В первой части статьи я описал предпосылки для исследования, его цели, допущения, исходные данные и инструменты. Сейчас можно без дальнейших разглагольствований сказать гагаринское...
Поехали!
Импортируем библиотеки и определяем путь к директории со всеми файлами:
import pandas as pd, numpy as np
# путь к папке с исходными файлами
ROOT_FOLDER = r'c:\_PROG_\Projects\us_crimes'Гибель от рук закона

Начнем с анализа данных по жертвам полиции. Давайте подгрузим файл из CSV в DataFrame:
# Файл с БД Fatal Encounters (FENC)
FENC_FILE = ROOT_FOLDER + '\\fatal_enc_db.csv'
# грузим в DataFrame
df_fenc = pd.read_csv(FENC_FILE, sep=';', header=0, usecols=["Date (Year)", "Subject's race with imputations", "Cause of death", "Intentional Use of Force (Developing)", "Location of death (state)"])Заметьте сразу, что мы не грузим все поля из БД, а только необходимые нам для анализа: год, расовая принадлежность (с учетом экспертной оценки), причина смерти (здесь пока не используется, но может понадобиться в дальнейшем), признак намеренного применения силы и штат, в котором имело место событие.
Здесь надо пояснить, что такое "экспертная оценка" расовой принадлежности. Дело в том, что официальные источники, откуда FENC собирает данные, не всегда указывают расу жертвы, отсюда получаются пропуски в данных. Для компенсации этих пропусков сообщество привлекает экспертов, оценивающих расу жертвы по другим данным (с определенной погрешностью). Более подробно на эту тему можете почитать на самом сайте Fatal Encounters или загрузив исходный Excel файл (во втором листе).
Переименуем столбцы для удобства и очистим строки с пропущенными данными:
df_fenc.columns = ['Race', 'State', 'Cause', 'UOF', 'Year']
df_fenc.dropna(inplace=True)Теперь нам надо унифицировать наименования расовой принадлежности для того, чтобы в дальнейшем сопоставлять эти данные с данными по преступлениям и численности населения. Классификация рас в этих источниках немного разная. БД FENC, в частности, выделяет латиноамериканцев (Hispanic/Latino), азиатов и уроженцев тихоокеанских территорий (Asian/Pacific Islander) и среднеазиатов (Middle Eastern). Нас же интересуют только белые и черные. Поэтому сделаем укрупнение:
df_fenc = df_fenc.replace({'Race': {'European-American/White': 'White', 'African-American/Black': 'Black',
'Hispanic/Latino': 'White', 'Native American/Alaskan': 'American Indian',
'Asian/Pacific Islander': 'Asian', 'Middle Eastern': 'Asian',
'NA': 'Unknown', 'Race unspecified': 'Unknown'}}, value=None)Оставляем только данные по белым (теперь с учетом латино) и черным:
df_fenc = df_fenc.loc[df_fenc['Race'].isin(['White', 'Black'])]Зачем нам поле "UOF" (намеренное использование силы)? Для исследования мы хотим оставить только случаи, когда полиция (или иные правоохранительные органы) намеренно применяли силу против человека. Мы опускаем случаи, когда человек совершил самоубийство (например, в результате осады полицией) или погиб в результате ДТП, преследуемый полицейскими. Это допущение сделано по двум причинам: 1) обстоятельства гибели по косвенным причинам часто не позволяют провести прямую причинно-следственную связь между действиями правоохранительных органов и смертью (пример: полицейский держит на мушке человека, который затем умирает от сердечного приступа; другой пример: при задержании преступник пускает себе пулю в лоб); 2) при рассмотрении действий властей расценивается именно применение силы; так, например, будущая официальная БД по применению силы (которую я упомянул в предыдущей статье) будет содержать именно данные, отражающая намеренное применение смертельной силы против граждан. Итак, оставляем только эти данные:
df_fenc = df_fenc.loc[df_fenc['UOF'].isin(['Deadly force', 'Intentional use of force'])]Для удобства добавим полные названия штатов. Для этого я приготовил отдельный CSV, который мы и подгрузим в наш датасет:
df_state_names = pd.read_csv(ROOT_FOLDER + '\\us_states.csv', sep=';', header=0)
df_fenc = df_fenc.merge(df_state_names, how='inner', left_on='State', right_on='state_abbr')Отобразим начальные строки командой df_fenc.head(), чтобы получить представление о датасете:
Race | State | Cause | UOF | Year | state_name | state_abbr | |
|---|---|---|---|---|---|---|---|
0 | Black | GA | Gunshot | Deadly force | 2000 | Georgia | GA |
1 | Black | GA | Gunshot | Deadly force | 2000 | Georgia | GA |
2 | Black | GA | Gunshot | Deadly force | 2000 | Georgia | GA |
3 | Black | GA | Gunshot | Deadly force | 2000 | Georgia | GA |
4 | Black | GA | Gunshot | Deadly force | 2000 | Georgia | GA |
Нам не нужно разбирать отдельные случаи гибели, давайте агрегируем данные по годам и расовой принадлежности:
# группируем по году и расе
ds_fenc_agg = df_fenc.groupby(['Year', 'Race']).count()['Cause']
df_fenc_agg = ds_fenc_agg.unstack(level=1)
# конвертируем численные данные в UINT16 для экономии
df_fenc_agg = df_fenc_agg.astype('uint16')В итоге получили таблицу с 2 столбцами: White (количество белых жертв) и Black (количество черных жертв), индексированную по годам (с 2000 по 2020). Давайте взглянем на эти данные в виде графика:
# белые и черные жертвы полицейских по годам (кол-во гибелей)
plt = df_fenc_agg.plot(xticks=df_fenc_agg.index)
plt.set_xticklabels(df_fenc_agg.index, rotation='vertical')
plt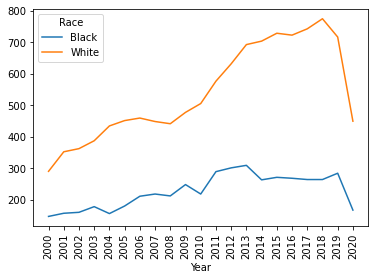
Промежуточный вывод:
В количественном (абсолютном) выражении белых жертв больше, чем черных.
Разница между этими данными составляет в среднем 2.4 раза. Напрашивается справедливое заключение о том, что это связано с разницей в численности белых и черных. Что же, давайте посмотрим теперь на удельные показатели.
Подгрузим данные по численности населения (по расам):
# файл CSV с данными по населению (1991 - 2018)
POP_FILE = ROOT_FOLDER + '\\us_pop_1991-2018.csv'
df_pop = pd.read_csv(POP_FILE, index_col=0, dtype='int64')Добавим эти данные в наш датасет:
# выбираем только данные по числ-ти белых и черных за 2000 - 2018 гг.
df_pop = df_pop.loc[2000:2018, ['White_pop', 'Black_pop']]
# объединяем датафреймы, выкидываем строки с пропусками
df_fenc_agg = df_fenc_agg.join(df_pop)
df_fenc_agg.dropna(inplace=True)
# конвертируем данные по численности в целочисленный тип
df_fenc_agg = df_fenc_agg.astype({'White_pop': 'uint32', 'Black_pop': 'uint32'})ОК. Осталось создать 2 столбца с удельными значениями, разделив количество жертв на численность и умножив на миллион (количество жертв на 1 млн. человек):
df_fenc_agg['White_promln'] = df_fenc_agg['White'] * 1e6 / df_fenc_agg['White_pop']
df_fenc_agg['Black_promln'] = df_fenc_agg['Black'] * 1e6 / df_fenc_agg['Black_pop']Смотрим, что получилось:
Black | White | White_pop | Black_pop | White_promln | Black_promln | |
|---|---|---|---|---|---|---|
Year | ||||||
2000 | 148 | 291 | 218756353 | 35410436 | 1.330247 | 4.179559 |
2001 | 158 | 353 | 219843871 | 35758783 | 1.605685 | 4.418495 |
2002 | 161 | 363 | 220931389 | 36107130 | 1.643044 | 4.458953 |
2003 | 179 | 388 | 222018906 | 36455476 | 1.747599 | 4.910099 |
2004 | 157 | 435 | 223106424 | 36803823 | 1.949742 | 4.265861 |
2005 | 181 | 452 | 224193942 | 37152170 | 2.016112 | 4.871855 |
2006 | 212 | 460 | 225281460 | 37500517 | 2.041890 | 5.653255 |
2007 | 219 | 449 | 226368978 | 37848864 | 1.983487 | 5.786171 |
2008 | 213 | 442 | 227456495 | 38197211 | 1.943229 | 5.576323 |
2009 | 249 | 478 | 228544013 | 38545558 | 2.091501 | 6.459888 |
2010 | 219 | 506 | 229397472 | 38874625 | 2.205778 | 5.633495 |
2011 | 290 | 577 | 230838975 | 39189528 | 2.499578 | 7.399936 |
2012 | 302 | 632 | 231992377 | 39623138 | 2.724227 | 7.621809 |
2013 | 310 | 693 | 232969901 | 39919371 | 2.974633 | 7.765653 |
2014 | 264 | 704 | 233963128 | 40379066 | 3.009021 | 6.538041 |
2015 | 272 | 729 | 234940100 | 40695277 | 3.102919 | 6.683822 |
2016 | 269 | 723 | 234644039 | 40893369 | 3.081263 | 6.578084 |
2017 | 265 | 743 | 235507457 | 41393491 | 3.154889 | 6.401973 |
2018 | 265 | 775 | 236173020 | 41617764 | 3.281493 | 6.367473 |
Последние 2 столбца - наши удельные показатели на миллион человек по каждой из двух рас. Пора посмотреть на графике:
plt = df_fenc_agg.loc[:, ['White_promln', 'Black_promln']].plot(xticks=df_fenc_agg.index)
plt.set_xticklabels(df_fenc_agg.index, rotation='vertical')
plt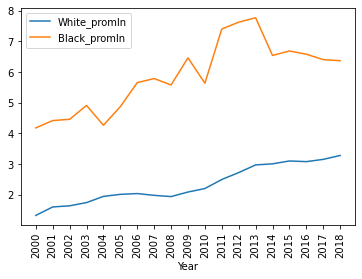
Также выведем основную статистику по этим данным:
df_fenc_agg.loc[:, ['White_promln', 'Black_promln']].describe()White_promln | Black_promln | |
|---|---|---|
count (количество) | 19.000000 | 19.000000 |
mean (среднее арифм.) | 2.336123 | 5.872145 |
std (станд. отклонение) | 0.615133 | 1.133677 |
min (мин. значение) | 1.330247 | 4.179559 |
25% | 1.946485 | 4.890977 |
50% | 2.091501 | 5.786171 |
75% | 2.991827 | 6.558062 |
max (макс. значение) | 3.281493 | 7.765653 |
Промежуточные выводы:
1. В среднем от рук полиции погибает 5.9 на 1 млн. черных и 2.3 на 1 млн. белых (черных в 2.6 раз больше).
2. Разброс (отклонение) в данных по черным жертвам в 1.8 раз выше, чем в данных по белым жертвам. (На графике видно, что кривая по белым жертвам гораздо более плавная, без резких скачков.)
3. Максимальное количество жертв среди черных - в 2013 г. (7.7 на миллион); максимальное количество жертв среди белых - в 2018 г. (3.3 на миллион).
4. Жертвы среди белых монотонно растут (в среднем на 0.1 - 0.2 в год), в то время как жертвы среди черных вернулись на уровень 2009 г. после пика в 2011 - 2013 гг.
Итак, на первый поставленный вопрос мы ответили:
- Можно ли сказать, что полицейские убивают черных чаще, чем белых?
- Да, это верный вывод. От рук закона черных гибнет в среднем в 2.6 раз больше, чем белых.
Держа в голове эти промежуточные выводы, идем дальше - посмотрим данные по преступлениям, чтобы понять, как они соотносятся с расовой принадлежностью и жертвами от рук стражей закона.
Данные по преступлениям

Загружаем наш CSV по преступлениям:
CRIMES_FILE = ROOT_FOLDER + '\\culprits_victims.csv'
df_crimes = pd.read_csv(CRIMES_FILE, sep=';', header=0, index_col=0, usecols=['Year', 'Offense', 'Offender/Victim', 'White', 'White pro capita', 'Black', 'Black pro capita'])Здесь опять-таки используем только необходимые столбцы: год, вид преступления, классификатор и данные по количеству преступлений, совершенных черными и белыми (абсолютные - "White", "Black" и удельные на человека - "White pro capita", "Black pro capita").
Взглянем на данные (`df_crimes.head()`):
Offense | Offender/Victim | Black | White | Black pro capita | White pro capita | |
|---|---|---|---|---|---|---|
Year | ||||||
1991 | All Offenses | Offender | 490 | 598 | 1.518188e-05 | 2.861673e-06 |
1991 | All Offenses | Offender | 4 | 4 | 1.239337e-07 | 1.914160e-08 |
1991 | All Offenses | Offender | 508 | 122 | 1.573958e-05 | 5.838195e-07 |
1991 | All Offenses | Offender | 155 | 176 | 4.802432e-06 | 8.422314e-07 |
1991 | All Offenses | Offender | 13 | 19 | 4.027846e-07 | 9.092270e-08 |
Нам пока не нужны данные по жертвам преступлений. Убираем лишние данные и столбцы:
# оставляем только преступников (убираем жертв)
df_crimes1 = df_crimes.loc[df_crimes['Offender/Victim'] == 'Offender']
# берем исследуемый период (2000-2018) и удаляем лишние столбцы
df_crimes1 = df_crimes1.loc[2000:2018, ['Offense', 'White', 'White pro capita', 'Black', 'Black pro capita']]Получили такой датасет (1295 строк * 5 столбцов):
Offense | White | White pro capita | Black | Black pro capita | |
|---|---|---|---|---|---|
Year | |||||
2000 | All Offenses | 679 | 0.000003 | 651 | 0.000018 |
2000 | All Offenses | 11458 | 0.000052 | 30199 | 0.000853 |
2000 | All Offenses | 4439 | 0.000020 | 3188 | 0.000090 |
2000 | All Offenses | 10481 | 0.000048 | 5153 | 0.000146 |
2000 | All Offenses | 746 | 0.000003 | 63 | 0.000002 |
... | ... | ... | ... | ... | ... |
2018 | Larceny Theft Offenses | 1961 | 0.000008 | 1669 | 0.000040 |
2018 | Larceny Theft Offenses | 48616 | 0.000206 | 30048 | 0.000722 |
2018 | Drugs Narcotic Offenses | 555974 | 0.002354 | 223398 | 0.005368 |
2018 | Drugs Narcotic Offenses | 305052 | 0.001292 | 63785 | 0.001533 |
2018 | Weapon Law Violation | 70034 | 0.000297 | 58353 | 0.001402 |
Теперь нам надо превратить удельные показатели на 1 человека в удельные на 1 миллион (так как именно эти данные используются во всем исследовании). Для этого просто умножаем на миллион соответствующие столбцы:
df_crimes1['White_promln'] = df_crimes1['White pro capita'] * 1e6
df_crimes1['Black_promln'] = df_crimes1['Black pro capita'] * 1e6Чтобы увидеть целую картину, как соотносится количество преступлений между белыми и черными по видам преступлений (в абсолютном выражении), просуммируем годовые наблюдения:
df_crimes_agg = df_crimes1.groupby(['Offense']).sum().loc[:, ['White', 'Black']]White | Black | |
|---|---|---|
Offense | ||
All Offenses | 44594795 | 22323144 |
Assault Offenses | 12475830 | 7462272 |
Drugs Narcotic Offenses | 9624596 | 3453140 |
Larceny Theft Offenses | 9563917 | 4202235 |
Murder And Nonnegligent Manslaughter | 28913 | 39617 |
Sex Offenses | 833088 | 319366 |
Weapon Law Violation | 829485 | 678861 |
Или в виде графика:
df_crimes_agg.plot.barh()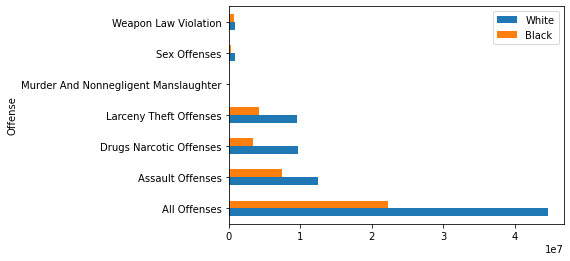
Итак, видим, что:
В количественном отношении нападения, наркотики, воровство и "все преступления" сильно превалируют над преступлениями, связанными с убийством, оружием и сексом
В абсолютных значениях белые совершают больше преступлений, чем черные (ровно в 2 раза для категории "все преступления")
Опять понимаем, что без информации о численности никакие выводы о "криминальности" рас не сделаешь. Соответственно, посмотрим на удельные показатели:
df_crimes_agg1 = df_crimes1.groupby(['Offense']).sum().loc[:, ['White_promln', 'Black_promln']]White_promln | Black_promln | |
|---|---|---|
Offense | ||
All Offenses | 194522.307758 | 574905.952459 |
Assault Offenses | 54513.398833 | 192454.602875 |
Drugs Narcotic Offenses | 41845.758869 | 88575.523095 |
Larceny Theft Offenses | 41697.303725 | 108189.184125 |
Murder And Nonnegligent Manslaughter | 125.943007 | 1016.403706 |
Sex Offenses | 3633.777035 | 8225.144985 |
Weapon Law Violation | 3612.671402 | 17389.163849 |
И на графике:
df_crimes_agg1.plot.barh()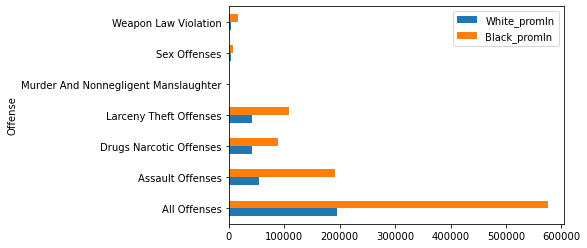
Здесь уже совсем иная картина. По всем видам преступлений (из анализируемых) черные совершают больше, чем белые. По категории "все преступления" эта разница составляет почти 3 раза.
Давайте теперь оставим только категорию "все преступления" (All Offenses) как наиболее представительную, только удельные показатели по преступлениям (на миллион человек) и сгруппируем данные по годам (так как в исходных данных на каждый год может быть несколько записей - по количеству служб, предоставивших данные).
# оставляем только 'All Offenses' = все преступления
df_crimes1 = df_crimes1.loc[df_crimes1['Offense'] == 'All Offenses']
# чтобы использовать другую выборку, можем, например, оставить нападения и убийства:
#df_crimes1 = df_crimes1.loc[df_crimes1['Offense'].str.contains('Assault|Murder')]
# убираем абсолютные значения и агрегируем по годам
df_crimes1 = df_crimes1.groupby(level=0).sum().loc[:, ['White_promln', 'Black_promln']]Полученный датасет:
White_promln | Black_promln | |
|---|---|---|
Year | ||
2000 | 6115.058976 | 17697.409882 |
2001 | 6829.701429 | 20431.707645 |
2002 | 7282.333249 | 20972.838329 |
2003 | 7857.691182 | 22218.966500 |
2004 | 8826.576863 | 26308.815799 |
2005 | 9713.826255 | 30616.569637 |
2006 | 10252.894313 | 33189.382429 |
2007 | 10566.527362 | 34100.495064 |
2008 | 10580.520024 | 34052.276749 |
2009 | 10889.263592 | 33954.651792 |
2010 | 10977.017218 | 33884.236826 |
2011 | 11035.346176 | 32946.454471 |
2012 | 11562.836825 | 33150.706035 |
2013 | 11211.113491 | 32207.571607 |
2014 | 11227.354594 | 31517.346141 |
2015 | 11564.786088 | 31764.865490 |
2016 | 12193.026562 | 33186.064958 |
2017 | 12656.261666 | 34900.390499 |
2018 | 13180.171893 | 37805.202605 |
Посмотрим на графике:
plt = df_crimes1.plot(xticks=df_crimes1.index)
plt.set_xticklabels(df_fenc_agg.index, rotation='vertical')
plt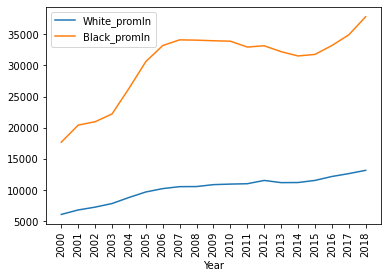
Промежуточные выводы:
1. Белые совершают в 2 раза больше преступлений, чем черные, в абсолютном выражении, но в 3 раза меньше в относительном выражении (на миллион представителей своей расы).
2. Преступность среди белых относительно монотонно растет на протяжении всего периода (выросла в 2 раза за 18 лет). Преступность среди черных также растет, но скачкообразно: с 2001 по 2006 г. резкий рост, с 2007 по 2016 она даже убывала, с 2017 года опять резкий рост. За весь период преступность среди черных выросла также в 2 раза (аналогично белым).
3. Если не принимать во внимание спад среди черной преступности в 2007-2016 гг., преступность среди черных растет более быстрыми темпами, чем среди белых.
Итак, мы ответили на второй вопрос:
- Представители какой расы статистически чаще совершают преступления?
- Черные статистически совершают преступления в 3 раза чаще белых.
Криминальность и гибель от рук полиции
Теперь мы подошли к самому важному: необходимо ответить на третий поставленный вопрос, а именно "Можно ли сказать, что полиция стреляет насмерть пропорционально количеству совершаемых преступлений?"
То есть надо как-то проследить корреляцию между двумя нашими наборами данных - данных по жертвам полиции и данных по преступлениям.
Начнем с того, что объединим эти два датасета в один:
# объединяем датасеты
df_uof_crimes = df_fenc_agg.join(df_crimes1, lsuffix='_uof', rsuffix='_cr')
# удаляем лишние столбцы (абс. показатели по жертвам)
df_uof_crimes = df_uof_crimes.loc[:, 'White_pop':'Black_promln_cr']Что получили?
White_pop | Black_pop | White_promln_uof | Black_promln_uof | White_promln_cr | Black_promln_cr | |
|---|---|---|---|---|---|---|
Year | ||||||
2000 | 218756353 | 35410436 | 1.330247 | 4.179559 | 6115.058976 | 17697.409882 |
2001 | 219843871 | 35758783 | 1.605685 | 4.418495 | 6829.701429 | 20431.707645 |
2002 | 220931389 | 36107130 | 1.643044 | 4.458953 | 7282.333249 | 20972.838329 |
2003 | 222018906 | 36455476 | 1.747599 | 4.910099 | 7857.691182 | 22218.966500 |
2004 | 223106424 | 36803823 | 1.949742 | 4.265861 | 8826.576863 | 26308.815799 |
2005 | 224193942 | 37152170 | 2.016112 | 4.871855 | 9713.826255 | 30616.569637 |
2006 | 225281460 | 37500517 | 2.041890 | 5.653255 | 10252.894313 | 33189.382429 |
2007 | 226368978 | 37848864 | 1.983487 | 5.786171 | 10566.527362 | 34100.495064 |
2008 | 227456495 | 38197211 | 1.943229 | 5.576323 | 10580.520024 | 34052.276749 |
2009 | 228544013 | 38545558 | 2.091501 | 6.459888 | 10889.263592 | 33954.651792 |
2010 | 229397472 | 38874625 | 2.205778 | 5.633495 | 10977.017218 | 33884.236826 |
2011 | 230838975 | 39189528 | 2.499578 | 7.399936 | 11035.346176 | 32946.454471 |
2012 | 231992377 | 39623138 | 2.724227 | 7.621809 | 11562.836825 | 33150.706035 |
2013 | 232969901 | 39919371 | 2.974633 | 7.765653 | 11211.113491 | 32207.571607 |
2014 | 233963128 | 40379066 | 3.009021 | 6.538041 | 11227.354594 | 31517.346141 |
2015 | 234940100 | 40695277 | 3.102919 | 6.683822 | 11564.786088 | 31764.865490 |
2016 | 234644039 | 40893369 | 3.081263 | 6.578084 | 12193.026562 | 33186.064958 |
2017 | 235507457 | 41393491 | 3.154889 | 6.401973 | 12656.261666 | 34900.390499 |
2018 | 236173020 | 41617764 | 3.281493 | 6.367473 | 13180.171893 | 37805.202605 |
Давайте вспомним, что хранится в каждом поле:
White_pop - численность белых
Black_pop - численность черных
White promln_uof - количество жертв полиции среди белых (на 1 млн)
Black promln_uof - количество жертв полиции среди черных (на 1 млн)
White promln_cr - количество преступлений, совершенных белыми (на 1 млн)
Black promln_cr - количество преступлений, совершенных черными (на 1 млн)
Наверное, можно было бы не полениться и дать этим столбцам русские названия... Но я надеюсь, читатели меня простят :)
Взглянем, как соотносятся графики преступлений и жертв полиции для каждой расы. Начнем с белых - в шахматном порядке :)
plt = df_uof_crimes['White_promln_cr'].plot(xticks=df_uof_crimes.index, legend=True)
df_uof_crimes['White_promln_uof'].plot(xticks=df_uof_crimes.index, legend=True, secondary_y=True, style='g')
plt.set_xticklabels(df_uof_crimes.index, rotation='vertical')
plt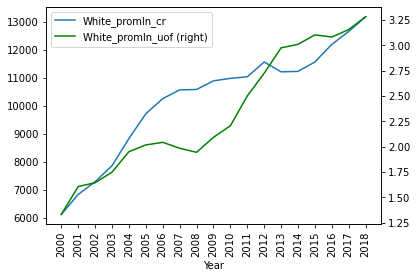
То же самое на диаграмме рассеяния:
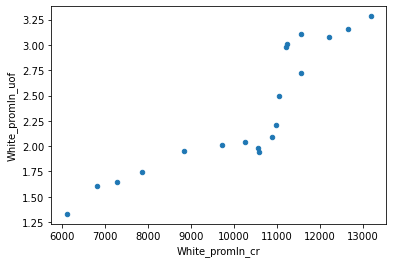
Отметим мимоходом, что определенная корреляция есть. ОК, теперь то же для черных:
plt = df_uof_crimes['Black_promln_cr'].plot(xticks=df_uof_crimes.index, legend=True)
df_uof_crimes['Black_promln_uof'].plot(xticks=df_uof_crimes.index, legend=True, secondary_y=True, style='g')
plt.set_xticklabels(df_uof_crimes.index, rotation='vertical')
plt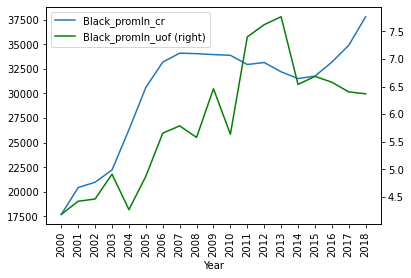
И скаттерплот:
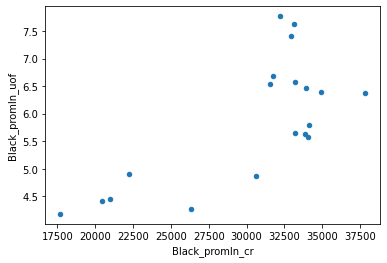
Здесь все намного хуже: тренды явно "пляшут", хотя общая тенденция все равно прослеживается: пропорция здесь явно прямая, хотя и нелинейная.
Давайте воспользуемся методами матстатистики для определения величины этих корреляций, построив корреляционную матрицу на основе коэффициента Пирсона:
df_corr = df_uof_crimes.loc[:, ['White_promln_cr', 'White_promln_uof', 'Black_promln_cr', 'Black_promln_uof']].corr(method='pearson')
df_corr.style.background_gradient(cmap='PuBu')Получаем такую картинку:
White_promln_cr | White_promln_uof | Black_promln_cr | Black_promln_uof | |
|---|---|---|---|---|
White_promln_cr | 1.000000 | 0.885470 | 0.949909 | 0.802529 |
White_promln_uof | 0.885470 | 1.000000 | 0.710052 | 0.795486 |
Black_promln_cr | 0.949909 | 0.710052 | 1.000000 | 0.722170 |
Black_promln_uof | 0.802529 | 0.795486 | 0.722170 | 1.000000 |
Коэффициенты корреляции для обеих рас выделены жирным: для белых = 0.885, для черных = 0.722. Таким образом, положительная корреляция между гибелью от полиции и преступностью прослеживается и для белых, и для черных, но для белых она гораздо выше (статистически значима), в то время как для черных она близка к статистической незначимости. Последний результат, конечно, связан с большей неоднородностью данных как по жертвам полиции, так и по преступлениям среди черных.
Напоследок для этой статьи попробуем выяснить, какова вероятность белых и черных преступников быть застреленным полицией. Прямых способом это выяснить у нас нет (нет данных по тому, кто из погибших от рук полиции был зарегистрирован как преступник, а кто как невинная жертва). Поэтому пойдем простым путем: разделим удельное количество жертв полиции на удельное количество преступлений по каждой расовой группе (и умножим на 100, чтобы выразить в %):
# агрегированные значения (по годам)
df_uof_crimes_agg = df_uof_crimes.loc[:, ['White_promln_cr', 'White_promln_uof', 'Black_promln_cr', 'Black_promln_uof']].agg(['mean', 'sum', 'min', 'max'])
# "вероятность" преступника быть застреленным
df_uof_crimes_agg['White_uof_cr'] = df_uof_crimes_agg['White_promln_uof'] * 100. / df_uof_crimes_agg['White_promln_cr']
df_uof_crimes_agg['Black_uof_cr'] = df_uof_crimes_agg['Black_promln_uof'] * 100. / df_uof_crimes_agg['Black_promln_cr']Получаем такие данные:
White_promln_cr | White_promln_uof | Black_promln_cr | Black_promln_uof | White_uof_cr | Black_uof_cr | |
|---|---|---|---|---|---|---|
mean | 10238.016198 | 2.336123 | 30258.208024 | 5.872145 | 0.022818 | 0.019407 |
sum | 194522.307758 | 44.386338 | 574905.952459 | 111.570747 | 0.022818 | 0.019407 |
min | 6115.058976 | 1.330247 | 17697.409882 | 4.179559 | 0.021754 | 0.023617 |
max | 13180.171893 | 3.281493 | 37805.202605 | 7.765653 | 0.024897 | 0.020541 |
Отобразим полученные значения в виде столбчатой диаграммы:
plt = df_uof_crimes_agg.loc['mean', ['White_uof_cr', 'Black_uof_cr']].plot.bar()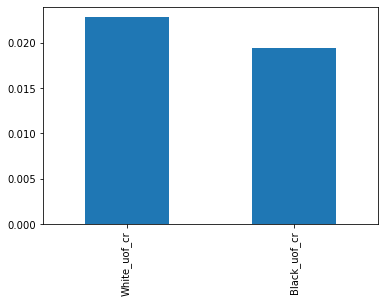
На диаграмме видно, что вероятность белого преступника быть застреленным несколько выше, чем черного преступника. Конечно, этот анализ весьма условный, но все же дает какое-то представление.
Промежуточные выводы:
1. Гибель от рук полиции связана с криминальностью (количеством совершаемых преступлений). При этом эта корреляция неоднородна по расам: для белых она близка к идеальной, для черных далека от идеальной.
2. При рассмотрении совмещенных диаграмм гибели от полиции и преступности видно, что фатальные встречи с полицией растут "в ответ" на рост преступности, с лагом в несколько лет (особенно видно по данным среди черных). Это согласуется с логическим предположением о том, что власти "отвечают" на преступность (больше преступлений -> больше безнаказанности -> больше стычек с представителями закона -> больше смертельных исходов).
3. Белые преступники немного чаще встречают смерть от рук полиции, чем черные. Однако эта разница почти несущественна.
Итак, ответ на третий вопрос:
- Можно ли сказать, что полиция стреляет насмерть пропорционально количеству совершаемых преступлений?
- Да, такая корреляция наблюдается, хотя она неоднородна по расам: для белых почти идеальная, для черных - почти неидеальная.
В следующей части статьи посмотрим на географическое распределение анализируемых данных по штатам США.


