
Схема компьютера CS-1 показывает, что большая часть отведена для питания и охлаждения гигантского «процессора-на-пластине» Wafer Scale Engine (WSE). Фото: Cerebras Systems
В августе 2019 года компания Cerebras Systems и её производственный партнер TSMC анонсировали крупнейшую микросхему в истории компьютерной техники. С площадью 46 225 мм² и 1,2 триллиона транзисторов микросхема Wafer Scale Engine (WSE) примерно в 56,7 раз больше, чем самый большой GPU (21,1 млрд транзисторов, 815 мм²).
Скептики говорили, что разработать процессор — не самая сложная задача. Но вот как он будет работать в реальном компьютере? Каков процент брака на производстве? Какое потребуется питание и охлаждение? Сколько будет стоить такая машина?
Похоже, инженерам Cerebras Systems и TSMC удалось решить эти проблемы. 18 ноября 2019 года на конференции Supercomputing 2019 они официально представили CS-1 — «самый быстрый в мире компьютер для расчётов в области машинного обучения и искусственного интеллекта».
Первые экземпляры CS-1 уже отправлены заказчикам. Один из них установлен в Аргоннской национальной лаборатории министерства энергетики США, той самой, в которой скоро начнётся сборка самого мощного в США суперкомпьютера из модулей Aurora на новой архитектуре GPU от Intel. Другим заказчиком стала Ливерморская национальная лаборатория.
Процессор с 400 000 вычислительными ядрами предназначен для дата-центров по обработке вычислений в области машинного обучения и искусственного интеллекта. Cerebras заявляет, что компьютер обучает системы AI на порядки эффективнее, чем существующее оборудование. CS-1 по производительности эквивалентен «сотням серверов на базе GPU», потребляющих сотни киловатт. В то же время он занимает всего 15 юнитов в серверной стойке и потребляет около 17 кВт.
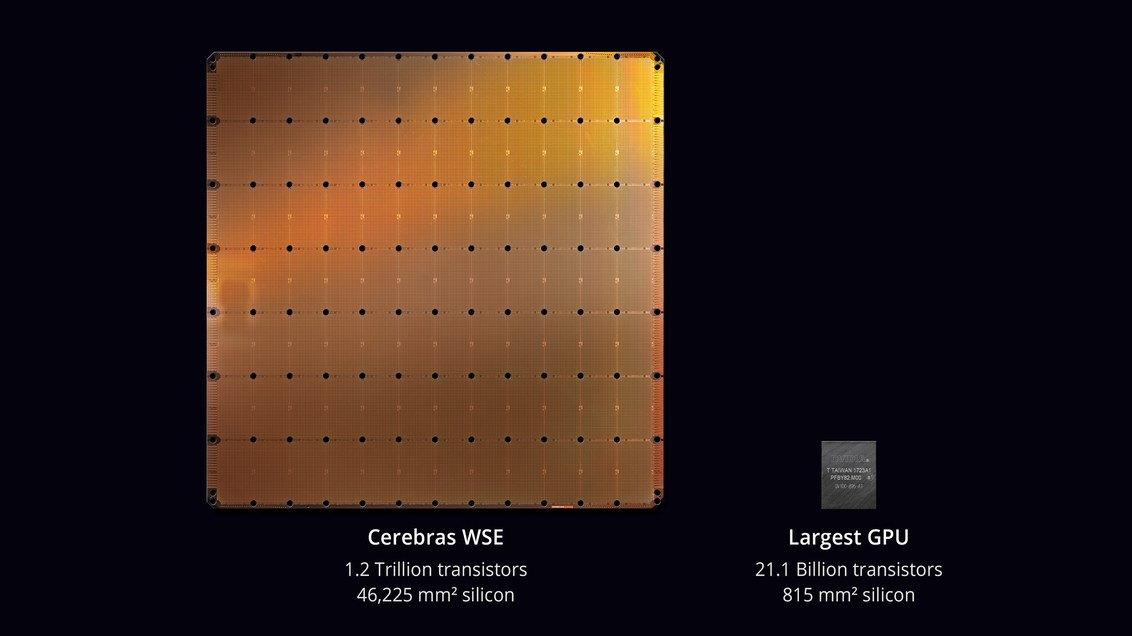
Процессор WSE. Фото: Cerebras Systems
Генеральный директор и соучредитель Cerebras Systems Эндрю Фельдман (Andrew Feldman) говорит, что CS-1 является «самым быстрым в мире компьютером AI». Он сравнил его с кластерами TPU от Google и отмечает, что каждый из них «занимает 10 стоек и потребляет более 100 киловатт, чтобы обеспечить треть производительности одной установки CS-1».

Компьютер CS-1. Фото: Cerebras Systems
Обучение больших нейронных сетей может занимать недели на стандартном компьютере. Установка CS-1 с процессорным чипом из 400 000 ядер и 1,2 триллиона транзисторов выполняет эту задачу за минуты или даже секунды, пишет IEEE Spectrum. Однако Cerebras не представила реальные результаты тестов, чтобы проверить заявления о высокой производительности, например, тесты MLPerf. Вместо этого компания напрямую установила контакты с потенциальными клиентами — и позволила обучать собственные модели нейронных сетей на CS-1.
Такой подход не является чем-то необычным, считают аналитики: «Каждый управляет своими собственными моделями, которые они разработали для своего собственного бизнеса, — говорит Карл Фройнд (Karl Freund), аналитик по приложениям искусственного интеллекта в Moor Insights & Strategies. — Это единственное, что имеет значение для покупателей».
Разработкой специализированных чипов для AI занимаются многие компании, в том числе традиционные представители индустрии, такие как Intel, Qualcomm, а также различные стартапы в США, Великобритании и Китае. Google разработала чип специально для нейронных сетей — тензорный процессор, или TPU. Несколько других производителей последовали её примеру. Системы AI работают в многопоточном режиме, а узким местом становится перемещение данных между чипами: «Соединение микросхем на самом деле замедляет их — и требует много энергии, — объясняет Субраманьян Айер (Subramanian Iyer), профессор Калифорнийского университета в Лос-Анджелесе, который специализируется на разработке чипов для искусственного интеллекта. Производители оборудования изучают множество различных вариантов. Некоторые пытаются расширить межпроцессорные соединения.
Основанный три года назад стартап Cerebras, который получил более $200 млн венчурного финансирования, предложил новый подход. Идея в том, чтобы сохранить все данные на гигантском чипе — и тем самым ускорить вычисления.

Вся пластина-микросхема разделена на 400 000 более мелких секций (ядра), с учётом того, что некоторые из них не будут работать. Чип разработан с возможностью маршрутизации вокруг дефектных областей. Программируемые ядра SLAC (Sparse Linear Algebra Cores) оптимизированы для линейной алгебры, то есть для вычислений в векторном пространстве. Компания также разработала технологию «утилизации разреженности» (sparsity harvesting) для повышения производительности вычислений при разреженных рабочих нагрузках (содержащих нули), таких как глубокое обучение. Векторы и матрицы в векторном пространстве обычно содержат множество нулевых элементов (от 50% до 98%), поэтому на традиционных GPU большая часть вычислений уходит впустую. В отличие от них, ядра SLAC предварительно отфильтровывают нулевые данные.
Коммуникации между ядрами обеспечивает система Swarm с пропускной способностью 100 петабит в секунду. Маршрутизация аппаратная, задержки измеряются в наносекундах.
Стоимость компьютера не называется. Независимые эксперты считают, что реальная цена зависит от процента брака. Также достоверно не известна производительность микросхемы и сколько ядер работоспособны в реальных образцах.
Программное обеспечение
Cerebras огласила некоторые подробности о программной части системы CS-1. Программное обеспечение даёт возможность пользователям создавать собственные модели машинного обучения с использованием стандартных фреймворков, таких как PyTorch и TensorFlow. Затем система распределяет 400 000 ядер и 18 гигабайт памяти SRAM на чипе по слоям нейронной сети таким образом, чтобы все слои завершали работу примерно в одно время со своими соседями (задача оптимизации). В результате информация обрабатывается всеми слоями без задержек. Благодаря подсистеме ввода-вывода из 12 линий 100-гигабитного Ethernet машина CS-1 может обрабатывать 1,2 терабита данных в секунду.
Преобразованием исходной нейросети в оптимизированную исполняемую репрезентацию (Cerebras Linear Algebra Intermediate Representation, CLAIR) занимается компилятор графов (Cerebras Graph Compiler, CGC). Компилятор выделяет вычислительные ресурсы и память для каждой части графа, а затем сопоставляет их с вычислительным массивом. Затем вычисляется путь коммуникации по внутренней структуре пластины, уникальный для каждой сети.
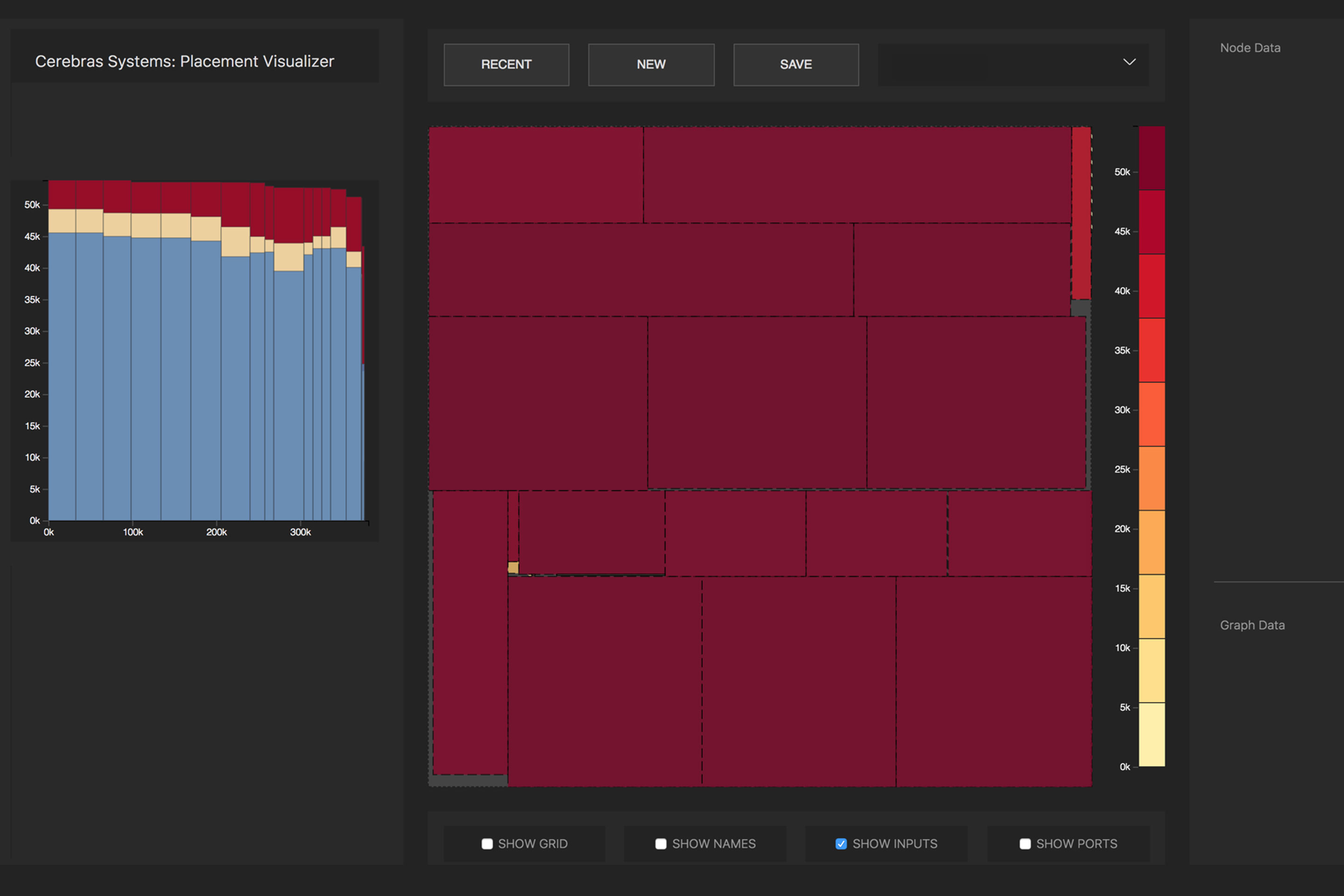
Распределение математических операций нейросети по ядрам процессора. Фото: Cerebras
Из-за огромного размера WSE все слои в нейронной сети одновременно размещаются на нём и работают параллельно. Этот подход уникален для WSE — ни у одного другого устройства недостаточно встроенной памяти, чтобы поместить все слои сразу на одном чипе, заявляет Cerebras. Такая архитектура с размещением сразу всей нейросети на чипе даёт огромные преимущества благодаря высокой пропускной способности и низкой задержке.
Программное обеспечение может выполнять задачу оптимизации для нескольких компьютерах, позволяя кластеру компьютеров действовать как одна большая машина. Кластер из 32 компьютеров CS-1 показывает примерно 32-кратное увеличение производительности, что свидетельствует об очень хорошей масштабируемости. Фельдман говорит, что это отличается от поведения кластеров на основе GPU: «Сегодня, когда вы составляете кластер из графических процессоров, он не ведёт себя как одна большая машина. Вы получаете множество маленьких машин».
В пресс-релизе сказано, что Аргоннская национальная лаборатория работает с Cerebras уже два года: «Развернув CS-1, мы резко увеличили скорость обучения нейронных сетей, что позволило повысить продуктивность наших исследований и добиться значительных успехов».
Одной из первых нагрузок для CS-1 станет нейросетевая симуляция столкновения чёрных дыр и гравитационных волн, которые создаются в результате этого столкновения. Предыдущая версия этой задачи работала на 1024 из 4392 узлов суперкомпьютера Theta.




