
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
YouTube можно использовать не только для развлечений, но и для обучения чему угодно.
Рекомендации на YouTube очень полезны, так как подсказывают релевантные видео к текущему, но и опасны потому что содержат ещё и в принципе интересные и отвлекающие ролики (не на тему видео).
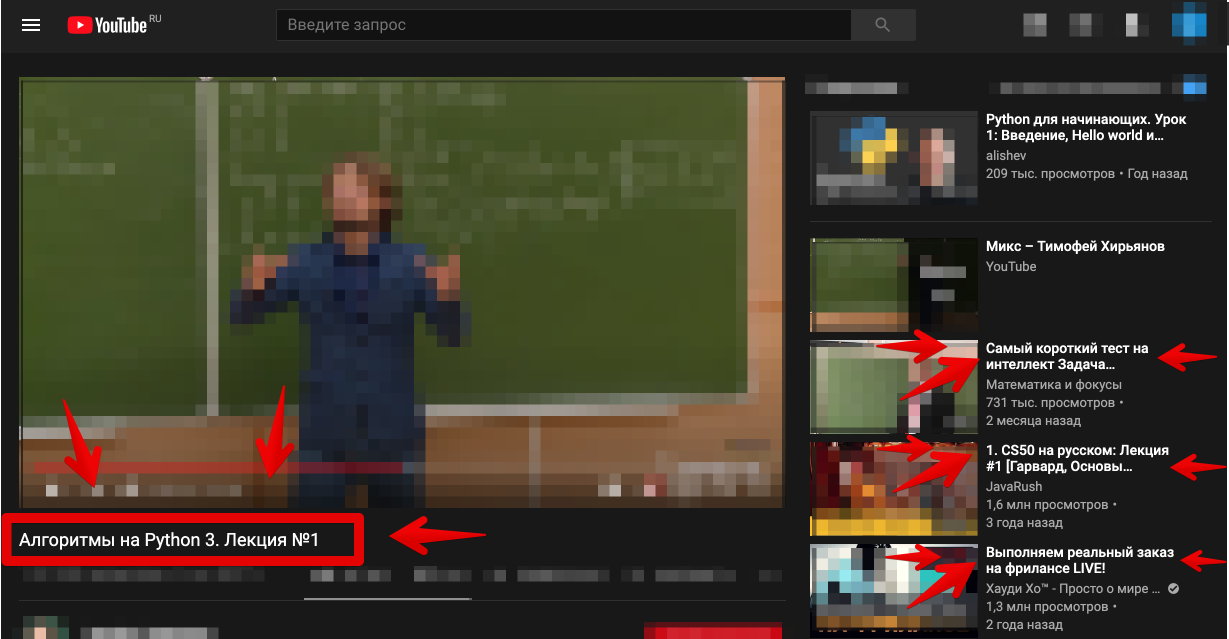
В какой-то момент ты просто устаешь смотреть ролики на определенную тему, и тут тебя ловят отвлекающие рекомендации, ибо YouTube выгоднее привлечь любым другим контентом лишь бы вы провели на нем больше времени. Серфя таким образом, теряем время впустую.
Предлагаемое решение
Можно разделять аккаунты для YouTube (для обучения и для развлечений), но к сожалению это не поможет от вбросов не релевантных роликов, так как рекомендательная система учится не только на вас, а на всех пользователях в принципе, а значит нужно чтобы все последовали этой тактике.
Поэтому решил, что можно попробовать сделать что-то, что будет блокировать не тематические рекомендации.
Идея реализация
В голову первым делом приходит машинное обучение, классификация текстов и т.п.
Но для обучения нужны огромные объемы информации. Да, и кто будет размечать рекомендации — непонятно.
Если решение делать через отправку всех рекомендаций на сервер для анализа, это значит построить свою "анти-рекомендательную" сеть роликов, и нужно слишком много ресурсов.
Сосредоточился на локальном решении — chrome расширение, которое на основе ролика и описания, классифицирует рекомендации на тематические и нет. Плюсом будет безопасность, данные не покидают клиента.
Реализация
Chrome расширение умеет инъектировать код. Прописываем в manifest.json:
"content_scripts": [
{
"matches": ["https://www.youtube.com/*"],
"css": ["styles.css"],
"js": ["page-script.js"]
}
],Селекторами достаем заголовок и описание, и рекомендованные видео. Делается достаточно просто:
// заголовок текущего ролика
document.querySelector('h1'),
// описание текущего ролика
document.querySelector('#description'),
// заголовки рекомендаций
document.querySelectorAll('ytd-compact-video-renderer')Можем добавить css класс, реализующий блюр и его исчезновение при ховере:
.youtube-stay-focused__blur {
filter: blur(5px) grayscale(100%);
opacity: 0.3;
}
.youtube-stay-focused__blur:hover {
filter: none;
opacity: 1;
}
Данные у нас есть и воздействовать на страницу тоже умеем, теперь пишем алгоритм.
Оценка рекомендаций
Ранжирование это и есть оценка тематичности документа.
Есть много алгоритмов ранжирования например TF-IDF, BM25 и прочее, можно было для них выставить пороговое значение 0. То есть если вглядеться в формулу

Можно понять что мы ищем хоть одно вхождение нужных слов в заголовок рекомендованного. Другими словами будем просто выбирать из всех заголовков рекомендаций, те к которых есть вхождение, хоть одного таргет слова (из заголовка и описания просматриваемого ролика).
Итоговый код простой "класификации"
https://github.com/itwillwork/youtube-stay-focused/blob/master/src/classifier.js
и тесты на него
https://github.com/itwillwork/youtube-stay-focused/blob/master/src/classifier.test.js
Подготовка текстов
Сначала все текста нужно "почистить":
- убирать лишние пробелы, переносы и т.п.;
- привести все к нижнему регистру;
- убрать всю пунктуацию и другие символы "#", "$", кавычки и т.п.;
- убрать числа, потому что не несут информации о тематике;
- удалить ссылки;
- убрать служебные слова, такие как trailer, audio, video и т.п.;
Токенизация
Любое приложение можно разбить на слова и называется это умным словом токенизация текста:
"Как написать красивый и понятный код?"
=>
["Как", "написать", "красивый", "и", "понятный", "код", "?"]Стемминг
Написать каждое слово можно огромным количеством вариаций из-за падежей, склонений и т.п. Все эти слова ассоциируются у нас в грамматике с корнем:
код, кода, коду, кодом, коде => кодЕсть алгоритм отрезающий все ненужное, называется стемминг. Есть множество вариации, выбрал Поттера, так как она лучше реализована.
Естественно реализация стемминга зависит от языка текста. И самостоятельного npm пакета русского стемминга не нашлось. Под руку попался лишь natural, https://www.npmjs.com/package/natural, но он заточен под nodejs (использует fshttps://www.npmjs.com/package/fs), но можно подключить модульно только тот код который нужен из всего пакета!
const porterStemmerRu = require('natural/lib/natural/stemmers/porter_stemmer_ru');
const porterStemmer = require('natural/lib/natural/stemmers/porter_stemmer');
// ...
const stem = (words) =>
words
.map((word) => porterStemmerRu.stem(word))
.map((word) => porterStemmer.stem(word));Таким образом заголовок преобразовывается в
"Как написать красивый и понятный код?"
=>
["как", "напис", "красив", "понят", "код"]Итоговый код подготовки текстов:
https://github.com/itwillwork/youtube-stay-focused/blob/master/src/prepare-senteces.js
И тесты к нему:
https://github.com/itwillwork/youtube-stay-focused/blob/master/src/prepare-senteces.test.js
Итог
Получилось Chrome расширение для скрывания НЕ тематических рекомендации на YouTube.

Исходники можно посмотреть:
https://github.com/itwillwork/youtube-stay-focused
Опубликовано в официальном chrome маркете, можно прямо сейчас установить и попробовать как оно работает:
https://chrome.google.com/webstore/detail/youtube-stay-focused/enhfmpfmofdnhelhegdjanoaomlcieen
Кто знает как сделать лучше welcome в комментарии или в контребьютеры ;)
https://github.com/itwillwork/youtube-stay-focused
Цените свое время.



