
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!

Проанализируем объявление о приеме на работу в Теслу на позицию джуниор-проектировщика процессора для AI автопилота автомобиля (скриншот ниже). Как мы видим, от соискателя требуется понимание микроархитектуры процессора, проектирование на уровне регистровых передач используя язык описания аппаратуры Verilog, а также понимание, как проектирование логики влияет на временные задержки. Иными словами, соискатель должен понимать, как связаны его строки на верилоге с гигагерцами синтезируемого из них процессора. А понимаете ли это вы?

90% текстов, которые выдает гугл на запрос "что такое тактовая частота процессора", содержат очень мутные "объяснения", который продавцы и поверхностные популяризаторы переписывают друг у друга. Например пишут "тактовая частота - это число тактов (операций) в секунду", не определяя что такое операция:
Может мутнописатели считают операцией элементарную логическую операцию типа И, ИЛИ, НЕ? Непохоже, потому за один такт гигагерцового процессора сигнал от одного D-триггера до другого может пройти через цепочку из пары десятков таких элементов.
Или они считают операцией вычисление в блоке типа комбинационного сумматора? Тоже непохоже, так как 1) два таких сумматора можно поставить каскадом друг за другом и будет две операции за такт и 2) один сумматор можно разложить на два такта, поставить внутри него слой из D-триггеров.
Может эти писатели считают операцией архитектурную инструкцию/команду процессора, соотвествующую инструкции ассемблера (за исключением псевдоинструкций)? Типа "add r1, r2, r3". Опять же, нет, так как инструкция может проходить конвейер за пару десятков тактов.

Хуже того, последовательное выполнение инструкций процессора - это иллюзия, поддерживаемая процессором для удобства программиста. Параллельность в процессоре не исчерпывается многоядерностью. В динамическом конвейере даже одного суперскалярного ядра могут одновременно на разных стадиях выполнения находиться десятки и даже сотни инструкций, причем многие из них выполняться спекулятивно.
Слева - картинка из полезной книжки Modern Processor Design: Fundamentals of Superscalar Processors 1st Edition by John Paul Shen and Mikko H. Lipasti, которую я рекомендую, если вы хотите разобраться с конвейерами процессоров. Но ее стоит читать после вводной книжки Харрисов.
Вообще "что такое тактовая частота" лучше объяснять не сверху, через инструкции процессора, а снизу, начиная от задержек распостранения сигнала в комбинационных вычислениях и с элементов состояния - D-триггеров. Вот объяснение на пальцах из моего старого поста:
Допустим, нам нужно сделать микросхему - счетчик, которая бы выводила в цикле числа 0, 1, 2, 3, 0, 1, 2, 3, ...
Пишем на SystemVerilog:
module counter
(
input clock,
input reset,
output reg [1:0] n
);
always @(posedge clock)
begin
if (reset)
n <= 0;
else
n <= n + 1;
end
endmodule
Это означает: Имеется модуль, в который идет два провода - clock (сигнал тактовой частоты, который идет вверх-вниз-вверх-вниз-...) и reset (сброс в начальное состояние). Из модуля выходит тоже два провода, которые образуют одно двухбитное число, которое на каждом биении сигнала тактовой частоты увеличивают значение на единицу (по модулю 4). Иными словами: на каждом положительном фронте тактового сигнала (positive clock edge - переход с 0 в 1) смотреть на провод reset. Если reset равен 1, то обнулить внутренний регистр (подсоединенный к выводу), если reset равен 0, то увеличить число, хранящееся в этом регистре на единицу.
Теперь если скормить этот код программе логического синтеза, в нашем случае Synopsys Design Compiler, то он превратит его вот в такую схему:

Схема выглядит мудрено, но на самом деле она работает так:
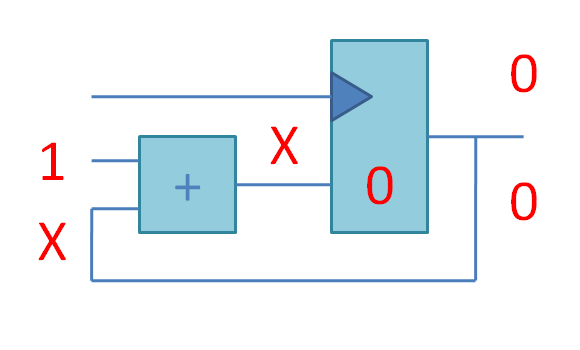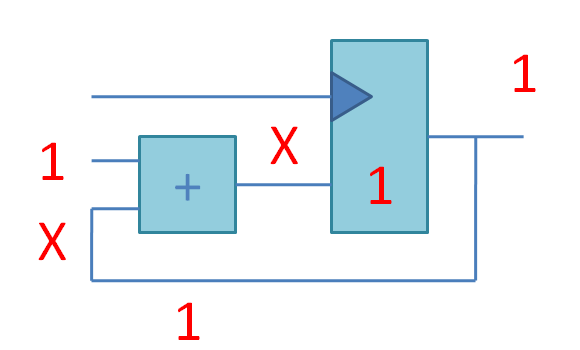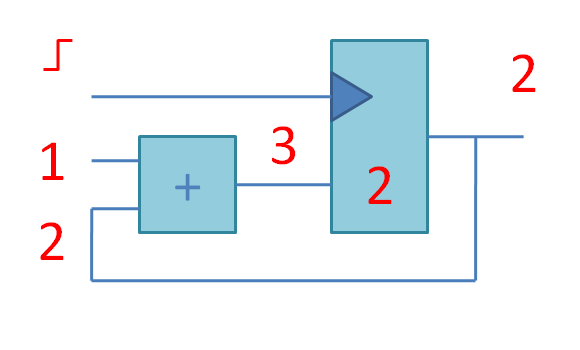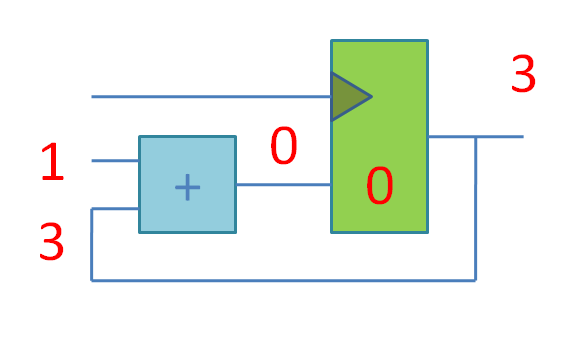
Что происходит в этой схеме:
Квадратик слева - сумматор, такая комбинационная схема, которая берет на входе два числа и через некоторое время T (выраженное в пикосекундах) выдает на выходе их сумму. До истечения времени T на выходе сумматора будут находиться какие-то неопределенные значения, а после T все устаканится.
Время T должно быть меньше, чем время между положительными фронтами (переходами с 0 в 1) сигнала тактовой частоты (clock). Точнее, наоборот. Проектировщик задаёт программе-синтезатору, с какой частотой должна работать схема и программа подбирает подходящий сумматор (быстрый (с малой задержкой в пикосекундах) и большой, медленный-маленький и т.д.) под эту частоту. Если получится (если не получится - синтезатор рапортует negative slack).
Квадратик справа - это двухбитовый регистр из двух D-триггеров (по английски D-flip-flop). Каждый из D-триггеров хранит бит информации между пульсами тактового сигнала. Пока всякая арифметика в сумматоре устаканивается, булькает и чавкает, в это время D-триггер хранит значение с предыдущего такта и отдает его только в качестве read-only значения для вычислений.
В конце-концов вся комбинационная логика (сумматор) устаканивается, и наконец приходит положительный фронт тактового сигнала, который разрешает D-триггеру записать новые значения для следующего такта.

Вот чуть более глубокое описание из моих черновиков к сценарию курса Как работают создатели умных наночипов: логическая сторона цифровой схемотехники
Пути в комбинационном облаке считаются от выхода Q одного D-триггера до входа D другого D-триггера. Путь с самой длинной временной задержкой называется "критическим путем", по английски critical path. По задержке на критическом пути определяется максимальная частота тактового сигнала, которую можно использовать для работы схемы. Например есть задержка на критическом пути равно 500 пикосекунд, то максимальная частота тактового сигнала равно 1 / 500 пикосекунд = 2 Гигагерца.
Для разработчика уровня регистровых передач следить за максимальной частотой не менее важно, чем сделить за тем, что схема производит правильные результаты. Рынок не примет чип, который работает правильно, но при этом существенно медленнее, чем чипы от конкурирующих компаний.
Для того, чтобы уменьшить критический путь, разработчик использует различные приемы, многие из которых приходят с опытом. Два главных приема:
* Выполнять как можно больше действий параллельно, не создавая зависимостей в порядке выполнения между ними.
* Разрезать критический путь на несколько коротких путей, вставляя в него D-триггеры. Тогда некоторые вычисления будут занимать не один цикл тактового сигнала, а несколько, но из-за более высокой тактовой частоты, общая производительность схемы увеличится.
Программы, которые анализируют критические пути, называются программами статического анализа задержек, по английски static timing analysis. При анализе программа смотрит не только на функции задержки и связанность графа схемы, но и на логику работы схемы, из-за которой некоторые пути в графе могут оказаться "ложными" и проигнорированы.

Для анализа, вписывается ли ваша схема в бюджет тактовой частоты, используют так называемые программы статического временного анализа, например Synopsys PrimeTime или Cadence Tempus.

"Ну хорошо, а причем тут Элон Маск", - спросите вы. А притом. Когда вы прийдете к инженерам Маска на собеседование на позицию (см. выше), они вас спросят (обязательно), какой impact производит ваша logic на timing. Например принесут вам распечатку critical path от Synopsys Design Compiler / PrimeTime / ICC2 и спросят что все это значит и как уменьшит negative slack. И что вы будете делать, если вы этой распечатки в жизни не видели?
Скачать тулы от Synopsys с интернета и попрактиковаться вам не светит - они дорого стоят. Как я писал в предыдущем посте:
Это вам не ардуина. Этот софт стоит реально бешенные деньги. Если вы считаете бешенными деньгами скромные $5000 за платную версию Intel FPGA Quartus, то для ASIC design приготовьтесь к следущему уровню бешенности. Еще в 1990-е лицензия на Synopsys Design Compiler стоила в районе 80 тысяч долларов. Потом где-то была цифра что одно инженерное место с Synopsys IC Compiler стоило в ~2010 году $300K, а вот можно нагуглить, что годовая подписка на ICC в 2015 году стоила $735 тысяч долларов. Обычно крупные электронные компании покупают сразу сотни плавающих лицензий и заключают с Cadence и Synopsys сделки на десятки миллионов долларов.
Но выход есть. В эту субботу 12 февраля вы можете принять участие в онлайн занятии Сколковской Школы Синтеза Цифровых Схем вместе с Московским Институтом Электронной Техники, которые договорился с Synopsys, что мы дадим желающим доступ к этим лицензиям на ограниченное время. Записаться можно сегодня (в четверг) до вечера. Зарегистрируйтесь на сайте школы и пошлите емейл Александру Биленко на info@chipexpo.com . Для доступа вам нужно получить от МИЭТ специальный VPN, а также использовать программу VNC для доступа к удаленным линуксным серверам, на которых будут работать все программы. Вот инфо с сайта:
Тема занятия: Пробуем маршрут RTL2GDSII: как разрабатываются массовые микросхемы.
Часть II. Synopsys.
Ведет Андрей Владимирович Коршунов, доцент кафедры ПКИМС МИЭТ
Среди спонсоров школы - российская процессорная компания Syntacore, которая сейчас как раз набирает людей на проектировщиков процессоров , так что к Маску возможно ехать будет и не нужно. Тем более что в Москве и Питере, где нанимает Syntacore, есть Третьяковская Галерея и Эрмитаж, которых у Маска в Калифорнии и Техасе нет.




