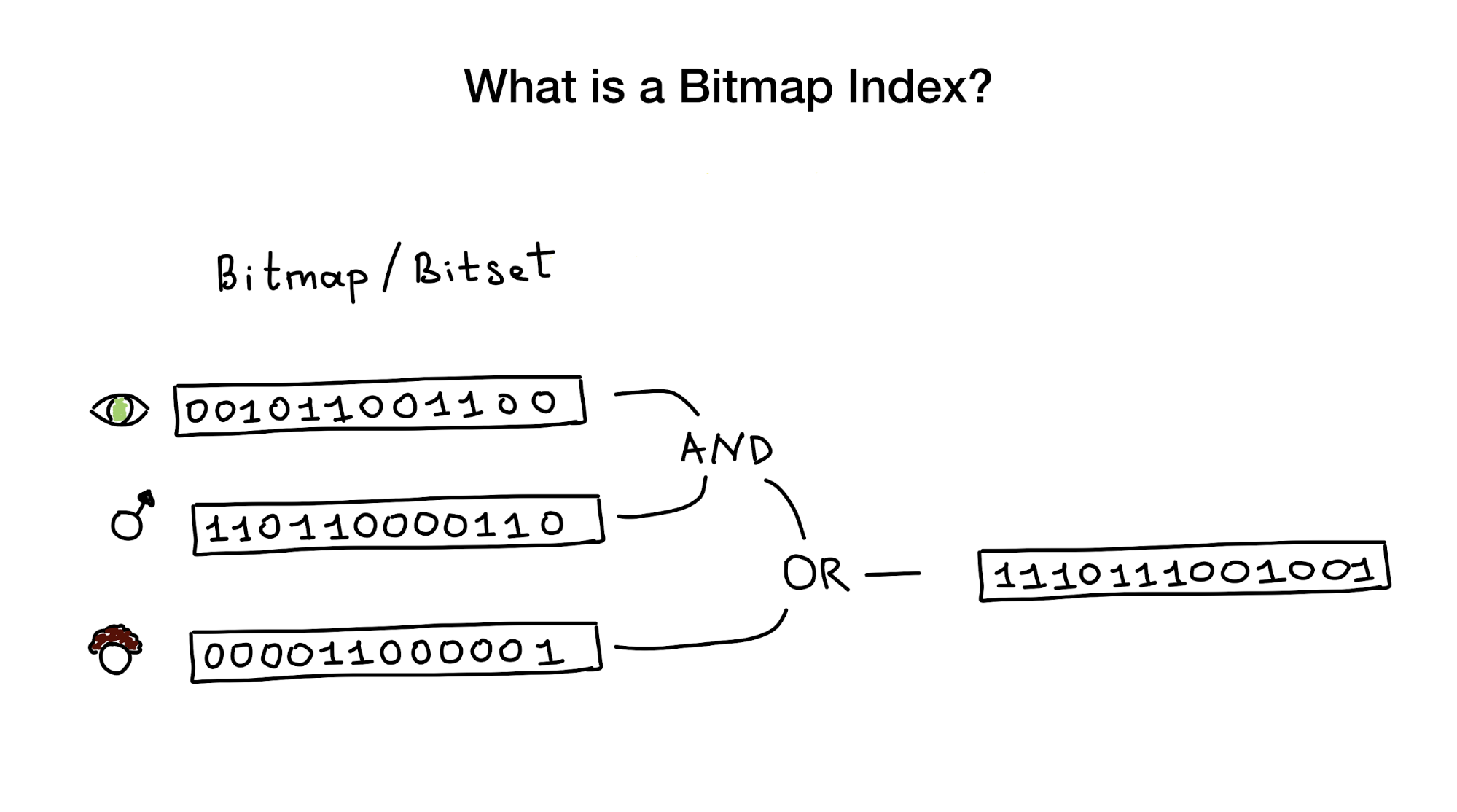
Bitmap-индексы, как подсказывает нам название, используют битмапы или битсеты для того, чтобы заимплементить поисковый индекс. С высоты птичьего полета этот индекс состоит из одного или нескольких таких битмапов, представляющих какие-либо сущности (типа людей) и их свойства или параметры (возраст, цвет глаз и т. д.), и из алгоритма, использующего битовые операции (AND, OR, NOT) для ответа на поисковый запрос.

Нам говорят что bitmap-индексы лучше всего подходят и очень производительны для случаев, когда есть поиск, объединяющий запросы по многим столбцам, имеющим малую кардинальность (представьте «цвет глаз» или «семейное положение» против чего-то типа «расстояние от центра города»). Но позже я покажу, что они прекрасно работают и в случае со столбцами с высокой кардинальностью.
Рассмотрим простейший пример bitmap-индекса.

Представьте, что у нас есть список московских ресторанов с бинарными свойствами вроде этих:
- рядом с метро (near metro);
- есть частная парковка (has private parking);
- есть веранда (has terrace);
- можно забронировать столик (accepts reservations);
- подходит для вегетарианцев (vegan friendly);
- дорогой (expensive).
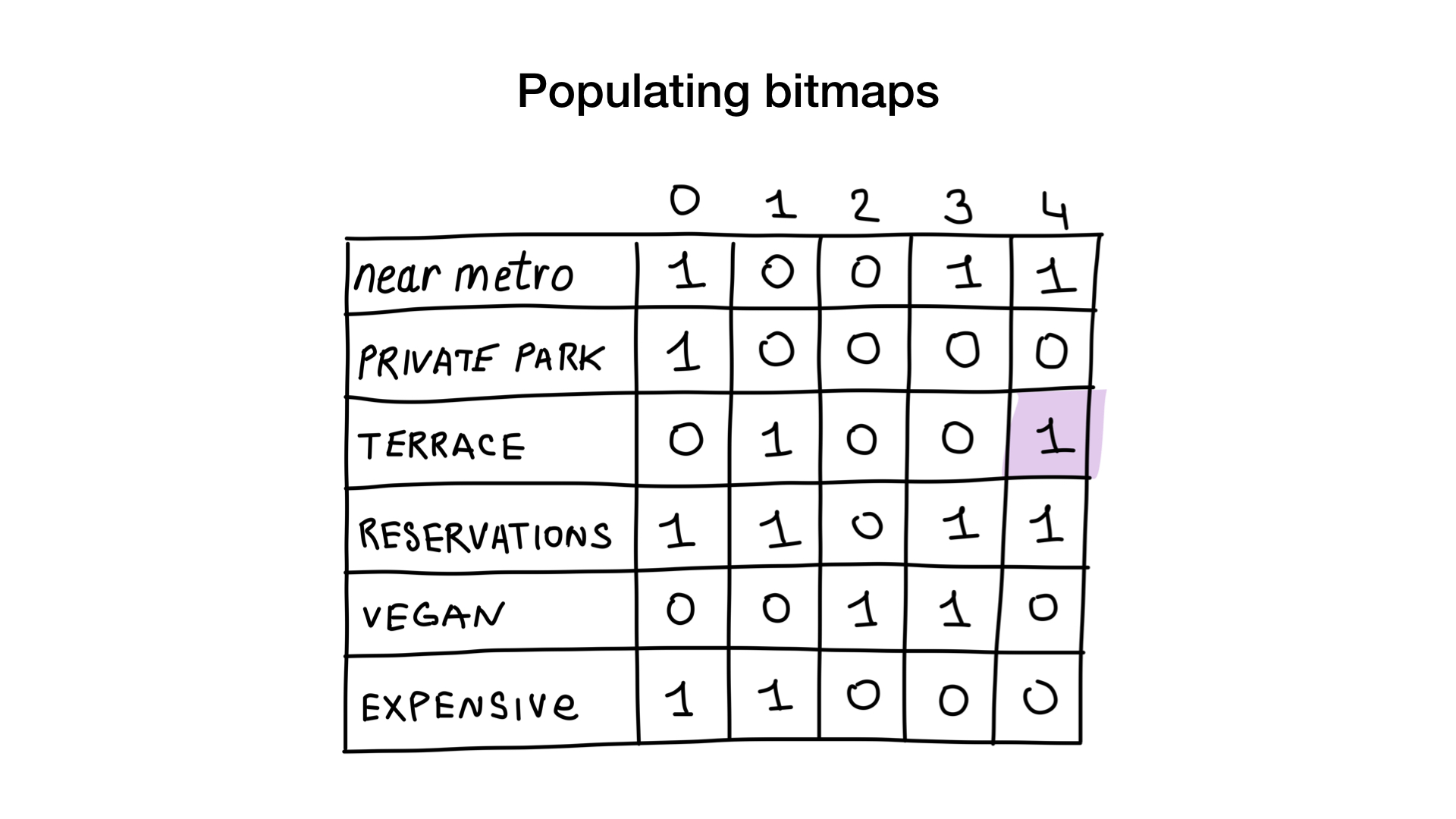
Давайте дадим каждому ресторану порядковый номер начиная с 0 и выделим память под 6 битмапов (один для каждой характеристики). Затем мы заполним эти битмапы в зависимости от того, обладает ресторан данным свойством или нет. Если у ресторана 4 есть веранда, то бит №4 в битмапе «есть веранда» будет выставлен в 1 (если веранды нет, то в 0).

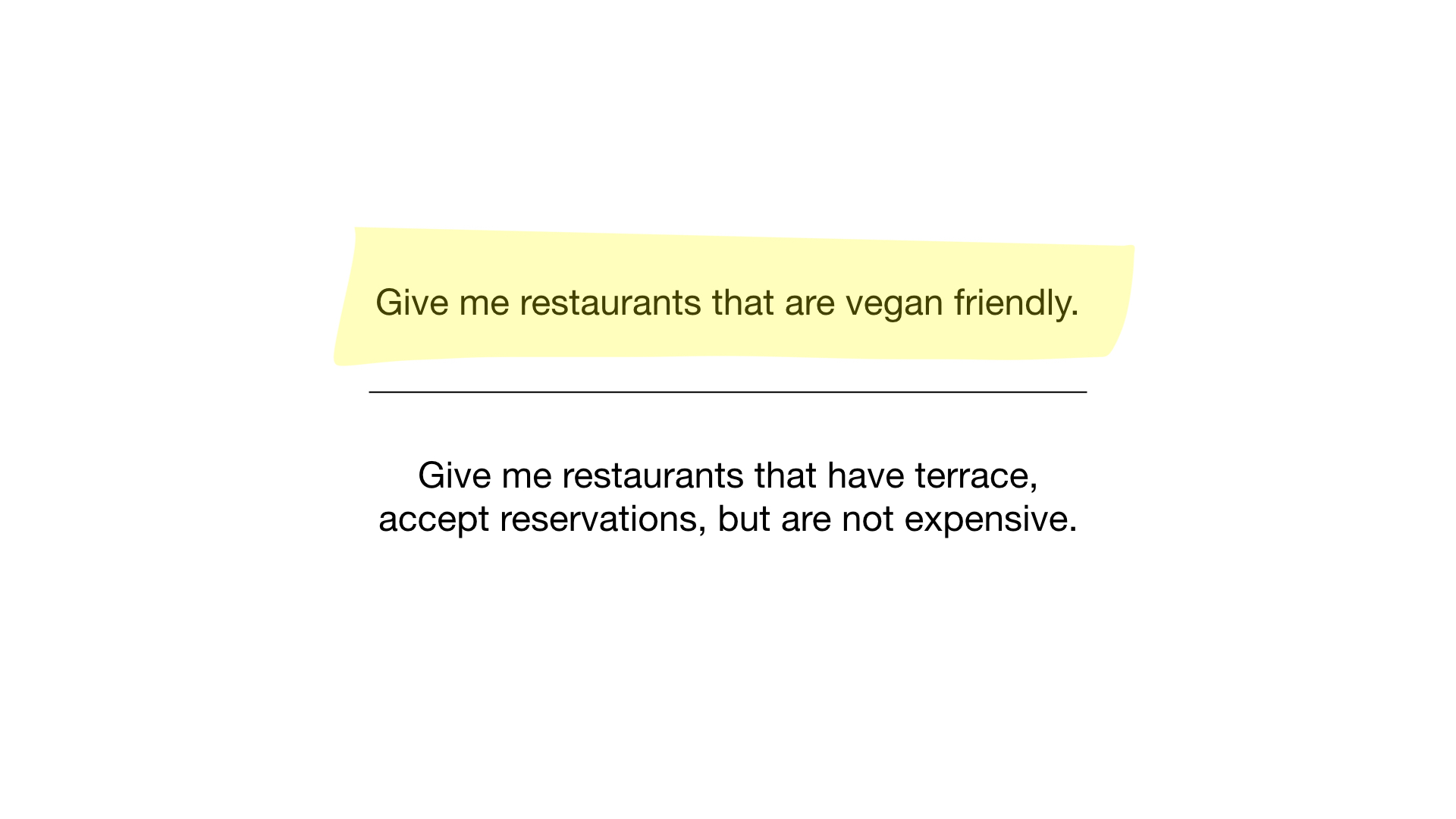
Теперь у нас есть самый простой bitmap-индекс из возможных, и мы можем использовать его для ответа на запросы вроде:
- «Покажи мне рестораны, подходящие для вегетарианцев»;
- «Покажи мне недорогие рестораны с верандой, где можно забронировать столик».
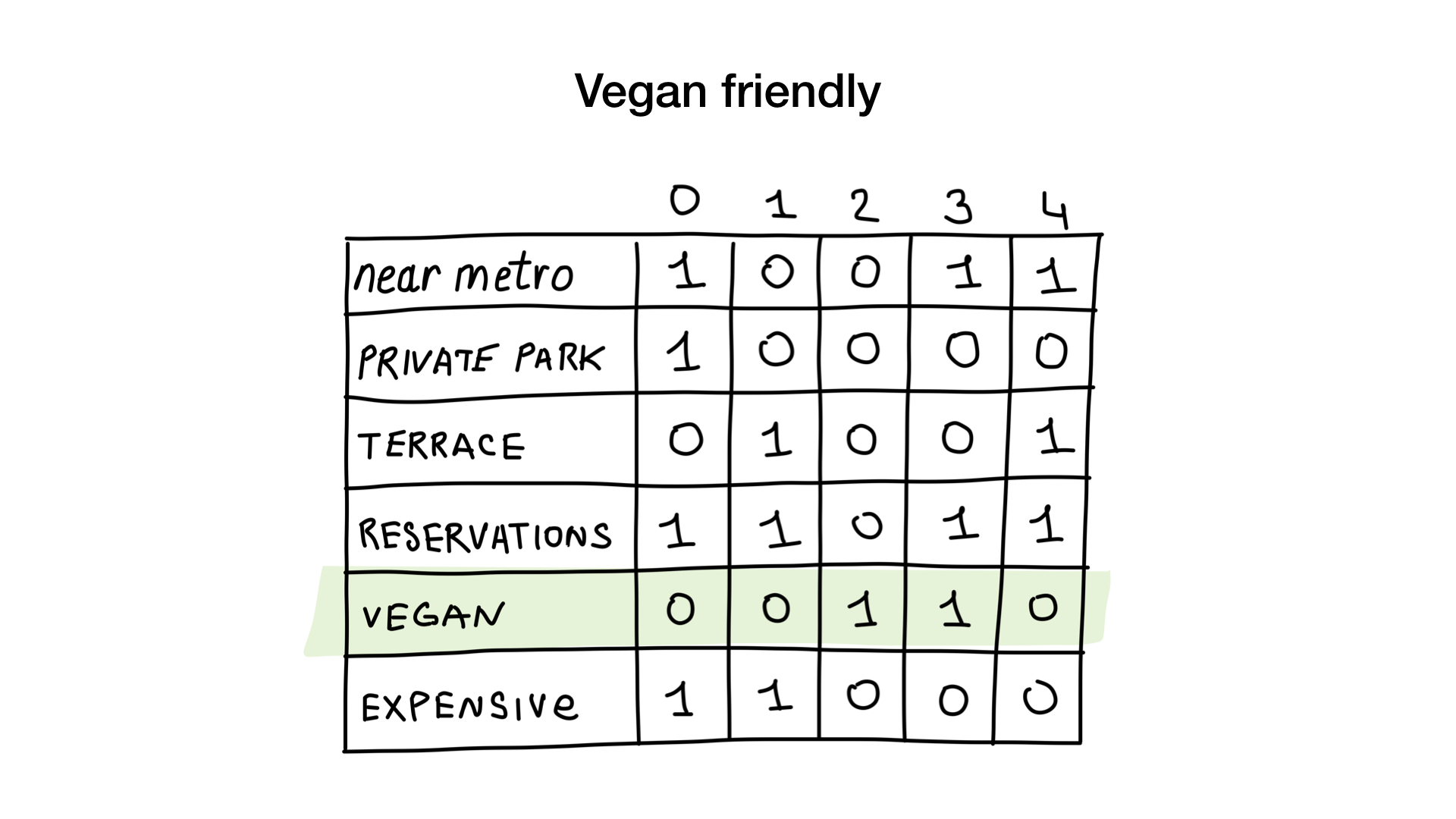
Как? Давайте посмотрим. Первый запрос очень простой. Всё, что нам нужно, — это взять битмап «подходит для вегетарианцев» и превратить его в список ресторанов, чьи биты выставлены.
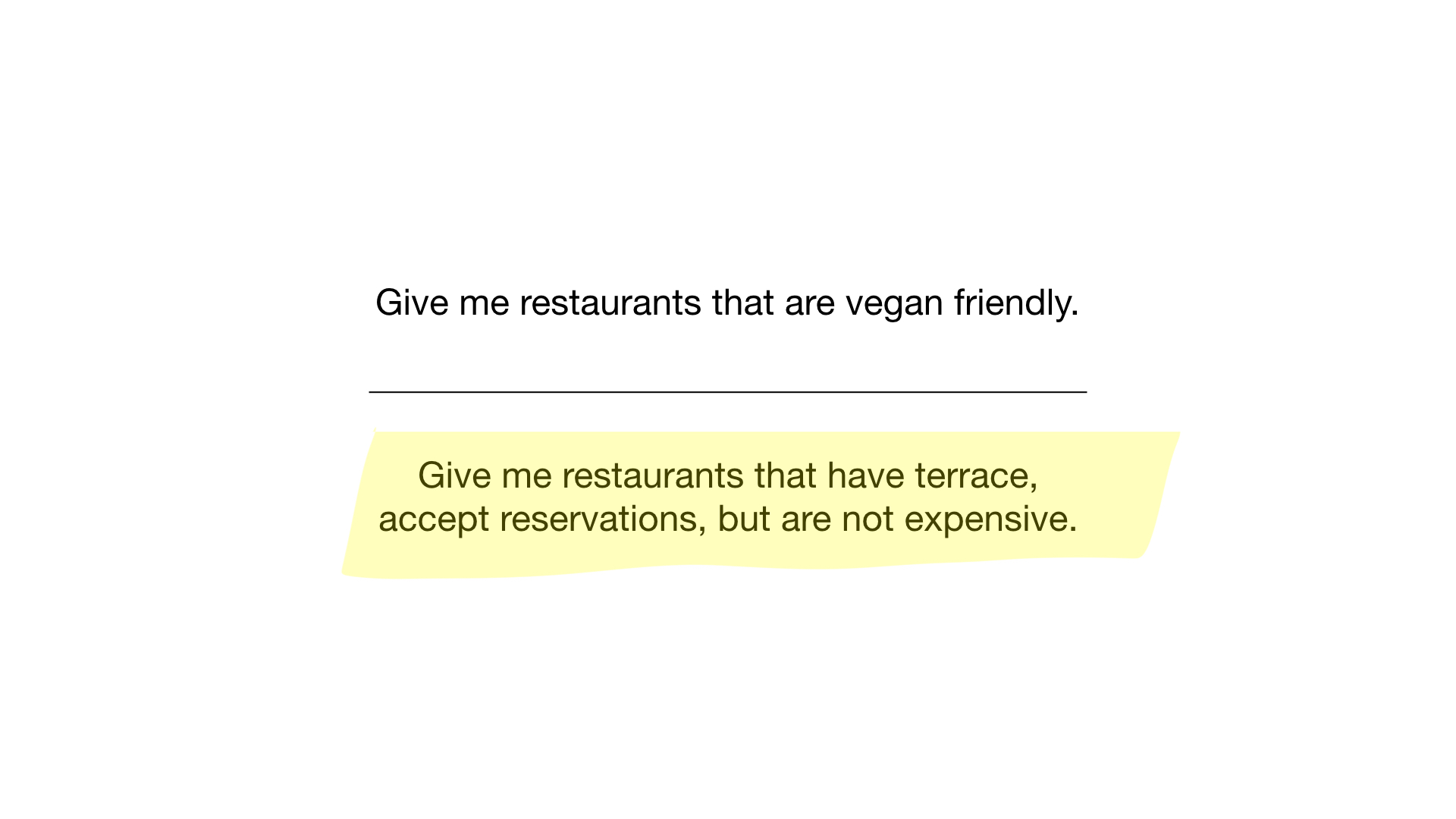

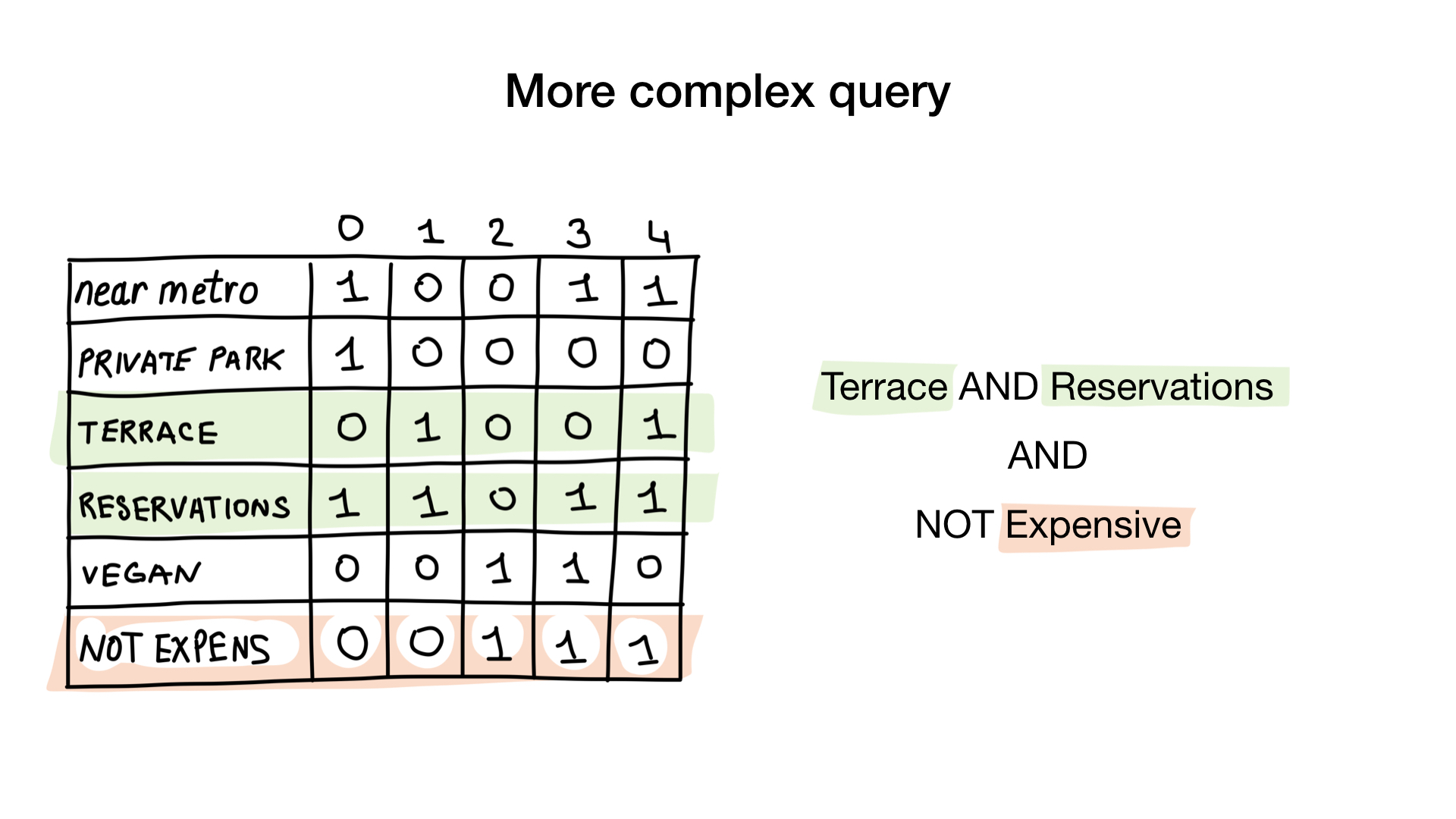
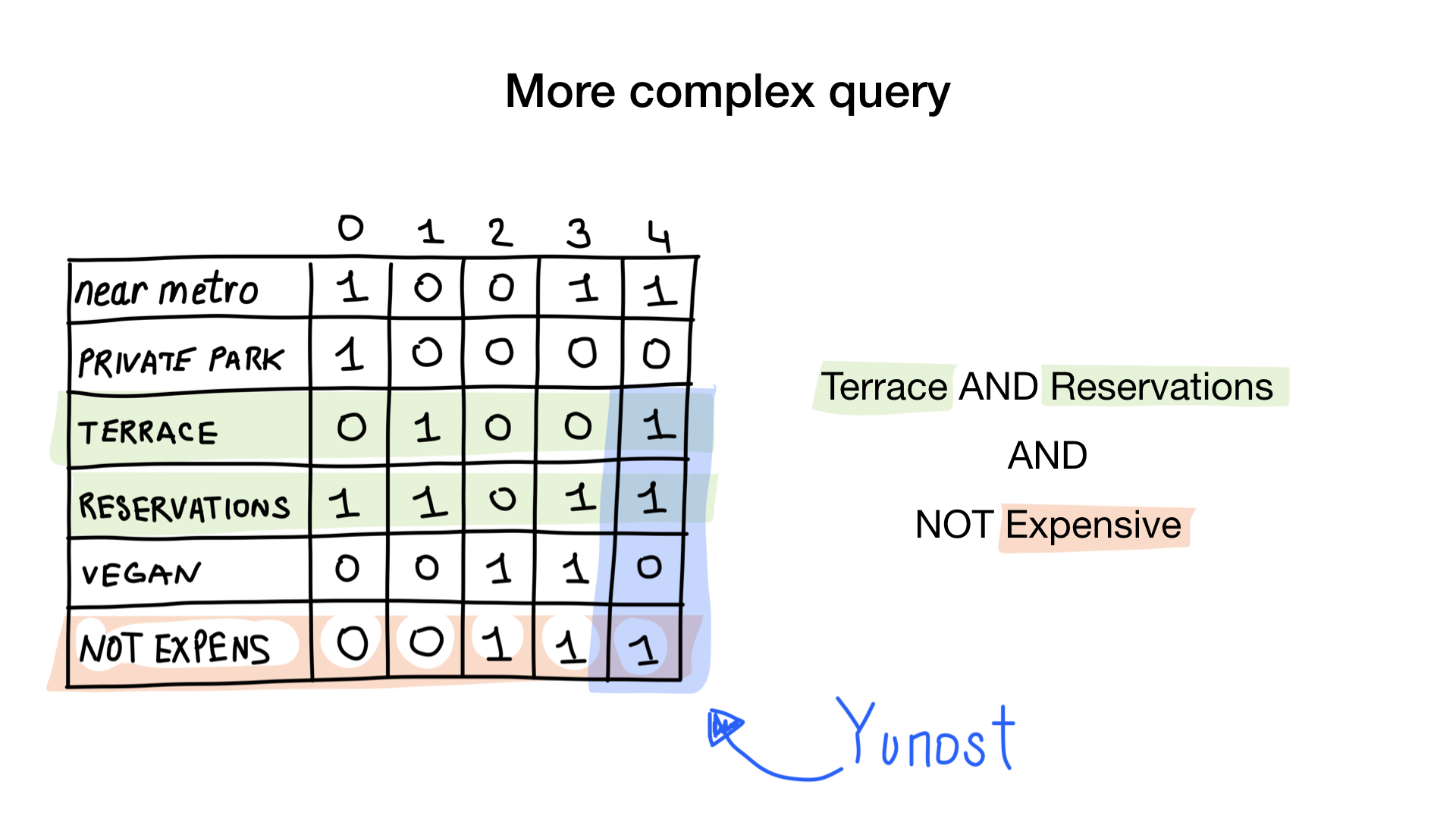
Второй запрос немного сложнее. Нам необходимо использовать битовую операцию NOT на битмапе «дорогой», чтобы получить список недорогих ресторанов, затем за-AND-ить его с битмапом «можно забронировать столик» и за-AND-ить результат с битмапом «есть веранда». Результирующий битмап будет содержать список заведений, которые соответствуют всем нашим критериям. В данном примере это только ресторан «Юность».
Тут очень много теории, но не волнуйтесь, мы увидим код очень скоро.
Где используются bitmap-индексы?

Если вы «загуглите» bitmap-индексы, 90% ответов будут так или иначе связаны с Oracle DB. Но остальные СУБД тоже наверняка поддерживают такую крутую штуку, правда? Не совсем.
Пройдёмся по списку основных подозреваемых.

MySQL ещё не поддерживает bitmap-индексы, но есть Proposal с предложением добавить эту опцию (https://dev.mysql.com/worklog/task/?id=1524).
PostgreSQL не поддерживает bitmap-индексы, но использует простые битмапы и битовые операции для объединения результатов поиска по нескольким другим индексам.
У Tarantool есть bitset-индексы, он поддерживает простой поиск по ним.
У Redis есть простые битовые поля (https://redis.io/commands/bitfield) без возможности поиска по ним.
MongoDB ещё не поддерживает bitmap-индексы, но также есть Proposal с предложением добавить эту опцию https://jira.mongodb.org/browse/SERVER-1723
Elasticsearch использует битмапы внутри (https://www.elastic.co/blog/frame-of-reference-and-roaring-bitmaps).

- Но в нашем доме появился новый сосед: Pilosa. Это новая нереляционная база данных, написанная на Go. Она содержит только bitmap-индексы и базирует всё на них. Мы поговорим о ней чуть позже.
Имплементация на Go
Но почему bitmap-индексы так редко используются? Прежде чем ответить на этот вопрос, я хотел бы продемонстрировать вам имплементацию очень простого bitmap-индекса на Go.

Битмапы, по сути, представлены просто кусками данных. В Go давайте для этого воспользуемся слайсами байтов.
У нас есть один битмап на одну ресторанную характеристику, и каждый бит в битмапе говорит о том, есть у конкретного ресторана данное свойство или нет.

Нам понадобятся две вспомогательные функции. Одна будет использоваться для заполнения наших битмапов рандомными данными. Рандомными, но с определённой вероятностью того, что ресторан обладает каждым свойством. Например, я считаю, что в Москве очень мало ресторанов, в которых нельзя забронировать столик, и мне кажется, что примерно 20% заведений подходят для вегетарианцев.
Вторая функция будет преобразовывать битмап в список ресторанов.


Чтобы ответить на запрос «Покажи мне недорогие рестораны, у которых есть веранда и в которых можно забронировать столик», нам понадобятся две битовые операции: NOT и AND.
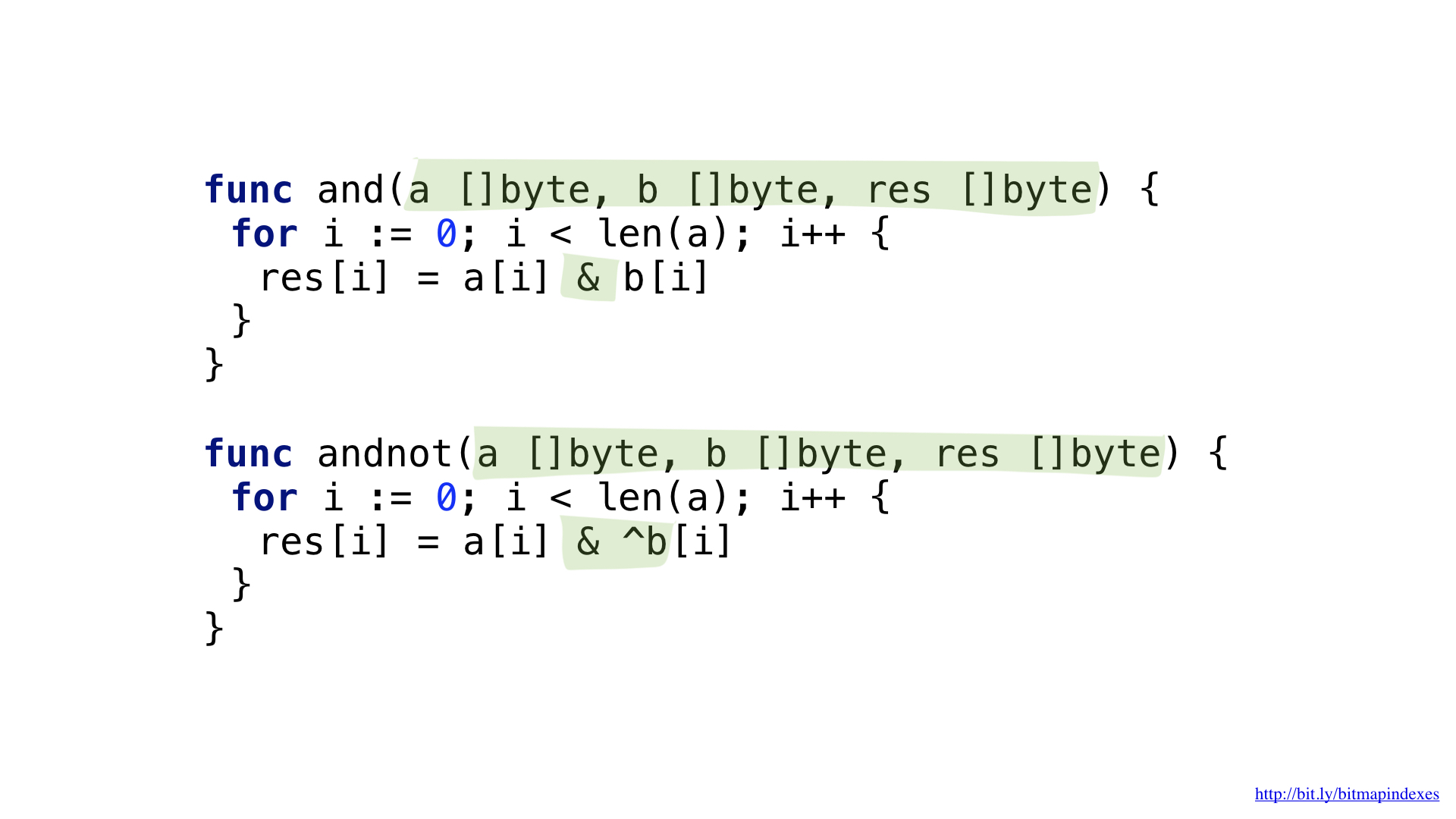
Мы можем немного упростить наш код, воспользовавшись более сложной операцией AND NOT.
У нас есть функции для каждой из этих операций. Обе они идут по слайсам, берут соответствующие элементы из каждого, объединяют их битовой операцией и кладут результат в результирующий слайс.
И вот теперь мы можем воспользоваться нашими битмапами и функциями для ответа на поисковый запрос.

Производительность не такая высокая, даже несмотря на то, что функции очень простые и мы прилично сэкономили на том, что не возвращали новый результирующий слайс при каждом вызове функции.
Попрофилировав немного с pprof, я заметил, что компилятор Go пропустил одну очень простую, но очень важную оптимизацию: function inlining.
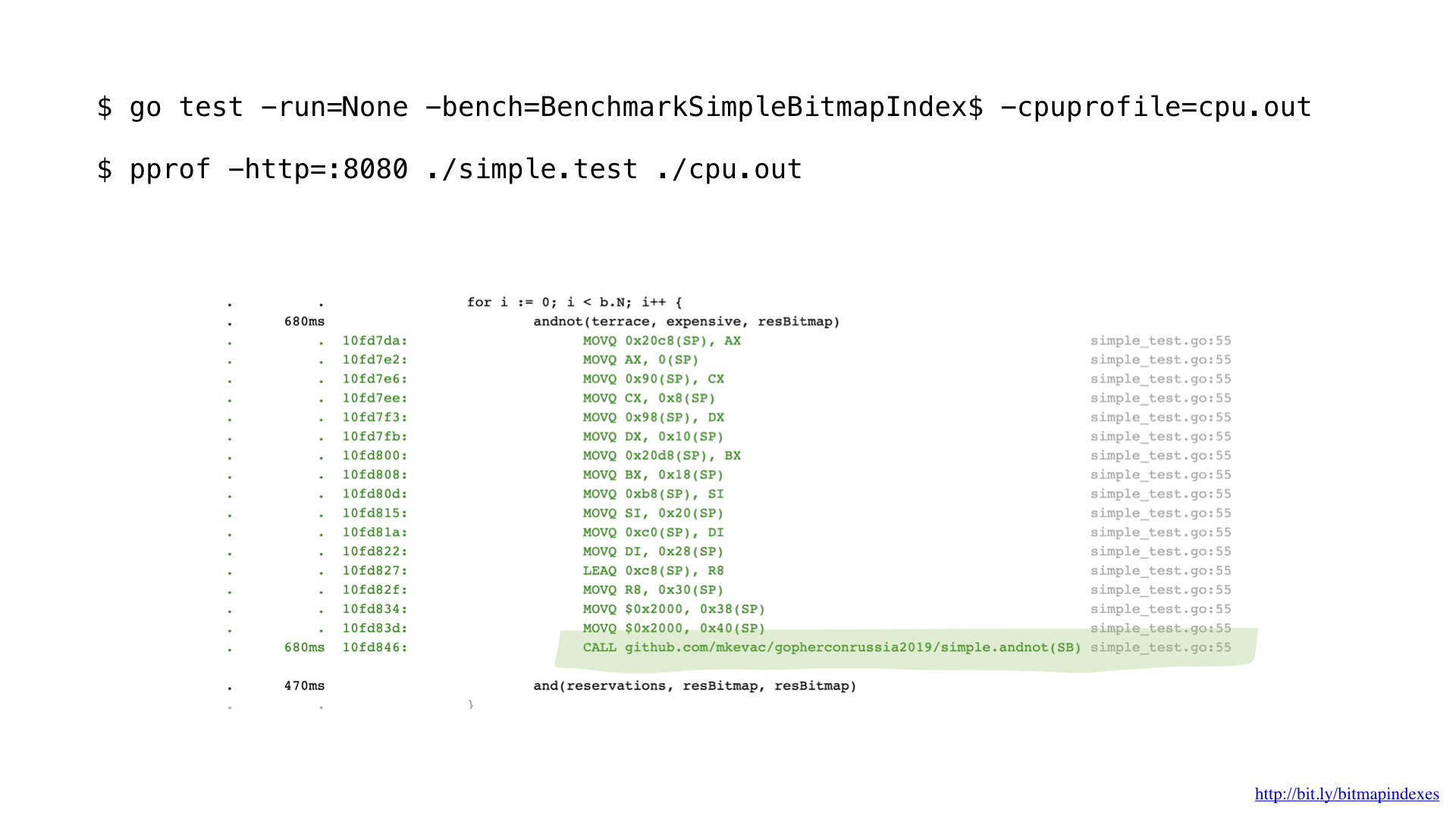
Дело в том, что компилятор Go ужасно боится циклов, которые идут по слайсам, и категорически отказывается инлайнить функции, которые содержат такие циклы.
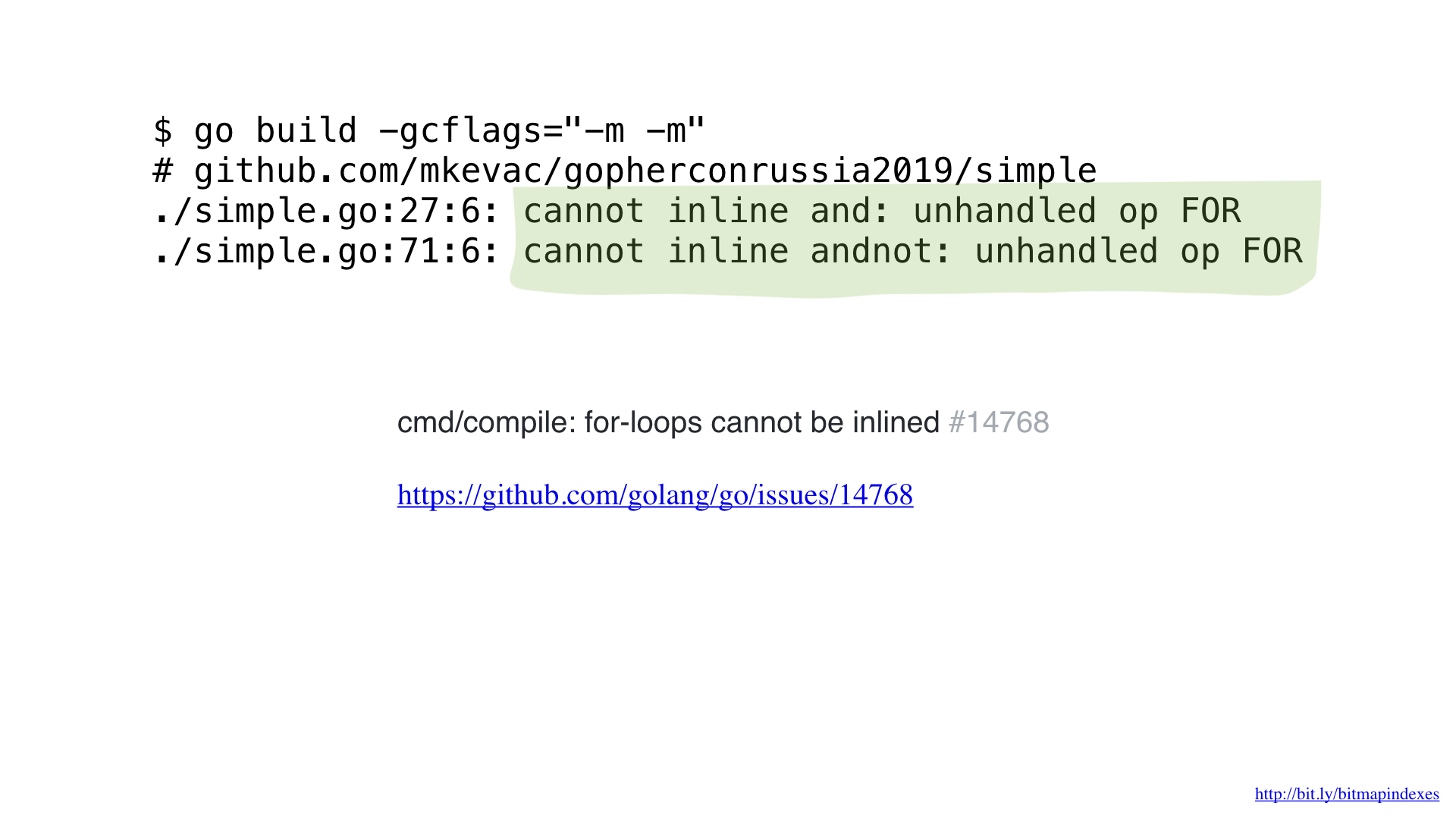
Но я-то не боюсь и могу обмануть компилятор, воспользовавшись goto вместо цикла, как в старые добрые времена.


И, как видите, теперь компилятор с радостью инлайнит нашу функцию! В итоге нам удаётся сэкономить около 2 микросекунд. Неплохо!

Второе узкое место несложно увидеть, если внимательно посмотреть на ассемблерный вывод. Компилятор добавил проверку на границы слайса прямо внутрь нашего самого горячего цикла. Дело в том, что Go — безопасный язык, компилятор опасается, что три моих аргумента (три слайса) имеют разный размер. Ведь тогда будет теоретическая возможность возникновения так называемого переполнения буфера (buffer overflow).
Давайте же успокоим компилятор, показав ему, что у всех слайсов одинаковый размер. Мы можем это сделать, добавив простую проверку в начале нашей функции.
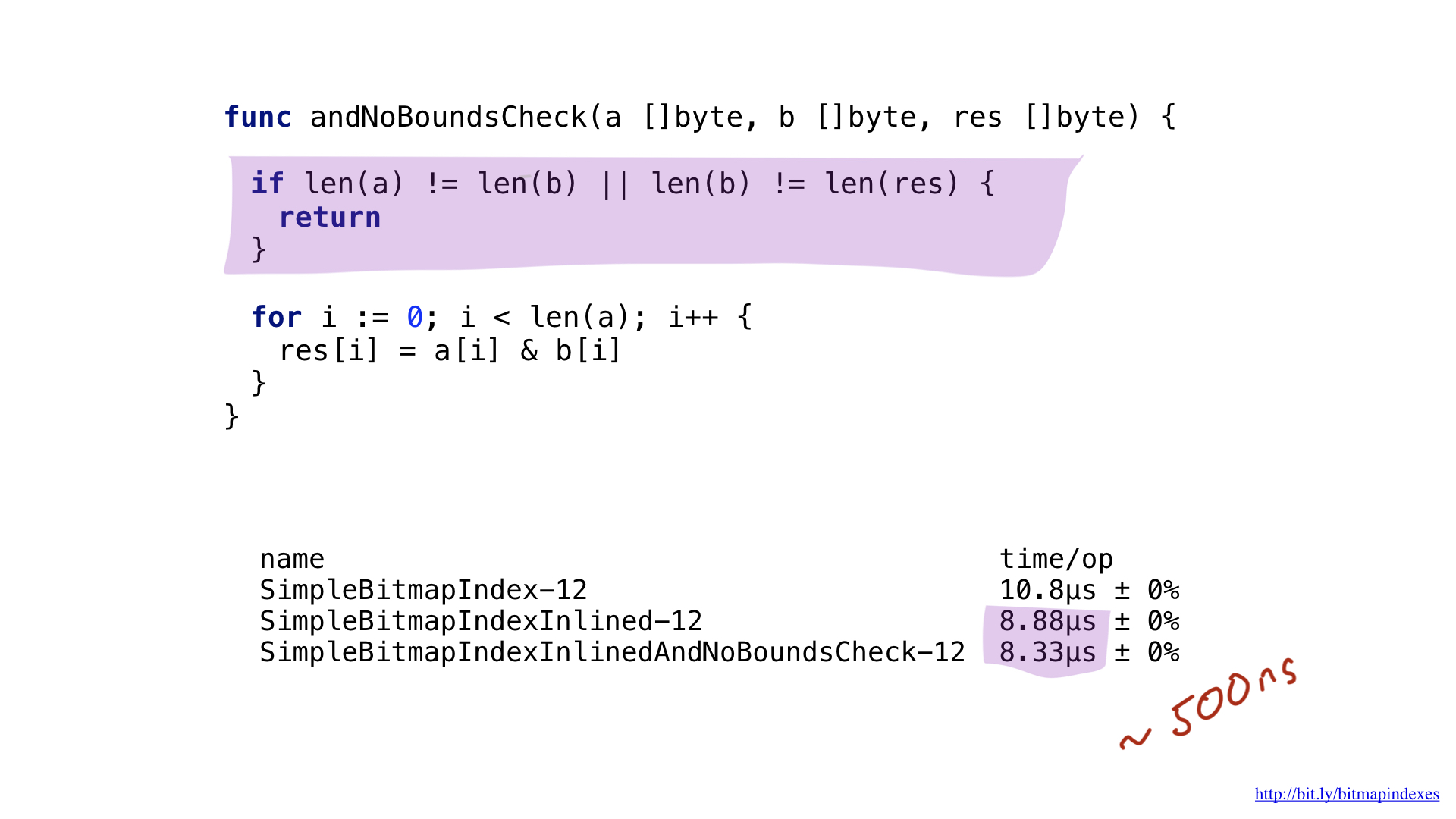
Видя это, компилятор с радостью пропускает проверку, а мы в итоге экономим ещё 500 наносекунд.
Большие батчи
Окей, нам удалось выжать какую-то производительность из нашей простой имплементации, но этот результат, на самом деле, гораздо хуже, чем возможно с текущим железом.
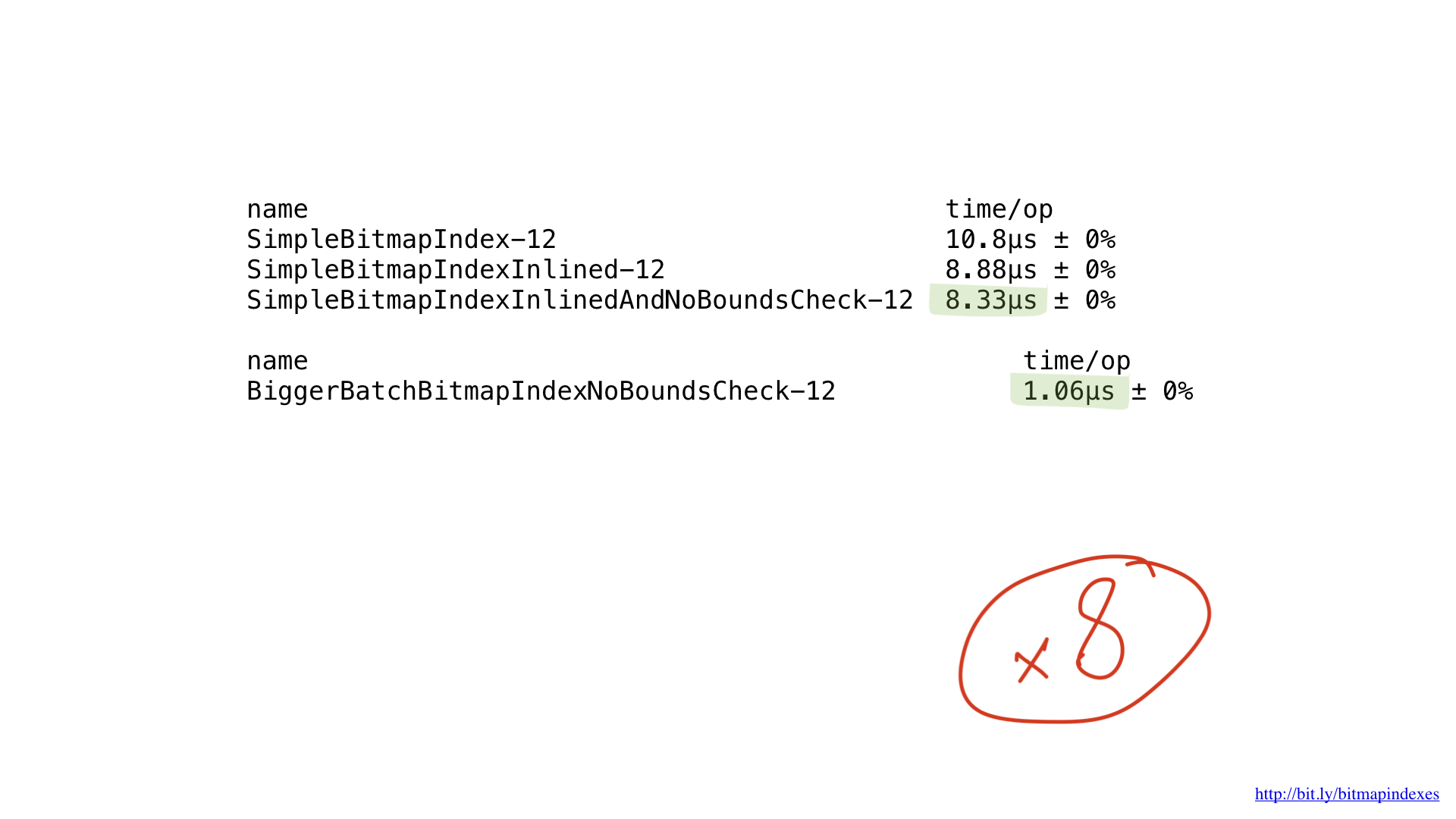
Всё, что мы делаем, — это базовые битовые операции, и наши процессоры очень эффективно их выполняют. Но, к сожалению, мы «кормим» наш процессор очень маленькими кусками работы. Наши функции выполняют операции побайтово. Мы можем очень просто подтюнить наш код, чтобы он работал с 8-байтовыми кусками, используя слайсы UInt64.

Как видите, это маленькое изменение ускорило нашу программу в восемь раз за счёт увеличения батча в восемь раз. Выигрыш, можно сказать, линейный.
Имплементация на ассемблере

Но это ещё не конец. Наши процессоры могут работать с кусками по 16, 32 и даже 64 байта. Такие «широкие» операции называются single instruction multiple data (SIMD; одна инструкция, много данных), а процесс преобразования кода таким образом, чтобы он использовал такие операции, называется векторизация.
К сожалению, компилятор Go — далеко не отличник в векторизации. На текущий момент единственный способ векторизации кода на Go — это взять и положить данные операции вручную с использованием ассемблера Go.

Ассемблер Go — странный зверь. Вы наверняка знаете, что ассемблер — это что-то, что сильно привязано к архитектуре компьютера, для которого вы пишете, но в Go это не так. Ассемблер Go больше похож на IRL (intermediate representation language) или промежуточный язык: он практически платформонезависимый. Роб Пайк выступил с отличным докладом на эту тему несколько лет назад на GopherCon в Денвере.
В дополнение к этому Go использует необычный формат Plan 9, отличающийся от общепризнанных форматов AT&T и Intel.

Можно с уверенностью сказать, что писать ассемблер Go вручную — это не самое весёлое занятие.
Но, к счастью, уже есть две высокоуровневые тулзы, которые помогают нам в написании Go ассемблера: PeachPy и avo. Обе утилиты генерируют Go-ассемблер из более высокоуровневого кода, написанного на Python и Go соответственно.

Эти утилиты упрощают такие вещи, как register allocation (выбор процессорного регистра), написание циклов, и в целом упрощают процесс входа в мир ассемблерного программирования в Go.
Мы будем использовать avo, так что наши программы будут почти обычными программами на Go.

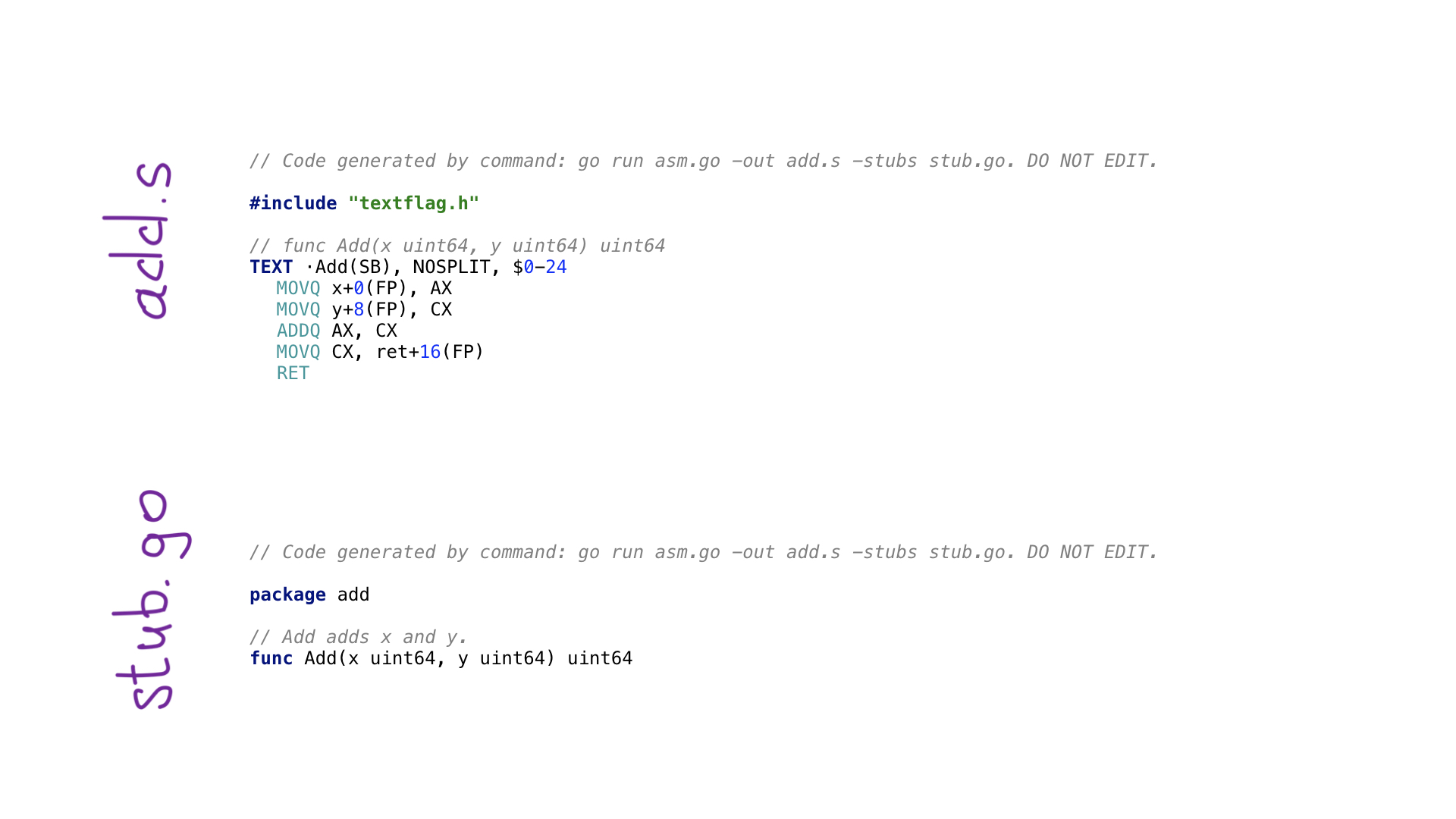
Вот так выглядит самый простой пример avo-программы. У нас есть функция main(), которая определяет внутри себя функцию Add(), смысл которой заключается в сложении двух чисел. Здесь присутствуют вспомогательные функции для получения параметров по имени и получения одного из свободных и подходящих процессорных регистров. У каждой процессорной операции есть соответствующая функция на avo, как видно по ADDQ. И наконец, мы видим вспомогательную функцию для сохранения результирующего значения.

Вызвав go generate, мы выполним программу на avo и в итоге будут сгенерированы два файла:
- add.s с результирующим кодом на Go-ассемблере;
- stub.go с заголовками функций для связи двух миров: Go и ассемблера.
Теперь, когда мы увидели, что и как делает avo, давайте посмотрим на наши функции. Я реализовал и скалярную, и векторную (SIMD) версии функций.
Сначала посмотрим на скалярные версии.

Как и в предыдущем примере, мы просим предоставить нам свободный и правильный регистр общего назначения, нам не нужно вычислять смещения и размеры для аргументов. Всё это avo делает за нас.

Ранее мы использовали лейблы и goto (или прыжки) для повышения производительности и для того чтобы обмануть компилятор Go, но сейчас мы делаем это с самого начала. Дело в том, что циклы — это более высокоуровневое понятие. В ассемблере же у нас есть только лейблы и прыжки.

Оставшийся код должен быть уже знаком и понятен. Мы эмулируем цикл лейблами и прыжками, берём маленькую часть данных из двух наших слайсов, объединяем их битовой операцией (AND NOT в данном случае) и затем кладём результат в результирующий слайс. Всё.

Вот так выглядит окончательный код на ассемблере. Нам не нужно было высчитывать смещения и размеры (выделено зелёным) или следить за используемыми регистрами (выделено красным).
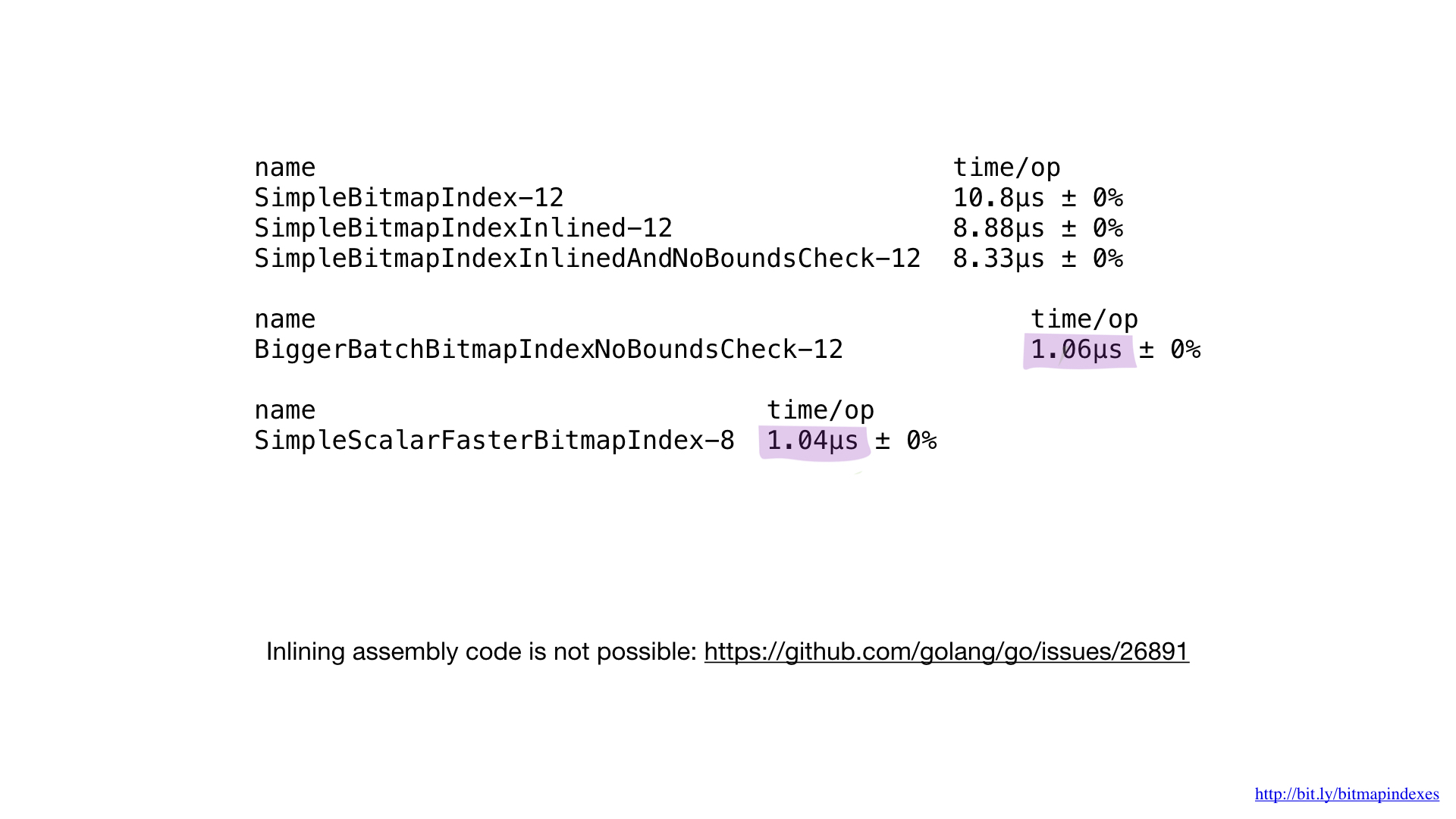
Если сравнить производительность имплементации на ассемблере с производительностью лучшей имплементации на Go, то мы увидим, что она одинакова. И это ожидаемо. Ведь мы не делали ничего особенного — мы лишь воспроизвели то, что делал бы компилятор Go.
К сожалению, мы не можем заставить компилятор заинлайнить наши функции, написанные на ассемблере. У Go-компилятора на сегодняшний день такая возможность отсутствует, хотя просьба добавить её существует уже довольно длительное время.
Именно поэтому невозможно получить какие-либо преимущества от мелких функций на ассемблере. Нам надо либо писать большие функции, либо использовать новый пакет math/bits, либо обходить ассемблер стороной.
Давайте теперь посмотрим на векторные версии наших функций.

Для данного примера я решил применить AVX2, поэтому мы будем использовать операции, работающие с 32-байтными кусками. Структура кода очень похожа на скалярный вариант: загрузка параметров, просьба предоставить нам свободный общий регистр и т. п.
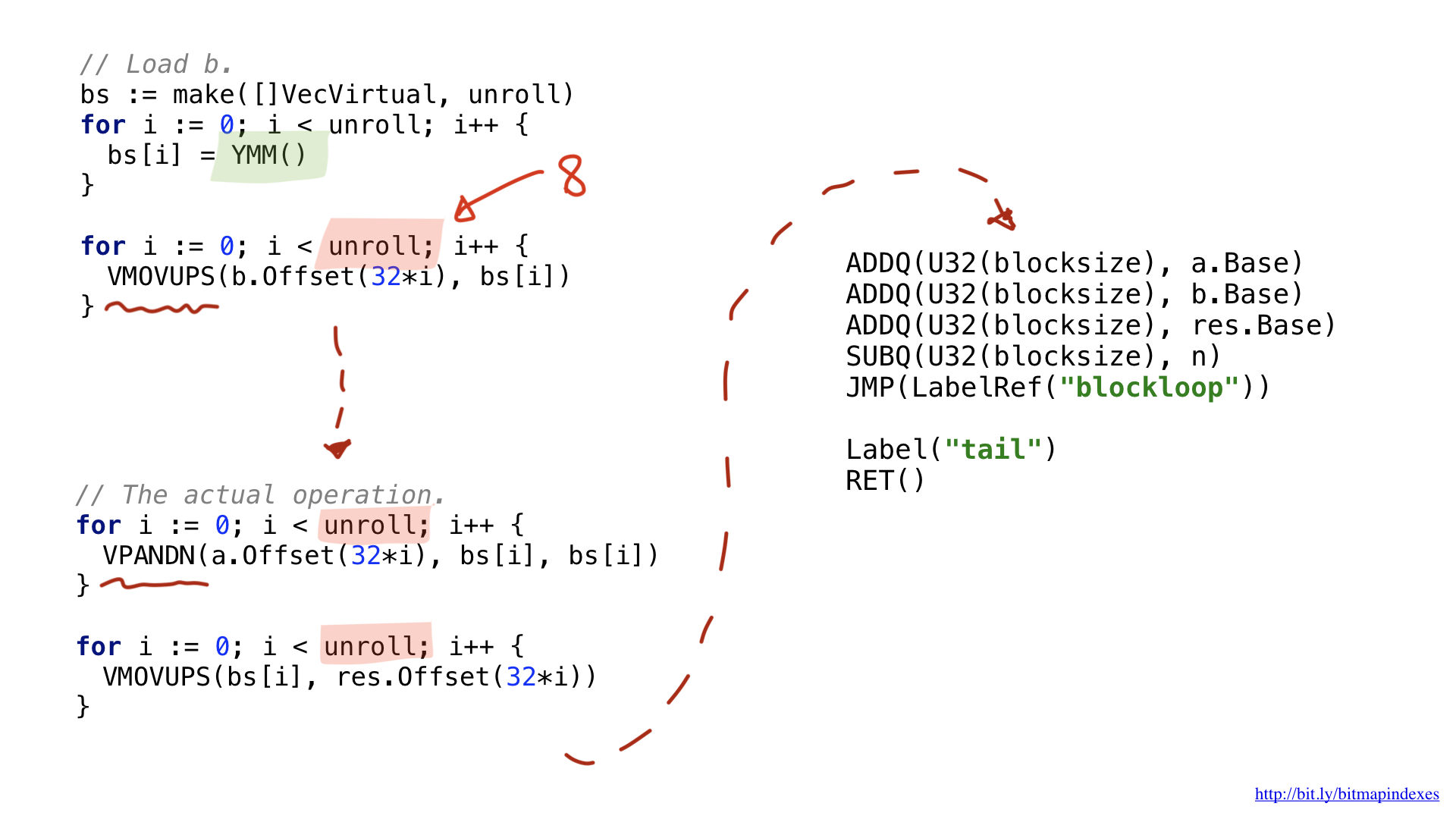
Одно из новшеств связано с тем, что более широкие векторные операции используют специальные широкие регистры. В случае с 32-байтными кусками это регистры с префиксом Y. Именно поэтому вы видите функцию YMM() в коде. Если бы я использовал AVX-512 с 64-битными кусками, то префикс был бы Z.
Второе новшество связано с тем, что я решил использовать оптимизацию, которая называется разворачивание цикла (loop unrolling), то есть сделать восемь операций цикла вручную, прежде чем прыгнуть в начало цикла. Данная оптимизация уменьшает количество бранчей (ветвлений) в коде, и она ограничена количеством свободных регистров, имеющихся в наличии.
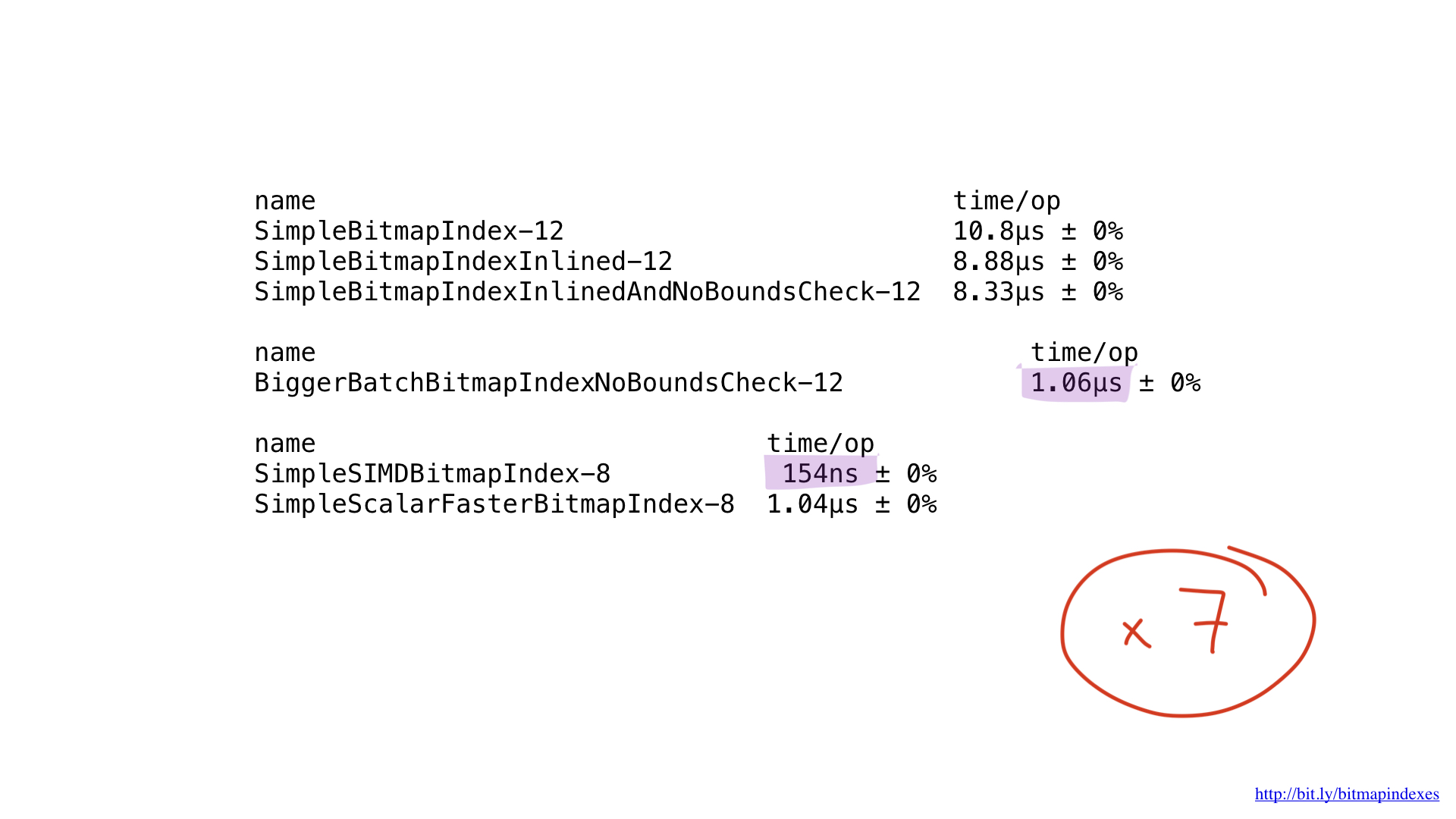
Ну а что насчёт производительности? Она прекрасна! Мы получили ускорение примерно в семь раз по сравнению с лучшим решением на Go. Впечатляет, да?
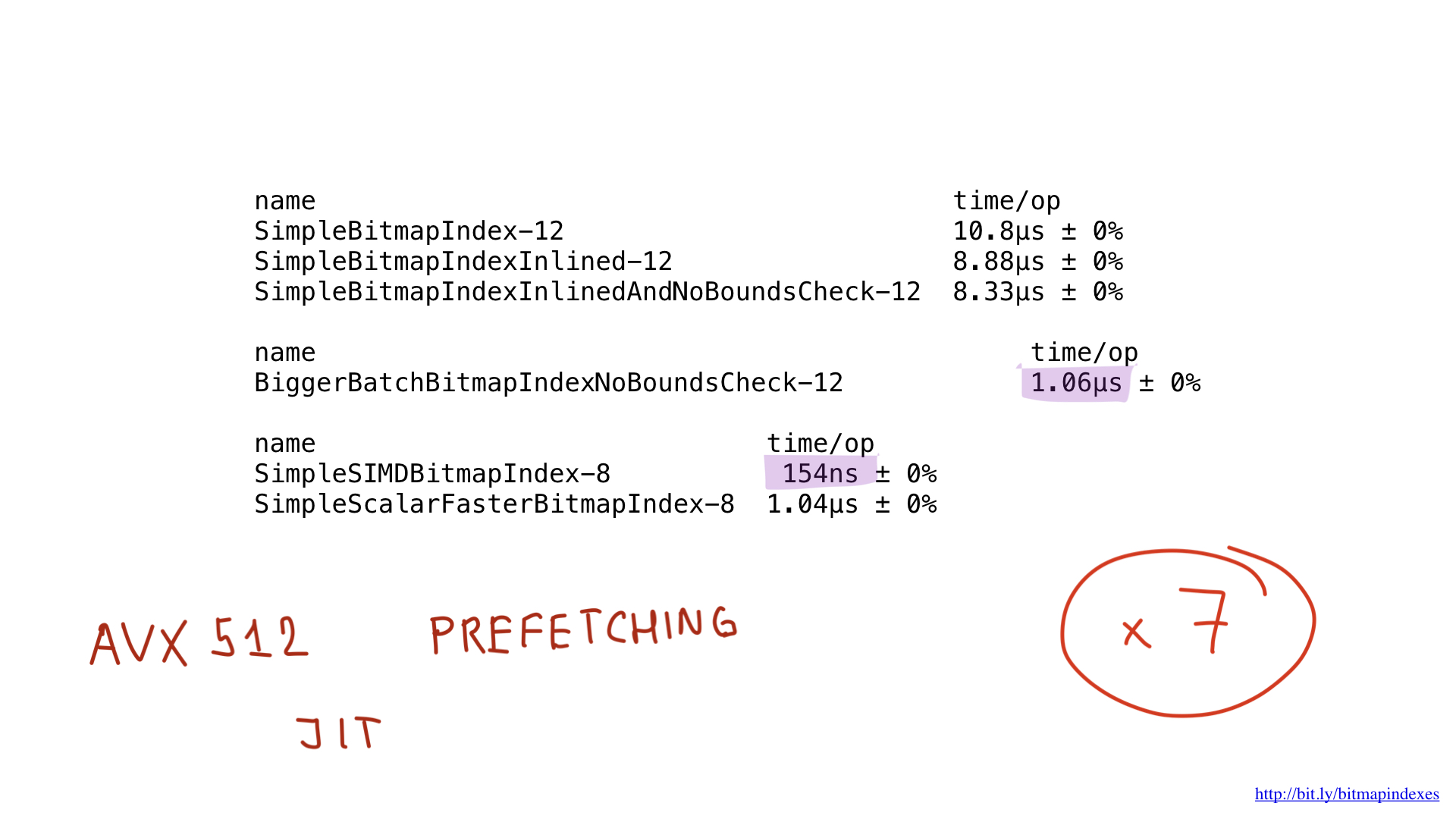
Но даже эту имплементацию потенциально можно было бы ускорить, воспользовавшись AVX-512, префетчингом или JIT (just-in-time compiler) для планировщика запросов. Но это уж точно тема для отдельного доклада.
Проблемы bitmap-индексов
Сейчас, когда мы уже рассмотрели простую реализацию bitmap-индекса на Go и гораздо более производительную на ассемблере, давайте, наконец, поговорим о том, почему же bitmap-индексы так редко используются.

В старых научных работах упоминаются три проблемы bitmap-индексов, но более новые научные работы и я утверждаем, что они уже неактуальны. Не будем глубоко погружаться в каждую из этих проблем, но поверхностно их рассмотрим.
Проблема большой кардинальности
Итак, нам говорят, что bitmap-индексы подходят только для полей с малой кардинальностью, то есть таких, у которых мало значений (например, пол или цвет глаз), и причина в том, что обычное представление таких полей (один бит на значение) в случае большой кардинальности будет занимать слишком много места и, более того, эти bitmap-индексы будут слабо (редко) заполнены.
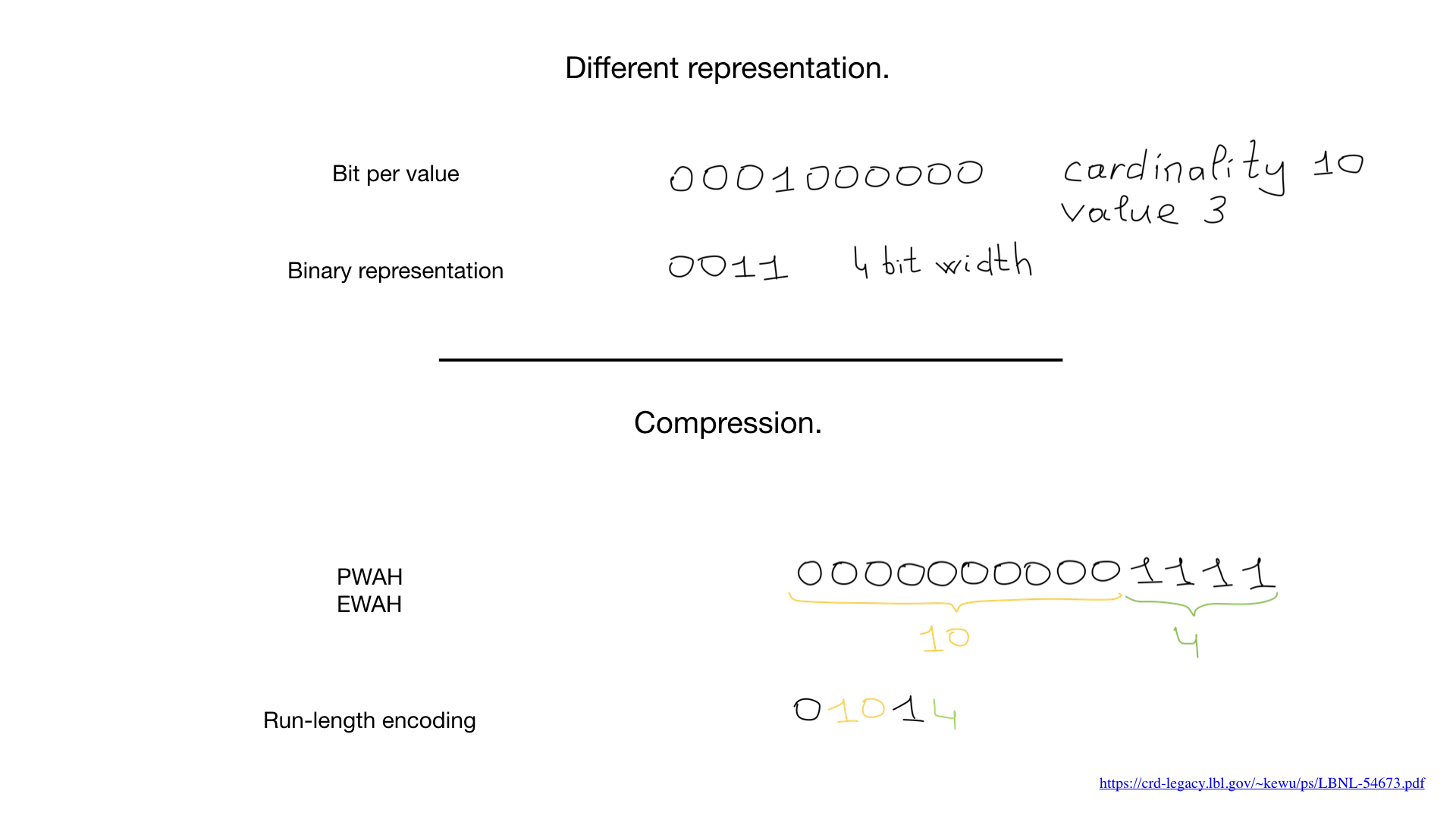
Иногда мы можем использовать другое представление, например стандартное, которое мы используем для представления чисел. Но именно появление алгоритмов сжатия всё изменило. За последние десятилетия учёные и исследователи придумали большое количество алгоритмов сжатия для битмапов. Основное их преимущество в том, что не нужно расжимать битмапы для проведения битовых операций — мы можем совершать битовые операции прямо над сжатыми битмапами.

В последнее время стали появляться и гибридные подходы, как, например, roaring битмапы. Они используют одновременно три разных представления для битмапов — собственно битмапы, массивы и так называемые bit runs — и балансируют между ними, чтобы максимизировать производительность и минимизировать потребление памяти.
Вы можете встретить roaring битмапы в самых популярных приложениях. Уже существует огромное количество имплементаций для самых разных языков программирования, в том числе более трёх имплементаций для Go.
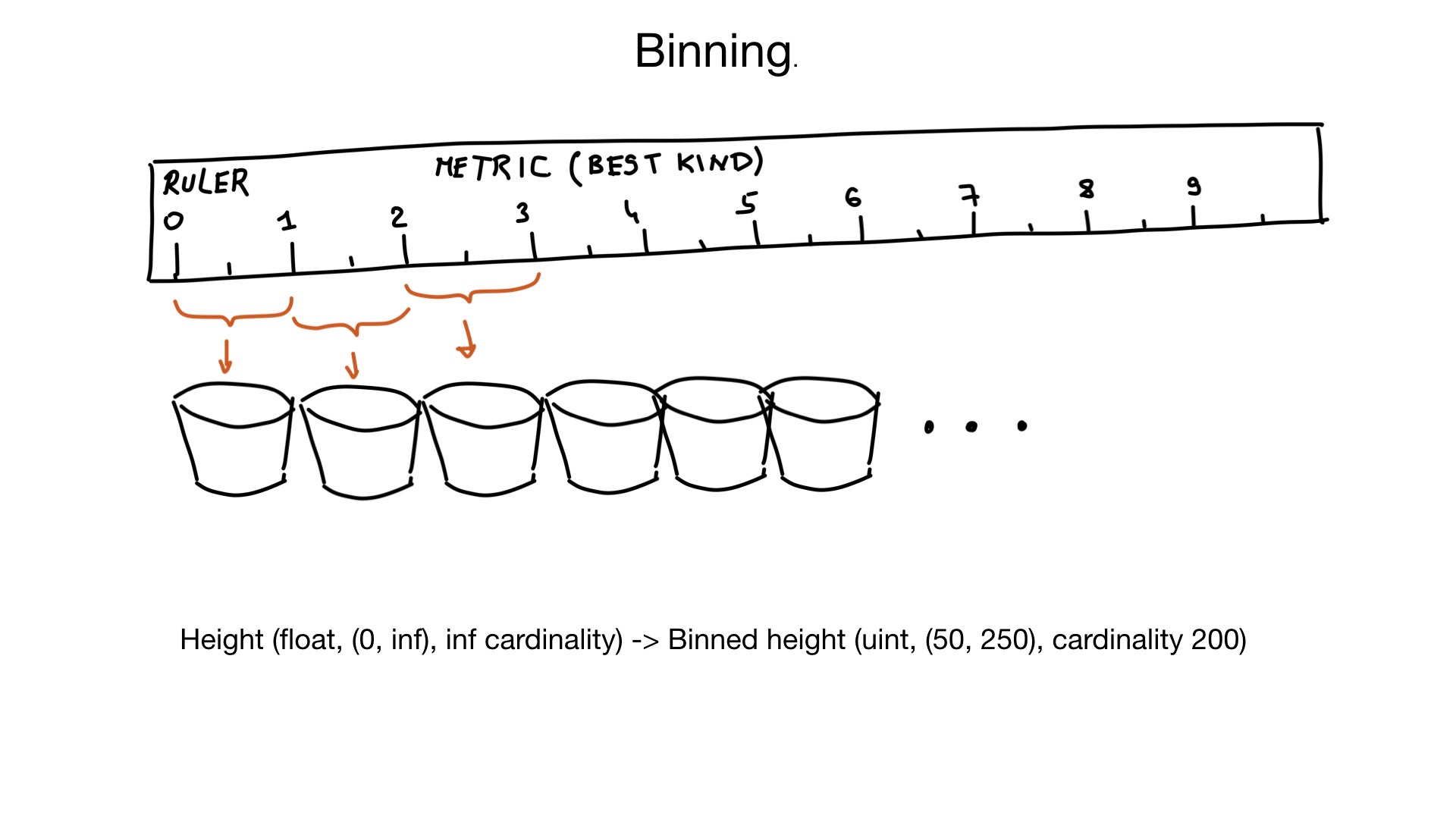
Ещё один подход, который может нам помочь справиться с большой кардинальностью, называется группировка (binning). Представьте, что у вас есть поле, представляющее рост человека. Рост — это число с плавающей запятой, но мы, люди, не думаем о нём в таком ключе. Для нас нет разницы между ростом 185,2 см и 185,3 см.
Получается, мы можем сгруппировать похожие значения в группы в пределах 1 см.
А если мы ещё и знаем, что очень мало людей имеют рост меньше 50 см и больше 250 см, то мы можем, по сути, превратить поле с бесконечной кардинальностью в поле с кардинальностью примерно в 200 значений.
Конечно, при необходимости мы можем сделать дополнительную фильтрацию уже после.
Проблема большой пропускной способности
Следующая проблема bitmap-индексов заключается в том, что их обновление может быть очень дорогим.
Базы данных должны давать возможность обновлять данные в тот момент, когда потенциально сотни других запросов осуществляют поиск по этим данным. Нам нужны локи, чтобы избежать проблем с одновременным доступом к данным или иных проблем совместного доступа. А там, где есть один большой лок, там есть проблема — lock contention, когда этот лок становится узким местом.
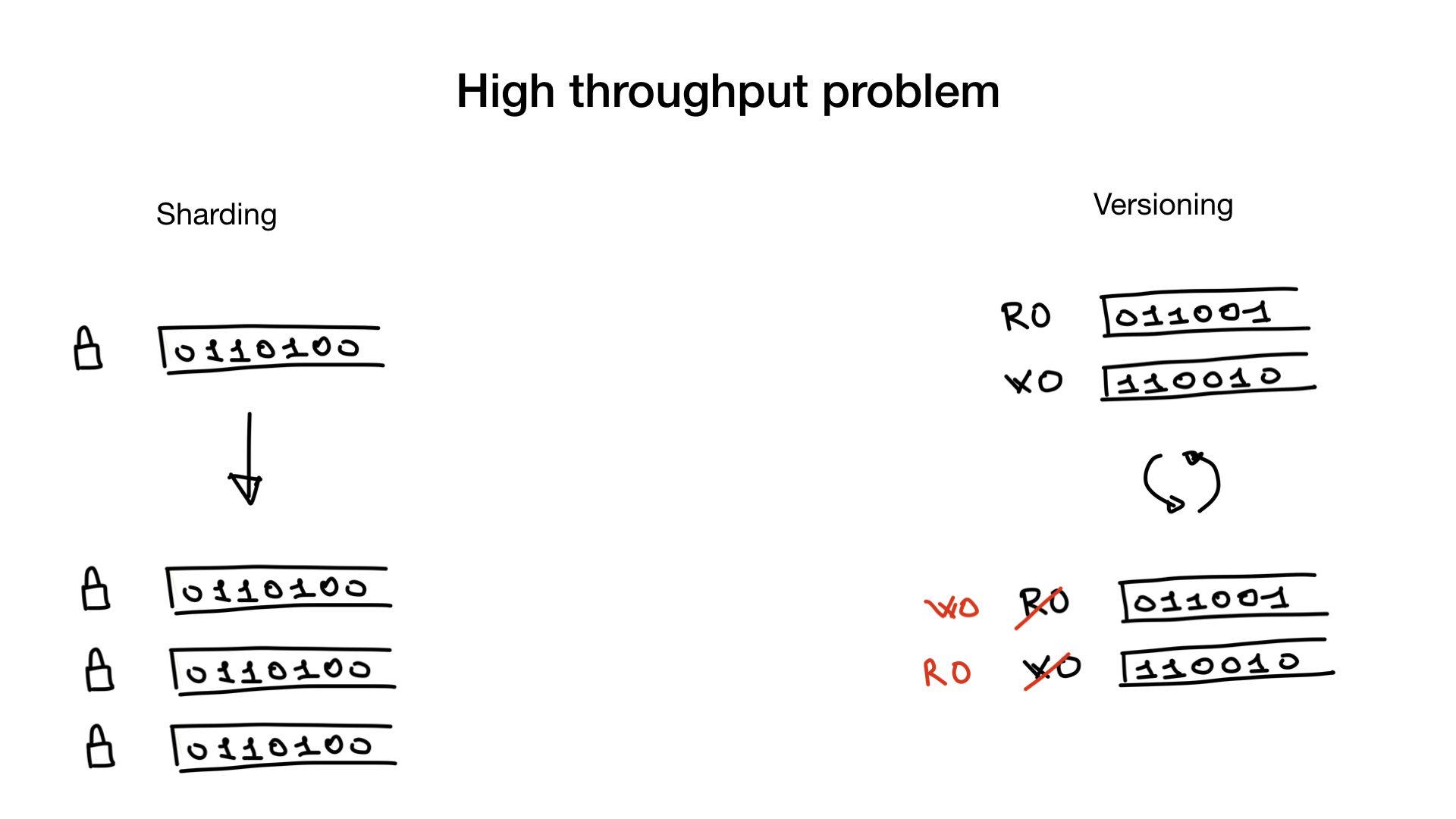
Эту проблему можно решить или обойти с помощью шардинга или использования версионированных индексов.
Шардинг — штука простая и общеизвестная. Вы можете шардировать bitmap-индекс так, как вы шардировали бы любые другие данные. Вместо одного большого лока вы получите кучу мелких локов и таким образом избавитесь от lock contention.
Второй способ решения проблемы — это использование версионированных индексов. У вас может быть одна копия индекса, которую вы используете для поиска или чтения, и одна — для записи или обновления. И раз в какой-то промежуток времени (например, раз в 100 мс или 500 мс) вы их дублируете и меняете местами. Конечно, этот подход применим только в тех случаях, когда ваше приложение может работать с чуть отстающим поисковым индексом.
Эти два подхода можно использовать одновременно: у вас может быть шардированный версионированный индекс.
Более сложные запросы
Последняя проблема bitmap-индексов заключается в том, что, как нам говорят, они плохо подходят для более сложных типов запросов, например запросов «по промежутку».
И правда, если подумать, битовые операции типа AND, OR и т. д. не очень подходят для запросов а-ля «Покажи мне отели со стоимостью номера от 200 до 300 долларов за ночь».

Наивным и очень неразумным решением было бы взять результаты для каждого долларового значения и объединить их битовой операцией OR.

Чуть более правильным решением было бы использовать группировку. Например, в группы по 50 долларов. Это ускорило бы наш процесс в 50 раз.
Но проблема также легко решается использованием представления, созданного специально для такого типа запросов. В научных работах оно называется range-encoded bitmaps.

В таком представлении мы не просто выставляем один бит для какого-либо значения (например, 200), а выставляем это значение и всё, что выше. 200 и выше. То же самое для 300: 300 и выше. И так далее.
Используя это представление, мы можем ответить на такого рода поисковый запрос, пройдя по индексу всего два раза. Сначала мы получим список отелей, где номер стоит меньше или 300 долларов, а затем выкинем из него те, где стоимость номера меньше или 199 долларов. Готово.

Вы удивитесь, но даже геозапросы возможны с использованием bitmap-индексов. Хитрость в том, чтобы использовать геопредставление, которое окружает вашу координату геометрической фигурой. Например, S2 от Google. Фигуру должно быть возможно представить в виде трёх или более пересекающихся прямых, которые можно пронумеровать. Таким образом мы сможем превратить наш геозапрос в несколько запросов «по промежутку» (по этим пронумерованным линиям).
Готовые решения
Надеюсь я немного вас заинтересовал и у вас в арсенале появился ещё один полезный инструмент. Если вам когда-нибудь нужно будет сделать что-то подобное, вы будете знать, в какую сторону смотреть.
Однако не у всех есть время, терпение и ресурсы, чтобы создать bitmap-индексы с нуля. Особенно более продвинутые, с использованием SIMD, например.
К счастью, есть несколько готовых решений, которые вам помогут.

Roaring битмапы
Во-первых, есть та самая roaring bitmaps-библиотека, о которой я уже говорил. Она содержит все необходимые контейнеры и битовые операции, которые вам понадобятся для того, чтобы сделать полноценный bitmap-индекс.
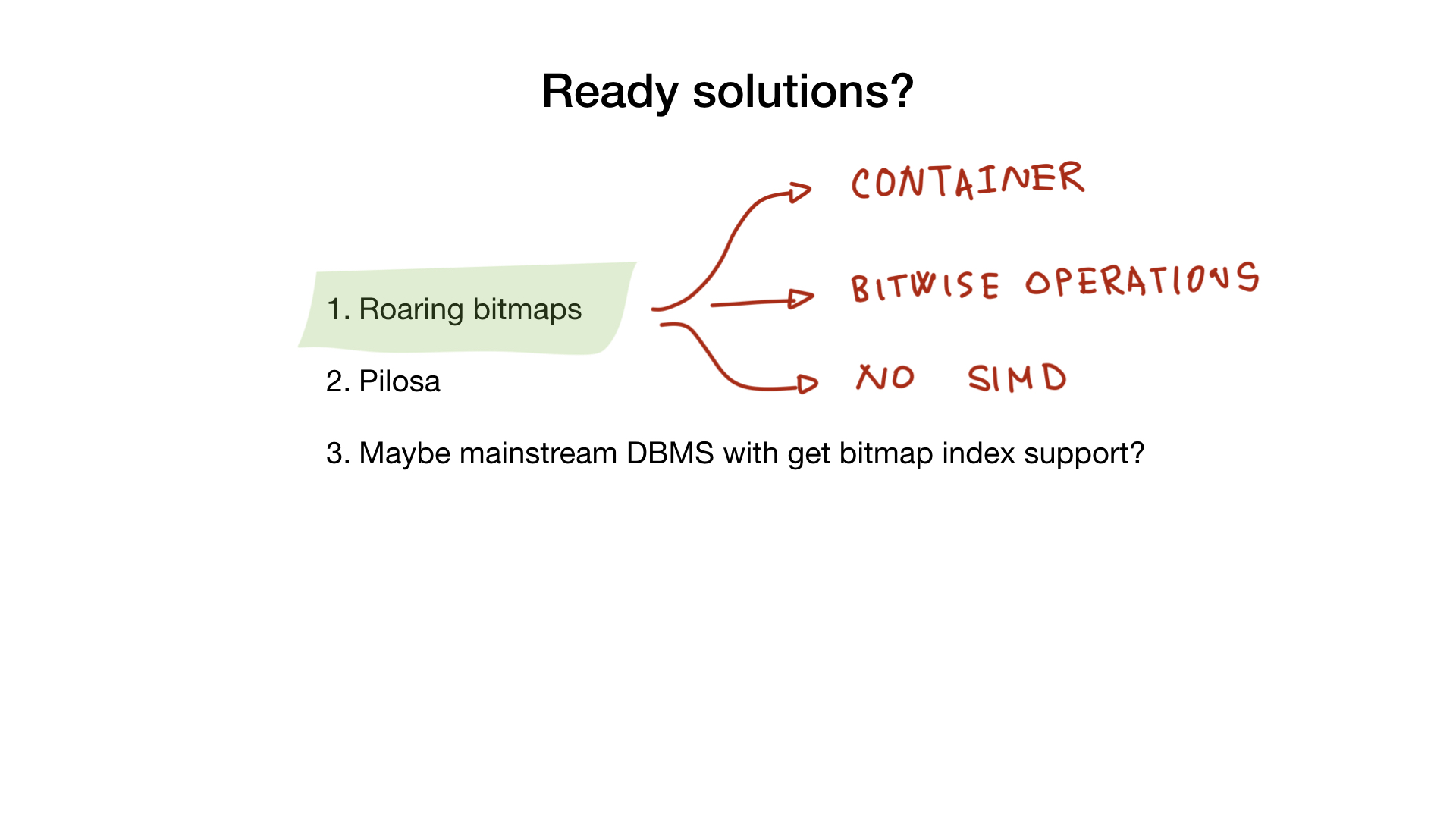
К сожалению, на данный момент ни одна из Go-реализаций не использует SIMD, а значит, Go-реализации менее производительны, чем реализации на C, например.
Pilosa
Другой продукт, который может вам помочь, — СУБД Pilosa, у которой, по сути, только bitmap-индексы и есть. Это относительно новое решение, но оно завоёвывает сердца с огромной скоростью.
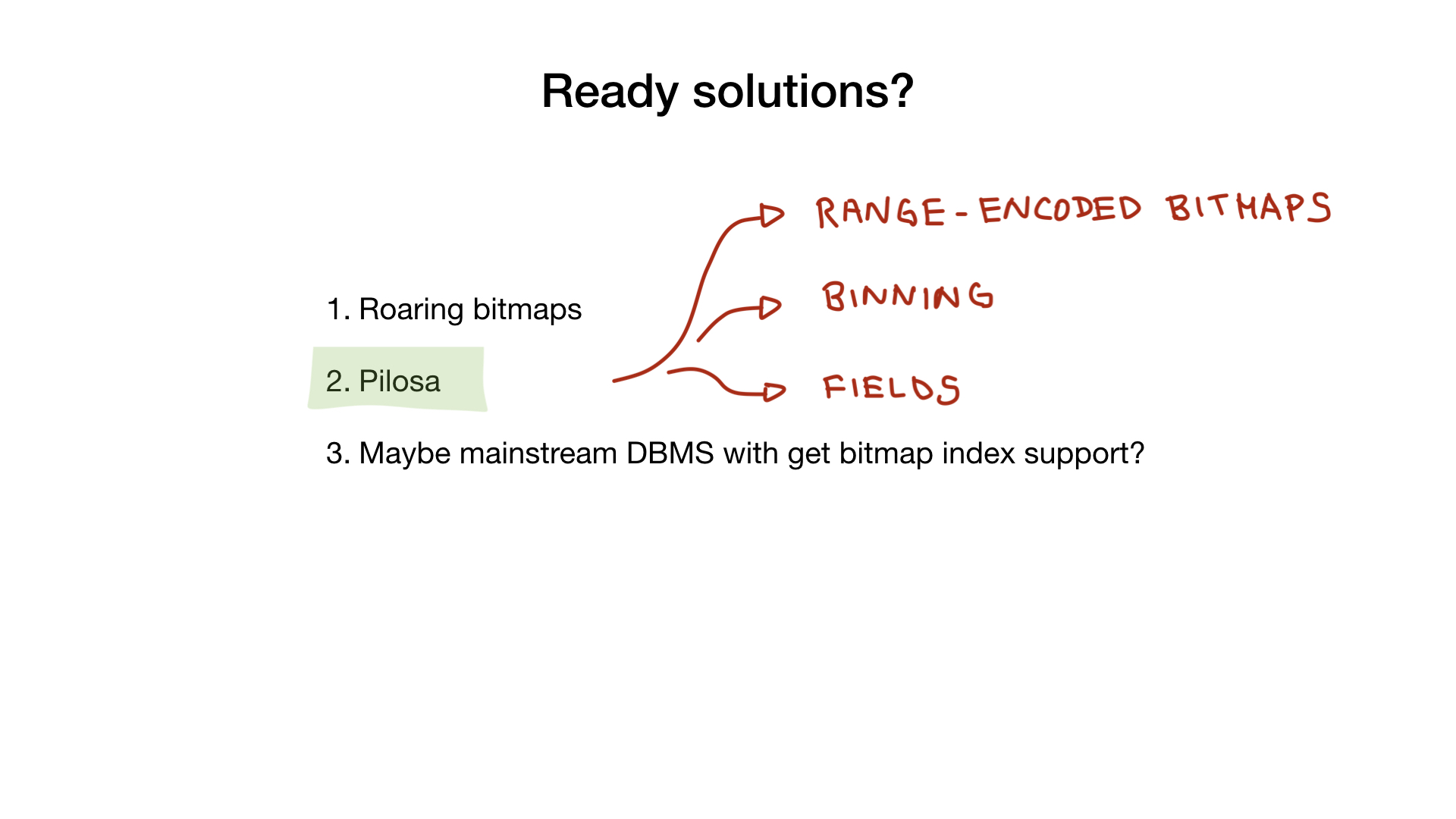
Pilosa использует roaring битмапы внутри себя и даёт вам возможность использовать их, упрощает и объясняет все те вещи, о которых я говорил выше: группировка, range-encoded bitmaps, понятие поля и т. п.
Давайте быстренько взглянем на пример использования Pilosa для ответа на уже знакомый вам вопрос.

Пример очень похож на то, что вы видели раньше. Мы создаём клиент к серверу Pilosa, создаём индекс и необходимые поля, затем заполняем наши поля рандомными данными с вероятностями и, наконец, выполняем знакомый запрос.
После этого мы используем NOT на поле «expensive», затем пересекаем результат (или AND-им) с полем «terrace» и с полем «reservations». И наконец, получаем финальный результат.

Я очень надеюсь, что в обозримом будущем в СУБД вроде MySQL и PostgreSQL тоже появится этот новый тип индексов — bitmap-индексы.

Заключение

Если вы ещё не заснули, спасибо. Мне пришлось вскользь затронуть многие темы из-за ограниченного количества времени, но я надеюсь, что доклад был полезным и, может, даже мотивирующим.
О bitmap-индексах хорошо знать, даже если прямо сейчас они вам не нужны. Пусть они будут ещё одним инструментом в вашем ящичке.
Мы с вами рассмотрели различные трюки увеличения производительности для Go и те вещи, с которыми компилятор Go пока не очень хорошо справляется. А вот это абсолютно точно полезно знать каждому программисту на Go.
Это всё, что я хотел рассказать. Спасибо!


![Программа для поиска единомышленников ВКонтакте [Open source]](/upload/resize_cache/iblock/4df/105_70_0/4df96e711f49b5310e1074a3c4a30b2f.png "Программа для поиска единомышленников ВКонтакте [Open source]")
