

Дисклеймер: речь в данной статье не идёт о браузерных войнах как таковых. Скорее, автор пытается объяснить устройство и механизм работы браузеров простым языком (прим. переводчика).
Наблюдая за тем, как Google Chrome планомерно подавляет конкуренцию на рынке браузеров, Нил Мор пытается проанализировать причины его популярности, а также объясняет, почему не стоит им пользоваться.
Подозреваем, что одно только упоминание о браузерных войнах 2000-го года вызовет у олдов горечь и раздражение (да, скорее всего, войны были в 1995-м, нам просто нравится округлять числа). В те дни веб-сайты представляли собой страницы, украшенные недружелюбными к пользователю логотипами «Compatible with Netscape» («Совместимый с Netscape») и анимированными гифками вроде «Under Construction» («В разработке»), загружать которые модем на 56 кбит/с мог вечность.
Сайты работали на аляповатых плагинах, а Microsoft нарушала бытующие в то время стандарты направо и налево, чтобы заполучить долю на рынке. Чудесные деньки, если под словом «чудесный» понимать «отвратительный».

Всё изменилось благодаря той же корпорации Microsoft, точнее Биллу Гейтсу, который уже тогда осознал значимость браузеров для будущего и всё равно умудрился уступить лидирующую позицию на рынке какому-то отважному неудачнику. Этого неудачника звали Google
Зачем нам вообще нужно раздумывать над выбором веб-браузера? Что сделало етаким производительным? Как он устроен, и есть ли между веб-обозревателями хоть какая-то значительная разница? Для ответа на эти и другие вопросы нужно разобраться в принципе работы веб-браузера, протестировать несколько из них и спросить эксперта о том, стоит ли продолжать использовать обозреватель, навязанный нам корпорациями. Подсказка: нет.
Мы не собираемся возвращаться в 1993 год и рассказывать вам историю появления всемирной компьютерной сети, также известной как Web 1.0. Это дела давно минувших дней, спасибо Тиму Бернерс-Ли. Мы будем говорить о наших днях, чтобы выяснить, за счёт чего работают современные браузеры и почему так велика разница между ними. Также важно ответить на вопрос «почему»? Что так кардинально поменялось за эти 27 лет, отчего устройство современных браузеров стало таким сложным? Отметим для начала, что один только обзор основных высокоуровневых функций веб-браузера раскрывает его сложную структуру. Их частью является структура коммутации сети, необходимая для получения всех протоколов HTTP и связанных с ним протоколов, прежде чем ваш браузер отобразит что-либо.

Тут нужно отметить, что Всемирная паутина представляет собой набор ненадёжных, нагромождённых друг на друга стандартов, распространяемых посредством сети на международном уровне. Любое вмешательство корпорации или государства может привести к нарушению её работы. Взять хотя бы DDoS-aтаки или тот факт, что отдельные страны перенаправляют трафик, нарушая тем самым протокол граничного шлюза. Это означает, что если владельцы известного браузера решат подорвать открытые стандарты, то они вполне могут сделать это – и, можно сказать наверняка, делали это.
Внутри браузера
Базовые составляющие браузера мало изменились со времени его появления в середине 1990-х годов. Сейчас веб-обозреватели способны поддерживать обработку языка JavaScript и сохранять локальные данные. На диаграмме ниже показано, как построен браузер.
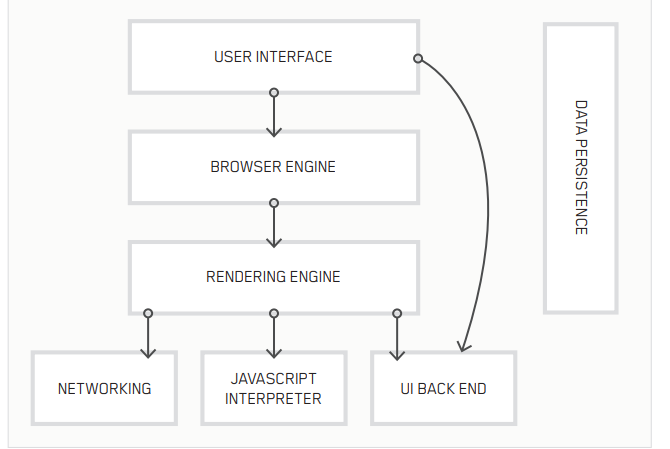
- Сеть. Работа браузеров сильно завязана на сети. И хотя HTTP(S) – основа всего, существует также протокол FTP, предназначенный для передачи файлов, SMTP – для пересылки электронной почты и DNS – для получения информации об электронном адресе и запроса страниц с веб-сервера, не говоря уж о TCP/IP-соединениях и передаче пакетов.
- Пользовательский интерфейс. Наверное, вы считаете это само собой разумеющимся, но всевозможные интерактивные моргалки и дуделки в браузере, а также его дополнительные функции вроде закладок, истории, хранения паролей и др. – всё это часть интерфейса.
- Браузерный движок. Наименее понятная по сравнению с остальными составляющая браузера. Включает в себя элементы пользовательского интерфейса, рендеринга и движков Java с привязкой к хранилищу данных.
- Хранилище данных. Хотя браузеры начинались с куки, для локальных приложений современные обозреватели чаще используют локальные хранилища. Веб-хранилище предоставляет базовые локальные переменные, в то время как Web SQL предлагает настоящую локальную базу данных. Индексная база данных API является компромиссным решением между двумя вариантами.
- Движок JavaScript. Язык веб-программирования JavaScript включает интерактивное и динамическое содержимое веб-страниц. Поскольку он нуждается в интерпретации, современные браузеры используют динамический компилятор, который исполняет код по требованию в максимально сжатые сроки. Все популярные веб-обозреватели работают на собственном движке и имеют разную производительность.
- Механизм визуализации. Ключевой компонент любого современного браузера. Большая часть статьи будет посвящена изучению механизма его работы, для чего нам понадобится ещё одна блок-диаграмма (см. изображение ниже). Фактически здесь всего два парсера: один отвечает за обработку кода HTML и объектных моделей документов (DOM), другой—за анализ данных в каскадной таблице стилей. На основе этого создаётся дерево рендера.

Всё то же самое, но другое
Здесь мы не будем много распространяться про сеть, пользовательский интерфейс, движок браузера и хранилище данных. И не потому, что они не важны (это абсолютно не так), но потому что по большей части эти составляющие открыто дублируют друг друга на разных уровнях.
Получение доступа к сетевому стеку протоколов TCP/IP и запрос/отправка HTTP – рутинная работа, выполняемая библиотекой стандартных программ. Мастерство разработки интерфейса лучше оставить для отдельного критического обзора или группового теста. И хотя в статье будет упомянуто хранилище данных, мы не будем вдаваться в его глубокий анализ.
А посему из всего списка остаются лишь два компонента, которые задают уровень производительности и соответствия стандартам: движок JavaScript и механизм визуализации.
Мы остановимся на механизме визуализации, потому что он большой и имеет сложную структуру. Но сначала ответим на вопрос: почему столько шума из-за простого кода HTML? Как было упомянуто ранее, интернет и онлайн-приложения строятся на стандартах; в случае HTML это Консорциум Всемирной паутины, известный также под именем W3C, руководящие принципы которого определяют, что должен делать каждый тег HTML.
Проблема заключается в том, что из-за большого количества обстоятельств эти руководящие принципы и правила можно интерпретировать по-разному, и то, что будет допустимо для одного браузера, для другого таковым являться не будет. К тому же глупые людишки придумали ещё один набор тегов.
Поскольку механизм визуализации отвечает за интерпретирование и отображение контента, а движки у браузеров отличаются, то может оказаться, что содержимое интернет-страниц может отображаться по-разному. Обычно различия минимальны, но иногда это может привести к позиционным изменениям или же в крайнем случае к невозможности отобразить всю страницу.
Как ни странно, ошибки в процессе рендеринга появляются от того, что движки не справляются с ситуациями сбоя, потому как подобное поведение не стандартизировано. Случается, что редакторы HTML и разработчики могут выдать всякого рода дикий неподдерживаемый код, который бедный браузер должен интерпретировать максимально точно.

Подноготная механизма визуализации
Сетевой движок выполняет свою работу, извлекает содержимое веб-страницы и адресует его механизму визуализации. На этом этапе есть два варианта обработки содержимого. Мы посмотрим, как движки WebKit и Blink справляются с этим процессом, но знайте, что у Gecko, на котором построен Firefox (и его производные) иной порядок обработки.
Все вышеупомянутые движки, однако, делят всё содержимое веб-сайта на HTML и CSS данные. И те и другие данные обрабатываются отдельно своим собственным парсером. А что потом? В общих чертах парсер принимает этот входящий двоичный поток и переводит данные в дерево узлов; структуру такого дерева определяет синтаксис (правила) языка (HTML или CSS).
Если вам знакомы теги HTML, то имеет смысл сказать, что парсинг включает в себя две составляющие:
· лексический анализатор. Делит входящие данные на известные токены (теги) в соответствии с существующими правилами;
· синтаксический анализатор. Создаёт структуру документа, построенную по определённым грамматическим правилам. Токен запрашивается у лексического анализатора. Если тэг подпадает под известное правило, то добавляется к дереву, в противном случае он сохраняется и запрашивается другой токен. Если для сохранённого токена не находится совпадений, то синтаксический анализатор выдаёт ошибку.
HTML интересен в языковом плане. Его грамматика нечётко определена, потому что должна быть обратно совместимой и ошибкоустойчивой. В то же время она должна уметь обрабатывать динамический код (посредством скриптов), который может обратно добавлять токены, пока он обрабатывается синтаксическим анализатором. Это означает, что его синтаксический анализатор не может регулярно использовать нисходящий или восходящий подход для анализа. В языковом мире это называют контекстно-зависимой грамматикой.
.")
Чтобы вы имели представление, с чем имеет дело парсер, давайте взглянем мельком на тяжёлые будни лексического анализатора кода HTML. Сначала он по умолчанию включает режим «data state» (данные). Когда он обнаруживает символ <, то включает режим «tag open state» («открытый тег»). Идущие далее символы a–z создают токен «start tag» (открывающий тег») и состояние «tag name state» («название тега»). Это продолжается до тех пор, пока не появится закрывающий тег и не включится режим «data state». Если же после символа < обнаруживается символ /,то создаётся «end tag token» («закрывающий тег»), и так до тех пор, пока не будет найден символ > .
Эти токены передаются в синтаксический анализатор кода HTML и впоследствии встраиваются в структуру документа, всякий раз когда находится подходящий тег HTML, от <HTML> к <BODY> , от <BODY> к </BODY> , и от </BODY> к </HTML>.
Что кажется ещё более интересным, так это то, какие танцы с бубном приходится выплясывать браузерам, когда они когда натыкаются на не просто плохо отформатированные документы HTML, но на откровенную ересь. Синтаксический анализатор браузера должен быть ошибкоустойчивым, иначе веб-страницы просто «споткнутся» и не смогут загрузиться. Как минимум браузер должен знать, что делать, если какой-либо тег закрыт некорректно, что случается повсеместно. Кроме того, нередки случаи, когда анализатор натыкается на неизвестный, старый или неподдерживаемый тэг.
И хотя официальной инструкции по исправлению кривого кода HTML не существует, в коде движка WebKit от Apple имеются занимательные комментарии относительно подхода к различным классическим ошибкам, в том числе к незакрытым или неверно закрытым тэгам, неправильно размещённым таблицам, тэгам с большими вложениями или ошибочно закрытым тегам <body>.
В итоге обработанный парсером код HTML становится объектной моделью документа, так называемой моделью DOM. Отдельно от HTML также анализируются элементы CSS (каскадные таблицы стилей) и на основе этого создаётся объектная модель CSS. В отличие от HTML грамматика CSS не имеет контекстуальных ограничений, отчего глупым людишкам становится трудно сломать её. Синтаксический анализатор должен обработать каскадные таблицы стилей, чтобы определить стиль каждого элемента.
Ранее мы упоминали про динамическое содержимое и скрипты. И хотя сценарии не сильно меняются, браузеры должны обрабатывать их синхронно –парсинг не возобновится до тех пор, пока каждый скрипт не будет выполнен. Если требуются сетевые ресурсы, то их надо загрузить, а все остальные процессы должны быть остановлены до тех пор, пока это не будет сделано. Авторы сценариев также могут добавить атрибут <defer>, чтобы отложить выполнение сценария до тех пор, пока документ не будет проанализирован.
Однако WebKit и Gecko используют спекулятивный парсинг, чтобы заранее считывать и загружать любые сетевые ресурсы, например, скрипты, изображения и CSS, облегчая тем самым загрузку страницы. Это хорошее решение, поскольку сценарии, которые запрашивают нагружающие сеть таблицы стилей, вызывают проблемы, если к ним (к таблицам стилей) нельзя получить доступ
Дерево рендера
И тут начинается самое интересное. Из модели DOM мы знаем, где должны располагаться объекты на странице, созданной из кода HTML. Из объектной модели CSS мы знаем также, как элементы должны быть оформлены стилями. Каждый визуализируемый объект – это, по сути, прямоугольная область, имеющая определённый размер, позицию и стиль. Большинство объектов построено из множества отрисованных прямоугольников; важно помнить, что дерево рендера построено из узла DOM.
Также нужно заметить, что процесс совмещения стиля с объектом отображения не так прост, как кажется. Он зависит от унаследованных правил. А на саму обработку браузером унаследованных правил стиля и поиск соответствий с объектами может уйти не один обход дерева.
Теперь можно начать вёрстку страницы. Она подразумевает вычислительный процесс, в ходе которого те самые прямоугольники совмещаются с назначенным стилем. HTML уже сконструирован, и потому вёрстку можно сделать в один заход. Переверстать страницу можно полностью (например, при кардинальной смене стиля или размера окна) или же её отдельные «дочерние» объекты. В заключение отметим, что дерево рендера можно нарисовать и обработать элементами пользовательского интерфейса браузера, поскольку последний зависим от ОС.

Наращивание возможностей
Раннее мы упоминали о том, что во всех современных браузерах имеется движок JavaScript с JIT-компилятором. Динамический компилятор нужен для максимального увеличения скорости работы программ. Все браузеры используют свой движок JavaScript, и именно благодаря ему вы можете «программировать паутину» и создавать комплексные интерактивные онлайн-приложения. И так как JavaScript морально устарел (он появился ещё 1990-х, и в то время ещё никто не знал его прямого предназначения), встречайте- Web Assembly (Wasm).
Этот бинарный формат стартовал в 2015-м, а к 2017-му поддерживался почти во всех браузерах и стал стандартизированным концу 2019-го. Он поддерживает низкоуровневый кроссплатформенный язык и нативно запускается на самом устройстве через браузер. Wasm может компилировать C/C++ и Rust и запускается в той же "песочнице", что и JavaScript, и потому может быть использован его библиотеками для безграничного ускорения.
В итоге мы имеем совместимую с HTML5 веб-страницу со всеми моргалками и дуделками от Web 2.0 на любой вкус и цвет. IT-корпорации (Google, Apple, Microsoft), видимо, остановили свой выбор на браузерах с движками WebKit/Blink, которые имеют хорошую совместимость и кучу производных. Искренне надеемся, что Mozilla отстоит независимость Firefox, но сейчас она действует в невыгодных для себя условиях. Похоже, браузерные войны возвращаются.




