
Всем привет! Меня зовут Максим, я руководитель одной из групп эксплуатации инфраструктурных сервисов в Ozon. Наша команда занимается поддержкой и развитием нескольких базовых сервисов компании, одним из которых, по историческим причинам, является сервис разрешения доменных имен (DNS).

В Ozon много различных сервисов и систем. Они общаются друг с другом и внешним миром по доменным именам. DNS — центральное звено, без которого не обходится почти ни одна инфраструктура. Понятно, что когда DNS отдаёт некорректные данные, то это неприятно, когда таймаутит — плохо, когда прилёг — очень плохо, когда прилёг надолго — в принципе, можно расходиться. Значит, одна из основных задач команды инфраструктуры — обеспечить сервисам надёжное и, желательно, быстрое разрешение доменных имён. Об этом мы и поговорим. Также затронем вопросы управления ресурсными записями, жизнь в Multi DC-среде, обслуживание DNS, кеширование, журналирование запросов и возможные проблемы.
Статья может быть полезна коллегам, интересующимся эксплуатацией, архитектурой и высокой доступностью сервисов, да и просто может быть любопытна как история построения инфраструктурной единицы в крупной компании.
Небольшое примечание: потребителями нашего инфраструктурного DNS будут внутренние клиенты компании (любой сервис во внутренней сети). Внешние зоны у нас, конечно же, есть, но, исторически, ими занимается команда NOC (сетевые инженеры), и передавать их в инфру пока не стремится. Поэтому мы ориентируемся только на внутренних клиентов. По этой же причине в статье не будем затрагивать DNSSEC и IPv6.
Disclaimer
Любые совпадения имен машин и IP-адресов с реальными именами и ip случайны.
Основная часть
Так, а зачем нам вообще что-то менять, разве наш текущий инфраструктурный DNS ненадёжен? У меня вот есть три DNS-сервера в трёх ЦОДах, все они прописаны в resolv.conf каждого клиента, то есть если основной сервер прилёг, системный резолвер пойдёт во второй, а затем и в третий.
Дело в том, что в самом неудачном случае (когда остался доступен только третий ЦОД) и при дефолтных настройках резолвера (option timeout:5), последний nameserver ответит на запрос только по прошествии десяти секунд, что в микросервисной среде, когда один сервис взаимодействует с десятками других микросервисов и в коде нет кеширования DNS-запросов, просто недопустимо. Можно поиграть с уменьшенным таймаутом и другими опциями системного резолвера, но это не изменит картину принципиально. Тот же options rotate будет отправлять запросы на серверы из nameserver-списка по алгоритму round-robin (то есть по очереди), и 33 % запросов будут обработаны без таймаутов… ТОЛЬКО 33 %! Нам это не подходит.
Зафиксируем первое требование: Не хотим полагаться на системный resolver.
Идём дальше. Думаю, многие слышали и, возможно, нередко используют “smart DNS resolver”. По сути, это легковесный DNS forwarder, который ставится на каждый хост. Его ключевой особенностью является функциональность отправки параллельных запросов сразу в несколько DNS-серверов и обработка ответа от самого быстрого из них. Достаточно интересно — получаем и отказоустойчивость, и максимальную скорость разрешения имён.
(Возможно, кому-то трафик x2,3,N может быть критичен, поэтому следует это учитывать в своей архитектуре.)
Для гомогенной среды (например, везде Linux) с единым центром управления (DNS контролирует одна команда инженеров) это вполне себе хорошее решение, и, что немаловажно, — простое.
Но, у нас не гомогенная среда (встречается Windows, немного, но есть), а также много инфраструктурных команд; придётся уговаривать каждую команду. К тому же при изменении адреса хотя бы одного DNS-сервера (например, при переезде машины в другой ЦОД), конфигурацию «smart DNS» нужно будет раскатить на тысячи машин… Тоже не подходит.
Вобщем, хочется более гибкого и универсального решения. Универсальное — это значит, что IP-адрес DNS-сервиса не должен меняться.
Второе требование: DNS-сервис должен быть отказоустойчив на сетевом (IP не меняется) уровне (L3 OSI).
Получается, за одним IP-адресом нашего DNS-сервиса должно скрываться два и более реальных DNS-сервера. Давайте для краткости такой IP называть VIP-адресом (Virtual IP), реальный DNS-сервер — real (сервером), а пачку реальных DNS-серверов за VIP — пулом (pool)
Также в Ozon есть общее требование:
Сервис должен переживать полную недоступность одного ЦОД на любой период времени (мы называем это требование DC-1).
Что делать, если за VIP один из real-серверов «задумался» или «приказал долго жить»? По сути, мы попадём в ту же ситуацию, что и с системным resolver, когда некая доля DNS-запросов будет гарантировано не обслужена. Именно поэтому необходим механизм проверок (healthchecks) real-серверов с выкидыванием из пула «больных» и закидыванием обратно «здоровых».
Следующее требование: Проверки (healthchecks) real-серверов со стороны VIP.
Мы будем успевать обрабатывать входящие запросы? Нагрузка на наш текущий DNS сервис весьма незначительна, всего 15-20 тыс. RPS, которую легко вывозит одна виртуалка, поэтому в эту сторону сильно не копаем. А с горизонтальным масштабированием и подавно вопрос «успевания» полностью закрыт. Оно у нас, скорее, для высокой доступности и возможности локализации трафика.
Пятое требование: Уметь горизонтально масштабироваться.
Раз уж у нас несколько ЦОД, стоит подумать и о сетевых задержках. Странно ходить в DNS из одного ЦОД в другой, когда под боком есть рабочий экземпляр DNS. Мы хотим, чтобы при наличии сервера в том же ЦОД сервисы ходили именно в него и получали ответ быстрее.
Шестое требование: Уметь локализовывать трафик в пределах ЦОД.
А что если мне захочется выполнить регламентное обслуживание сервера (обновить ОС, железо, другой деструктив)? Я могу остановить локальную DNS-службу, дождаться неудачных healthchecks, дождаться исключения сервера из пула и заняться обслуживанием. Но тогда все запросы после остановки локального DNS и вплоть до исключения сервера из пула завершатся ошибкой. Такое себе. Поэтому:
Седьмое требование: Плавно выводить трафик с сервера, на котором проводим регламентные работы.
DNS-сервер должен поддерживать динамическое обновление зон по протоколу DNS или API. Это нужно для различных систем наливки железных и виртуальных серверов (Foreman, MaaS, Terraform и т.д.).
Восьмое требование: Поддержка динамически обновляемых зон.
Далее, что насчёт IP-адреса клиента?
Очень желательно, я бы даже сказал, обязательно для поддержки и расследования инцидентов. А ещё это может пригодиться нам в будущем, например geo DNS прикрутить.
Девятое требование: Должны видеть source IP источника запроса.
Логирование DNS-запросов? Да, отдел информационной безопасности очень хочет. К тому же с логами debug куда проще и приятнее.
Десятое требование: Уметь логировать DNS-запросы.
В современном мире без мониторинга никуда, поэтому у DNS-сервиса должны иметься встроенные метрики. Прекрасно, если это будет формат Prometheus, потому что именно эту систему мониторинга мы используем в Ozon.
Последнее требование: Наличие встроенных в DNS-сервис метрик.
Прикинем архитектуру
По задумке путь прохождения клиентского DNS-запроса должен выглядеть так:
Client (DNS-query) → LoadBalancer → Caching DNS → Authoritative DNS
Конечно, все компоненты DNS (LoadBalancer, Caching DNS, Authoritative DNS) — должны быть зарезервированы, поэтому немного усложним схему дублирующими узлами.
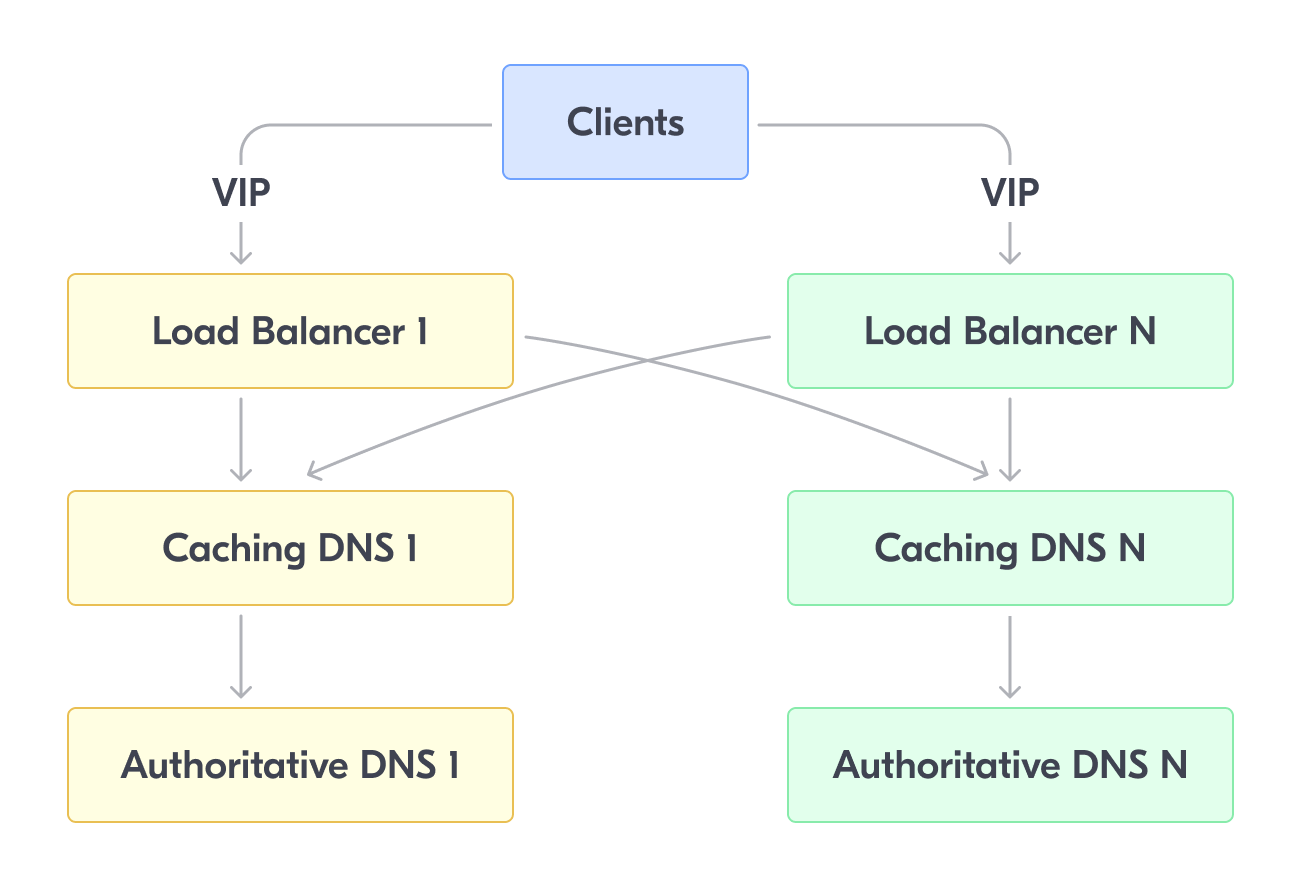
Машины LoadBalancer (LB) являются точками входа клиентского трафика. Напомню, что у них должен быть VIP — единый IP-адрес, на который LB будет откликаться.
VIP (Virtual IP)
На ум приходят две технологии: CARP/VRRP и динамическая маршрутизация (BGP). Давайте сравним:
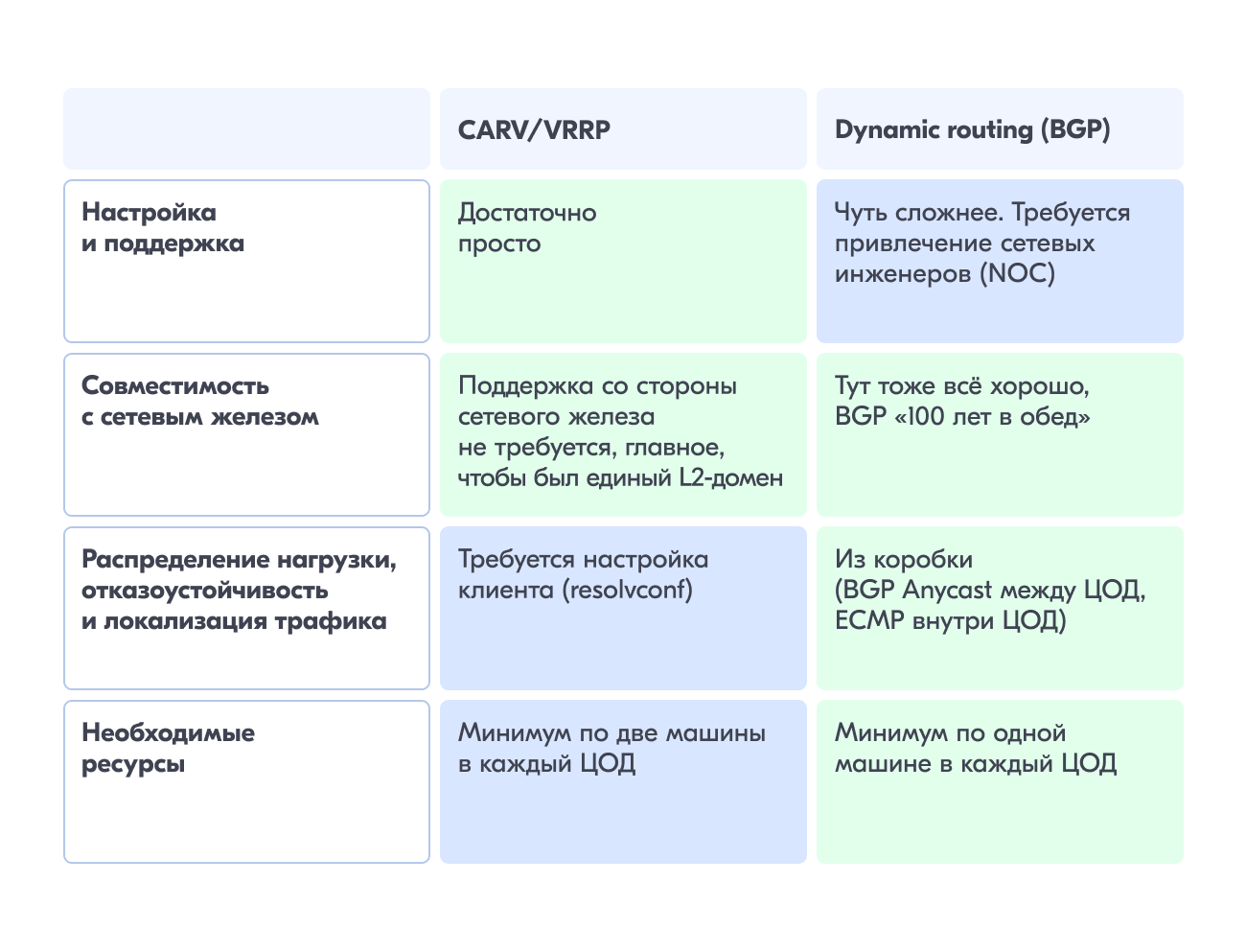
LoadBalancer
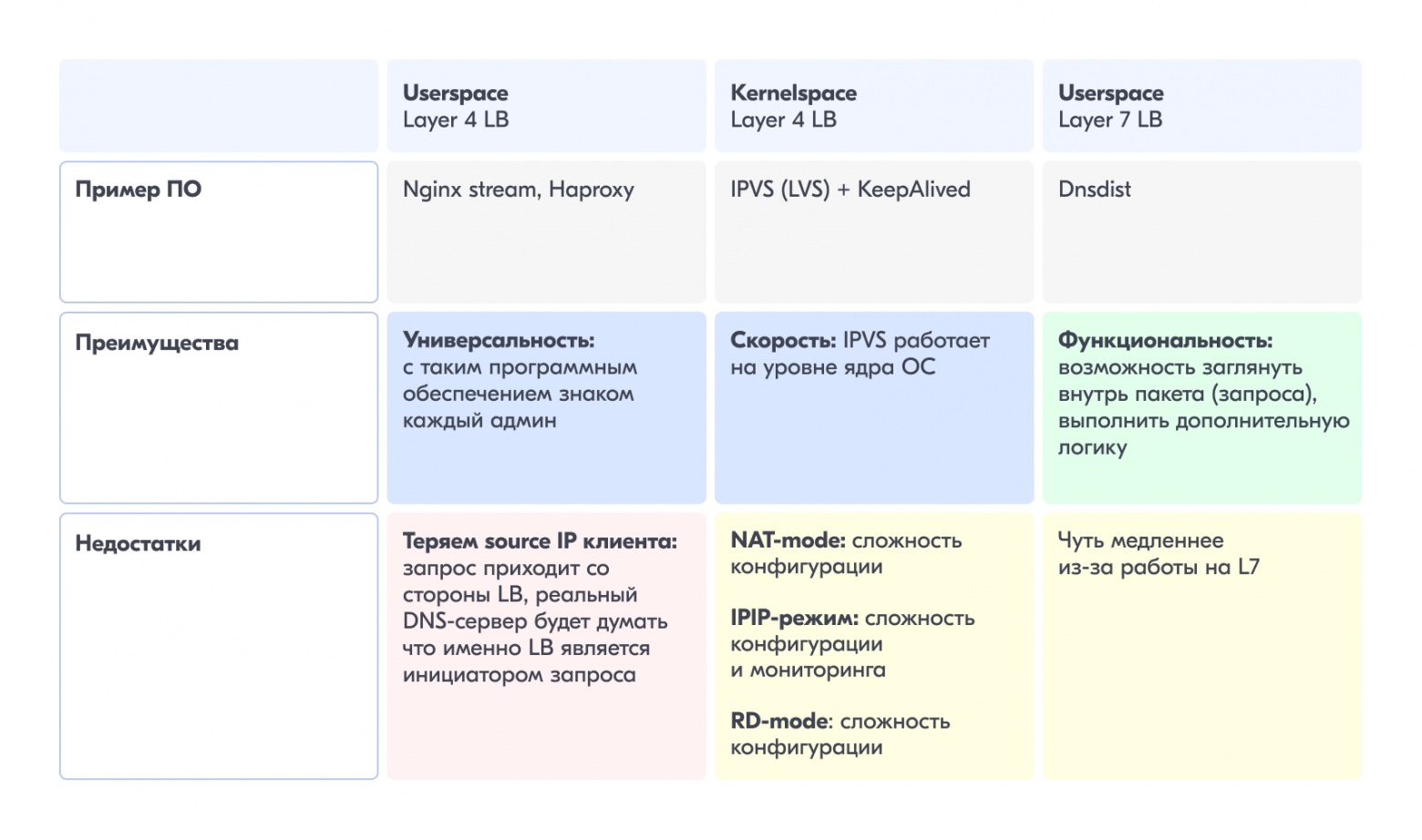
Если мы озаботились вопросом о healthchecks, то должен быть компонент в нашей инфраструктуре, который эти проверки запускает. Обычно таким компонентом является балансировщик (LoadBalancer, или LB). Из названия понятно, что его главная задача — балансировка, то есть распределение трафика между real-серверами. Кроме того, он, как правило, проверяет доступность этих real-серверов, и при необходимости убирает и добавляет их из пула (балансировки).
Тут мы выбирали из следующих вариантов:
Немного про внутреннее устройство сети в Ozon:
Три ЦОД. В качестве физической сети, или underlay, выступает Layer 3 Network, в качестве overlay — BGP EVPN VXLAN. VLAN между ЦОД стараемся не тянуть, чтобы не увеличивать сложность обслуживания сети.
IPVS NAT mode обяжет нас возвращать ответ через тот же IPVS-шлюз, что уже непросто для real-сервера, если таких шлюзов больше одного. Усложняется debug.
IPVS DR mode завязан на L2-сегмент сети. И если не тянуть эти сегменты через VLAN, то «пошарить» real-серверы между ЦОД не получится.
IPVS IPIP — самый подходящий: благодаря GRE-туннелю трафик может быть проброшен в любую L3-сеть и отдан клиенту напрямую, минуя IPVS. Но, опять же, усложняется конфигурирование сети, debug и мониторинг.
Вывод: выбираем Userspace Layer7 LB как самый функциональный по возможностям и простой с точки зрения конфигурации сети.
Про source IP клиента
Обсудим способы, которыми можем выполнить требования записи IP-адреса каждого клиента в логи системы.
EDNS Client Subnet (ECS)
Принцип работы: модифицируем (если есть, и добавляем, если отсутствует) поле ECS в DNS-запросе, прописывая там source IP клиента. Поскольку записывается подсеть, для того, чтобы получить конкретный IP, нам нужна маска /32 (для IPv4). Добавлением поля ECS будет заниматься L7 LoadBalancer.
Недостаток в том, что это решение требует анализа и редактирования исходного запроса: балансировщик принимает DNS-запрос, разбирает его на Layer7 (OSI), принимает решение о модификации или добавлении поля ECS в запрос.
X-Proxied-For (XPF)
По сути, мета-RR (resource record), которая добавляется к запросу. Имеет экспериментальный статус, с истёкшим драфтом.
Не рассматриваем это решение, потому что нам нужно надёжное и проверенное временем.
Proxy Protocol (PROXYv2)
Информация о начальных адресах и портах источника и получателя добавляется в header в начале UDP-датаграммы или TCP-соединения, аналогично тому, как это реализовано в nginx, Haproxy и т.д.
Недостаток в том, что требуется поддержки в lb, resursor и auth.
Поддержка в PowerDNS: Dnsdist начиная с 1.5.0, recursor — с 4.4.0, auth — с 4.6.0.
В результате на момент выбора механизма передачи source IP клиента самым универсальным решением показался ECS. И так как проблем с производительностью на наших небольших объемах нет (15-20 тыс. RPS), мы остановились на нём.
Proxy protocol, честно говоря, пощупать тогда не удалось, не было нужных версий бинарей. Как бы там ни было, этот вариант выглядит вполне рабочим. Недавно руки дошли, протестировали, работает. Оставили его как вариант на будущее, если возможностей ECS перестанет хватать.
Подробнее про source ip от Dnsdist здесь и здесь.
Control Plane
Для хранения RR раньше мы использовали PowerDNS + Generic PostgreSQL backend.
Но после аварии (о которой я расскажу ниже) решили пересмотреть подход к хранению данных. Для динамически обновляемых зон (например, по протоколу DNS update) можно оставить SQL-совместимый backend (тот же PostgreSQL), а для относительно редко меняющихся RR взять что-нибудь более статичное, например, BIND zone backend.
Для редактирования RR удобно пользоваться какой-нибудь готовой админкой, например, PowerDNS-Admin. Тяп-ляп и в production. К сожалению, использование таких инструментов несёт серьёзные риски, которые незаметны на первый взгляд. Мы начали с такого решения, что привело к плачевным последствиям: потере данных и простою на время восстановления. Подробнее об этом ниже.
Так или иначе, необходимо проработать более отказоустойчивое решение.
В нашей компании для доставки кода мы используем Gitlab. Почему бы не доставлять через него статику bind-zone? Подумаем.
Обслуживание (Maintenance)
При обслуживании любого компонента нашей архитектуры мы хотим плавно убирать с него нагрузку без влияния на клиентские запросы, и потом так же плавно возвращать. Другими словами, switchover.
Нам нужен признак, по наличию которого auth, recursor и сервис BGP-маршрутизации поймут, что им следует снять нагрузку. По опыту, самым простым признаком может быть наличие обычного файла: если он отсутствует — нормальный режим работы, присутствует — режим обслуживания (убираем нагрузку).
Локализация трафика
Тут всё просто. Anycast BGP перенаправляет клиента на ближайший LoadBalancer. который всегда находится в том же ЦОД, что и клиент (если анонс VIP поднят и нет специфичных настроек маршрутизации). Далее LoadBalancer отправляет DNS-запрос на локальный, заранее прописанный в конфиге Caching/Authoritative DNS, и только в случае его недоступности — на Caching/Authoritative DNS, находящийся в одном из соседних ЦОД.
Подытожим нашу архитектуру
Клиентский трафик заводится в три ЦОД через BGP anycast. Через ECMP попадает на несколько Layer7 LoadBalancer, далее перенаправляется на Caching DNS, и затем — на Authoritative DNS.
LoadBalancer живут на отдельных машинах (в нашем случае — виртуальных). Caching DNS и Authoritative DNS живут на одной виртуалке (VM).
С транспортным цехом (NOC, network operation center) договорились, что там, где будет настроена BGP-маршрутизация, будут жить только балансировщики.
Caching DNS и Authoritative DNS на одной машине — такая конструкция достаточно автономна, легко горизонтально масштабируется, нет лишних сетевых хопов.
Авторитативный DNS должен иметь два бэкенда: статичный, в котором нельзя удалить RR легким кликом мышки, и динамичный — для всякого рода DNS update (Foreman), редактирование через API (Terraform, MaaS).
Также должно быть управляющее ПО, через которое народ сможет вносить изменения (в RR) в бэкенды, описанные выше.
Нагрузка с машины LB снимается прекращением BGP-анонса VIP-адреса, с машины Caching/Authoritative DNS — неудачным healthcheck со стороны LB.
Failover: в случае проблем на одной из LB-машин BGP-анонс VIP-адреса прекращается, таблицы маршрутизации перестраиваются, клиенты идут на оставшиеся LB-машины.
В случае проблем с виртуальной машиной с Caching/Authoritative DNS балансировщик через healthchecks понимает это и переключает трафик на виртуалку Caching/Authoritative DNS в другом ЦОД.
Switchover: аналогично failover, но без отказа в обслуживании для клиента — нагрузка с машины LB снимается с помощью прекращения BGP-анонса VIP-адреса, с машины Caching/Authoritative DNS — неудачным healthcheck со стороны LB.
Мониторинг через Prometheus.
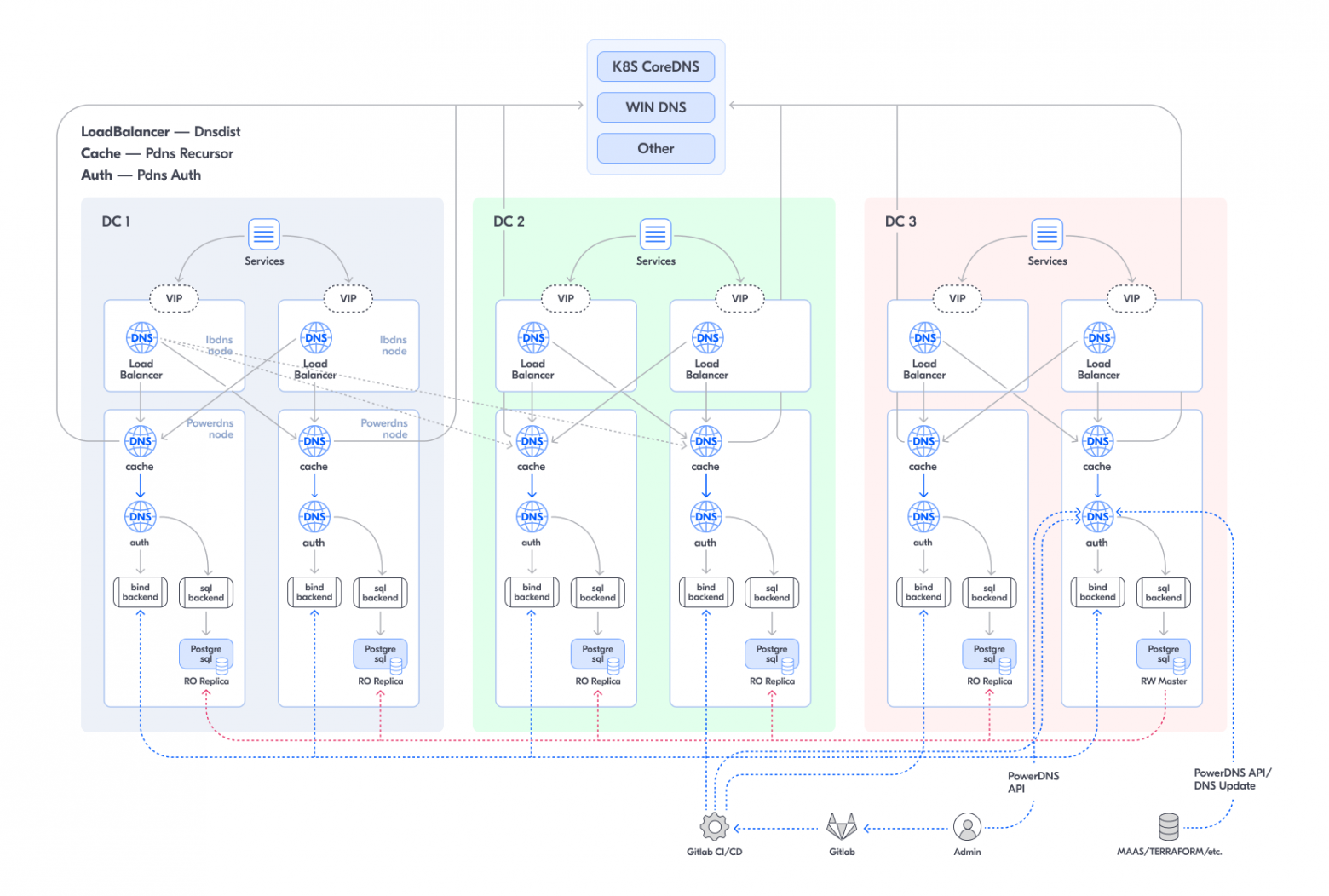
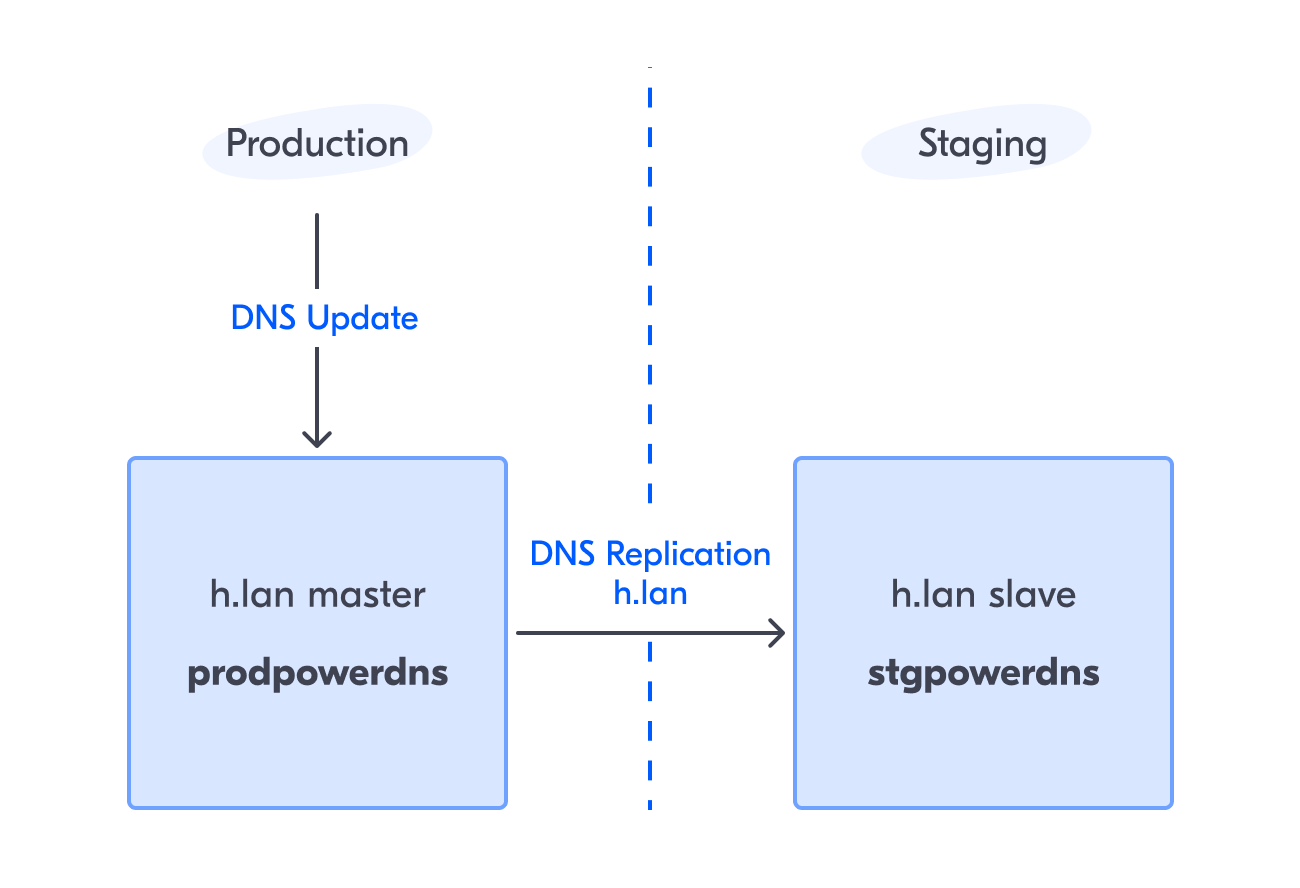
По сути, DNS — это такой же сервис, и перед выкаткой в production новая конфигурация должна быть протестирована на более терпимом к сбоям окружении. Таким окружением для PowerDNS, как и для наших микросервисов, является staging. Для максимального приближения к условиям в prod на PowerDNS кластер в staging-окружении также подаётся нагрузка. Это запросы сервисов из development- и staging-окружений. Таким образом, и по конфигу, и по данным, и по наличию трафика кластеры в production и staging почти идентичны. Разница только в конфигурации «железной» зоны (h.lan). Исторически сложилось, что у нас нет отдельной зоны для production, отдельной для staging и т.д. Все реальные имена машин изо всех окружений находятся в h.lan. Очевидно, что вносить изменения в «железную» зону мы обязаны через единый эндпоинт, которым является production. При этом изменения, прилетевшие в production, мы должны видеть и в staging PowerDNS. Связывать эти окружения БД-репликацией не очень хорошая идея, потому что реплика из staging легко может повлиять на prod, а вот обычная master → slave DNS-репликация (через AXFR) — то, что нужно.
Выбор программного обеспечения
Authoritative DNS и Caching DNS
В качестве authoritative и caching DNS у нас уже использовался PowerDNS, поэтому в первую очередь смотрели на него.
PowerDNS Authoritative Server (или просто pdns auth) поддерживает различные SQL-базы, файлы bind zone, кучу других бэкендов, Lua-записи (это нам чуть позже пригодится), встроенные метрики для Prometheus и SNMP, имеет API для менеджмента RR и управления демоном.
PowerDNS Caching Server (или просто pdns recursor) — высокопроизводительный кеширующий DNS-сервер со встроенной поддержкой Lua-сценариев. Метрики тоже имеются.
L7 LoadBalancer
Долго искать не пришлось: оказывается, в PowerDNS обо всём уже подумали и завезли Dnsdist — балансировщик с защитой от DNS- и DoS-атак.
Справедливости ради попытались нагуглить другие альтернативы, но ничего даже отдалённо напоминающее Dnsdist не нашлось.
BGP
Кроме, собственно, BGP-сервиса нам нужны healthcheks, чтобы снять или вернуть нагрузку (убрать или вернуть анонс /32 префикса VIP), если что-то не так с интерфейсом, dnsdist, или если мы решили вывести машину на обслуживание.
Выбирали между:
ExaBGP — демоном на Python с поддержкой healthchecks, но без BFD.
BIRD — можно сказать, стандартом де-факто в индустрии. Есть встроенный BFD, но нет healthchecks, то есть все проверки придётся костылить сбоку.
Из-за большой применимости и наличия встроенного BFD остановились на BIRD.
Database & database orchestrator
Для редактирования RR PowerDNS требует SQL-совместимую БД. В нашей компании большая экспертиза в PostgreSQL, поэтому выбрали её. Также в качестве оркестратора поверх PostgreSQL мы используем Patroni, здесь выбор тоже очевиден.
Кеширование в PowerDNS
Если взять всю цепочку прохождения DNS-запроса — Dnsdist → PDNS Recursor → PDNS Auth, — то в сумме мы получим пять уровней, на которых запрос может быть закеширован. Пять, Карл!!! Понятно, что если мы включим их все, то навряд ли debug окажется лёгкой прогулкой.
Dnsdist: packet cache.
PDNS Recursor: packet cache, query cache.
PDNS Auth: packet cache, query cache.
Разница между кешами пакетов и запросов следующая.
В кеше пакетов лежат записи в виде уже сформированных ответов. То есть на идентичные запросы без какой-либо дополнительной обработки отдаём готовые ответы. Получается вроде кеша запросов в MySQL.
Query cache или record cache, — кеш внутренних запросов, сюда попадают отдельные записи, то есть ответы от бэкенда. Некоторые запросы приводят к ряду внутренних запросов, которые также попадут в query cache. Самый очевидный пример — когда запрос A-типа приводит к дополнительному запросу CNAME-типа.
TTL в ответе из packet cache не будет меняться, в то время как из query cache TTL честно будет уменьшаться на 1 с каждой секундой.
Что еще… Packet cache для всех ответов проставляет одинаковый TTL (packetcache-ttl), в то время как query cache ориентируется на TTL записи и может быть разным, но не более max-cache-ttl. Если используются бэкенды на основе ОЗУ (не требующие переключений контекста), то packet cache может быть даже вреден и лучше его отключить.
Оставляем максимум два кеша. Какие именно?
Dnsdist для нас — проксирующий узел, который должен просто передать пакет дальше, поэтому кеш здесь не используем.
PDNS Recursor — кеш запросов — да, кеш пакетов — нет. Простой синтетический тест показал, что packet cache на бэкенде bind-zone профита не дает. Поэтому выключим его в pdns, но включим с небольшим TTL query cache. Он нам нужен, чтобы не сильно мучить тяжелый SQL-бэкенд, но и слишком длительным по времени он тоже быть не должен (по крайней мере в нашем случае), чтобы healthcheck сквозь SQL-бэкенд был достаточно актуальным.
Приступим к настройке
Dnsdist на LoadBalancer (LB) узле
/etc/dnsdist/dnsdist.conf
Ключевые моменты
--- алгоритм выбора бэкенда для поступившего запроса
setServerPolicy(roundrobin)
--- backends
newServer({
pool="current_dc",
...
})
newServer({
pool="fallback_dc",
...
})Полный конфиг
--- добавляем в dns запрос source ip клиента - /32 чтобы сохранить весь ipv4 адрес
setECSSourcePrefixV4(32)
--- чтобы можно было подключится к работающему демону и что-нибудь с ним поделать
controlSocket("127.0.0.1:5199")
--- для безопасности
setKey("секретный_ключ")
--- webui для просмотра статистики в realtime
webserver("0.0.0.0:8080")
setWebserverConfig({
password="секретный_ключ_2",
apiKey="",
statsRequireAuthentication=false,
acl="127.0.0.1, ::1, 10.0.0.0/8"
})
--- только чтение, нам нужны только метрики
setAPIWritable(false)
--- принимаем запросы на 53 порту на всех интерфейсах
setLocal("0.0.0.0:53")
--- политика выбора бэкенда для поступившего запроса
setServerPolicy(roundrobin)
--- backends. Для простоты оставим по одному бэкенду на ЦОД (1 в current_dc пуле, 2 в fallback_dc пуле)
newServer({
--- адрес бэкенда
address="10.0.0.1",
--- имя бэкенда
name="powerdns1",
--- один из бэкендов пула "fallback_dc"
pool="fallback_dc",
--- проверка живости бэкенда
checkClass=DNSClass.IN,
checkName="status.backend.powerdns.lan.",
checkType="TXT",
checkTimeout=2000,
--- проверяем 3 раза
maxCheckFailures=3,
--- 3 секунды между попытками
checkInterval=3,
--- должны явно получить ответ, без ошибок
mustResolve=true,
--- добавляем ECS
useClientSubnet=true,
--- ждем 2 удачные попытки перед вводом бэкенда обратно в строй
rise=2
})
newServer({
address="10.0.0.2",
name="powerdns2",
pool="fallback_dc",
checkClass=DNSClass.IN,
checkName="status.backend.powerdns.lan.",
checkType="TXT",
checkTimeout=2000,
maxCheckFailures=3,
checkInterval=3,
mustResolve=true,
useClientSubnet=true,
rise=2
})
newServer({
address="10.0.0.3",
name="powerdns3",
pool="current_dc",
checkClass=DNSClass.IN,
checkName="status.backend.powerdns.lan.",
checkType="TXT",
checkTimeout=2000,
maxCheckFailures=3,
checkInterval=3,
mustResolve=true,
useClientSubnet=true,
rise=2
})
--- если "current_dc" доступен (хотя бы один из его бэкендов), отправляем запросы в него
addAction(PoolAvailableRule("current_dc"), PoolAction("current_dc"))
--- если нет – отправляем запросы в "fallback_dc"
addAction(AllRule(), PoolAction("fallback_dc"))
Если настроить webserver, то можно посмотреть статистику по http://127.0.0.1:8080:
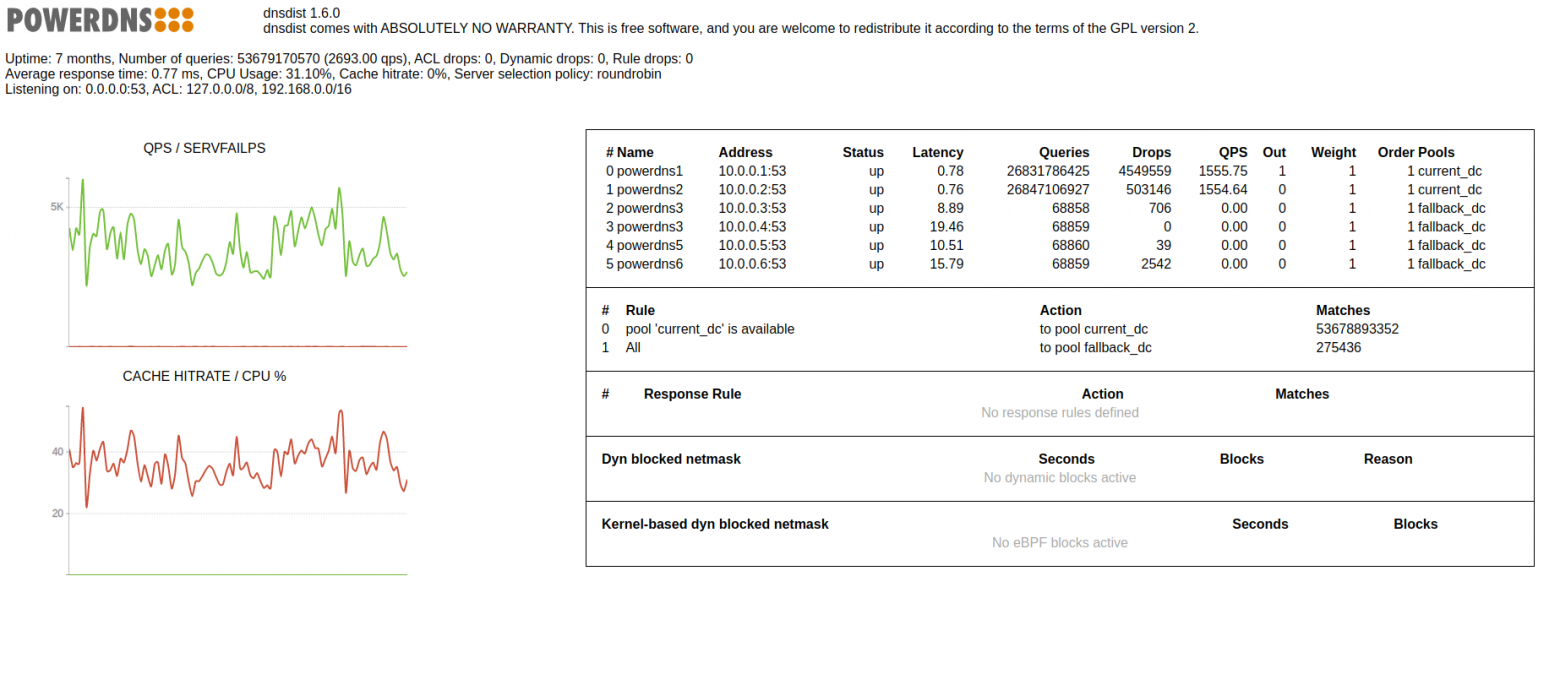
Или её можно посмотреть из CLI:
lbdns1:~# echo "showServers()" | dnsdist -c 127.0.0.1:5100
# Name Address State Qps Qlim Ord Wt Queries Drops Drate Lat Outstanding Pools
0 powerdns1 10.0.0.1:53 up 0.0 0 1 1 0 0 0.0 0.0 0 fallback_dc
1 powerdns2 10.0.0.2:53 up 0.0 0 1 1 163994 3917 0.0 1.2 0 fallback_dc
2 powerdns3 10.0.0.3:53 up 971.8 0 1 1 5209759184 512719881 80.0 40.3 9603 current_dc
3 powerdns4 10.0.0.4:53 up 972.1 0 1 1 5261742931 17716 0.0 75.2 57 current_dc
4 powerdns5 10.0.0.5:53 up 0.0 0 1 1 23001 0 0.0 0.8 0 fallback_dc
5 powerdns6 10.0.0.6:53 up 0.0 0 1 1 23435 0 0.0 1.1 0 fallback_dc
All 1943.0 10471712545 512741514
Что ещё, кроме балансировки, умеет dnsdist?
Отбрасывать неугодные по содержанию запросы, кешировать запросы, лимитировать клиентов по DNS query и по IP, использовать в качестве фильтра eBPF для максимальной производительности.
Если захотите включить packet cache в dnsdist:
pc = newPacketCache(
10000, --- записей в кэше
{
--- максимальный ttl
maxTTL=86400,
--- минимальный ttl для включения в кэш
minTTL=0,
--- кэшируем Server Failure or a Refused
temporaryFailureTTL=60,
---
staleTTL=60,
dontAge=false
}
)
getPool(""):setCache(pc)
Кеш включается на каждый пул. “” — пул по умолчанию. А с помощью setStaleCacheEntriesTTL() можно временно отдавать клиенту устаревший кеш, пока бэкенд не придёт в норму.
BIRD на LoadBalancer узле
Сообщаем наш VIP-адрес, а точнее маршрут к нему (обязательно с префиксом /32). Сам VIP будет висеть на dummy-интерфейсе, а анонс префикса /32 будет убираться и добавляться в BGP через удаление и добавление маршрута /32. Всё это будем делать скриптами под управлением monit.
/etc/bird/bird.conf
log syslog all;
router id 10.1.0.1;
filter z00_p32 {
if net ~ [ 10.10.0.0/23{32,32} ] then accept;
reject;
}
protocol device {
debug { states,routes,filters,interfaces,events,packets };
}
protocol direct {
disabled;
}
protocol kernel {
learn; # Learn all alien routes from the kernel
persist; # Don't remove routes on bird shutdown
scan time 10; # Scan kernel routing table every 2 seconds
import filter z00_p32;
export none; # Export to protocol. default is export none
graceful restart; # Turn on graceful restart to reduce potential flaps in
}
template bgp bgp_template {
debug { states,routes,filters,interfaces,events,packets };
description "Connection to BGP peer";
local as 4200000002;
multihop;
gateway recursive; # This should be the default, but just in case.
add paths on;
graceful restart; # See comment in kernel section about graceful restart.
connect delay time 2;
connect retry time 5;
error wait time 5,30;
import none;
# самое главное место
export filter z00_p32;
bfd on;
}
protocol bgp Node_10_1_1_1 from bgp_template {
neighbor 10.1.1.1 as 4200000001;
source address 10.1.0.1;
}
# bfd, чтобы быстрее детектить проблемы на сети
protocol bfd {
interface "eth*" {
min rx interval 100 ms;
min tx interval 100 ms;
idle tx interval 300 ms;
multiplier 10;
};
multihop {
interval 200 ms;
multiplier 10;
};
import none;
export filter z00_p32;
neighbor 10.1.1.1 local 10.1.0.1 multihop;
}
Monit на LoadBalancer узле
Давайте настроим систему так, чтобы трафик снимался с машины, если мы не можем получить успешный ответ от локального Dnsdist, или когда инженер выполняет регламентные работы.
Алгоритм простой:
Выполняем healthcheck (обычный DNS-запрос к локальному Dnsdist) и проверяем наличие файла /var/lib/vip0.down.
Снимаем анонс (удаляем маршрут к vip0), если результат healthcheck неуспешен или существует /var/lib/vip0.down.
Добавляем анонс (добавляем маршрут к vip0), если healthcheck успешен и отсутствует файл /var/lib/vip0.down.
Скрипт проверки живости:
/usr/local/bin/dns_healthcheck_vip0.sh
#!/bin/bash
dummy_iface=vip0
announce_ip=10.50.0.1
check_record=status.backend.powerdns.lan.
check_type=TXT
check_content=\"up\"
# check1
if [ -e "/var/lib/${dummy_iface}.down" ]; then
echo "file /var/lib/${dummy_iface}.down is exist"
exit 1
fi
# check2
_result=$(dig +short +timeout=3 +tries=2 @127.0.0.1 -t ${check_type} ${check_record})
if [ "${_result}" != "${check_content}" ]; then
echo "failed to check record ${check_record}"
exit 22
fi
echo OKСнимаем анонс маршрута /32:
/usr/local/bin/bgp_withdraw_vip0.sh
#!/bin/bash
dummy_iface=vip0
announce_ip=10.50.0.1
_result=$(ip route show ${announce_ip})
if [ -n "${_result}" ]; then
ip route delete ${announce_ip}/32 && echo OK
else
echo "NOTHING TO DO: route ${announce_ip}/32 not exists"
fiВозвращаем анонс маршрута /32:
/usr/local/bin/bgp_announce_vip0.sh
#!/bin/bash
check_vip () {
iface=${1}
ip=${2}
if [[ "${ip}" =~ ^[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}$ ]]; then
ip -brief a | grep "^${iface} " | grep " ${ip}/32 " | grep -q -v " DOWN "
e_code=$?
if (( e_code != 0 )); then
echo "Interface \"${iface}\" is not UP or IP \"${ip}\" is not match ip format"
exit 0
fi
fi
}
check_maintenance () {
if [ -e "/var/lib/${dummy_iface}.down" ]; then
echo "file /var/lib/${dummy_iface}.down is exist"
exit 0
fi
}
dummy_iface=vip0
announce_ip=10.50.0.1
check_maintenance
check_vip ${dummy_iface} ${announce_ip}
_result=$(ip route show ${announce_ip})
if [ -z "${_result}" ]; then
ip route add ${announce_ip}/32 dev ${dummy_iface} && echo OK
else
echo "NOTHING TO DO: route ${announce_ip}/32 already exists"
fiОсталось передать это всё под управление какого-нибудь супервизора. Старый добрый monit должен с этим справиться.
/etc/monit/monitrc
set daemon 10
set log /var/log/monit.log
set idfile /var/lib/monit/id
set statefile /var/lib/monit/state
set eventqueue
basedir /var/lib/monit/events
slots 100
check program dns_healthcheck_vip0.sh
with path /usr/local/bin/dns_healthcheck_vip0.sh
with timeout 8 seconds
if status != 0 for 3 cycles then
exec /usr/local/bin/bgp_withdraw_vip0.sh
repeat every 5 cycles
if status == 0 for 2 cycles then
exec /usr/local/bin/bgp_announce_vip0.sh
repeat every 5 cyclesPDNS Recursor на узле PowerDNS
Конфигурация рекурсора:
/etc/powerdns/recursor.conf
allow-from=0.0.0.0/0, 127.0.0.0/8, 10.0.0.0/8, 169.254.0.0/16, 192.168.0.0/16, 172.16.0.0/12, ::1/128, fc00::/7, fe80::/10
api-key=секретный_апи_кей
config-dir=/etc/powerdns
forward-zones-file=/etc/powerdns/recursor-forward.zones
hint-file=/usr/share/dns/root.hints
include-dir=/etc/powerdns/recursor.d
local-address=0.0.0.0
local-port=53
disable-packetcache=yes
#packetcache-ttl=5
#packetcache-servfail-ttl=5
max-cache-ttl=86400
max-negative-ttl=10
quiet=no
security-poll-suffix=
setgid=pdns
setuid=pdns
webserver=yes
webserver-address=0.0.0.0
webserver-password=вебсервер_пароль
webserver-port=8082
dnssec=off
# а здесь будем делать всякие интересные вещи, типа контролиовать maintenance режим и беспардонно модифицировать пролетающие запросы и ответы
lua-dns-script=/etc/powerdns/recursor.lua.d/main.lua
lua-maintenance-interval=5
trace=fail
loglevel=5
ecs-ipv4-bits=32
use-incoming-edns-subnet=yesДля удобства объединяем все Lua-вставки в один файл:
/etc/powerdns/recursor.lua.d/main.lua
function fileExists(file)
local f = io.open(file, "rb")
if f then
f:close()
return true
end
return false
end
dofile("/etc/powerdns/recursor.lua.d/maintenance.lua")
dofile("/etc/powerdns/recursor.lua.d/dns.lua")Далее рассмотрим код процедуры maintenance. Наличие файла включает режим обслуживания, отсутствие — выключает. Физически это заключается в проверке наличия файла и присвоении булевой переменной maintenanceState значения true или false.
/etc/powerdns/recursor.lua.d/dns.lua
healthcheckSet = newDS()
healthcheckSet:add{"status.backend.powerdns.lan"}
function preresolve(dq)
if healthcheckSet:check(dq.qname) then
dq.variable = true -- disable packet cache. Это нужно если у вас ключен packet cache в recursor
if maintenanceState == true then
dq.rcode = pdns.NXDOMAIN
return true;
end
end
return false;
endПолный конфиг
healthcheckSet = newDS()
healthcheckSet:add{"status.backend.powerdns.lan"}
backendname_request = "name.backend.powerdns.lan"
backendname_response = "\"powerdns1.lan\""
function preresolve(dq)
if healthcheckSet:check(dq.qname) then
dq.variable = true -- disable packet cache. Это нужно если у вас ключен packet cache в recursor
if maintenanceState == true then
dq.rcode = pdns.NXDOMAIN
return true;
end
end
if dq.qname:equal(backendname_request) then
dq.variable = true -- disable packet cache
dq.rcode=0 -- make it a normal answer
dq:addAnswer(pdns.TXT, backendname_response, 1) -- ttl 1s
return true
end
return false;
endФайл форварда зон:
/etc/powerdns/recursor-forward.zones
# forward zones
h.lan=127.0.0.1:5300
s.lan=127.0.0.1:5300
powerdns.lan=127.0.0.1:5300
# forward zones recurse
+k8s.lan=10.2.0.1, 10.2.0.2
+example.net=9.9.9.9 , 8.8.8.8:53, 8.8.4.4
+.=10.9.0.1
# Где 127.0.0.1:5300 это pdns authPDNS Auth на узле PowerDNS
Конфигурация авторитетного DNS:
/etc/powerdns/pdns.conf
allow-axfr-ips=127.0.0.0/8, ::1
api=yes
api-key=секрет_ари_кей
include-dir=/etc/powerdns/pdns.d # подключаем BIND и PG бэкенды
launch=
local-address=127.0.0.1,10.1.2.1
local-port=5300
cache-ttl=0
negquery-cache-ttl=10
query-cache-ttl=3
security-poll-suffix=
setgid=pdns
setuid=pdns
webserver=yes
webserver-address=0.0.0.0
webserver-allow-from=127.0.0.1,10.0.0.0/8
webserver-password=вебсервер_пароль
webserver-port=8081
enable-lua-records=yes # это чтобы работали LUA RR в бэкенде
primary=no # дальше будет понятно почему
secondary=no # дальше будет понятно почему
xfr-cycle-interval=60
only-notify=
also-notify=
loglevel=5Подключение плагинов bind и gpgsql:
/etc/powerdns/pdns.d/40_bind.conf
launch+=bind
bind-config=/etc/powerdns/backend_bind/zone_bind.conf
bind-supermaster-config=/var/lib/powerdns/supermaster.conf
bind-supermaster-destdir=/var/lib/powerdns/zones.slave.d/etc/powerdns/pdns.d/20_gpgsql.conf
launch+=gpgsql
gpgsql-host=127.0.0.1
gpgsql-port=5432
gpgsql-dbname=powerdns
gpgsql-user=powerdns
gpgsql-password=пароль_к_бд
gpgsql-dnssec=yesЗдесь мы подключили плагины bind и gpgsql.
Может показаться хорошей идеей прописать одну и ту же зону с разным набором записей в разных бэкендах и получить выгоду от использования обоих. Например, нам было бы удобно работать с простым и понятным всем по формату bind-файлом, но в некоторых случаях всё-таки подключать записи из GeoIP-бэка (то есть отдавать разный набор записей в зависимости от source IP клиента, просто потому что там это делать очень удобно.
Так вот, забудьте про это. Архитектура бэкендов на это не рассчитана. Да, технически вы можете разместить одну и ту же зону с разным или идентичным набором записей в разных бэкендах, и PDNS Auth это проглотит без ошибок, но порядок просмотра бэкендов в этом случае неочевиден. Зону из какого бэка PDNS Auth возьмёт в качестве эталонной? Ответ знает только сам PDNS Auth.
Может поиграться с опцией launch=bind в gpgsql, меняя очерёдность подгрузки бэкендов. В этом случае бэки действительно загрузятся в том порядке, в котором они перечислены в опции launch, но, опять же, это никак не повлияет на то, в какой бэк PDNS Auth пойдёт за зоной.
Пример:
берём bind- и geoip-бэки;
заполняем одинаковым по количеству набором записей, но с немного отличающимся содержимым (чтобы понимать, из какого бэка пришёл ответ);
делаем запрос;
получаем содержимое из geoip-бэка;
меняем местами бэки в launch;
опять получаем содержимое из geoip-бэка;
меняем serial в большую и в меньшую сторону;
снова получаем контент из geoip-бэка;
добавляем новую запись только в bind-бэк;
ищем по ней
получаем NXDOMAIN;
удаляем SOA из geoip;
получаем REFUSED.
А вот с парой bind + gpgsql было чуть иначе: при именовании конфигурационных файлов 40_gpgsql.conf и 20_bind.conf (которые подключались через include-dir=/etc/powersns/pdns.d).
Вывод: каждая зона должна быть определена только один раз в одном из бэкендов PDNS Auth.
Теперь донастроим оба бэка и добавим пару ресурсных записей.
Настроим кластер PostgreSQL. Процесс настройки связки master –> replica тривиален, поэтому останавливаться здесь не будем. Гораздо интереснее подъём полноценного HighAvailability (HA)решения, например Patroni. В Ozon по нему отличная компетенция, поэтому сюрпризов в эксплуатации быть не должно. Однако есть небольшое отличие от стандартных кластеров под микросервисы: все необходимые для HA компоненты (PostgreSQL, Patroni, etcd) будут располагаться на тех же машинах, что и PDNS Auth. Сделано это для того, чтобы запросы к БД были максимально быстрыми, а отдельные компоненты, такие как etcd, не использовались совместно с другими сервисами, никак не связанными с DNS, дабы избежать влияния от них.
Небольшой оффтоп. Наш текущий кластер etcd-Patroni (тот, который под микросервисы, а не тот, который под DNS), обслуживает уже 3,7 тыс. Patroni-кластеров и 11 тыс. отдельных экземпляров PostgreSQL в production.
Конфиг Patroni будет примерно такой:
/etc/patroni/patroni.yml
---
name: stgpowerdns1.h.lan
namespace: /service/
scope: powerdns_multidc
restapi:
listen: 0.0.0.0:8008
connect_address: 10.40.0.11:8008
authentication:
username: patroni
password: "somepassword"
bootstrap:
dcs:
ttl: 60
loop_wait: 10
retry_timeout: 20
maximum_lag_on_failover: 1048576
master_start_timeout: 60
synchronous_mode: True
postgresql:
use_pg_rewind: True
use_slots: True
parameters:
wal_level: logical
hot_standby: 'on'
wal_keep_segments: 100
max_wal_senders: 24
max_replication_slots: 30
wal_log_hints: 'on'
max_connections: '100'
max_locks_per_transaction: '64'
initdb: ['encoding=UTF8', 'data-checksums', 'auth-local=trust', 'locale=en_US.UTF-8', 'auth-host=md5', 'auth-local=trust']
pg_hba:
- 'local all all trust'
- 'local replication all trust'
- 'host replication replication 127.0.0.1/32 trust'
- 'host replication replication 127.0.0.1/32 md5'
- 'host all all 127.0.0.0/8 md5'
- 'local all all trust'
- 'host replication replication 10.40.0.11/32 trust'
- 'host replication replication 10.40.0.12/32 trust'
- 'host replication replication 10.40.0.13/32 trust'
- 'host replication replication 10.40.0.14/32 trust'
- 'host replication replication 10.40.0.15/32 trust'
postgresql:
basebackup:
{'max-rate': '1000M', 'checkpoint': 'fast'}
listen: 0.0.0.0:5432
connect_address: 10.40.0.11:5432
data_dir: "/data/postgresql"
config_dir: "/etc/postgresql/12/main"
bin_dir: "/usr/lib/postgresql/12/bin"
use_unix_socket: True
parameters:
unix_socket_directories: "/var/run/postgresql"
authentication:
replication:
username: replication
password: "somepassword2"
superuser:
username: postgres
password: "somepassword3"
etcd: # отказоустойчивое хранилище для хранения состояния кластера
protocol: https
cert: "/etc/patroni/ssl/patroni.pem"
key: "/etc/patroni/ssl/patroni-key.pem"
cacert: "/etc/patroni/ssl/ca.pem"
hosts: "10.40.0.11:2379,10.40.0.12:2379,10.40.0.13:2379,10.40.0.14:2379,10.40.0.15:2379"
watchdog:
mode: "off"
device: "/dev/watchdog"
safety_margin: 5
tags:
noloadbalance: False
nofailover: False
clonefrom: False
nosync: FalseПосле сетапа БД..
Импортируем схему данных (таблицы, индексы и т.д.). Для PostgreSQL: https://doc.powerdns.com/authoritative/backends/generic-postgresql.html#default-schema
Теперь можно создать пару зон и наполнить их записями.
Зона powerdns.lan
Нужна для правильной работы механизма healthchecks. Dnsdist постоянно запрашивает у бэкенда status.backend.powerdns.lan текстовую запись и тем самым прозрачно проверяет работоспособность базы данных на каждом PowerDNS узле. Чтобы healthcheck был более-менее актуален, отключаем paсket cache на рекурсоре, выставляем TTL записи в 1 секунду и кеш запроса в 3 секунды (чтобы не сильно мучить PostgreSQL).
Поскольку в зону powerdns.lan мы никогда никакие изменения не вносим, то вероятность накосячить, удалив или изменив ключевую запись status.backend.powerdns.lan, существенно снижается.
Создаём зону в БД: pdnsutil create-zone powerdns.lan ns1.powerdns.lan.
Заполняем: pdnsutil edit-zone powerdns.lan.
Смотрим: pdnsutil list-zone powerdns.lan.
Загляните под спойлер
$ORIGIN .
powerdns.lan 3600 IN SOA ns1.powerdns.lan hostmaster.powerdns.lan 1234568 10800 3600 604800 3600
powerdns.lan 3600 IN NS ns1.powerdns.lan.
ns1.powerdns.lan 3600 IN A 10.10.0.1
status.backend.powerdns.lan 1 IN TXT "up"Зона h.lan — основная («железная») зона.
Создаём, заполняем и смотрим:
pdnsutil create-zone h.lan ns1.powerdns.lan
pdnsutil edit-zone h.lan
pdnsutil list-zone h.lan
Загляните под спойлер
$ORIGIN .
h.lan 3600 IN NS ns1.powerdns.lan.
h.lan 3600 IN SOA ns1.powerdns.lan hostmaster.powerdns.lan 1234568 10800 3600 604800 3600
powerdns1.h.lan 3600 IN A 10.40.0.11
powerdns2.h.lan 3600 IN A 10.40.0.12
powerdns3.h.lan 3600 IN A 10.40.0.13
powerdns4.h.lan 3600 IN A 10.40.0.14
powerdns5.h.lan 3600 IN A 10.40.0.15
...
...Всё, теперь резолв h.lan должен заработать:
dig @10.10.0.1 +short powerdns3.h.lan
10.40.0.13Для production зону h.lan мы настроили, теперь её нужно затащить в staging-окружение. Навскидку это можно организовать через репликацию PostgreSQL или DNS. DNS-репликация видится более гибким решением, потому что позволяет для того же staging-окружения применить отличную от production «конфигурацию». Например, можно на лету модифицировать получаемую по AXFR зону или настроить DNSSEC, что в доступной только для чтения базе PostgreSQL было бы невозможно.
Соответственно, для staging-окружения поднимаем свой экземпляр кластера Patroni и всего остального (PDNS Auth, PDNS Recursor, Dnsdist).
И далее у нас есть два пути.
Путь 1
Создаём в БД вторичную зону h.lan: pdnsutil create-secondary-zone h.lan 10.40.0.11:5300 10.40.0.12:5300 и т.д.
Заполняем pdnsutil edit-zone h.lan.
Чтобы DNS-репликации заработала в конфигурации PDNS Auth (/etc/powerdns/pdns.conf), мы должны прописать secondary=yes. И только на той PowerDNS-машине, на которой PostgreSQL в данный момент является primary! Если это сделать и на остальных vm, то при попытке получить зону (AXFR-запрос) процесс pdns_server (PDNS Auth) будет постоянно падать, потому что БД находиться в режиме только для чтения.
Загляните под спойлер
Ну и остался bind-бэкенд. Тут всё максимально просто: обычный файл bind zone, который раскатываем сначала в staging, потом в production: /etc/PowerDNS/backend_bind/zone_bind.conf.
Описываем тип зоны/зон: master, slave или native.
Вспоминаем, что PDNS Auth (бэкенд gpgsql) смотрит на локальный экземпляр PostgreSQL, и только на одной из машин находится master, на остальных — реплики только на чтение.
Путь 2
Создаём в БД зону h.lan: pdnsutil create-zone h.lan
Заполняем: pdnsutil edit-zone h.lan
На всех PowerDNS-машинах staging-окружения прописываем в конфигурации pdns secondary=yes.
А зону h.lan (AXFR-запрос) получаем через периодический запуск команды:
/usr/bin/pdns_control retrieve h.lan 10.40.0.11:5300.В чем тут соль? Через secondary=yes мы говорим PDNS Auth, чтобы он был готов выполнять функции вторичного (slave) DNS, но будет ли он по факту брать зону с первичного , определяется настройками (типом) зоны.
В первом примере (Путь 1) мы явно задали тип зоны как SECONDARY. И в соответствии с TTL из SOA-записи PDNS Auth начал периодические попытки «стянуть» зону.
Во втором примере (Путь 2) тип зоны получился NATIVE, что отключает логику PRIMARY (отсылка notify всем NS) при обновлении зоны и отключает логику SECONDARY (периодический опрос PRIMARY-машин), но отсутствие функциональности SECONDARY нивелируется периодическим выполнением pdns_control retrieve.
Второй путь кажется красивше. Все узлы PowerDNS в staging получаются идентичны по конфигурации:
на всех узлах включен secondary=yes;
на всех узлах есть cron-задача pdns_control retrieve, которая успешно запускается, только если локальный PostgreSQL является первичным.
Ну и остался bind-бэкенд. Тут всё максимально просто: обычный файл bind zone, который раскатываем сначала в staging, потом в production: /etc/PowerDNS/backend_bind/zone_bind.conf.
Описываем тип зоны/зон: master, slave или native.
https://doc.powedns.com/authoritative/backends/bind.html#master-slave-native-configuration
zone "s.lan" {
file "/etc/powerdns/backend_bind/s.lan.zone";
type native;
};Добавляем записи:
s.lan. 3600 IN SOA ns1.powerdns.lan hostmaster.powerdns.lan 2021081853 3600 300 604800 300
s.lan. 3600 IN NS ns1.powerdns.lan.
db1.s.lan. 600 IN A 10.100.0.45
web1.s.lan. 600 IN A 10.100.0.47Обновить состояние зоны можно без рестарта pdns_server (PDNS Auth) службы:
/usr/bin/pdns_control bind-reload-now s.lanДоставка resource records до PowerDNS
Пару лет назад у нас случился «неплохой» такой инцидент, который привёл к даунтайму ozon.ru на час с лишним и убытку в огромную сумму. Просто из PowerDNS пропала бОльшая часть записей.
Почему? Всё дело в той самой админке, о которой я писал выше, PowerDNS-Admin — WebUI для управления ресурсными записями в PowerDNS. И оказалось, что если при редактировании внести синтаксически, с точки зрения формата RR, ошибочную запись, то этот UI типа этого не замечает.

Он отбрасывает пачку текущих записей, но добавить новые не может, так как в одной из записей синтаксическая ошибка. В общем, в первый раз табличка PostgreSQL records потёрлась из-за неверно внесённой записи, во второй раз — ну, надо было проверить, что мы не ошиблись в своих суждениях, и повторили предыдущую операцию, а в третий раз — просто дрогнула рука.
Проблема известна и на тот момент не была решена. В итоге, админку отключили совсем и временно перешли на pdnsutil edit-zone <zone>.
Теперь подумаем, как можно уменьшить влияние подобных эксцессов, сохранив приемлемый уровень контроля и комфорта при внесении правок в статичные зоны.
Первое, что приходит в голову — разделить имеющийся набор SQL-записей на две части:
Редко меняющуюся. Положить её в какой-нибудь статичный бэкенд типа bind
Часто меняющуюся — динамический бэк, типа SQL.
Так и сделаем: сервисные записи (s.lan) выносим в bind-бэкенд, а железные записи (h.lan) — в GPGSQL.
С GPGSQL всё понятно: заходим на машину и редактируем зону через CLI pdnsutil edit-zone <zone>, благо не приходится это делать достаточно часто, ведь обычно за нас эту работу выполняет Terraform или другой наливатор железных или виртуальных машин.
Проблем со сменой IP-адресов мы, как правило, не имеем, потому что никогда их не меняем (исключением может быть первоначально неудачная настройка виртуальных машин или оборудования). Подход такой: если хочешь перенести виртуальную машину или железный сервер в другое место — как правило, другой ЦОД, — то полностью перенастрой: задай новое имя, IP-адрес и т.д.
А как быть со статикой? Может, в Git положить?
В нашей компании в качестве основной системы CI/CD используется gitlab (локальная версия. конечно). На первый взгляд, правильное место для интеграции, давайте на нём и остановимся.
Алгоритм выкатки такой:
Создать задачу.
Внести изменения в данные зоны.
Закоммитить и запушить в новую ветку.
Создать MR.
Попросить коллег проверить и заапрувить.
После удачного завершения задачи zones check мержим MR.
Ждём, пока запустится новый pipeline и успешно отработают стадии diff staging и diff production.
Проверяем diff -зоны (достаточно по одной job из diff staging/diff production).
Если diff соответствует нашим ожиданиям, то запускаем задачуstgpowerdns1.lan.
После успешного прогона stgpowerdns1.lan прогоняем оставшиеся задачи в Deploy staging и Deploy production.
Gitlab pipeline выглядит следующим образом:
.gitlab-ci.yml
---
include:
- local: ".vault.gitlab-ci.yml"
stages:
- build
- validate
- diff staging
- diff production
- deploy staging
- deploy production
workflow:
rules:
- &merge_and_changes
if: $CI_MERGE_REQUEST_ID # Execute jobs in merge request context
changes: &change_list
- Dockerfile
- .gitlab-ci.yml
- bind/zones/*
- &master_and_changes
if: $CI_COMMIT_BRANCH == 'master' # Execute jobs when a new commit is pushed to master branch
changes:
*change_list
- when: never
- allow_failure: false
.master.on_success:
rules:
- if: $CI_COMMIT_BRANCH == 'master' # Execute jobs when a new commit is pushed to master branch
when: on_success
variables:
TARGET_IMAGE: $CI_REGISTRY_IMAGE/deploy:latest
WORKDIR: workdir/$CI_PIPELINE_ID
ZONES_FILE: workdir/$CI_PIPELINE_ID/zones.list
SSH_PRIVATE_KEY: .ssh_private_key
VAULT_SECRET: deploy:ssh_private_key
create image:
extends: .containers.build
stage: build
variables:
BUILD_DST: ${TARGET_IMAGE}
DOCKERFILE_PATH: Dockerfile
when: manual
zones check:
stage: validate
image: ${TARGET_IMAGE}
script:
- unset COMMIT_FIRST COMMIT
- rm -rf ${WORKDIR}
- mkdir -p ${WORKDIR}
- git config --global url."https://gitlab-ci-token:${CI_JOB_TOKEN}@gitlab.lan/".insteadOf "ssh://git@gitlab.lan/"
- echo "Searching for zones changed"
- |
if [[ -n "$CI_MERGE_REQUEST_ID" ]]; then
COMMIT=$CI_COMMIT_SHA
echo $COMMIT
fi
- |
if [[ -z "$CI_MERGE_REQUEST_ID" ]]; then
COMMITS="$(git show --pretty=format:%P $CI_COMMIT_SHA | head -1 || true)"
COMMIT_FIRST=${COMMITS%% *}
COMMIT=${COMMITS##* }
fi
- git diff-tree --no-commit-id --name-only -r ${COMMIT} bind/zones/*
- |
for zone_file in $(git diff-tree --no-commit-id --name-only -r ${COMMIT} bind/zones/*); do
echo ${zone_file##*/}
done | sort | uniq > ${ZONES_FILE}
- |
if [[ -s "${ZONES_FILE}" ]]; then
echo -e "\e[1m\e[34mProcceding zones\e[0m"
echo -e "\e[1m\e[34m================\e[0m"
cat ${ZONES_FILE}
echo -e "\e[1m\e[34m================\e[0m"
# gen config
for ZONE in $(cat ${ZONES_FILE}); do
echo "
zone \"${ZONE}\" {
file \"/tmp/pdns/zones/${ZONE}\";
type native;
};" >> /tmp/pdns/zone.conf
cp bind/zones/${ZONE} /tmp/pdns/zones/${ZONE}
echo "${ZONE}"
echo -e "\e[1m\e[34m--------\e[0m"
cat /tmp/pdns/zones/${ZONE}
echo -e "\e[1m\e[34m========\e[0m"
done
# run powerdns
pdnsutil create-bind-db /tmp/pdns/dnssec-db
pdns_server --config-dir=/tmp/pdns/ --daemon=no --write-pid=no --disable-syslog &
sleep 5
echo -----------------
find /tmp/pdns
echo -----------------
cat /tmp/pdns/pdns.conf
echo -----------------
cat /tmp/pdns/zone.conf
echo -----------------
# reload zones
for ZONE in $(cat ${ZONES_FILE}); do
pdns_control bind-reload-now ${ZONE} | grep 'parsed into memory'
done
pdnsutil --config-dir=/tmp/pdns check-all-zones
else
echo -e "\e[1m\e[34mNo zone files found in the commit. Nothing to do. Exit\e[0m"
exit 10
fi
artifacts:
paths:
- ${ZONES_FILE}
expire_in: 1 week
# ======
# DIFF
# ======
.diff_zone_script:
image: ${TARGET_IMAGE}
extends: .vault_before_script
script:
- vault_get_secret ${VAULT_PATH}/${VAULT_SECRET} > ${SSH_PRIVATE_KEY}
- chmod go= ${SSH_PRIVATE_KEY}
- |
for zone in $(cat ${ZONES_FILE}); do
ssh -i ${SSH_PRIVATE_KEY} \
-o "StrictHostKeyChecking no" \
-o "VerifyHostKeyDNS no" \
deploy@${CI_JOB_NAME#diff } diff-bind-zone ${zone} ${CI_PIPELINE_ID}
done
rules:
- *master_and_changes
- when: never
- allow_failure: true
.diff_staging:
extends: .diff_zone_script
stage: diff staging
tags: [staging, deploy]
environment:
name: staging
needs: [zones check]
resource_group: staging
.diff_production:
extends: .diff_zone_script
stage: diff production
tags: [production, deploy-specific]
environment:
name: production
needs: [zones check]
resource_group: production
diff stgpowerdns1.lan:
extends: .diff_staging
diff stgpowerdns2.lan:
extends: .diff_staging
diff prodpowerdns1.lan:
extends: .diff_production
diff prodpowerdns2.lan:
extends: .diff_production
# ======
# DEPLOY
# ======
.deploy_zone_script:
image: ${TARGET_IMAGE}
extends: .vault_before_script
script:
- vault_get_secret ${VAULT_PATH}/${VAULT_SECRET} > ${SSH_PRIVATE_KEY}
- chmod go= ${SSH_PRIVATE_KEY}
- |
for zone in $(cat ${ZONES_FILE}); do
ssh -i ${SSH_PRIVATE_KEY} \
-o "StrictHostKeyChecking no" \
-o "VerifyHostKeyDNS no" \
deploy@${CI_JOB_NAME} deploy-bind-zone ${zone} ${CI_PIPELINE_ID}
done
rules:
- if: $CI_COMMIT_BRANCH == 'master' # Execute jobs when a new commit is pushed to master branch
changes:
*change_list
when: manual
- when: never
- allow_failure: true
.deploy_staging:
extends: .deploy_zone_script
stage: deploy staging
tags: [staging, deploy]
environment:
name: staging
needs: [zones check, diff stgpowerdns1.lan]
resource_group: staging
.deploy_production:
extends: .deploy_zone_script
stage: deploy production
tags: [production, deploy-specific]
environment:
name: production
needs: [zones check, stgpowerdns1.lan]
resource_group: production
stgpowerdns1.lan:
extends: .deploy_staging
stgpowerdns2.lan:
extends: .deploy_staging
prodpowerdns1.lan:
extends: .deploy_production
prodpowerdns2.lan:
extends: .deploy_productionВ итоге deploy заходит по SSH на каждый узел PowerDNS, берёт master-ветку из Gitlab и подгружает в PDNS Auth новые данные зоны. Загрузка данных сделана через reload, простоя в обслуживании нет.
Pull-модель выглядит более безопасной по сравнению с push, выбрали её.
command="/home/deploy/deploy.sh",from="10.0.0.0/8",no-agent-forwarding,no-port-forwarding,no-user-rc,no-X11-forwarding,no-pty ssh-ed25519 <PUBLIC KEY> /home/deploy/deploy.sh
#!/bin/bash -fue
# Managed by Ansible
set -- ${SSH_ORIGINAL_COMMAND}
case ${1} in
deploy-bind-zone)
ZONE=${2}
ZONE_ENC=${ZONE//./%2E}
PIPELINE_ID=${3}
mkdir -p ${HOME}/zones/${PIPELINE_ID}
mkdir -p ${HOME}/zones_last
mkdir -p ${HOME}/zones_backup
echo "Deploing zone ${ZONE} by gitlab pipeline (id ${PIPELINE_ID})"
curl --fail --silent\
--header "PRIVATE-TOKEN: `cat ${HOME}/.gitlab_access_token`" \
"https://gitlab.lan/api/v4/projects/<project_id>/repository/files/bind%2Fzones%2F${ZONE_ENC}/raw?ref=master" \
> ${HOME}/zones/${PIPELINE_ID}/${ZONE}
sudo -u root /bin/cp -a ${HOME}/zones/${PIPELINE_ID} /etc/powerdns/deploy/
echo '### DIFF ###'
/usr/bin/diff -u /etc/powerdns/backend_bind/${ZONE}.zone /etc/powerdns/deploy/${PIPELINE_ID}/${ZONE} || true
echo '### END DIFF ###'
/bin/cp -f /etc/powerdns/backend_bind/${ZONE}.zone ${HOME}/zones_backup/${ZONE}
sudo -u root /bin/ln -f -s /etc/powerdns/deploy/${PIPELINE_ID}/${ZONE} /etc/powerdns/backend_bind/${ZONE}.zone
sudo -u root /usr/bin/pdns_control bind-reload-now ${ZONE}
/bin/cp -f /etc/powerdns/backend_bind/${ZONE}.zone ${HOME}/zones_last/${ZONE}
;;
diff-bind-zone)
ZONE=${2}
ZONE_ENC=${ZONE//./%2E}
PIPELINE_ID=${3}
mkdir -p /tmp/diff-bind-zone/${PIPELINE_ID}
echo "Diff zone ${ZONE} by gitlab pipeline (id ${PIPELINE_ID})"
curl --fail --silent\
--header "PRIVATE-TOKEN: `cat ${HOME}/.gitlab_access_token`" \
"https://gitlab.ozon.ru/api/v4/projects/14443/repository/files/bind%2Fzones%2F${ZONE_ENC}/raw?ref=master" \
> /tmp/diff-bind-zone/${PIPELINE_ID}/${ZONE}
echo '### DIFF ###'
/usr/bin/diff -u /etc/powerdns/backend_bind/${ZONE}.zone /tmp/diff-bind-zone/${PIPELINE_ID}/${ZONE} || true
echo '### END DIFF ###'
rm -rf /tmp/diff-bind-zone/${PIPELINE_ID}
;;
*)
echo "Bad command"
exit 1
;;
esacНо через некоторое время выяснили «на практике», что Gitlab может быть недоступен, а изменения в DNS нас могут попросить выкатить в любое время. Сделали процедуру аварийной выкатки нужных изменений в рамках Ansible (это наш основной инструмент управления конфигурацией серверов). Выглядит так:
Берём репозиторий с данными зон.
Берём Ansible (как правило, у каждого инженера Ansible репозиторий уже есть и актуален).
Вносим правки в файлы зон.
Катим: playbooks/powerdns/disaster_zones_deploy/main.yml -l powerdns_multidc -v.
playbooks/powerdns/disaster_zones_deploy/readme.md
# check zones loaded to pdns last time
ansible-playbook -i inventory/production_powerdns_multidc.yml playbooks/powerdns/disaster_zones_deploy/check_loaded_status.yml -l powerdns_multidc -v | grep -e changed -e lan --color=never
# specific zone
ansible-playbook -i inventory/production_powerdns_multidc.yml playbooks/powerdns/disaster_zones_deploy/check_loaded_status.yml -l powerdns_multidc -v -e zone=lan | grep -e changed -e lan --color=never
# PREPARE TO DEPLOY
cd git
git clone git@gitlab.lan:powerdns/deploy-zones.git
git clone git@gitlab.lan:ansible.git
cd ansible
https://gitlab.lan/ansible/-/blob/master/README.md#prepare-for-local-work
https://gitlab.lan/ansible/-/blob/master/README.md#vault
vim ../powerdns/deploy-zones/bind/zones/lan
# STAGING DEPLOY
# check mode
ansible-playbook -i inventory/staging_powerdns_multidc.yml playbooks/powerdns/disaster_zones_deploy/main.yml -l powerdns_multidc -CD -v
# check mode | specific zone
ansible-playbook -i inventory/staging_powerdns_multidc.yml playbooks/powerdns/disaster_zones_deploy/main.yml -l powerdns_multidc -CD -v -e zone=s.lan
# fire
ansible-playbook -i inventory/staging_powerdns_multidc.yml playbooks/powerdns/disaster_zones_deploy/main.yml -l powerdns_multidc -D -v
# fire | specific zone
ansible-playbook -i inventory/staging_powerdns_multidc.yml playbooks/powerdns/disaster_zones_deploy/main.yml -l powerdns_multidc -D -v -e zone=s.lan
# PRODUCTION DEPLOY
# check mode
ansible-playbook -i inventory/production_powerdns_multidc.yml playbooks/powerdns/disaster_zones_deploy/main.yml -l powerdns_multidc -CD -v
# check mode | specific zone
ansible-playbook -i inventory/production_powerdns_multidc.yml playbooks/powerdns/disaster_zones_deploy/main.yml -l powerdns_multidc -CD -v -e zone=s.lan
# fire
ansible-playbook -i inventory/production_powerdns_multidc.yml playbooks/powerdns/disaster_zones_deploy/main.yml -l powerdns_multidc -D -v
# fire | specific zone
ansible-playbook -i inventory/production_powerdns_multidc.yml playbooks/powerdns/disaster_zones_deploy/main.yml -l powerdns_multidc -D -v -e zone=s.lanСам код:
playbooks/powerdns/disaster_zones_deploy/main.yml
---
- hosts: powerdns_multidc
gather_facts: false
become: true
vars:
static_zones:
- s.lan
tasks:
- name: include __deploy_zone_tasks.yml
include_tasks: __deploy_zone_tasks.yml
with_items:
- "{{ zone | default(static_zones) }}"playbooks/powerdns/disaster_zones_deploy/__deploy_zone_tasks.yml
---
- name: deploy bind zone {{ item }}
copy:
src: ../../../../powerdns-deploy-zones/bind/zones/{{ item }}
dest: /etc/powerdns/backend_bind/{{ item }}.zone
owner: pdns_deploy
group: pdns_deploy
mode: 0664
follow: true
backup: true
register: zone_file
- name: /usr/bin/pdns_control bind-reload-now {{ item }} # noqa 503
shell: >
[ "{{ ansible_check_mode }}" = "True" ]
&& echo "DO NOTHING"
|| /usr/bin/pdns_control bind-reload-now {{ item }}
check_mode: false
ignore_errors: "{{ ansible_check_mode }}"
when: zone_file.changedplaybooks/powerdns/disaster_zones_deploy/check_loaded_status.yml
---
- hosts: powerdns_multidc
gather_facts: false
become: true
tasks:
- name: /usr/bin/pdns_control bind-domain-status ZONE # noqa 301
shell: /usr/bin/pdns_control bind-domain-status {{ zone | default("") }} | sort
check_mode: false
ignore_errors: "{{ ansible_check_mode }}"«Железную» зону редактируем через API PowerDNS: например, добавляем RR при настройке виртуальной машины через Terraform или настройке железного хоста через MaaS. Вручную исправляем редко, но если нужно, то выполняем pdnsutil edit-zone <zone> на узле с PostgreSQL-мастером.
Хорошо, а если всё вышеописанное работает слишком медленно, громоздко, или мне не нравится катить DNS через Gitlab или другой CI/CD, да и вообще я смелый?! Берите PowerDNS-Admin. Ошибка с отбрасыванием данных исправлена, пользоваться можно.

Какие есть аналоги для редактирования RR:
Pdns-gui не поддерживается (последний релиз — 25 апреля 2010).
Poweradmin (478 звёзд). Имеет неприятную особенность: в текстовых записях не сохраняет двойные кавычки (“), что напрочь ломает доступ к этим записям через API, который необходим для хранения текстовыми полями информации внутри экранированного кавычками (”) блока. Хотя на функционирование самого сервера это не влияет. Также Poweradmin добавляет несколько своих таблиц и полей в исходную БД, не ведет никаких логов работы в веб-интерфейсе.
PDNS manager (160 звёзд) — два года не обновлялся.
Ну и сам PowerDNS-Admin (1,8 тыс. звёзд). Самая популярная админка, достаточно гибкая, есть аудит, разграничение прав, разные методы аутентификации, двухфакторка… но удаляет данные.

Проблемы после внедрения
Resolve Lua record
Тут весело. Оказывается, Lua record, та, что реализует проверки и формирует на их основе ответ, начинает работать только после первого совершённого к ней DNS-запроса. Для обхода этой проблемы существует прекрасный костыль:
crontab -l
* * * * * dig @localhost smart-record.s.lan &> /dev/nullДеплой статичных зон через Gitlab
Как-то раз случился инцидент, не связанный с PowerDNS, который, в итоге, привёл к сильному замедлению задач, выполнявшихся на gitlab runners. Одним из шагов по решению проблемы была задача поправить несколько A-записей. Конечно же, через Gitlab нам этого сделать не удалось, джобы могли висеть в статусе ожидания ресурсов по 10-20 минут. В итоге зону поправили вручную и позже написали процедуру раскатки статичных зон в случае форс-мажора.
Из кеша recursor не удалялась устаревшая DNS-запись
У нас Kubernetes, и его записи имеют достаточно малый TTL, порядка пяти секунд. Иногда замечали, что при перевыкатке некоторых проектов их сервисные DNS-имена, которые указывают на service_ip в Kubernetes, вели в никуда (NXDOMAIN). Настройка кеша подобных записей стояла 10 секунд (max-negative-ttl=10), но почему-то они висели в кеше минуты и часы. Если сбросить кеш рекурсора или перезапустить сам рекурсор, то всё приходило в норму. Может, ошибка была в предыдущей версии рекурсора (4.4.), или нет, но после обновления на 4.5. такое поведение прекратилось.
Есть подозрения в отношении обработки ECS или DNSSEC, потому как после включения опций edns0 и/или trust-ad в /etc/resolv.conf системный резолвер начинал видеть желанный IP-адрес. Также, если попытаться разрезолвить имя через nslookup, получали NXDOMAIN, в то время как dig всё прекрасно видел. Разница в том, что dig по умолчанию выставляет query опции +adflag +edns. А вот так они уравниваются: dig +noadflag +noedns == nslookup.
Что насчёт функциональности наподобие bind views?
В самом PDNS Auth её нет (https://github.com/powerdns/pdns/issues/63, https://github.com/powerdns/pdns/issues/10816), но можно накостылить:
использовать GeoIP-бэкенд;
использовать Lua-записи;
использовать Dnsdist и несколько PDNS Auth.
GeoIP-бэкенд
Пример из https://doc.powerdns.com/authoritative/backends/geoip.html
domains:
- domain: geo.example.com
ttl: 30
records:
geo.example.com:
- soa: ns1.example.com hostmaster.example.com 2014090125 7200 3600 1209600 3600
- ns:
content: ns1.example.com
ttl: 600
- ns: ns2.example.com
fin.eu.service.geo.example.com:
- a: 192.0.2.2
- txt: hello world
- aaaa: 2001:DB8::12:34DE:3
# this will result first record being handed out 30% of time
swe.eu.service.geo.example.com:
- a:
content: 192.0.2.3
weight: 50
- a: 192.0.2.4
services:
# syntax 1
service.geo.example.com: '%co.%cn.service.geo.example.com'
# syntax 2
service.geo.example.com: [ '%co.%cn.service.geo.example.com', '%cn.service.geo.example.com']
# alternative syntax
services:
service.geo.example.com:
default: [ '%co.%cn.service.geo.example.com', '%cn.service.geo.example.com' ]
10.0.0.0/8: 'internal.service.geo.example.com'
mapping_lookup_formats: ['%cc-%re', '%cc']
custom_mapping:
fr: eu-central
be: eu-central
es: eu-south
us-tx: us-southСамый гибкий вариант. Недостаток в том, что если исходная зона находится в другом бэке, то придётся перенести её в GeoIP-бэк полностью.
Lua-записи
Файл bind zone:
www IN LUA A ";if countryCode('US') then return {'192.0.2.1','192.0.2.2'} else return '192.0.2.2' end" Самый простой для внедрения вариант. Недостаток в отсутствии гибкости, один if и два варианта содержимого. Если захочется что-то более сложное, возможно, придётся писать свою Lua-функцию. В SQL-совместимом бэкенде также будет работать.
Dnsdist и несколько PDNS Auth
Два экземпляра PDNS Auth с разным содержимым для внутренних и внешних потребителей.
newServer({address="10.0.9.1:5301", pool="INTERNAL"})
newServer({address="10.0.9.1:5302", pool="EXTERNAL"})
addAction({"10.0.0.0/8"}, PoolAction("INTERNAL"))
addAction(AllRule(),PoolAction("EXTERNAL")) Если сюда добавить логику выбора следующего сервера при недоступности основного, то получится достаточно громоздко.
Логирование DNS-запросов
Нужно как минимум в двух случаях: для отдела ИБ и для отладки.
Решили логировать на уровне рекурсора, потому что запрос обязан через него проходить. Dnsdist можно обойти, зная реальные адреса PowerDNS-машин (закрыть не проблема), а прямой доступ в PDNS Auth есть только у локального PDNS Recursor (специально).
Каких-то специфичных требований к логированию запросов не было, поэтому сделали просто:
/etc/powerdns/recursor.conf
quiet=no
trace=fail
loglevel=5journalctl -u pdns-recursor.service
# запрос
pdns_recursor[10861]: 3 [1418626328/2] question for 'stgpostgres44.lan|A' from 10.1.2.3:55002 (ecs 10.100.1.52/32)
# и ответ
pdns_recursor[10861]: 3 [1418626328/2] answer to question 'stgpostgres44.lan|A': 1 answers, 1 additional, took 1 packets, 0.359 netw ms, 0.474 tot ms, 0 throttled, 0 timeouts, 0 tcp connections, rcode=0Если packetcache включен и ответ из него отдаётся, то в логе увидим:
pdns_recursor[10861]: 3 question answered from packet cache tag=0 from 10.1.2.3:55002 Но существует более зрелый подход — DNStap (https://dnstap.info). Это гибкий, структурированный бинарный формат лога на основе protobuf. Dnsdist поддерживает его с версии 1.3 (https://dnsdist.org/reference/dnstap.html), pdns recursor — с версии 4.2 (https://docs.powerdns.com/recursor/lua-config/protobuf.html)
Кроме его поддержки на стороне рекурсора и/или балансировщика, нам понадобится DNStap-коллектор, ведь сгенерированный лог нужно где-то хранить и анализировать (желательно централизованно). В качестве коллектора можно использовать go-dns-collector. Много звёзд, поддерживается. Является одновременно агрегатором, анализатором и транспортом в другие системы. Может экспортировать логи в Elastic, Fluentd, Syslog и т.д., предоставляет метрики и REST API.
Запустим коллектор: ./go-dnscollector -config config.yml
config.yaml
global:
trace:
verbose: true
multiplexer:
collectors:
- name: dnstap
dnstap:
listen-ip: 0.0.0.0
listen-port: 6000
loggers:
- name: console
stdout:
mode: json
routes:
- from: [dnstap]
to: [console]И натравим на него рекурсор:
cat /etc/PowerDNS/resursor.conf
...
lua-config-file=/etc/powerdns/recursor.lua.d/log.lua cat log.lua
dnstapFrameStreamServer("172.6.0.156:6001") Важные моменты:
Для логирования в формате DNStap по TCP PDNS Recursor должен быть скомпилирован с параметром --enable-dnstap. Также должна быть обновлена библиотека libfstrm, иначе передача логов будет возможна только через unix-socket.
Передача данных на удалённый узел осуществляется по протоколу TCP, поэтому в случае недоступности коллектора неотправленные сообщения будут копиться, что в конечном итоге приведёт к исчерпанию оперативной памяти. Смотрим на параметры inputQueueSize и outputQueueSize, подбираем под себя размеры очередей, после переполнения которых DNStap логи начнут теряться.
Если логи нужны прям обязательно, да ещё чтобы не терялись, поднимаем несколько коллекторов и прописываем директиву DNStapFrameStreamServer необходимое количество раз.
Ну и dnsdist давайте настроим. Тут всё аналогично:
cat /etc/dnsdist/dnsdist.conf
...
newFrameStreamTcpLogger("172.6.0.156:6001") Пример лога.
Операция "DNSQueryType"
{
"network": {
"family": "INET",
"protocol": "UDP",
"query-ip": "172.6.0.156",
"query-port": "48408",
"response-ip": "172.6.0.20",
"response-port": "53",
"as-number": "-",
"as-owner": "-"
},
"dns": {
"length": 28,
"opcode": 0,
"rcode": "-",
"qname": "nginx.ozon",
"qname-public-suffix": "-",
"qname-effective-tld-plus-one": "-",
"qtype": "A",
"flags": {
"qr": false,
"tc": false,
"aa": false,
"ra": false,
"ad": false
},
"resource-records": {
"an": [],
"ns": [],
"ar": []
},
"malformed-packet": false
},
"edns": {
"udp-size": 0,
"rcode": 0,
"version": 0,
"dnssec-ok": 0,
"options": []
},
"dnstap": {
"operation": "DNSQueryType",
"identity": "d12b46e263cc",
"timestamp-rfc3339ns": "2022-12-01T07:24:41.000425932Z",
"latency": "-"
},
"geo": {
"city": "-",
"continent": "-",
"country-isocode": "-"
},
"pdns": {
"tags": [],
"original-request-subnet": "",
"applied-policy": ""
},
"suspicious": {
"score": 0,
"malformed-pkt": false,
"large-pkt": false,
"long-domain": false,
"slow-domain": false,
"unallowed-chars": false,
"uncommon-qtypes": false,
"excessive-number-labels": false
}
}Операция “DNSResponseType”
{
"network": {
"family": "INET",
"protocol": "UDP",
"query-ip": "172.6.0.156",
"query-port": "48408",
"response-ip": "172.6.0.20",
"response-port": "53",
"as-number": "-",
"as-owner": "-"
},
"dns": {
"length": 109,
"opcode": 0,
"rcode": "NOERROR",
"qname": "nginx.ozon",
"qname-public-suffix": "-",
"qname-effective-tld-plus-one": "-",
"qtype": "AAAA",
"flags": {
"qr": false,
"tc": false,
"aa": false,
"ra": false,
"ad": false
},
"resource-records": {
"an": [],
"ns": [],
"ar": []
},
"malformed-packet": false
},
"edns": {
"udp-size": 0,
"rcode": 0,
"version": 0,
"dnssec-ok": 0,
"options": []
},
"dnstap": {
"operation": "DNSResponseType",
"identity": "d12b46e263cc",
"timestamp-rfc3339ns": "2022-12-01T07:24:41.000445065Z",
"latency": "0.021053"
},
"geo": {
"city": "-",
"continent": "-",
"country-isocode": "-"
},
"pdns": {
"tags": [],
"original-request-subnet": "",
"applied-policy": ""
},
"suspicious": {
"score": 0,
"malformed-pkt": false,
"large-pkt": false,
"long-domain": false,
"slow-domain": false,
"unallowed-chars": false,
"uncommon-qtypes": false,
"excessive-number-labels": false
}
}Вот что увидим в Grafana:

Debug
С помощью утилиты rec_control и команды trace-regex можно получить детальный разбор запроса при прохождении его через рекурсор.
# rec_control trace-regex '^(b|c).nonexists.domain'
00:32:06 stgpowerdns1 pdns_recursor[10861]: 3 [1801294368/1] question for 'c.nonexists.domain|A' from 127.0.0.1:39805
00:32:06 stgpowerdns1 pdns_recursor[10861]: [1801294368] : no TA found for 'c.nonexists.domain' among 1
00:32:06 stgpowerdns1 pdns_recursor[10861]: [1801294368] : no TA found for 'nonexists.domain' among 1
00:32:06 stgpowerdns1 pdns_recursor[10861]: [1801294368] c.nonexists.domain: Wants NO DNSSEC processing, auth data in query for A
00:32:06 stgpowerdns1 pdns_recursor[10861]: [1801294368] c.nonexists.domain: No cache hit for 'c.nonexists.domain|A', trying to find an appropriate NS record
00:32:06 stgpowerdns1 pdns_recursor[10861]: [1801294368] c.nonexists.domain: Cache consultations done, have 1 NS to contact
00:32:06 stgpowerdns1 pdns_recursor[10861]: [1801294368] c.nonexists.domain: Domain has hardcoded nameservers
00:32:06 stgpowerdns1 pdns_recursor[10861]: [1801294368] c.nonexists.domain.: Nameservers: +10.2.2.2:53(1.05ms), +10.2.2.1:53(862.82ms)
00:32:06 stgpowerdns1 pdns_recursor[10861]: [1801294368] c.nonexists.domain: Resolved '.' NS (empty) to: 10.2.2.2, 10.2.2.1
00:32:06 stgpowerdns1 pdns_recursor[10861]: [1801294368] c.nonexists.domain: Trying IP 10.2.2.2:53, asking 'c.nonexists.domain|A'
00:32:06 stgpowerdns1 pdns_recursor[10861]: [1801294368] c.nonexists.domain: Got 2 answers from (empty) (10.2.2.2), rcode=3 (Non-Existent domain), aa=0, in 0ms
00:32:06 stgpowerdns1 pdns_recursor[10861]: [1801294368] c.nonexists.domain: accept answer '.|SOA|a.root-servers.net. nstld.verisign-grs.com. 2023010801 1800 900 604800 86400' from '.' nameservers? ttl=537, place=2 YES! - This answer was received from a server we forward to.
00:32:06 stgpowerdns1 pdns_recursor[10861]: [1801294368] c.nonexists.domain: OPT answer '.' from '.' nameservers
00:32:06 stgpowerdns1 pdns_recursor[10861]: [1801294368] c.nonexists.domain: determining status after receiving this packet
00:32:06 stgpowerdns1 pdns_recursor[10861]: [1801294368] c.nonexists.domain: got negative caching indication for name 'c.nonexists.domain' (accept=1), newtarget='(empty)'
00:32:06 stgpowerdns1 pdns_recursor[10861]: [1801294368] c.nonexists.domain: status=NXDOMAIN, we are done (have negative SOA)
00:32:06 stgpowerdns1 pdns_recursor[10861]: [1801294368] c.nonexists.domain: failed (res=3)
00:32:06 stgpowerdns1 pdns_recursor[10861]: 3 [1801294368/1] answer to question 'c.nonexists.domain|A': 0 answers, 1 additional, took 1 packets, 0.845 netw ms, 0.984 tot ms, 0 throttled, 0 timeouts, 0 tcp connections, rcode=3Вот с таким кодом на рекурсоре и соответствующим txt-запросом можно понять, на какие бэкенды в данный момент могут уходить DNS-запросы с того или иного хоста:
somehost#
dig +short txt name.backend.powerdns.lan
"stgpowerdns2.lan"
dig +short txt name.backend.powerdns.lan
"stgpowerdns1.lan"stgpowerdns1.lan# /etc/powerdns/recursor.lua.d/dns.lua
backendname_request = "name.backend.powerdns.lan"
backendname_response = "\"stgpowerdns1.lan\""
function preresolve(dq)
if dq.qname:equal(backendname_request) then
dq.variable = true -- disable packet cache
dq.rcode=0 -- make it a normal answer
dq:addAnswer(pdns.TXT, backendname_response, 1) -- ttl 1s
return true
end
return false;
endА вот так мы понимаем, где находится первичный узел кластера PostgreSQL, на который настроен PowerDNS:
dig +short powerdns-leader.s.lan.
10.14.0.9 Файл bind zone с Lua-записями
config_stg IN LUA LUA ("settings={stringmatch='replication'} backends={'10.12.0.1','10.13.1.59','10.14.0.9','10.15.0.2','10.16.0.40','10.17.0.5'}" )
powerdns-leader.s.lan. 30 IN LUA A ( ";include('config_stg') return ifurlup('http://127.0.0.1:8005/leader',{backends,{}}, settings)" )На 127.0.0.1:8005 висит Patroni. Команда backends выводит список всех узлов Patroni-кластера.
Наша Grafana
Тут пусть будут одни картинки.



Заключение
Эта статья должна была выйти год назад. Отлежалась, дополнилась некоторыми разделами. Приведённая конфигурация работает в бою уже 1,5 года. Инцидентов, кроме описанного, за это время не было.
Что нас ждёт впереди? Можно задуматься о написании собственной админки: ключевые моменты — уменьшение длительности выкатки статичных зон и уход от рисков, связанных с использованием стороннего ПО (вспоминаем PowerDNS-Admin и 2022 год в целом (https://habr.com/ru/news/t/655929/)).
Кардинально менять архитектуру не планируем, пока устраивает. Возможно, подумаем над выселением кластера PostgreSQL с узлов PowerDNS.
Из рекомендаций: в инфраструктурах меньшего масштаба, или когда нет возможности настроить динамическую маршрутизацию на LB, самым подходящим решением для VIP будет использование протокола CARP/VRRP. Например, пара LB машин с Keepalived на борту в каждом ЦОД, а в resolv.conf клиента перечислены все VIP.
Вроде всё. Спасибо.



