

1. Введение
В первой части статьи мы обсуждали разработку самого нижнего слоя СУБД Boson - CachedFileIO. Как упоминалось, статистика такого явления как Locality of Reference говорит о том, что в реальных приложениях ~95% запросов к данным локализованы в 10-15% базы данных. При этом среднее соотношение чтения/записи - 70%/30%. Это делает эффективным использование кэша (cache) работающего на основе алгоритма Least Recently Used (LRU). Реализовав его, мы получили 260%-600% прироста скорости чтения при 87%-97% cache hits.
Если вспомнить упрощенную архитектуру Boson, то она поделена на четыре основных программных слоя, каждый из которых предоставляет очередной уровень абстракции.

2. Функциональные требования
Следующим после кэша слоем СУБД Boson является хранилище записей RecordFileIO. Это уже первый прообраз базы данных, который начинает приносить прикладную пользу. Сформулируем верхнеуровневую спецификацию требований:
Хранение записей произвольной* длины (создание, чтение, изменение, удаление). Произвольную длину будем понимать как бинарные записи размером до 4Gb.
Навигация по записям как по двусвязному списку (первая, последняя, следующая, предыдущая), а также служебная возможность прямого указания позиции в файле.
Повторное использование пространства удалённых записей.
Проверка целостности данных и заголовков на основе контрольных сумм.
3. Структуры данных
Для реализации перечисленных требований, нам потребуется организовать следующую структуру данных в кэшированном файле, которая наряду с заголовком хранилища, будет содержать два двусвязных списка: записей данных и удаленных записей для повторного использования при создании новых.

Нарисовать диаграмму заняло гораздо больше времени, чем описать заголовок хранилища и заголовок записи в коде. Они будут иметь следующую простую структуру:
//----------------------------------------------------------------------------
// Boson storage header signature and version
//----------------------------------------------------------------------------
constexpr uint32_t BOSONDB_SIGNATURE = 0x42445342;
constexpr uint32_t BOSONDB_VERSION = 0x00000001;
//----------------------------------------------------------------------------
// Boson storage header structure (64 bytes)
//----------------------------------------------------------------------------
typedef struct {
uint32_t signature; // BOSONDB signature
uint32_t version; // Format version
uint64_t endOfFile; // Size of file
uint64_t totalRecords; // Total number of records
uint64_t firstRecord; // First record offset
uint64_t lastRecord; // Last record offset
uint64_t totalFreeRecords; // Total number of free records
uint64_t firstFreeRecord; // First free record offset
uint64_t lastFreeRecord; // Last free record offset
} StorageHeader;
//----------------------------------------------------------------------------
// Record header structure (32 bytes)
//----------------------------------------------------------------------------
typedef struct {
uint64_t next; // Next record position in data file
uint64_t previous; // Previous record position in data file
uint32_t recordCapacity; // Record capacity in bytes
uint32_t dataLength; // Data length in bytes
uint32_t dataChecksum; // Checksum for data consistency check
uint32_t headChecksum; // Checksum for header consistency check
} RecordHeader;На первый взгляд, может показаться, что часть полей в заголовке избыточна. Это так. Но он продиктован требованиями по возможности изменения записей, повторному использованию места удаленных записей, проверки целостности по контрольным суммам и возможности навигации как в прямом, так и обратном порядке. В конечном итоге, мы будем хранить JSON документы, поэтому ожидается, что размер большинства записей будет примерно в диапазоне 512-2048 байт и размер заголовка в 32 байта будет приемлемым.
4. Реализация RecordFileIO
Сама реализация будет иметь следующую простую логику:
Файл записей открывается на основе объекта CachedFile. Если файл не смогли открыть, кидаем исключение. Если файл оказался пустым, но доступен для записи, то создаем заголовки хранилища, чтобы можно было работать дальше. Если же файл не пустой или заголовок не корректный или битый (не сошлась контрольная сумма), то кидаем исключение.
Создание записи. Если список удаленных записей пустой, либо среди удаленных записей нет необходимой ёмкости, то добавляем новую запись в конец файла (по данным из заголовка). Связываем последнюю запись с новой. Обновляем заголовок хранилища с указанием нового конца файла и новой последней записи. Записываем данные. Сохраняем в заголовок контрольную сумму данных. Сохраняем в конце заголовка контрольную сумму заголовка. Если же в списке удаленных записей есть необходимой ёмкости (пробегаемся по списку), то связываем её с последней записью, записываем данные и обновляем её заголовок с контрольными суммами.
Обновление записи. Если длина обновляемых данных меньше или равна ёмкости записи, просто обновляем данные. Если же новые данные больше ёмкости записи, то удаляем текущую запись. Создаём новую запись, затем связываем вновь созданную с предыдущей и следующей записью той что удалили. Сохраняем в заголовок записи контрольную сумму данных. Сохраняем в конце заголовка контрольную сумму заголовка.
Удаление записи. Связываем предыдущую и следующую запись напрямую. А удаленную запись добавляем в конец списка удаленных записей.
Навигация по записям. Позиция первой и последней записи берётся из заголовка хранилища. Перемещение вперёд и назад по записям осуществляется на основе информации о предыдущей и следующей записи в заголовке текущей записи. Переход на абсолютную позицию в файле проверяет корректность контрольной суммы заголовка записи.
В первом приближении, определение класса RecordFileIO выглядит следующим образом:
class RecordFileIO {
public:
RecordFileIO(CachedFileIO& cachedFile, size_t freeDepth = NOT_FOUND);
~RecordFileIO();
uint64_t getTotalRecords();
uint64_t getTotalFreeRecords();
void setFreeRecordLookupDepth(uint64_t maxDepth) { freeLookupDepth = maxDepth; }
// records navigation
bool setPosition(uint64_t offset);
uint64_t getPosition();
bool first();
bool last();
bool next();
bool previous();
// create, read, update, delete (CRUD)
uint64_t createRecord(const void* data, uint32_t length);
uint64_t removeRecord();
uint32_t getDataLength();
uint32_t getRecordCapacity();
uint64_t getNextPosition();
uint64_t getPrevPosition();
uint64_t getRecordData(void* data, uint32_t length);
uint64_t setRecordData(const void* data, uint32_t length);
private:
CachedFileIO& cachedFile;
StorageHeader storageHeader;
RecordHeader recordHeader;
size_t currentPosition;
size_t freeLookupDepth;
void initStorageHeader();
bool saveStorageHeader();
bool loadStorageHeader();
uint64_t getRecordHeader(uint64_t offset, RecordHeader& result);
uint64_t putRecordHeader(uint64_t offset, RecordHeader& header);
uint64_t allocateRecord(uint32_t capacity, RecordHeader& result);
uint64_t createFirstRecord(uint32_t capacity, RecordHeader& result);
uint64_t appendNewRecord(uint32_t capacity, RecordHeader& result);
uint64_t getFromFreeList(uint32_t capacity, RecordHeader& result);
bool putToFreeList(uint64_t offset);
void removeFromFreeList(RecordHeader& freeRecord);
uint32_t checksum(const uint8_t* data, uint64_t length);
};Вот тут вы можете посмотреть саму реализацию класса RecordFileIO.cpp.
6. Функциональное тестирование
Сначала проверим базовый функционал, что записи добавляются. Ссылки корректны и данные целостны. Для этих целей запишем 10 записей (в данном случае строк текста с переменной длиной) в базу и закроем её. Откроем заново, прочитаем со служебной информацией и выведем в консоль.

Вроде бы, записи записываются и читаются ровно, ссылки корректные и длины записей корректны. Давайте посмотрим через HEX редактор, проверив поля заголовка хранилища и первой записи. По умолчанию мы пишем цифры в файле Big-Endian формате, когда младшие байты в начале, старшие в конце. На других системах может быть по другому, но пока будем тестировать под Win x64. Проверил заголовки записей, всё корректно.

Теперь проверим механизм удаления записей и проверим все ли ссылки будут корректны. Удалим четные записи и заодно прочитаем их в обратном порядке с конца хранилища. И посмотрим что получится (должно остаться 5 записей, ссылки верны, в обратном порядке):

Удаление работает корректно. А теперь вставим 3 записи заведомо меньше длины, чтобы использовалось место ранее удаленных записей. Выведем записи в консоль в прямом порядке. Посмотрим что получилось (порядок верный, новые записи заполнили место удаленных записей в позициях 64, 321, 508):
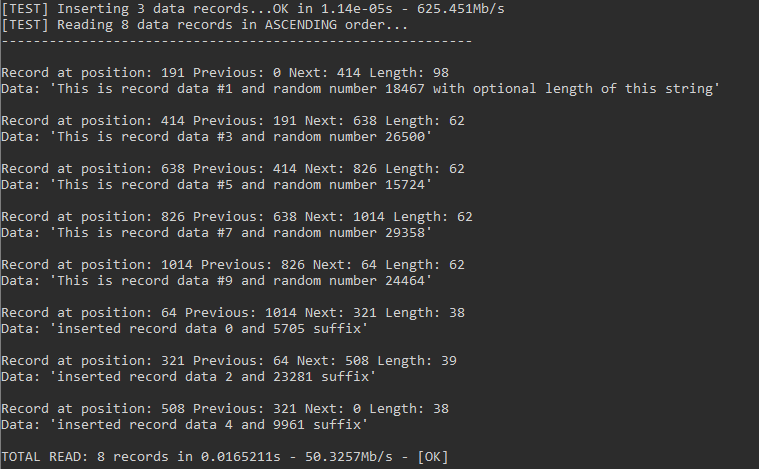
Сработало. Теперь посмотрим общую нагрузочный тест по записи и чтению миллиона записей. Пока проверим как есть.
")
В целом неплохо, с учётом того, что в нашем тесте чтение не последовательное и при каждом записи считается, а при чтении проверяется контрольная сумма заголовка и самих данных. Конечно же, в коде много есть где наводить порядок и оптимизировать производительность. Но сделаю это позже. Вот тут исходный код теста на коленках.
Таким образом, мы реализовали второй архитектурный слой СУБД Boson - Record File IO (хранилище записей), который решает следующие задачи: возможность создания, удаления, изменения записей, повторному использованию места удаленных записей, проверки целостности по контрольным суммам и возможности навигации как в прямом, так и обратном порядке. Разработанный класс задачу решает - и это отлично!
До встречи!
. Расширения Kotest и Spring Test")
")


")