
В этом посте делимся с вами подборкой источников полезной информации о Data Science от сооснователя и CTO DAGsHub — сообщества и веб-платформы для контроля версий данных и совместной работы дата-сайентистов и инженеров по машинному обучению. В подборку попали самые разные источники, от аккаунтов в твиттере, до полноценных инженерных блогов, которые ориентированы для тех, кто точно знает, что ищет. Подробности под катом.
От автора:
Вы – это то, что вы едите, и вам, как работнику умственного труда — нужна хорошая информационная диета. Я хочу поделиться источниками информации о Data Science, искусственном интеллекте и связанных с ним технологиях, которые нахожу наиболее полезными или привлекательными. Я надеюсь, что это поможет и вам тоже!
Two Minute Papers
YouTube-канал, который хорошо подходит, для того чтобы быть в курсе последних событий. Канал часто обновляется, а ведущий обладает заразительным энтузиазмом и позитивом во всех освещаемых темах. Ожидайте освещения интересных работ не только об ИИ, но и о компьютерной графике и других визуально привлекательных темах.
Янник Килчер
На своем YouTube-канале, Янник технически подробно объясняет значимые исследования в глубоком обучении. Вместо того, чтобы читать исследование самостоятельно, часто бывает быстрее и проще посмотреть одно из его видео, чтобы глубже понять важные статьи. Объяснения передают суть статей, не пренебрегая математикой и не теряясь в трех соснах. Янник также делится своими взглядами — о том, как исследования соотносятся друг с другом, мнением о том, насколько серьезно нужно относиться к результатам, более широкими интерпретациями и т.д. Новичкам (или неакадемическим практикам) труднее прийти к этим открытиям самостоятельно.
Distill.pub
По их собственным словам:
Исследования в области машинного обучения должны быть ясными, динамичными и яркими. А Distill создан, чтобы помогать в исследованиях.
Distill — уникальное издание с исследованиями в области машинного обучения. Продвигаются статьи с потрясающими визуализациями, чтобы дать читателю более интуитивное понимание тем. Пространственное мышление и воображение, как правило, работают очень хорошо, помогая в понимании тем машинного обучения и Data Science. Традиционные же форматы публикаций, напротив, имеют тенденцию быть жесткими в своей структуре, статичными и сухими, а иногда и «математическими». Крис Ола (Chris Olah), один из создателей Distill, также ведет удивительный личный блог на GitHub. Он давно не обновлялся, но до сих пор остается коллекцией лучших из когда-либо написанных объяснений по теме глубокого обучения. В частности, мне очень помогло описание LSTM!
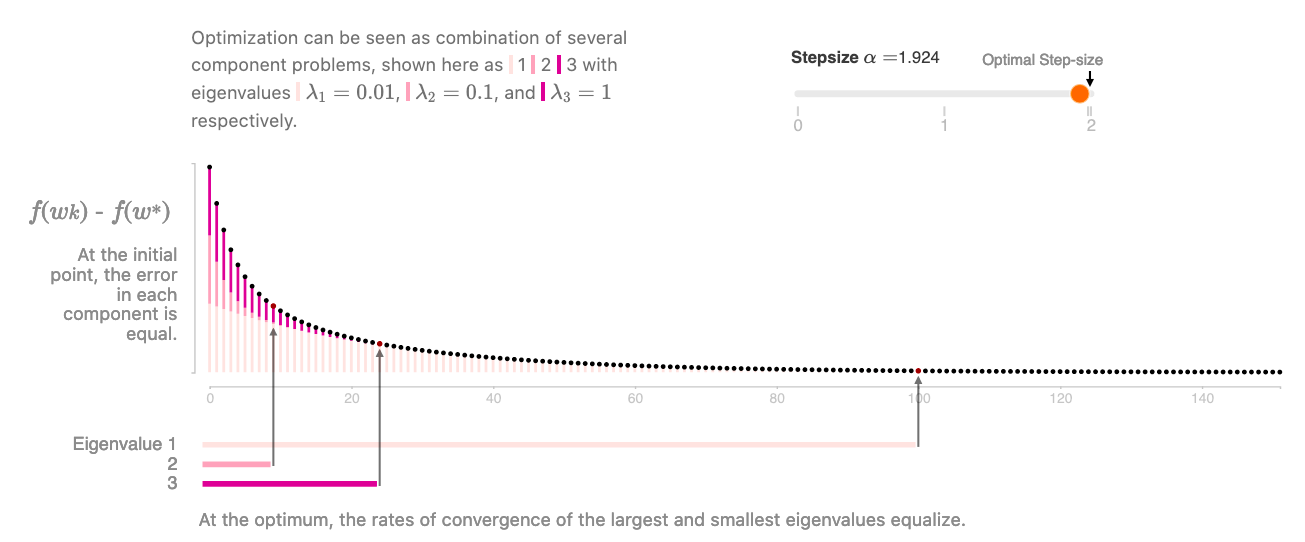
источник
Себастьян Рудер
Себастьян Рудер пишет очень содержательный блог и информационный бюллетень, в первую очередь о пересечении нейронных сетей и анализа текстов на естественных языках. Он также дает много советов исследователям и докладчикам на научных конференциях, они могут быть очень полезны, если вы находитесь в академических кругах. Статьи Себастьяна, как правило, имеют форму обзоров, подводя итоги и объясняя состояние современных исследований и методов в той или иной области. Это означает, что статьи крайне полезны для практиков, которые хотят быстро сориентироваться. Себастьян также пишет в Twitter.
Андрей Карпати
Андрей Карпати не нуждается в представлении. Помимо того, что он является одним из самых известных исследователей глубокого обучения на Земле, он создает широко используемые инструменты, например, arxiv sanity preserver в качестве сторонних проектов. Бесчисленное множество людей вошли в эту сферу через его Стэнфордский курс cs231n, и вам будет полезно узнать его рецепт обучения нейронной сети. Я также рекомендую посмотреть его речь о реальных проблемах, которые Tesla должна преодолеть, пытаясь применить машинное обучение в массовом масштабе в реальном мире. Речь информативна, она впечатляет и отрезвляет. Помимо статей об ML непосредственно, Андрей Карпати дает хорошие жизненные советы для амбициозных ученых. Читайте Андрея в Twitter и на Github.
Uber Engineering
Инженерный блог Uber действительно впечатляет масштабом и широтой охвата, освящая массу тем, в частности искусственный интеллект. Что мне особенно нравится в инженерной культуре Uber, так это их тенденция выпускать очень интересные и ценные проекты с открытым исходным кодом в головокружительном темпе. Вот некоторые примеры:
- ludwig
- h3
- react-vis
- aresdb
- И этот список можно продолжать и продолжать… Снимаю шляпу, Uber
OpenAI Blog
Если отбросить разногласия, блог OpenAI, несомненно, прекрасен. Время от времени в блоге публикуется контент и идеи о глубоком обучении, которые могут прийти только в масштабах OpenAI: гипотетический феномен глубокого двойного спуска. Команда OpenAI, как правило, публикует посты нечасто, но это важные материалы.

источник
Taboola Blog
Блог Taboola не так хорошо известен, как некоторые другие источники в этом посте, но я считаю его уникальным — авторы пишут об очень приземленных, реальных проблемах при попытке применять ML в производстве для «нормального» бизнеса: меньше о самоуправляемых автомобилях и агентах RL, побеждающих чемпионов мира, больше о том, «как мне узнать, что моя модель теперь предсказывает вещи с фальшивой уверенностью?». Эти проблемы актуальны почти для всех, кто работает в этой области, и они меньше освещаются в прессе, чем более расхожие темы ИИ, но для правильного решения этих проблем все еще требуется талант мирового класса. К счастью, Taboola обладает как этим талантом, так и готовностью и способностью писать о нем, чтобы другие люди тоже могли учиться.
Наряду с Twitter, нет ничего лучше в Reddit, чем зацепиться за исследования, инструменты или мудрость толпы.
- reddit.com/r/machinelearning
- reddit.com/r/datascience
State of AI
Посты публикуются только ежегодно, но наполнены информацией очень плотно. По сравнению с другими источниками из этого списка, этот доступнее для не связанных с технологиями деловых людей. Что мне нравится в докладах, так это то, что он пытается дать более целостное представление о том, куда движется отрасль и исследования, с высоты птичьего полета связывая воедино достижения в области аппаратного обеспечения, исследований, бизнеса и даже геополитики. Обязательно начинайте с конца, чтобы прочитать о конфликте интересов.
Подкасты
Откровенно говоря, я считаю, что подкасты плохо приспособлены для изучения технических тем. Ведь для объяснения тем они используют только звук, а наука о данных — это очень визуальная область. Подкасты, как правило, дают вам повод для более глубокого исследования позже или в для увлекательных философских дискуссий. Тем не менее, вот некоторые рекомендации:
- подкаст Лекса Фридмана, когда он разговаривает с видными исследователями из области искусственного интеллекта. Особенно хороши эпизоды с Франсуа Шолле!
- Data Engineering подкаст. Хорош, чтобы услышать о новых инструментах инфраструктуры данных.
Потрясающие списки
Здесь меньше того, за чем нужно следить, но больше ресурсов, которые полезны, когда вы знаете, что ищете:
- github.com/josephmisiti/awesome-machine-learning
- awesomedataengineering.com
- Мэтти Мариански
Мэтти находит красивые, творческие способы использования нейронных сетей, и это просто забавно — видеть его результаты в вашей ленте Twitter. Взглянуть бы хотя бы на этот пост. - Ори Коэн
Ори — просто машина для ведения блогов. Он много пишет о проблемах и решениях для дата-сайентистов. Обязательно подпишитесь, чтобы получить уведомление, когда публикуется статья. Его сборник, в частности, действительно впечатляет. - Джереми Говард
Соучредитель компании fast.ai, всесторонний источник творчества и продуктивности. - Хамель Хусейн
Штатный инженер ML в Github, Хамель Хусейн занят на работе созданием и отчетностью по многим инструментам для кодеров в области данных. - Франсуа Шолле
Создатель Keras, сейчас пытается обновить наши представления о том, что такое интеллект и как его проверить. - Хардмару
Ученый-исследователь в Google Brain.
Заключение
Оригинал поста может обновляться по мере того, как автор находит замечательные источники контента, которые было бы стыдно не включить в список. Не стесняйтесь обращаться к нему в Twitter, если хотите порекомендовать какой-то новый источник! А еще DAGsHub нанимает Advocate [прим. перев. публичного практикующего стороннника] в Data Science, так что если вы создаете свой собственный контент по Data Science, не стесняйтесь написать автору поста.

Развивайтесь, читая рекомендованные источники, а по промокоду HABR, вы сможете получить дополнительные 10% к скидке указанной на баннере.
- Онлайн-буткемп по Data Science
- Обучение профессии Data Analyst с нуля
- Онлайн-буткемп по Data Analytics
- Обучение профессии Data Science с нуля
- Курс «Python для веб-разработки»
Eще курсы
- Курс по аналитике данных
- Курс по DevOps
- Профессия Веб-разработчик
- Профессия iOS-разработчик с нуля
- Профессия Android-разработчик с нуля
- Профессия Java-разработчик с нуля
- Курс по JavaScript
- Курс по Machine Learning
- Курс «Математика и Machine Learning для Data Science»
- Продвинутый курс «Machine Learning Pro + Deep Learning»
Рекомендуемые статьи
- Как стать Data Scientist без онлайн-курсов
- 450 бесплатных курсов от Лиги Плюща
- Как изучать Machine Learning 5 дней в неделю 9 месяцев подряд
- Сколько зарабатывает аналитик данных: обзор зарплат и вакансий в России и за рубежом в 2020
- Machine Learning и Computer Vision в добывающей промышленности



