

Высказать то, что слова не могут передать; почувствовать самые разнообразные эмоции, переплетающиеся в ураган чувств; оторваться от земли, неба и даже самой Вселенной, отправившись в путешествие, где нет карт, нет дорог, нет указателей; придумать, рассказать и пережить целую историю, которая всегда останется уникальной и неповторимой. Все это позволяет сделать музыка — искусство, существующее уже многие тысячи лет и услаждающее наши слух и сердца.
Однако музыка, а точнее музыкальные произведения могут послужить не только для эстетического удовольствия, но и для передачи закодированной в них информации, предназначенной для какого-либо устройства и незаметной для слушателя. Сегодня мы с вами познакомимся с весьма необычным исследованием, в котором аспиранты из швейцарской высшей технической школы Цюриха смогли незаметно для человеческого уха внедрить определенные данные в музыкальные произведения, за счет чего сама музыка становится каналом передачи данных. Как именно они реализовали свою технологию, сильно ли отличаются мелодии с и без внедренных данных, и что показали практические испытания? Об этом мы узнаем из доклада исследователей. Поехали.
Основа исследования
Исследователи называют свою технологию акустической техникой передачи данных. Когда динамик воспроизводит измененную мелодию, человек воспринимает ее как обычную, а вот, например, смартфон может считывать закодированную информацию между строк, точнее между нот, если можно так выразиться. Самым важным аспектом в реализации этой методики передачи данных ученые (то, что эти ребята все еще аспиранты не мешает им быть учеными) называют скорость и надежность передачи при сохранении уровня этих параметров вне зависимости от выбранного аудиофайла. Справиться с этой задачей помогает психоакустика, изучающая психологические и физиологические аспекты восприятия человеком звуков.
Стержнем акустической передачи данных можно назвать OFDM (мультиплексирование с ортогональным частотным разделением каналов), которая наряду с адаптацией поднесущих к исходной музыке с течением времени позволили максимально использовать спектр передаваемой частоты для передачи информации. Благодаря этому удалось достичь скорости передачи в 412 бит/с на расстояние до 24 метров (коэффициент ошибок < 10%). Практические же эксперименты с участием 40 добровольцев подтвердили факт того, что услышать разницу между оригинальной мелодией и той, в которую была внедрена информация, практически невозможно.
Где же можно применить такую технологию на практике? У исследователей есть свой вариант ответа: практически все современные смартфоны, ноутбуки и прочие карманные устройства оснащены микрофонами, а во многих общественных местах (кафе, рестораны, торговые центры и т.д.) есть колонки с фоновой музыкой. В эту фоновую мелодию можно внедрить, например, данные для подключения к сети Wi-Fi без необходимости производить дополнительные действия.
Общие черты акустической передачи данных нам стали ясны, теперь перейдем к детальному изучению структуры данной системы.
Описание системы
Внедрение данных в мелодию происходит за счет маскировки частоты. Во временных интервалах маскирующие частоты идентифицируются, и поднесущие OFDM, близкие к этим маскирующим элементам, заполняются данными.
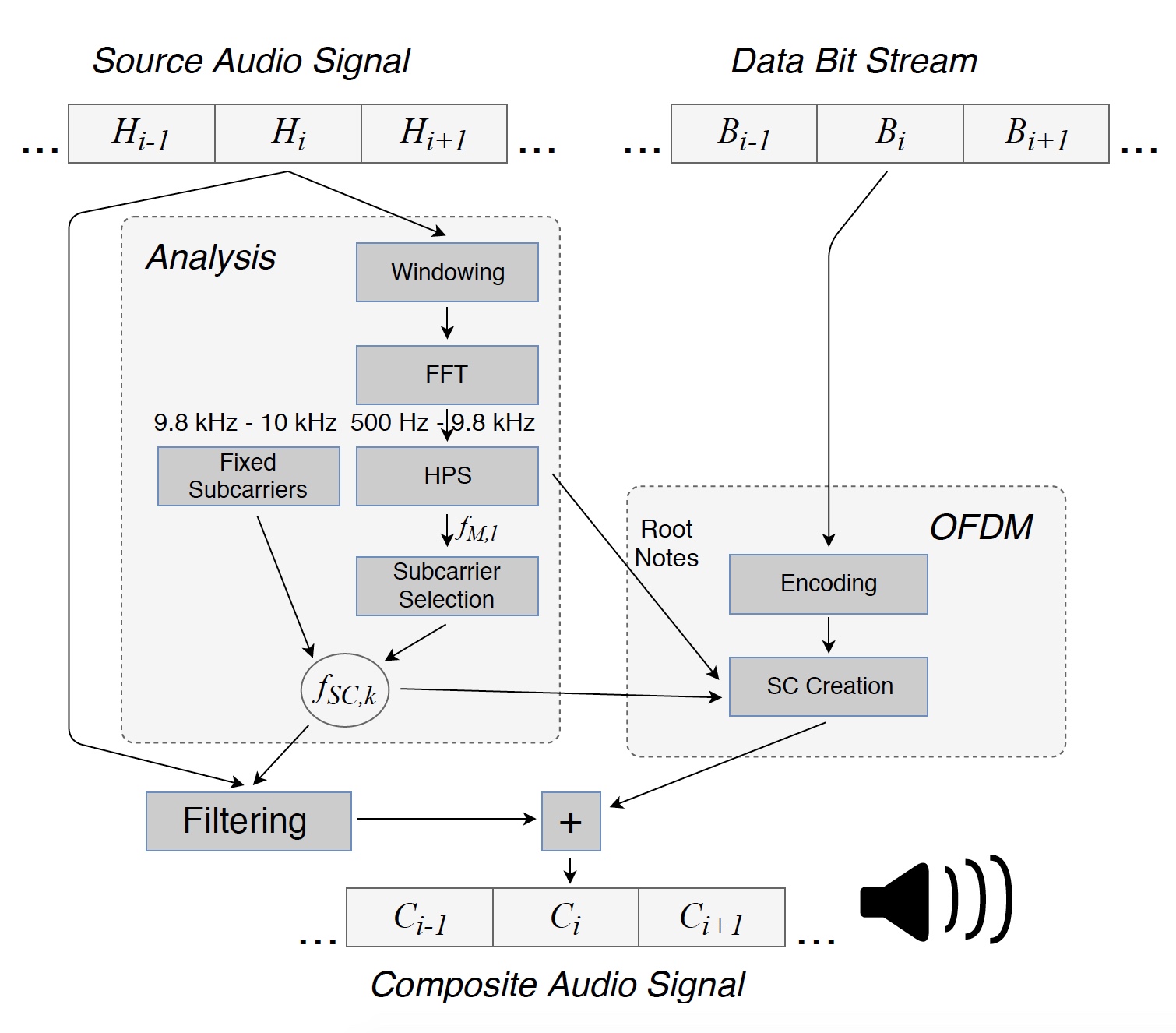
Изображение №1: преобразование исходного файла в композитный сигнал (мелодия + данные), передаваемый через динамики.
Для начала исходный аудиосигнал разделяется на последовательные сегменты для анализа. Каждый такой сегмент (Hi) из L = 8820 образцов, равный 200 мс, умножается на окно* для минимизации граничных эффектов.
Окно* — весовая функция, используемая для управления эффектами, обусловленными наличием боковых лепестков в спектральных оценках.Далее обнаруживались доминирующие частоты исходного сигнала в диапазоне от 500 Гц до 9.8 кГц, что позволило получить маскирующие частоты fM,l для данного сегмента. В дополнение к этому производилась передача данных в малом диапазоне от 9.8 до 10 кГц для установления местоположения поднесущих в приемнике. Верхний предел используемой области частот был установлен на 10 кГц из-за низкой чувствительности микрофонов смартфона на высоких частотах.
Маскирующие частоты определялись для каждого анализируемого сегмента индивидуально. Посредством метода HPS (гармонический спектр продуктов) были установлены три доминирующие частоты, после чего они были округлены до ближайших нот гармонической хроматической шкалы. Именно так были получены основные ноты fF,i = 1…3, лежащие между клавишами C0 (16.35 Гц) и B0 (30.87 Гц). Исходя из того, что основные ноты слишком низкие для использования в передаче данных, в диапазоне 500 Гц … 9.8 кГц были рассчитаны их более высокие октавы 2kfF,i. Многие из этих частот (fO,l1) были более выражены из-за природы HPS.
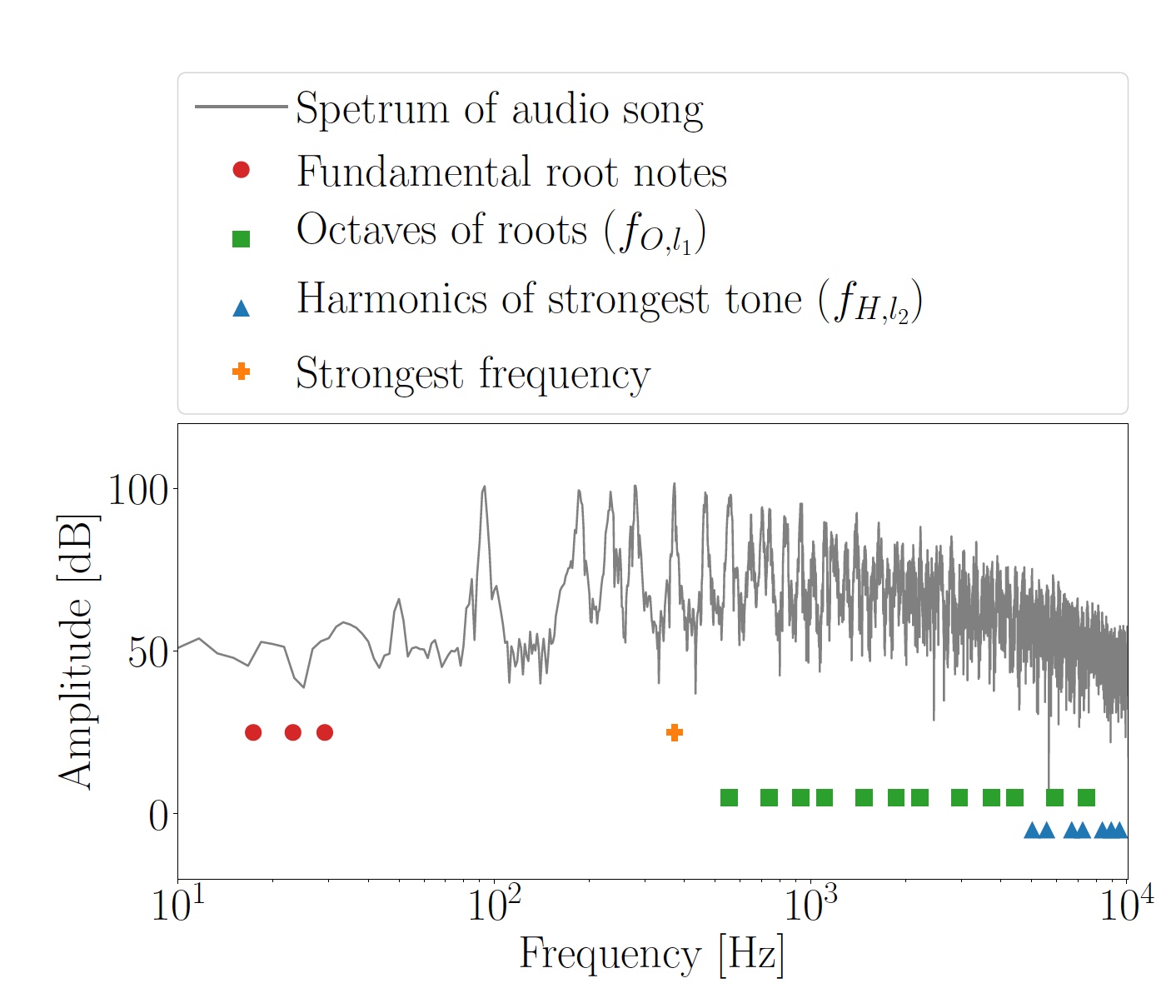
Изображение №2: рассчитанные октавы fO,l1 для основных нот и гармоник fH,l2 самого сильного тона.
Совокупность октав и гармоник в результате использовались как маскирующие частоты, на основе которых были получены частоты OFDM поднесущей fSC,k. Ниже и выше каждой маскирующей частоты вставлялись две поднесущие.
Далее происходила фильтрация спектра аудиосегмента Hi на частотах поднесущих fSC,k. После чего на основе информационных битов в Bi создавался OFDM символ, за счет чего композитный сегмент Ci мог передаваться через динамик. Величины и фазы поднесущих необходимо выбрать таким образом, чтобы приемник мог извлекать переданные данные, в то время как слушатель не замечал изменений в мелодии.
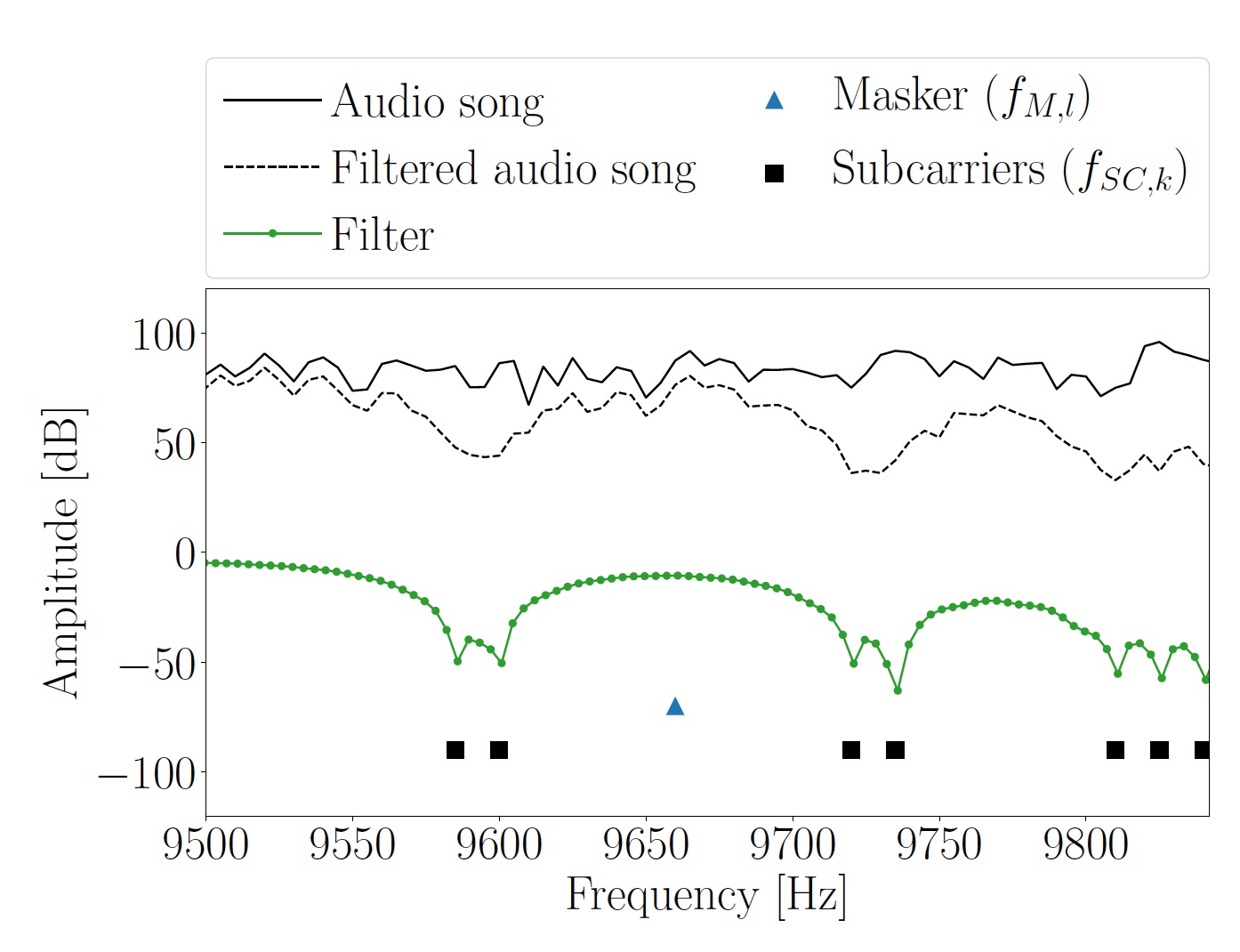
Изображение №3: участок спектра и частоты поднесущих сегмента Hi исходной мелодии.
Когда аудиосигнал с закодированной в нем информацией воспроизводится через динамики, микрофон принимающего устройства записывает его. Чтобы найти начальные позиции встроенных символов OFDM, записи для начала необходимо пропустить через полосовую фильтрацию. Таким образом извлекается верхний частотный диапазон, где нет музыкальных сигналов-помех между поднесущими. Найти начало OFDM символов можно с помощью циклического префикса.
После обнаружения начала OFDM символов приемник получает информацию о наиболее доминирующих нотах посредством декодирования верхней частотной области. К тому же, OFDM достаточно устойчив к воздействию источников узкополосных помех, поскольку они влияют только на некоторые из поднесущих.
Практические испытания
В качестве источника измененных мелодий выступил динамик KRK Rokit 8, а роль принимающей стороны сыграл смартфон Nexus 5X.

Изображение №4: разница между реальными проявлениями OFDM и пиками корреляции, измеренными в помещении на расстоянии 5 м между динамиком и микрофоном.
Большинство OFDM точек лежит в диапазоне от 0 до 25 мс, поэтому можно найти допустимое начало внутри циклического префикса 66.6 мс. Исследователи отмечают, что приемник (в данном опыте смартфон) учитывает, что OFDM символы воспроизводятся периодически, что улучшает их обнаружение.
Первое, что необходимо было проверить, так это влияние расстояния на коэффициент ошибок по битам (BER). Для этого было проведено три теста в разных типах помещений: коридор с ковровым покрытием, кабинет с линолеумом на полу и аудитория с деревянным полом.
В качестве «испытуемого» была выбрана песня «And The Cradle Will Rock» группы Van Halen.
Громкость звучания была настроена таким образом, чтобы измеряемый смартфоном на расстоянии 2 м от динамика уровень звука был 63 дБ.
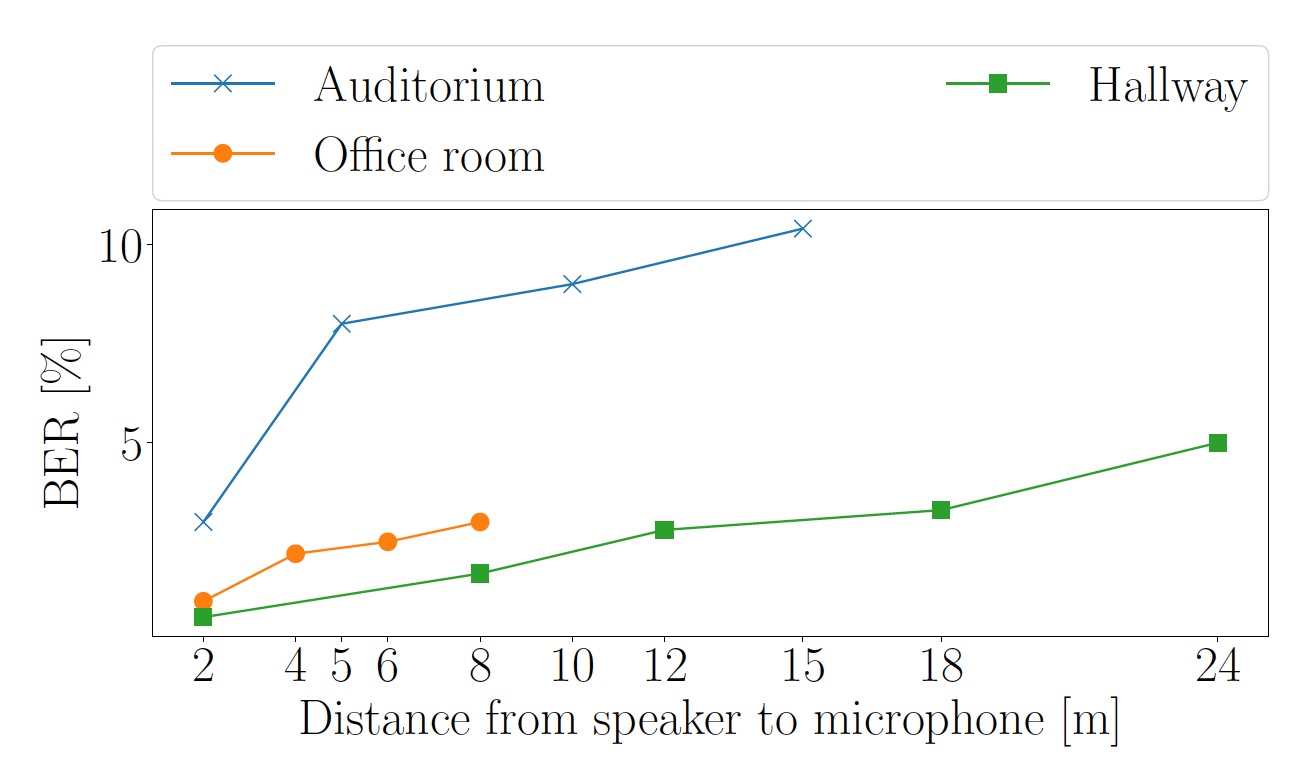
Изображение №5: показатели BER в зависимости от расстояния между динамиком и микрофоном (синяя линия — аудитория, зеленая — коридор, оранжевая — офис).
В коридоре звук в 40 дБ улавливался смартфоном на расстоянии до 24 метров от динамика. В аудитории на расстоянии 15 м звук был 55 дБ, а в офисе при расстоянии в 8 метров уровень воспринимаемого смартфоном звука достигал 57 дБ.
Ввиду того, что аудитория и офис являются более реверберирующими, поздние эхо-сигналы OFDM символов превышают длину циклического префикса и увеличивают BER.
Реверберация* — постепенное уменьшение интенсивности звука ввиду его многократного отражения.Далее исследователи продемонстрировали универсальность своей системы, применив ее к 6 разным песням трех жанров (таблица ниже).
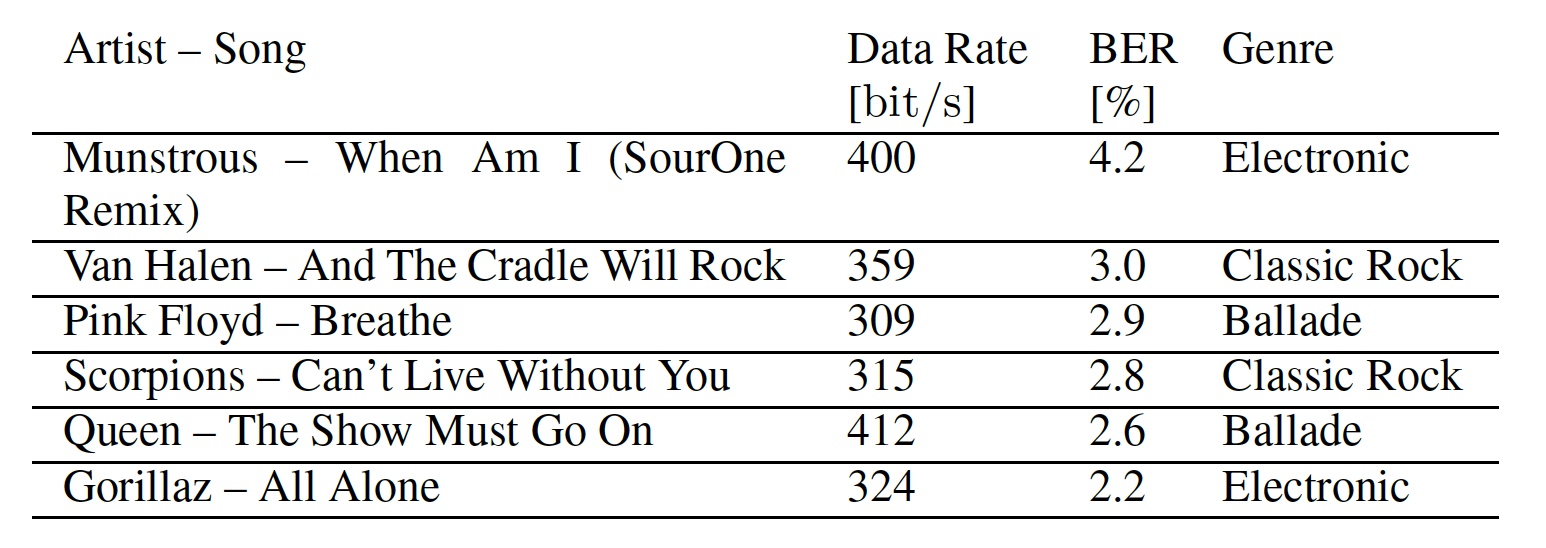
Таблица №1: использованные в тестах песни.
Также посредством данных таблицы мы можем увидеть скорость передачи и коэффициенты ошибок по битам для каждой песни. Скорость передачи данных отличается потому, что дифференциальный BPSK (фазовая манипуляция) работает лучше, когда используются одни и те же поднесущие. А это возможно, когда соседние сегменты содержат одинаковые маскирующие элементы. Непрерывно громкие песни обеспечивают оптимальную базу для сокрытия данных, поскольку маскирующие частоты более выражено присутствуют в широком частотном диапазоне. Быстро меняющаяся музыка может маскировать OFDM символы только частично из-за фиксированной длины окна анализа.
Далее к тестированию системы приступили люди, которые должны были определить какая мелодия изначальна, а какая была модифицирована внедренной в нее информацией. Для этого 12-секундные отрывки песен из таблицы №1 были размещены на специальном сайте.
В первом эксперименте (E1) каждому участнику предоставлялся либо измененный, либо исходный фрагмент для прослушивания, и он должен был решить, является ли этот фрагмент оригинальным или измененным. Во втором эксперименте (E2) участники могли сколько угодно раз прослушивать оба варианта, а потом решить, какой из них оригинал, а какой изменен.
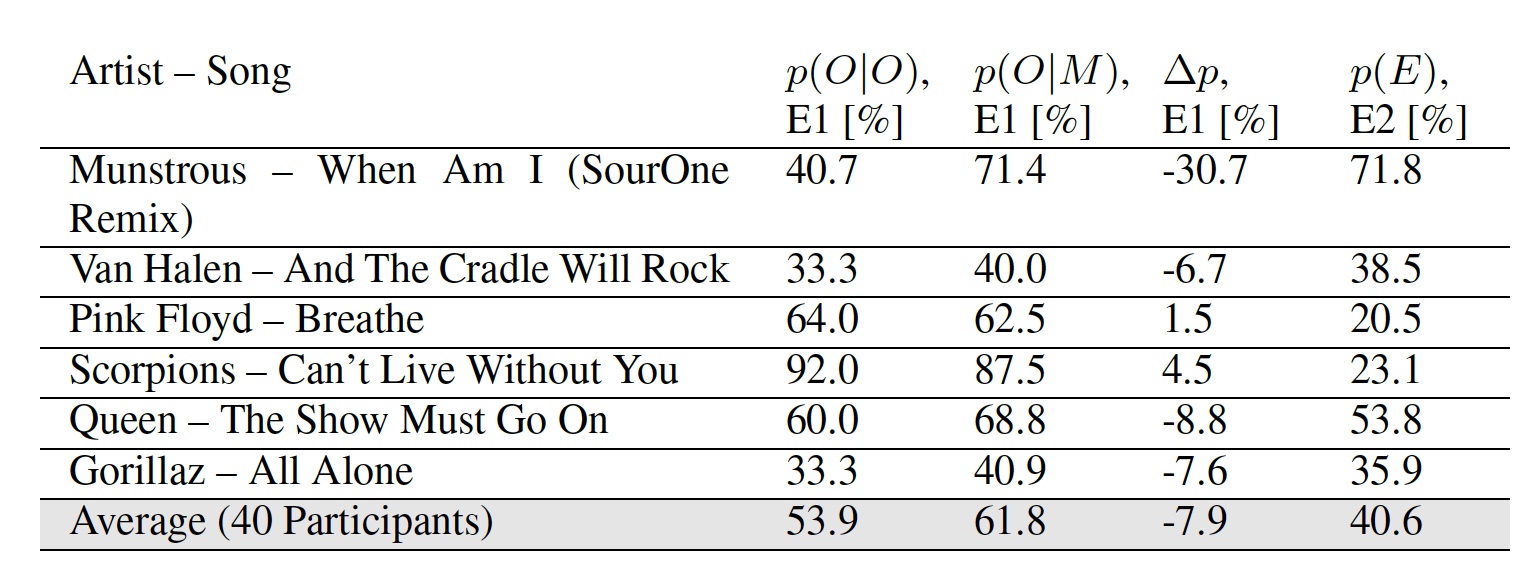
Таблица №2: результаты экспериментов E1 и E2.
В результатах первого опыта есть два показателя: p(О|О) — процент участников, которые верно отметили исходную мелодию и p(О|М) — процент участников, которые отметили измененную версию мелодии как оригинальную.
Любопытно, что некоторые участники, по словам исследователей, считали определенные измененные мелодии более оригинальными, чем сам оригинал. Средний показатель обоих экспериментов говорит о том, что среднестатистический слушатель не заметит разницы между обычной мелодией и той, в которую были встроены данные.
Естественно, знатоки музыки и музыканты смогут уловить некие неточности и подозрительные элементы в измененных мелодиях, но эти элементы не так значительны, чтобы вызывать дискомфорт.
А теперь мы сами можем поучаствовать в эксперименте. Ниже представлены два варианта одной и той же мелодии — оригинальный и измененный. Слышите ли вы разницу?
Оригинальный вариант мелодии
vs
Модифицированный вариант мелодии
Для более детального ознакомления с нюансами исследования рекомендую заглянуть в доклад исследовательской группы.
Также вы можете скачать ZIP-архив аудиофайлов оригинальных и измененных мелодий, использованных в исследовании, по этой ссылке.
Эпилог
В данном труде аспиранты швейцарской высшей технической школы Цюриха описали удивительную систему передачи данных внутри музыки. Для этого они применили частотное маскирование, что позволило внедрить данные в мелодию, проигрываемую динамиком. Эта мелодия воспринимается микрофоном устройства, которое распознает сокрытые данные и декодирует их, в то время как среднестатистический слушатель разницы даже не заметит. В дальнейшем ребята планируют развивать свою систему, подбирая более совершенные методы внедрения данных в аудио.
Когда кто-то придумывает что-то необычное, а главное рабочее, мы всегда радуемся. Но еще больше радости от того, что это изобретение было создано молодыми людьми. Наука не имеет возрастных ограничений. А если молодежь считает науку скучной, значит ее преподносят не под тем углом, так сказать. Ведь, как мы знаем, наука — это удивительный мир, который никогда не перестает удивлять.
Пятничный офф-топ:
Раз уж мы заговорили о музыке, а точнее о рок-музыке, то вот вам прекрасное путешествие по просторам рока.
Queen, «Radio Ga Ga» (1984).
Благодарю за внимание, оставайтесь любопытствующими, и отличных всем выходных, ребята! :)
Раз уж мы заговорили о музыке, а точнее о рок-музыке, то вот вам прекрасное путешествие по просторам рока.
Queen, «Radio Ga Ga» (1984).
Благодарю за внимание, оставайтесь любопытствующими, и отличных всем выходных, ребята! :)
Спасибо, что остаётесь с нами. Вам нравятся наши статьи? Хотите видеть больше интересных материалов? Поддержите нас оформив заказ или порекомендовав знакомым, 30% скидка для пользователей Хабра на уникальный аналог entry-level серверов, который был придуман нами для Вас: Вся правда о VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps от $20 или как правильно делить сервер? (доступны варианты с RAID1 и RAID10, до 24 ядер и до 40GB DDR4).
Dell R730xd в 2 раза дешевле? Только у нас 2 х Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 ТВ от $199 в Нидерландах! Dell R420 — 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB — от $99! Читайте о том Как построить инфраструктуру корп. класса c применением серверов Dell R730xd Е5-2650 v4 стоимостью 9000 евро за копейки?



