Привет, Хабр! Меня зовут Андрей, я новый Android-разработчик в команде онлайн-кинотеатра PREMIER.
Когда я только пришел на работу в проект, мне поставили задачу внедрить измерение билдов для того, чтобы видеть, как с течением времени у нас меняется время сборки проекта на разных билд-машинах.
Решение задачи
После проведенного анализа я выявил два варианта решения
Использовать gradle enterprise
Написать скрипты для gradle для сборки и отправки метрик
Первый вариант нам не подходит, потому что он платный;
Второй вариант нам не подходит, потому что он требует большого кол-ва времени, а в рамках испытательного срока оно ценное, и я рисковал не успеть уложиться в срок.
Так как оба варианта не подошли я начал искать альтернативное решение, которое не требовало бы много времени на написание скриптов и больших вложений. После n-го времени, проведенного в гугле и на гитхабе, нашелся один вариант, который удовлетворял запросы – это Talaiot.

Немного о talaoit:
Talaiot – внешняя библиотека для gradle проектов, которая измеряет и записывает время билдов/тасок в бд. В дальнейшем эта информация помогает выявлять проблемы перфоманса тех или иных фич в проекте.
Библиотека поддерживает как локальный отчеты в формате json и визуализацию в виде картинок, так и отправку отчетов в базу данных, - расположенную на сервере. Единственный минус – это ограниченный выбор баз данных для хранения данных о сборках, в основном это time-series databases, но скорее это обусловлено работой самого talaiot.
Технологический стек:
Docker-compose
Grafana
InfluxDB
InfluxCLI
Talaiot
Подготовка:
Начнем с того, что нам необходимо установить docker-compose на котором мы будет разворачивать наши контейнеры с influx-db и grafana.
Создаем папку, в которой создаем файл docker-compose.yml с описанными контейнерами.
Eсли вы более продвинутый юзер в использовании докера, никто не запрещает описать докер файл со скриптом запуска, как это сделано в примере talaiot’a на гитхабе в папке docker .
docker-compose.yml:
version: "1" |
Я создал дополнительно двух юзеров с разными правами: один записывает данные в нашу бд-шку и используется в проекте для talaiot, второй используетя графаной для чтения данных. Так-же можете можете указать параметр для каждого сервера restart: unless_stopped – это позволит контейнерам подняться самостоятельно, если удаленный сервер будет перезапущен. Сохраняем файл и закрываем его.
Далее нам нужно поднять наши контейнеры. Открываем терминал в нашей папке и пишем заветную команду docker compose up -d и….. вуаля – у нас развернуты influx-db и grafana.

Работоспособность последнего можно проверить, перейдя по ссылке [ссылка-удаленного-или-локального-сервера]:3000, например: localhost:3000 (юзер и пароль для админки графаны по-дефолту: admin).
Influx-DB:
Для работы с моей версией influx-db необходимо поставить influx-cli (ссылки сверху). После установки пишем команду:
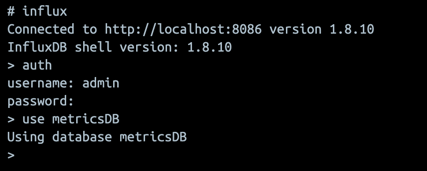
sudo docker exec -it influx_db /bin/bash и после вводим influx, если мы все сделали правильно, терминал должен показать сообщение:

Теперь авторизируемся под админом в нашей базе данных, вводим следующие команды и данные, которые мы указали в docker-compose.yml
Теперь необходимо создать retention policy, которая будет хранить данные n-ое время, я выберу срок хранения год (подробнее про retention policy можете почитать тут)
CREATE RETENTION POLICY rpTalaiot ON metricsDB DURATION 52w REPLICATION 1 |
GRAFANA:
Вернемся к графане, после того, как мы авторизовались, нам необходимо связать графану и базу данных – для этого в боковом меню выбираем раздел connections -> connect data
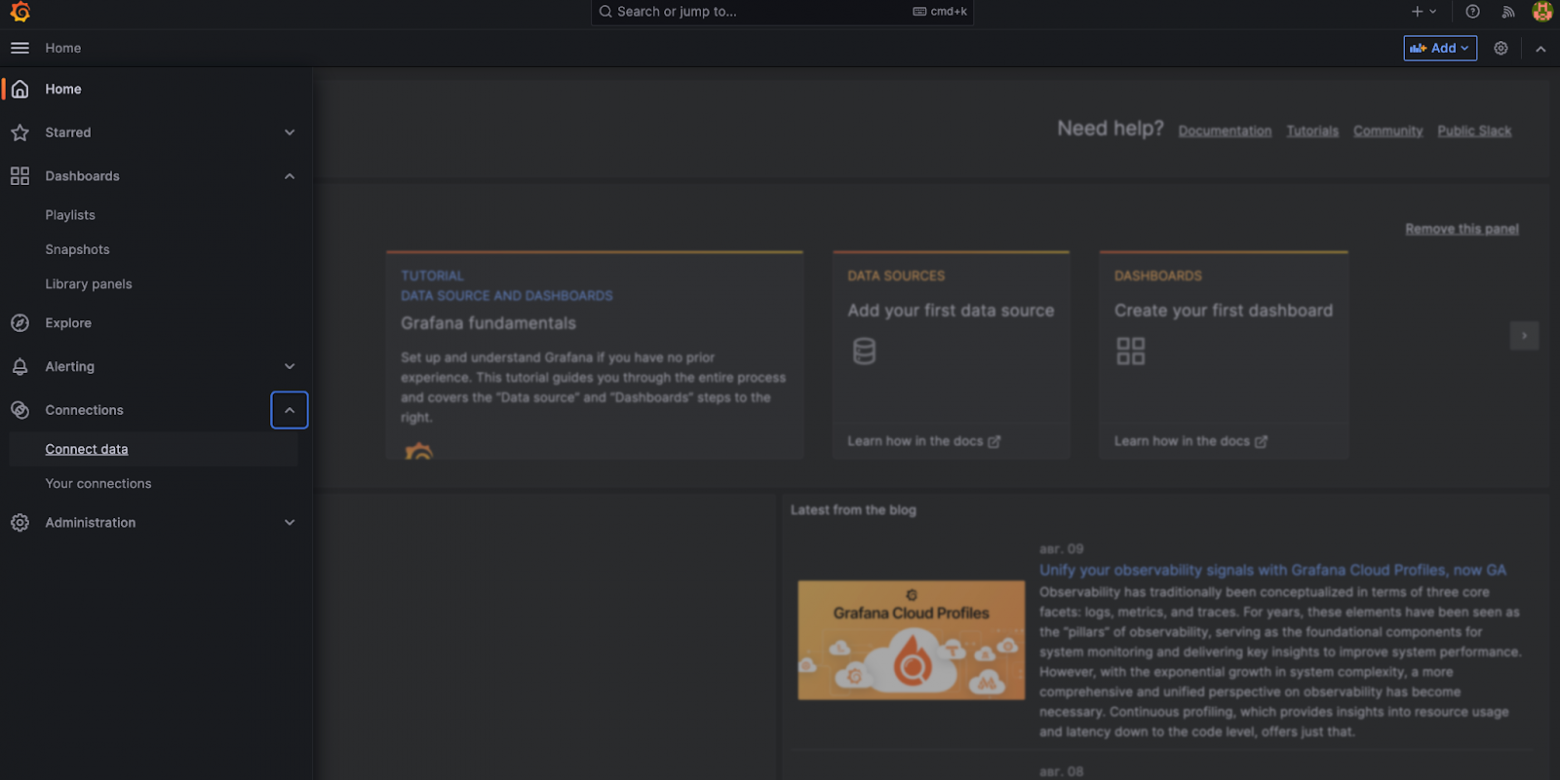
В поисковой строке ищем influx и выбираем influxDb

В появившимся окне нажимаем по кнопке ‘create a influxDb data source’.
Открывается окно, которое заполняем так же, как у меня на скрине, url - будет ваш локальный/удаленный url сервера, либо url докера, как в моем случае. Данные юзера берете, которые указали в docker-compose.yml.

Об успешности испытаний нам скажет графана:

Мы почти на финише, осталось только настроить проект….
Работа с проектом:
Для начала нам необходимо добавить в проект зависимости talaiot, согласно документации.
В своем примере я делаю отдельный build script для talaiot, чтобы, по возможности, можно было подключать в разные проекты.
build.gradle (project) ->
plugins { |
Синкаем проект и описываем скрипт согласно примеру из гита
talaior.gradle ->
talaiot { taskMetricName = "task"
'prepareKotlinBuildScriptModel', 'clean'] |
А теперь вкратце объясню, что тут за что отвечает.
В publishers мы должны выбрать паблишер. Название поддерживаемой базы данных соответствует названию паблишера, у меня это influxDbPublisher.
dbName - название базы данных, которая будет создана в инфлюксе;
url – url удаленного или локально сервера (может быть localhost или 192.168.1.8);
task и build-metricNames – я оставил без изменений;
username и password – те что указаны в docker-compose.yml для инфлюкса.
В talaiot есть возможность отбрасывать ненужные таски, чтобы исключить их замеры. Помимо замера данных, talaiot тригерит функции гита для получения названия ветки, в которой вы работаете. Т.к. у нас есть удаленные сборщики проектов по типу миракла, там гит отсутствует, поэтому мы отключили возможность использовать сбор гит-информации. Также можно указывать свои дополнительные поля для метрик, которые будут содержать информацию, необходимую вам, для нас это модель процессора.
Для получения модели процессора был написан несложный код, который выполняется в командной строке и отбрасывает ненужную информацию необходимую вам, оставляя только семейство процессора:
static def buildMachine() { } |

А, чуть не забыл, для дашборда графаны можно взять готовый sample из нашего примера и импортировать его в вашу графану. Теперь все готово к употреблению! Делаем несколько сборок проекта и проверяем результат в графане.
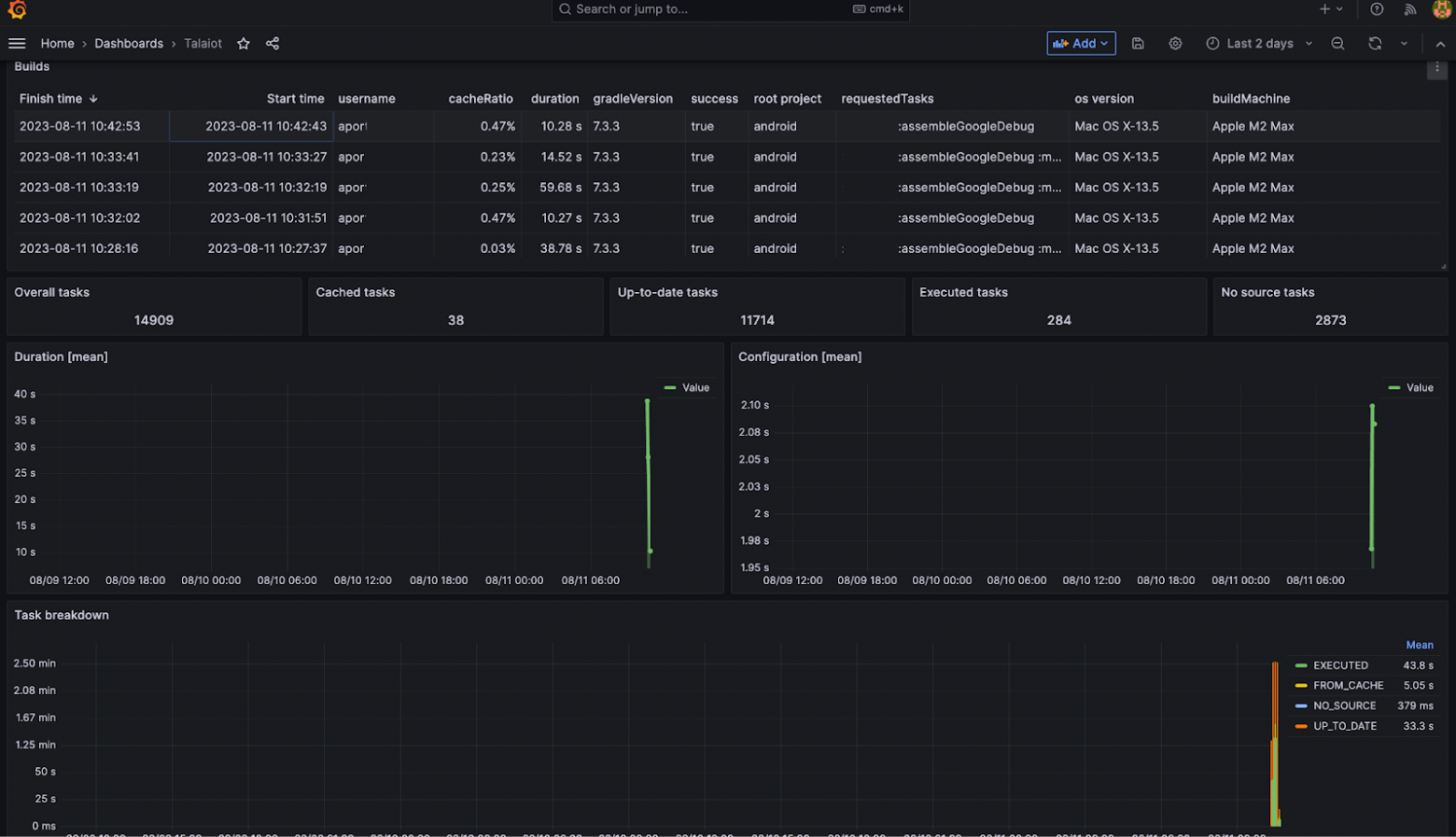
Итог
Из того, что есть в открытом доступе, локально была развернута необходимая система с функционалом, которую далее можно перенести на удаленную виртуальную машину, как было сделано на нашем проекте.
Полный пример кода для android-проекта можете посмотреть в нашем примере.
P.S. Это мой первый опыт работы с докером, поэтому если Вы хотите поделиться своей идеей по оптимизации скриптов для докера - буду рад вашим комментариям!



