
Наверное, мало какому айтишнику нужно объяснять, что такое Memtest86+ — пожалуй, он уже стал более-менее стандартом в тестировании оперативной памяти на ПК. Когда в одной из предыдущих частей я наткнулся на битую планку памяти, пришедшую в комплекте с платой, он (вместе с поддерживающим DDR2 нетбуком) казался очевидным решением. Другой вопрос, что там в принципе нестабильная работа системы была видна невооружённым глазом. В более хитрых случаях, слышал, что кроме банального «простукивания» ячеек памяти до бесконечности, этот инструмент использует некоторые специальные паттерны данных, на которых ошибки в работе DDR выявляются с большей вероятностью. В общем чудесная вещь, жаль, что даже в названии указано: 86 — «Только для x86-совместимых систем». Или нет?
Под катом вы увидите мои попытки портировать MemTest86+ v5.1 на RISC-V и промежуточный итог. Спойлер: оно шевелится!
DISCLAIMER: полученный проект минимально тестировался конкретно мной на конкретной сборке RocketChip на конкретной плате. Точность и безопасность (особенно на других системах) не гарантируется. Используйте на свой страх и риск. В частности, на данный момент никак не обрабатываются зарезервированные области памяти, если они попали в диапазон RAM.
Как я уже рассказывал, не так давно я купил на AliExpress плату с Cyclone IV, но память в ней глючила. К счастью, одна из важных фич той платы заключалась в использовании обычных DDR2 SO-DIMM модулей — таких же, как в моём старом нетбуке. Тем не менее, было бы интересно получить, так сказать, self-hosted решение для тестирования модулей памяти (а фактически, ещё и контроллера). Перспектива отлаживать свои ошибки в условиях битой памяти как-то вообще не радовала. Особо не надеясь на быстрое решение и мысленно готовясь отложить полное переписывание на другом ассемблере на неопределённо долгий срок, открыл на Википедии статью про Memtest86+ и внезапно увидел «Written in: C and assembly» в карточке. Хм, то есть он, хоть и «...86», но написан не целиком на ассемблере? Это обнадёживает. Осталось лишь понять соотношение.
Итак, идём на memtest.org и качаем версию 5.01 под GPL2. Для удобства разработки я перезалил её на GitHub. К счастью, прямо в архиве с исходниками нас встречает файл README.background, озаглавленный
The Anatomy & Physiology of Memtest86-SMP
В нём довольно подробно (и даже с картинками в виде ASCII-art) объясняется высокоуровневая работа кода. В самом начале документа мы видим Binary layout, состоящий из bootsect.o, setup.o, head.o и некоего memtest_shared. Несложно видеть, что указанные три объектных файла получаются из соответствующих ассемблерных исходников. На первый взгляд, всё остальное написано на C! Неплохо, неплохо...
В итоге я скопировал Makefile в Makefile.arch и начал всё переписывать, а что не переписывается, пытаться выкинуть. Первым делом мне, конечно, потребовался тулчейн для RISC-V, который, к счастью, всё ещё лежит у меня со времени предыдущих экспериментов. Сначала я думал делать порт под 32-битную архитектуру, но потом вспомнил, что в плату залит 64-битный процессор, да и тулчейн у меня с префиксом riscv64-.
Лирическое отступление: разумеется, первым делом стоило изучить вопрос совместимости 32- и 64-битного кода. В итоге в спецификации на непривилегированную часть ISA (Instruction Set Architecture) нашёл в пункте 1.3 RISC-V ISA Overview утверждение:
The main advantage of explicitly separating base ISAs is that each base ISA can be optimized for its needs without requiring to support all the operations needed for other base ISAs. For example, RV64I can omit instructions and CSRs that are only needed to cope with the narrower registers in RV32I. The RV32I variants can use encoding space otherwise reserved for instructions only required by wider address-space variants.
Также хочу заметить, что тулчейн с префиксом riscv64- скорее всего запросто соберёт и 32-битный код при правильном выборе целевой архитектуры — об этом позже.
В процессе портирования имеет смысл держать под рукой эти документы:
- The RISC-V Instruction Set Manual Volume I: Unprivileged ISA
- The RISC-V Instruction Set Manual Volume II: Privileged Architecture
- Также не лишним будет какой-нибудь SiFive FU540-C000 Manual — мануал на чип, по поведению аналогичный софт-процессору, что используется для отладки в ПЛИС
Настройка сборки
Для начала условимся: хочется получить порт, пригодный для дальнейшего переноса на архитектуры, отличные от x86 и RISC-V. Также предлагаю выкинуть из кросс-платформенной сборки создание загрузочных дискет и прочую специфику x86.
Что мы в итоге имеем: есть три ассемблерных файла: bootsect.S, setup.S и head.S. Первые два нужны лишь при старте, а третий нужен и впоследствии при релокации в другую область памяти. Дело в том, что чтобы протестировать память «под собой», тестирующему коду нужно сначала переехать на новое место. Сишные файлы собираются в ELF, из которого потом берутся секции кода, данных и т.д. Более того, собирается оно в виде PIC (Position Independent Code) — меня поначалу даже удивило: код хотя и freestanding (то есть без ядра, libc и т.д.), но использует такие продвинутые фичи.
Далее, в Makefile'е периодически попадаются параметры, задающие архитектуру: -march=i486, -m32 и подобные. Надо бы и мне что-нибудь такое написать, а то чё как лох. С указанием архитектуры у RISC-V дела обстоят примерно так: есть варианты rv32 и rv64 (вроде, есть ещё максимально урезанный embedded и припасённый на будущее rv128, но нас они не очень интересует), а название ISA образуется приписыванием к этому префиксу букв, обозначающих расширения: i — базовый целочисленный набор инструкций, m — целочисленное умножение и деление,… Конечно, хотелось бы обойтись rv64i, но вряд ли будет легко портировать Memtest86 на архитектуру без умножения. Правда, похоже компилятор просто сгенерирует вместо «проблемных» инструкций вызовы функций, но есть риск остаться с сильно пониженной производительностью (не говоря уже о том, что эти функции нужно будет написать или где-то взять).
Также потребуется строчка ABI. В принципе, азы calling convention описаны уже в указанном Volume I в части «RISC-V Assembly Programmer’s Handbook», поэтому просто выполню что-то вроде
$ riscv64-linux-gnu-gcc-9 -mabi=help
riscv64-linux-gnu-gcc-9: error: unrecognized argument in option ‘-mabi=help’
riscv64-linux-gnu-gcc-9: note: valid arguments to ‘-mabi=’ are: ilp32 ilp32d ilp32e ilp32f lp64 lp64d lp64f
riscv64-linux-gnu-gcc-9: fatal error: no input files
compilation terminated.И недолго думая, возьму lp64. Забегая вперёд скажу, что с этим ABI заголовочные файлы из стандартной библиотеки не заработали, поэтому взял lp64f, а ARCH «проапгрейдил» до rv64imf. Без паники, я не планирую реально использовать в своём порте floating point.
Поскольку углубляться в написание кросс-платформенных линкер-скриптов как-то не хотелось — и так не сразу удалось подобрать ключи к ld, решил обойтись одним ассемблерным файлом head.S, цепляющимся перед остальными функциями с помощью memtest_shared.arch.lds. Из него я выкинул указание на формат вывода и архитектуру (всё-таки, это проще поменять из переменной в Makefile'е), а также временно закомментировал DISCARD в конце, с ходу не сумев разобраться, какие конкретно секции отладочной информации мне нужны. (Забегая вперёд: ладно отладочная информация, а вот .rela добавить пришлось) Вообще говоря, в x86-версии подчёркивалась необходимость уместиться в 64k — буду надеяться, что это просто как-то связано с особенностями реального режима и на RISC-V нас не касается. В итоге будет, как и в оригинале, собираться shared object с PIC, из него выкусываться код и данные, которые будут загружаться в память.
Собираем… и компиляция валится на первом же файле reloc.c — он, по-видимому, взят из какого-нибудь ld-linux.so и отвечает за поддержку Global Offset Table и т.д. в соответствии с calling conventions для x86. Оказалось, в нём потребовалось работать напрямую с регистрами с помощью ассемблерных вставок. Но мы-то на RISC-V — он-то изначально сделан для нативной поддержки PIC, поэтому смело выкидываем reloc.c. Далее там ещё попадались вставки, местами довольно длинные. К счастью, они были или в коде тестов сразу после закомментированного кода на C, который они оптимизируют (из них я вновь сделал полноправные куски кода, переключаемые директивой препроцессора) или что-то платформенно-зависимое, без чего в крайнем случае можно (наверное) обойтись (вроде включения-выключения кэша, вычитывания CPUID и т.д.). Наконец, были отдельные вещи типа вызова rdtsc, который я без больших проблем тоже вынес в платформенно-зависимый хедер и перереализовал в соответствии с документацией на RISC-V.
В итоге получился каталог arch/i386, куда переехало большое количество кода поддержки PCI, чтения информации из чипсетов, платформенно-зависимые определения memory-mapped адресов и т.д. Также туда уехало начало функции test_start, являющееся точкой входа из setup.S в код на C. Долго ли, коротко ли, но закомментировав всё что можно и перереализовав под RISC-V всё, что закомментировать нельзя (вроде setup.S и кода работы с последовательным портом в реализации SiFive), я получил каталог arch/riscv, с которым всё более-менее скомпилировалось.
Тут я вынужден уточнить, что сами эксперименты частично проводились до начала написания статьи, поэтому конкретная последовательность действий может содержать некоторое количество «художественного вымысла». Впрочем, я стараюсь как минимум вести изложение таким образом, чтобы оно в любом случае представляло одну из возможных траекторий (я программист, я так помню). Поэтому давайте посмотрим, как всё это запустить.
Запуск на железе
Со времён прошлых экспериментов у меня всё ещё пылится «стенд» из Raspberry Pi, соединённой проводами с отладочной платой. Провода обеспечивают UART, JTAG и адаптер с SD-карточкой. В конфигурационную память зашит некий RV64-процессор с контроллером DDR2. Как и в прошлые разы, включаю «малинку», открываю до неё две SSH-сессии, одна из которых пробрасывает 3333 порт TCP для соединения gdb с OpenOCD. В одной из сессий стартую minicom, чтобы наблюдать за UART, в другой — openocd, чтобы отлаживать с хоста по JTAG. Включаю питание платы — и побежали сообщения в консоли о том, как оно грузит данные с SD.
Теперь можно выполнить команду:
riscv64-unknown-elf-gdb \
-ex 'target remote 127.0.0.1:3333' \
-ex 'restore /path/to/memtest_shared.bin binary 0x80010000' \
-ex 'add-symbol-file /path/to/memtest_shared 0x80010000'
-ex 'set $pc=0x80010000'опции -ex командуют gdb сделать вид, что пользователь ввёл эти команды с консоли:
- первая устанавливает соединение с OpenOCD
- вторая копирует содержимое указанного файла хоста по указанному адресу
- третья объясняет gdb, что информацию об исходном коде нужно брать из вот этого файла, с учётом того, что загружен об был по вот этому адресу (а не тому, что указано в нём самом)
- обратите внимание: символы мы берём из ELF-файла, а загружаем «сырой» бинарник
- наконец, четвёртая принудительно переводит указатель текущей команды на наш код
К сожалению, не всё идёт абсолютно гладко, и хотя строчки кода в отладчике показываются корректно, но во всех глобальных переменных — нули. На самом деле, если в gdb выполнить команду вида p &global_var, мы, увы, увидим адрес в соответствии с изначальным адресом загрузки (у меня — 0x0), в не указанным с помощью add-symbol-file. Как костыльное, но очень простое решение, я просто добавлял к указанному адресу 0x80010000 вручную и смотрел содержимое памяти через x/x 0xADDR. Вообще-то, можно было бы временно указать правильный начальный адрес в линкер-скрипте, который на данный момент будет совпадать с адресом загрузки в данной тестовой конфигурации.
Особенности релокации на современных архитектурах
Хорошо, как загружать код худо-бедно разобрались — запускаем. Не работает. Пошаговая отладка показывает, что мы падаем в процессе работы функции switch_to_main_stack — похоже, она всё-таки пытается использовать не релоцированное значение адреса символа, соответствующего рабочему стеку.
Всё тот же первый том документации рассказывает нам о разных псевдоинструкциях и их работе с включённым и выключенным PIC:

Как видим, общий принцип в том, что адреса в памяти отсчитываются от текущей инструкции, причём первая прибавляет верхнюю часть смещения, а последующий add дошлифовывает младшие биты. Едва ли такое поможет для объявления глобальной переменной вроде
struct vars * const v = &variables;А потому берём документацию RISC-V ELF psABI с описаниями видов релокаций и пишем платформенно-зависимую часть для reloc.c. Тут нужно заметить, что оригинальный файл, видимо, был взят из кросс-платформенного кода. Там даже вместо указания конкретной разрядности используются макросы вида ElfW(Addr), раскрывающиеся в Elf32_Addr или Elf64_Addr. Не везде, правда, поэтому добавим их, где они отсутствуют в общем коде (а так же в коде arch/riscv/reloc.inc.c — всё-таки для RISC-V нет особого смысла завязываться на конкретную разрядность, там где это не требуется).
В итоге switch_to_main_stack начал проходить (не без платформенно-зависимой ассемблерной инструкции, конечно). Дебаггер же показывает глобальные переменные всё ещё криво. Ну и ладно :(
Определение оборудования
Конечно, для тестов можно было бы вместо выкинутого кода определения оборудования использовать захардкоженные константы, но под каждую конкретную сборку процессора пересобирать memtest — это даже по меркам моей прикладной задачи чересчур костыльно. Поэтому будем поступать «как взрослые серьёзные люди». К счастью, на RISC-V (а наверное, и на большинстве современных архитектур) принято, чтобы загрузчик передавал коду указатель на Device Tree Blob, являющийся скомпилированной версией DTS-описания вроде такого:
/dts-v1/;
/ {
#address-cells = ^_^ltgt^_^;
#size-cells = ^_^ltgt^_^;
compatible = "freechips,rocketchip-unknown-dev";
model = "freechips,rocketchip-unknown";
chosen {
bootargs = "console=ttySIF0,125200 debug loglevel=7";
};
firmware {
sifive,uboot = "YYYY-MM-DD";
};
L16: aliases {
serial0 = &L8;
};
L15: cpus {
#address-cells = ^_^ltgt^_^;
#size-cells = ^_^lt�gt^_^;
timebase-frequency = ^_^ltgt^_^;
L5: cpu@0 {
device_type = "cpu";
clock-frequency = ^_^lt�gt^_^;
compatible = "sifive,rocket0", "riscv";
d-cache-block-size = ^_^ltgt^_^;
d-cache-sets = ^_^lt@gt^_^;
d-cache-size = ^_^ltကgt^_^;
d-tlb-sets = ^_^ltgt^_^;
d-tlb-size = ^_^lt gt^_^;
i-cache-block-size = ^_^ltgt^_^;
i-cache-sets = ^_^lt@gt^_^;
i-cache-size = ^_^ltကgt^_^;
i-tlb-sets = ^_^ltgt^_^;
i-tlb-size = ^_^lt gt^_^;
mmu-type = "riscv,sv39";
next-level-cache = <&L10>;
reg = <0x0>;
riscv,isa = "rv64imafdc";
status = "okay";
timebase-frequency = ^_^ltgt^_^;
tlb-split;
L3: interrupt-controller {
#interrupt-cells = ^_^ltgt^_^;
compatible = "riscv,cpu-intc";
interrupt-controller;
};
};
};
L10: ram@80000000 {
device_type = "memory";
reg = <0x0 0x80000000 0x0 0x40000000>;
reg-names = "mem";
};
L14: soc {
#address-cells = ^_^ltgt^_^;
#size-cells = ^_^ltgt^_^;
compatible = "freechips,rocketchip-unknown-soc", "simple-bus";
ranges;
L1: clint@2000000 {
compatible = "riscv,clint0";
interrupts-extended = <&L3 3 &L3 7>;
reg = <0x2000000 0x10000>;
reg-names = "control";
};
L2: debug-controller@0 {
compatible = "sifive,debug-013", "riscv,debug-013";
interrupts-extended = <&L3 65535>;
reg = <0x0 0x1000>;
reg-names = "control";
};
L9: gpio@64002000 {
#gpio-cells = ^_^ltgt^_^;
#interrupt-cells = ^_^ltgt^_^;
compatible = "sifive,gpio0";
gpio-controller;
interrupt-controller;
interrupt-parent = <&L0>;
interrupts = <3 4 5 6 7 8>;
reg = <0x64002000 0x1000>;
reg-names = "control";
};
L0: interrupt-controller@c000000 {
#interrupt-cells = ^_^ltgt^_^;
compatible = "riscv,plic0";
interrupt-controller;
interrupts-extended = <&L3 11 &L3 9>;
reg = <0xc000000 0x4000000>;
reg-names = "control";
riscv,max-priority = ^_^ltgt^_^;
riscv,ndev = ^_^ltgt^_^;
};
L6: rom@10000 {
compatible = "sifive,maskrom0";
reg = <0x10000 0x2000>;
reg-names = "mem";
};
L8: serial@64000000 {
compatible = "sifive,uart0";
interrupt-parent = <&L0>;
clocks = <&tlclk>;
interrupts = ^_^ltgt^_^;
reg = <0x64000000 0x1000>;
reg-names = "control";
};
L7: spi@64001000 {
#address-cells = ^_^ltgt^_^;
#size-cells = ^_^lt�gt^_^;
compatible = "sifive,spi0";
interrupt-parent = <&L0>;
interrupts = ^_^ltgt^_^;
reg = <0x64001000 0x1000>;
clocks = <&tlclk>;
reg-names = "control";
L12: mmc@0 {
compatible = "mmc-spi-slot";
disable-wp;
reg = <0x0>;
spi-max-frequency = ^_^lt�gt^_^;
voltage-ranges = <3300 3300>;
};
};
tlclk: tlclk {
#clock-cells = ^_^lt�gt^_^;
clock-frequency = ^_^lt�gt^_^;
clock-output-names = "tlclk";
compatible = "fixed-clock";
};
};
};Когда-то я уже разбирал ELF-файлы, а сейчас с FDT (flat device tree) вновь убеждаюсь: эти спецификации пишут добрые заботливые люди (ещё бы, им же потом это самим парсить!) и разбор таких файлов (по крайней мере, пока не требуется обрабатывать недоверенный ввод) особых проблем не представляет. Так и здесь: в начале файла идёт нехитрая структура-заголовок, содержащая magic number 0xd00dfeed и ещё несколько полей. Нас из них интересуют смещение «плоского дерева» off_dt_struct и таблицы строк off_dt_strings. Вообще-то, нужно ещё обрабатывать off_mem_rsvmap, перечисляющие области памяти, в которые лучше не соваться. Я их пока игнорирую (на моей плате их нет), но не повторяйте такого дома.
В принципе, обработка не представляет особого труда: нужно просто идти по плоскому дереву в соответствии с токенами. Ключевых токенов три:
FDT_BEGIN_NODE— в extra data, непосредственно следующем за ним, идёт имя элемента поддерева в виде нуль-терминированной строки. Просто дописываем имя на стекFDT_END_NODE— поддерево закончилось, снимаем элемент со стекаFDT_PROP— тут малость похитрее: за ним идёт структура, за которой идёт len байтов extra data. Имя же «переменной» лежит по смещениюnameoffв string table
struct { uint32_t len; uint32_t nameoff; }
Ну, в общем, и всё: идём по этой секции, не забывая соблюдать выравнивание на 4 байта. Ах да, ложка дёгтя: числа в FDT указаны в big endian формате, поэтому делаем простенькую функцию
static inline uint32_t be32(uint32_t x)
{
return (x << 24) | (x >> 24) | ((x & 0xff0000) >> 8) | ((x & 0xff00) << 8);
}В итоге в riscv_entry первым делом надо распарсить FDT, а часть head.S, отвечающая за передачу управления на riscv_entry, выглядит примерно так
.globl startup_32
# Название -- просто по историческим причинам...
startup_32:
lla sp, boot_stack_top
mv s0, a0 # s0, s1 -- callee-saved
mv s1, a1
# ... чистим .bss
# Выполняем релокацию
jal _dl_start
# Переходим на штатную точку входа
mv a0, s0
mv a1, s1
j riscv_entryВ регистре a0 нам передаётся hart id (hart — это что-то вроде аппаратного потока в терминологии RISC-V) — его я пока не использую, мне бы в однопоточном случае разобраться. В a1 загрузчик кладёт указатель на FDT. Его мы передаём функции void riscv_entry(ulong hartid, uint8_t *fdt_address).
Теперь, с появлением парсилки FDT в моём коде, последовательность загрузки платы стала такой:
- включить питание
- дождаться консоли U-Boot
- ввести в ней команды, чтобы приготовить правильное FDT. В частности, в листе
/chosen/bootargsхранится командная строка ядра. Всё остальное, что я беру из FDT — диапазон RAM, адрес UART,… — можно и нужно оставить, как есть
run fdtsetup fdt set /chosen bootargs "console=ttyS0 btrace" - с помощью команды
fdt addrузнать адрес загрузки FDT, если ещё не смотрели
А со стороны gdb добавляется команда
-ex 'set $a1=0xfdtaddr'
Вывод информации на экран
Как оказалось, кроме ассемблерных вставок есть ещё и известные адреса памяти. Например SCREEN_ADR (именно так, с одной D), который указывает на область, соответствующую тому, что выводится на экран. Когда я на это наткнулся, то просто поместил широким жестом всё, что на него ссылается, под #if HAS_SCREEN, а потом долго отлаживал вслепую. Думал уже вручную раз в сколько-то времени выдавать дамп этого всего в консоль, но потом обратил внимание, что этот же код уж больно много escape-последовательностей выводит в последовательный порт. Оказалось, всё уже написано до нас, нужно только аккуратнее расставить дефайны — и вот он, знакомый интерфейс (правда, чёрно-белый) в окне minicom'а! (На данный момент HAS_SCREEN вообще не используется — я просто завёл массив dummy_con, чтобы по минимуму менять изначальный код.)
Отладка на QEMU
Так я и отлаживал всё на реальной плате, а с некоторых пор — даже не вслепую. Но вот тормозит всё по JTAG — жуть! Что же, в итоге всё должно работать на реальном железе, но вот отладку неплохо было бы вести на QEMU. После некоторого количества экспериментов получилось что-то костыльное, но весьма похожее на работу с платой:
$ qemu-system-riscv64 -M help
Supported machines are:
none empty machine
sifive_e RISC-V Board compatible with SiFive E SDK
sifive_u RISC-V Board compatible with SiFive U SDK
spike_v1.10 RISC-V Spike Board (Privileged ISA v1.10) (default)
spike_v1.9.1 RISC-V Spike Board (Privileged ISA v1.9.1)
virt RISC-V VirtIO Board (Privileged ISA v1.10)Смотрим, какие платы готов эмулировать QEMU. Меня интересует sifive_u-совместимое железо.
$ qemu-system-riscv64 -M sifive_u,dumpdtb -m 1g # Почему-то QEMU пишет в файл с именем on -- без strace не разберёшься
$ ls -l on
-rw-rw-r-- 1 trosinenko trosinenko 1923 янв 19 20:14 on
$ dtc -I dtb < on > on.dts # Декодируем файл
$ vim on.dts # Подправляем bootargs
$ dtc < on.dts > on.dtb
<stdout>: Warning (clocks_property): /soc/ethernet@100900fc:clocks: cell 0 is not a phandle reference
<stdout>: Warning (clocks_property): /soc/ethernet@100900fc:clocks: cell 1 is not a phandle reference
<stdout>: Warning (clocks_property): /soc/ethernet@100900fc:clocks: cell 2 is not a phandle reference
<stdout>: Warning (interrupts_extended_property): /soc/interrupt-controller@c000000:interrupts-extended: cell 0 is not a phandle reference
<stdout>: Warning (interrupts_extended_property): /soc/interrupt-controller@c000000:interrupts-extended: cell 2 is not a phandle reference
<stdout>: Warning (interrupts_extended_property): /soc/clint@2000000:interrupts-extended: cell 0 is not a phandle reference
<stdout>: Warning (interrupts_extended_property): /soc/clint@2000000:interrupts-extended: cell 2 is not a phandle referenceТеперь у нас есть «исправленный» device tree blob. Не меняя конфигурации ВМ (костыли!), запускаем:
qemu-system-riscv64 \
-M sifive_u -m 1g \
-serial stdio \
-s -S-serial stdio переадресует последовательный порт в консоль, ведь будут активно использоваться escape-последовательности. Опции -s -S поднимают gdbserver и создают VM на паузе, соответственно. Можно было бы загружать код с помощью устройства loader, но тогда придётся перезапускать QEMU каждый раз.
Можно подключаться с помощью
riscv64-unknown-elf-gdb \
-ex 'target remote 127.0.0.1:1234' \
-ex 'restore /path/to/on.dtb binary 0x80100000' \
-ex 'restore /path/to/memtest_shared.bin binary 0x80020000' \
-ex 'add-symbol-file memtest_shared 0x80100000' \
-ex 'set $a1=0x80020000' \
-ex 'set $pc=0x80100000'В итоге всё работает более, чем шустро!
Общий принцип работы
Многие, наверное, не знают, но у Memtest86+ есть режим btrace, когда он по циклу пишет сообщения о том, что он делает прямо сейчас (снимок из терминала, в который идёт вывод QEMU):
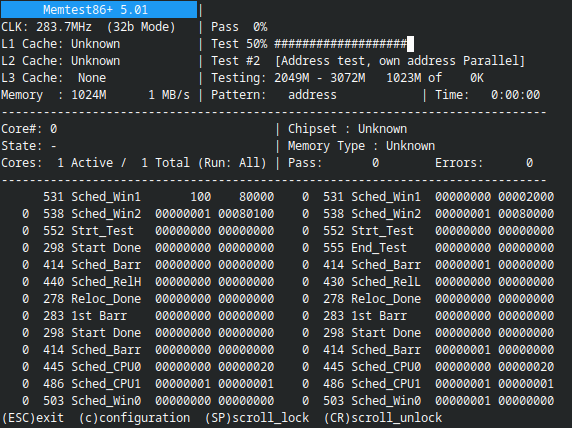
После того, как удалось заставить работать код инициализации, memtest начал показывать в консоли своё окно и падать на тестах. Иногда он показывал понятное сообщение, которое выводил мой обработчик прерываний (точнее, trap): если приглядеться, можно поверх сообщений, что у QEMU память-то битая! увидеть «заплатку» с надписью Illegal instruction и адресами, вычитанными из специальных регистров. За первую строку отвечает регистр mcause (почему?), за вторую — mepc (где?), за третью — mtval (в связи с каким адресом?), который актуален не всегда.

В простейшем случае, обработка ошибок может выглядеть примерно так:
head.S:
# При каждой релокации выставляем адрес обработчика
# Младший бит = 0 --- один для всех, не вектор
# В принципе, может быть не записываемый, но не будем о грустном...
lla t1, _trap_entry
csrw mtvec, t1
# ...
_trap_entry:
csrr a0, mcause
csrr a1, mepc
csrr a2, mtval
jal riscv_trap_entryА теперь, когда аккуратно разложили аргументы в соответствии с calling convention, можно обрабатывать. Идея с массивом строк использовалась и в memtest, и в коде HiFive_U-Boot, а сами сообщения взяты из Volume II:
arch.c:
static const char *errors[] = {
"Instruction address misaligned",
"Instruction access fault",
"Illegal instruction",
"Breakpoint",
"Load address misaligned",
"Load access fault",
"Store/AMO address misaligned",
"Store/AMO access fault",
^_^quotquot^_^, ^_^quot quot^_^, ^_^quot
quot^_^, ^_^quot
quot^_^,
"Instruction page fault",
"Load page fault",
^_^quotquot^_^,
"Store/AMO page fault",
};
void riscv_trap_entry(ulong cause, ulong epc, ulong tval)
{
char buf[32];
cprint(12, 0, "EXCP: ");
if (cause < sizeof(errors) / sizeof(errors[0])) {
cprint(12, 8, errors[cause]);
} else {
itoa(buf, cause);
cprint(12, 8, buf);
}
cprint(13, 0, "PC: ");
hprint3(13, 8, epc, 8);
cprint(14, 0, "Addr: ");
hprint3(14, 8, tval, 8);
HALT();
}Обратите внимание на длиииинные строчки с пробелами — это простой способ «расчистить место» под реальные значения. В противном случае, они перезапишут «подложку» ровно по своей длине, и например, в случае адреса не очень понятно, где граница.
В некоторых случаях всё может быть не так просто: обработчик ошибки отработать не может. Одна из возможных причин заключается в том, что memtest очень упорный: перефразируя изречение про фломастеры: «С одного адреса загрузки можно протестировать всю память, кроме десятка килобайтов, в которых сидишь сам. С двух адресов загрузки можно протестировать вообще всё». Работает это примерно так: функция do_test в файле main.c отсчитывает окна по 2Гб, настраивая тесты (какую область и как тестируем), при этом нулевое и первое окно — это части одной «младшей» области, в которой сидит memtest. Если ему пора сниматься с насиженных мест, он вызывает функцию run_at, которая копирует весь memtest от _start до _end на новое место (этим занимается только «загрузочное» ядро процессора), потом что-то делает с барьером и spinlock'ами для синхронизации всех ядер и с помощью goto *addr; прыгает на ассемблерную точку входа на новом месте. Кстати, обратите внимание, сделано оно не по принципу «прозрачных» для остального кода корутин, а просто через «перезаход».
Тут нужно обратить внимание на то, что ассемблерный код не должен переинициализировать bss нулями при перезапуске — нужно просто вызвать _dl_start для релокации, а потом riscv_entry для запуска, предварительно настроив trap entry. Ну, и ещё одно: неплохо было бы сообщить L1I-кэшу, что код поменялся. Насколько я понял документацию, для этого используется инструкция fence.i.
На самом деле, оригинальный Memtest86+ — многопроцессорный, и при релокации он использует известный адрес структуры barrier_s для синхронизации после релокации. У меня же код пока что однопоточный, поэтому структуру я банально таскаю за собой в сегменте данных. Наверное, если чуть исхитриться, можно будет вообще без глобальных адресов выкрутиться.
Подводные камни
Как я уже говорил, есть сложности очевидные: три ассемблерных файла. Есть сложности неочевидные: рассыпанные по всему коду ассемблерные вставки и обращение по известным адресам. А есть сложности внезапные: например, в какой-то момент я добился запуска первого теста (Own Address, хоть и с включённым кэшем) на реальной плате. Он отработал в релоцированном виде, потом релоцировался на старое место, отработал и там. А потом запустился следующий тест и упал. Из-за ошибки не выровненного доступа. Дело в том, что на x86 можно, например, прочитать или записать uint64_t по адресу 0x80000002 и вам за это ничего не будет. Ну, то есть как не будет: ходят слухи, что выровненные load/store на x86 якобы всегда атомарные, а вот не выровненные — нет. А ещё смутно вспоминаю, что в коде QEMU периодически всплывали ворчливые комментарии, мол «Здесь всё просто, если операция не пересекает границы страниц».
Теперь, когда тесты в целом запускаются, нужно просто их починить — разобраться с unaligned access и т.д.
Кстати, судя по тому, какие ошибки выдаёт реальный RocketChip, а какие — QEMU, можно сделать предположение, что то, что для RocketChip — unaligned access trap, для QEMU просто «слегка неопределённое поведение».
Поискал строчку «misaligned» в первом томе спецификации и вскоре наткнулся на абзац в списке изменений, прямо говорящий
Changed description of misaligned load and store behavior. The specification now allows visible misaligned address traps in execution environment interfaces, rather than just mandating invisible handling of misaligned loads and stores in user mode. Also, now allows access exceptions to be reported for misaligned accesses (including atomics) that should not be emulated.
То есть, получается, раньше — выкручивайся как хочешь, но user-mode code не должно заботить, будешь ли ты эмулировать не выровненный доступ или оно отработает на аппаратном уровне. Сейчас же можно и поругаться. Неопределённого же поведения, похоже, здесь нет принципиально. В любом случае, на меня система поругаться могла всегда — я-то работаю в machine mode или как оно называется. Например, когда я попытался переписать rdtsc (x86) через rdtime (rv64), оно выдало trap, хотя это и допустимая инструкция. Просто, оказалось, на моём процессоре её для простоты аппаратной реализации должно эмулировать ядро через более точный имеющийся memory-mapped регистр.
Есть ещё такая особенность: загрузить наш код могут куда угодно, а куда нужно переместиться в low_test_addr (который логично бы выставить равным младшему тестируемому адресу), мы узнаем, лишь распарсив fdt в сишном коде. На самом деле, есть подозрение, что low_test_addr может быть любым, при условии, что он попадает в первое 2Гб окно и high_test_adr вычислится в доступный адрес… Короче, переместимся в самое начало — это довольно просто: head.S будет сохранять начальный адрес загрузки в initial_load_addr, а в конце riscv_entry вызовем нехитрую функцию move_to_correct_addr:
static void move_to_correct_addr(void)
{
uintptr_t cur_start = (uintptr_t)&_start;
uintptr_t cur_end = (uintptr_t)&_end;
if (cur_start == low_test_addr || cur_start == high_test_adr) {
// Всё отлично, мы уже на месте
return;
}
if (cur_start == initial_load_addr &&
(cur_start - low_test_addr) < (cur_end - cur_start)
) {
// Сейчас будет "финт ушами": переместимся чуть вперёд,
// чтобы не перетереть свой код при переезде в младший адрес
// Делаем это только при необходимости, а то мало ли, нас уже
// загрузили в самые старшие адреса...
serial_echo_print("FIRST STARTUP RELOCATION...\n");
void *temp_addr = (((uintptr_t)&_end >> 12) + 1) << 12;
run_at(temp_addr, 0);
} else {
// Ну, тут всё просто --- идём, куда собирались.
serial_echo_print("FINAL STARTUP RELOCATION...\n");
run_at(low_test_addr, 0);
}
}Вообще, один из подводных камней — это тот факт, что memtest уверен, что RAM отображена куда-то в младшие адреса. На RISC-V это отнюдь не обязательно, поэтому пришлось накостылить смещение в тестах на v->plim_lower.
Ещё одна проблема в целом, типична для «старого» кода, который хотят сделать кросс-платформенным, а именно — файл test.c усыпан переменными типа ulong (затайпдефленный на unsigneg long), которые на 32-битном x86 обычно являются uint32_t, а вот на «гнутых 64 битах» обычно представлен uint64_t. Из этого появляются забавные ошибки вида «Ошибка!!! Good: ffffffff Real: ffffffff Bad bits: 00000000». Что за чепуха? А это просто в функцию передался параметр-паттерн -1, младшие 32 бита которого равны 1. Проблема в том, что у него есть ещё столько же старших битов, и они как бы тоже отнюдь на 0… В общем, было некоторое количество творческой работы: понять, какой ulong представляет из себя тестовые данные (uint32_t), а какой на самом деле имеет ширину машинного указателя (uintptr_t). Кстати, не выровненный доступ после этого тоже исчез. Видимо, это было обращение к uint64_t с шагом 4. RISC-V такое может игнорировать полностью, а вот с точки зрения языка C, кстати, не выровненный доступ — это очень даже UB. Значит нужно просто собрать memtest с UBSan. Между прочим, не удивлюсь, если UBSan в режиме trap-on-error сможет отлично работать вместе с отладкой по JTAG.
Упаковываем для загрузчика
Теперь, когда memtest более-менее выполняет тесты, пора задуматься о том, чтобы грузился он не через отладчик а традиционным загрузчиком U-Boot.
Для своей платы я выработал такое решение: с помощью утилиты mkimage из состава U-Boot я упаковываю якобы ядро Linux:
mkimage -A riscv -O linux -T kernel -C none \
-a 0x80000000 -e 0x80000000 \
-n memtest -d memtest.bin memtest.ubootТеперь его можно положить на SD-карту и запустить с помощью команды
run mmcsetup; run fdtsetup; fdt set /chosen bootargs "console=ttyS0"; fatload mmc 0:1 82000000 memtest.uboot; bootm fdt; bootm 82000000 - ${fdtaddr}(при этом нужно учитывать, что после run фактически указывается имя скрипта — на вашей плате конкретно таких может не оказаться).
Тут меня поджидала ещё одна неожиданность: загрузчик передавал мне корректное значение адреса FDT: 0xbffb7c80. Ну, почти корректное: старшие биты были ffffffff, в итоге ничего не работало. Я уж приготовился к тому, что за меня уже настроили страничную организацию памяти (что мне вообще было не нужно), но ларчик просто открывался: в коде HiFive_U-Boot передача управления выполнялась как вызов функции:
theKernel(machid, (unsigned long)images->ft_addr);Проблема была в том, что объявлена она как
void (*theKernel)(int arch, uint params);Не уверен, что это именно ожидаемое поведение, но, по логике, больше 32 битов адреса туда в любом случае не пролезет, поэтому просто добавим в head.S строчку: li t0, 0xffffffffL.
Промежуточный итог
Итак, оно грузится, что-то тестирует, но понятно, что это скорее начало работы, чем финал:
- Надо бы починить сборку x86. Пока что это больше для порядка — всё равно запускать её без тщательного review и тестирования на реальном железе я не решусь и вам не советую
- Добавить поддержку SMP в код RISC-V
- Более тщательно убрать всё ещё оставшийся вне
arch/платформенно-зависимый код - Перереализовать ассемблерный вставки из
test.cпод RISC-V (он явным образом собирается с опцией-O0!)
")


