Привет! Меня зовут Вадим Мадисон, я руковожу разработкой System Platform Авито. О том, как мы в компании переходим с монолитной архитектуры на микросервисную, было сказано не раз. Пора поделиться тем, как мы преобразовали свою инфраструктуру, чтобы извлечь из микросервисов максимум пользы и не дать себе в них потеряться. Как нам здесь помогает PaaS, как мы упростили деплой и свели создание микросервиса к одному клику — читайте дальше. Не всё, о чём я пишу ниже, в Авито реализовано в полной мере, часть — то, как мы развиваем нашу платформу.
(А ещё в конце этой статьи я расскажу о возможности попасть на трехдневный семинар от эксперта по микросервисной архитектуре Криса Ричардсона).

Как мы пришли к микросервисам
Авито — один из крупнейших в мире классифайдов, на нём публикуется больше 15 млн новых объявлений в сутки. Наш бэкенд принимает больше 20 тыс. запросов в секунду. Сейчас у нас несколько сотен микросервисов.
Микросервисную архитектуру мы выстраиваем не первый год. Как именно — наши коллеги деталях рассказали на нашей секции на РИТ++ 2017. На CodeFest 2017 (см. видео), Сергей Орлов и Михаил Прокопчук подробно объяснили, зачем нам вообще понадобился переход к микросервисам и какую роль здесь у нас играл Kubernetes. Ну а сейчас мы делаем всё, чтобы свести к минимуму те издержки масштабирования, которые такой архитектуре присущи.
Изначально мы не делали экосистему, которая всесторонне помогала бы нам в разработке и запуске микросервисов. Просто собирали толковые опенсорсные решения, запускали их у себя и предлагали разработчику разобраться с ними. В итоге тот ходил в десяток мест (дашборды, внутренние сервисы), после чего укреплялся в стремлении пилить код по-старому, в монолите. Зелёным цветом на схемах ниже обозначено то, что делает разработчик так или иначе своими руками, жёлтым цветом — автоматизация.
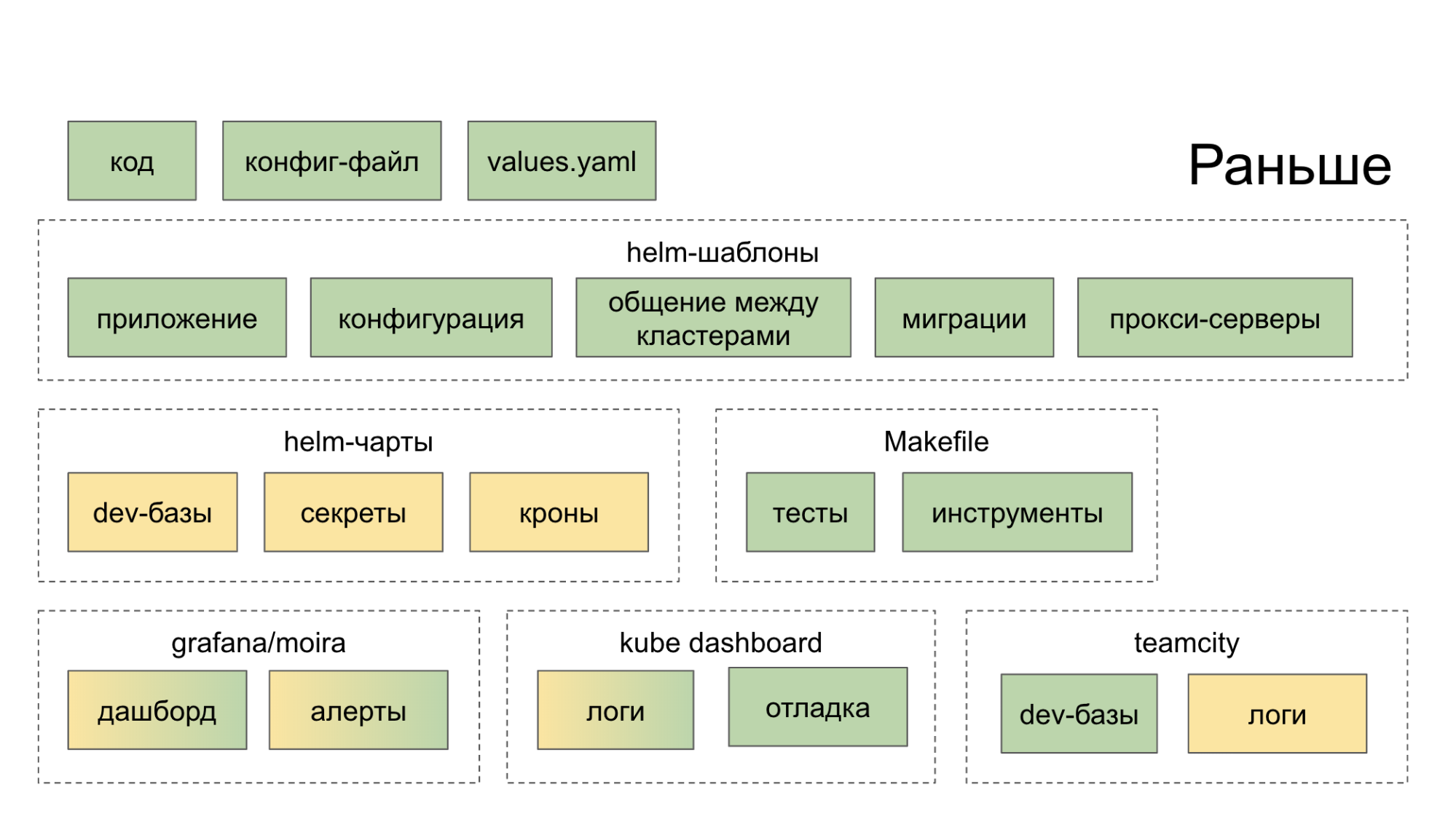
Сейчас в CLI-утилите PaaS одной командой создаётся новый сервис, а ещё двумя добавляется новая база данных и деплоится в Stage.
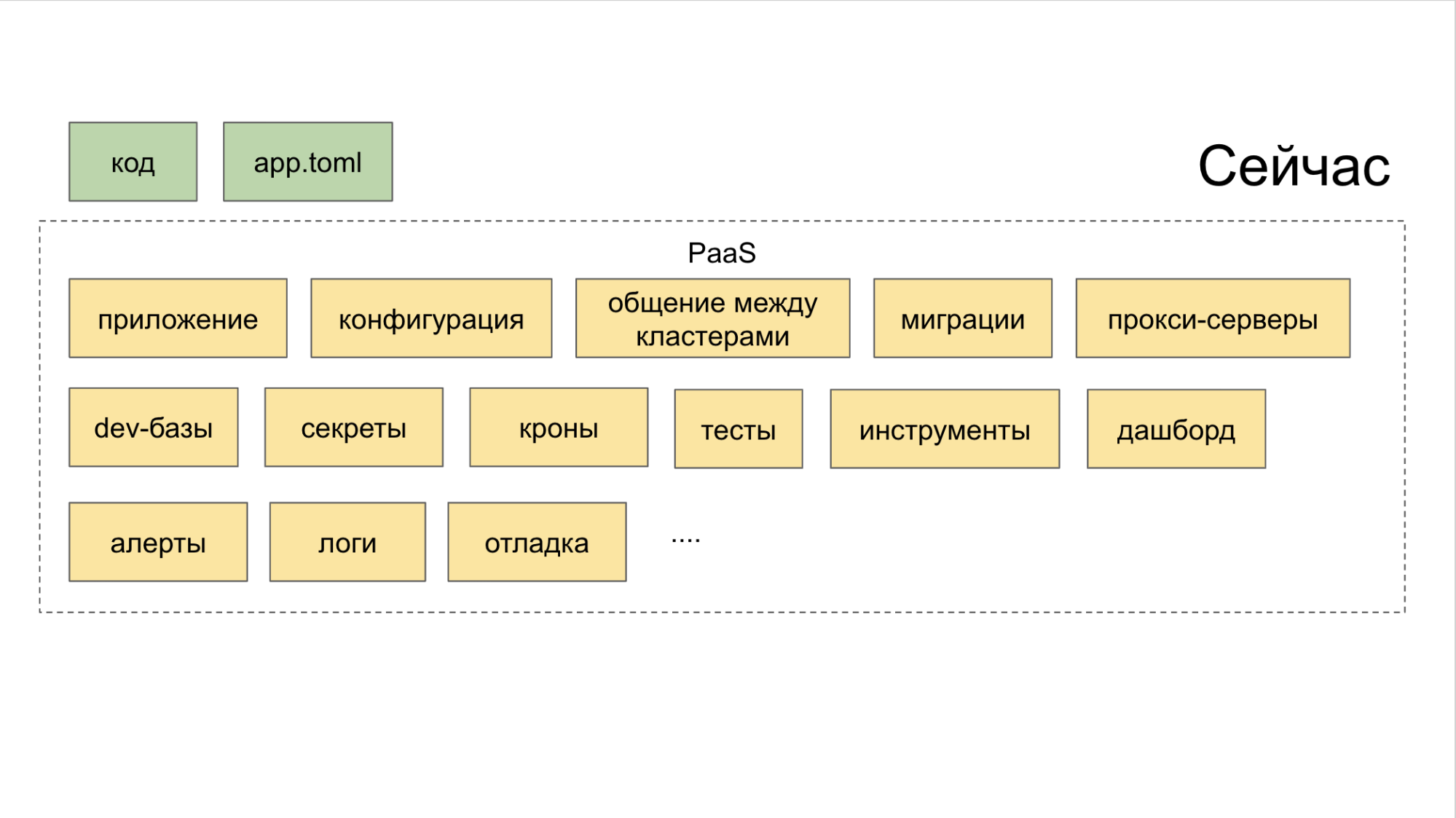
Как преодолеть эпоху «микросервисной раздробленности»
При монолитной архитектуре, ради консистентности изменений в продукте разработчики были вынуждены разбираться, что творится у соседей. При работе по новой архитектуре контексты сервисов перестали зависеть друг от друга.
Кроме того, чтобы микросервисная архитектура была эффективной, требуется наладить множество процессов, а именно:
• логирование;
• трассировка запросов (Jaeger);
• агрегация ошибок (Sentry);
• статусы, сообщения, события из Kubernetes (Event Stream Processing);
• race limit / circuit breaker (можно использовать Hystrix);
• контроль связности сервисов (мы используем Netramesh);
• мониторинг (Grafana);
• сборка (TeamCity);
• общение и нотификация (Slack, email);
• трекинг задач; (Jira)
• составление документации.
Чтобы по мере масштабирования система не утратила целостность и оставалась эффективной, мы переосмыслили организацию работы микросервисов в Авито.
Как мы управляемся с микросервисами
Проводить единую «политику партии» среди множества микросервисов Авито помогают:
- разделение инфраструктуры на слои;
- концепция Platform as a Service (PaaS);
- мониторинг всего, что с микросервисами происходит.
Уровни абстракции инфраструктуры включают в себя три слоя. Пойдём от верхнего к нижнему.
A. Верхний — service mesh. Поначалу мы пробовали Istio, но оказалось, что он использует слишком много ресурсов, что на наших объёмах выходит чересчур дорого. Поэтому старший инженер в команде архитектуры Александр Лукьянченко разработал собственное решение — Netramesh (доступно в Open Source), которое мы сейчас используем в продакшене и которое потребляет в несколько раз меньше ресурсов, чем Istio (но и делает не всё, чем может похвастаться Istio).
B. Средний — Kubernetes. На нём мы развёртываем и эксплуатируем микросервисы.
C. Нижний — bare metal. Мы не используем облака и штуки типа OpenStack, а сидим целиком на bare metal.
Все слои объединяются PaaS. А платформа эта, в свою очередь, состоит из трёх частей.
I. Генераторы, управляемые через CLI-утилиту. Именно она помогает разработчику создать микросервис по-правильному и с минимумом усилий.
II. Сводный коллектор с контролем всех инструментов через общий дашборд.
III. Хранилище. Стыкуется с планировщиками, которые автоматически выставляют триггеры на значимые действия. Благодаря такой системе ни одна задача не оказывается упущенной только из-за того, что кто-то забыл поставить себе таск в Jira. Мы для этого используем внутренний инструмент под названием Atlas.

Реализация микросервисов в Авито также ведётся по единой схеме, что упрощает контроль над ними на каждой стадии разработки и выпуска.
Как устроен стандартный конвейер разработки микросервиса
В общем виде цепочка создания микросервиса выглядит следующим образом:
CLI-push → Continuous Integration → Bake → Деплой → Искусственные тесты → Canary-тесты → Squeeze Testing → Продакшен → Обслуживание.
Пройдёмся по ней ровно в такой последовательности.
CLI-push
• Создание микросервиса.
Мы долго бились над тем, чтобы научить каждого разработчика делать микросервисы. В том числе писали в Confluence подробные инструкции. Но схемы менялись и дополнялись. Итог — бутылочное горлышко образовалось в начале пути: на запуск микросервисов уходило времени куда больше допустимого, и всё равно при их создании часто возникали проблемы.
В конце концов мы соорудили простую CLI-утилиту, которая автоматизирует основные шаги при создании микросервиса. Фактически она заменяет первый git push. Вот что конкретно она делает.
— Создаёт сервис по шаблону — пошагово, в режиме «визарда». У нас есть шаблоны для основных языков программирования в бэкенде Авито: PHP, Golang и Python.
— По одной команде разворачивает среду для локальной разработки на конкретной машине — поднимается Minikube, Helm-чарты автоматически генерируются и запускаются в локальном kubernetes’е.
— Подключает нужную базу данных. Разработчику нет надобности знать IP, логин и пароль, чтобы получить доступ к нужной ему БД — хоть локально, хоть в Stage, хоть на продакшене. Причём развёртывается база данных сразу в отказоустойчивой конфигурации и с балансировкой.
— Сама выполняет live-сборку. Допустим, разработчик поправил что-то в микросервисе через свою IDE. Утилита видит изменения в файловой системе и исходя из них пересобирает приложение (для Golang) и перезапускает. Для PHP мы просто пробрасываем директорию внутрь куба и там live-reload получается «автоматом».
— Генерирует автотесты. В виде болванок, но вполне пригодных к использованию.
• Деплой микросервиса.
Разворачивать микросервис у нас раньше было слегка муторно. В обязательном порядке требовались:
I. Dockerfile.
II. Конфиг.
III. Helm-чарт, который сам по себе громоздкий и включает в себя:
— сами чарты;
— шаблоны;
— конкретные значения с учётом разных сред.
Мы избавились от боли с переделыванием манифестов Kubernetes, и теперь они генерируются автоматически. Но главное, упростили до предела деплой. Отныне у нас есть Dockerfile, а весь конфиг разработчик прописывает в одном-единственном коротком файле app.toml.
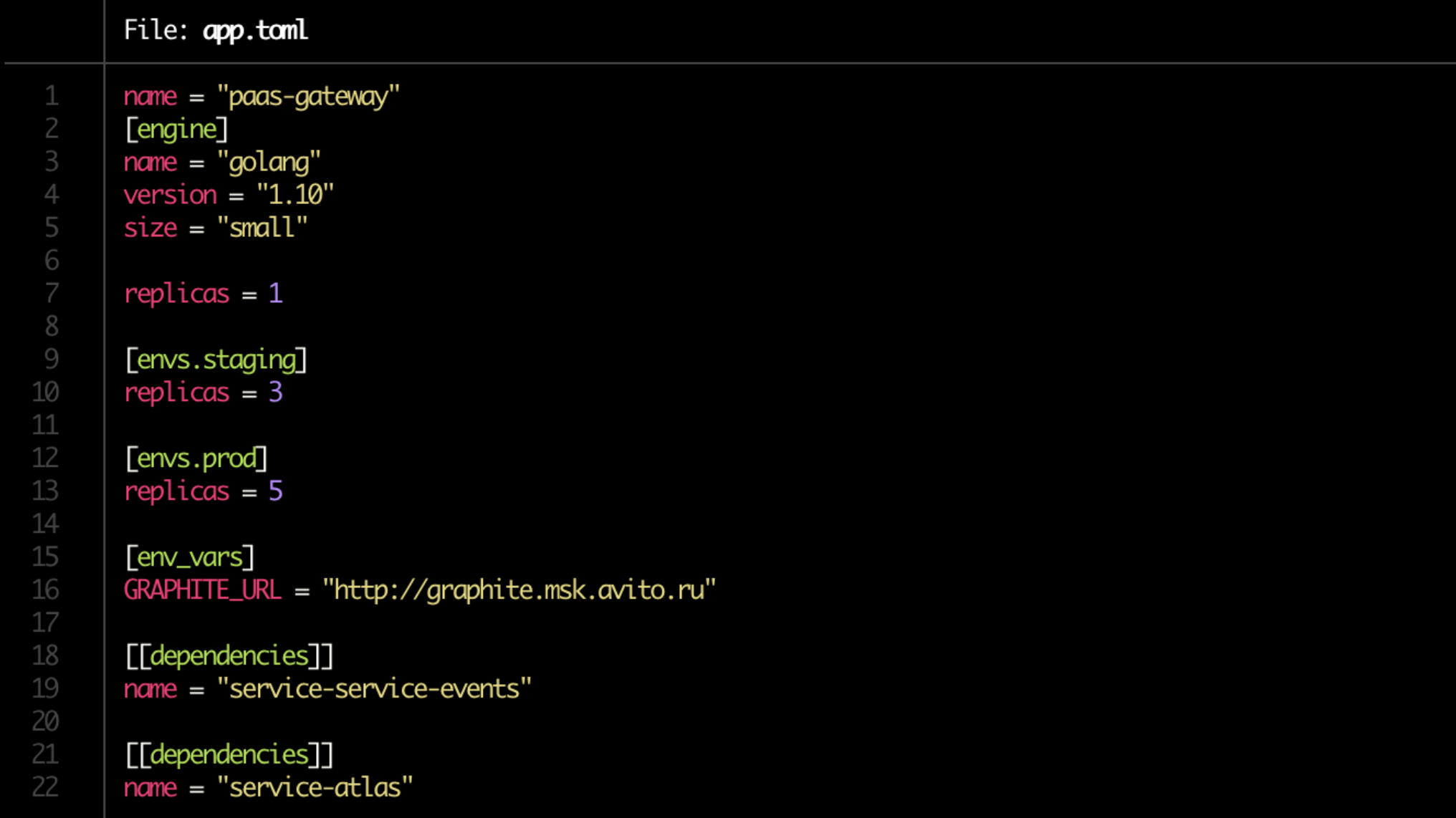
Да и в самом app.toml сейчас дел на минуту. Прописываем, где сколько копий сервиса поднимать (на dev-сервере, на staging, на продакшене), указываем его зависимости. Обратите внимание на строку size = "small" в блоке [engine]. Это лимит, который будет выделен сервису через Kubernetes.
Дальше на базе конфига автоматически генерируются все необходимые Helm-чарты и создаются подключения к базам данным.
• Базовая валидация. Такие проверки тоже автоматизированы.
Нужно отслеживать:
— есть ли Dockerfile;
— есть ли app.toml;
— имеется ли документация;
— в порядке ли зависимости;
— заданы ли правила алертов.
К последнему пункту: владелец сервиса сам указывает, какие продуктовые метрики мониторить.
• Подготовка документации.
До сих пор проблемное место. Вроде бы самое очевидное, но вместе с тем и рекордно «часто забываемое», а значит, и уязвимое звено цепочки.
Необходимо, чтобы документация была под каждый микросервис. Входят в неё следующие блоки.
I. Краткое описание сервиса. Буквально несколько предложений о том, что он делает и для чего нужен.
II. Ссылка на диаграмму архитектуры. Важно, чтобы при беглом взгляде на неё легко было понять, например, используете вы Redis для кэширования или как основное хранилище данных в персистентном режиме. В Авито пока что это ссылка на Confluence.
III. Runbook. Короткий гайд по запуску сервиса и тонкостям обращения с ним.
IV. FAQ, где хорошо бы предвосхитить проблемы, с которыми могут столкнуться ваши коллеги при работе с сервисом.
V. Описание endpoints для API. Если вдруг вы не указали точки назначения, расплачиваться за это почти наверняка будут коллеги, чьи микросервисы связаны с вашим. Сейчас у нас для этого используется Swagger и наше решение под названием brief.
VI. Labels. Или маркеры, которые показывают, к какому продукту, функциональности, структурному подразделению компании относится сервис. Помогают быстро понять, например, не пилите ли вы функциональность, которую неделю назад выкатили для того же бизнес-юнита ваши коллеги.
VII. Владелец или владельцы сервиса. В большинстве случаев его — или их — с помощью PaaS получается определить автоматически, но для страховки мы требуем от разработчика указывать их и вручную.
Наконец, хорошая практика — проводить ревью документации, по аналогии с code review.
Continuous Integration
- Подготовка репозиториев.
- Создание пайплайна в TeamCity.
- Выставление прав.
- Поиск владельцев сервиса. Тут гибридная схема — ручная маркировка и минимальная автоматика от PaaS. Полностью автоматическая схема дает сбои при передаче сервисов в поддержку в другую команду разработки или, например, если разработчик сервиса уволился.
- Регистрация сервиса в Atlas (см. выше). Со всеми его владельцами и зависимостями.
- Проверка миграций. Проверяем, нет ли среди них потенциально опасных. Например, в одной из них всплывает alter table или ещё что-то способное нарушить совместимость схемы данных между разными версиями сервиса. Тогда миграция не выполняется, а ставится в подписку — PaaS должна просигналить владельцу сервиса когда станет безопасно ее применить.
Bake
Следующая стадия — упаковка сервисов перед деплоем.
- Сборка приложения. По классике — в Docker-образ.
- Генерация Helm-чартов для самого сервиса и связанных с ним ресурсов. В том числе для баз данных и кэша. Создаются они автоматически в соответствии с тем конфигом app.toml, который был сформирован на стадии CLI-push.
- Создание тикетов админам на открытие портов (когда это требуется).
- Прогон юнит-тестов и подсчёт code coverage. Если покрытие кода ниже заданного порогового значения, то, скорее всего, дальше — на деплой — сервис не пройдёт. Если оно на грани допустимого, то сервису будет присвоен «пессимизирующий» коэффициент: тогда при отсутствии улучшений показателя с течением времени разработчик получит уведомление о том, что прогресса по части тестов нет (и надо бы что-то с этим сделать).
- Учёт ограничений по памяти и CPU. В основном микросервисы мы пишем на Golang и запускаем их в Kubernetes. Отсюда одна тонкость, связанная с особенностью языка Golang: по умолчанию при запуске задействуются все ядра на машине, если в явном виде не выставить переменную GOMAXPROCS и когда на одной машине запускается несколько таких сервисов, то они начинают конкурировать за ресурсы, мешая друг другу. На графиках ниже показано, как меняется время выполнения, если запустить приложение без конкуренции и в режиме гонки за ресурсы. (Исходники графиков лежат здесь).

Время исполнения, меньше — лучше. Максимум: 643ms, минимум: 42ms. Фото кликабельно.
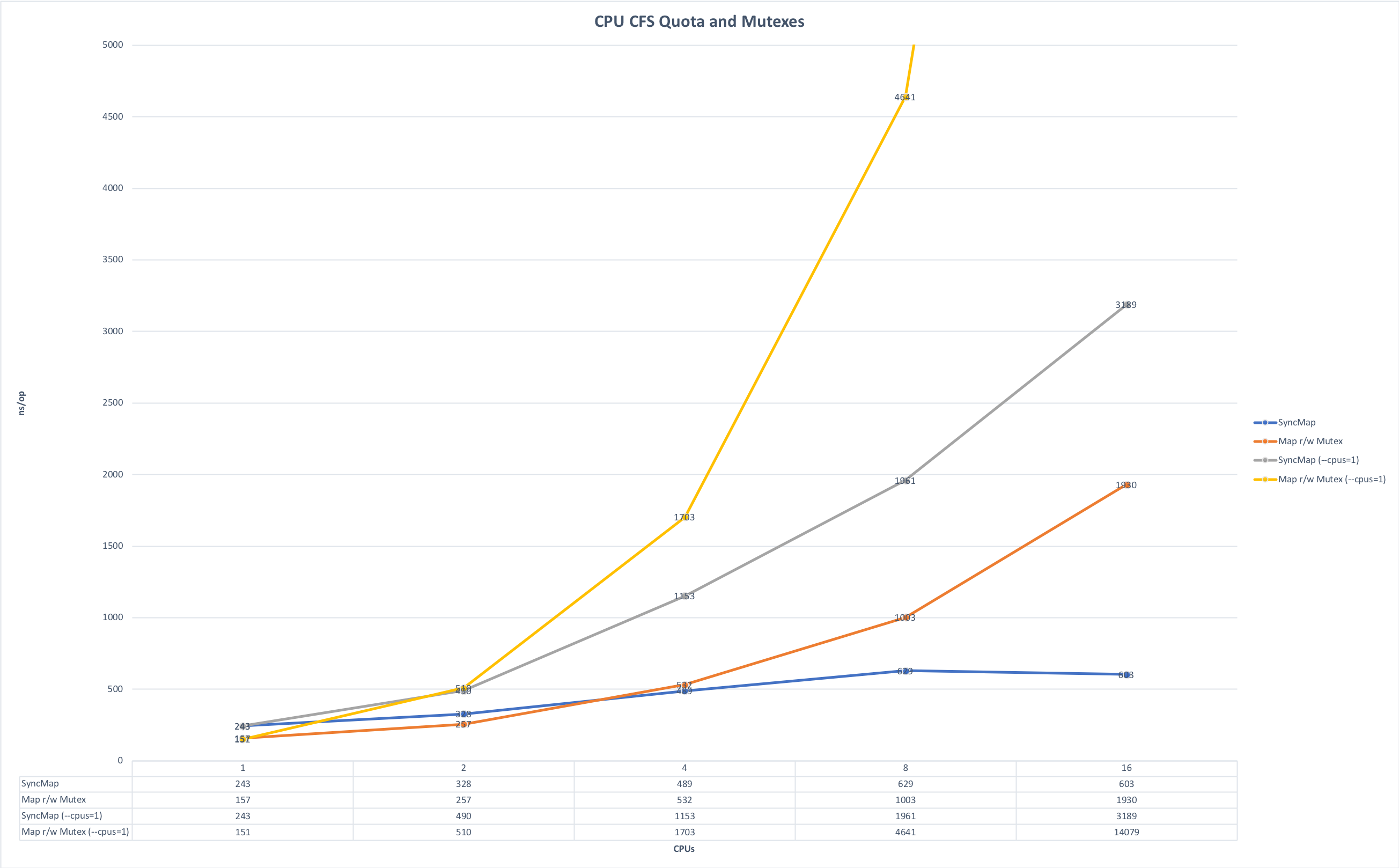
Время на операцию, меньше — лучше. Максимум: 14091 ns, минимум: 151 ns. Фото кликабельно.
На этапе подготовки сборки можно выставлять эту переменную явно или можно пользоваться библиотекой automaxprocs от ребят из Uber.
Деплой
• Проверка конвенций. Перед тем как начать доставлять сборки сервиса в намеченные среды, нужно проверить следующее:
— API endpoints.
— Соответствие ответов API endpoints схеме.
— Формат логов.
— Выставление заголовков при запросах к сервису (сейчас это делает netramesh)
— Выставление маркера владельца при отправке сообщений в шину (event bus). Это нужно для отслеживания связности сервисов через шину. В шину можно отправлять как идемпотентные данные, не повышающие связность сервисов (что хорошо), так и бизнес-данные, которые связность сервисов усиливают (что очень плохо!). И в тот момент, когда эта связность становится проблемой, понимание, кто пишет и читает шину, помогает правильно разделить сервисы.
Пока конвенций в Авито не очень много, но их пул расширяется. Чем больше подобных соглашений в виде, понятном и удобном команде, тем проще поддерживать согласованность между микросервисами.
Синтетические тесты
• Тестирование в закрытом контуре. Для него мы сейчас используем опенсорсный Hoverfly.io. Сначала он записывает реальную нагрузку на сервис, затем — как раз в закрытом контуре — её эмулирует.
• Нагрузочное тестирование. Все сервисы мы стараемся привести к оптимальной производительности. И все версии каждого сервиса должны подвергаться нагрузочному тестированию — так мы можем понять текущую производительность сервиса и разницу с предыдущими версиями этого же сервиса. Если после апдейта сервиса его performance упал в полтора раза, это чёткий сигнал для его владельцев: нужно закопаться в код и исправить ситуацию.
От собранных данных мы отталкиваемся, например, чтобы правильно реализовать auto scaling и, в конце концов, вообще понять, насколько сервис поддаётся масштабированию.
При нагрузочном тестировании мы проверяем, отвечает ли потребление ресурсов выставленным ограничениям. И заостряем внимание прежде всего на экстремумах.
a) Смотрим на общую нагрузку.
— Слишком мала — скорее всего что-то вообще не работает, если нагрузка вдруг упала в несколько раз.
— Слишком велика — требуется оптимизация.
b) Смотрим на отсечку по RPS.
Тут смотрим и разницу текущей версии и предыдущей и общее количество. Например, если сервис выдает 100 rps — то он либо плохо написан, либо это его специфика, но в любом случае это повод очень пристально посмотреть на сервис.
Если же RPS наоборот слишком много, то, возможно, какой-то баг и какой-то из endpoint-ов перестал выполнять полезную нагрузку, а просто срабатывает какой-нибудь return true;
Canary-тесты
После того как пройдены синтетические тесты, мы обкатываем работу микросервиса на малом количестве пользователей. Начинаем осторожно, с мизерной доли предполагаемой аудитории сервиса — меньше 0,1%. На этом этапе очень важно, чтобы в мониторинге были заведены правильные технические и продуктовые метрики, чтобы они максимально быстро показали проблему в сервисе. Минимальное время canary-теста — 5 минут, основное — 2 часа. Для сложных сервисов выставляем время в ручном режиме.
Анализируем:
— метрики, специфические для языка, в частности, воркеры php-fpm;
— ошибки в Sentry;
— статусы ответов;
— время ответов (response time), точное и среднее;
— latency;
— исключения, обработанные и необработанные;
— продуктовые метрики.
Squeeze Testing
Squeeze Testing ещё называют тестированием через «выдавливание». Название методики ввели в Netflix. Суть её в том, что сначала мы заполняем реальным трафиком один инстанс до состояния отказа и таким образом устанавливаем его предел. Дальше добавляем ещё один инстанс и нагружаем эту парочку — снова до максимума; мы видим их потолок и дельту с первым «сквизом». И так подключаем по одному инстансу за шаг и высчитываем закономерность в изменениях.
Данные по тестам через «выдавливание» тоже стекаются в общую базу метрик, где мы либо обогащаем ими результаты искусственной нагрузки, либо вообще заменяем ими «синтетику».
Продакшен
• Масштабирование. Выкатывая сервис на продакшен, мы отслеживаем, как он масштабируется. Мониторить при этом только показатели CPU, по нашему опыту, неэффективно. Auto scaling с бенчмаркингом RPS в чистом виде работает, но лишь для отдельных сервисов, например онлайн-стриминга. Так что мы смотрим в первую очередь на специфические для приложения продуктовые метрики.
В итоге при масштабировании анализируем:
— показатели CPU и RAM,
— количество запросов в очереди,
— время ответа,
— прогноз на основании накопленных исторических данных.
При масштабировании сервиса также важно отслеживать его зависимости, чтобы не получилось так, что мы первый сервис в цепочке скейлим, а те, к которым он обращается, падают под нагрузкой. Чтобы установить приемлемую для всего пула сервисов нагрузку, мы смотрим на исторические данные «ближайшего» зависимого сервиса (по комбинации показателе CPU и RAM вкупе с app-specific metrics) и сопоставляем их с историческими данными инициализирующего сервиса, и так далее по всей «цепочке зависимостей», сверху донизу.
Обслуживание
После того как микросервис введён в строй, мы можем навешивать на него триггеры.
Вот типичные ситуации, в которых срабатывают триггеры.
— Обнаружены потенциально опасные миграции.
— Были выпущены обновления безопасности.
— Сам сервис давно не обновлялся.
— Ощутимо снизилась нагрузка на сервис или какие-либо его продуктовые метрики выходят за пределы нормы.
— Сервис перестал соответствовать новым требованиям платформы.
Часть триггеров отвечает за стабильность работы, часть — как функция обслуживания системы — например, какой-то сервис давно не деплоился и его базовый образ перестал проходить проверку безопасности.
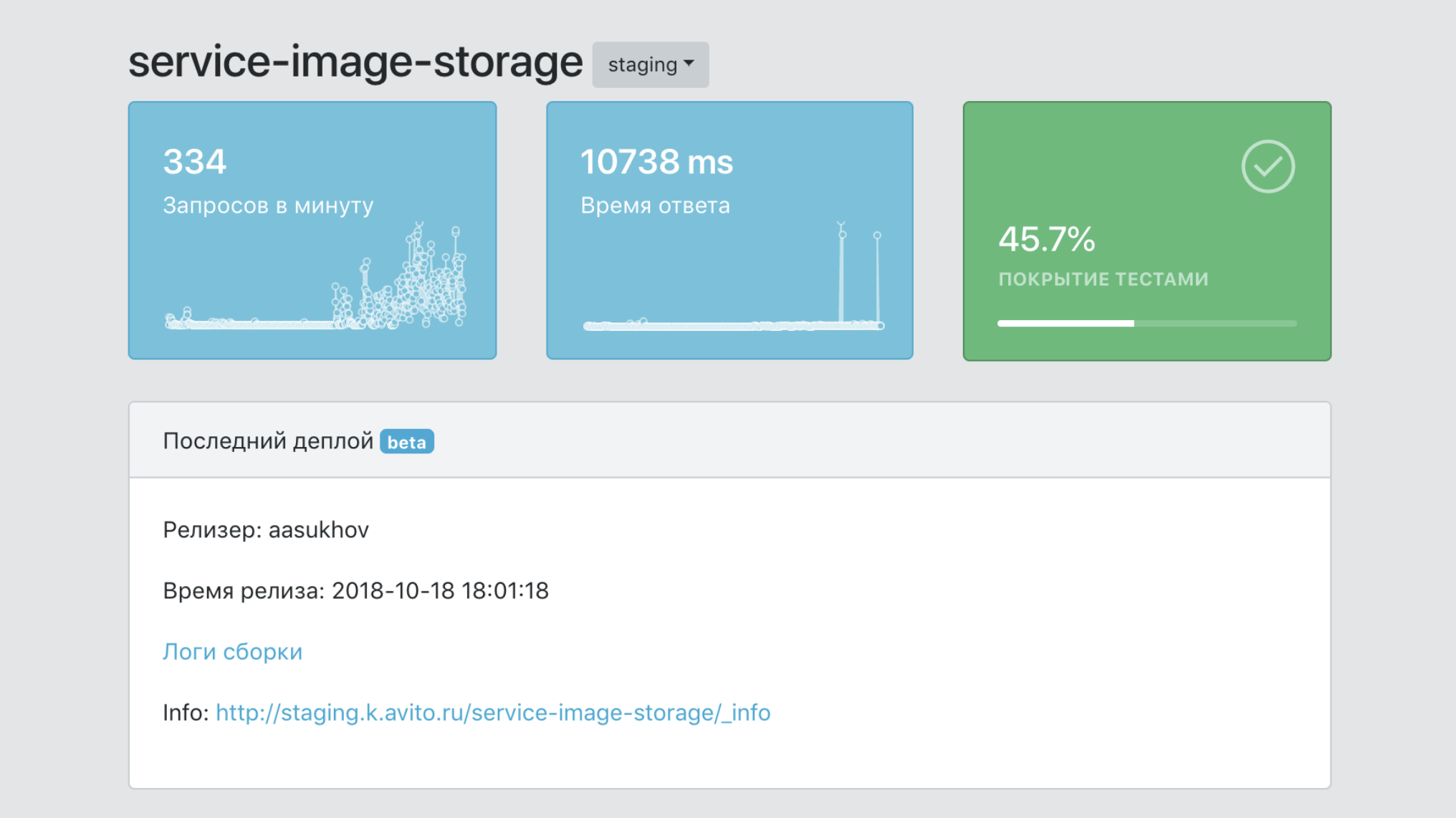
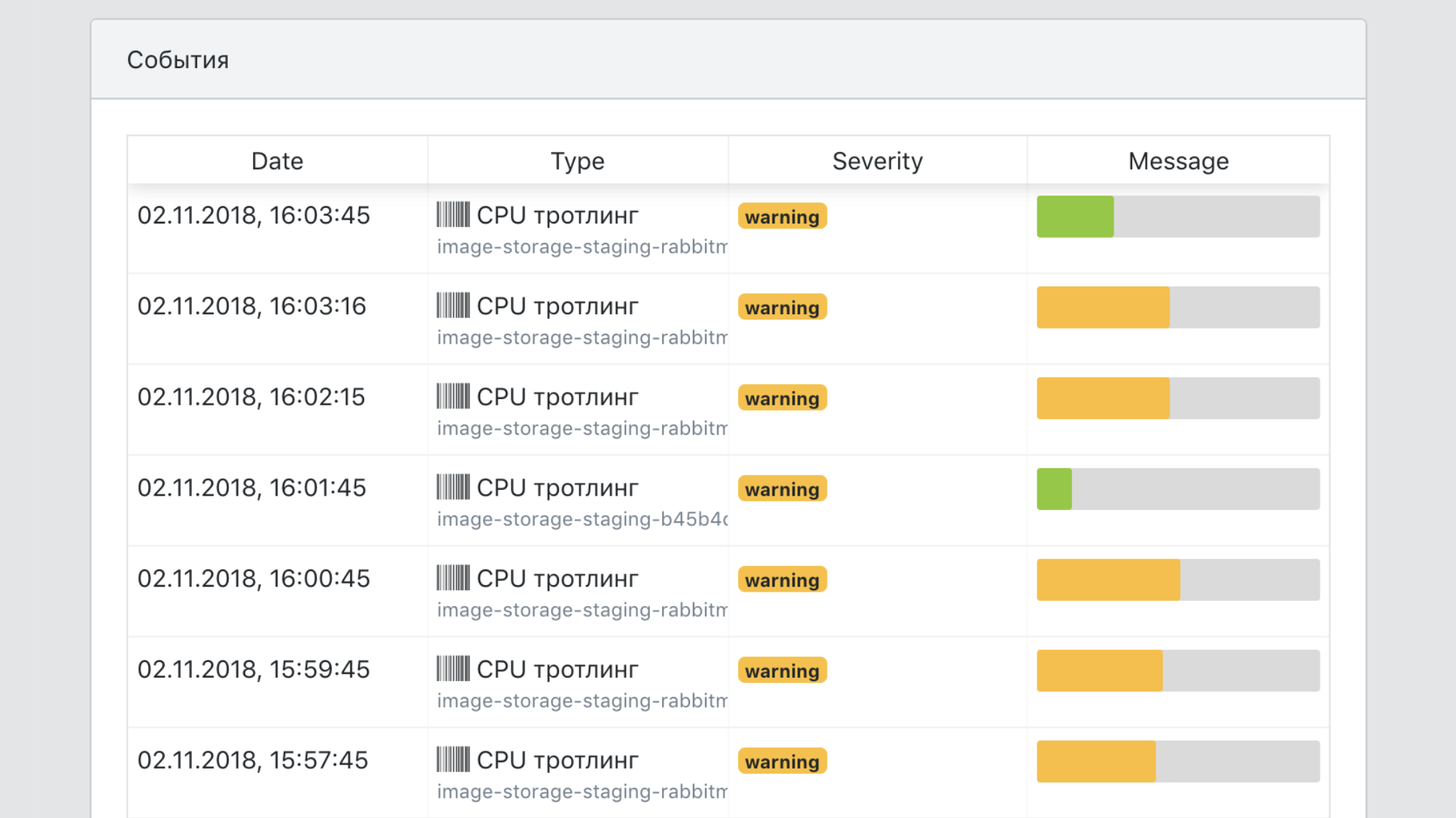
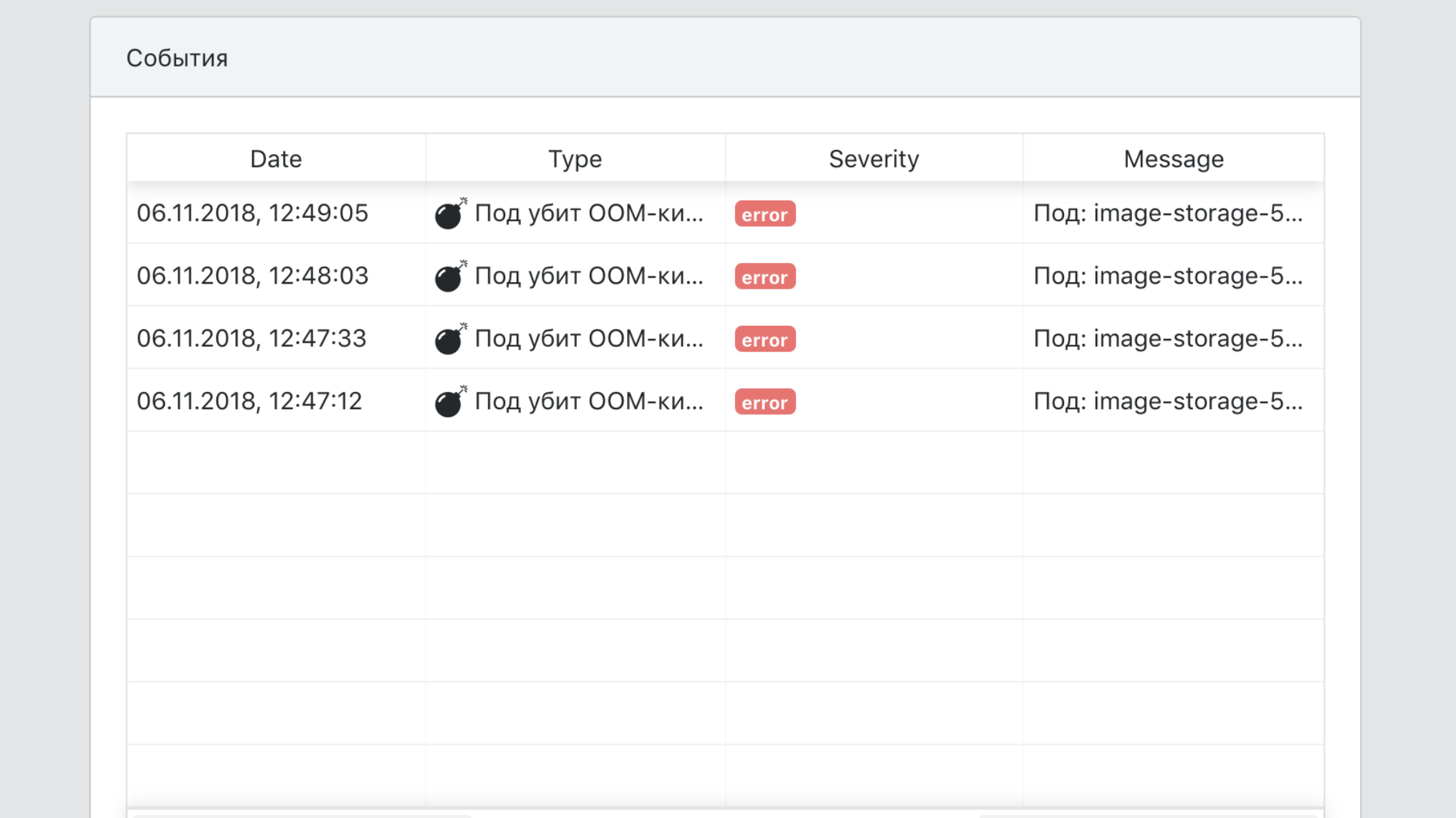
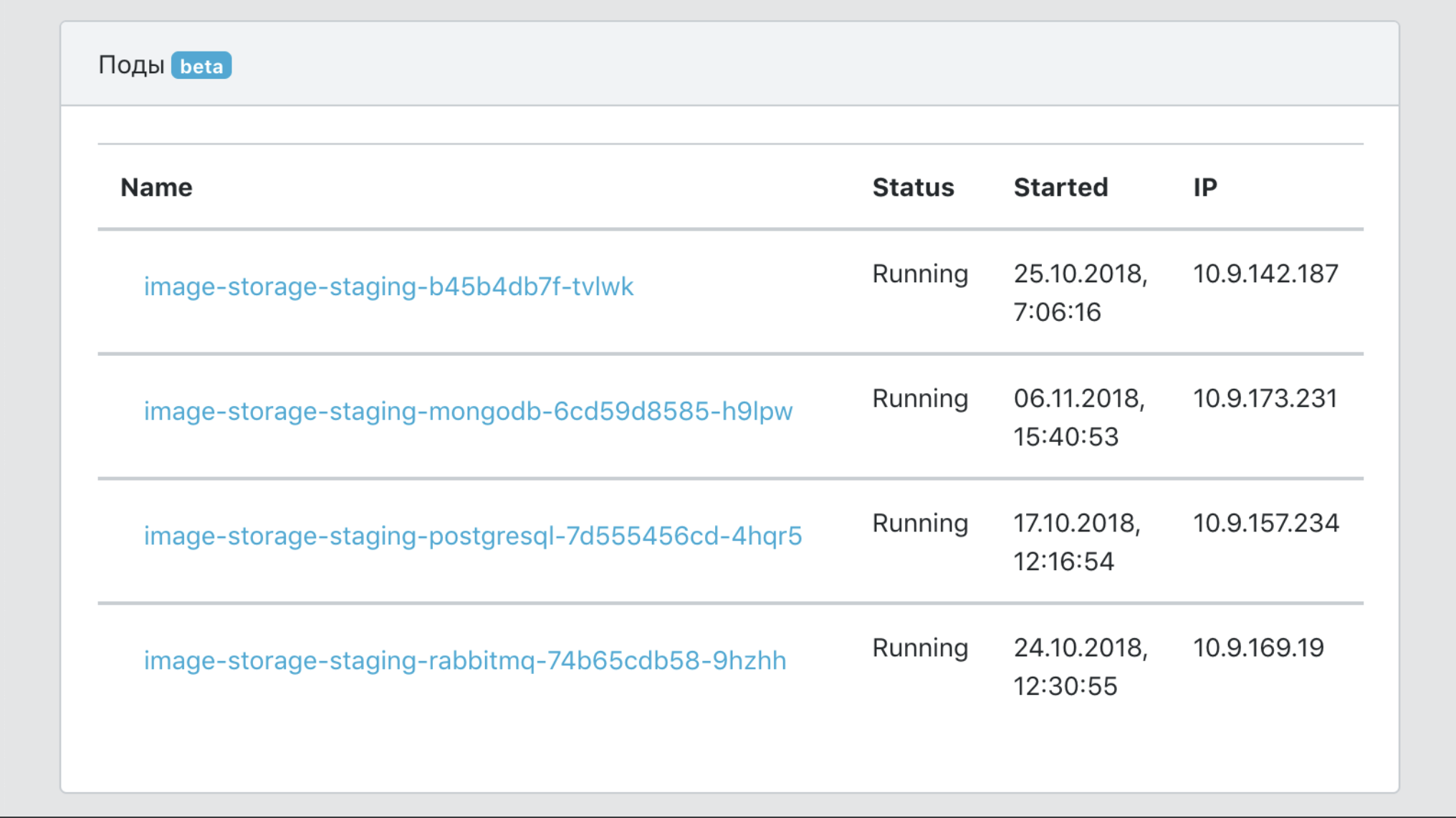
Дашборд
Если совсем коротко, дашборд — контрольный пульт всего нашего PaaS.
- Единая точка информации о сервисе, с данными о его покрытии тестами, количестве его образов, количестве продакшен-копий, версий и т. д.
- Средство фильтрации данных по сервисам и labels (маркерам принадлежности к бизнес-юнитам, продуктовой функциональности и т. д.)
- Средство интеграции с инфраструктурными инструментами для трассировки, логирования, мониторинга.
- Единая точка документации по сервисам.
- Единая точка обзора всех событий по сервисам.
Итого
До внедрения PaaS новый разработчик мог потратить несколько недель на то, чтобы разобраться во всех инструментах, необходимых для запуска микросервиса в продакшен: Kubernetes, Helm, — в наших внутренних особенностях TeamCity, настройке подключения к базам и кэшам в отказоустойчивом виде и т. д. Сейчас на это уходит пара часов — прочесть quickstart и сделать сам сервис.
Я делал доклад на эту тему для HighLoad++ 2018, можно посмотреть видео и презентацию.
Бонус-трек для тех, кто дочитал до конца
Мы в Авито организуем внутренний трёхдневный тренинг для разработчиков от Криса Ричардсона, эксперта по микросервисной архитектуре. Хотим подарить возможность участия в нём кому-то из читателей этого поста. Здесь выложена программа тренинга.
Тренинг пройдёт с 5 по 7 августа в Москве. Это рабочие дни, которые будут полностью заняты. Обед и обучение будут в нашем офисе, а дорогу и проживание выбранный участник оплачивает сам.
Подать заявку на участие можно в этой гугл-форме. От вас — ответ на вопрос, почему именно вам нужно посетить тренинг и информация, как с вами связаться. Отвечайте на английском, потому что участника, который попадёт на тренинг, Крис будет выбирать сам.
Мы объявим имя участника тренинга апдейтом к этому посту и в социальных сетях Авито для разработчиков (AvitoTech в Фейсбуке, Вконтакте, Твиттере) не позднее 19 июля.



