

Всем привет! Меня зовут Дмитрий Самсонов, я работаю ведущим системным администратором в «Одноклассниках». У нас более 7 тыс. физических серверов, 11 тыс. контейнеров в нашем облаке и 200 приложений, которые в различной конфигурации формируют 700 различных кластеров. Подавляющее большинство серверов работают под управлением CentOS 7.
14 августа 2018 г. была опубликована информация об уязвимости FragmentSmack
(CVE-2018-5391) и SegmentSmack (CVE-2018-5390). Это уязвимости с сетевым вектором атаки и достаточно высокой оценкой (7.5), которая грозит отказом в обслуживании (DoS) из-за исчерпания ресурсов (CPU). Фикс в ядре для FragmentSmack на тот момент предложен не был, более того, он вышел значительно позже публикации информации об уязвимости. Для устранения SegmentSmack предлагалось обновить ядро. Сам пакет с обновлением был выпущен в тот же день, оставалось только установить его.
Нет, мы совсем не против обновления ядра! Однако есть нюансы…
Как мы обновляем ядро на проде
В общем-то, ничего сложного:
- Cкачать пакеты;
- Установить их на некоторое количество серверов (включая серверы, хостящие наше облако);
- Убедиться, что ничего не сломалось;
- Удостовериться, что все стандартные настройки ядра применились без ошибок;
- Подождать несколько дней;
- Проверить показатели серверов;
- Переключить деплой новых серверов на новое ядро;
- Обновить все серверы по дата-центрам (один дата-центр за раз, чтобы минимизировать эффект для пользователей в случае проблем);
- Перезагрузить все серверы.
Повторить для всех веток имеющихся у нас ядер. На данный момент это:
- Стоковое CentOS 7 3.10 — для большинства обычных серверов;
- Ванильное 4.19 — для нашего облака one-cloud, потому что нам нужен BFQ, BBR и т.д.;
- Elrepo kernel-ml 5.2 — для высоконагруженных раздатчиков, потому что 4.19 раньше вёл себя нестабильно, а фичи нужны те же.
Как вы могли догадаться, больше всего времени занимает перезагрузка тысяч серверов. Поскольку не все уязвимости критичны для всех серверов, то мы перезагружаем только те, которые напрямую доступны из интернета. В облаке, чтобы не ограничивать гибкость, мы не привязываем доступные извне контейнеры к отдельным серверам с новым ядром, а перезагружаем все хосты без исключения. К счастью, там процедура проще, чем с обычными серверами. Например, stateless-контейнеры могут просто переехать на другой сервер во время ребута.
Тем не менее работы всё равно много, и она может занимать несколько недель, а при возникновении каких-либо проблем с новой версией — до нескольких месяцев. Злоумышленники это прекрасно понимают, поэтому нужен план «Б».
FragmentSmack/SegmentSmack. Workaround
К счастью, для некоторых уязвимостей такой план «Б» существует, и называется он Workaround. Чаще всего это изменение настроек ядра/приложений, которые позволяют минимизировать возможный эффект или полностью исключить эксплуатацию уязвимостей.
В случае с FragmentSmack/SegmentSmack предлагался такой Workaround:
«Можно изменить дефолтные значения 4MB и 3MB в net.ipv4.ipfrag_high_thresh и net.ipv4.ipfrag_low_thresh (и их аналоги для ipv6 net.ipv6.ipfrag_high_thresh и net.ipv6.ipfrag_low_thresh) на 256 kB и 192 kB соответственно или ниже. Тесты показывают от небольшого до значительного падения использования CPU во время атаки в зависимости от оборудования, настроек и условий. Однако может быть некоторое влияние на производительность из-за ipfrag_high_thresh=262144 bytes, так как только два 64K-фрагмента могут одновременно уместиться в очереди на пересборку. Например, есть риск, что приложения, работающие с большими UDP-пакетами, поломаются».
Сами параметры в документации ядра описаны так:
ipfrag_high_thresh - LONG INTEGER
Maximum memory used to reassemble IP fragments.ipfrag_low_thresh - LONG INTEGER
Maximum memory used to reassemble IP fragments before the kernel
begins to remove incomplete fragment queues to free up resources.
The kernel still accepts new fragments for defragmentation.На продакшен-сервисах больших UDP у нас нет. В LAN фрагментированный трафик отсутствует, в WAN есть, но не значительный. Ничто не предвещает — можно накатывать Workaround!
FragmentSmack/SegmentSmack. Первая кровь
Первая проблема, с которой мы столкнулись, заключалась в том, что облачные контейнеры порой применяли новые настройки лишь частично (только ipfrag_low_thresh), а иногда не применяли вообще — просто падали на старте. Стабильно воспроизвести проблему не удавалось (вручную все настройки применялись без каких-либо сложностей). Понять, почему падает контейнер на старте, тоже не так-то просто: никаких ошибок не обнаружено. Одно было известно точно: откат настроек решает проблему с падением контейнеров.
Почему недостаточно применить Sysctl на хосте? Контейнер живёт в своём выделенном сетевом Namespace, поэтому по крайней мере часть сетевых Sysctl-параметров в контейнере может отличаться от хоста.
Как именно применяются настройки Sysctl в контейнере? Так как контейнеры у нас непривилегированные, изменить любую настройку Sysctl, зайдя в сам контейнер, не получится — просто не хватит прав. Для запуска контейнеров наше облако на тот момент использовало Docker (сейчас уже Podman). Докеру через API передавались параметры нового контейнера, в том числе нужные настройки Sysctl.
В ходе перебора версий выяснилось, что API Docker не отдавало все ошибки (по крайней мере, в версии 1.10). При попытке запустить контейнер через “docker run” мы, наконец-то, увидели хоть что-то:
write /proc/sys/net/ipv4/ipfrag_high_thresh: invalid argument docker: Error response from daemon: Cannot start container <...>: [9] System error: could not synchronise with container process.Значение параметра не валидное. Но почему? И почему оно не валидное только иногда? Выяснилось, что Docker не гарантирует порядок применения параметров Sysctl (последняя проверенная версия — 1.13.1), поэтому иногда ipfrag_high_thresh пытался выставиться на 256K, когда ipfrag_low_thresh ещё был 3M, то есть верхняя граница была ниже, чем нижняя, что и приводило к ошибке.
На тот момент у нас уже использовался свой механизм доконфигуривания контейнера после старта (заморозка контейнера через cgroup freezer и выполнение команд в namespace контейнера через ip netns), и мы добавили в эту часть также прописывание Sysctl-параметров. Проблема была решена.
FragmentSmack/SegmentSmack. Первая кровь 2
Не успели мы разобраться с применением Workaround в облаке, как стали поступать первые редкие жалобы от пользователей. На тот момент прошло несколько недель с начала применения Workaround на первых серверах. Первичное расследование показало, что жалобы поступали на отдельные сервисы, и не на все серверы данных сервисов. Проблема вновь обрела крайне неопределённый характер.
В первую очередь мы, конечно, попробовали откатить настройки Sysctl, но это не дало никакого эффекта. Различные манипуляции с настройками сервера и приложения тоже не помогли. Помог reboot. Reboot для Linux столь же противоестественен, сколь он был нормальным условием для работы с Windows в былые дни. Тем не менее он помог, и мы списали всё на «глюк в ядре» при применении новых настроек в Sysctl. Как же это было легкомысленно…
Через три недели проблема повторилась. Конфигурация этих серверов была довольно простой: Nginx в режиме прокси/балансировщика. Трафика немного. Новая вводная: на клиентах с каждым днём увеличивается количество 504-х ошибок (Gateway Timeout). На графике показано число 504-х ошибок в день по этому сервису:
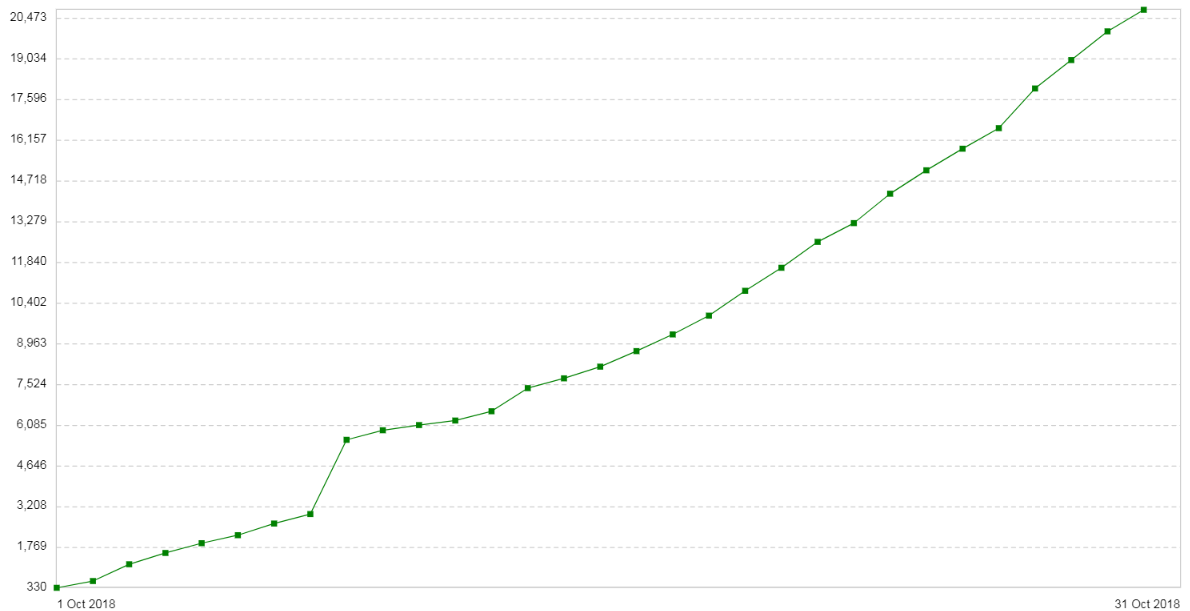
Все ошибки про один и тот же бекенд — про тот, который находится в облаке. График потребления памяти под фрагменты пакетов на этом бекенде выглядел следующим образом:
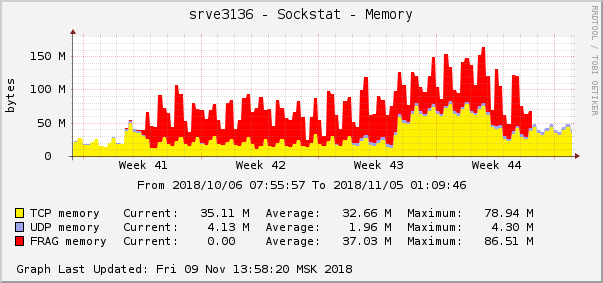
Это одно из самых ярких проявлений проблемы на графиках операционной системы. В облаке как раз в это же время была пофикшена другая сетевая проблема с настройками QoS (Traffic Control). На графике потребления памяти под фрагменты пакетов она выглядела точно так же:
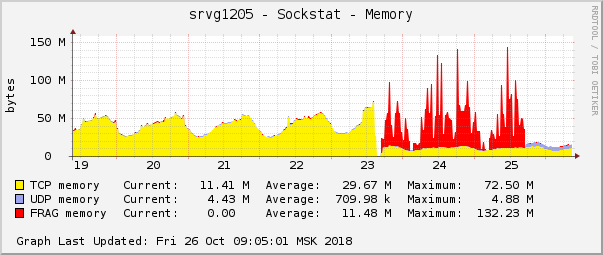
Предположение было простым: если на графиках они выглядят одинаково, то и причина у них одинаковая. Тем более, что какие-либо проблемы с этим типом памяти случаются чрезвычайно редко.
Суть пофикшенной проблемы заключалась в том, что мы использовали в QoS пакетный шедуллер fq с дефолтными настройками. По умолчанию для одного соединения он позволяет добавлять в очередь 100 пакетов и некоторые соединения в ситуации нехватки канала стали забивать очередь до отказа. В этом случае пакеты дропаются. В статистике tc (tc -s qdisc) это видно так:
qdisc fq 2c6c: parent 1:2c6c limit 10000p flow_limit 100p buckets 1024 orphan_mask 1023 quantum 3028 initial_quantum 15140 refill_delay 40.0ms
Sent 454701676345 bytes 491683359 pkt (dropped 464545, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
1024 flows (1021 inactive, 0 throttled)
0 gc, 0 highprio, 0 throttled, 464545 flows_plimit«464545 flows_plimit» — это и есть пакеты, дропнутые из-за превышения лимита очереди одного соединения, а «dropped 464545» — это сумма всех дропнутых пакетов этого шедулера. После увеличения длины очереди до 1 тыс. и рестарта контейнеров проблема перестала проявляться. Можно откинуться в кресле и выпить смузи.
FragmentSmack/SegmentSmack. Последняя кровь
Во-первых, спустя несколько месяцев после анонса уязвимостей в ядре, наконец, появился фикс для FragmentSmack (напомню, что вместе с анонсом в августе вышел фикс только для SegmentSmack), что дало шанс отказаться от Workaround, который доставил нам довольно много неприятностей. Часть серверов за это время мы уже успели перевести на новое ядро, и теперь надо было начинать с начала. Зачем мы обновляли ядро, не дожидаясь фикса FragmentSmack? Дело в том, что процесс защиты от этих уязвимостей совпал (и слился) с процессом обновления самого CentOS (что занимает ещё больше времени, чем обновление только ядра). К тому же SegmentSmack — более опасная уязвимость, а фикс для него появился сразу, так что смысл был в любом случае. Однако, просто обновить ядро на CentOS мы не могли, потому что уязвимость FragmentSmack, которая появилась во времена CentOS 7.5, была пофикшена только в версии 7.6, поэтому нам пришлось останавливать обновление до 7.5 и начинать всё заново с обновлением до 7.6. И так тоже бывает.
Во-вторых, к нам вернулись редкие жалобы пользователей на проблемы. Сейчас мы уже точно знаем, что все они связаны с аплоадом файлов от клиентов на некоторые наши серверы. Причём через эти серверы шло очень небольшое количество аплоадов от общей массы.
Как мы помним из рассказа выше, откат Sysctl не помогал. Помогал Reboot, но временно.
Подозрения с Sysctl не были сняты, но на этот раз требовалось собрать как можно больше информации. Также крайне не хватало возможности воспроизвести проблему с аплоадом на клиенте, чтобы более точечно изучить, что происходит.
Анализ всей доступной статистики и логов не приблизил нас к пониманию происходящего. Остро не хватало возможности воспроизвести проблему, чтобы «пощупать» конкретное соединение. Наконец, разработчикам на спецверсии приложения удалось добиться стабильного воспроизведения проблем на тестовом устройстве при подключении через Wi-Fi. Это стало прорывом в расследовании. Клиент подключался к Nginx, тот проксировал на бекенд, которым являлось наше приложение на Java.
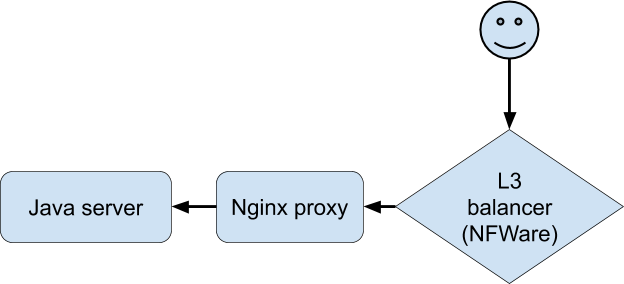
Диалог при проблемах был такой (зафиксирован на стороне Nginx-прокси):
- Клиент: запрос на получение информации о докачивании файла.
- Java-сервер: ответ.
- Клиент: POST с файлом.
- Java-сервер: ошибка.
Java-сервер при этом пишет в лог, что от клиента получено 0 байт данных, а Nginx-прокси — что запрос занял больше 30 секунд (30 секунд — это время таймаута у клиентского приложения). Почему же таймаут и почему 0 байт? С точки зрения HTTP всё работает так, как должно работать, но POST с файлом как будто пропадает из сети. Причём пропадает между клиентом и Nginx. Пришло время вооружиться Tcpdump! Но для начала надо понять конфигурацию сети. Nginx-прокси стоит за L3-балансировщиком NFware. Используется туннелирование для доставки пакетов от L3-балансировщика до сервера, которое добавляет свои хидеры в пакеты:

При этом сеть на этот сервер приходит в виде Vlan-теггированного трафика, которое тоже добавляет свои поля в пакеты:

А ещё этот трафик может фрагментироваться (тот самый небольшой процент входящего фрагментированного трафика, о котором мы говорили при оценке рисков от Workaround), что тоже меняет содержание хидеров:
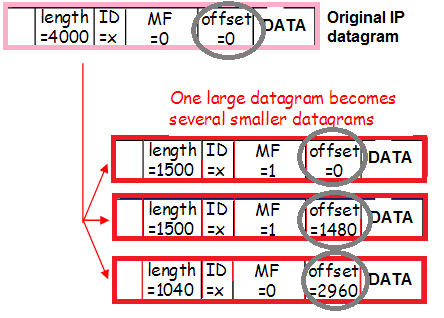
Ещё раз: пакеты инкапсулированы Vlan-тегом, инкапсулированы туннелем, фрагментированы. Чтобы точнее понять, как это происходит, проследим маршрут пакета от клиента до Nginx-прокси.
- Пакет попадает на L3-балансировщик. Для корректной маршрутизации внутри дата-центра пакет инкапсулируется в туннель и отправляется на сетевую карту.
- Так как пакет + хидеры туннеля не влезают в MTU, пакет режется на фрагменты и отправляется в сеть.
- Свитч после L3-балансировщика при получении пакета добавляет к нему Vlan-тег и отправляет дальше.
- Свитч перед Nginx-прокси видит (по настройкам порта), что сервер ожидает Vlan-инкапсулированный пакет, поэтому отправляет его, как есть, не убирая Vlan-тег.
- Linux получает фрагменты отдельных пакетов и склеивает их в один большой пакет.
- Далее пакет попадает на Vlan-интерфейс, где с него снимается первый слой — Vlan-инкапсулирование.
- Затем Linux отправляет его на Tunnel-интерфейс, где с него снимается ещё один слой — Tunnel-инкапсулирование.
Сложность в том, чтобы передать это всё в виде параметров в tcpdump.
Начнём с конца: есть ли чистые (без лишних заголовков) IP-пакеты от клиентов, со снятым vlan- и tunnel-инкапсулированием?
tcpdump host <ip клиента>Нет, таких пакетов на сервере не было. Таким образом, проблема должна быть раньше. Есть ли пакеты со снятым только Vlan-инкапсулированием?
tcpdump ip[32:4]=0xx390x2xx0xx390x2xx — это IP-адрес клиента в hex-формате.
32:4 — адрес и длина поля, в котором записан SCR IP в Tunnel-пакете.
Адрес поля пришлось подбирать перебором, так как в интернете пишут про 40, 44, 50, 54, но там IP-адреса не было. Также можно посмотреть один из пакетов в hex (параметр -xx или -XX в tcpdump) и посчитать, по какому адресу известный вам IP.
Есть ли фрагменты пакетов без снятого Vlan- и Tunnel-инкапсулирования?
tcpdump ((ip[6:2] > 0) and (not ip[6] = 64))
Эта магия покажет нам все фрагменты, включая последний. Наверное, то же можно зафильтровать по IP, но я не пытался, поскольку таких пакетов не очень много, и в общем потоке легко нашлись нужные мне. Вот они:
14:02:58.471063 In 00:de:ff:1a:94:11 ethertype IPv4 (0x0800), length 1516: (tos 0x0, ttl 63, id 53652, offset 0, flags [+], proto IPIP (4), length 1500)
11.11.11.11 > 22.22.22.22: truncated-ip - 20 bytes missing! (tos 0x0, ttl 50, id 57750, offset 0, flags [DF], proto TCP (6), length 1500)
33.33.33.33.33333 > 44.44.44.44.80: Flags [.], seq 0:1448, ack 1, win 343, options [nop,nop,TS val 11660691 ecr 2998165860], length 1448
0x0000: 0000 0001 0006 00de fb1a 9441 0000 0800 ...........A....
0x0010: 4500 05dc d194 2000 3f09 d5fb 0a66 387d E.......?....f8}
0x0020: 1x67 7899 4500 06xx e198 4000 3206 6xx4 .faEE.....@.2.m.
0x0030: b291 x9xx x345 2541 83b9 0050 9740 0x04 .......A...P.@..
0x0040: 6444 4939 8010 0257 8c3c 0000 0101 080x dDI9...W.\......
0x0050: 00b1 ed93 b2b4 6964 xxd8 ffe1 006a 4578 ......ad.....jEx
0x0060: 6966 0000 4x4d 002a 0500 0008 0004 0100 if..MM.*........
14:02:58.471103 In 00:de:ff:1a:94:11 ethertype IPv4 (0x0800), length 62: (tos 0x0, ttl 63, id 53652, offset 1480, flags [none], proto IPIP (4), length 40)
11.11.11.11 > 22.22.22.22: ip-proto-4
0x0000: 0000 0001 0006 00de fb1a 9441 0000 0800 ...........A....
0x0010: 4500 0028 d194 00b9 3f04 faf6 2x76 385x E..(....?....f8}
0x0020: 1x76 6545 xxxx 1x11 2d2c 0c21 8016 8e43 .faE...D-,.!...C
0x0030: x978 e91d x9b0 d608 0000 0000 0000 7c31 .x............|Q
0x0040: 881d c4b6 0000 0000 0000 0000 0000 ..............Это два фрагмента одного пакета (одинаковый ID 53652) с фотографией (видно слово Exif в первом пакете). По причине того, что на этом уровне пакеты есть, а в склеенном виде в дампах — нет, то проблема явно со сборкой. Наконец-то этому есть документальное подтверждение!
Декодер пакетов не выявил никаких проблем, препятствующих сборке. Пробовал тут: hpd.gasmi.net. Сначала, при попытке туда что-то запихать, декодеру не нравится формат пакета. Оказалось, что там были какие-то лишние два октета между Srcmac и Ethertype (не относящиеся к информации о фрагментах). После их удаления декодер заработал. Однако никаких проблем он не показал.
Как ни крути, кроме тех самых Sysctl ничего больше не нашлось. Оставалось найти способ выявления проблемных серверов, чтобы понять масштаб и принять решение о дальнейших действиях. Достаточно быстро нашёлся нужный счётчик:
netstat -s | grep "packet reassembles failed”Он же есть в snmpd под OID=1.3.6.1.2.1.4.31.1.1.16.1 (ipSystemStatsReasmFails).
«The number of failures detected by the IP re-assembly algorithm (for whatever reason: timed out, errors, etc.)».
Среди группы серверов, на которых изучалась проблема, на двух этот счётчик увеличивался быстрее, на двух — медленнее, а ещё на двух вообще не увеличивался. Сравнение динамики этого счётчика с динамикой HTTP-ошибок на Java-сервере выявило корреляцию. То есть счётчик можно было ставить на мониторинг.
Наличие надёжного индикатора проблем очень важно, чтобы можно было точно определить, помогает ли откат Sysctl, так как из предыдущего рассказа мы знаем, что по приложению это сразу понять нельзя. Данный индикатор позволил бы выявить все проблемные места в продакшене до того, как это обнаружат пользователи.
После отката Sysctl ошибки по мониторингу прекратились, таким образом причина проблем была доказана, как и то, что откат помогает.
Мы откатили настройки фрагментации на других серверах, где загорелся новый мониторинг, а где-то под фрагменты выделили даже больше памяти, чем было до этого по умолчанию (это была udp-статистика, частичная потеря которой не была заметна на общем фоне).
Самые главные вопросы
Почему у нас на L3-балансировщике фрагментируются пакеты? Большинство пакетов, которые прилетают от пользователей на балансировщики, — это SYN и ACK. Размеры этих пакетов небольшие. Но так как доля таких пакетов очень велика, то на их фоне мы не заметили наличие больших пакетов, которые стали фрагментироваться.
Причиной стал поломавшийся скрипт конфигурации advmss на серверах с Vlan-интерфейсами (серверов с тегированным трафиком на тот момент в продакшене было очень мало). Advmss позволяет донести до клиента информацию о том, что пакеты в нашу сторону должны быть меньшего размера, чтобы после приклеивания к ним заголовков туннеля их не пришлось фрагментировать.
Почему откат Sysctl не помогал, а ребут помогал? Откат Sysctl менял объём памяти, доступной для склеивания пакетов. При этом, судя по всему сам факт переполнения памяти под фрагменты приводил к торможению соединений, что приводило к тому, что фрагменты надолго задерживались в очереди. То есть процесс зацикливался.
Ребут обнулял память и всё приходило в порядок.
Можно ли было обойтись без Workaround? Да, но велик риск оставить пользователей без обслуживания в случае атаки. Конечно, применение Workaround в результате привело к возникновению различных проблем, включая торможение одного из сервисов у пользователей, но тем не менее мы считаем, что действия были оправданы.
Большое спасибо Андрею Тимофееву за помощь в проведении расследования, а также Алексею Кренёву — за титанический труд по обновлению Centos и ядер на серверах. Процесс, который в данном случае несколько раз пришлось начинать с начала, из-за чего он затянулся на много месяцев.
")
