
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Функция CDP (она же Continuous Data Protection) для многих сейчас видится манной небесной. Ведь она позволяет свести риски потери данных к около-нулевым значениям (RTO и RPO - единицы секунд), при этом не используя тормозящие всё вокруг себя снапшоты, и не зависеть от ограничений классических вариантов репликации.
Вот об этом мы сегодня и поговорим: что это за магия такая, как она работает и как мы её реализовали в Veeam Backup & Replication v11.

Achtung! Прочтение данной статьи никак не освобождает вас от необходимости изучить официальную документацию. Написанное ниже следует понимать скорее как выжимку из ключевых моментов с дополнениями, нежели как более правильную или альтернативную версию документации. И пока далеко не ушли, очень советую особенно тщательно изучить раздел Requirements and Limitations. Ещё никогда он не был настолько важен, как в случае с CDP. Почему-то именно здесь у многих появилось какое-то очень своё видение этой технологии, что мешает трезво оценивать её реальные возможности. Особенно часто все любят упускать слово Clusters. Может в это весна виновата, но суть одна: нет кластеров - нет мультиков. Совсем.
Зачем CDP нужен этому миру
Начинаем по порядку: а какие проблемы может решить CDP и кому он нужен?
Отвечать будем по порядку поступления вопросов, чтобы ответ на предыдущий помогал понять ответ на следующий. Итак, CDP - это ещё один вид репликации виртуальных машин. Вот так всё просто. На этом всё. Всем спасибо, все свободны. Шутка.
CDP удобнее всего сравнивать с асинхронной репликацией стораджей. То есть ваши виртуалочки спокойно работают, а где-то там далеко внизу одно хранилище реплицирует данные на другое, как бы гарантируя вам, что в случае сбоя вы потеряете минимум информации и просто продолжите работать в новом месте.
Соответственно, проблема, которую помогает нам решить CDP - это обеспечение минимальных значений RTO и RPO. Получается, что это история для самых важных приложений, где допустимый простой может измеряться минутами или даже секундами. А лучше, чтобы его вообще не было. Разные умные люди считают, что под эти требования попадает не более 5% нагрузок. Просто от их функционирования зависят остальные 95%, так что обеспечение их бесперебойной работы становится основной задачей IT отдела.
Хорошо, но чем тогда нас не устраивают классические реплики? В том же Hyper-V, технически, можно реализовать репликацию каждые пять секунд. Вот же оно! Но нет. Вся проблема в снапшотах и задержках, которые они тянут за собой. Как ни крути, но создание снапшота - это весьма небанальный процесс (просто посмотрите на эту обзорную схему работы VSS), происходящий сначала на уровне машины, а потом и хоста. Который неизбежно приводит к задержкам и накладным расходам. А потом снапшот надо удалить, а в процессе всех этих операций не угробить машину и работающие на ней приложения (что очень запросто, уж поверьте). Да и в целом, весь этот процесс выглядит довольно громоздко: надо создавать пачку снапшотов (на уровне ОС, потом на уровне гипервизора, а потом ещё и на уровне датасторы может понадобиться), выхватить пачку получившихся данных (не просто прочитать файлик, а получить его в виде дельты двух состояний), куда-то их все махом переложить, корректно удалить снапшоты в обратном порядке и дать отмашку гостевой ОС, что можно продолжать спокойно работать.
Так что если снапшоты можно исключить, их надо исключить.
Как работает CDP
Видя всё это безобразие, разработчики из VMware как-то сели крепко подумать и решили выпустить некое API, которое сейчас известно под именем VAIO. Фактически, это технология, позволяющая сделать классический I/O фильтр, который даёт возможность следить за I/O потоками гостевых машин и делать что-то с этим знанием. Причём с момента включения этого фильтра ни один изменившейся на диске байт не останется без нашего внимания. А дальше дело за малым: берём эти блоки, копируем из одной машину в другую - и мы восхитительны. Буквально пара недель работы программистов, неделька на тестирование, и можно релизить.
Хотелось бы так, но нет. На практике всё несколько сложнее. Давайте разбираться.

Вот так выглядит общая схема работы. Для видавшего виды VBR пользователя здесь знакомо только слово Proxy. И, пожалуй, да, на прокси вся схожесть с классическими схемами работы и заканчивается.
Погнали по списку:
Координатор. Умывальников начальник и мочалок командир. Управляет всеми процессами, отвечает за связь с vCenter, говорит другим компонентам, что делать, и всячески следит, чтобы всё было хорошо. На местах выглядит как Windows сервис. Единственный, кто знает про существование таких вещей, как vCenter и виртуальные машины. Все остальные работают только с дисками. Поэтому всё, что не связано с репликацией контента, делает координатор. Например, создаёт виртуалку на таргете, к которой мы прицепим реплицируемые диски.
Source filter. Та самая штука, которая занимается перехватом IO запросов. Соответственно, работает уже на ESXi. Дабы повысить надёжность и производительность, один инстанс фильтра работает с одним виртуальным диском. Фильтры держат связь с демоном.
Технически, фильтр - это dll библиотека, живущая внутри виртуальной машины. И если с ним что-то случается (залипла память, скрешился и т.п.), то следом прилетает виртуалке, внутри которой он работает. Поэтому жизнеспособности фильтров было уделено огромное внимание. Ну и если вы сомневаетесь по поводу прямоты рук создателей фильтра: такие штуки можно устанавливать на хосты только после прохождения строгой сертификации получившегося изделия со стороны VMware.
Важно: VBR производит установку на кластер. Довести фильтр до каждого хоста - это уже задача самой VMware. Причём если вы добавляете новую ноду в кластер, то наш бандл на него будет установлен автоматически. Зачем? Давайте представим, что произойдёт, если в кластере появится новая нода и для какой-то из машин сработает vMotion на эту ноду? Всё верно - CDP реплика сломается. Однако вся эта автоматика не отменяет необходимости пройти через Manage I/O filters визард - для актуализации настроек. Поэтому, если добавили ноду, то быстренько проходим “Manage I/O filters” визард, который обнаружит новичка и всё настроит.
Source Daemon. Используется один на каждый хост. В отличие от мифического фильтра, который где-то там работает, демон - это вполне конкретный процесс на хосте. Отвечает за связь с координатором и общается с прокси на предмет поиска оптимального маршрута трафика. Работает по медленному TCP, так как шустрый UDP не гарантирует доставку. И да, это именно тот случай, где это критично и необходимо.
Зачем нужна прокладка в виде демона и почему бы фильтру самому не работать с прокси? Это ограничение технологии со стороны VMware, не позволяющее фильтру работать с внешней сетью. То есть фильтр с демоном связь установить может, а с прокси нет. Это называется by design, и ничего с этим не поделаешь. Во всяком случае, сейчас. И напомню: демон не знает ни про какие виртуальные машины. Он работает с потоками данных от дисков. И ничего другого в его мире не существует. Поэтому диски одной машины могут обрабатываться сразу несколькими прокси. Мы, конечно, стараемся отвозить диски одной машины через один прокси, но если она не справляется, то подключится другая. И это нормально!
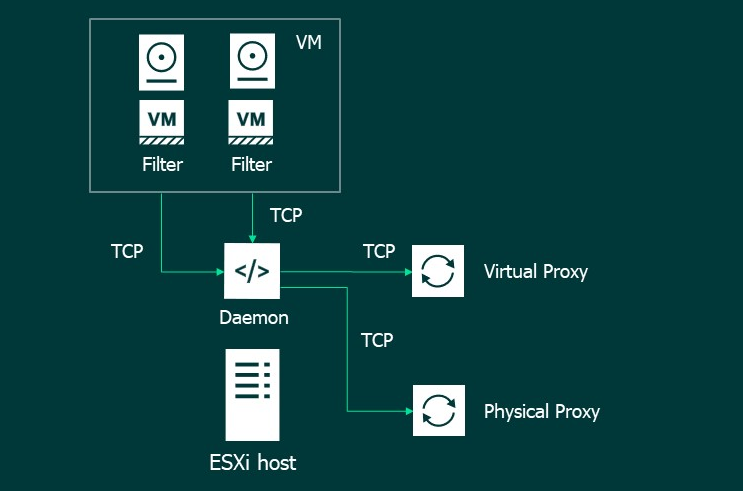
Source Proxy. Агрегирует в себе всю информацию, полученную от фильтров через демонов. Хранит всё строго в RAM, с возможностью подключения дискового кэша, если оперативка кончилась. По этому очень (ОЧЕНЬ!) требователен к RAM, дисковому кешу и задержкам на сети. Так что только SSD и прочее адекватное железо.
Прокси занимается составлением так называемых микроснапшотов, которые отправляются дальше. Данные перед передачей обязательно дедуплицируются: если в каком-то секторе произошло 100500 перезаписей, то до прокси дойдут все, но с самого прокси будет отправлена только одна последняя. Так же, само собой, всё сжимается и шифруется. На местах прокси представляют собой Windows машины, которые могут взаимозаменять друг друга, переключать нагрузку и так далее.
Target Proxy. Всё то же самое, но в обратном порядке. Принимает трафик от сорсных проксей, расшифровывает, разжимает, отправляет дальше. Так же может быть как физический, так и виртуальный.
Target Daemon. Занимается записью данных на датастор. Полная копия сорсного демона.
Target Filter. В нормальном состоянии находится в выключенном виде. Начинает работать только во время фейловера и фейлбека, но об этом позже.
Таргетные компоненты от сорсных в данном случае отличаются только названием и своим местом в логической схеме. Технически они абсолютно идентичны и могут меняться ролями на ходу. И даже одновременно работать в двух режимах, чтобы одна машина реплицировалась с хоста, а другая на хост. Но я вам ничего такого не говорил и делать не советовал. Также в момент переключения реплики в фейлбек таргеты переключаются на роль сорсов, а в логах появится соответствующая запись.
Немного промежуточных деталей
Сейчас хочется немного отвлечься на разные детали, понимание которых даст нам более полную картину в будущем.
Как мы видим, процессы, связанные с CDP, довольно плотно интегрированы в сам хост. Так что при выполнении многих операций надо быть предельно внимательным. Например, апгрейд/удаление VAIO драйвера происходит строго через maintenance mode. Установка, что хорошо, такого не требует. На случай отсутствия DRS предусмотрена защита, которая не даст запуститься процессу, однако это же IT, и бывает тут всякое. Поэтому действовать надо осторожно и внимательно.
И ловите бонус: фильтр с хоста можно удалить командой:
esxcli software remove -n=veecdp.
Но есть проблема: как я писал выше, установкой фильтров на хост занимается VMware в автоматическом режиме, поэтому при выходе из mm фильтр появится снова. Так что правильно удалять фильтр через кластер. Наименее зубодробительный способ - это через powercli:
Get-VAIOFilter |Remove-VAIOFilter
И дальше по обстановке.
Мой любимчик - DNS. Должен работать как часы, по принципу “каждый-каждого”, ибо все мы знаем, что It’s always DNS. Если у вас на VBR сервере используется один DNS сервер, а в vCenter и на хостах другой, то в этом нет никакой проблемы до тех пор, пока они могут резолвить неймспейсы друг друга. То есть vCenter должен уметь зарезолвить VBR и хосты. А хосты должны уметь резолвить VBR и vCener. И так далее.
И, конечно же, не забудем обрадовать ненавистников разного рода устанавливаемых на гостевую ОС агентов и сервисов. Для CDP ничего такого делать не надо, и даже админские креды никому больше не нужны (если только вы готовы отказаться от VSS точек с application consistent состоянием). Наконец-то угнетатели повержены и можно спать спокойно. Всё работает исключительно за счёт магии VAIO API.
Retention
Самое время упомянуть альфу и омегу запросов в саппорт - ретенш. А между прочим, их тут сразу целых два! Вот это поворот! (с)
На длинной дистанции мы используем Long-term retention, гарантирующий консистентность на уровне приложений(application aware). Делается это с помощью VSS и требует предоставления админской учётки от гостевой ОС. Выглядит это как создание точек отката с определённой периодичностью (например, раз в 12 часов), которые хранятся несколько дней.
И второе - это Short-term Retention, где гранулярность отката может доходить до 2 (двух!) секунд, но гарантируется только crash-consistent восстановление. Для short-term указывается значение RPO - как часто сохранять состояние дисков - и сколь долго хранить эти изменения. Можно понимать это как количество времени, которое мы будем хранить наши RPO точки. На скриншоте ниже мы будем хранить данные с нарезкой по 15 секунд за последние 4 часа.
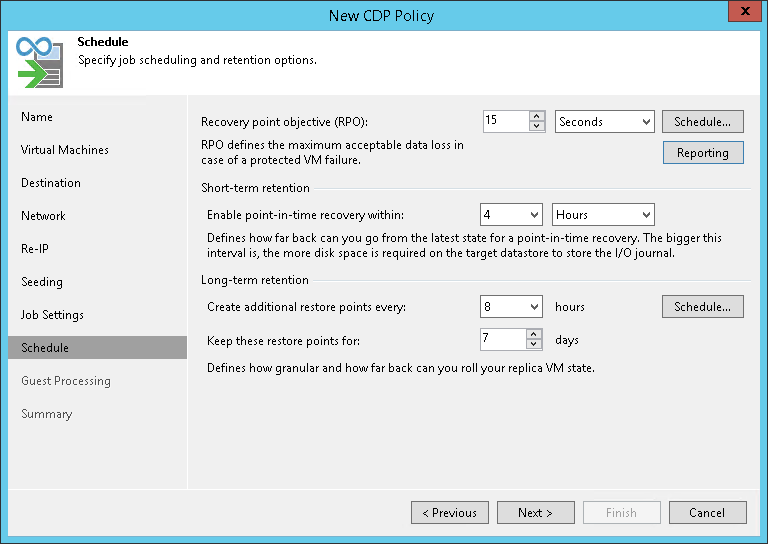
Расписание, само собой, гибко настраивается, позволяя, например, обеспечивать crash-consistent только в офисное время, а в ночное переключаться на редкие, но application-consistent точки.

Если подходить глобально, то вариантов сделать фейловер у нас два: прямо сейчас по кнопке Failover now… или создав Failover Plan. Соответственно, если случилась авария, то мы можем сделать фейловер нашей реплики в следующих режимах:
Откат на последнее состояние (crash-consistent)
Восстановиться на нужный нам момент времени в режиме Point-in-time (crash-consistent)
Откатиться на Long term точку (здесь можно выбрать между application-aware и crash-consistent)
А failback и permanent failover делаются по правилам обычных старомодных реплик, так что останавливаться на этом не буду. Всё есть в документации.
Совет: в выборе нужного момента времени при Point-in-time ресторе очень удобно двигать ползунок стрелочками на клавиатуре ;)
Как работает CDP ретеншн
И прежде чем мы начнём обсуждать, почему вы поставили хранить три точки отката, а на диске их двадцать восемь, давайте посмотрим, что вообще будет храниться на таргетной датасторе.
.VMDK Тут без сюрпризов. Обычный диск вашей машины, который создаётся в момент первого запуска репликации.
.TLOG и .META - логи и метаданные транзакций. Всё для того, чтобы ничего не потерялось. Также они позволяют сделать откат на произвольный момент времени.
VM-000X.VMDK Дельта диски, коих может быть огромное количество. И не думайте, что каждый дельта диск - это точка отката. Это просто хранилища блоков данных, жестко связанные с файлами логов транзакций. Примерно как в базах данных. Когда вы будете делать фейловер, Veeam выстроит цепочку из нужных дельта дисков и первоначального VMDK. А с помощью лога транзакций найдёт необходимые блоки данных, которые фильтр применит к базовому диску при запуске машины. Это тот единственный момент, когда нам нужно включить Target Filter.
Short-term retention

Теперь рассмотрим, как это работает.
В первый момент времени на таргете нет ничего, поэтому, чтобы начать работать, нам надо взять и в лоб поблочно скопировать VMDK файл с сорса на таргет.
Интересный факт: в интерфейсе VBR иконки успешно переехавших машин окрашиваются в синий. В то время как их менее успешные товарищи остаются серыми. Если время, которое вы выделили на первичную синхронизацию, уже прошло, а машины так и не посинели, то надо разбираться, что им мешает. Правильный и простой вариант действий в этом случае: обратиться в сапорт. Более долгий и увлекательный - копаться в логах самому. Только учтите, что на тему CDP логов можно ещё одну статью смело писать, так что лучше доверьте это дело профессионалам.
Совет: если тащить по сети огромный VMDK вам нет никакого удовольствия, то Seeding и Mapping вам в помощь. Они позволяют перевести ваши файлы на таргетный хост хоть на флешке в кармане, в дальнейшем подключив их к заданию.
Абсолютно реальна ситуация, при которой на реплицируемой машине в момент первой синхронизации будет настолько большая нагрузка, что таргет будет не успевать записывать все приходящие блоки (оригинальный диск + новые блоки). Особенно если там используется сторадж значительно медленнее сорсного. Поэтому когда накапливается большое количество блоков, для которых не было получено подтверждение о доставке, сеть останавливается, и не надо этого бояться. Как только придёт достаточное количество подтверждений, сеть запускается заново. А подтверждение - это когда таргетный демон рапортует об успешной записи всего микроснапшота (про это чуть ниже) на сторадж. Ситуация не слишком частая, но бывает и такое.
Возникает закономерный вопрос: каков размер этих самых блоков? Он динамический и зависит от размера диска. Для простоты можно считать, что 1 Тб диска соответствует 1 Мб блока.
1 ТБ -> 1 МБ | 7 ТБ -> 8 МБ | 64 ТБ -> 64 МБ |
2 ТБ -> 2 МБ | 10 ТБ -> 16 МБ | 100 ТБ -> 128 МБ |
3 ТБ -> 4 МБ | 37 ТБ -> 64 МБ | |
4 ТБ -> 4 МБ | 62 ТБ -> 64 МБ |
Как только VMDK перевезён, можно начинать создавать дельта диски. Для чего фильтр и демон начинают отслеживать IO машины, отправляя по сети всё, что пишется на машине.
Этот поток сознания, приходя на сорс прокси, проходит через процедуру отбрасывания лишних блоков. То есть если некий блок за период репликации был перезаписан несколько раз, то в дельту уйдёт исключительно последнее его состояние, а не вообще все. Это позволяет сохранять вагон ресурсов и два вагона пропускной способности вашей сети.
Рядом с дельта диском создаётся транзакцонный лог.
Если лог становится слишком большим, то создаётся новый дельта диск.
И так всё работает до достижения выбранного Retention policy. После чего Veeam смотрит на содержимое лога.
Если это просто устаревшая точка восстановления, которая нам больше не нужна, то данные из неё вносятся в наш базовый диск, и файлы удаляются.
Если оказывается, что в логе нет вообще ничего, необходимого для создания новых точек восстановления, такой файл сразу удаляется.
Примечание: Соблюдение Retention Policy довольно важно. Однако поддержка CDP реплики в боевом состоянии ещё важнее. Поэтому в механизм заложена потенциальная возможность временного расширения периода хранения до 125% от первоначального.
Long-term retention

Служит логическим продолжением short-term retention. То есть всё работает ровно так, как и написано выше, пока не наступает момент создать long-term точку.
В этот момент создаётся особый дельта диск. Внешне он не отличается от других, однако во внутренней логике он помечается как long-term delta.
Репликация продолжает идти своим чередом.
Когда подходит время для срабатывания short term, то все предыдущие логи и дельта диски (если их несколько) просто удаляются.
Теперь всё считается от этой long-term точки. Она остаётся нетронутой и высится как глыба.
Затем создаётся новая long-term точка, и цикл замыкается.
Когда подходит время, то самая первая long-term точка инжектируется в базовый VMDK.
Про логику транзакций
Путь данных с оригинальной машины до реплицированной можно разбить на два логических участка, водораздел которых проходит по source proxy.

В первой части наши данные - это просто набор транзакций, которые по большому счёту представляют собой неструктурированный поток сознания дисковых IO операций. Попадая на сорсной прокси, этот поток структурируется, обрабатывается и отправляется дальше в виде состояния блоков диска в определённый момент времени. У себя мы называем это микроснапшотом. Да, название так себе, но, как говорится, так исторически сложилось.
Отсюда два важных следствия:
Если мы не успеваем передать данные на участке фильтр-демон-прокси, они считаются безвозвратно потерянными, и сделать с этим уже ничего нельзя.
На втором участке задержка уже не критична. Если даже в какой-то момент времени мы не успеваем получить подтверждение от таргетного демона, то данные остаются в кеше сорсного и таргетного прокси и будут переданы ещё раз. Если кажется, что такое кеширование избыточно, то это кажется. Сети сейчас, конечно, быстрые, но зачем лишний раз лезть далеко, если можно попросить данные ближе? В логе джобы в этот момент возникнет предупреждение, что RPO нарушено, но ничего критичного ещё не случилось. Позднее данные будут довезены до таргета.
Что под капотом у фильтров
Теперь, когда мы разобрались на базовом уровне в устройстве и принципах работы CDP, давайте посмотрим более внимательно на работу отдельных компонентов. А именно фильтров. Ведь именно от их красивой работы зависит всё остальное. И как мы все прекрасно понимаем, ровно и красиво может быть только в лабораторных условиях. Именно там у нас всегда стабильный поток IO операций, нет резких всплесков нагрузки, сетевые пакеты никуда не пропадают, и все графики выглядят как прямая рельса, уходящая за горизонт.
Именно из-за таких расхождений с реальностью у фильтров есть два режима работы. Clean Mode и Dirty Mode. В первом варианте у нас всё хорошо, и все измененные блоки мы успеваем отправить вовремя, а на принимающей стороне успевают их принять и уложить в требуемое место. Но как только над нами сгущаются тучи и мы не успеваем передать очередную порцию данных, CDP фильтр переключается во второй режим. Вернее, он получает команду от демона, что у того переполнена очередь на отправку и новые данные хранить негде. После чего фильтр перестаёт передавать данные, а только ведёт учёт изменённых блоков. Такие блоки данных помечаются как DirtyBlockMap. Единственное, что можно сделать в этой ситуации - это ждать возвращения стабильного канала связи и отмашки, что всё успешно записалось на таргет. Как только принимается решение, что связь удовлетворяет нашим потребностям, помеченные блоки передаются ещё раз, и в случае успеха фильтр переключается обратно в Clean Mode.
Немного сухих цифр: кэш каждого из фильтров - на всё про всё 32 МБ. Вроде мало, но больше и не надо. Задача фильтра - считать блок и как можно быстрее поставить в очередь сорс демона. Там кэш - уже 2 ГБ заранее выделенного RAM. Дисковый кеш прокси задаётся пользователем вручную. И в целом надо помнить, что архитектура CDP подразумевает максимальное наполнение кеша всех из компонентов в надежде, что данные всё же получится отвезти на таргет. И только когда кончается вся свободная память, реплика останавливается с ошибкой.
Вот так вот можно изобразить на любимых всеми квадратиках с буквами режимы работы. В данном примере у нас установлено RPO 10 секунд, из которых пять секунд (половина RPO) мы отслеживаем изменения данных, а вторую половину времени пытаемся передать последнее их состояние. То есть, промежуточные, как я говорил выше, нас не интересуют.
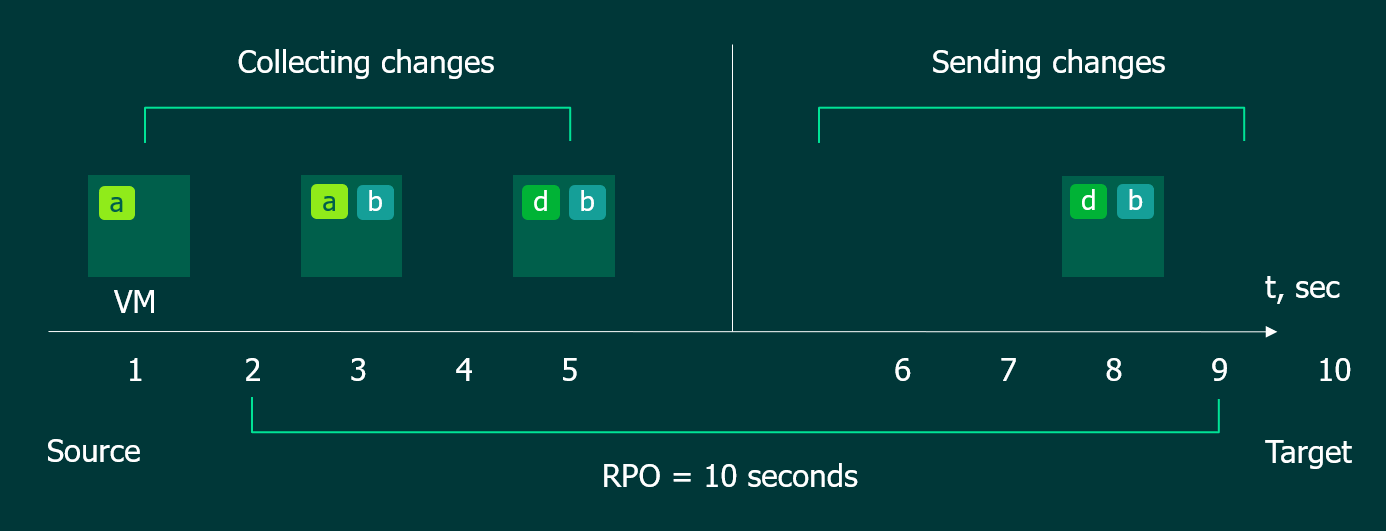
А вот что случается, когда мы не получаем подтверждение доставки от таргета. Данные мы собрали, однако передать их не можем. В этот момент Veeam начинает сохранять в сторонку номера таких блоков. И только номера, никаких данных. Почему? Потому что когда связь восстановится, нам надо передать актуальное состояние блоков.

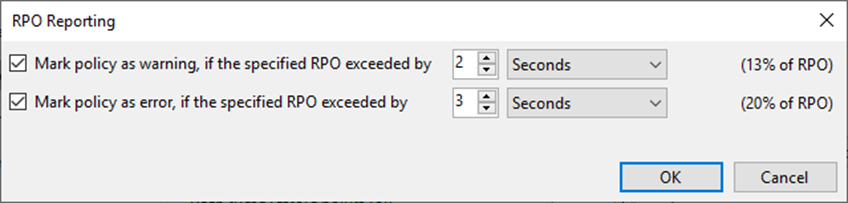
Примечание: Чтобы администратор спал спокойней, предусмотрены два оповещения, скрывающихся под кнопкой RPO Reporting. Фактически они просто считают, сколько данных за указанный промежуток времени мы можем потерять. И бьют в набат, если что-то пошло не так.
Инфраструктура
Обычно, когда заходит речь о проработке какой-либо инфраструктуры, все сразу начинают думать про CPU и RAM. Но только не в этот раз! Здесь надо начинать с поиска вашего сетевика, чтобы он сделал вам сеть с наикратчайшим маршрутом, с 10 Gbit+ линками, и не забыл включить MTU 9000 (Release Jumbo frames!!!) на всём протяжении маршрута. Согласно нашим тестам, такой набор нехитрых действий позволяет добиться прироста производительности почти на 25%. Неплохо, да?
Но не бросаем сетевика на полдороге и тащим его к тем, кто занимается серверами: для VMkernel должны стоять выделенные физичеcкие NIC. Если нет - не приходите жаловаться на тормоза. Ибо сеть, скорее всего, будет забита под потолок своих возможностей. Но вообще, чисто технически, минимально нужны гигабитные карточки и задержки в пределах 80 мс.
Теперь сетевика можно уже отпустить и переключиться, например, на таргетный сторадж. Тут всё очень просто: всегда используйте выделенный сторадж. Процесс записи невозможно как-то замедлить, попросить подождать пока идёт транзакция от другого приложения, и так далее. Нет, сторадж будет молотить на весь свой ценник и вряд ли будет очень рад дополнительным нагрузкам. Хотя, конечно, тут всё зависит от вашего железа. Ну и роли прокси, конечно же, лучше выдавать выделенным машинам. Насчёт того, физическим или виртуальным - тут мнения расходятся. Лично я за физические, но правильно будет протестировать на месте.
И общий совет на все случаи жизни: десять маленьких CDP политик всегда будут работать лучше и стабильней, чем одна большая. Что такое маленькая политика? Это до 50 машин или 200 дисков. В мире большого энтерпрайза это считается за немного. Технически, опять же, здесь ограничений нет, и проводились успешные тесты аж до 1500 машин и 5000 дисков. Так что лучше, опять же, протестировать на месте и найти оптимальный для себя вариант.
Немного о прокси
И хотя кажется, что прокси серверам в схеме CDP отведена роль тупых молотильщиков трафика, без их успешного взаимодействия всё остальное теряет смысл. И задачи там решаются достаточно серьёзные, так что не будем принижать их вклад в общее дело.
Что хочется сказать про этих ребят:
Дисковый кеш - это исключительно запасной план на случай закончившейся оперативки. Всё придумано и сделано так, будто находится исключительно в RAM. Поэтому, пожалуйста, не жадничайте и дайте серверам памяти.
Не надо заставлять один и тот же прокси сервер выступать в роли сорсного и таргетного. Ничего хорошего из этого не выйдет. Запретить вам так сделать мы не можем, однако будем долго отговаривать.
В идеальном мире на один ESXi - один прокси.
А вот физический или виртуальный на том же хосте - этого вам никто не скажет, и надо тестировать. Часто бывает, что виртуальный оказывается быстрее физического.
Да и вообще, общая логика такова, что чем больше вы сможете развернуть прокси серверов, тем лучше будет результат. Особенно если речь идёт о репликации между удалёнными дата центрами.
Также самые внимательные заметят, что на шаге назначения проксей есть кнопка Test с таинственным набором цифр внутри.
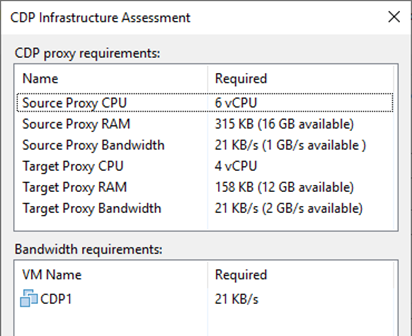
Давайте разбираться что же это такое и откуда оно взялось. Все эти скорости и количества являются ничем иным, как усреднёнными максимумами за последний час, полученными от vCenter. То есть это не мы что-то там померили в моменте, ловко запустив какие-то таинственные тесты, а такова родная статистика хостов за последний час.
Давайте теперь пройдёмся по строчкам.
Source Proxy CPU: количество ядер CPU на всех доступных проксях, которые могут работать в качестве сорса. Видим vCPU, но читаем как ядра CPU.
Source Proxy RAM. Здесь уже посложней будет. Цифра перед скобками показывает, сколько оперативки нам может понадобиться для данной CDP политики.
Формула расчёта довольно простая: RPO* пропускную способность.
Пропускную способность кого/чего? Да всех дисков всех вируталок, участвующих в этой политике. Напоминаю, что берётся максимальное значение за последний час.
То есть предположим, что наш RPO - 15 секунд, и что диски выдают 150 Мб/сек. Значит, нам понадобится 2250 Мб RAM.
А цифра в скобках - это вся доступная оперативка на всех наших проксях, Но, как обычно, есть нюансы. Во-первых, половина RAM считается зарезервированной под нужды ОС и других приложений. Это можно подправить ключиком в реестре в любую сторону (сие остаётся полностью на вашей совести). Во-вторых, учтите, что в случае возникновения задержек на сети или задумчивости хранилища, данные будут сохраняться в кеше до двух минут, после чего будет включена аварийная сирена. И если в течение этих двух минут память переполнится, то подключится медленный дисковый кэш.
Source Proxy Bandwidth. Здесь опять всё просто. Число перед скобками мы получаем от vCenter, а число в скобках считается на основе доступного количества ядер с округлением до целого. Если мы шифруем трафик, то это 150 Мб/с на ядро. Если не шифруем, то 200 Мб/с на ядро.
Target Proxy CPU. Всё ровно так же, как у сорса: взяли и посчитали все доступные ядра на доступных проксях.
Target Proxy RAM. Хочется, как и в предыдущем пункте, сказать, что всё такое же, но нет. Здесь в формулу для расчёта внесён поправочный коэффициент 0.5. А значит, что если мы за те же 15 секунд хотим обработать 150 Мб/c от дисков, то понадобится нам уже только 1125 RAM (вместо 2250, как это было с сорсом).
Target Proxy Bandwith. Здесь тоже не обошлось без скидок. Считаем, что одно ядро при шифровании трафика будет обрабатывать 350 Мб/c, а без шифрования - все 400 Мб/c.
И помним важное: таргет и прокси меняются ролями в момент фейловера. То есть вся схема начинает работать в обратную сторону. Поэтому на таргете и есть неактивный фильтр, который оживает в момент фейловера. А фильтр на бывшем сорсе, соответственно, выключается.
Быстрое Ч.А.В.О. в конце
Как добавить в CDP Policy выключенную машину?
Никак. Виртуалка выключена > фильтр не работает > передавать нечего.
Какие версии vSphere поддерживаются?
Ну я же просил - читайте документацию, там всё есть. Но пользуйтесь пока я добрый: 6.5, 6.7, 7.0
Хочу минимальное RPO, чтобы ну вообще ничего не потерялось.
Если у вас железо хорошее (прям хорошее-хорошее, а не вам кажется, что хорошее), то вполне реально добиться RPO в 2 секунды. А так, в среднем по больнице, вполне реально обеспечивать 10-15 секунд.
А что с vRDM?
Всё отлично поддерживается.
А можно CDP прокси назначить и другие роли?
Назначайте, мы не против. Только следите за соответствием доступных ресурсов предполагаемым нагрузкам.
А можно CDP реплику, как и обычную, использовать для создания бекапов?
Нет. Во всяком случае сейчас.
Я могу запустить CDP реплику из консоли vCenter?
Нет. С точки зрения vCenter там какой-то фарш из дельта дисков, поэтому он выдаст ошибку зависимостей.
А если я руками удалю CDP реплику из Inventory в vCenter?
Умрут все id и всё сломается. А вы чего ожидали?
А если таргетная стора будет чем-то очень загружена?
Veeam будет присылать на почту уведомления, что очень старается, но у вас ботлнек на принимающей стороне и нельзя впихнуть невпихуемое.
А что с Hyper-V?
Это вопрос к Microsoft.
Немного полезных ESXi команд
Убить daemon сервис:
# ps | grep iof
# kill -9 <PID> Остановить/запустить daemon сервис:
# /etc/init.d/iofilterd-vvr stop/startПолюбопытствовать насчет последних логов демона:
# tail -n 100 -f /var/log/iofilterd-vvr.logВыяснить, сколько памяти потребили все демоны:
# vsish -e get /sched/memClients/[iofilterd-PID]/SchedGroupID# memstats -r group-stats -s name:min:max:eMin:rMinPeak:consumed:flags -g [iofilterd-ScheddGroupID] -u mbПроверить установку пакета фильтра. Он выглядит как обычный vib
# esxcli software vib list | grep veecdp


