
Задача интеграции сервисов и различных систем является чуть ли не одной из основных проблем современного IT. На сегодняшний день самым популярным архитектурным стилем для проектирования распределенных систем является REST. Но, как известно, единого стандарта для RESTful сервисов нет, а у кажущейся простоты и свободы есть обратная сторона медали. Не менее важной является задача интеграции систем разными командами или даже компаниями, с которой приходит вопрос об актуальности документации на протяжении жизни всего проекта, и удобного способа передачи потребителю.
Эту проблему отчасти удалось решить при помощи спецификации OpenAPI (OAS 3.0)[1], но все равно часто встает вопрос о правильном применении и подводных камнях кодогенерации, например на языке Java. И можно ли полностью предоставить аналитикам написание функциональных требований, документации и моделей в yml форме для OpenAPI, а разработчикам предоставить возможность только написание бизнес-логики?
Что было раньше: код или документация?
Я уже около десяти лет занимаюсь разработкой на Java, и почти в каждом проекте так или иначе приходилось сталкиваться с необходимостью поделиться разработанным сервисом с другими людьми. Иногда достаточно просто составить понятное описание API существующего сервиса, но в серьезной enterprise-разработке такое описание часто создается еще на этапе аналитики в виде полноценного документа и является основой для грядущей работы.
В некоторых случаях такие документы составляются на этапе проектирования архитектуры в обычном текстовом формате, а потом передаются разработчику для реализации. Однако, для разработки REST-API такой подход не очень удобен и усложняет жизнь как программистам, которые должны еще правильно понять написанное, так и командам, которые будут с получившимся продуктом интегрироваться. К тому же документы могут интерпретироваться людьми по-разному, что обязательно приведет к необходимости дополнительных обсуждений, согласований и переделок, что в конечном счете срывает сроки и добавляет дефекты в продукт. Хотя, метод не очень удобен, иногда он до сих пор применяется при проектировании проектов без OpenAPI (например файловая интеграция, интеграция через БД, интеграция через очереди и общую шину).
Бывают подходы, когда требования создаются программистами уже в процессе работы, тогда финальная документация формируется на основе реализованного кода и передается потребителям сервиса. Часто это оправдано при быстрой реализации гипотез, единоличной разработке или очень сжатых cроках, например, при создании стартапов или при участии в хакатонах. В этом случае удобно генерировать документацию на основе написанного кода и предоставлять потребителю вместе с сервисом.
Но применимо это только в том случае, если разработчик может изначально продумать всю логику приложения. Если же задача слишком большая и сложная, а над проектом работает целая команда, то такой подход не очень эффективен. Например, когда из-за большого объема кода и сложности логики слишком сложно восстановить все тонкости работы приложения и детали реализации.
В случае крупных и серьезных проектов, ручное документирование приводит к ряду больших проблем. В SOAP сервисах потребители, получая ссылку на WSDL-документ, генерируют на своей стороне модель данных и клиентский код. В отличие от SOAP при интеграции OAS 3.0 или OpenAPI Specification является не просто спецификацией, а целой экосистемой инструментов для создания REST сервисов, и она позволяет решить как задачу генерации документации по существующему коду, так и обратную - генерацию кода по документации. Но прежде чем ответить на вечный вопрос, что первично, нужно определиться с целями и потребностями проекта.
Генерация документации по коду
Первым рассмотрим подход с автодокументируемым кодом[2,3]. Простота здесь заключается в том, что при использовании Spring MVC от разработчиков требуется всего лишь подключить пару библиотек, и на выходе уже получается вполне сносная документация с возможностью интерактивного взаимодействия с API.
Зависимости:
Spoiler
Maven
<dependency>
<groupId>org.springdoc</groupId>
<artifactId>springdoc-openapi-ui</artifactId>
<version>1.4.8</version>
</dependency><dependency>
<groupId>org.springdoc</groupId>
<artifactId>springdoc-openapi-webflux-ui</artifactId>
<version>1.4.8</version>
</dependency>Gradle
compile group: 'org.springdoc', name: 'springdoc-openapi-ui', version: '1.4.8'compile group: 'org.springdoc', name: 'springdoc-openapi-webflux-ui', version: '1.4.8'Результат доступен на: http://localhost:8080/swagger-ui.html
Сгенерированная документация по ссылке: http://localhost:8080/v3/api-docs
Плюсы подхода:
Возможность быстро сгенерировать документацию по существующему коду
Простота интеграции
Актуальная онлайн документация
Встроенная возможность интерактивного взаимодействия
Минусы подхода:
Документация написанная для разработчиков, содержит немного бизнес информации
При требовании подробного описания моделей и API возникает необходимость внедрять в код аннотации.
Для любых изменений требуется участие разработчика и правки кода
Требует от разработчика полного понимания архитектуры приложения или дополнительного документа с ее описанием
Часто аннотации с документацией для API выносят в абстрактный класс, для разделения документации и реализации, но модели при этом все равно остаются загруженными. Поэтому подход по искусственному слиянию кода и документации изначально кажется неестественным и усложненным.
Также не следует забывать о потребности версионирования API. В случае генерации документации по коду, для этого нужно дополнительное конфигурирование библиотек, что может быть сложно на уже написанном коде без его значительных изменений, а разные языки программирования в некоторых командах могут быть разными, что порождает дополнительную сложность.
Генерация кода по документации
Однако есть и обратный подход, когда код – объекты модели данных и интерфейсы контроллеров генерируются на основе описанной документации в yaml формате. Основной целью такого подхода является предоставление аналитикам возможности создать для потребителей не только общее описание, но и техническую документацию системы, по которой генерируется исходный код, а разработчик привлекается только при крупных изменениях, которые затрагивают бизнес логику системы.
Плюсы подхода
Ведение документации становится доступно не только разработчикам, но и техническим и системным аналитикам
Есть возможность разделить код и документацию
Можно объединить описание моделей, API и функциональных/бизнес требований
Любые изменения, инициированные бизнесом, сразу же применяются к модели и контроллерам
В случае критического несоответствия сервиса документации, сервис не соберется уже на этапе компиляции и потребует привести интерфейсы в соответствие с реализацией
Документацию в yaml формате легко предоставить потребителям сервиса при помощи сторонних библиотек, например redoc[4]
На основе yaml файлов можно описать сервисы на стороне потребителя, например, OpenApi для получения нотификаций от основного сервиса
На основе этой документации генерировать у себя тестовые сервисы для интеграционных и функциональных тестов
Минусы подхода
Более актуально для крупных и долгоживущих проектов (от одного года разработки)
Требует знания yaml формата для описания моделей
Требует навыки работы с markdown для описания функциональных требований
Нужно хорошее взаимодействие в команде, чтобы результаты изменения документации и бизнес-логики в сервисе были синхронизированы
Подводные камни и опыт реализации:
Задача по применению второго подхода впервые появилась, когда потребовалось предоставить потребителям актуальную веб-версию документации с подробным описанием функциональных требований и бизнес-кейсов. Написание такой документации и ее актуализацию предстояло вести техническим аналитикам без возможности напрямую редактировать код. И еще одним важным требованием было красивое визуальное представление документации. Далее опишу базовый набор конфигураций для достижения этой цели и возможные подводные камни и проблемы[2,3]
Первым делом добавляем зависимость на maven плагин
Spoiler
<dependency>
<groupId>io.swagger.codegen.v3</groupId>
<artifactId>swagger-codegen-maven-plugin</artifactId>
<version>3.0.21</version>
</dependency> <artifactId>springdoc-openapi-webflux-ui</artifactId> <version>1.4.8</version>И конфигурируем генератор кода
Spoiler
<plugin>
<groupId>io.swagger.codegen.v3</groupId>
<artifactId>swagger-codegen-maven-plugin</artifactId>
<version>3.0.21</version>
<executions>
<execution>
<id>1</id>
<goals>
<goal>generate</goal>
</goals>
<configuration>
<groupId>com.habr</groupId>
<artifactId>oas3</artifactId>
<inputSpec>${project.basedir}/src/main/resources/habr-1.yaml</inputSpec>
<output>${project.build.directory}/generated-sources/</output>
<language>spring</language>
<configOptions>
<sourceFolder>src/gen/java/main</sourceFolder>
<library>spring-mvc</library>
<interfaceOnly>true</interfaceOnly>
<useBeanValidation>true</useBeanValidation>
<dateLibrary>java8</dateLibrary>
<java8>true</java8>
<apiTests>false</apiTests>
<modelTests>false</modelTests>
</configOptions>
<modelPackage>com.habr.oas3.model</modelPackage>
<apiPackage>com.habr.oas3.controller</apiPackage>
</configuration>
</execution>
<execution>...</execution>
...
</executions>В случае наличия в проекте нескольких файлов документации следует указывать их в разных execution блоках, однако, каждый запуск перетирает результаты предыдущего запуска (либо игнорирует при включении определенного флага). При наличии нескольких yaml файлов рекомендуется избегать коллизий в моделях и интерфейсах чтобы запуски не перетирали уже сгенерированные модели.
InputSpec содержит путь к документации, а modelPackage и apiPackage пакеты для сгенерированных моделей. Также можно генерировать моковые реализации интерфейсов для тестов (при генерации некоторый контроллер, что отвечает типичным ответом).
Флаг interfaceOnly позволяет генерировать только интерфейсы контроллеров и предоставить разработчику лишь контракты для реализации.
Общая структура yaml документации:
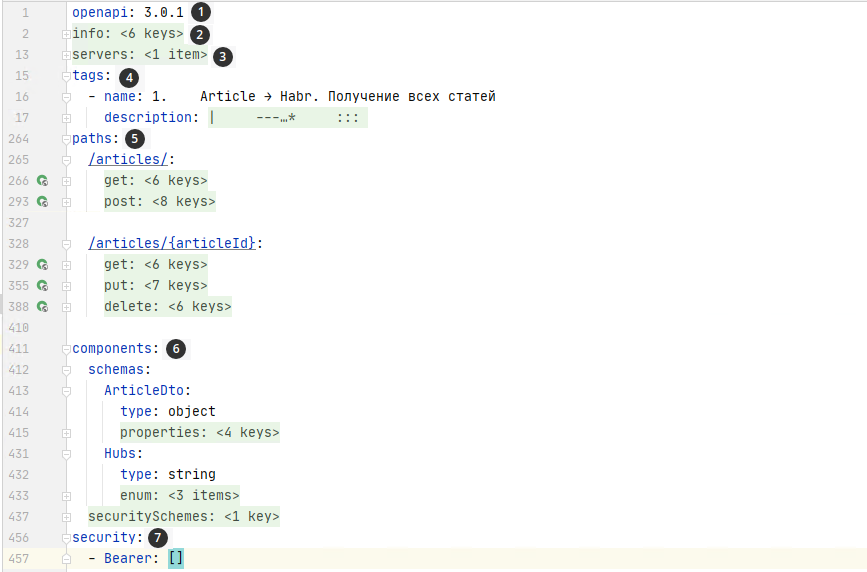
openApi- Содержит версиюinfo- метаданные для apiservers- информация о серверах c apitags- дополнительные метаданные, в этом блоке нужно писать текст ФТ и регламента взаимодействияpaths- описание endpoints и интерфейсов контроллеровcomponents- описание модели данныхsecurity- схема безопасности
Исходный код на github и пример документации можно посмотреть здесь
Визуализация и предоставление потребителю: swagger-ui vs redoc
Теперь поговорим про способы поставки полученной документации. Помимо ручного написания и передачи любым удобным каналом бытует подход с онлайн-документацией в связке с существующим сервисом. Рассмотрим самые удобные и популярный способы такой поставки.
Swagger-ui
Удобная реализация с возможностью интерактивного взаимодействия. Идет из коробки в проекте swagger.io[5]. Можно подключить как библиотеку вместе с сервисом или развернуть статикой отдельно.
Пример визуализации документации тестового сервиса:

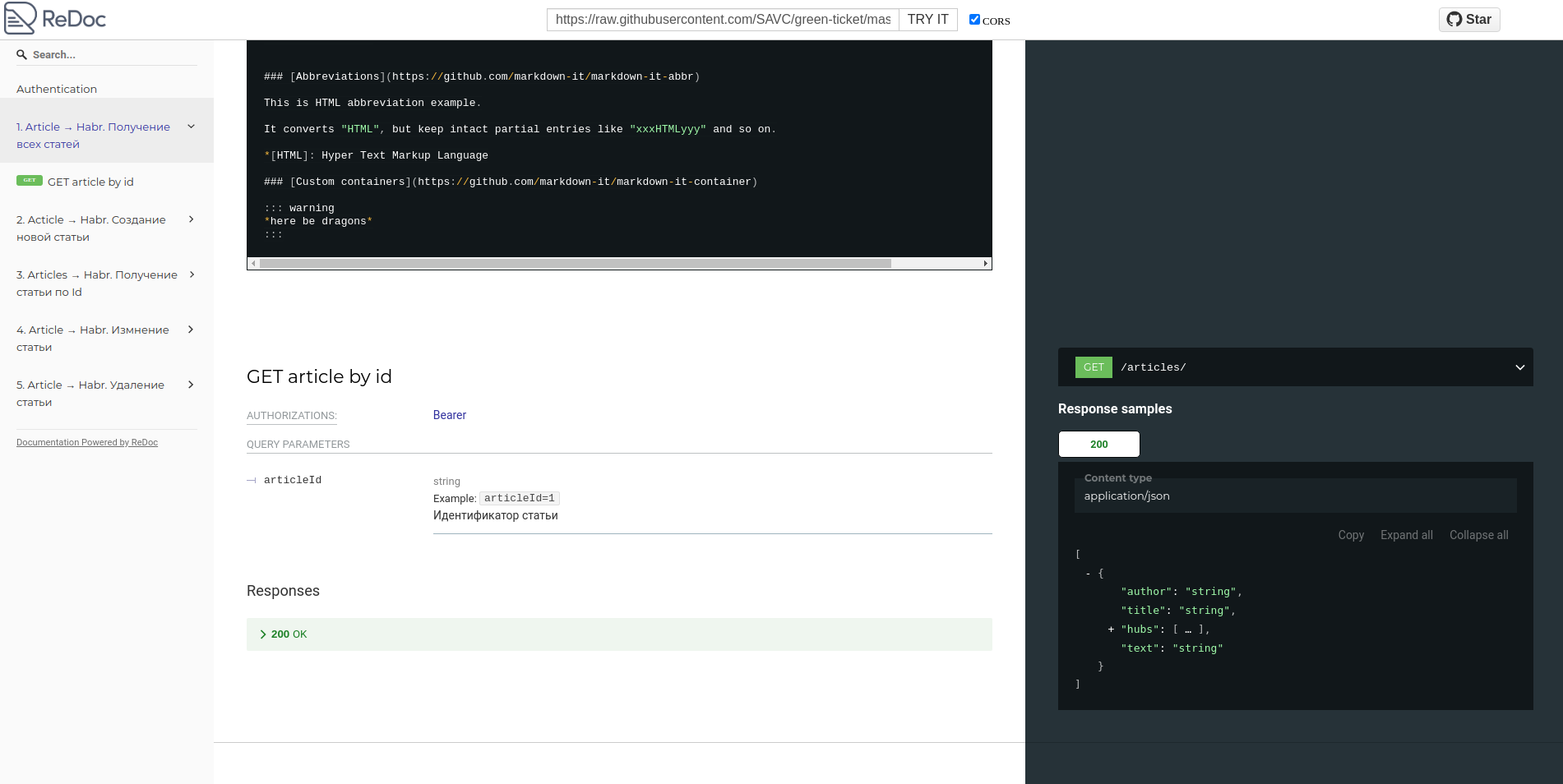
Redoc
Он позволяет отобразить и кастомизировать документацию альтернативным способом. Более удобная и красивая структура документации[4].
Пример визуализации документации тестового сервиса:
Хотя, redoc реализован на react, его также можно использовать и как VueJS компонент:
Spoiler
<template>
<div v-if="hasYmlContent">
<RedocStandalone :spec='ymlObject' :options='ropt' />
</div>
</template>
<style...>
<script>
import AuthService from '../services/auth.service';
import DocumentationService from '../services/documentation.service'
import {RedocStandalone} from 'redoc'
import {API_URL} from "../services/auth-header";
import YAML from "yamljs"
import Jquery from "jquery"
export default {
name: 'documentation',
components: {'RedocStandalone': RedocStandalone},
props: ['yml'],
data: function() {
return {
ymlContent: false,
ropt:{...},
}
},
created() {...},
computed: {...}
};
</script>Выводы
Проведение аналитики и проектирование системы до начала этапа разработки помогает лучше понять задачи и избежать многих ошибок при реализации. Проект OAS 3.0 показал себя очень удобным для описания документации и поставки ее потребителям сервиса.
На опыте своих проектов удалось убедиться, что такой подход не только удобен, но и позволяет без особых сложностей передавать аналитикам часть работы с описанием моделей и API будущей системы, что также повышает их собственную экспертизу и понимание сервиса. Освоение ведения такой документации довольно несложно, и, как показала практика, даже человек без опыта использования этого подхода уже через пару недель полноценно освоил не только ведение документации в yml формате, поставку ее через git, но и оценил его удобство против классического ручного составление функциональных требований.
Данный инструмент отлично подходит и для крупных проектов с генерацией кода по документации и для мелких проектов для быстрого для удобной визуализации документации на основе несложного кода.
Источники
https://swagger.io/specification/
https://www.baeldung.com/spring-rest-openapi-documentation
https://github.com/springdoc/springdoc-openapi
https://redocly.github.io/redoc/
https://swagger.io/tools/swagger-ui/


